
論文紹介・画像引用
https://arxiv.org/abs/1812.04948
https://users.aalto.fi/~laines9/publications/laine2018iclr_paper.pdf
関連記事
StyleGANを実際にGoogle Colaboratoryで使ってみた
StyleGAN
・各convolution層後にstyleの調整を行う
・細部の特徴(髪質やそばかす)はノイズによって生成される
・潜在変数$z$を中間潜在変数$w$にマッピングする
・これまでのGANのようにGeneratorの入力層に潜在変数$z$を入れることはしない
Style-based generator
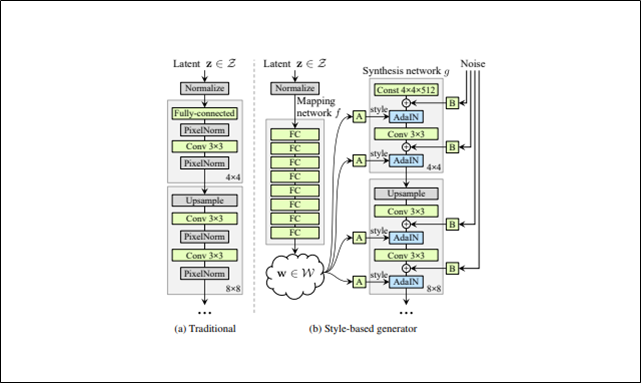
A:$w$をstyle($y_s,y_b$)に変えるためのアフィン変換
$y_s,y_b$はチャンネルごとに値をもつ
B:ノイズは1チャンネル画像から成る
convの出力に足し合わせる前に、ノイズをチャンネルごとにスケーリングすることを意味する
構成
Style-based generatorではこれまでのような入力層は使わず、全結合層を連ねたMapping network fから始まる
Mapping network fは8層で構成されSynthesis network gは18層で構成されている
流れ(上図の矢印を追う)
Mapping network fにおいて、入力である潜在変数zを潜在空間Wにマッピングする
潜在変数wはアフィン変換されることでスタイルyになる
スタイルyは各convolution層後でのAdaIn処理で使われ、Generatorをコントロールする
$$AdaIN(x_{i},y)=y_{s,i}\frac{x_i-\mu{(x_i)}}{\sigma{}(x_i)}+y_{b,i}$$
ガウシアンノイズをAdaInと各convolution層の間に加える
最終層の出力は1×1のconvolution層を使ってRGBに変換する
解像度は4×4で始まり、最終的に1024×1024
Style-based generatorの合計パラメーター数は26.2M
従来のGeneratorの合計パラメーター数は23.1M
これまでの改良の流れ
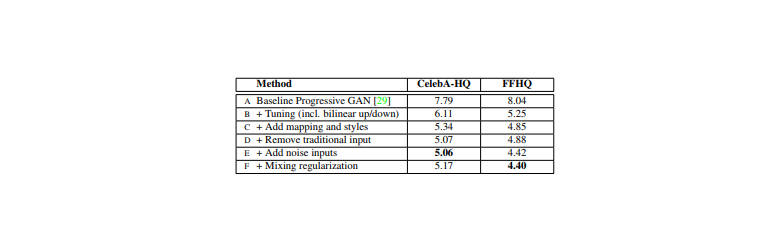
様々な改良をすることで画像のクオリティを上げてきた
評価指標はFID
FIDはGANの生成分布と真のデータ分布の距離を表す指標
数値は低いほど良いことを意味する
(A)
ベースラインとして設定したのはProgressive GAN
ネットワークとハイパーパラメーターの変更はしておらず、提案されたままを使った
(B)
ベースラインの改良として、bilinear up/downsamplingとハイパーパラメーターチューニングをした
(C)
更にベースラインの改良として、マッピングネットワークとAdaIN処理を加えた
この時点で、従来通り最初のconvolution層に潜在変数を与えるネットワークでは改善の余地がないという見解に至った
(D)
これまでの入力層を取り除き4×4×512のconstant tensorで画像生成を始めるというシンプルなアーキテクチャにした
synthesis network(Generator)は
AdaINをコントロールするスタイルのみの入力で素晴らしい生成ができることがわかった
(E)
ノイズを入れることで更に改善
(F)
mixing regularizationを導入により
隣接したスタイルの相互関係をなくし、より洗練された画像を生成することができる
Style mixing
mixing regularizationを導入する
訓練時、画像の指定範囲分(%)の生成を
1つのランダム潜在変数ではなく2つのランダム潜在変数を使ってすること
テスト時は下記結果表が示すように3つ以上でも実行されている
Synthesis networkのランダムに選ばれたところで潜在変数を他のものに切り替える(これをstyle mixingと呼ぶ)
具体的には、Mapping networkではz1とz2という2つの潜在変数を実行する
Synthesis networkではw1を適用して、その後ランダムに選ばれたところからw2を適用する
この正則化手法により、隣り合ったスタイルは相互に関連しているということをネットワークが仮定せずに生成することができる
テスト結果
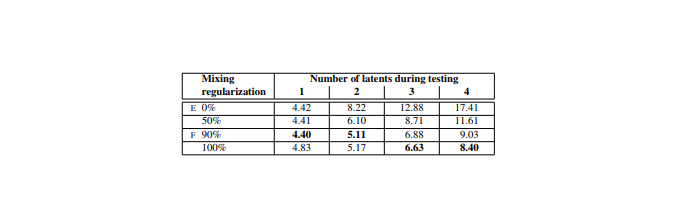
潜在変数の数(Number of latents during testing)と潜在変数を混ぜて生成する比率(Mixing regularization)を変えて結果を表にして示している
評価指標はFID
FIDはGANの生成分布と真のデータ分布の距離を表す指標
数値は低い方が良い
結果表のE,Fは最初に見た表のE,Fと対応している
Mixing regularizationの比率を大きくすることで結果が良くなっているのがわかる
2つの潜在変数を混ぜて生成された画像

1つの潜在変数で生成されたスタイル(Destination)に、同じく1つの潜在変数から生成されたスタイル(Source)を合わせると画像はどのように変化していくのかを可視化している
・解像度が粗い段階で合わせた場合(4×4 ~ 8×8)
顔の向き・髪型・顔の形・眼鏡のような大まかな特徴はsourceの要素が画像で表現されている一方で、目・髪・明暗のような色や顔の特徴はdestinationの要素が表現されている
・解像度(16×16 ~ 32×32)の場合
顔の特徴・髪型・目の特徴がsourceの要素で
顔の向きや顔の形や眼鏡がdestinationの要素で構成されている
・高解像度(64×64 ~ 1024×1024)の場合
配色や細部のデザインはsource由来になっている
ノイズの効果
・確率的特徴
正しい分布に従って生成されていれば、ランダムに生成しても画像の見た目に大きな影響を与えない特徴
例)髪質や髪の流れ、ヒゲ、そばかす、肌質
従来のgeneratorが確率的特徴を生成する場合、
入力層への入力のみになるため、ネットワークは必要となったら以前のアクティベーションから
空間的に変化する疑似乱数を生成しなくてはならない
しかしこの方法はネットワーク容量を消費し、周期性がない本当にランダムな乱数を生成することは困難である
本研究のアーキテクチャでは各convolution層の後に、ピクセルごとのノイズを加えることでこれらの問題を解決する
例1

上図はベースとなる生成画像は同じでノイズだけを変えた場合の結果である
ノイズは確率的特徴(毛の流れ)だけを変化させて、その他の高レベルな特徴(顔の特徴や向きなど)はそのままである
上図右の白黒の画像はどこがノイズの影響を受けているかを表している
白い部分がノイズの影響を受けている部分
ほとんどが髪の毛、輪郭、背景だが、目の反射も白くなっている
例2

この図もノイズがどのように生成画像を変化させるかについてである
男性の生成画像も同じように(a)(b)(c)(d)で分割して見てほしい
(a)すべての層でノイズを加えた場合
(b)ノイズを全く加えない場合
(c)ノイズを解像度がきれいな層(64×64 ~ 1024×1024)でのみノイズを加える場合
(d)ノイズを解像度が粗い層(4×4 ~ 32×32)でのみノイズを加える場合
(a)と(b)を比較するとわかるが、
ノイズを加えないことで特徴のない絵画っぽい(リアルではない)画像が生成される
(d)ノイズを解像度が粗い層(4×4 ~ 32×32)でのみノイズを加える場合、
髪の毛のカールが大きくなっていたり、背景の特徴が大きく表現されている
(c)ノイズを解像度がきれいな層(64×64 ~ 1024×1024)でのみノイズを加える場合、
髪の毛のカール、背景、肌質が細かくきれいに描かれていている
スタイルとノイズのまとめ
スタイルを変化させることは全体的な影響(姿勢、向き、顔の特徴を変える)を与えるのに対して、
ノイズはそこまで重要ではない部分(髪の毛の流れやヒゲ)に影響を与える
スタイルが画像全体に影響を与えるのはチャンネルごとにスケール変換、バイアス変換されるからである(AdaIn処理)
そのため、画像全体への影響(姿勢、明暗、背景)は一貫してコントロールされる
一方ノイズは独立的にピクセルごとに加えられ、確率的な変化をコントロールするには理想的である
もし生成画像の姿勢を変えたいときにノイズを使ってしまったら、
矛盾した選択であるためDiscriminatorに見破られてしまう
ネットワークは明確な指示がなくても、適切にスタイルとノイズを使えるように学習する
潜在空間Wの必要性
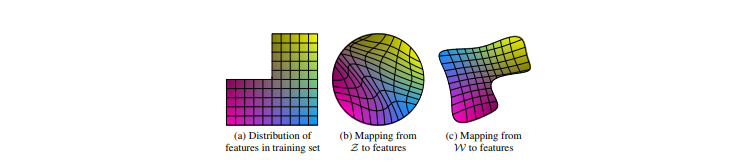
上図は2つの変動要因(男性らしさと髪の長さ)だけを考えた例
(a)訓練データの特徴分布
長い髪の男性など一部の組み合わせが存在しない訓練データ
(b)Zから特徴表現へのマッピング(従来のやり方)
訓練データになかった組み合わせ(長い髪の男性)がサンプリングされないようにするため
Zから画像特徴へのマッピングは曲線になる
(c)Wから特徴表現へのマッピング(本研究)
ZからWへのマッピングは学習されたマッピングであるため、このゆがみを元に戻すことができる
仮定
特徴が絡み合っている表現に基づいてリアルな画像を生成するよりも、
それぞれの特徴がしっかり分解されている表現に基づいてリアルな画像を生成する方が容易であるはず
例)人の顔を生成したいとき
・特徴が絡み合っている
→この軸を調整すると、目が大きくなって髪が長くなって輪郭が丸くなるみたいになると
各軸が複雑に影響し合って生成しづらい
・特徴がしっかり分解されている
→この軸は目の大きさ、この軸は髪の長さ、この軸は輪郭みたいに特徴が独立していると
生成がしやすい
目標
線形部分空間(それぞれの線形部分空間が1つの変動要因をコントロールする)を用意する
変動要因が事前にわかっていない状況の中で、学習によって可能な限り特徴が分解されたWができることが理想
問題
ただし、従来のGANのようなアーキテクチャでは
Z内の各要因の組み合わせのサンプリング確率は、学習データ内の対応する密度と一致する必要がある
そのため、各要因がデータセットの分布と入力潜在分布から完全に分解することができない
対策
本研究のGeneratorが優れている点は
中間潜在空間Wは任意の固定分布に従ってサンプリングする必要がないこと
Wのサンプリング密度は学習された区分的連続写像f(z)(線形変換である全結合層を8つ重ねて計算する)によってできたものを使う
このマッピングによって、変動要因はより線形になりゆがみのない潜在空間Wができる
指標
「特徴が分解されている」ということを定量化するための指標が最近提案されたのだが、
残念なことにその指標を使うには入力画像を潜在変数にマッピングするエンコーダーがなくてはならない
本研究ではそういったエンコーダーは使っていないため適した指標とは言えない
そのためにエンコーダーをわざわざ追加することもできるが、根本的解決にはならないのでやらない
その代りに新しい定量化手法を2つ提案する
その指標の場合はエンコーダーを必要とせず、変動要因を事前に知らなくていいため
どんな画像データセットやGeneratorでも問題ない
新指標1:Perceptual path length

潜在空間のinterpolation(上図)をすると両端の画像(①や⑨)にはない特徴が中間の画像(④、⑤、⑥)に現れるという非線形な変化が起こることがある
これは潜在空間が絡み合っていて変動要因が適切に分離されていないことを示す
潜在空間でinterpolationをしたときに、どれだけ急激に画像が変化するかを測ることでこの効果を定量化することができる
直感的には、曲りの大きい曲線の潜在空間よりも曲りの少ない曲線の潜在空間の方が画像がなめらかに変化していくと考えられる
方法
2枚の画像の距離を測定する
この計算はVGG16のembeddingで計算されるため、人間が2枚の画像を見たときに感じる画像の類似性と一致するようになっている
定義上は潜在空間のinterpolation pathを線形セグメントに無限に細分化した状況で計測することになっているが、
実際にはepsilon(10のマイナス4乗)を用いて近似計算する
潜在空間Zの取り得るすべての両端(①や⑨)の平均距離(perceptual path length)の定義は以下のようになる
$G$・・・Generator
$D$・・・画像間の距離を計測
$slerp$・・・標準化された入力潜在空間のinterpolationに最も適した球状interpolation
$z_1,z_2$~$P(z),;t$~$U(0,1)$
$$l_z=E[\frac{1}{\epsilon^2}d(G(slerp(z_1,z_2;t)),G(slerp(z_1,z_2;t+\epsilon)))]$$
潜在空間Wの場合は以下のようになる
Wのベクトルは標準化されていないため線形interpolation($lerp$)
$$l_w=E[\frac{1}{\epsilon^2}d(g(lerp(f(z_1),f(z_2);t)),g(lerp(f(z_1),f(z_2);t+\epsilon)))]$$
結果1
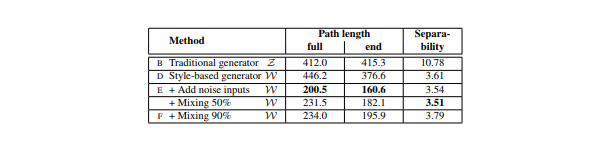
・ノイズありのStyle-based generator(本研究のgenerator)が最もpath lengthが短くなった
これはWがZよりも知覚的に線形であることを意味している
・Style mixingができるようなネットワークにすると中間潜在空間Wを多少ゆがませてしまうようだ
・Style mixingによって、Wが複数のスケールにわたる変動要因をエンコードすることを困難にしていると仮定できる
結果2
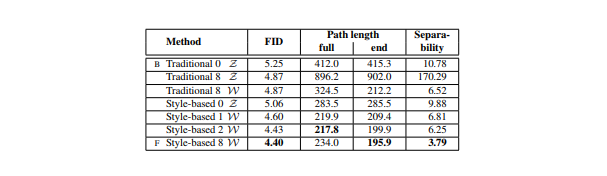
Path lengthがマッピングネットワークからどのように影響を受けているかを示している
従来のGeneratorでも本研究のstyle-based generatorでもマッピングネットワークを持つことは有益である
深さを増すこともほとんどのPath lengthとFIDで良い結果につながっている
従来のGeneratorのlwは向上しているのに対し、lzは悪化している点を見ると
これまでの様々なGANモデルの入力潜在空間が無作為に絡み合っていることがわかる
新指標2:Linear separability
潜在空間が十分に分解されていれば、個々の変動要因に対応した方向ベクトルを見つけることができるはず
この効果を定量化する指標がLinear separability
どれだけ上手に潜在空間の点を線形超平面で2つに分けられるかを計測する
分けられた2つはそれぞれ、画像のバイナリ属性に対応する(例:片方は男性、もう片方は女性)
方法
①生成画像にラベルを付けるために、画像の二値分類(男性と女性の顔を見分ける)ができる補助ネットワーク(Discriminatorと同じアーキテクチャ)を訓練する
②訓練データはCelebA-Hデータセット(元のCelebAデータセットの中の40属性を保持するデータセット)
属性の分離度を測るために20万枚の画像を生成し補助ネットワークを使って分類する
分類器のスコアが高い10万枚だけをラベル付きの潜在空間ベクトルとする
③各属性について、潜在空間点(従来の場合はz, style-basedではw)に基づいたラベルを予測するために線形SVMで学習する
④超平面がどれほど正確に点を分類できたかを条件付きエントロピーH(Y|X)で計算する
X・・・SVMで予測したクラス
Y・・・補助ネットワークが決めたクラス
条件付きエントロピーは正しいクラス分類をするために、どれほど追加情報が必要かを示している
もし変動要因が矛盾した潜在空間の方向を持っていたら、サンプル点を超平面でわけるのは一層難しいため
条件付きエントロピーは高い数値になる
低い数値になるということは簡単に分けられたということを示す
すなわち属性が対応する要因と潜在空間の方向が一致したことを意味する
最終的な分離スコアは下記のように求める
$i$は40属性
$$\exp(\sum_{i}H(Y_i|X_i))$$
潜在空間Wのまとめ
・結果1と結果2からWはZよりも分離しやすい(表現が絡み合っていない)ことがわかる
・マッピングネットワークの深さを増すことは画質とWの分離性を向上させる
これは合成ネットワーク(Synthesis network)がもつれを解消した入力表現を好むという仮説と一致している
・従来のジェネレータの前にマッピングネットワークを追加するとZの分離性が大幅に失われるが、中間潜在空間Wの状況は改善されFIDの結果も良くなる
これは訓練データの分布に従わなくてよい中間潜在空間を導入すると、従来のジェネレータアーキテクチャでもパフォーマンスが向上することを示している
全体まとめ
・従来のGANアーキテクチャは様々な点でStyleGANよりも劣っていることが明らかになった
・高レベルの属性(スタイル)と確率的効果(ノイズ)の分離、中間潜在空間の線形性に対する調査が
StyleGANの理解を深める上で有益であると確信している
・Path length指標とLinear separability指標が訓練時の正則化として容易に使えることも示した
・訓練時に直接、中間潜在空間を形成する方法が今後の研究のキーになっていくと考えている
FFHQデータセット

FlickrFaces-HQ (FFHQ)という顔画像のデータセットを提供する
・70000枚
・解像度:1024×1024
・データセットは年齢・民族・視点・明暗・画像の背景に関して多様な種類がある
・眼鏡・サングラス・帽子などを身に着けた画像も十分に用意されている