実際に生成してみた画像

本記事について
・Google Colaboratoryで学習済みのStyleGANを使って、冒頭のような顔画像・スタイルミックスした画像・ベッドルーム・車・猫の画像を生成してみた
・StyleGANのGitHubの説明通りに行うことで学習済みモデルを使える
・本記事で記載するコードはその説明通りのもののため、コピペすれば同じように画像生成ができると思う
・本記事にある画像はすべて実際に学習済みのStyleGANを使って生成した画像である
画像生成
①準備
# git clone でStyleGANのコードを使えるようにする
!git clone https://github.com/NVlabs/stylegan.git
# ディレクトリ移動
cd stylegan
②generatorをロードする
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
# Initialize TensorFlow.
tflib.init_tf()
# Load pre-trained network.
url = 'https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ' # karras2019stylegan-ffhq-1024x1024.pkl
with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f:
_G, _D, Gs = pickle.load(f)
# _G = Instantaneous snapshot of the generator. Mainly useful for resuming a previous training run.
# _D = Instantaneous snapshot of the discriminator. Mainly useful for resuming a previous training run.
# Gs = Long-term average of the generator. Yields higher-quality results than the instantaneous snapshot.
_G, _D, Gsの3つをロードできるが、使うのはGsのみ
_G, _Dに関しては無視で大丈夫
③潜在ベクトルを選ぶ
# Pick latent vector.
rnd = np.random.RandomState(200)
latents = rnd.randn(1, Gs.input_shape[1])
潜在ベクトルを選ぶ上で設定するRandomStateの値(上記のコードでは200)を変えることで、異なる画像を生成することができる
④画像生成
# Generate image.
fmt = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
images = Gs.run(latents, None, truncation_psi=0.7, randomize_noise=True, output_transform=fmt)
truncation_psiの値(上記のコードでは0.7)を変えると、画像の雰囲気を少し変えることができる
0にすると本物画像を平均した顔、-1~1の間で調整するのが良い(後述)
冒頭の顔画像はすべてtruncation_psi=0.7で生成されたもの
⑤生成画像を保存する
# Save image.
os.makedirs(config.result_dir, exist_ok=True)
png_filename = os.path.join(config.result_dir, 'example200.png')
PIL.Image.fromarray(images[0], 'RGB').save(png_filename)
'example200'のところは自由に画像ファイルの名前を設定する
その他はそのまま実行する
⑥Google Colaboratory上で生成画像を表示してみる
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
# 画像内に線を表示しない
fig,ax = plt.subplots()
ax.tick_params(labelbottom="off",bottom="off")
ax.tick_params(labelleft="off",left="off")
ax.set_xticklabels([])
ax.axis('off')
# 画像の読み込み
im = Image.open("results/example200.png")
# 画像をarrayに変換
im_list = np.asarray(im)
# 貼り付け
plt.imshow(im_list)
# 表示
plt.show()
RandamState(200)で画像を生成した場合(上記のコードをそのまま実行した場合)、下の画像が生成されるはず
"results/自分が設定したファイル名"(この例では"results/example200.png")に先ほど生成した画像がある

⑦画像をダウンロードする
from google.colab import files
files.download("results/example200.png")
・画像をダウンロードするときも画像を見るときと同じように("results/自分が設定したファイル名")とする
・生成画像をダウンロードしようとしてエラーメッセージ「Connection reset by peer」が出たときは、
Google Colaboratoryのランタイムから「すべてのランタイムをリセット」をしてからもう一度実行するとできると思う
・ダウンロードした生成画像の容量は大きいため、用途によってはリサイズする必要があるかもしれない
下記のようなサイトで画像縮小を行うことができる
https://resizer.myct.jp/
ハイパーパラメータを変えてみる
以下2つのハイパーパラメータを変えることで様々な種類・見た目の画像が生成できる
潜在変数
前述のようにRandomStateの値を変えることで様々な画像を生成できる
RandomState(841)の場合

RandomState(231)の場合

truncation_psi
truncation_psiを変えると、画像の雰囲気を変えることができる
truncation trick(どのあたりの潜在変数をとるかを選ぶ)は低解像度(4×4~32×32)のスタイルのみに適用されるため、人の特徴を変化させるはたらきがある
実際に生成してみた以下2つの例では、性別・髪の色・髪型・眼鏡の有無などが変わっている
例1
下のGIFはtruncatoin_psiを実際に-1→-0.7→-0.5→-0.2→0→0.2→0.5→0.7→1と変えて生成した画像
RandomState(29)


例2
RandomState(36)


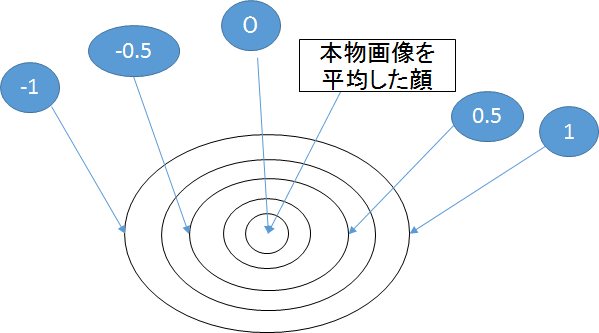
イメージ
truncation_psi=0のとき、生成される画像は本物画像(学習に使った画像のデータセット)を平均した顔
=本物画像通りの画像が生成されるため、画像の質は高いがオリジナリティはない
潜在変数を変えてもtruncation_psi=0にすると同じ女性の画像(背景は異なる)が生成される
truncation_psiを少し変えると(-1~1)本物画像から少し離れることになるため、本物画像の要素を残しながらオリジナリティが加わった画像ができる
ただ、3などに設定すると本物画像から離れすぎて変な画像になってしまう
スタイルミックス
実際に生成してみた画像
coarse(4×4~8×8):3枚, middle(16×16~32×32):2枚, fine(64×64~1024×1024):1枚(下記詳細)
黄線と黒線は区切りを明確にするために画像生成後に付け足したもの

スタイルミックス画像の見方
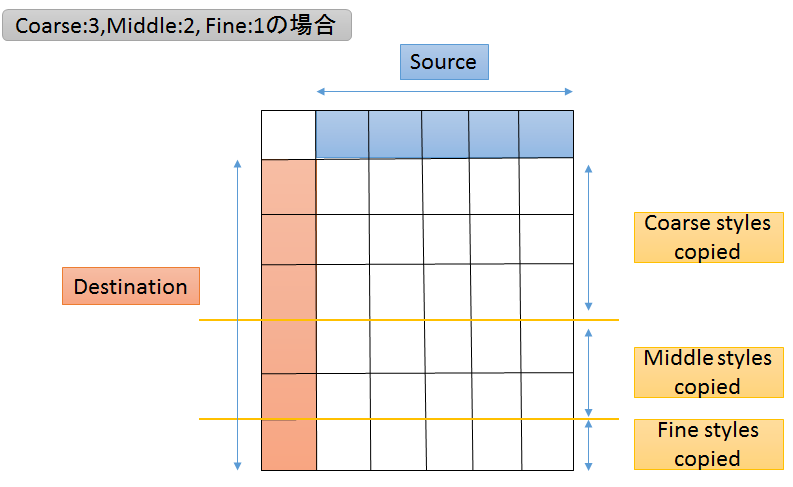
Destinationの画像(1列目)にSourceの画像(1行目)のスタイル(CoarseかMiddleかFine)をコピーして合わせる
・Coarse styles : 低解像度(例:4×4~8×8)のスタイル
イメージ)ぼやけた画像見たときに捉えられる特徴(顔の向き・輪郭・眼鏡)
・Middle styles:中間解像度(例:16×16~32×32)のスタイル
イメージ)顔にズームインしたときに捉えられる特徴(顔のパーツの特徴)
・Fine styles : 高解像度(例:64×64~1024×1024)のスタイル
イメージ)ピクセルレベルで画像を見たときに捉えられる特徴(背景の色や髪の毛の色)
解像度の範囲はrange(,)の値を変えることで変更できる(後述)
上図ではCoarse:3, Middle:2, Fine:1となっているが、これもハイパーパラメーターであるstyle_ranges(後述)を変えることで変更できる
①Destination + Source(Coarse styles copied)の画像
低解像度のスタイルだけはSourceのスタイルを使ったDestination画像
例)背景・髪の色に関してはDestinationのスタイルをそのまま使い、顔の向き・輪郭・髪型・眼鏡はSourceのスタイルを使う
②Destination + Source(Middle styles copied)の画像
中間解像度のスタイルだけはSourceのスタイルを使ったDestination画像
例)顔の向き・輪郭・髪型に関してはDestinationのスタイルをそのまま使い、髪質・髪の色・顔のパーツはSourceのスタイルを使う
③Destination + Source(Fine styles copied)の画像
高解像度のスタイルだけはSourceのスタイルを使ったDestination画像
例)顔の向き・顔のパーツ・髪型に関してはDestinationのスタイルをそのまま使い、背景の色や髪の色などの細かい部分はSourceのスタイルを使う
スタイルミックスのコード
このコードは何も変更せずにコピペして実行すれば大丈夫
def draw_style_mixing_figure(png, Gs, w, h, src_seeds, dst_seeds, style_ranges):
print(png)
src_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in src_seeds)
dst_latents = np.stack(np.random.RandomState(seed).randn(Gs.input_shape[1]) for seed in dst_seeds)
src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component]
dst_dlatents = Gs.components.mapping.run(dst_latents, None) # [seed, layer, component]
src_images = Gs.components.synthesis.run(src_dlatents, randomize_noise=False, **synthesis_kwargs)
dst_images = Gs.components.synthesis.run(dst_dlatents, randomize_noise=False, **synthesis_kwargs)
canvas = PIL.Image.new('RGB', (w * (len(src_seeds) + 1), h * (len(dst_seeds) + 1)), 'white')
for col, src_image in enumerate(list(src_images)):
canvas.paste(PIL.Image.fromarray(src_image, 'RGB'), ((col + 1) * w, 0))
for row, dst_image in enumerate(list(dst_images)):
canvas.paste(PIL.Image.fromarray(dst_image, 'RGB'), (0, (row + 1) * h))
row_dlatents = np.stack([dst_dlatents[row]] * len(src_seeds))
row_dlatents[:, style_ranges[row]] = src_dlatents[:, style_ranges[row]]
row_images = Gs.components.synthesis.run(row_dlatents, randomize_noise=False, **synthesis_kwargs)
for col, image in enumerate(list(row_images)):
canvas.paste(PIL.Image.fromarray(image, 'RGB'), ((col + 1) * w, (row + 1) * h))
canvas.save(png)
def load_Gs(url):
if url not in _Gs_cache:
with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f:
_G, _D, Gs = pickle.load(f)
_Gs_cache[url] = Gs
return _Gs_cache[url]
url_ffhq = 'https://drive.google.com/uc?id=1MEGjdvVpUsu1jB4zrXZN7Y4kBBOzizDQ' # karras2019stylegan-ffhq-1024x1024.pkl
_Gs_cache = dict()
synthesis_kwargs = dict(output_transform=dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True), minibatch_size=8)
上記のコードを実行したら続いて次の章のコード(draw_style_mixing_........)を実行する
(draw_style_mixing_........)のコードは各自で自由に変更できるところがある
自由に変更できるところ
draw_style_mixing_figure(os.path.join(config.result_dir, 'figure03-style-mixing15.png'), load_Gs(url_ffhq),
w=1024, h=1024, src_seeds=[3,48,6,63,13,68], dst_seeds=[36,18,26,29,33,84],
style_ranges=[range(0,4)]*3+[range(4,8)]*2+[range(8,18)]*1)
src_seeds
Source(1行目の画像)を何にするか、数字はRandomStateを意味する
dst_seeds
Destination(1列目の画像)を何にするか
style_ranges
range( , )について
Gsのモデルアーキテクチャの一部は以下のようになっている
1層目のconv: 解像度4×4、2層目のconv: 解像度4×4、3層目のconv: 解像度8×8、4層目のconv: 解像度8×8
5層目のconv: 解像度16×16、6層目のconv: 解像度16×16、7層目のconv: 解像度32×32、
8層目のconv: 解像度32×32、9層目のconv: 解像度64×64、10層目のconv: 解像度64×64、
11層目のconv: 解像度128×128、12層目のconv: 解像度128×128、13層目のconv: 解像度256×256、
14層目のconv: 解像度256×256、 15層目のconv: 解像度512×512、16層目のconv: 解像度512×512
17層目のconv: 解像度1024×1024、18層目のconv: 解像度1024×1024
・1層目から18層目を3つのグループ(CoarseとMiddleとFine)に分けたい
・Coarse, Middle, Fineのそれぞれの範囲(何層目から何層目の解像度にするのか)をrange( , )を使って自由に指定することができる
以下2つの例でどういうことかを確認してみる
例1
Coarse:4×4~8×8, Middle:16×16~32×32, Fine:64×64~1024×1024と設定し、
6枚の生成画像の内、3枚はSourceの低解像度(Coarse)スタイル、2枚はSourceの中間解像度(Middle)スタイル、1枚はSourceの高解像度(Fine)スタイルを使いたいときは以下のようなコードになる
[range(0,4)]*3+[range(4,8)]*2+[range(8,18)]*1
$range(0,4)$=1層目から4層目(コードは0スタートのため1つずれている)=4×4~8×8の解像度
$range(4,8)$=5層目から8層目=16×16~32×32の解像度
$range(8,18)$=9層目から18層目=64×64~1024×1024の解像度
range(,)の後にある***3と*2と*1**の値を自由に変更することで、Coarse, Middle, Fineの区切りを決めることができる
本章初めに添付したスタイルミックス画像はこの設定で生成されたもの
例2
[range(0,6)]*1+[range(6,12)]*3+[range(12,18)]*2
同じように考えると例2は
Coarse:4×4~16×16, Middle:32×32~128×128, Fine:256×256~1024×1024とし、
6枚の生成画像の内、1枚はSourceの低解像度(Coarse)スタイル、3枚はSourceの中間解像度(Middle)スタイル、2枚はSourceの高解像度(Fine)スタイルを使いたいときの設定である
例2の設定で生成したスタイルミックス画像は以下のようになる

range( , )を変更することで解像度の範囲を変えられることを示したが、個人的にはデフォルト通りの
Coarse:4×4~8×8, Middle:16×16~32×32, Fine:64×64~1024×1024を推奨する
実際に各解像度の画像を見ると、4×4~8×8はかなりぼやけていて、16×16~32×32になるとぼやけてはいるがどういう顔なのか大まかにわかる、64×64~1024×1024になるとぼやけのない鮮明な画像であることが確認できる
そのためこの分け方(Coarse:4×4~8×8, Middle:16×16~32×32, Fine:64×64~1024×1024)が一番自然だと思う
画像表示とダウンロードをしたいときは上述の⑥「Google Colaboratory上で生成画像を表示してみる」と「⑦画像をダウンロードする」の章で記載したコードをそのまま使える
ただし、画像ファイルの名前を変えた場合はパス(例:"results/example200")を変更する必要がある
他のデータセットで学習されたモデルを使って画像生成してみる
・これまで添付した画像はFFHQデータセットで学習したgeneratorが生成した顔画像
・「②generatorをロードする」の章で紹介したコードの中の「url=.....」の部分だけを変えることで他の画像を生成できる
・urlを変えたら、それ以降は前述した顔画像生成と同じコードを順番に実行する
・下図はすべて実際にurlだけを変えて生成してみた画像
celebAHQデータセットで学習されたモデルを使いたい場合

RandomState(30)
import os
import pickle
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import config
# Initialize TensorFlow.
tflib.init_tf()
# Load pre-trained network.
url = 'https://drive.google.com/uc?id=1MGqJl28pN4t7SAtSrPdSRJSQJqahkzUf' # karras2019stylegan-celebahq-1024x1024.pkl
with dnnlib.util.open_url(url, cache_dir=config.cache_dir) as f:
_G, _D, Gs = pickle.load(f)
urlだけが変わって、それ以外は全く同じであることが確認できると思う
顔以外の画像も生成したい場合
ベッドルーム・車・猫の画像を生成したいときもurlを変更するだけ
ベッドルーム画像

RandomState(32)
url = 'https://drive.google.com/uc?id=1MOSKeGF0FJcivpBI7s63V9YHloUTORiF' # karras2019stylegan-bedrooms-256x256.pkl
車画像

RandomState(41)
url = 'https://drive.google.com/uc?id=1MJ6iCfNtMIRicihwRorsM3b7mmtmK9c3' # karras2019stylegan-cars-512x384.pkl
猫画像

RandomState(35)
url = 'https://drive.google.com/uc?id=1MQywl0FNt6lHu8E_EUqnRbviagS7fbiJ' # karras2019stylegan-cats-256x256.pkl
まとめ・感想
・StyleGANを1から訓練するのは大変だと思うが、学習済みのモデルを使えばGANの学習に伴う難しいことを考えずに画像を生成することができる
・実際にコードを動かしてみると、論文を読むだけでは気づくことができないことも発見できる
例えば、ハイパーパラメータがどのように生成画像に影響を与えるのかは自分で生成してみることで初めて実感できる
コード