CNTK 2.2 Python API ガイド - 深層学習フレームワーク経験者のために (関数オブジェクト, 分散, TensorBoard)
0. はじめに
◆ CNTK ( Microsoft Cognitive Toolkit ) 2.2 の少しだけ高度な Python API ガイドです。
タイトルにもありますように (他の) 深層学習フレームワークを経験されている方を対象読者の中心として想定しています。
CNTK は初めてであるけれども深層ニューラルネットワークについてある程度の知識があり、他の深層学習フレームワークの経験があるユーザのために意図されています。
そしてもちろん、入門シリーズ (CNTK 2.2 Python API 入門 (1) 基本, (2) 2 クラス分類, (3) MNIST, (4) LSTM, (5) オートエンコーダ (6) 総集編) に多少なりとも目を通された方も想定しています。入門シリーズ読者は知識の整理に利用できるでしょうし、違った角度からの説明も見出すでしょう。
◆ CNTK は Microsoft 製品グループで様々なサービス - 音声認識・機械翻訳、各種画像分類サービス、Bing 検索ランキング等々を提供するために利用されているそうです。そして実際に使ってみると優れた特徴がたくさん見つかります。しかしながら、現時点では CNTK Python プログラミングに関する情報が少ないために CNTK の利用を躊躇されているかたも多いかと思いますので、CNTk 2.2 Tutorials (200 番台、中級~) への橋渡しとなるような Python API 記事の作成を続けていきたいと考えています。
本記事では、CNTK Python API 全体を俯瞰した後、CNTK のデータモデル/プログラミングモデルを紹介します。
CNTK のネットワークは関数オブジェクトですが、この関数オブジェクトを上手く利用すれば簡潔で柔軟な実装が可能です。
そして CNTK における深層学習モデリングから配備 (デプロイ) までの全体の流れをつかむことも一つの主眼としています :
CNTK モデル定義 => データ供給 => トレーニング/評価 => 配備
また、効率的な組み込みリーダーや分散トレーニングの方法のような CNTK の多くの進んだ特徴も紹介します。
以下の図のように TensorBoard を利用することも簡単です :
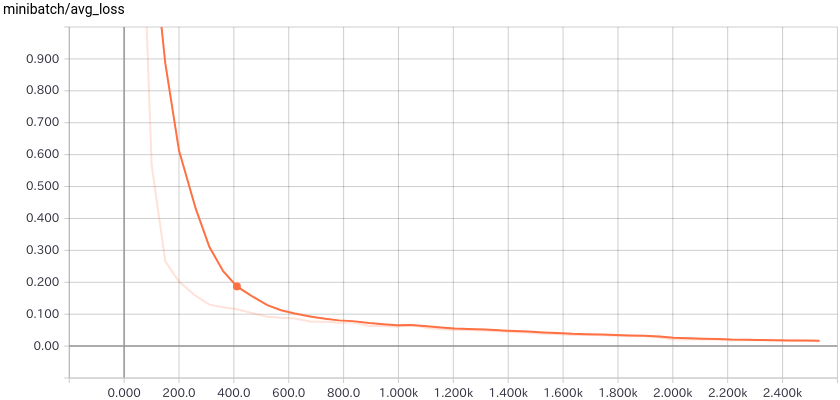
内容は :
- 動作環境と Jupyter Notebook について
- CNTK 2.2 Python API 概要
- 本記事で使用する主な CNTK Python API
- モデル構造の定義
- データの供給
- トレーニングと評価
- モデルの配備
- What's Next ?
本記事は以下の CNTK チュートリアル及びリソースを参考にしています :
1. 動作環境と Jupyter Notebook について
動作環境
動作環境の構築が必要な場合には、Cognitive Toolkit 2.2 を Azure Linux GPU 仮想マシンにインストール を参考にしてください。Azure ポータルと Ubuntu Linux にある程度慣れていれば、30 分程度で以下のような環境が構築できるかと思います :
- Azure NC 仮想マシン with NVIDIA Tesla® K80 GPU
- Ubuntu 16.04 LTS
- NVIDIA CUDA 8.0 & cuDNN 6.0
- Anaconda 3 4.1.1
- CNTK 2.2 (for GPU)
Jupyter Notebook
また、本記事でも CNTK チュートリアルでも Jupyter Notebook を多用します。
Jupyter Notebook の利用方法については「CNTK 2.2 Python API 入門 (2)」の記事中の Jupyter Notebook の活用 を参照してください。
2. CNTK 2.2 Python API 概要
2-1 コンセプト
最初に CNTK 2.2 Python API のコンセプトを知るために CNTK Library API の説明を紹介しますが
少し抽象的な表現が多いので、具体的な説明を簡単に追記しておきます :
CNTK Python API は、モデル定義と計算、学習アルゴリズム、データ・リーディングと分散訓練のための抽象モジュールから構成されます。
- 柔軟性と簡潔性 : これらの抽象モジュールはあらゆるニューラルネットワークの定義と訓練において、柔軟性と簡潔さの両者を直交性 (独立性) が高く提供するための基礎となります。
CNTK ネットワークは 関数オブジェクト で簡潔に柔軟に定義できます。これは他のフレームワークでも見られるものです。もちろん低位なグラフ API を中心に構成することも可能ですし、両者のスタイルを混在させることもできます。
- 効率的なデータ・インターフェイス : 単純ですがしかし軽量のデータ・インターフェイスはネイティブな NumPy 配列の形式のデータを計算エンジンに効率的に供給することを可能にします。
本記事でも説明します。メモリにロードできるような小さなデータセットについては、NumPy 配列 あるいは Scipy 疎行列 (CSR 形式) として供給可能です。
- 組み込みデータ・リーダー: 画像、テキスト・フォーマットと音声 HTK (Hidden markov model ToolKit, 隠れマルコフモデル・ツールキット) データフォーマットのための、CNTK 組み込みである最適化されスケーラブルなデータ・リーダーもまた Python API から利用可能です。これはユーザがデータを読むためのコードを作成することなしに既存のデータで直接トレーニングすることを容易にします。
本記事でも説明します。CNTK は特にメモリに乗らないような巨大なデータのために効率的な組み込みリーダーを持ち、これはランダム化、非同期なロード、分散リーディング等をサポートしています。
- 高度にスケーラブルな学習 : API は高度にスケーラブルなトレーニング性能を公開しています (1-Bit SGD のような並列アルゴリズム)。分散トレーニング・サンプル はトレーニング並列 API を示します。
これについても本記事で簡単に紹介します。CNTK の分散トレーニングは MPI を利用しています。そして3つ以上の方法をサポートします : 一般的なデータ並列トレーニング、1-bit SGD そして BlockMomentum です。
- 簡潔なネットワーク定義 : API は、CNTK V1 に類似した再起性 (= recurrence) を含む簡潔で高度なニューラルネットワーク定義を可能にする高位な 層ライブラリ を含みます。ツールキットは、再起ステップの静的展開を要求する代わりにネットワークにおける循環としてのシンボリック・フォームのリカレント・モデルの表現をサポートします。より一般的には、これはリカレント・ニューラルネットワークの簡潔で効率的な表現と実行という結果になります。
幾つかネットワーク定義の例をあげておきましょう。
最初は MLP の定義例です。Sequential や Dense は Keras 等でお馴染みでしょう。
Forは python の "for" に類似した層ファクトリ関数です。lambda 記法が利用できます :
MLP
num_hidden_layers = 2
hidden_layers_dim = 50
...
netout = Sequential([For(range(num_hidden_layers), lambda i: Dense(hidden_layers_dim, activation=sigmoid)),
Dense(num_output_classes)])(feature)
>次は CNN です。default_options() を with ブロックで利用すると、(活性化関数などの) 層への様々なデフォルト・オプションを指定することができます。もちろん上書き可能です :
>```python:CNN
def create_model(features):
with C.layers.default_options(init = C.layers.glorot_uniform(), activation = C.relu):
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=32,
strides=(1,1),
pad=True, name="first_conv")(features)
h = C.layers.MaxPooling(filter_shape=(2,2),
strides=(2,2), name="first_max")(h)
h = C.layers.Convolution2D(filter_shape=(5,5),
num_filters=64,
strides=(1,1),
pad=True, name="second_conv")(h)
h = C.layers.MaxPooling(filter_shape=(3,3),
strides=(3,3), name="second_max")(h)
r = C.layers.Dense(num_output_classes, activation = None, name="classify")(h)
return r
そして時系列予測のための LSTM の例です :
LSTM
H_DIMS = 15
def create_model(x):
with C.layers.default_options(initial_state = 0.1):
m = C.layers.Recurrence(C.layers.LSTM(H_DIMS))(x)
m = C.sequence.last(m)
m = C.layers.Dropout(0.2)(m)
m = C.layers.Dense(1)(m)
return m
CNTK Python API の総てのコア計算、学習、そしてデータ・リーディング API 抽象モジュールは Python と C++ の両者から非常に簡単に拡張可能で、新しい演算子、学習主体 (= learner) そしてデータ・リーダーを簡単に実装することを可能にします、これはライブラリの組み込み機能で自由に構成できます。
API は新しい [プロトコルバッファ](https://developers.google.com/protocol-buffers/) ベースのモデル・シリアライゼーションを導入します、これはセーブされたモデルの後方そして前方互換性をサポートします。
### 2-2 キーポイント
入門シリーズで紹介した CNTK 2.2 Python API の要点をまとめると次のようなものになります :
- CNTK 2.2 では Python API が公開されていて、他の深層学習フレームワークと同様に
Python プログラムを作成することで深層学習モデルが構築できます。
- CNTK はデータとしてテンソルとシークエンスを扱います。
- 層ライブラリのような、深層学習フレームワークでお馴染みのビルディング・ブロックも多数用意されています。
- コンピュータビジョンのための畳み込みネットワーク/オートエンコーダや時系列予測のための LSTM モデルも CNTK で簡単に実装できます。
- ネットワーク定義は Python 関数オブジェクトとして実装され、For ループや lambda 記法も利用できる Python ライクな記法で簡潔に定義可能です。
- Trainer クラスでカプセル化したトレーニングの実装も分かりやすく簡潔です。
- CTF フォーマットの利用で CNTK データ・リーダー (= Reader) が簡単に構成できます。
### 2-3 CNTK Python パッケージ構成
Python ライブラリとして site-packages/cntk にインストールされた CNTK ライブラリのパッケージ構成を確認します :
```bash:~/anaconda3/lib/python3.5/site-packages/cntk
$ ls -F
axis.py debugging/ __init__.py libs/ ops/ tensor.py
cntk_py.py default_options.py internal/ logging/ __pycache__/ tests/
conftest.py device.py io/ losses/ pytest.ini train/
contrib/ eval/ layers/ metrics/ random/ variables.py
core.py initializer.py learners/ misc/ sample_installer.py
ライブラリ構成は標準的な深層学習フレームワークの構成と言って良いでしょう。learners はオプティマイザと考えて良いです。
次に、サブモジュールとサブパッケージについて Python API リファレンス - CNTK パッケージ を参照して、提供される機能を確認してみましょう :
◆ CNTK サブパッケージ
| パッケージ名 | 提供される機能 |
|---|---|
| cntk.contrib | CNTK のための特別なユティリティ、例えば、他の深層学習ツールキットへの橋渡しをするユティリティ。 |
| cntk.debugging | cntk.debugging.debug, cntk.debugging.profiler |
| cntk.eval | モデル評価のためのユティリティ。 |
| cntk.io | CNTK I/O ユティリティ。 |
| cntk.layers | CNTK 層ライブラリ。 |
| cntk.learners | learner はトレーニング・プロセスの間パラメータ・セットの調整をします。パラメータの異なるセットのために異なる learner を使用できます。現在、CNTK は次の学習アルゴリズムをサポートしています : AdaDelta, AdaGrad, FSAdaGrad, Adam, MomentumSGD, Nesterov, RMSProp, SGD |
| cntk.logging | ロギングのためのユティリティ。 |
| cntk.losses | 損失関数。 |
| cntk.metrics | 評価メトリクス。 |
| cntk.misc | CNTK のための様々なユティリティ、例えば、CNTK 計算グラフのノードをフィルタリングして変換します。 |
| cntk.ops | CNTK コア演算子。これらの演算子の呼び出しは CNTK 計算グラフのノードを作成します。 |
| cntk.random | 指定された分布に関する乱数を生成する関数。 |
| cntk.train | トレーニングのためのユティリティ。 |
◆ CNTK サブモジュール
| モジュール名 | 提供される機能 |
|---|---|
| cntk.axis | データ・バインディングにおける CNTK 変数のための Axis(軸)。 |
| cntk.core | コア数値構築、NDArrayView, View クラス。 |
| cntk.default_options | CNTK 関数のデフォルト・オプション。 |
| cntk.device | CNTK 計算がその上で実行されるデバイスを指定するユティリティ。 |
| cntk.initializer | パラメータの初期化子。 |
| cntk.sample_installer | CNTK サンプルデータを取得するためのユティリティ。 |
| cntk.tensor | テンソル演算。 |
| cntk.variables | CNTK 変数、パラメータ、定数、そしてレコード。 |
3. 本記事で使用する主な CNTK Python API
4 章以後のサンプルで使用する CNTK Python API を先にリストアップしておきます :
cntk.io パッケージ
| API | 説明 |
|---|---|
CTFDeserializer |
組み込みの deserializer(*) で、CTF (CNTK Text Format) リーダーを構成します。 |
ImageDeserializer |
画像と相当するラベルを既定のフォーマットのファイルから読む画像リーダーを構成します。 |
MinibatchSource |
CNTK の Python API 用リーダーです。 |
StreamDef |
deserializer を使用するためにストリームを構成します。 |
StreamDefs |
キーワード引数からレコードを構築します。API というよりも (Python の) 辞書のような働きをします。 |
※ deserializer は外部ストレージからインメモリのシークエンスにデシリアライズ (復号) する機能を持ちます。
cntk.layers パッケージ
cntk.layers.blocks モジュール
| API | 説明 |
|---|---|
GRU |
recurrence の内側での使用のための GRU ブロックを作成するための層ファクトリ関数です。 |
LSTM |
recurrence の内側での使用のための LSTM ブロックを作成するための層ファクトリ関数です。 |
RNNStep |
recurrence の内側での使用のための plain RNN ブロックを作成するための層ファクトリ関数です。 |
cntk.layers.higher_order_layers モジュール
| API | 説明 |
|---|---|
For |
Python の for ステートメントに似たパターンを通して合成を作成する層ファクトリ関数です。 |
Sequential |
入力上に層のシーケンス (または任意の関数) を適用する合成 (= composite) を作成する層ファクトリ関数です。 |
cntk.layers.layers モジュール
| API | 説明 |
|---|---|
Convolution |
畳み込み層を作成する層ファクトリ関数です。 |
Convolution2D |
2D 畳み込み層を作成する層ファクトリ関数です。 |
Dense |
完全結合線形層のインスタンスを作成するための層ファクトリ関数です。 |
Dropout |
dropout 層を作成するための層ファクトリ関数です。 |
Embedding |
embedding (埋め込み) 層を作成するための層ファクトリ関数です。 |
MaxPooling |
マックス・プーリング層を作成するための層ファクトリ関数です。 |
cntk.layers.sequence モジュール
| API | 説明 |
|---|---|
Recurrence |
RNN, LSTM, そして GRU を含む、リカレント・モデルを実装する層ファクトリ関数です。 |
cntk.learners パッケージ
| API | 説明 |
|---|---|
learning_rate_schedule |
学習率スケジュールを作成します。 |
adam |
モデル・パラメータを学習するために Adam learner インスタンスを作成します。 |
fsadagrad |
モデル・パラメータを学習するために FSAdaGrad learner インスタンスを作成します。 |
sgd |
モデル・パラメータを学習するために SGD learner インスタンスを作成します。 |
sgd_momentum |
モデル・パラメータを学習するために Momentum SGD learner インスタンスを作成します。 |
UnitType |
schedule の値がサンプル毎上かミニバッチ毎上で指定されるかを示します。 |
cntk.loggingパッケージ
cntk.logging.progress_print モジュール
| API | 説明 |
|---|---|
ProgressPrinter |
訓練/評価の進捗として様々なスタッツを出力表示することを可能にします。 |
TensorBoardProgressWriter |
訓練/評価の間に様々なスタッツ (e.g. 損失とメトリクス) を TensorBoard イベントファイルに書くことを可能にします。生成されたファイルは進捗を可視化するために TensorBoard でオープンできます。 |
cntk.losses パッケージ
| API | 説明 |
|---|---|
binary_cross_entropy (output, target) |
output と target の間のバイナリ交差エントロピー (aka ロジスティック損失) を計算します。 |
cross_entropy_with_softmax (output_vector, target_vector) |
target_vector と output_vector の softmax 間の交差エントロピーを計算します。 |
squared_error |
二乗誤差 - この演算は2つの入力行列の要素間の二乗の差異の総和を計算します。 |
cntk.metrics パッケージ
| API | 説明 |
|---|---|
classification_error (output_vector, target_vector) |
分類エラーを計算します。 |
cntk.ops パッケージ
| API | 説明 |
|---|---|
input_variable |
ネットワークの入力を作成します : 特徴やラベルのようなデータが供給される場所で、いわゆるプレースホルダーです。 |
parameter |
パラメータ・テンソルを作成します。 |
relu |
ReLU 活性化関数です。 |
sigmoid |
sigmoid 活性化関数です。 |
softmax |
softmax 活性化関数です。 |
cntk.ops.functions モジュール
| API | 説明 |
|---|---|
Function |
総てのプリミティブなテンソル演算子の基底クラスです。 |
cntk.ops.sequence パッケージ
| API | 説明 |
|---|---|
sequence.input_variable |
ネットワークの入力を作成します: 特徴やラベルのようなデータが提供されるべき場所です。 |
sequence.last (seq) |
symbolic 入力シーケンス seq の最後の要素を返します。 |
cntk.tests.test_utils パッケージ
| API | 説明 |
|---|---|
set_device_from_pytest_env() |
Jupyter Notebook 利用時に正しいターゲット・デバイスを選択するためのヘルパー関数です。総ての Jupyter Notebook の開始時にこれを呼び出す必要があります。 |
cntk.train パッケージ
cntk.train.trainer モジュール
| API | 説明 |
|---|---|
Trainer |
モデル・パラメータをトレーニングするクラス。 |
cntk.train.training_session モジュール
| API | 説明 |
|---|---|
CheckpointConfig |
訓練セッションのためのチェックポイントを構成します。 |
CrossValidationConfig |
訓練セッションのための交差検証を構成します。 |
4. モデル構造の定義
さて本題に入ります。CNTK のモデリングから配備までの流れを順番に見ていくことにします。
まずは、CNTK のデータモデルとプログラミングモデルの紹介から始めます。
CNTK のプログラミング・モデルでは ネットワークは関数オブジェクトです。つまり、ネットワークは関数のように呼び出されることが可能で、そしてそれはトレーニング中に調整される何某かの状態、重み、パラメータもまた保持します。
本章ではそれらを実際に試して確認してみます。CNTK の Functional (関数型) API を使用してロジスティック回帰と MNIST 数字認識モデルを実装後、最後に CNTK の低位のグラフ API に言及します。
◆ 本記事で使用するコンポーネントのインポートから始めます。
※ 本章から Jupyter Notebook の利用を想定しています。ここで Jupyter Notebook の新しいノートブックを作成して使用していきましょう :
from __future__ import print_function
import cntk
import numpy as np
import scipy.sparse
import cntk.tests.test_utils
cntk.tests.test_utils.set_device_from_pytest_env() # (only needed for our build system)
cntk.cntk_py.set_fixed_random_seed(1) # fix the random seed so that LR examples are repeatable
from IPython.display import Image
import matplotlib.pyplot
%matplotlib inline
matplotlib.pyplot.rcParams['figure.figsize'] = (40,40)
※ cntk.tests.test_utils サブパッケージの set_device_from_pytest_env は Jupyter Notebook でターゲット・デバイスを正しく選択するためのユティリティ関数です。
4-1 CNTK プログラミング・モデル : 関数オブジェクト
章の冒頭でも書きましたように、CNTK ではニューラルネットワークは関数オブジェクトです。
つまり一面では、CNTK のニューラルネットワークはそれをデータに適用するために呼び出せる単なる関数です。
他方では、ニューラルネットワークはオブジェクトのメンバのようにアクセスできる、学習可能なパラメータを含みます。
複雑なネットワークは、(例えば層を表わすような) 単純化されたプリミティブの階層構造として構成されます。
※ この関数オブジェクトのアプローチは他の幾つかの深層学習フレームワークでも見られるものです。
次のコードブロックは完全結合層 (CNTK では Dense と呼称されます) を例として、擬似コードによる関数オブジェクトのアプローチを示しています :
# CNTK Dense 層の *概念的な* NumPy 実装 (逆伝播がないなど、単純化されています)
def Dense(out_dim, activation):
# 学習可能なパラメータを作成します。
b = np.zeros(out_dim) # b は shape (5,) の [ 0. 0. 0. 0. 0.]。
W = np.ndarray((0,out_dim)) # 入力次元は未知。W は shape (0, 5) の []。
# 関数自身を定義します
def dense(x):
if len(W) == 0: # 最初の呼び出し: W を reshape して初期化します。
W.resize((x.shape[-1], W.shape[-1]), refcheck=False)
W[:] = np.random.randn(*W.shape) * 0.05
return activation(x.dot(W) + b)
# 関数オブジェクトとして返します: 呼び出し可能 & メンバーとしてパラメータを保持します。
dense.W = W
dense.b = b
return dense
d = Dense(5, np.tanh) # 関数オブジェクトを作成します。
y = d(np.array([1, 2])) # それを関数のように適用します。
W = d.W # オブジェクトのようにメンバーにアクセスします。
print('W =', d.W)
print('y =', y)
W = [[-0.07926407 -0.06228412 0.02053397 -0.04564868 0.08109359]
[-0.02324916 0.03503332 0.07380208 0.02291377 -0.117858 ]]
y = [-0.12510353 0.00778237 0.16657139 0.00017886 -0.15340183]
分かりにくいポイントだけ簡単に説明しておきましょう :
-
d = Dense(5, np.tanh)のステップ直後、d.Wは shape (0, 5) の []、d.bは shape (5,) の [ 0. 0. 0. 0. 0.] です。 -
d(np.array([1, 2]))が呼び出されると、Wが reshape されてnp.random.randnを使用して初期化されます。 - そして
activation(x.dot(W) + b)が計算されて返されます。ここで x は [1 2] で、activationはnp.tanhです。
繰り返しになりますが、上のコードブロックは Dense のただの擬似コードに過ぎず、実際には CNTK 関数オブジェクトは NumPy 配列をバックエンドとはしていません。(他の深層学習ツールキットと同様に) それらは内部的には C++ のグラフ構造として表現されていて、これが計算をエンコードします。
しかし擬似コードとしては十分で、実際に以下の行 :
d = Dense(5, np.tanh)
は単にグラフを構築するだけで、その一方で以下の行 :
y = d(np.array([1, 2]))
はグラフ実行エンジンにデータを供給しています。
◆ CNTK のグラフ構造は Python クラス cntk.ops.functions.Function でラップされています。これは非常に重要なポイントです。
この Function は必要なインターフェイスを公開していますので、他の Python 関数はそれらを呼び出して (W と b のような) そのメンバーにアクセスすることができます。
関数オブジェクトは、異なる演算を表すために使用される CNTK の単一の抽象です。演算は規則 (= convention) によってのみ識別されます :
- 学習可能なパラメータを持たない 基本演算 (e.g.
+,*,sigmoid()...) -
層 (
Dense(),Embedding(),Convolution()...)。層は一つの入力を一つの出力にマップしてそれらにアタッチされた学習可能なパラメータを持つでしょう。 -
recurrent ステップ関数 (
LSTM(),GRU(),RNNStep())。ステップ関数は以前のステートと新しい入力を新しいステートにマップします。 -
損失とメトリクス関数 (
cross_entropy_with_softmax(),binary_cross_entropy(),squared_error(),classification_error()...)。CNTK では、損失とメトリクスは特別なものではなく単なる関数です。唯一の違いは CNTK 関数が1つまたはそれ以上の出力を持てる一方で、損失とメトリクスは単一の出力を持たなければならないことです。損失はスカラー値を出力しなくても良いことに注意してください : もし損失の出力がスカラーでない場合には、CNTK は損失を出力の総計として自動的に定義します。この挙動はユーザにより明示的に reduction 演算を遂行することで上書きできます。 - モデル。 モデルはユーザにより定義されます。モデルは特徴を予測やスコアにマップし、最終的に配備されます。
- 評価 (= criterion) 関数。評価関数は (特徴, ラベル) を損失とオプションでメトリクスにマップします。Trainer は SGD で損失を最適化し、そしてメトリクスをログ出力します。メトリクスは微分可能ではないかもしれませんが、損失は微分可能でなければなりません。
高位層はオブジェクトをより複雑なものを構成します、以下を含みます :
- 層スタッキング(積層) (
Sequential(),For()) -
recurrence (
Recurrence(),Fold(),UnfoldFrom(), ...)
ネットワークは一般的に (ニューラルネットワーク層の特定の型のような) 既存の CNTK 関数を使用することができて、そして Sequential() でそれらを組み合わせることによって定義されます。更に、ユーザはユーザ自身の関数を、(Python 式が) CNTK データ型に渡る CNTK 演算で構成されている限りは、任意の Python 式として書くことができます。Python 式はそれらを Function() への呼び出し内部にラッピングすることで内部表現に変換されます。式はデコレータ・シンタックス (@Function) を通して複数行の関数として書くことができます。
演算が CNTK のプリミティブの結合により表現できない場合でさえも、Python (または C++) でユーザ自身の "層" を書くことにより CNTK を拡張する ためのメカニズムがあります。
最後に、CNTK 関数オブジェクトは簡単なパラメータ共有を可能にします。
複数の場所で同じ関数オブジェクトを呼び出す場合、総ての呼び出しは同じ学習可能なパラメータを自然に共有するでしょう。
パラメータ共有を回避するためには、単に2つの異なる関数オブジェクトを作成すれば良いです。
◆ 要約すれば、関数オブジェクトは単純な/複雑なモデル、パラメータ共有、そして訓練目的を便利に定義するための CNTK の単一の抽象です。
多くの他のツールキットと同様に、基礎をなすグラフ演算の点から CNTK ネットワークを直接的に定義することもまた可能です。そしてニューラルネットワークを定義する2つのスタイルの間で自由に上手く組み合わせることができます。
4-2 CNTK のデータモデル : テンソルのシークエンス
CNTK は2つのデータ型の上で演算することができます :
- テンソル (i.e. N-次元配列), 密あるいは疎
- テンソルの シークエンス
これらの区別はテンソルの shape が演算の間に静的であるかです。
CNTK では 軸 (axis) を NumPy 配列における次元と同じものを意味する こととして扱います。例えば、shape (7, 10, 6) のテンソルは3つの 軸 を持ちます。
テンソルは 静的軸 を持つ一方でシークエンスは追加の 動的軸 を持ちます。動的軸は従って可変な長さの軸です。
これについては シークエンスの理解 が詳しいです。
カテゴリー・データは疎な one-hot テンソルとして表現されます (i.e. エンコードされたカテゴリーの位置における単一の 1 を除いて総ての要素が 0 を持ちます)。
これは embedding (埋め込み) と損失関数を行列積 (matrix products) として統一されたスタイルで書くことを可能にします。
◆ CNTK 関数の出力表示は次のフォーマットに類似した出力を与えます :
Operation(Sequence[Tensor[shape]], other arguments) -> Tensor[shape]
Operation が Composite である時は関数はその下のグラフ全体を表現していてそして示されるものは最後の演算のみです。
このグラフはある数の入力を持ち、特定の型の入力を想定しています。
関数を出力表示するとき、"バッチ次元の欠落 (the absence of a batch dimension)" に気がつくでしょう。
CNTK はユーザからバッチ処理を隠します。 ユーザにはテンソルとシークエンスで考えることが望ましく、ミニバッチ処理は CNTK に任せてください。
他のツールキットと違い、CNTK は異なる長さを持つシークエンスを一つのミニバッチに自動的にバッチ化し、総ての必要なパディングとパッキングを処理することも可能です。バケッティングのような回避策は必要ありません。
動的軸 (バッチとシークエンス) を静的軸から分けた理由は、これらの軸に影響するのは非常に少ない演算しかないためです。
デフォルトではバッチの総てのサンプルとシークエンスの総ての要素に何かをすることを望むでしょう。(recurrence や バッチ正規化のような) 僅かの特別な演算だけがこれらの軸を扱う必要があるだけです。
4-3 CNTK ネットワーク例 (1) ロジスティック回帰
ロジスティック回帰の簡単な例で具体的に見てみましょう。
2-次元の正規分布のデータポイントの合成データセットを作成します。データポイントは2つのクラスの一つに属するものとして分類されます。
※ CNTK はラベルは one-hot encoded として想定していることに注意しましょう。
input_dim_lr = 2 # 2-次元データを分類します。
num_classes_lr = 2 # 2つのクラスの1つに
# この例は正規分布からの合成データを使用します。
# それは次のように生成します :
# X_lr[corpus_size,input_dim] - 入力データ
# Y_lr[corpus_size] - ラベル (0 または 1), one-hot-encoded
np.random.seed(0)
def generate_synthetic_data(N):
Y = np.random.randint(size=N, low=0, high=num_classes_lr) # ラベル
X = (np.random.randn(N, input_dim_lr)+3) * (Y[:,None]+1) # データ
# Our model expects float32 features, and cross-entropy
# expects one-hot encoded labels.
Y = scipy.sparse.csr_matrix((np.ones(N,np.float32), (range(N), Y)), shape=(N, num_classes_lr))
X = X.astype(np.float32)
return X, Y
X_train_lr, Y_train_lr = generate_synthetic_data(20000)
X_test_lr, Y_test_lr = generate_synthetic_data(1024)
print('data =\n', X_train_lr[:4])
print('labels =\n', Y_train_lr[:4].todense())
data =
[[ 2.2741797 3.56347561]
[ 5.12873602 5.79089499]
[ 1.3574543 5.5718112 ]
[ 3.54340553 2.46254587]]
labels =
[[ 1. 0.]
[ 0. 1.]
[ 0. 1.]
[ 1. 0.]]
データポイントを訓練のために 20,000 個、テストのために 1,024 個作成しています。
イメージを掴むために、訓練データ・サンプル 1,000 個を安直に可視化してみましょう :
colors = ['r' if label == 0 else 'b' for label in Y_train_lr[:1000].todense()[:,0]]
_ = matplotlib.pyplot.scatter(X_train_lr[:1000].transpose()[0], X_train_lr[:1000].transpose()[1], c=colors, marker='o')

確かに 2 クラスに分類できそうです。
◆ さてモデル関数を定義します。モデル関数は入力データを予測にマップします。それは訓練プロセスの最終的な成果物です。
この例では、モデルの中でも最も単純なロジスティック回帰を使用します :
model_lr_factory = cntk.layers.Dense(num_classes_lr, activation=None)
x = cntk.input_variable(input_dim_lr)
y = cntk.input_variable(num_classes_lr, is_sparse=True)
model_lr = model_lr_factory(x)
Dense は完全結合層で、input_variable はネットワーク入力用のプレースホルダーです。特徴やラベル・データが供給されます。
◆ 次に、評価関数 (= criterion function) を定義します。
評価関数は一種の手綱であり、それを通して trainer はモデルを最適化するために使用します : 評価関数は (入力ベクトル, ラベル) を (損失、メトリクス) にマップします。
-
損失は SGD 更新のために使用されます。ここでは交差エントロピーを選択します。
特にcross_entropy_with_softmax()は、ネットワーク出力に最初にsoftmax()関数を適用します、これは交差エントロピーが確率を想定しているためです。
モデル関数自身にはsoftmax()は含めません、何故ならばモデルの利用には不要だからです。 -
メトリクスとしては、分類エラーをカウントします i.e.
classification_error (output_vector, target_vector)(このメトリクスは微分可能ではありません)。
評価関数を Python コードとして定義してそしてそれを Function オブジェクトに変換します。
(Keras の Lambda() のように、) 単一の式を Function(lambda x, y: expression of x and y) として書くことができます。
モデルを2度評価することを避けるために、デコレータ・シンタックスによる Python 関数定義を使用します。
これはまた入力のデータ型について CNTK に知らせる良い機会です、これはデコレータ @Function を通してなされます :
@cntk.Function
def criterion_lr_factory(data, label_one_hot):
z = model_lr_factory(data) # モデルを適用します。Computes a non-normalized log probability for every output class.
loss = cntk.cross_entropy_with_softmax(z, label_one_hot) # applies softmax to z under the hood
metric = cntk.classification_error(z, label_one_hot)
return loss, metric
criterion_lr = criterion_lr_factory(x, y)
print('criterion_lr:', criterion_lr)
criterion_lr: Composite(Tensor[2], SparseTensor[2]) -> Tuple[Tensor[1], Tensor[1]]
デコレータは Python 関数を CNTK の内部グラフ表現に "コンパイル" します。
このようにして評価関数は結果的に、Python 関数ではなく CNTK 関数オブジェクトとなります。
モデルを訓練する準備ができましたので、実行します :
learner = cntk.sgd(model_lr.parameters,
cntk.learning_rate_schedule(0.1, cntk.UnitType.minibatch))
progress_writer = cntk.logging.ProgressPrinter(0)
criterion_lr.train((X_train_lr, Y_train_lr), parameter_learners=[learner],
callbacks=[progress_writer])
print(model_lr.W.value) # peek at updated W
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
3.58 3.58 0.562 0.562 32
1.61 0.629 0.458 0.406 96
1.1 0.715 0.464 0.469 224
0.88 0.688 0.454 0.445 480
0.734 0.598 0.427 0.402 992
0.637 0.543 0.351 0.277 2016
0.541 0.447 0.257 0.165 4064
0.45 0.359 0.186 0.115 8160
0.366 0.284 0.137 0.0876 16352
[[-1.25055134 -0.53687745]
[-0.99188197 -0.30085728]]
learner は実際にモデル更新を遂行するオブジェクトです。オプティマイザと考えて良いです。
ここでは sgd を選択していますが、learner の他の選択肢は momentum_sgd() や adam() を含みます。
progress_writer は組み込みのログ出力用コールバックで上で見られるように出力を表示します。
そしてユーザのもの、あるいは TensorBoard を使用して訓練進捗を可視化するための組み込みの TensorBoardProgressWriter で置き換えることもできます。
train() 関数はデータ (X_train_lr, Y_train_lr) をミニバッチ毎にモデルに供給してそれを更新します、ここではデータは criterion_lr() の引数と同じ順序のタプルです。
◆ 次にテストセットの上でどの程度上手く動作するかテストしましょう (これもまたミニバッチ毎で動作します) :
test_metric_lr = criterion_lr.test((X_test_lr, Y_test_lr),
callbacks=[progress_writer]).metric
Finished Evaluation [1]: Minibatch[1-32]: metric = 8.11% * 1024;
そして最後に、モデルを通して 2, 3 のサンプルを実行して上手くやれるかを見ます :
model_lr = model_lr_factory(x)
print('model_lr:', model_lr)
model_lr: Dense(Tensor[2]) -> Tensor[2]
任意の Python 関数のように呼び出すことができます :
z = model_lr(X_test_lr[:20])
print("Label :", [label.todense().argmax() for label in Y_test_lr[:20]])
print("Predicted:", [z[i,:].argmax() for i in range(len(z))])
Label : [0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1]
Predicted: [0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0]
4-4 CNTK ネットワーク例 (2) : MNIST 数字認識
前節と同じことを現実的なタスク上で行ないましょう -- ご存知のように、MNIST タスクは手書き数字のスキャンを認識するもので、深層学習の "hello world" の類のようなものです。
最初にダウンロードしてデータを準備します。ここでは scikit-learn を利用します :
input_shape_mn = (28, 28) # MNIST 数字は 28 x 28
num_classes_mn = 10 # 10 の数字の一つとして分類します
# MNIST データを取得します。scikit-learn でベストに遂行されます。
try:
from sklearn import datasets, utils
mnist = datasets.fetch_mldata("MNIST original")
X, Y = mnist.data / 255.0, mnist.target
X_train_mn, X_test_mn = X[:60000].reshape((-1,28,28)), X[60000:].reshape((-1,28,28))
Y_train_mn, Y_test_mn = Y[:60000].astype(int), Y[60000:].astype(int)
except: # scikit-learn が存在しない場合の回避策
import requests, io, gzip
X_train_mn, X_test_mn = (np.fromstring(gzip.GzipFile(fileobj=io.BytesIO(requests.get('http://yann.lecun.com/exdb/mnist/' + name + '-images-idx3-ubyte.gz').content)).read()[16:], dtype=np.uint8).reshape((-1,28,28)).astype(np.float32) / 255.0 for name in ('train', 't10k'))
Y_train_mn, Y_test_mn = (np.fromstring(gzip.GzipFile(fileobj=io.BytesIO(requests.get('http://yann.lecun.com/exdb/mnist/' + name + '-labels-idx1-ubyte.gz').content)).read()[8:], dtype=np.uint8).astype(int) for name in ('train', 't10k'))
# 訓練データをシャッフルします。
np.random.seed(0) # always use the same reordering, for reproducability
idx = np.random.permutation(len(X_train_mn))
X_train_mn, Y_train_mn = X_train_mn[idx], Y_train_mn[idx]
# 更に交差検証セットを切り離します。
X_train_mn, X_cv_mn = X_train_mn[:54000], X_train_mn[54000:]
Y_train_mn, Y_cv_mn = Y_train_mn[:54000], Y_train_mn[54000:]
# モデルは float32 特徴を想定し、交差エントロピーは one-hot encoded ラベルを想定します。
Y_train_mn, Y_cv_mn, Y_test_mn = (scipy.sparse.csr_matrix((np.ones(len(Y),np.float32), (range(len(Y)), Y)), shape=(len(Y), 10)) for Y in (Y_train_mn, Y_cv_mn, Y_test_mn))
X_train_mn, X_cv_mn, X_test_mn = (X.astype(np.float32) for X in (X_train_mn, X_cv_mn, X_test_mn))
# Have a peek.
matplotlib.pyplot.rcParams['figure.figsize'] = (5, 0.5)
matplotlib.pyplot.axis('off')
_ = matplotlib.pyplot.imshow(np.concatenate(X_train_mn[0:10], axis=1), cmap="gray_r")
(28-28)-次元画像を 10-次元スコア・ベクトルにマップする CNTK モデル関数を定義しましょう。
そして後で簡単に再作成できるように、それを関数にラップします :
def create_model_mn_factory():
with cntk.layers.default_options(activation=cntk.ops.relu, pad=False):
return cntk.layers.Sequential([
cntk.layers.Convolution2D((5,5), num_filters=32, reduction_rank=0, pad=True), # reduction_rank=0 for B&W images
cntk.layers.MaxPooling((3,3), strides=(2,2)),
cntk.layers.Convolution2D((3,3), num_filters=48),
cntk.layers.MaxPooling((3,3), strides=(2,2)),
cntk.layers.Convolution2D((3,3), num_filters=64),
cntk.layers.Dense(96),
cntk.layers.Dropout(dropout_rate=0.5),
cntk.layers.Dense(num_classes_mn, activation=None) # no activation in final layer (softmax is done in criterion)
])
model_mn = create_model_mn_factory()
このモデルは先のロジスティック回帰よりは少しばかり複雑で、幾つかの畳み込み層/プーリング層と分類のための2つの完全結合層から成ります。
◆ CNTK の Functional API の幾つかの特徴を示します :
-
CNTK の層ライブラリ (
cntk.layers) からの関数を使用して各層を作成します。 -
高位層 (higher-order 層)
Sequential()はそれら総ての層に次々に適用される新しい関数を作成します。
これは forward function composition (前方関数合成)として知られています。
幾つかの他のツールキットとは異なり、sequential 層に更なる層を後からAdd()- 追加することはできないことに注意してください。CNTK のFunctionオブジェクトは学習可能なパラメータを別にすれば不変 (= immutable) です (Functionオブジェクトを編集するためには、それをclone()できます)。そのスタイルを好むのであれば、貴方の層を Python リストとして作成してそれをSequential()に渡せば良いでしょう。 -
コンテキスト・マネージャ
default_options()は層への様々なオプションの引数のためのデフォルトを指定することを可能にします。例えば活性化関数が常にreluである、というようにです。上書きすることも可能です。 -
最後に、
reluは実際の関数として渡されます、文字列ではないことに注意してください。
任意の関数が活性化関数になれます。Python lambda を直接渡すこともまた可能で、例えばactivation=lambda x: cntk.ops.element_max(x, 0)で relu は手動で認識されます。
(28x28)-次元特徴とそれに従ったラベルを損失とメトリクスにマップするための評価関数は前のサンプルと同様に定義されます :
@cntk.Function
def criterion_mn_factory(data, label_one_hot):
z = model_mn(data)
loss = cntk.cross_entropy_with_softmax(z, label_one_hot)
metric = cntk.classification_error(z, label_one_hot)
return loss, metric
x = cntk.input_variable(input_shape_mn)
y = cntk.input_variable(num_classes_mn, is_sparse=True)
criterion_mn = criterion_mn_factory(x,y)
◆ ここでのトレーニングのために、momentum_sgd を選択しましょう :
N = len(X_train_mn)
lrs = cntk.learning_rate_schedule([0.001]*12 + [0.0005]*6 + [0.00025]*6 + [0.000125]*3 + [0.0000625]*3 + [0.00003125], cntk.learners.UnitType.sample, epoch_size=N)
momentums = cntk.learners.momentum_as_time_constant_schedule([0]*5 + [1024], epoch_size=N)
minibatch_sizes = cntk.minibatch_size_schedule([256]*6 + [512]*9 + [1024]*7 + [2048]*8 + [4096], epoch_size=N)
learner = cntk.learners.momentum_sgd(model_mn.parameters, lrs, momentums)
このブロックは少し普通とは違うように見えます。
第一に、学習率は epoch_size パラメータと一緒に、リスト ([0.001]*12 + [0.0005]*6 +...) として指定されています。
これは CNTK に 12 エポックの間 0.001 を使用してそれから次の 6 エポックについて 0.0005, etc. として続けることを知らせています。
2番目に、学習率がサンプル毎で、そして momentum が time constant として指定されていることです。
これらの値は直接的に重みを指定しています。その値で各サンプルの勾配はモデルに寄与し、そしてその寄与が訓練の進捗につれてどのくらい減衰するかを指定しています ; ミニバッチサイズからは独立的にです。
この独特な CNTK の特徴はミニバッチサイズを調整することを可能にします。ここでは、そのサイズを 256 から 4096 にまで増大していて、これは終わりに向かって 3 倍速い演算に導かれます (Titan-X の場合)。
◆ それでは、モデルを訓練しましょう :
progress_writer = cntk.logging.ProgressPrinter()
criterion_mn.train((X_train_mn, Y_train_mn), minibatch_size=minibatch_sizes,
max_epochs=40, parameter_learners=[learner], callbacks=[progress_writer])
test_metric_mn = criterion_mn.test((X_test_mn, Y_test_mn), callbacks=[progress_writer]).metric
Learning rate per 1 samples: 0.001
Momentum per 1 samples: 0.0
Finished Epoch[1]: loss = 0.678428 * 54000, metric = 22.62% * 54000 2.934s (18404.9 samples/s);
Finished Epoch[2]: loss = 0.130326 * 54000, metric = 3.76% * 54000 2.331s (23166.0 samples/s);
Finished Epoch[3]: loss = 0.089973 * 54000, metric = 2.62% * 54000 2.329s (23185.9 samples/s);
Finished Epoch[4]: loss = 0.072712 * 54000, metric = 2.13% * 54000 2.332s (23156.1 samples/s);
Finished Epoch[5]: loss = 0.060643 * 54000, metric = 1.74% * 54000 2.329s (23185.9 samples/s);
Momentum per 1 samples: 0.9990239141819757
Finished Epoch[6]: loss = 0.051962 * 54000, metric = 1.55% * 54000 2.328s (23195.9 samples/s);
Finished Epoch[7]: loss = 0.045413 * 54000, metric = 1.28% * 54000 2.229s (24226.1 samples/s);
Finished Epoch[8]: loss = 0.041152 * 54000, metric = 1.20% * 54000 2.076s (26011.6 samples/s);
Finished Epoch[9]: loss = 0.037911 * 54000, metric = 1.12% * 54000 2.085s (25899.3 samples/s);
Finished Epoch[10]: loss = 0.033193 * 54000, metric = 1.00% * 54000 2.089s (25849.7 samples/s);
Finished Epoch[11]: loss = 0.032183 * 54000, metric = 0.96% * 54000 2.089s (25849.7 samples/s);
Finished Epoch[12]: loss = 0.029251 * 54000, metric = 0.91% * 54000 2.081s (25949.1 samples/s);
Learning rate per 1 samples: 0.0005
Finished Epoch[13]: loss = 0.023589 * 54000, metric = 0.68% * 54000 2.081s (25949.1 samples/s);
Finished Epoch[14]: loss = 0.022030 * 54000, metric = 0.62% * 54000 2.093s (25800.3 samples/s);
Finished Epoch[15]: loss = 0.019968 * 54000, metric = 0.60% * 54000 2.092s (25812.6 samples/s);
Finished Epoch[16]: loss = 0.018816 * 54000, metric = 0.55% * 54000 2.264s (23851.6 samples/s);
Finished Epoch[17]: loss = 0.018812 * 54000, metric = 0.55% * 54000 1.976s (27327.9 samples/s);
Finished Epoch[18]: loss = 0.017495 * 54000, metric = 0.49% * 54000 1.976s (27327.9 samples/s);
Learning rate per 1 samples: 0.00025
Finished Epoch[19]: loss = 0.015304 * 54000, metric = 0.43% * 54000 1.977s (27314.1 samples/s);
Finished Epoch[20]: loss = 0.015531 * 54000, metric = 0.42% * 54000 1.976s (27327.9 samples/s);
Finished Epoch[21]: loss = 0.013701 * 54000, metric = 0.41% * 54000 1.975s (27341.8 samples/s);
Finished Epoch[22]: loss = 0.013611 * 54000, metric = 0.41% * 54000 1.977s (27314.1 samples/s);
Finished Epoch[23]: loss = 0.014296 * 54000, metric = 0.41% * 54000 2.503s (21574.1 samples/s);
Finished Epoch[24]: loss = 0.012532 * 54000, metric = 0.39% * 54000 1.942s (27806.4 samples/s);
Learning rate per 1 samples: 0.000125
Finished Epoch[25]: loss = 0.012845 * 54000, metric = 0.37% * 54000 1.942s (27806.4 samples/s);
Finished Epoch[26]: loss = 0.010860 * 54000, metric = 0.32% * 54000 1.938s (27863.8 samples/s);
Finished Epoch[27]: loss = 0.011842 * 54000, metric = 0.34% * 54000 1.940s (27835.1 samples/s);
Learning rate per 1 samples: 6.25e-05
Finished Epoch[28]: loss = 0.012103 * 54000, metric = 0.35% * 54000 1.939s (27849.4 samples/s);
Finished Epoch[29]: loss = 0.011201 * 54000, metric = 0.33% * 54000 1.939s (27849.4 samples/s);
Finished Epoch[30]: loss = 0.011154 * 54000, metric = 0.34% * 54000 1.939s (27849.4 samples/s);
Learning rate per 1 samples: 3.125e-05
Finished Epoch[31]: loss = 0.011192 * 54000, metric = 0.34% * 54000 3.010s (17940.2 samples/s);
Finished Epoch[32]: loss = 0.011413 * 54000, metric = 0.35% * 54000 1.906s (28331.6 samples/s);
Finished Epoch[33]: loss = 0.010924 * 54000, metric = 0.31% * 54000 1.910s (28272.3 samples/s);
Finished Epoch[34]: loss = 0.010529 * 54000, metric = 0.29% * 54000 1.899s (28436.0 samples/s);
Finished Epoch[35]: loss = 0.010408 * 54000, metric = 0.31% * 54000 1.904s (28361.3 samples/s);
Finished Epoch[36]: loss = 0.011141 * 54000, metric = 0.34% * 54000 1.904s (28361.3 samples/s);
Finished Epoch[37]: loss = 0.010458 * 54000, metric = 0.28% * 54000 1.912s (28242.7 samples/s);
Finished Epoch[38]: loss = 0.011195 * 54000, metric = 0.33% * 54000 1.903s (28376.2 samples/s);
Finished Epoch[39]: loss = 0.010112 * 54000, metric = 0.30% * 54000 1.912s (28242.7 samples/s);
Finished Epoch[40]: loss = 0.010477 * 54000, metric = 0.28% * 54000 1.901s (28406.1 samples/s);
Finished Evaluation [1]: Minibatch[1-313]: metric = 0.58% * 10000;
4-5 Graph API 例 : 再度 MNIST 数字認識
CNTK では、ネットワークをグラフ・レベル API を使用して書くこともまた可能です。この API は冗長ですが時にはより柔軟でしょう。
次は上と同じモデルと評価関数を定義して、そして同じ結果を得ます :
images = cntk.input_variable(input_shape_mn, name='images')
with cntk.layers.default_options(activation=cntk.ops.relu, pad=False):
r = cntk.layers.Convolution2D((5,5), num_filters=32, reduction_rank=0, pad=True)(images)
r = cntk.layers.MaxPooling((3,3), strides=(2,2))(r)
r = cntk.layers.Convolution2D((3,3), num_filters=48)(r)
r = cntk.layers.MaxPooling((3,3), strides=(2,2))(r)
r = cntk.layers.Convolution2D((3,3), num_filters=64)(r)
r = cntk.layers.Dense(96)(r)
r = cntk.layers.Dropout(dropout_rate=0.5)(r)
model_mn = cntk.layers.Dense(num_classes_mn, activation=None)(r)
label_one_hot = cntk.input_variable(num_classes_mn, is_sparse=True, name='labels')
loss = cntk.cross_entropy_with_softmax(model_mn, label_one_hot)
metric = cntk.classification_error(model_mn, label_one_hot)
criterion_mn = cntk.combine([loss, metric])
print('criterion_mn:', criterion_mn)
criterion_mn: Composite(images: Tensor[28,28], labels: SparseTensor[10]) -> Tuple[Tensor[1], Tensor[1]]
5. データの供給
モデル構造を決めてそれを定義すれば、訓練データを CNTK 訓練プロセスに供給する問題に直面します。
前出の例では単純にデータを NumP/Scipy 配列として供給していますが、これは CNTK がデータを trainer に供給するための3つの方法の一つでしかありません :
- NumPy 配列あるいは Scipy スパース行列 (CSR 形式) として。メモリにロードできる小さなデータセットのために。
- CNTK の
MinibatchSourceクラスのインスタンスを通して。メモリに適合しない巨大なデータセットのため。 - 明示的な minibatch ループを通して。上の方法が適用されないとき。
5-1 NumPy/Scipy 配列を通してデータを供給する
train() と test() 関数は minibatch_source 引数のために NumPy 配列または Scipy スパース行列 (CSR 形式) のタプルを受けとります。タプル・メンバーは criterion の引数と同じ順序でなければなりません。
密なテンソルについては NumPy 配列を使用します。一方でスパースデータは scipy.sparse.csr_matrix 型を持つべきです。
引数の各々は NumPy/Scipy 配列の Python リストであるべきで、ここで各リスト要素はデータ項目を表します。
シークエンスとして宣言された引数については、NumPy/Scipy 配列の最初の軸 (次元) がシークエンスの長さで、残りの軸はシークエンスの各々の要素の shape です。
シークエンスでない引数は単一のテンソルから成ります。
shape, データ型 (np.float32/float64) そしてスパースネス (= sparseness, 密か疎か) は引数型に適合しなければなりません。
最適化の観点からは、シークエンスでない引数は (リストの代わりに) 単一の巨大な NumPy/Scipy 配列としても渡されます。これは前出の例で行なっています。
データをランダム化するのはユーザの責任であることに注意してください。
5-2 MinibatchSource クラスを使用してデータを供給する
製品スケールの訓練データはときにメモリにフィットしません。
この場合のために、CNTK は MinibatchSource クラスを提供し、これは以下の機能を提供します :
- chunked ランダム化アルゴリズム。これは任意の時間において、メモリにデータの一部だけを保持します。
- 分散リーディング。各ワーカーは異なるサブセットを読みます。
- 画像と画像拡張 (augmentation) のための 変換パイプライン。
- 複数のデータ型に渡る 構成可能性 (= composability) (e.g. 画像キャプション)。
- 透過な 非同期ローディング。これにより、ミニバッチが読み込み/準備の間に GPU が停滞 (= stall) しません。
現在、MinibatchSource クラスは "deserializers" の形式でデータ型の限定されたセットを実装しています :
-
画像 (
ImageDeserializer)。 -
音声ファイル (
HTKFeatureDeserializer,HTKMLFDeserializer)。 - CNTK の CTF フォーマット のデータ。これは、サンプル毎に1次元スパース/密なシークエンスを含む、名前付けられた特徴チャネルのセットから成ります。そして
CTFDeserializerは各特徴チャネルをモデルか評価関数の入力と関連付けることができます。
ImageDeserializer クラスを使用する次のサンプルは一般的なパターンを示します。
image_width, image_height, num_channels = (32, 32, 3)
num_classes = 1000
def create_image_reader(map_file, is_training):
transforms = []
if is_training: # train uses data augmentation (translation only)
transforms += [
cntk.io.transforms.crop(crop_type='randomside', side_ratio=0.8) # random translation+crop
]
transforms += [ # to fixed size
cntk.io.transforms.scale(width=image_width, height=image_height, channels=num_channels, interpolations='linear'),
]
# deserializer
return cntk.io.MinibatchSource(cntk.io.ImageDeserializer(map_file, cntk.io.StreamDefs(
features = cntk.io.StreamDef(field='image', transforms=transforms),
labels = cntk.io.StreamDef(field='label', shape=num_classes)
)), randomize=is_training, max_sweeps = cntk.io.INFINITELY_REPEAT if is_training else 1)
5-3 明示的な minibatch ループを通してデータを供給する
(minibatch ループを内部的に実装している) train() と test() 関数にデータを全体として供給する代わりに、
ユーザ自身で minibatch ループを実装して低位 API train_minibatch() と test_minibatch() を呼び出すことも可能です。
ユーザデータが上述の方法に適合するような形式にないときに有用です。
train_minibatch() と test_minibatch() メソッドはクラス Trainer のオブジェクトをインスタンス化することを必要とします。
これは train() の引数のサブセットを取ります。
次は前出のロジスティック回帰の例を、明示的な minibatch ループを通して実装しています :
# モデルを再作成して、再び開始します。これは上からの直接コピーです。
model_lr = cntk.layers.Dense(num_classes_lr, activation=None)
@cntk.Function
def criterion_lr_factory(data, label_one_hot):
z = model_lr(data) # apply model. Computes a non-normalized log probability for every output class.
loss = cntk.cross_entropy_with_softmax(z, label_one_hot) # this applies softmax to z under the hood
metric = cntk.classification_error(z, label_one_hot)
return loss, metric
x = cntk.input_variable(input_dim_lr)
y = cntk.input_variable(num_classes_lr, is_sparse=True)
criterion_lr = criterion_lr_factory(x,y)
# learner を作成します; 上と同じです。
learner = cntk.sgd(model_lr.parameters, cntk.learning_rate_schedule(0.1, cntk.UnitType.minibatch))
# 今回は Trainer インスタンスをユーザ自身で作成しなければなりません。
trainer = cntk.Trainer(None, criterion_lr, [learner], [cntk.logging.ProgressPrinter(50)])
# Train the model by spoon-feeding minibatch by minibatch.
minibatch_size = 32
for i in range(0, len(X_train_lr), minibatch_size): # ミニバッチに渡るループ
x = X_train_lr[i:i+minibatch_size] # get one minibatch worth of data
y = Y_train_lr[i:i+minibatch_size]
trainer.train_minibatch({criterion_lr.arguments[0]: x, criterion_lr.arguments[1]: y}) # 一つのミニバッチからモデルを更新します。
trainer.summarize_training_progress()
# ミニバッチ毎のテストエラー。
evaluator = cntk.Evaluator(criterion_lr.outputs[1], [progress_writer]) # metric is the second output of criterion_lr()
for i in range(0, len(X_test_lr), minibatch_size): # loop over minibatches
x = X_test_lr[i:i+minibatch_size] # get one minibatch worth of data
y = Y_test_lr[i:i+minibatch_size]
evaluator.test_minibatch({criterion_lr.arguments[0]: x, criterion_lr.arguments[1]: y}) # test one minibatch
evaluator.summarize_test_progress()
Learning rate per minibatch: 0.1
Minibatch[ 1- 50]: loss = 0.663274 * 1600, metric = 37.31% * 1600;
Minibatch[ 51- 100]: loss = 0.481867 * 1600, metric = 20.56% * 1600;
Minibatch[ 101- 150]: loss = 0.402196 * 1600, metric = 12.94% * 1600;
Minibatch[ 151- 200]: loss = 0.386619 * 1600, metric = 13.75% * 1600;
Minibatch[ 201- 250]: loss = 0.328646 * 1600, metric = 9.19% * 1600;
Minibatch[ 251- 300]: loss = 0.301831 * 1600, metric = 9.50% * 1600;
Minibatch[ 301- 350]: loss = 0.299345 * 1600, metric = 9.44% * 1600;
Minibatch[ 351- 400]: loss = 0.279577 * 1600, metric = 8.94% * 1600;
Minibatch[ 401- 450]: loss = 0.281061 * 1600, metric = 8.25% * 1600;
Minibatch[ 451- 500]: loss = 0.261366 * 1600, metric = 7.81% * 1600;
Minibatch[ 501- 550]: loss = 0.244967 * 1600, metric = 7.12% * 1600;
Minibatch[ 551- 600]: loss = 0.243953 * 1600, metric = 8.31% * 1600;
Finished Epoch[1]: loss = 0.344399 * 20000, metric = 12.58% * 20000 5.795s (3451.3 samples/s);
Finished Evaluation [2]: Minibatch[1-32]: metric = 8.11% * 1024;
6. トレーニングと評価
これまでのサンプルでは、訓練のために train() 関数を、そして評価のために test() を使用していました。
この章では、train() の高度なオプションを紹介します :
- MPI を使用する、複数 GPU 上の分散トレーニング。
- Progress トラッキング、TensorBoard 可視化、チェックポインティング、交差検証ベースの訓練コントロール等のためのコールバック。
6-1 分散トレーニング
CNTK は分散トレーニングを容易にします。革新的なことに、分散トレーニングの3つの方法をサポートします :
- 単純なデータ並列トレーニング。
- 1-bit SGD。
- BlockMomentum。
※ 別の分類の仕方もあります。分散トレーニングについての詳細は Multiple GPUs and Machines をご覧ください。
単純な データ並列 トレーニングは各ミニバッチを N ワーカー・プロセスに渡って分散します。ここで各プロセスは一つの GPU を使用します。
各ミニバッチ処理の後、各モデルのコピーを更新する前に総てのワーカーからの勾配が集められます。
これはしばしば、高速計算/通信レシオを持つ畳み込みネットワークのためには十分です。
1-bit SGD は次のペーパーからのテクニックを使用してデータ並列トレーニングにおける通信ステップを高速化します :
このメソッドは完全結合ネットワークとある種のリカレント・ネットワークのような通信コストが支配する要因となるようなネットワークのために効果的であることが分かっています。
このメソッドは良いスピードアップにおいて精度を最小限だけ下げることが分かっています。
BlockMomentum は次のペーパーからのテクニックを使用します :
これは N ミニバッチ毎だけの勾配交換により通信帯域を改善します。
◆ プロセスは MPI を通して開始されて通信します。
そして CNTK の分散トレーニングは単一のサーバ内でも複数のサーバに渡っても両者で動作します。
ユーザが行なわなければならない総てのことは :
-
distributed_learnerオブジェクトの内側にユーザの learner をラップする。 -
mpiexecを使用して Python スクリプトを実行する
ここでは分散トレーニングについて深入りはしませんが (詳細は Multiple GPUs and Machines を参照)、
以下は CNTK で 8 GPU の環境で CIFAR-10 用のモデルをトレーニングしている際の nvidia-smi の出力表示です :
$ nvidia-smi
Mon Oct 23 07:41:43 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.81 Driver Version: 384.81 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:17.0 Off | 0 |
| N/A 77C P0 64W / 149W | 681MiB / 11439MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla K80 Off | 00000000:00:18.0 Off | 0 |
| N/A 60C P0 73W / 149W | 207MiB / 11439MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla K80 Off | 00000000:00:19.0 Off | 0 |
| N/A 76C P0 63W / 149W | 207MiB / 11439MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla K80 Off | 00000000:00:1A.0 Off | 0 |
| N/A 58C P0 72W / 149W | 207MiB / 11439MiB | 5% Default |
+-------------------------------+----------------------+----------------------+
| 4 Tesla K80 Off | 00000000:00:1B.0 Off | 0 |
| N/A 77C P0 60W / 149W | 207MiB / 11439MiB | 5% Default |
+-------------------------------+----------------------+----------------------+
| 5 Tesla K80 Off | 00000000:00:1C.0 Off | 0 |
| N/A 57C P0 72W / 149W | 207MiB / 11439MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 6 Tesla K80 Off | 00000000:00:1D.0 Off | 0 |
| N/A 74C P0 62W / 149W | 207MiB / 11439MiB | 5% Default |
+-------------------------------+----------------------+----------------------+
| 7 Tesla K80 Off | 00000000:00:1E.0 Off | 0 |
| N/A 57C P0 72W / 149W | 207MiB / 11439MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 3567 C python 58MiB |
| 0 3568 C python 58MiB |
| 0 3569 C python 58MiB |
| 0 3570 C python 58MiB |
| 0 3571 C python 255MiB |
| 0 3572 C python 58MiB |
| 0 3573 C python 58MiB |
| 0 3574 C python 58MiB |
| 1 3572 C python 196MiB |
| 2 3569 C python 196MiB |
| 3 3570 C python 196MiB |
| 4 3573 C python 196MiB |
| 5 3568 C python 196MiB |
| 6 3567 C python 196MiB |
| 7 3574 C python 196MiB |
+-----------------------------------------------------------------------------+
6-2 コールバック
train() の callbacks パラメータは、train() 関数が定期的に、典型的にはエポック毎に実行するアクションを指定します。
callbacks パラメータはオブジェクトのリストで、ここでオブジェクト型が特定のコールバック・アクションを決定します。
-
進捗トラッカー (= Progress trackers) は
nミニバッチ後と各エポック後に進捗 (平均損失とメトリクス) を定期的にログ出力することを可能にします。
オプションで、最初の 2, 3 のミニバッチの総てもログ出力可能です :-
ProgressPrinter- stderr とファイルにログ出力します。 -
TensorBoardProgressWriter- TensorBoard における可視化のためにイベントをログ出力します。 - ユーザ自身の tracker クラスを書くこともできます。
-
-
CheckpointConfigクラスは、エポック毎にチェックポイント・ファイルを書き、そして最新の利用可能なチェックポイントで訓練を再開するコールバックを示します。 -
CrossValidationConfigクラスは、CNTK に検証データセット上でモデルを定期的に評価して、
そしてユーザ指定のコールバック関数 - これは False を返すことで訓練の早期停止を示すことができます - を呼び出すことを伝えます。 -
TestConfigは、CNTK に与えられたテストセットで最後にモデルを評価することを命じます。これは前出のサンプルでの明示的なtest()呼び出しと同じです。
6-3. まとめ: 上級のトレーニング・サンプル
これまでの説明を単一のトレーニング・サンプルにまとめてみましょう。
下は MNIST のサンプルを実行しますが、次の機能を併せ持っています : ログ出力、TensorBoard イベント、チェックポインティング、CV (交差検証) ベースの訓練コントロール、そして最終的なテストです :
# モデルと評価関数を作成します。
x = cntk.input_variable(input_shape_mn)
y = cntk.input_variable(num_classes_mn, is_sparse=True)
model_mn = create_model_mn_factory()
@cntk.Function
def criterion_mn_factory(data, label_one_hot):
z = model_mn(data)
loss = cntk.cross_entropy_with_softmax(z, label_one_hot)
metric = cntk.classification_error(z, label_one_hot)
return loss, metric
criterion_mn = criterion_mn_factory(x, y)
# learner を作成します。
learner = cntk.learners.momentum_sgd(model_mn.parameters, lrs, momentums)
# ファイルへのログ出力と TensorBoard イベントログのための Progress コールバックを作成します。
# Prints statistics for the first 10 minibatches, then for every 50th, to a log file.
progress_writer = cntk.logging.ProgressPrinter(50, first=10, log_to_file='my.log')
tensorboard_writer = cntk.logging.TensorBoardProgressWriter(50, log_dir='my_tensorboard_logdir',
model=criterion_mn)
# チェックポイント・コールバックを作成します。
# Set restore=True to restart from available checkpoints.
epoch_size = len(X_train_mn)
checkpoint_callback_config = cntk.CheckpointConfig('model_mn.cmf', epoch_size, preserve_all=True, restore=False)
# 交差検証ベースの訓練コントロールを作成します。
# This callback function halves the learning rate each time the cross-validation metric
# improved less than 5% relative, and stops after 6 adjustments.
prev_metric = 1 # metric from previous call to the callback. Error=100% at start.
def adjust_lr_callback(index, average_error, cv_num_samples, cv_num_minibatches):
global prev_metric
if (prev_metric - average_error) / prev_metric < 0.05: # did metric improve by at least 5% rel?
learner.reset_learning_rate(cntk.learning_rate_schedule(learner.learning_rate() / 2, cntk.learners.UnitType.sample))
if learner.learning_rate() < lrs[0] / (2**7-0.1): # we are done after the 6-th LR cut
print("Learning rate {} too small. Training complete.".format(learner.learning_rate()))
return False # means we are done
print("Improvement of metric from {:.3f} to {:.3f} insufficient. Halving learning rate to {}.".format(prev_metric, average_error, learner.learning_rate()))
prev_metric = average_error
return True # means continue
cv_callback_config = cntk.CrossValidationConfig((X_cv_mn, Y_cv_mn), 3*epoch_size, minibatch_size=256,
callback=adjust_lr_callback, criterion=criterion_mn)
# 最終モデルをテストするためのコールバック。
test_callback_config = cntk.TestConfig((X_test_mn, Y_test_mn), criterion=criterion_mn)
# 訓練します!
callbacks = [progress_writer, tensorboard_writer, checkpoint_callback_config, cv_callback_config, test_callback_config]
progress = criterion_mn.train((X_train_mn, Y_train_mn), minibatch_size=minibatch_sizes,
max_epochs=50, parameter_learners=[learner], callbacks=callbacks)
# Progress is available from return value
losses = [summ.loss for summ in progress.epoch_summaries]
print('loss progression =', ", ".join(["{:.3f}".format(loss) for loss in losses]))
Redirecting log to file my.log
Improvement of metric from 0.010 to 0.010 insufficient. Halving learning rate to 0.0005.
Improvement of metric from 0.008 to 0.009 insufficient. Halving learning rate to 0.00025.
Improvement of metric from 0.009 to 0.008 insufficient. Halving learning rate to 0.000125.
Improvement of metric from 0.008 to 0.008 insufficient. Halving learning rate to 6.25e-05.
Improvement of metric from 0.008 to 0.008 insufficient. Halving learning rate to 3.125e-05.
Improvement of metric from 0.008 to 0.008 insufficient. Halving learning rate to 1.5625e-05.
Learning rate 7.8125e-06 too small. Training complete.
loss progression = 0.720, 0.129, 0.091, 0.075, 0.063, 0.052, 0.046, 0.043, 0.037, 0.030, 0.028, 0.026, 0.025, 0.024, 0.022, 0.020, 0.021, 0.019, 0.017, 0.016, 0.015, 0.015, 0.015, 0.015, 0.014, 0.013, 0.014, 0.014, 0.014, 0.013, 0.014, 0.013, 0.013
◆ TensorBoard 用のイベントログ・ファイルも生成されています :
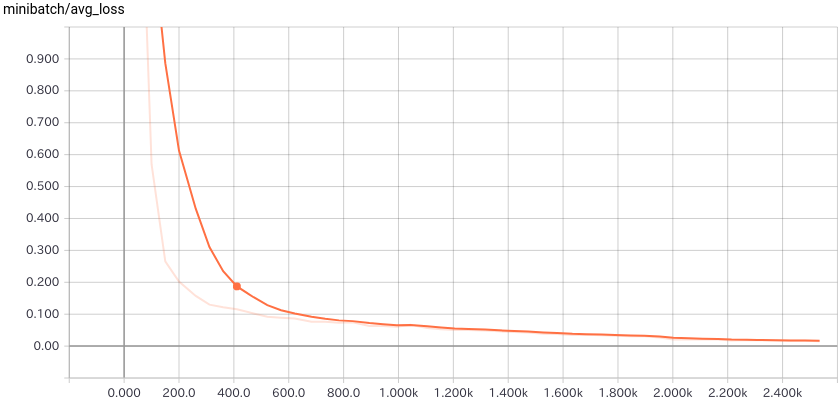
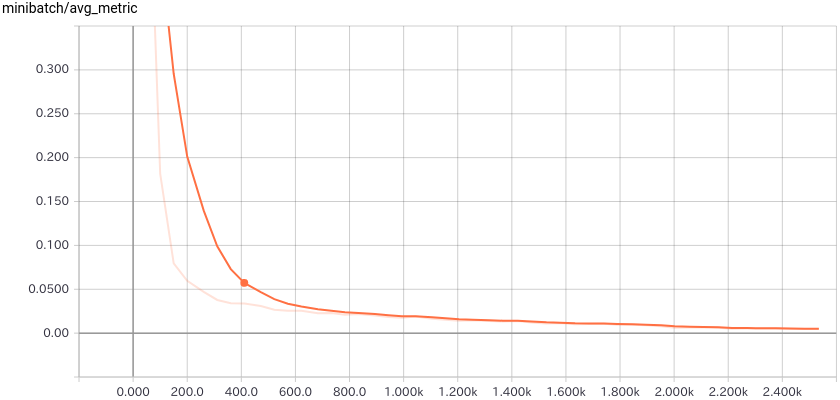
7. モデルの配備
深層ニューラルネットワークの訓練の究極的な目的は、ユーザ自身のプログラムか製品の一部として訓練されたモデルを配備することです。その細部については Python 以外のプログラミング言語も伴いますので、ここでは Python の例と高位の概要を記述します。個別の言語については指定のサンプルを参照してください。
モデルの訓練が完了すれば、多くの方法で配備可能です :
- ユーザの Python プログラムで直接。
- C++, C#, そして Java を含む、CNTK がサポートする任意の他の言語から。
- ユーザ自身の Web サービスから。
- Microsoft Azure にデプロイされた Web サービスを通して。
総ての場合について最初のステップは、モデルの入力型が知られていることを確認して
そしてそれから訓練後にディスクへ貴方のモデルをセーブします。
model を print するだけで入力を探求できます :
print(model_mn)
x = cntk.input_variable(input_shape_mn)
model = model_mn(x)
print(model)
Composite(keep: Sequence[tensor]) -> Sequence[tensor]
Composite(Tensor[28,28]) -> Tensor[10]
model.save('mnist.cmf')
確かに mnist.cmf ファイルとしてセーブされています :
$ ls -l mnist.cmf
-rw-rw-r-- 1 ubuntu ubuntu 409365 Oct 22 23:49 mnist.cmf
Python ベースのプログラムで貴方のモデルを配備することは簡単です。
何故ならばネットワークは関数オブジェクトですから、関数のように呼び出し可能で、
モデルを単純にロードできてそして入力とともに呼び出せば良いのです :
# At program start, load the model.
classify_digit = cntk.Function.load('mnist.cmf')
# To apply model, just call it.
image_input = X_test_mn[8345] # (pick a random test digit for illustration)
scores = classify_digit(image_input) # call the model function with the input data
image_class = scores.argmax() # find the highest-scoring class
# And that's it. Let's have a peek at the result
print('Recognized as:', image_class)
matplotlib.pyplot.axis('off')
_ = matplotlib.pyplot.imshow(image_input, cmap="gray_r")
Recognized as: 8
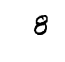
◆ (バインディングが存在する) 他のプログラム言語で書かれたプログラムからでもモデルは直接配備できます。
上述の Python の例に類似したサンプルについては、以下を参照してください :
- C++:
Examples/Evaluation/CNTKLibraryCPPEvalCPUOnlyExamples/CNTKLibraryCPPEvalCPUOnlyExamples.cpp - C#:
Examples/Evaluation/CNTKLibraryCSEvalCPUOnlyExamples/CNTKLibraryCSEvalExamples.cs
貴方自身の Web サービスからモデルを配備するためには、モデルを同じ方法でロードして開始してください。
Azure Web サーバを通してモデルを配備するためには、次のチュートリアルに従ってください :
8. What's Next ?
CNTK 2.2 Python API をマスターするためには CNTK 2.2 Tutorials が最適です。
一連の投稿記事で既に 100 番台 (初級編) はカバーしています。
今回の記事は 200 番をベースにしていますので、残りの 200 番台 (中級編) に取り組まれるのが良いでしょう。
以上