はじめに
「GAN」にものすごく興味があります。特に「pix2pix」に興味があります。
画像から画像を生成する仕組みは、様々な応用が考えられます。
また「GAN」ですので、画像にこだわらずとも、「何か」から「何か」を生成できる気がします。
Qiita内にも「pix2pix」関連の投稿はいっぱいありますが、どうもいまいち内容が理解できない...
ということで、こちらのソースコードをベースに、内容を理解したいと思います。
なお、ソースコードはJupyter Notebookで確認しているため、実際に実行スクリプトとするときにはちょこちょこっと直したほうがいいです。
今回やろうとしていること
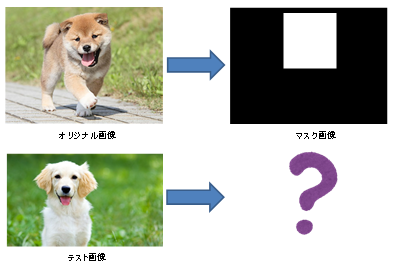
今回は、ある画像から特定の領域を見つけ出すということをやろうかと思います。
オリジナルの画像と、その中のある領域を示すマスク画像を用意し、学習させ、テスト用の画像を渡した時にある領域を見つけ出すといったイメージです。
準備
まず学習データを準備します。
今回は、hdf5(Hierarchical Data Format Version 5)形式にまとめています。
画像を4種類(学習用オリジナル、学習用結果、テスト用オリジナル、テスト用結果)に分け、フォルダに保存しています。
- 学習用オリジナル:train_data_raw
- 学習用結果:train_data_gen
- テスト用オリジナル:val_data_raw
- テスト用結果:val_data_gen
各種宣言
import numpy as np
import glob
import h5py
from keras.preprocessing.image import load_img, img_to_array
画像をnumpyの配列に変換してhdf5で保存するために必要なパッケージを宣言しています。
入出力フォルダ
inpath = '.\\input'
outpath = '.\\output'
学習用の画像データの入っているフォルダと、作成したhdf5ファイルの保存先を指定しています。
別にどこでもいいですし、実際には引数から指定できるようにしたほうがいいです。
ファイルの読み込み
orgs = []
masks = []
print('original img')
files = glob.glob(inpath+'\\org\\*.jpg')
for imgfile in files:
print(imgfile)
img = load_img(imgfile, target_size=(64,64))
imgarray = img_to_array(img)
orgs.append(imgarray)
print('mask img')
files = glob.glob(inpath+'\\mask\\*.jpg')
for imgfile in files:
print(imgfile)
img = load_img(imgfile, target_size=(64,64))
imgarray = img_to_array(img)
masks.append(imgarray)
入力フォルダに「org」と「mask」というフォルダがあり、その中にオリジナル画像(JPEG)とマスク画像(JPEG)が入っているという前提で作られています。
また、オリジナル画像とマスク画像の組み合わせは同じファイル名ということでマッチングしています。
この辺りはそれぞれの環境に合わせて直してもらえればと思います。
globでファイルリストを取得し、forループで回してそれぞれのファイルを読み込みます。
画像は64x64にリサイズし、numpyの配列に変換後、ため込んでいます。
画像サイズは、それぞれの環境に合わせて調整してもらえればと思います。
分割
perm = np.random.permutation(len(orgs))
orgs = np.array(orgs)[perm]
masks = np.array(masks)[perm]
threshold = len(orgs)//10*9
imgs = orgs[:threshold]
gimgs = masks[:threshold]
vimgs = orgs[threshold:]
vgimgs = masks[threshold:]
print('shapes')
print('org imgs : ', imgs.shape)
print('mask imgs : ', gimgs.shape)
print('test org : ', vimgs.shape)
print('test tset : ', vgimgs.shape)
ここでは、読み込んだ画像を学習用とテスト用に分割しています。
まず画像の順番をランダムに並べ直し、学習用とテスト用を9:1の割合で分割します。
(オリジナル/マスク共)
最終的には、numpyの配列は、以下のような4次元配列になっています。
org imgs : (900, 64, 64, 3)
(画像数、縦、横、RGB)といった感じです。
実はマスクの画像もRGBになっています。
hdf5ファイルの保存
outh5 = h5py.File(outpath+'.hdf5', 'w')
outh5.create_dataset('train_data_raw', data=imgs)
outh5.create_dataset('train_data_gen', data=gimgs)
outh5.create_dataset('val_data_raw', data=vimgs)
outh5.create_dataset('val_data_gen', data=vgimgs)
outh5.flush()
outh5.close()
出力フォルダに「datasetimages.hdf5」というファイルを作ります。
分割したそれぞれの画像をフォルダ内に納めた形式で保存されます。
pix2pix本体
ようやく本文です。
説明の方も気合を入れていきます。
見やすくするため、処理のほとんどは関数で宣言されています。
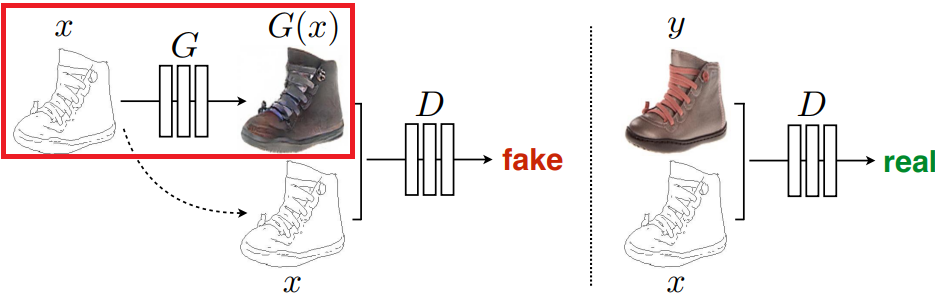
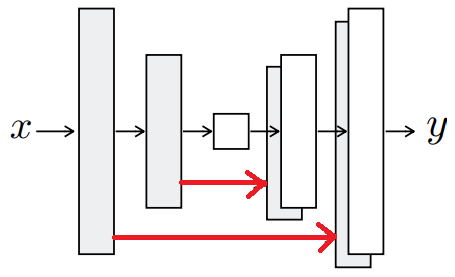
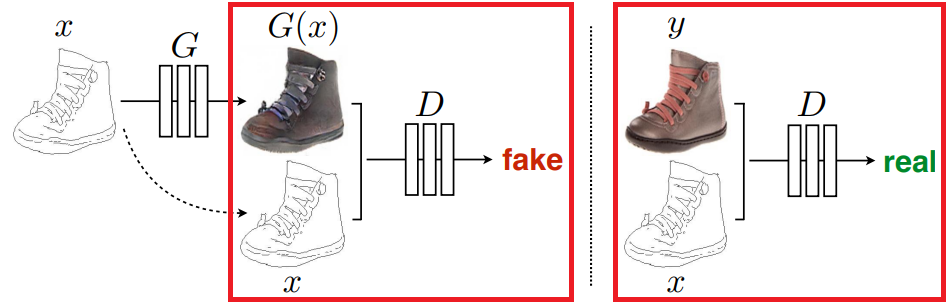
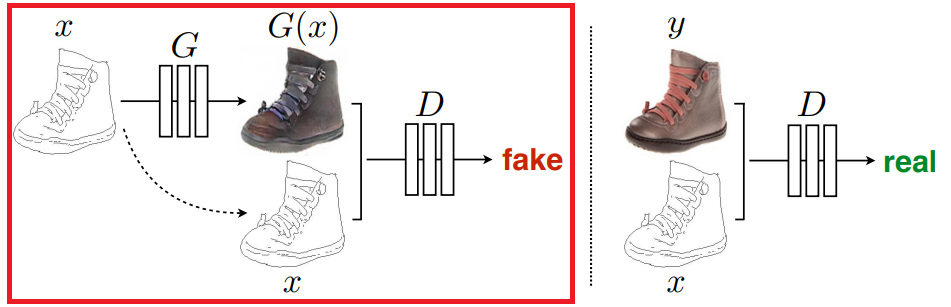
なお、DCGANのイメージはこんな感じです。
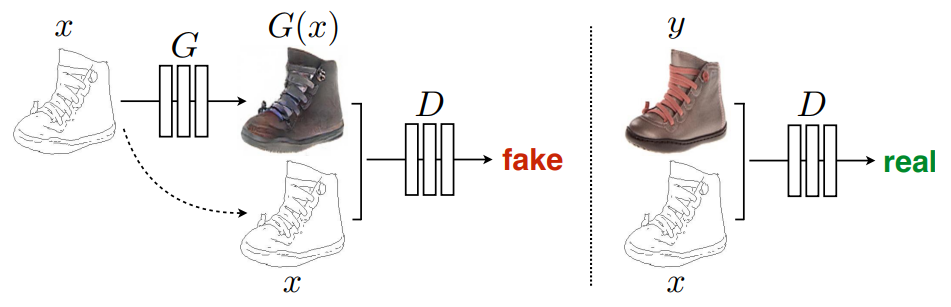
G(Generator)で画像を生成し、D(Discriminator)で本物か偽物かを判断します。
Generatorで生成したものは偽物ですし、オリジナルの組み合わせは本物になります。
※今回は実写からマスクを生成するので、上の画像とはxとG(x) or yが逆になるイメージです
各種宣言
import numpy as np
import h5py
import time
import matplotlib.pylab as plt
import keras.backend as K
from keras.utils import generic_utils
from keras.optimizers import Adam, SGD
from keras.models import Model
from keras.layers.core import Flatten, Dense, Dropout, Activation, Lambda, Reshape
from keras.layers.convolutional import Conv2D, Deconv2D, ZeroPadding2D, UpSampling2D
from keras.layers import Input, Concatenate
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D
import keras.backend as K
%matplotlib inline
使うパッケージをひたすら宣言しています。
基本的に必要なのはKerasになります。timeは時間計測用です。
なお、ここではJupter Notebookでmatplotlib表示するため「%matplotlib inline」が入っています。
変数の宣言
datasetpath = '.\\output\\datasetimages.hdf5'
patch_size = 32
batch_size = 12
epoch = 1000
学習用データのファイルや画像を分割するパッチのサイズ、ミニバッチのサイズ、回すエポック数を指定しています。
この辺りは引数にしたほうがよいかと思います。
学習データの読み込み
def normalization(X):
return X / 127.5 - 1
def load_data(datasetpath):
with h5py.File(datasetpath, "r") as hf:
X_full_train = hf["train_data_raw"][:].astype(np.float32)
X_full_train = normalization(X_full_train)
X_sketch_train = hf["train_data_gen"][:].astype(np.float32)
X_sketch_train = normalization(X_sketch_train)
X_full_val = hf["val_data_raw"][:].astype(np.float32)
X_full_val = normalization(X_full_val)
X_sketch_val = hf["val_data_gen"][:].astype(np.float32)
X_sketch_val = normalization(X_sketch_val)
return X_full_train, X_sketch_train, X_full_val, X_sketch_val
事前に作成した学習データのファイルを読み込みます。
フォルダごとに取出し、0~255を-1~1の値(float32)に変換して保存しています。
- 学習用オリジナル画像:X_full_train
- 学習用マスク画像:X_sketch_train
- テスト用オリジナル画像:X_full_val
- テスト用マスク画像:X_sketch_val
モデル
GeneratorやDiscriminatorを作成します。
共通ブロック
def conv_block_unet(x, f, name, bn_axis, bn=True, strides=(2,2)):
x = LeakyReLU(0.2)(x)
x = Conv2D(f, (3,3), strides=strides, name=name, padding='same')(x)
if bn: x = BatchNormalization(axis=bn_axis)(x)
return x
def up_conv_block_unet(x, x2, f, name, bn_axis, bn=True, dropout=False):
x = Activation('relu')(x)
x = UpSampling2D(size=(2, 2))(x)
x = Conv2D(f, (3,3), name=name, padding='same')(x)
if bn: x = BatchNormalization(axis=bn_axis)(x)
if dropout: x = Dropout(0.5)(x)
x = Concatenate(axis=bn_axis)([x, x2])
return x
GeneratorやDiscriminatorで共通して使用するブロックを作成しています。
「conv_block_unet」は以下の処理を行っています。
- 活性化関数「LeakyReLU」
- 畳み込み
- 正規化「BatchNormalization」
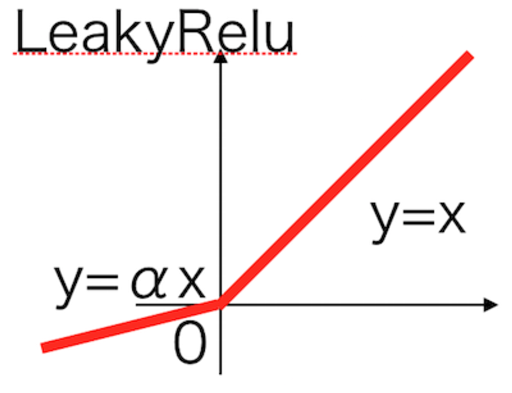
デフォルトのstrideが(2, 2)になっているように、poolingではなくConv2Dで画素数を半分にしています。
「up_conv_block_unet」は以下の処理を行っています。
- 活性化関数「ReLU」
- UpSampling
- 畳み込み
- 正規化「BatchNormalization」
- ドロップアウト(指定されていれば)
- 合成
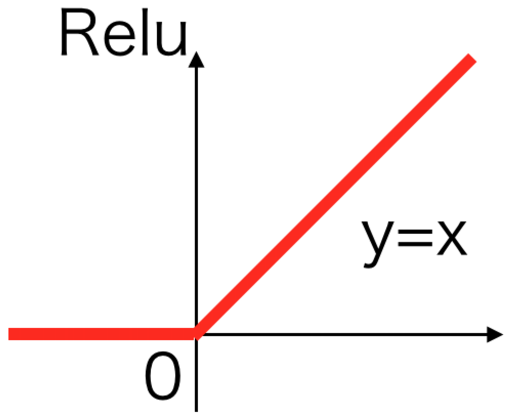
ドロップアウトは学習時のノイズとなり、固定の画像しか生成できないといったことを防ぐ役割をします。
ここでの「合成」が今回のポイントになるかと思います。
pix2pixではUNETモデルというネットワークを使用しており、Encode-Decodeモデルと異なり畳み込んだ時の情報をUpsamplingするときに使用するようになっています。
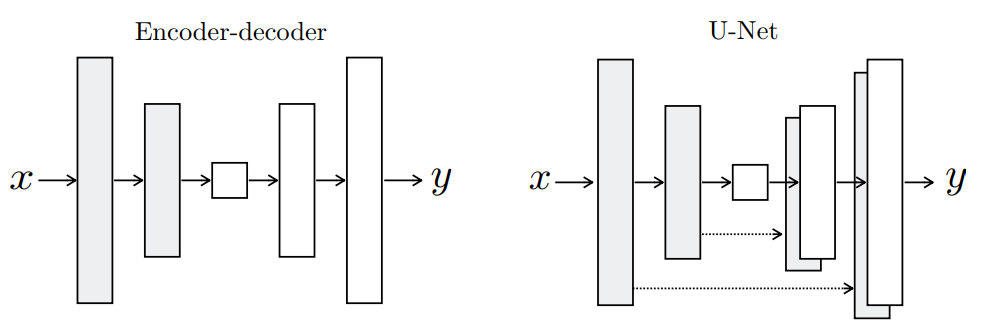
これら「ブロック」の中身に関しては工夫のし甲斐があるような気がします。
(下手をすれば、全然まともなものが生成できなくなる可能性もありますが)
Generator
def generator_unet_upsampling(img_shape, disc_img_shape, model_name="generator_unet_upsampling"):
filters_num = 64
axis_num = -1
channels_num = img_shape[-1]
min_s = min(img_shape[:-1])
unet_input = Input(shape=img_shape, name="unet_input")
conv_num = int(np.floor(np.log(min_s)/np.log(2)))
list_filters_num = [filters_num*min(8, (2**i)) for i in range(conv_num)]
# Encoder
first_conv = Conv2D(list_filters_num[0], (3,3), strides=(2,2), name='unet_conv2D_1', padding='same')(unet_input)
list_encoder = [first_conv]
for i, f in enumerate(list_filters_num[1:]):
name = 'unet_conv2D_' + str(i+2)
conv = conv_block_unet(list_encoder[-1], f, name, axis_num)
list_encoder.append(conv)
# prepare decoder filters
list_filters_num = list_filters_num[:-2][::-1]
if len(list_filters_num) < conv_num-1:
list_filters_num.append(filters_num)
# Decoder
first_up_conv = up_conv_block_unet(list_encoder[-1], list_encoder[-2],
list_filters_num[0], "unet_upconv2D_1", axis_num, dropout=True)
list_decoder = [first_up_conv]
for i, f in enumerate(list_filters_num[1:]):
name = "unet_upconv2D_" + str(i+2)
if i<2:
d = True
else:
d = False
up_conv = up_conv_block_unet(list_decoder[-1], list_encoder[-(i+3)], f, name, axis_num, dropout=d)
list_decoder.append(up_conv)
x = Activation('relu')(list_decoder[-1])
x = UpSampling2D(size=(2, 2))(x)
x = Conv2D(disc_img_shape[-1], (3,3), name="last_conv", padding='same')(x)
x = Activation('tanh')(x)
generator_unet = Model(inputs=[unet_input], outputs=[x])
return generator_unet
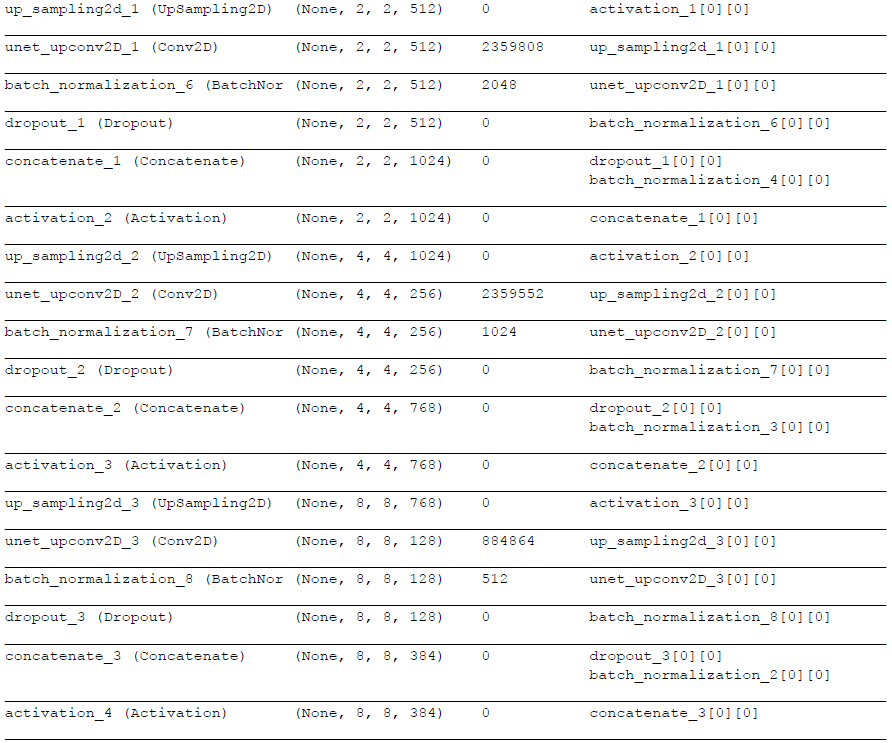
UNETを使って画像を生成する処理になります。
フィルターの階層数は動的に決めています。
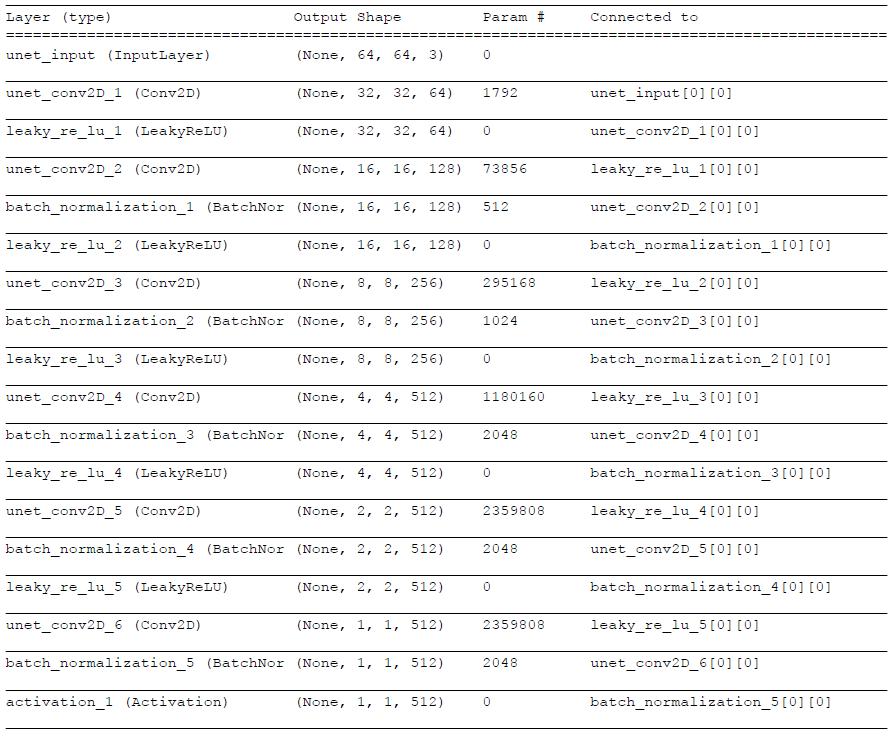

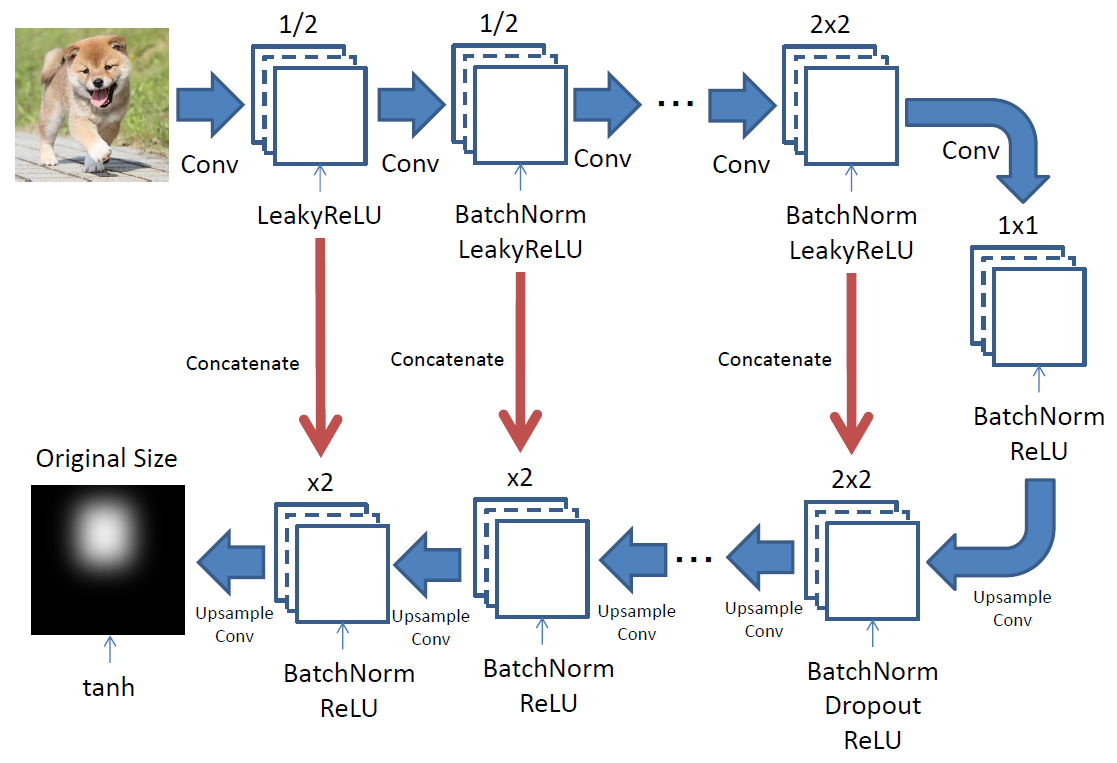
Generatorの入出力画像はパッチに分割されていないオリジナルのサイズのものを使用します。
Encoderで畳み込みを行い、DecoderでUpsamplingしています。
Decoderのブロックには、Upsamplingするデータと対応するEncoderのデータを渡して、中で結合しています。
Decoderでは、最初に追加したブロックとのその後2ブロックだけドロップアウトを指定しています。
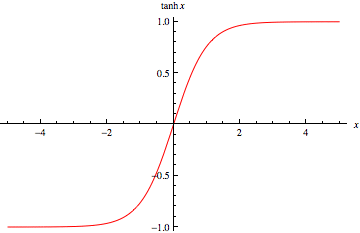
最後の階層のUpsamplingでは、活性化関数を「tanh」にしています。
(そのために、学習データを-1~1に変換しています)
このUNETの部分を別なものに置き換えることは可能かと思います。
要は、何らかの方法で、入力データを元に画像を生成できればよいはずです。
Discriminator
def DCGAN_discriminator(img_shape, disc_img_shape, patch_num, model_name='DCGAN_discriminator'):
disc_raw_img_shape = (disc_img_shape[0], disc_img_shape[1], img_shape[-1])
list_input = [Input(shape=disc_img_shape, name='disc_input_'+str(i)) for i in range(patch_num)]
list_raw_input = [Input(shape=disc_raw_img_shape, name='disc_raw_input_'+str(i)) for i in range(patch_num)]
axis_num = -1
filters_num = 64
conv_num = int(np.floor(np.log(disc_img_shape[1])/np.log(2)))
list_filters = [filters_num*min(8, (2**i)) for i in range(conv_num)]
# First Conv
generated_patch_input = Input(shape=disc_img_shape, name='discriminator_input')
xg = Conv2D(list_filters[0], (3,3), strides=(2,2), name='disc_conv2d_1', padding='same')(generated_patch_input)
xg = BatchNormalization(axis=axis_num)(xg)
xg = LeakyReLU(0.2)(xg)
# First Raw Conv
raw_patch_input = Input(shape=disc_raw_img_shape, name='discriminator_raw_input')
xr = Conv2D(list_filters[0], (3,3), strides=(2,2), name='raw_disc_conv2d_1', padding='same')(raw_patch_input)
xr = BatchNormalization(axis=axis_num)(xr)
xr = LeakyReLU(0.2)(xr)
# Next Conv
for i, f in enumerate(list_filters[1:]):
name = 'disc_conv2d_' + str(i+2)
x = Concatenate(axis=axis_num)([xg, xr])
x = Conv2D(f, (3,3), strides=(2,2), name=name, padding='same')(x)
x = BatchNormalization(axis=axis_num)(x)
x = LeakyReLU(0.2)(x)
x_flat = Flatten()(x)
x = Dense(2, activation='softmax', name='disc_dense')(x_flat)
PatchGAN = Model(inputs=[generated_patch_input, raw_patch_input], outputs=[x], name='PatchGAN')
x = [PatchGAN([list_input[i], list_raw_input[i]]) for i in range(patch_num)]
if len(x)>1:
x = Concatenate(axis=axis_num)(x)
else:
x = x[0]
x_out = Dense(2, activation='softmax', name='disc_output')(x)
discriminator_model = Model(inputs=(list_input+list_raw_input), outputs=[x_out], name=model_name)
return discriminator_model
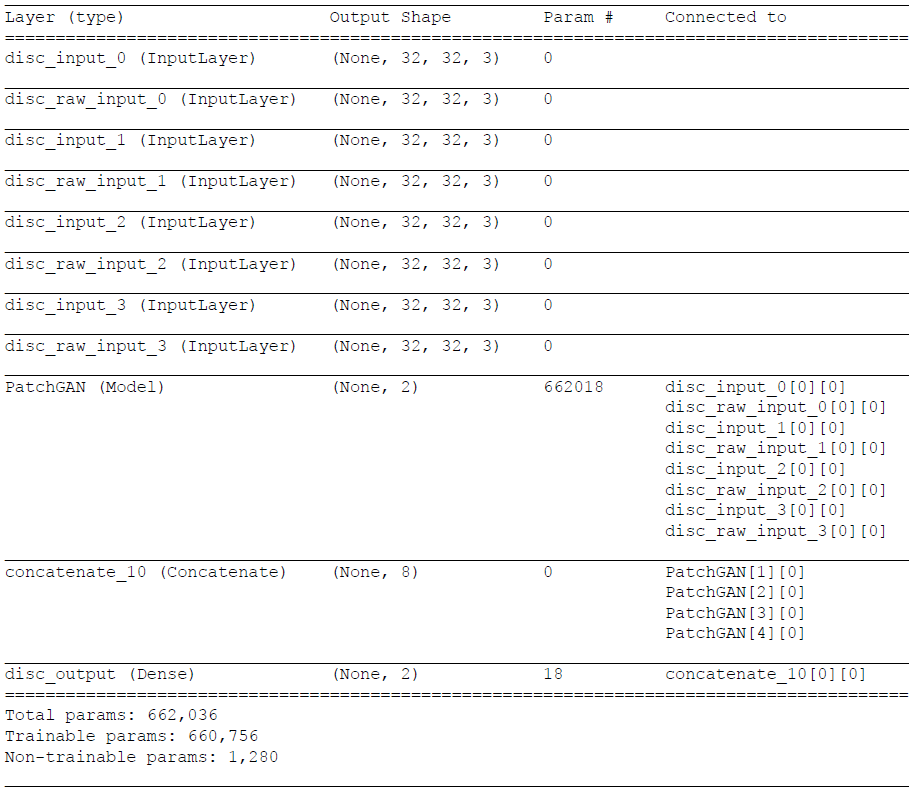
※PatchGAN部分
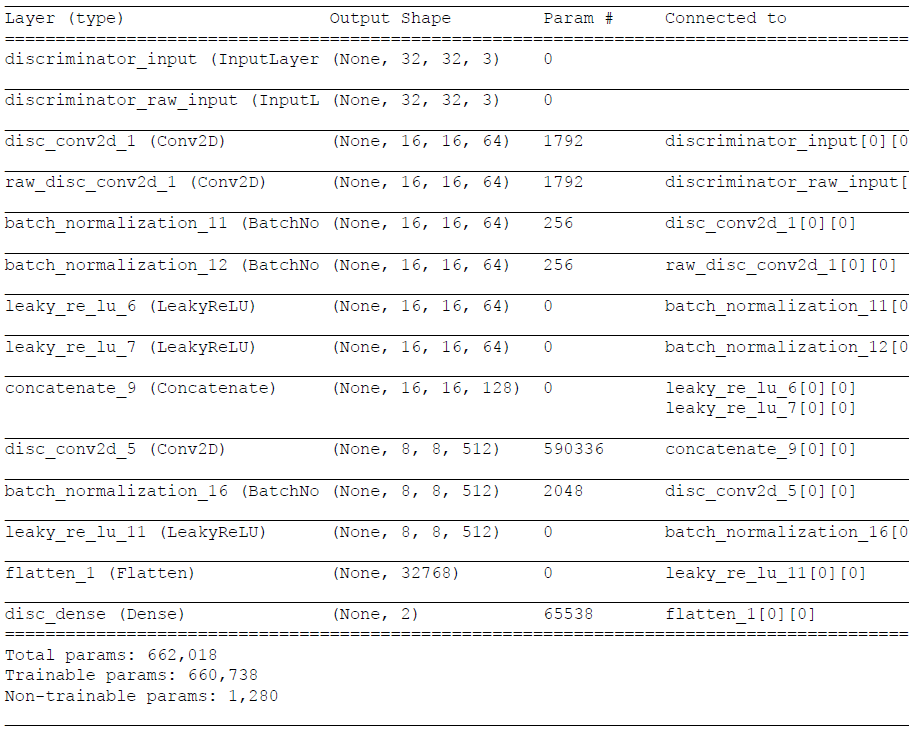
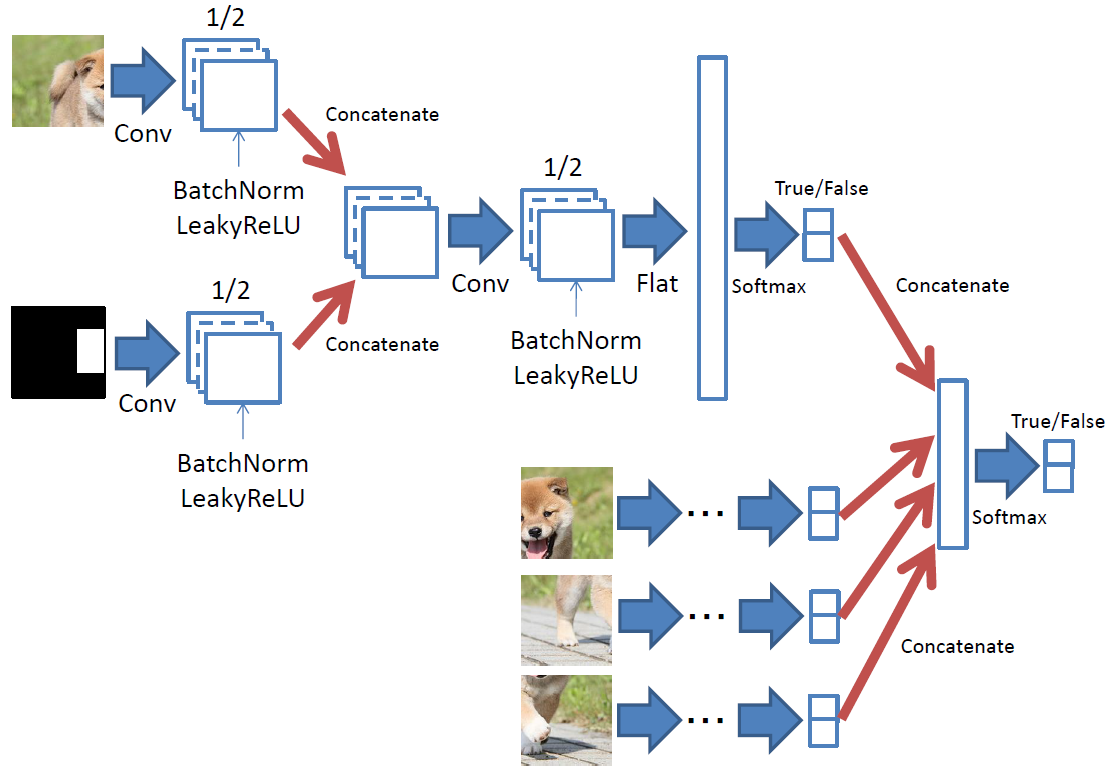
まず、オリジナル画像とマスク画像を1回畳み込みます。
(poolingは使わずにConv2Dのストライドで半分にします)
その後、上記で求めた各パッチごとのデータを結合して、更に畳み込んで全結合用に1次元に変換し、softmaxで2値(True,False)分類します。
その結果を全パッチで結合し、最終的にsoftmaxで2値(True,False)分類します。
※実際には、[0]=fakeの確率、[1]=realの確率になっているみたいです
DCGAN
def DCGAN(generator, discriminator, img_shape, patch_size):
raw_input = Input(shape=img_shape, name='DCGAN_input')
genarated_image = generator(raw_input)
h, w = img_shape[:-1]
ph, pw = patch_size, patch_size
list_row_idx = [(i*ph, (i+1)*ph) for i in range(h//ph)]
list_col_idx = [(i*pw, (i+1)*pw) for i in range(w//pw)]
list_gen_patch = []
list_raw_patch = []
for row_idx in list_row_idx:
for col_idx in list_col_idx:
raw_patch = Lambda(lambda z: z[:, row_idx[0]:row_idx[1], col_idx[0]:col_idx[1], :])(raw_input)
list_raw_patch.append(raw_patch)
x_patch = Lambda(lambda z: z[:, row_idx[0]:row_idx[1], col_idx[0]:col_idx[1], :])(genarated_image)
list_gen_patch.append(x_patch)
DCGAN_output = discriminator(list_gen_patch+list_raw_patch)
DCGAN = Model(inputs=[raw_input],
outputs=[genarated_image, DCGAN_output],
name='DCGAN')
return DCGAN
Generatorで生成した画像をDiscriminatorに渡して判定しています。
画像はパッチに分割して渡しています。これが「PatchGAN」といわれる仕組みになります。
小さい領域で本物/偽物を評価することで高周波成分の特徴をとらえているようです。
呼び出し
def load_generator(img_shape, disc_img_shape):
model = generator_unet_upsampling(img_shape, disc_img_shape)
return model
def load_DCGAN_discriminator(img_shape, disc_img_shape, patch_num):
model = DCGAN_discriminator(img_shape, disc_img_shape, patch_num)
return model
def load_DCGAN(generator, discriminator, img_shape, patch_size):
model = DCGAN(generator, discriminator, img_shape, patch_size)
return model
呼び直しただけなので基本的に意味はありません。
学習
ここからモデルを呼び出して、実際に学習する処理に入ります。
共通処理
def l1_loss(y_true, y_pred):
return K.sum(K.abs(y_pred - y_true), axis=-1)
def inverse_normalization(X):
return (X + 1.) / 2.
def to3d(X):
if X.shape[-1]==3: return X
b = X.transpose(3,1,2,0)
c = np.array([b[0],b[0],b[0]])
return c.transpose(3,1,2,0)
L1正則化を設定したり、正規化(-1~1→0~1)を戻したり、配列の要素の順番を入れ替えたりします。
結果表示
def plot_generated_batch(X_proc, X_raw, generator_model, batch_size, suffix):
X_gen = generator_model.predict(X_raw)
X_raw = inverse_normalization(X_raw)
X_proc = inverse_normalization(X_proc)
X_gen = inverse_normalization(X_gen)
Xs = to3d(X_raw[:5])
Xg = to3d(X_gen[:5])
Xr = to3d(X_proc[:5])
Xs = np.concatenate(Xs, axis=1)
Xg = np.concatenate(Xg, axis=1)
Xr = np.concatenate(Xr, axis=1)
XX = np.concatenate((Xs,Xg,Xr), axis=0)
plt.imshow(XX)
plt.axis('off')
plt.savefig("current_batch_"+suffix+".png")
plt.clf()
plt.close()
画像を生成して、正解と比較するため表示を行います。
オリジナル画像、生成画像、マスク画像の順に最大5枚表示しています。

画面に画像を表示せず、ファイルに保存しています。
def extract_patches(X, patch_size):
list_X = []
list_row_idx = [(i*patch_size, (i+1)*patch_size) for i in range(X.shape[1] // patch_size)]
list_col_idx = [(i*patch_size, (i+1)*patch_size) for i in range(X.shape[2] // patch_size)]
for row_idx in list_row_idx:
for col_idx in list_col_idx:
list_X.append(X[:, row_idx[0]:row_idx[1], col_idx[0]:col_idx[1], :])
return list_X
def get_disc_batch(procImage, rawImage, generator_model, batch_counter, patch_size):
if batch_counter % 2 == 0:
# produce an output
X_disc = generator_model.predict(rawImage)
y_disc = np.zeros((X_disc.shape[0], 2), dtype=np.uint8)
y_disc[:, 0] = 1
else:
X_disc = procImage
y_disc = np.zeros((X_disc.shape[0], 2), dtype=np.uint8)
X_disc = extract_patches(X_disc, patch_size)
return X_disc, y_disc
batch_counterが偶数のときは生成した画像を返し、奇数のときは入力された画像を返します。
その際、画像をパッチに分割し、更に正解/不正解のデータ(2値)も作成して返しています。
※奇数のとき、なぜ正解/不正解データが全て0なのかがわからない...
「y_disc[:, 1] = 1」がなくてもうまくいく理由がわからない...
学習
def train():
# load data
rawImage, procImage, rawImage_val, procImage_val = load_data(datasetpath)
img_shape = rawImage.shape[-3:]
patch_num = (img_shape[0] // patch_size) * (img_shape[1] // patch_size)
disc_img_shape = (patch_size, patch_size, procImage.shape[-1])
# train
opt_dcgan = Adam(lr=1E-3, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
opt_discriminator = Adam(lr=1E-3, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
# load generator model
generator_model = load_generator(img_shape, disc_img_shape)
# load discriminator model
discriminator_model = load_DCGAN_discriminator(img_shape, disc_img_shape, patch_num)
generator_model.compile(loss='mae', optimizer=opt_discriminator)
discriminator_model.trainable = False
DCGAN_model = load_DCGAN(generator_model, discriminator_model, img_shape, patch_size)
loss = [l1_loss, 'binary_crossentropy']
loss_weights = [1E1, 1]
DCGAN_model.compile(loss=loss, loss_weights=loss_weights, optimizer=opt_dcgan)
discriminator_model.trainable = True
discriminator_model.compile(loss='binary_crossentropy', optimizer=opt_discriminator)
# start training
print('start training')
for e in range(epoch):
starttime = time.time()
perm = np.random.permutation(rawImage.shape[0])
X_procImage = procImage[perm]
X_rawImage = rawImage[perm]
X_procImageIter = [X_procImage[i:i+batch_size] for i in range(0, rawImage.shape[0], batch_size)]
X_rawImageIter = [X_rawImage[i:i+batch_size] for i in range(0, rawImage.shape[0], batch_size)]
b_it = 0
progbar = generic_utils.Progbar(len(X_procImageIter)*batch_size)
for (X_proc_batch, X_raw_batch) in zip(X_procImageIter, X_rawImageIter):
b_it += 1
X_disc, y_disc = get_disc_batch(X_proc_batch, X_raw_batch, generator_model, b_it, patch_size)
raw_disc, _ = get_disc_batch(X_raw_batch, X_raw_batch, generator_model, 1, patch_size)
x_disc = X_disc + raw_disc
# update the discriminator
disc_loss = discriminator_model.train_on_batch(x_disc, y_disc)
# create a batch to feed the generator model
idx = np.random.choice(procImage.shape[0], batch_size)
X_gen_target, X_gen = procImage[idx], rawImage[idx]
y_gen = np.zeros((X_gen.shape[0], 2), dtype=np.uint8)
y_gen[:, 1] = 1
# Freeze the discriminator
discriminator_model.trainable = False
gen_loss = DCGAN_model.train_on_batch(X_gen, [X_gen_target, y_gen])
# Unfreeze the discriminator
discriminator_model.trainable = True
progbar.add(batch_size, values=[
("D logloss", disc_loss),
("G tot", gen_loss[0]),
("G L1", gen_loss[1]),
("G logloss", gen_loss[2])
])
# save images for visualization
if b_it % (procImage.shape[0]//batch_size//2) == 0:
plot_generated_batch(X_proc_batch, X_raw_batch, generator_model, batch_size, "training")
idx = np.random.choice(procImage_val.shape[0], batch_size)
X_gen_target, X_gen = procImage_val[idx], rawImage_val[idx]
plot_generated_batch(X_gen_target, X_gen, generator_model, batch_size, "validation")
print("")
print('Epoch %s/%s, Time: %s' % (e + 1, epoch, time.time() - starttime))
学習処理の本体です。
まず学習データを読み込んでいます。
次にGenerator、Descriminator、DCGANの各モデルをロードし、それぞれ目的関数を設定してコンパイルして使えるようにします。
- Generator:平均絶対誤差
- Descriminator:クロスエントロピー(2分類)
- DCGAN:L1正則化を行ったクロスエントロピー(2分類)
このL1正則化を行うところがpix2pixのもう一つのポイントのようです。
ここでぼやかすことで低周波成分の特徴を捉えられるようになるようです。
学習は、まずエポックで回します。
その中でミニバッチ用に学習データを作成(順番は毎回ランダム)し、今度はミニバッチ単位で実行します。
更にその中でパッチに分割した画像を作成し、オリジナルの画像と本物のマスク画像、または、偽物のマスク画像(Generatorで生成)の組み合わせでDescriminatorを学習させます。
※ここでDiscriminatorだけ賢くなるように鍛えます
最後に、オリジナルの画像と偽物のマスク画像(Generatorで生成)の組み合わせを使って、Descriminatorを更新しないようにしながらDCGANを学習させます。
※ここでGeneratorだけ賢くなるように鍛えます
学習後、テストデータを使って定期的に画像を生成して保存します。
実行
train()
学習処理を呼び出しているだけです。
まとめ
個々の処理はそれほど難しくないのですが、組み合わさるとよくわからなくなるところが悩ましいです。
また、「Discriminator」の処理は、よくわからない書き方で、まだちょっと理解しきれていません。
更に理解できたところは、随時更新していきたいと思います。