きっかけ
次のような日本語NLPをやってきました.
tfidf/mbart/mt5/CLIP embeddings cluster reconstructing vis: 特許など長文の、動的な文章間類似可視化・迅速閲覧・解析手段。および第三の特許検索・探索手法
https://qiita.com/kzuzuo/items/8a80d8974bf3a7db7e54
更新中 前) 特許SDI用AI: 複数の自然言語深層学習モデルにおいて見られた個性とその解釈 および認知的観点に基づく知識構造の多様性を評価した価値共創の展望と、創造性
https://qiita.com/kzuzuo/items/4670b5ff7526319680f4
これら実践や知識がどの程度広く役に立つのか,例えばコンペにおいてどの程度有効なのか,との疑問を持っていたところ,日本語NLPが関連しそうなコンペが開催されていたので参加してみました.
コンペ初参加.専門は工学・生物・DDS・医薬系知的財産です.
コンペ概要
小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~
https://www.nishika.com/competitions/21/summary
・目的:
「本コンペでは、日本最大級の小説投稿サイトである“小説家になろう”様のデータを用いて、ジャンルや作者名などの関連データから各小説のブックマーク数を予測することをテーマとします。
予測に活用可能なデータには、テキスト情報としてタイトルとあらすじが含まれています。
小説家になろうのタイトルとあらすじをAIが評価してくれるサービス(https://rawi-novel.work/help/rawi )も提供されている中で、「どのようなタイトル・あらすじがブックマーク数が多くなっているのか」について示唆を得ることも、本コンペ開催の意図の1つです。」
・与えられたデータは以下の通りです.ブックマーク度を予測します.
・予測精度の評価はMulti-class loglossにて行われます.
要素 説明
ncode Nコード
general_firstup 初回掲載日 YYYY-MM-DD HH:MM:SSの形式
title 小説名
story 小説のあらすじ
keyword キーワード
userid 作者のユーザID(数値)
writer 作者名
biggenre 大ジャンル
genre ジャンル
novel_type 連載の場合は1、短編の場合は2
end 短編小説と完結済小説は0となっています。連載中は1です。
isstop 長期連載停止中なら1、それ以外は0です。
isr15 登録必須キーワードに「R15」が含まれる場合は1、それ以外は0です。
isbl 登録必須キーワードに「ボーイズラブ」が含まれる場合は1、それ以外は0です。
isgl 登録必須キーワードに「ガールズラブ」が含まれる場合は1、それ以外は0です。
iszankoku 登録必須キーワードに「残酷な描写あり」が含まれる場合は1、それ以外は0です。
istensei 登録必須キーワードに「異世界転生」が含まれる場合は1、それ以外は0です。
istenni 登録必須キーワードに「異世界転移」が含まれる場合は1、それ以外は0です。
pc_or_k 1はケータイのみ、2はPCのみ、3はPCとケータイで投稿された作品です。
fav_novel_cnt_bin ブックマーク度
初見と偏見
・テーブルデータが主,テキストデータは従となるコンペとなりそう.
・チュートリアルをベースとして検討して良さそう.
・web小説には変化しやすいトレンドが存在するであろう.時系列が重要となるコンペとなりそう?
・NLPを用いることができそうな特徴は,title,keyword,story.後発作は人気作のこれらを真似てくるであろうから,単純な出現頻度をもとにした文章類似やヒトが簡単に認知できる単語相関のみからブックマーク度を予測することは難しいかもしれない.
・ヒトが認知し難い部分まで抽出できる,比較的高度な言語モデルを採用する必要があるかもしれない.
・時系列要素を他の特徴と絡める事ができるモデル作りをする必要があるだろう.NLPの結果をテーブルの特徴とすると良いかもしれない.ラグ特徴が重要となるかもしれない.
・チュートリアルではBERTVectorizerにより得られた文章の768dimベクトルをそのままテーブルの特徴としているが,テーブルデータにはより重要な特徴が多くあることから?,次元削減しておいたほうが良さそうにも思える.一方,比較的高度な言語モデルの必要性を考慮すると,そのまま用いたほうが良いようにも思える.検証必要.
メモ
・時系列の見せかけの回帰に注意.基本差分をとる.
・勾配ブースティングがおすすめ.分布変換としても.
・分布変換として,対数変換やBox-cox変換を考慮.
・月など,三角関数を使って変換
・イベントはヒューステリックが有意なことも.ある程度あきらめも.
・バリデーションにおけるリーク注意.
・目的に応じた評価指標は重要.
初期EDA
・tfidf/mbart/mt5/CLIP on embeddings cluster visを流用し,title + storyを図示.

・それぞれの点は一つの小説.ブックマーク度が大きいほど暖色となるようにしている.
・tfidf/mbart/mt5/CLIP embeddings cluster visはヒトが簡単に認知できること=ヒトの認知により近いを優先した比較的シンプルなアルゴリズムとしている.
この比較的シンプルな手法においても,ある程度のクラスタの存在が確認できる.NLPは予想より有効かもしれない.
・現実の恋愛と童話とホラーが近傍に現れるってのは示唆t...何でも無いです.
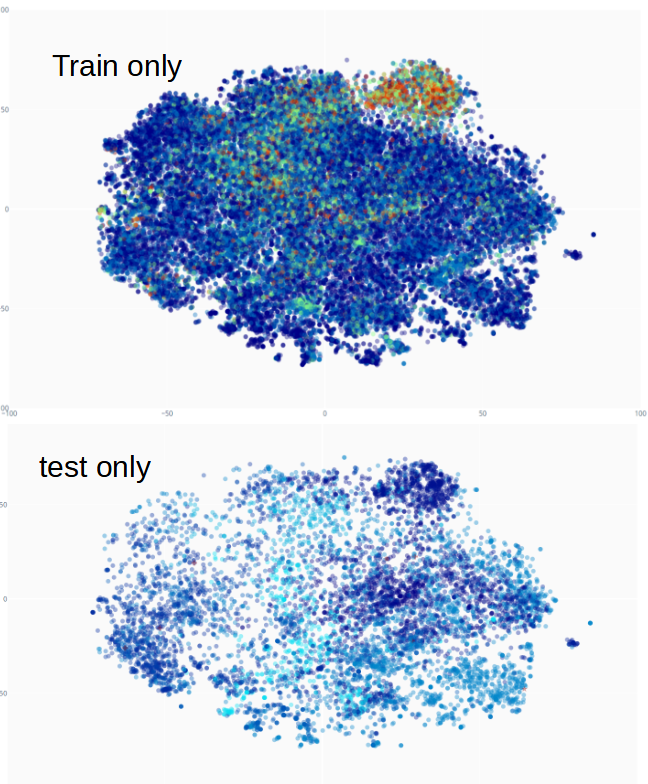
・trainは過去データ,testは最新データである.最新データはある程度人気トレンドに沿っているように見えなくもない(件数を揃えて比較した図を載せるべきだった).
その他手法を含め時系列特性を確認したところ,恋愛ものが流行しているようである,かつて流行していたファンタジーものは下火となっているようである,歴史推理ものの流行の兆しが見られなくもない.先行人気作が少ない新流行ジャンルのブックマーク度はどう予測すればよいのであろうか?


・genreごとに分布が全く異なる印象.あるジャンルにおいて人気のキーワードが他のジャンルでは不人気であることも.NLPではジャンル分けしたモデル作りも有効かと想定された.
・驚いたことに,(与えられたデータ上では)ほとんどハズレが無いジャンル,があるようだ.genre==101の多くを占めるいわゆる「悪役令嬢もの」がこれに該当する.今後はどうなるかわからないが.(データにはトレンドの隆盛情報はあまり含まれていないようであった.現状のトレンドを考慮しすぎるモデルは作れるが,将来に対する汎用性がないモデルとなるかもしれない.)
・その他,著者特性の確認など行ったが省略
結果
・正確な順位はぼかしますが,次の記事の順位と同等でした.金メダル下位~銀メダル上位です.
【AI Shift Advent Calendar 2021】Nishikaコンペ振り返り 小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~
https://www.ai-shift.co.jp/techblog/2246
解法
Common Settings
Types of networks
Model NLP: BERT classification
Model NLP2: tfidf/mbart/mt5/CLIP embeddings cluster vis vector
Model Table: CatBoost
Backbones
Model NLP: cl-tohoku/bert-base-japanese-char, finetuned
Model NLP2: self-distributed representation
DataSet
holdout
Model NLP: novel_type, title, writer, keyword, story and each prefix
Model NLP2: title, keyword, story
Model Table: All features + original features (keyword word2vec sum dimensionality reduction vector, lag, combination, aggregate, Target Encoding, etc)
keyword word2vec sum dimensionality reduction vector: キーワードを分散表現に変更しその要素の和を次元削減し特徴とした
Loss
Model NLP: weighted loss
Optimizer
Model NLP: *
Augmentation
non
The track of scores
single model
tutorial: LB 0.752
Model NLP: LB 0.777
Model Table(LightGBM): LB 0.726
Model Table(CatBoost): LB 0.718
add NLP result and NLP2 dimensionality reduction vector to Table model
Model Table: LB 0.685
add genre 101,401 only NLP results to Table model
Model Table: LB(private) 0.64*
(1st LB(private) 0.627)
振り返り
特徴
・主にSHAPにより特徴の評価を行った.
・スコアへの寄与が大きかった特徴,SHAPにおいて評価の大きかった特徴は次の通り
・・genre 101 only NLP result
・・userid_titlelength
・・Model NLP result
・・userid_isr15_isBL
・・userid
・・novel_type
・・・
うまくゆかなかった試行
・stacking
・tabnet: LB 0.9
・tfidfCNN: LB 1.3
・ヒューステリックな後処理
・分布から重みを計算したBERT weighted loss
・RoBERTa
・imblearn
・ControlBurn
・・・
コメント
・コンペ初参加で金メダル下位~銀メダル上位.まずまずの結果ではありました.
・前述した既存の知識が役に立ったか,と言われると?
・本コンペがNLPコンペであったのかと言われると?
・BERT単独である程度のスコアが得られており,BERTの結果をtableに組み込んだときに最も有効であったことを考慮すれば,NLPにtableの知識構造を導入するNLPコンペであったと言っても良いかもしれません.
・HuggingFace transformersのBERTをまともに使うのは初めてでしたが,簡単である上に拡張も可能であり非常に楽でした.(そろそろtensorflow1ベースの生BERTから切り替えようかな・・・)
・BERTにおいて,weight lossは必須でした.ただしそのweightは分類の分布比から計算した値が最適とはなりませんでした.正例が少ないところ負例は正例にある程度近く分布を揃えるとデータ不足と重複部分の相対的重要化により学習しきれないそこでバランスを考慮したnegative samplingっぽくなるようweightを設定した,と申しましょうか?
(多分固有名詞があるのだと思います →次の Distribution-balanced lossと近い考え方かもしれません
Balancing Methods for Multi-label Text Classification with Long-Tailed Class Distribution
https://arxiv.org/abs/2109.04712
Rocheか…製薬も色々やっているのですね.)
・細かい点を見分けることを優先しcharベースのBERTのみ用いましたが,セオリー通り,wordベースなどのBERTも組み合わせるべきだったでしょう.文章データをフルに入力できていませんでした.時間不足でした.初手としてはsubwordベースのBERTを用いておくべきだったかもしれません.
・genre==101専用のBERTとgenre==401専用のBERTを用いましたが,他のgenreについてはBERTモデルを作成しませんでした.この検証時にはすでに時間が足りず,ブックマーク度の分布が全体と大きく異なるgenreのみしか実施できませんでした,少々細かい部分にハマりすぎていた気がします.(とはいえ,モデルを無制限に増やす設計はよろしくはないでしょう.モデル内部で処理できるような設計が理想ではあるでしょう.とはいえ,モデルを分割したほうが説明可能性は高くできます.目的次第でしょうか.理解することが目的であるならば,モデルを分割してSHAPの結果を見つつ解析的に組み合わせ,その結果としてモデルが増えることは,許容できるでしょう.)
・genre==101専用のBERTを用いるなどgenre単位で検討してしまいましたが,genreのようなジャンル自体を求めるクラスタリングを行ったほうが,より柔軟なモデルとできたでしょう.(genre102の現実の恋愛は,異世界の恋愛と対局に出現するブックマーク度が低めのたぶんガチガチのリアルな恋愛と,中央付近に出現するブックマーク度が高めのたぶんある程度ファンタジーな恋愛に,分けられたでしょう.またgenre400番台のSFは,別の切り口で分類するのが適切かもしれないと思えました.)深層距離学習が使えたかもしれません.
・genre専用BERTではclassificationの結果そのものを特徴量(目的変数と同じ5次元)としました。genre専用とするとデータが不足するため低次元で扱う方針としたことに間違いはないとは思いますが、層の平均ベクトルなどを任意の次元に次元削減し特徴量とした場合にどうであったか検証しませんでした。SHAPを用いた際の理解しやすさを優先しておりまた時間が足りず試しませんでした。(総じて、後半になるまでBERTに期待していませんでした…) 回転させたほうが良かったかなと思わなくもないです.目的変数に寄与する独立した特徴はいくつあったでしょうね.
・ヒトが認知できる程度の単語相関など,いわゆる伝統的なテキストマイニングを用いた任意の特徴づくりを行いましたが,あまりスコアに影響があった感覚がありません.(後発作は有名作のキーワードなどを分析しそれをもとにあらすじなどを作成していると伺わせる記事を見ました.伝統的なテキストマイニングにより得られる程度の情報は,先行作を分析し作成される近年の小説?においては,予測の足しとならなくなっているのかもしれません.BERTなどある程度ブラックボックスであるモデルを用いて初めて,残された情報を探ることが可能となる状況にあるのかもしれません.そのようないたちごっこなのかもしれません.)
・読みやすさに関する文献などを読み,それを考慮した任意の特徴づくり,例えば文末から主語までの単語割合など,を行いましたが,スコアに影響があった感覚がありません.本文ではなくあらすじにおける適用では限界があったのかもしれません.
・テーブルデータの取り扱いにつき,学び直しができました.定期的に手を動かしていないとだめですね.
・lag特徴が予想より重要と評価されませんでした.トレンドはほとんど無視しても良かったのかもしれません.StratifiedKFoldを使うべきだったかもしれません.単に,シンプル過ぎる手法しか用いなかったため,トレンド情報を抽出するに充分な特徴とできていなかったのかもしれません.
・テーブルで用いた特徴をBERTに押し込む手法もありましたが,ほぼ試していません.トレンドがそれほど重要でなかったのならば試してみても面白かったかもしれません.
・ensembleが有効と理解してはいたのですが,仮説実証と後の学びのしやすさを優先し,行いませんでした.また大きくスコアに影響してもいませんでした.
・EDA重視,特徴生成最重視,モデル検討後回し,のスケジューリングをしました.
・EDAにかける時間は,適当だったと思います.もう少しポイントを絞るべきではありました.
・特徴生成は多々行えましたが,各特徴の有効性を細かく検証するシステムを構築しきれませんでした.例えばマイナス効果のある特徴を除去しきれなかったなど問題が残っているかもしれません.
・モデル検討を後回しとした判断は間違っていなかったとは思いますが,最後に回したモデル検討に予想以上の時間を取られました.モデル検討において新たな仮説を思いつくこともありましたので,モデル検討を完全に後回しとするのではなく,モデル検討まで含めたコンパクトなサイクルを作成し,回すべきだったかと思います.
・ある仮説を徹底的に検証する場合と、課題を発見しつつ数多くの仮説を検証してゆく場合では、スケジュール管理の仕方が全く異なるな、と再認識しました。後者ではシステム作りが非常に重要ですね。
・ブックマーク度の分布はなだらかであったのでわかりませんが,予測対象となるブックマーク度をbinningし回帰的な問題に置換えたほうが良い結果となったかもしれません.
・いくらか未実施の仮説を残したまま期限切れとなってしまいました.
やり残した後悔はありますが,やり残しを実行しても金メダル上位に届いたとは思えません.
振り返り会に参加し,また他参加者の振り返りを見て,再検証することにより,参加時以上の学びがありそうです.
【Nishikaコンペ振り返り会】 小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?
https://www.youtube.com/watch?v=IcDHebW-q3E
・振り返り会前
・上位陣は「2020年以降に限定した?BERTモデルを作成し」その予測値をcatboostに加えたとのこと?.
データ全体のトレンド予測を切り捨てた?ほうが良かったようです.確かにデータにトレンド隆盛に関する情報は殆ど無いようでした.異常値がありそうな年を捨てるために2010年?より前を切り捨てるなどは試していましたが,2020年以降のみとするような度胸はありませんでした.「データ全体に渡る長期的なトレンド」を予測するモデルとしなければという思い込みを破棄するような発想が自分には足りないと理解しました.短期トレンドにしか意味がないと考えてデータを切り捨てても見るべきでした.
・コンペの記載上の目的はシンプルな予測(トレンドに依存しない普遍性?)であるようであるところ,testが最新データであることからトレンド予測も目的であるように理解してしまいました.目的の設定自体を間違えてしまったことが敗因のひとつなのでしょう.(示唆を得ることも目的であったようです.結果としては,ジャンルと最新トレンドの影響が大きくこれら無視した普遍性は得られない,との示唆が得られたことになるのかもしれません.)
・実務においては、顧客から「目的」が示されその「評価指標」を作るのは技術者の役割である場合、評価がいくら良くても目的が達成されていないなら意味がないところです。技術者が評価指標を作るにおいて、「ヒアリング」により顧客が予め提示していない「隠れた目的まで聞き出し」また理解を正しくし、評価指標を作るのが通常でしょう。それができない?コンペには独自の難しさがあるなとも感じました。
・振り返り会
・主催者
・・storyに記載されていた書籍化などの単語はリークとして一部除去済みとのこと.
・・テキスト単体では微妙な結果であったため構造化データも合わせて提供したとのこと.
・3位
・・ゲーム会社?.振り返りHPあり
・・解法:LghtGBMで特徴量選択(特徴量追加の後importance順500件選択),GBDT,NNアンサンブル.後処理はn乗.
・・特徴:useridのtarget encoding.複数のペンネームを使用しているか*この特徴は作成していなかった
・・モデル:HuggingFaceモデルのうちどれを用いるかについて,HuggingFaceのHosted interface API使用し選定*面白い
・・テキストと非テキストの融合:テキストのGBDTへの融合は優秀な記事あり.非テキストのBERTへの融合はまだ確立していない*埋め込みを変異ベクトルで補正?*あえて濁しているとのこと.3月の言語処理学会NLP2022で発表とのこと(楽しみにしています! →NLP2022 RINA:マルチモーダル情報を利用したキャラクターの感情推定 )
・2位
・・独学
・・改善プロセス:トップトークン特徴量(ブックマーク度1以上のトップ単語.ブックマーク度が大きい小説群ほど多くの単語が抽出される結果となっているとのこと.)LightGBM CV -0.02,BERT whole,v2特徴量追加(単独CV 0.9-1.1),スパンモデル特徴1,2年追加(単独CV 0.64ほど),optuna LightGBM,CatBoostをメインに CV -0.025,ミス修正,スパンモデルLGBM1,2年追加.
・・アンサンブルはしていない.モデル統合はしているので.
・1位
・・バイオ系学生.遺伝子解析に?transformer使ったり?
・・モデル:BERT,CatBoost.テキストのみCV 0.814 LB 0.79,テキスト含む LB 0.70.?
・・工夫:学習データ作成.データを3組に分けた.1組目(~2020年)は学習に使わず.valは202106-のhold.CV,LBの乖離は少ない.
・・kaggle algernoneのノートブックを参照.*こちら? https://www.kaggle.com/chamecall/competitions https://www.kaggle.com/c/commonlitreadabilityprize
・・BERT出力にattention head
・・BERT学習が難しい.lossが振動.*同感
・・工夫:学習時の工夫.BERT MLMのpretrain,学習率を層ごとに変えた.
・・工夫:アンサンブル.ブックマーク度5段階を2段階にしてRMSE,期待値を特徴量など.
・・テキストは扱いが難しかったがスコアアップに大きく貢献.
・・zoteroで実験管理(文献管理)
・ほか
https://nishika.connpass.com/event/236291/presentation/
・反省
・詳細を詰めることでもう少しなんとかなった気がします.
・BERTモデルを複数使用しなかった点は大きな問題であったでしょう.
・ブックマーク度ごとの上位単語も重要特徴とできたようです.少々意外です.前半での工夫であったようなので,総合的にどれほど重要であったのかよく分からなくもありました.(今にして思えば、この特徴量は、既存のgenre分類では足りなかったジャンル分類を情報源として与える効果があったのかもしれません.単語自体が直接予測に寄与するのではなく、間接的に寄与していたのかもしれません.tfidf/mbart/mt5/CLIP embeddings cluster visから得られていた独自ジャンル情報を加えるだけでもかなり有効だったかもしれません.)
・時系列特徴も重要とできた様子でした.作り込みが足りなかったようです.
・工夫は様々?のようです.3位までのモデルを統合し,統合した上での各特徴の重要度を評価してみたいと感じました・・・
・今思えばフーリエ変換をしてラグ周期の参考とすべきだったか。
他参加者の振り返り記事
小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~ 3rd place solution & 振り返り
https://qiita.com/z-lai/items/4b563c4c78bf25427120#_reference-44ae427a1102c8ea2fe3
【AI Shift Advent Calendar 2021】Nishikaコンペ振り返り 小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~
https://www.ai-shift.co.jp/techblog/2246
Nishika 小説家になろう ブクマ数予測コンペ振り返り
https://note.com/baukmilze/n/neea25b8bd0a0
なろう小説のブクマ数予測コンペに参加した話
https://qiita.com/pndnism/items/905523333984516f887d
Nishikaブクマ予測コンペの最終結果
https://ameblo.jp/toru59er/entry-12712943319.html
・・・
その他
・EDA中に小説家になろうサイトの小説検索機能を用い検索してみたのですが,なかなか意中の小説が見つかりませんでした.(キーワード検索では結果に有名作品の追従作が混ざり見分けがたい印象でした.今回のコンペにおいてuseridが重要特徴でしたが,これは著者というブランドに対する将来への期待を示しているとともに,検索者が著者情報を用いざるを得ない,現行の検索システムの限界も示しているのかもしれません.昨今は著者を重視せず中身を重視する顧客が増えていると聞きます.もしそうなら,今回のコンペで著者が重要特徴となったことは,課題を示しているのかもしれません.)
例えば以下のような,未知軸を考慮したグラフィカルな検索システムも採用したのなら,隠れた面白い作品含むより意中の小説を見つけやすくなる,と思うところでもありました.

*しかしぶっ飛んだ設定の小説があるな・・・
・【自然言語処理】Kaggleコンペで利用されている文書分類のtips
https://tma15.github.io/blog/2020/05/03/%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E5%87%A6%E7%90%86kaggle%E3%82%B3%E3%83%B3%E3%83%9A%E3%81%A7%E5%88%A9%E7%94%A8%E3%81%95%E3%82%8C%E3%81%A6%E3%81%84%E3%82%8B%E6%96%87%E6%9B%B8%E5%88%86%E9%A1%9E%E3%81%AEtips/
・【自然言語処理】 あなたのBERTに対するfine-tuningはなぜ失敗するのか 【論文紹介】
https://tma15.github.io/blog/2020/10/03/%E8%87%AA%E7%84%B6%E8%A8%80%E8%AA%9E%E5%87%A6%E7%90%86-%E3%81%82%E3%81%AA%E3%81%9F%E3%81%AEbert%E3%81%AB%E5%AF%BE%E3%81%99%E3%82%8Bfine-tuning%E3%81%AF%E3%81%AA%E3%81%9C%E5%A4%B1%E6%95%97%E3%81%99%E3%82%8B%E3%81%AE%E3%81%8B-%E8%AB%96%E6%96%87%E7%B4%B9%E4%BB%8B/
・・「単純だけど強力なfine-tuningのコツ
学習時初期における勾配消失をさけるために、バイアス補正つきのoptimizationと、小さな学習率を使う
学習のiteration回数を増やし、early stoppingを使いつつも学習時の損失を小さくする」
・BERTのfine-tuning不安定性はどのように解決できるか?
https://ai-scholar.tech/articles/bert/bert-fine-tuning
・・CoLAはfine-tuningが特に安定していること、RTEは特に不安定であることが過去の研究でわかっています。
・・fine-tuningの不安定性は訓練データサイズの不足というより、むしろイテレーション回数の不足に起因していると考えることが出来ます。
・・バイアス補正あり、学習率を2e-5に設定したADAMを利用
・On Stability of Few-Sample Transformer Fine-Tuning
https://www.kaggle.com/code/rhtsingh/on-stability-of-few-sample-transformer-fine-tuning/notebook
・・Debiasing Omission In BertADAM
・・Re-Initializing Transformer Layers
・・Utilizing Intermediate Layers
・・Layer-wise Learning Rate Decay (LLRD)
・・Mixout Regularization
・・Pre-trained Weight Decay
・・Stochastic Weight Averaging
・Kaggleで学んだBERTをfine-tuningする際のTips②〜精度改善編〜
https://www.ai-shift.co.jp/techblog/2145
・・Custom Header,各層に異なった学習率を適用,重みの初期化
・Utilizing Transformer Representations Efficiently
https://www.kaggle.com/code/rhtsingh/utilizing-transformer-representations-efficiently/notebook
・・Pooler Output
・・Last Hidden State Output
CLS Embeddings Mean Pooling Max Pooling Mean + Max Pooling Conv1D Pooling
・・Hidden Layers Output
Layerwise CLS Embeddings Concatenate Pooling Weighted Layer Pooling LSTM / GRU Pooling Attention ・・Pooling WKPooling
・BERTの精度を向上させる手法10選
https://qiita.com/YuiKasuga/items/343309257da1798c1b63
・私のブックマーク:不均衡データ分類
https://www.jstage.jst.go.jp/article/jjsai/37/3/37_376/_article/-char/ja/
・【ML Tech RPT. 】第4回 不均衡データ学習 (Learning from Imbalanced Data) を学ぶ(1)~
https://buildersbox.corp-sansan.com/entry/2019/03/05/110000
https://buildersbox.corp-sansan.com/entry/2019/04/03/110000
https://buildersbox.corp-sansan.com/entry/2019/05/03/110000
・不均衡データを損失関数で攻略してみる
https://qiita.com/tancoro/items/c58cbb33ee1b5971ee3b
・Plankton classification on imbalanced large scale database via convolutional neural networks with transfer learning
https://ieeexplore.ieee.org/document/7533053
不均衡データのtwo-phase training
・質とスピード
https://speakerdeck.com/twada/quality-and-speed-2022-spring-edition
スピードと品質はトレードオフではない。知識整理や事前知識がありテスト自動化していればスピードが速くとも内部品質は落ちない?。スピードを上げることにより犠牲になるものは(それを得るための)全体に対する教育?
・Stock predictions with state-of-the-art Transformer and Time Embeddings
https://towardsdatascience.com/stock-predictions-with-state-of-the-art-transformer-and-time-embeddings-3a4485237de6
時系列
・時系列解析の基礎https://www.kaggle.com/code/anguillajaponica/time-series-basics/notebook
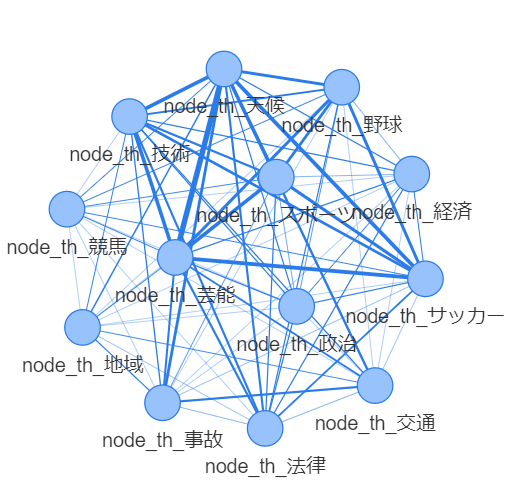
ベクトル空間を任意の要素からなるネットワークに変換し,よもやま

ノードの大きさはブックマーク度の中央値.エッジの太さは正規化した件数.赤ノードは中心.
次数中心性: ファンタジー コメディ 恋愛 まったり
固有ベクトル中心性: ファンタジー コメディ 恋愛 まったり
媒介中心性: ファンタジー コメディ 恋愛 まったり
ページランク: まったり
情報中心性: ファンタジー コメディ 恋愛
中心性とブックマーク度の乖離.価値の高さと中心性に直接の相関はない.多分,「中心は価値の媒介を適切にしている」と考えると良いのだろう.テキストにおいても.
もう少し視座を上げてみると
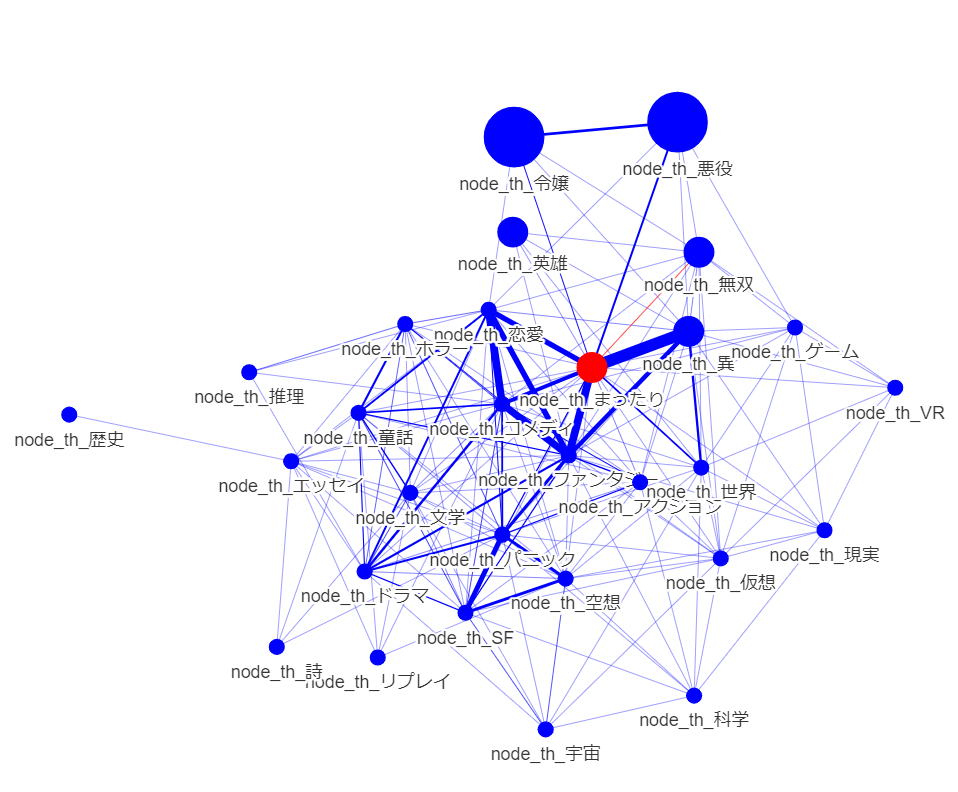
多分,「人気のもと」をコアとして,共有認識である「中心性の高い要素」を加えつつ,ブランドとなる「独自性」をもたせると,流行りに乗りつつある程度新しくかつ安心して楽しんでもらえる,「よい小説」になるのだろう.
例えば,
人気のもとは「悪役令嬢」,
人気のもとの近傍にあり中心性の高い要素として「まったり」であるところに,
独自性として直接エッジのつながっていない「ホラー」を選択して,
「悪役令嬢のまったりホラー物」など良さそうかもしれない.
これを下位概念化して,「ゾンビとなった悪役令嬢の日常」 などどうだろうか?
(出願すべき特許の解析にも同じ手法が使えそう)
*創造的アイディアを自分の頭から抽出するために、「任意概念レベルの知識ネットワークを眺める」、ってのはありなんだろうなと感じます。CLIPなどで適切な隙間を埋めるなどすれば、創造も計算でできそうでしょうかね。
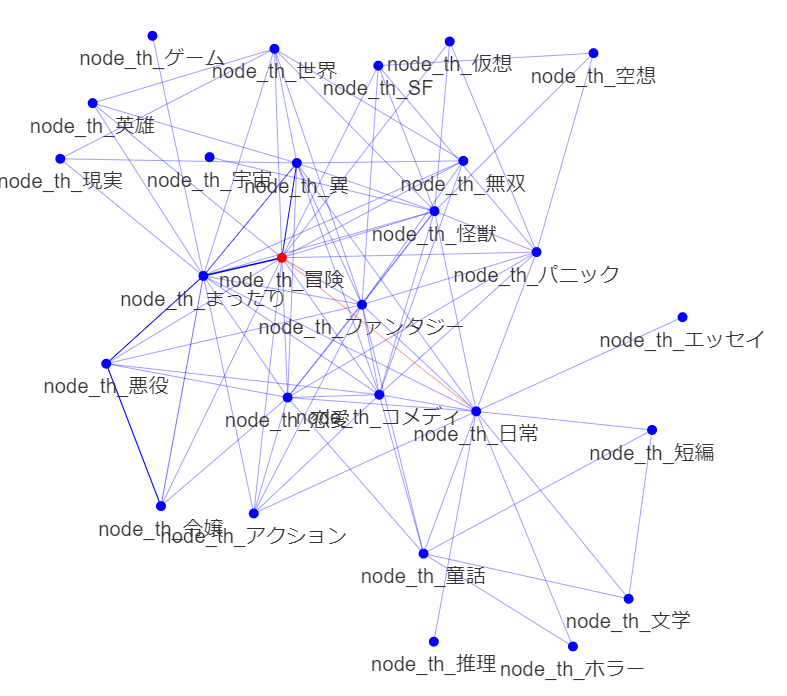
・ブックマーク度ごとの違い
fav_novel_cnt_bin == 0
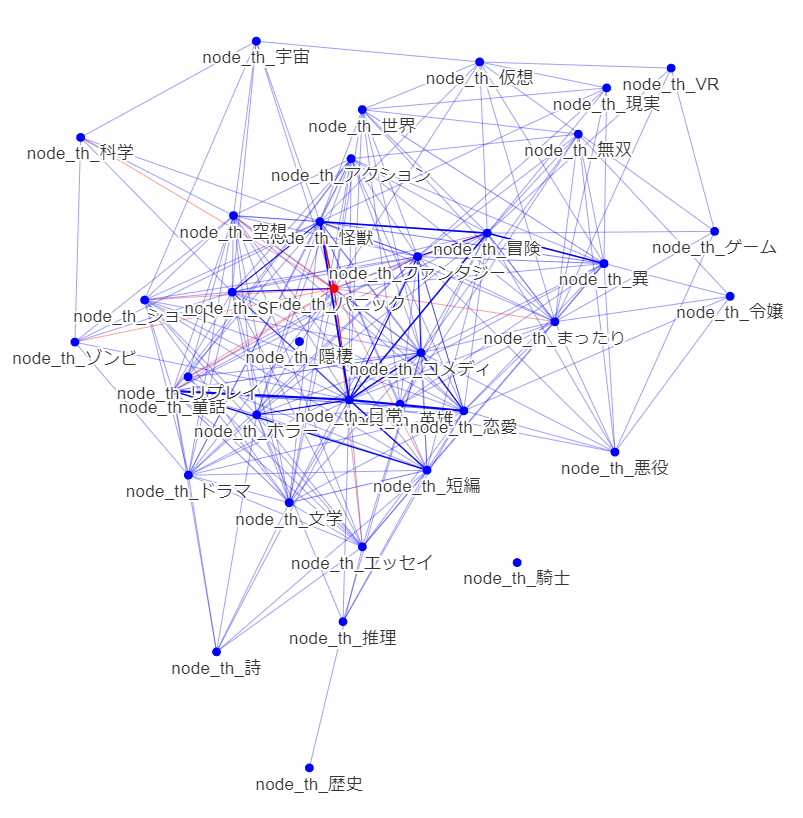
fav_novel_cnt_bin == 1
fav_novel_cnt_bin == 2
fav_novel_cnt_bin == 3
fav_novel_cnt_bin == 4
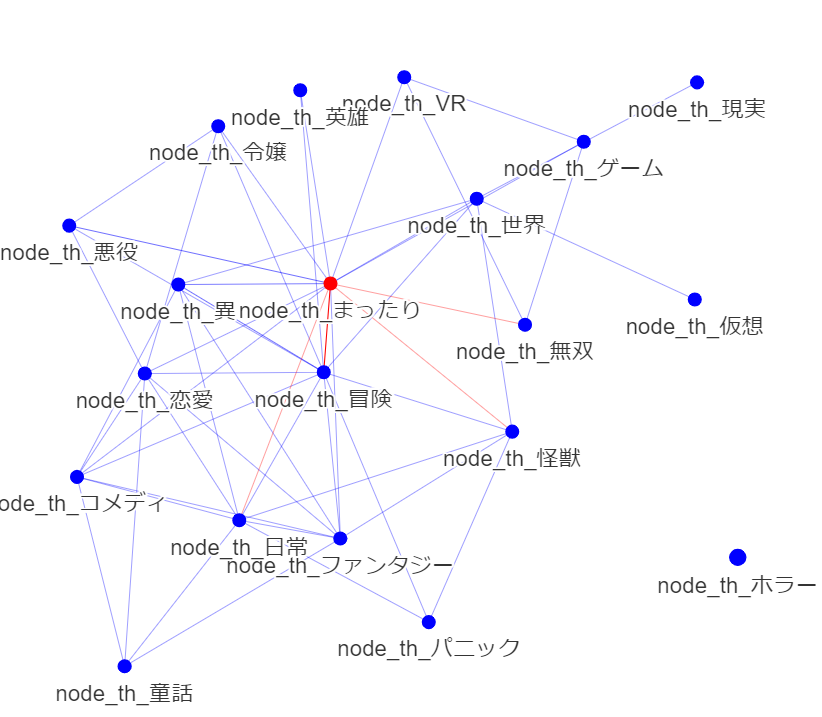
中心が結構違いますかね.中心性がずれていると今一つ人気とならないのかもしれません.
概念からみても,短編・ショート小説はブックマークされににくいのでしょうか.
パニックは,中心にあるときは筋が悪いがフレーバーとしては良し,ということでしょうか?
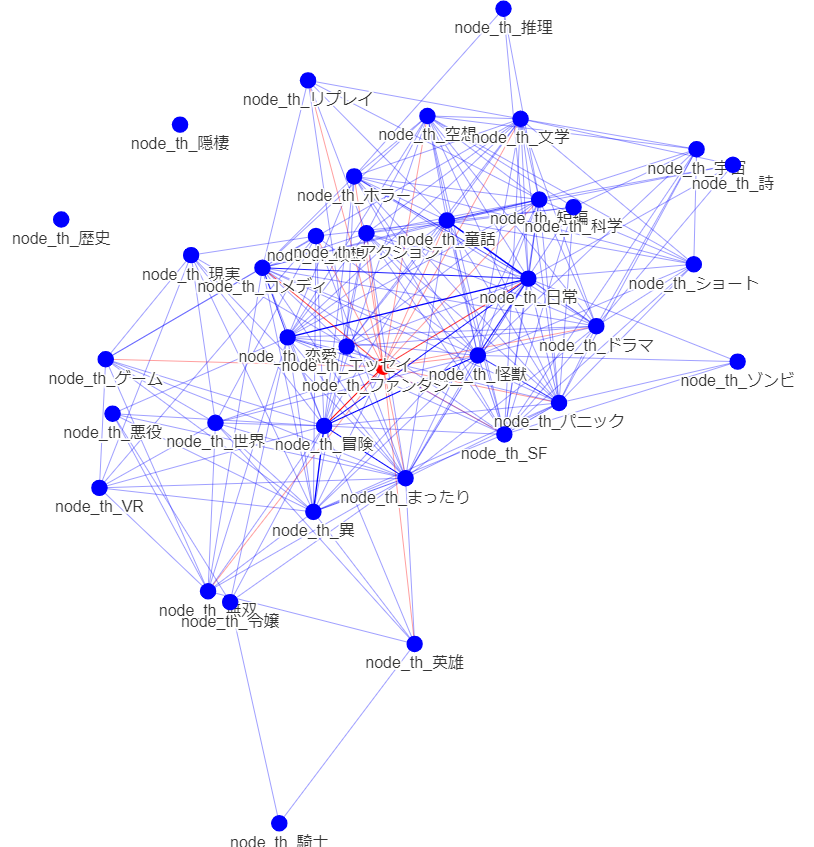
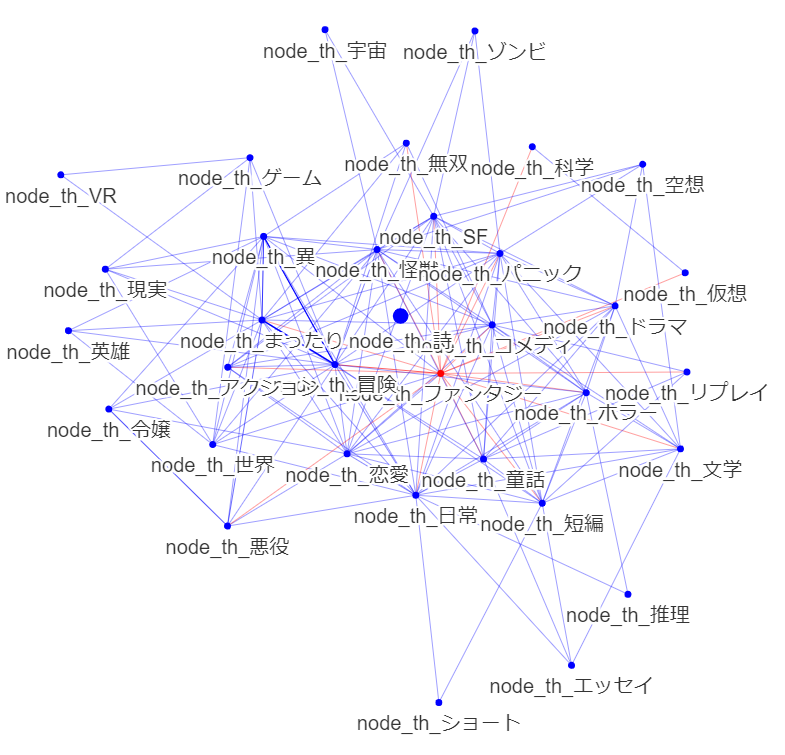
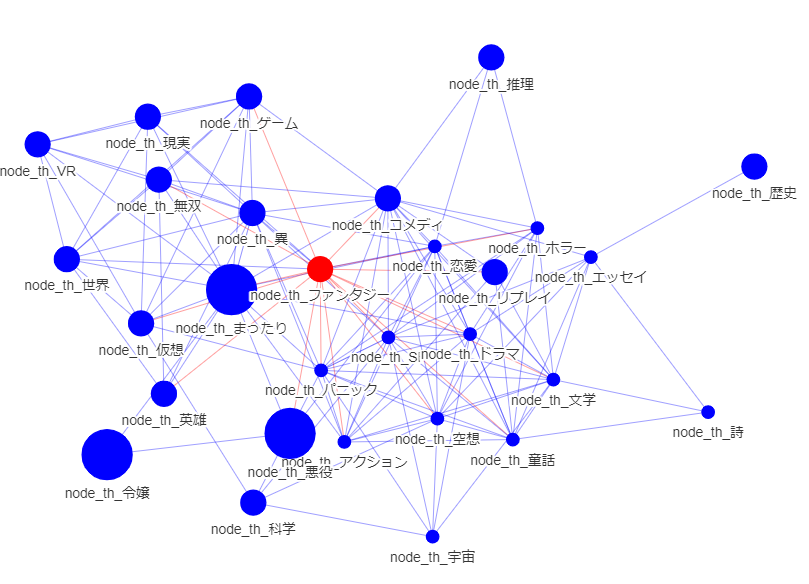
・全体 時系列
公開20200101以前
公開20200101以降
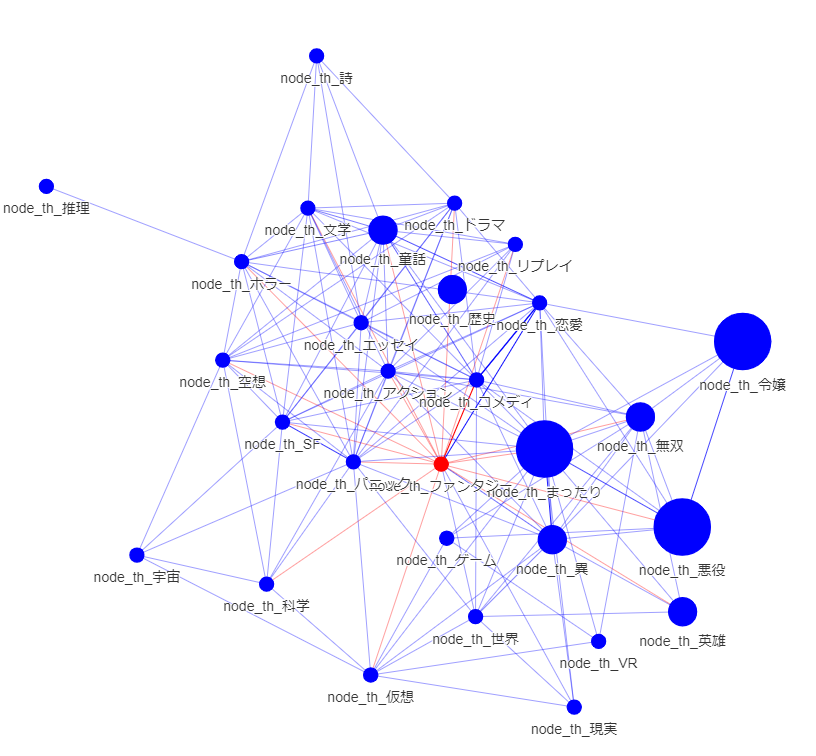
悪役令嬢からの接続がふえています.ノード数は増大きく変化していないようです.悪役令嬢の多様化が見られるといってよいでしょう.
人気分野からファンタジー色が薄れている傾向があるでしょうか?
童話の存在が目立ってきています.
総じて,中心が変化するという,大きな変化が起きているようにも見えます.直近のデータでのみ学習する選択は正解だったでしょう.(ここまでやっておけば気づいたのに・・・EDA大事です.)
まったり傾向は変化なしでしょうか?
まったりはより細分化できる気がします。グルメなど一定の分野を締めているでしょう。概念ノードを足してみるべきでしょう。ミクロ分析もしてみるべきでしょう
ホラーは変化なしでしょうか?
今後はどうでしょう? ニュースやSNSなど比較的迅速な情報源において現れているでしょうか・・・
*目視では限界があるな・・・何らかの評価指数が欲しい.
*BERTとの整合性もチェックしておきたい
*視座を変えた複数のネットワークをからGNNを使って学習し特徴を作っても一定の価値があったかもしれない
・ TabTransformer: Tabular Data Modeling Using Contextual Embeddings
https://arxiv.org/abs/2012.06678v1
TableDataの学習/推論に適用した論文。既存のモデルより優れた性能を発揮できるとのこと。
コンペ参加記録2: 特許庁[Nishika] AI×商標:イメージサーチコンペティション(類似商標画像の検出)
https://www.nishika.com/competitions/22/summary
仮説が空っぽになる程度に試行してもLBが上がらず画像系ほぼ初体験やし基礎からかなわねえやと早々に諦めたコンペ.
振り返り会に参加.
https://t.co/fUDAvdqNWt
自分も行っていた工夫が多く紹介されあれ?と.確認してみたところ,提出ファイル作成用コードにバグがありましたorz
で,銅メダル.複雑な気分です.
実施
・データのクラスタリングによる再グループ化と目的変数の変更
・正方形padding
・weak augmentationとstrong augmentation
・非対称クロップ
・epochと連動したaugmentationの変更
・学習率の調整
・正解ラベル画像以上に類似した画像がモデルにより提示され正解ラベル画像がrecall@20から漏れてしまう問題あり.正解ラベルを設定したであろう審査官が認識し正解としたであろう画像に置き換えるために行う,モデル出力の一部差し替え後処理(基本的には,複数のほぼ同じ類似画像が存在しており,その中からどの画像を選択し正答としても良いところ,審査官が選んだ画像しか正答とされない問題,であったかと思います.なお,中には,審査官が認識した要部が画像の類否以上に重要でありそちらを優先したラベルもあったかもしれませんが,サンプリングした限りでは,そのように認識できる例を見つけられませんでした.なお,3位までに審査官の認識に踏み込んだ解法は無かったように認識しています.)
・pseudo label
・ConViT
・OCR
・icrawler
・CLIPによる商標ロゴ画像からのテーマ単語抽出(CLIPにはロゴの特徴を商標分類程度に表現するほどの細かい言語知識は含まれていませんでした.とはいえもう少し類型化(丸形状との近さや四角形状との近さなど)すれば役に立ったかとも思えています.
https://qiita.com/kzuzuo/items/e35e0c0535f0d32b135e )
未実施
・ConvNeXt(外形に強いとされるViT系を優先しテキスチャに強いとされるCNN系は後回しとしていました.今思えば,画像の一部抽出タスクに近いのでCNN系をまず採用しウインドウサイズを検討するが王道であったかと感じています.ViT系もブロックで認識するから良いかとも思っていたのですが長距離のattentionはどちらかといえば邪魔だろうと考えてみるべきでした.また画像系については自然言語処理において参考となる程度しか情報収集しておらずConvNeXtを知リませんでした.)
Transformer(ViT)系より良いConvだけのネットワーク出たよ(画像認識向け)
https://qiita.com/TeamN/items/edee1b3803a1d77fc252
・上記後処理問題解決のための,アノテーションやり直し(時間的に不可)
・省メモリ,高速化の工夫(必要な段階まで至らなかった)
・その他,Lossの最適化など,モデル内部構造に踏み込んだ工夫.ここがクリティカル?(完全に自分の知識不足です.multisimilarity loss>contrastive loss,multisimilarity loss>contrastive loss with crossbatchmemory,elasticface-cos+>arcfaceほか.contrastive lossはうまく学習できないことも?)
試してみたかったこと
・infographic VQAの応用.個人的には,CLIPはより概念的,infographic VQAはより具体的という切り分け.
文書画像に対する質問応答技術の最新動向/ Recent Trends in Document Visual Question Answering
https://speakerdeck.com/ryotatanaka/recent-trends-in-document-visual-question-answering
コメント
・アイディア自体に大差はなく,詰め方の精度と細かな引き出しの多さが異なるのであろうなと感じました.
・結局、どの程度のaugmentationが適切であったのかわかりませんでした。やるほど検索施行した結果が怪しいものになってしまい…独自クラスを作り試し続けた自分を褒めては上げたい(次回使おう)
・自分が仮説も建てられなかったドメイン知識を利用した解法があるか,と期待していたのですが,特に見受けられませんでした.残念です.
なお,上記に述べた審査官の要部認定について,個人的には,学習データが非要部を表現するに十分な需要者の認識を示す母集団であることを前提としますが,ロゴの非要部は画像系モデルの学習中に低評価となりやすく,結果として画像系モデルは審査官の要部認定と同じような計算をすることになっているのかな,なのでその点に付きドメイン知識に基づく工夫は不要だったのかな,とも思えていますがどうなんでしょうか.(ロゴ商標はほぼ確実に商標登録出願されておりデータは現実の情報をほぼ含むと仮定するとして、現実の分布とデータの分布は複数出願や関連出願の影響を受けますので異なり、審査官の要部認定に近づけるには、同一出願人の関連する商標を一つにまとめるなど分布調整が必要となる、と言えるでしょう.分布調整はすべての解法で行われたと思いますが、目的に対しどこまで調整できたといえるでしょうか….
出願人のデータが与えられていればより良いモデルが作れただろう、とも思えています.コンペの成果を実用とするに、出題内容により限界が決まってしまっておりそのためあまり良い実用にならない、ということもよく聞くところですが、出願人等のデータがあったらどれだけ違ったでしょうか.
なお、現実の分布って入手できるんですかね? あえて言えばCLIPから抽出できるかも…)
・・Data-Centric AI- andrew ng
https://youtu.be/Yqj7Kyjznh4
「
1. make the labels consistent
2. use multiple labelers to spot inconsisitencies
3. clarify labeling instructions by tracking down ambiguous examples
4. toss out noisy examples. more data is not always better!
5. use error analysis to focus on subset of data to improve
」
あいまいさ確認と排除.ラベル付方法を複数とし矛盾排除.アノテーション指示の統一.ノイズの多い例を捨てる.エラー分析を使って、改善すべきデータのサブセットに焦点を当てる.
現実の多様性?統計的前処理?.弱分類機などで難しい問題を分けておくなどはよくやる手法.エラー分析→モデル改善サイクルよりもエラー分析→データ改善サイクルを主体とする? データに目的の情報が含まれるか,そしてどう取り出すか,どう入力分布を目的の分布に調整するか?
・商標ロゴ検索においてドメイン知識を利用せずとも7割以上正答できるものなのですね.ロゴの要部を認定した上でのロゴからの一部構造抽出など必要と考えていましたので少々意外でした.まあこのあたりの印象はデータセットの分布が実データの分布と等しいかどうかにも依存しますからあまり意味がないですが.
・画像分割などルールベースの画像商標検索ツールを持つベンダーがいくらかあるのですが,参加しなかったのでしょうか.参加し勝てなかったのか参加するまでもないとしたのか気になるところです.(これらツールには商標出願時お世話になりました.今回のコンペで作成したモデルと比較してもおきますデータ足んないですけど.)
・ColabとGoogle Driveを使用しました.データは重いわnotebookのサイズは大きくなりすぎるわ試験を繰り返すごとにリソース不足でヒヤヒヤしながら施行をしていました.画像系のコンペはまず環境づくりがキツイなと思うところでした.ローカルに環境作ると時間制限もなく自動化もできやはり便利そうですねぇ.
・1st
特許庁主催のAIコンペで1位、ヤフーの画像検索技術を使った優勝解法紹介
https://techblog.yahoo.co.jp/entry/2022061330306280/
・・「※ デモで確認する限りは、後処理を実施しないほうが、見た目としては自然な検索結果になります。」
そうですよね…実装では後処理省くのかな
・2ndの方の解法など.
TTDの方ですね.近所で務められており自分はトレイルランニングなどしていましたのでどこかですれ違っていたかもしれません.
・・https://github.com/anyai-28/nishika_jpo_2nd_solution
・・https://github.com/TTDC-keisoku/trademark-image-retrieval-sample-code
・・Facebook AI主催の画像のコピー検知のコンペで入賞した際の取り組み
https://engineering.dena.com/blog/2021/12/fb-isc-1st/
「距離学習には embedding lossとclassification loss の2つのタイプがあり、 contrastive loss や triplet loss はembedding lossに、 CosFace , ArcFace はclassification lossに分類されます。最近の類似画像検索に関連するコンペだと、精度の高さから後者のclassification lossが用いられることが多いようです。
ただ、本コンペの場合はそもそもクラスの概念が無く、クラス分類を発展させた手法であるclassfication lossの適用は難しいと考えられます。一方で、embedding lossは正例・負例のペアさえあればクラスが存在しなくても学習可能となっています。そこで、自分はembedding lossの一種であるcontrastive lossを用いることにしました。
余談ですが、本コンペのような場合でも、画像1枚を1つのクラスとして割り振ることで無理やりclassification lossを適用することもできます。ただ、学習データの数に比例してクラス数が増えるためメモリ消費量が爆発する上に、自分が実験した限りでは精度的にもembedding lossと比較して劣るようでした。
ちなみに、lossについては色々と試しはしてみたのですが、contrastive lossが一番精度が良く学習も安定している印象でした。こちらの 論文 やこちらの 論文 でも報告されているように、contrastive lossはシンプルと言えど強力なようです。
Contrastive lossは単体でも充分強力なのですが、効率良く学習させるためには大きなバッチサイズが要求されるという側面があります。距離学習では、「似てるけど違う」ような難しいペアをいかにモデルに学習させるかが重要だからです。とはいえ現実的にはメモリの制約からバッチサイズをそこまで大きくできません。
そこで、 cross-batch memory と呼ばれる手法をcontrastive lossに組み合わせることにしました。」
・・AugLyを少し試してみた
https://qiita.com/sumita_v09/items/7df3d794b313579f6980
・ほか
https://nishika.connpass.com/event/241285/presentation/
※全国医療AIコンテスト2022
https://www.kaggle.com/c/ai-medical-contest-2022/overview
胸部レントゲン写真から肺炎かどうかを判定する画像処理タスクと商標ロゴ画像検索タスクとで解法に違いがあるか参考。
ラベルありデータ数が少ない&事前学習禁止とのこと.参考とならないかもしれない.
・・2nd
https://t.co/FTIGBSM845
・・5th place solution
https://www.kaggle.com/c/ai-medical-contest-2022/discussion/314120
・PetFinder.my - Pawpularity Contest
Predict the popularity of shelter pet photos
避難所のペットの写真の人気を予測する
・・1st Place - Winning Solution - Full Writeup
https://www.kaggle.com/c/petfinder-pawpularity-score/discussion/301686
CLIPの利用
CLIPの文章ベクトル,内在する各単語の重さはどう表現されているのかな.解像度変換するには共通する画像平面に落とす必要があると思っていたが,単に平均し取り出し直せば解像度変換できるのかも.…実装によって後進される重みが異なっていたような
・仮説管理
仮説と検証結果はpptファイルに記載し管理してきたが,コンペにおいて生成される仮説は非常に多く,また優先順位も頻繁に変わるため,単なるテキストやpptでは管理し難い.
今後はtrelloを使ってみる.
trello
https://trello.com/
・深層距離学習(Deep metric learning)を理解する
https://yaakublog.com/deep_metric_learning
コンペ参加記録3: Nishika: Fake News detection
https://www.nishika.com/competitions/27/summary#description
・目的:「本コンペでは、虚偽報道の中でもフェイクニュースに焦点を当てて、言語生成モデルにより生成したフェイクニュースと、実際のニュースとを判別するモデルの開発をテーマとします。」
・https://huggingface.co/rinna/japanese-gpt-1b で生成されたフェイクニュースの検出.
事実の真偽を問うというよりも,文体の自然さを問うコンペでしょう.
・簡単にAccuracy=0.98以上達成可能です.
簡単なタスクにおいていかに評価を詰めるか,に関するコンペと認識しました.
・Data-Centric AIの練習と設定して取り組んでみます.基本のBERTのみでどこまでできるか.
・アンサンブルは禁じ手としてみます.
・文章生成モデルにおいて使用するDiscriminatorをどう作るべきか、とも設定し取り組んでみます.
https://qiita.com/kzuzuo/items/1f86f8a1e430447a6e22
初期EDA
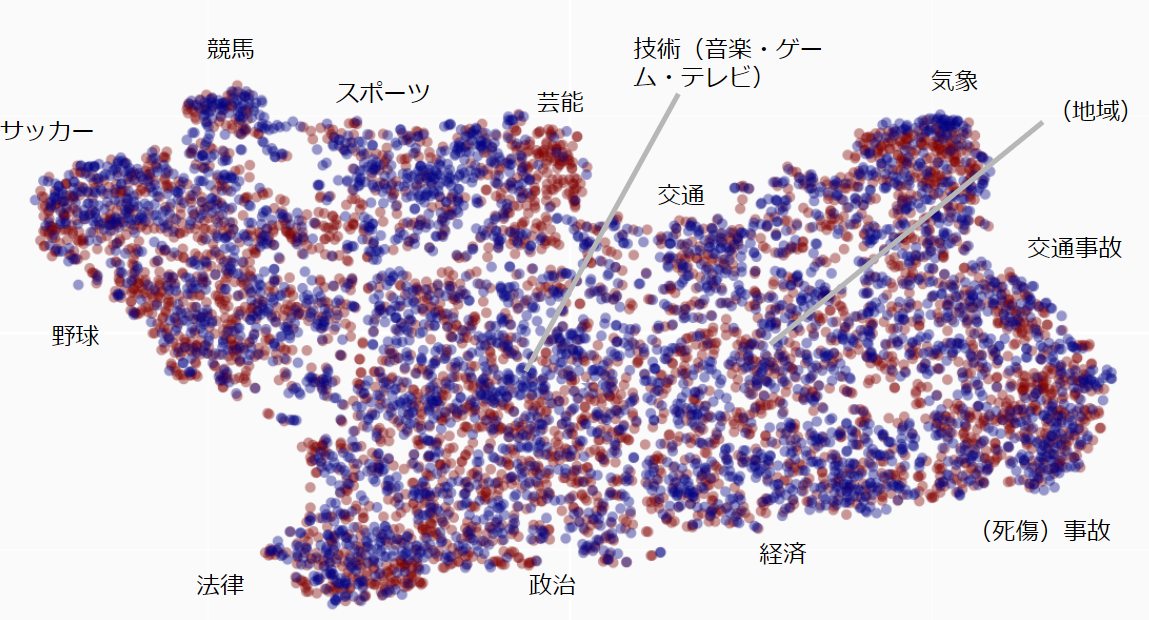
・tfidf/mbart/mt5/CLIP on embeddings cluster visでは,真偽に差は見られません.語順や文体を考慮しないアルゴリズム,あえて言えばゴミを捨てる要約のアルゴリズム,であるからでしょう.
・青丸が真,赤丸が偽です.不自然なほど一様ですね.元のニュースと生成ニュースは1対1の関係にあるのかもしれません.生成ニュースに元のニュースの一部が組み込まれているかもしれません.ラベルは,生成したかどうかで付与されており,人間が認識して付与しているのではないのかもしれません.前者であれば,ミスラベルは無いでしょう.(以後略)
*相対位置について.野球が政治に近くサッカーは政治と遠い点になるほどと思いつつ,競馬がスポーツ系の中では一番政治から離れている点について意外に思うとともに,競馬ファンは純粋なのか賭け事と政治はあえて離れようとしているのか,とも面白く思えるところでした.コンペとは関係ないですが.
*概念化について.気象との近さは不確実性を示す,とまで言えれば面白いのですがね(経済>政治>法律,競馬>サッカー,など.ほか,確実性の牙城に法律がある,技術は経済より確実で政治より不確実,なんて評価できたら面白いところです.)これもコンペとは関係ないですね.
*クラスタの大きさについて.興味の大きさと集合の大きさはだいたい一致しているようで面白いです(母集団がニュースに対し一様に作られたかどうかはわかりませんが)これもコンペとは関係ないですね.
・クラスタの密度について.気象・法律・競馬・事故は集合の密度が高いように見えます.密度の高さは似たニュースが多いということですが,これらは事実関係を見分けることが難しいだろうなと感じました.
(注:相対位置や大きさや密度について.アルゴリズム上では精密であるはずがないのですが,結果を検証して否定されたって経験が無いんですよね.なんでなんでしょう?)
・・・
結果
・銀メダルでした.一時期金メダルだったことを思うと無念ですがshake downは予想の範囲ではあります.
・Shake downしました.ダメダメの証拠みたいなもんですね
解法
・bert-base-japanese-whole-word-masking 一本勝負.
・headの工夫は一通り.
・Data-Centric AIの練習と設定し,疑似ラベルの付け方を検討.
・「Cによると」など確実にfakeにしか存在しない記載を利用した後処理.
コメント
・効かなかったもの: そも正解スコアが高すぎきちんと比較しがたかったです.1問差の向上をどう見るべきだったか.
*画像の機械学習が劣化する理由
https://qiita.com/nonbiri15/items/2bd2320d8268321c331d
*Japanese Fake News Dataset
https://hkefka385.github.io/dataset/fakenews-japanese/
*終了後思うところですが,次で文章校正し,変更された点を数えても面白かった気もします
振り返り
・1st
https://www.nishika.com/competitions/27/topics/290
・・日本語のRobertaモデル&mDebertaモデル おそらくCC-100が事前学習に含まれているモデルが有効だった.mdeberta-v3-baseは特に有効(アンサンブルしていたがこれ単独でも同等スコア)
・・ハイパーパラメータによってスコアが結構変動していた.
・・テストデータを使用した擬似ラベリングは効かなかった.
・2nd
https://www.nishika.com/competitions/27/topics/291
https://github.com/ktrw1011/Nishika-Fake-News-Detection
・・xlm-roberta-large,cl-tohoku/bert-large-japanese,microsoft/mdeberta-v3-base.mdeberta-v3-baseが最も有効.
・・性能の傾向は基本的にマルチリンガル>モノリンガルでした.
・・疑似ラベルは効かなかった.
・3rd
https://www.nishika.com/competitions/27/topics/292
・・rinna/japanese-roberta-base
・・疑似ラベル.日本語RoBERTaモデルを複数訓練.ほとんどのモデルで推論結果が一致するtestデータに限り擬似ラベルを付与しtrainデータとして利用.「Cによると」「C+」「<PRICE>」などのfakeデータにのみ含まれる記号を含むtestデータはfakeとみなしtrainデータとして利用
・6th
・・rinna/japanese-gpt2-medium で分類器を学習
・・生成に用いた事前学習済みモデルが必ずしも検知で有効とは限らない点は https://arxiv.org/abs/2011.01314 でも考察されている *興味深かったです
・・1行目の後に [SEP] を入れる *課題に対し興味深かったです
*全体として,モデル選択以外は,やっていることは変わらない印象ではあります.とはいえ、なにかわかっていないことがわかっていない印象でもあります.基本的に,仮説作成前にもう少しエビデンスの高いインプットをすべきかと感じました.場合によるとはいえ,上位概念化しすぎた,思いつきに依存した仮説が多すぎたかもしれません.
*モデル選択の評価が全然できていないと理解しました.パラメーターをもう少し個々に検討した後に評価すべきでした.
*自分が漁った範囲において,自分の評価手法では,BERTwholeがベストだったのですよね.日本語robertaはいまいちでした.
*マルチリンガルモデルは試していませんでした.mdeberta-v3-baseは知りませんでした.海外コンペではDebertaモデル無双の感もあるところです.覚えときます.(BERT系のマルチリンガルモデルは語順の検出に強かったとうろ覚えに聞いた記憶もあります.思いついておくべきではありました.)
*bert-base-japanese-whole-word-masking一本勝負の最高スコアはどれぐらいだったのでしょうね.そちらが気になります.
*1st,2ndの方は,疑似ラベルが効かなかったと.3rdの方は疑似ラベルが効いた?ようです.
*自分は多数のモデルの予測結果から擬似ラベルを作成しており,そちらは効きました.追加として,データを目視確認して任意の補正もしました.こちらはCVやLB publicは上がったのですが多分間違いでした.特に不確実性の高いデータをいじってしまったことは間違いだったでしょう(いやアカンよなとは思っていたんですよ.失敗すると予想したとおり失敗する体験も重要でうむ言い訳くさい).モデルはfakeかどうかでなく作成された文章かどうかを見分けていたようであるところ,fakeかどうかという基準で不確実性の高いデータを触ったため,モデル内で矛盾が起きやすくなってしまったのだという印象があります.モデルのみに任せるべきであったでしょう.
*疑似ラベルでやりすぎたまたは間違った方が,Shake downを食らった,のだろうという印象があります.Data-Centricの道は遠い.
*不確実性が高い部分を触りたかったなら,疑似教師とするのではなく,後処置で結果自体を変更すべきだったでしょうね.(今回の場合はあからさまなカンニングではありますが)
*なんとなくうろ覚えに見えてきた気はします。問題は不確実なものと確実なものをシステマティックに見分ける方法ですが…場合によるとしかならないのかな。
*「C+」等々が含まれるデータはfakeとする,との後処理はしていましたが,検討の後半になるとモデルが完全にこの点見分けてしまい意味がなくなっていました.マルチリンガルモデルでは有効だったのでしょうか・・・
*今回のコンペでは,モデル > Data-Centric AI ってイメージですかね.
もう少し条件分けして作業仮説をおいておきたいとは思います.
アンサンブルで安定性は向上するのか試しても見たく思いました.
・データの任意分類における共起ネットワーク化
・Data-Centric AI Competition — Tips and Tricks of a Top 5% Finish
https://towardsdatascience.com/data-centric-ai-competition-tips-and-tricks-of-a-top-5-finish-9cacc254626e
(i) トレーニング データと検証データの結合: 分布を等しくする作業
(ii) データクリーニングへの注力: 無関係の除去,誤りの除去 フォルダアイコンプレビューを利用した選別
(iii) 的を絞ったフリッピング: imgaugによるターゲットを絞ったランダム反転アプローチ
(iv) データセットのサイズ制限の最大化: 増幅を上限まで均等に
(4) うまくいかなかったこと
画像のサイズを大きく
拡張ステップのシーケンス内にランダムな順序を導入する
形態学的操作の適用 (例: 膨張/浸食、Otsu しきい値処理)
強化の強度をさらに高めます。たとえば、より劇的な回転、せん断、コントラスト
など
(5) 最高のアイデア
GoDataDriven は、画像を順次拡張する Streamlit アプリを作成しました。
Johnson Kuan は、(埋め込みに基づく) 最近傍拡張画像をトレーニング セットに追加するData-Boosting 手法を開発しました。
Pierre-Louis Bescondは、補強の一部として、正方形クロッピングとバックグラウンド ノイズ伝達関数を活用しました。
Walid Daboubi は、データのラベル付けに TornadoAI (ヒューマン イン ザ ループ機械学習の実装)を使用しました。
*正解率はかなり高かった.ベイズ誤差とほぼ同じに至っていると認識し,train/yバイアスの改善よりもtrain/dev分散を収束させることに注目し,正則化を中心に検討したほうが良かったかもしれない.train/devにも差は少なかったが・・・
*基本的に,エラー分析の後何をすべきかの理解が足りていないと認識した.基本的にはlabel mismatchに対しtrainの修正はあまり有効でないところ,その他のエラー要因を分析した上で,trainの修正を行う判断とはしなかった.devの修正は良いとして.ただ,エラーサンプルに共通点を見出すことは難しかった.現在の高度なNLPモデルにおいて,どのようにエラー分析を行うべきか,検討が必要.目視は難しいため,統計的手法でエラーサンプルの偏りを見つけるしか無いとは思うが・・・
*人間性能に近い場合の対応については,coursera Structuring Machine Learningが参考となると思う
・SHAPを用いて、devデータのうちおかしなところにweightがかかっている文を抽出し、それに関係するtrainを修正してみると良かった、かもしれない。data centric とするなら、可視化手法をまず作るべきだったかもしれない。
コンペ参加記録4: kaggle: U.S. Patent Phrase to Phrase Matching
Help Identify Similar Phrases in U.S. Patents (PPPM)
https://www.kaggle.com/competitions/us-patent-phrase-to-phrase-matching/overview
・目的:
・微小なドメイン差しかない場合における単語の意味の変化を捉えるコンペ,でしょう.
・なろうコンペで確立されていないとされていた,非テキストのBERTへの融合に関するコンペともなるでしょうか.
・解像度変換の参考となるでしょう.非常に興味深いです.
・初のcode competitionです.
internet切り忘れゴミ残存によるfailed出力のディレクトリ間違いwheelの保存add dataのやり方ワカランなど,本題の前に苦労しました.
・colabとkaggleで共通し使えるパイプラインも作成しました.trainをColabで実行inferenceをkaggle notobookで実行できるようにしました.
解法
・deberta-v3-large 一本勝負.
・headの工夫は一通り.
・入力の工夫,promptの工夫に集中.
特殊トークン,順番,case変更など検討.
・weight lossや など不均衡補正.
結果
・いやどうにもならなかった.0.02の遠さよ.
・完全に理解負けでした.時間がなかったとはいえEDAきちんとやりなさいよと当時の自分を叱りたい.気づくチャンスはあったのに.
・まだ記載の課題に縛られておりデータに忠実ととできていないと再認識しました。自分はやはり頭が硬いようです。実務上は学習外の単語でも使いたい、promptのヒントだけでフレーズ間の意味の違いを独立によりよく捉えられれば(それには他の問題を引用する限定的な手法ではよろしくないよな)、などと限定的に考えてしまいました。
両単語の差は品詞の差や略号であり、その知識はモデルが保有している。magicにより語幹自体ではなく品詞の差や略号を捉えることができるはずであり、それにより未知の単語でも判定できるようになるはずだ、と理解すべきだったでしょう。モデルの気持ちを理解してなかったということでしょう。
・仮説検証を1回廻すに丸1日.その合間にパイプラインづくりやFake newsコンペと、ハードでした.もう少し効率的なパイプラインを作るべきと反省しております.
・課題設定とリークの見極めがうまく行かないってのは勉強量の不足とセンスのなさの現れみたいなもんですね全く。
自分が何ができないのかなんとなくわかった気がしますな。しばし勉強時間を取るべきでしょう。
振り返り
postmortemというか検死.
・1st
https://www.kaggle.com/competitions/us-patent-phrase-to-phrase-matching/discussion/332243
Groupby['anchor', 'context'] ['target'] -> targets, add to input(anchor[SEP]target[SEP]CPC_TEXT[SEP]targets) produce best model
“prompt is all you need"
inference code:
https://www.kaggle.com/code/goldenlock/usp-base
most training code in:
https://www.kaggle.com/datasets/goldenlock/usppmatch
all training code opensource here:
https://github.com/chenghuige/U.S.-Patent-Phrase-to-Phrase-Matching
・2nd
https://www.kaggle.com/competitions/us-patent-phrase-to-phrase-matching/discussion/332234
・11th
https://www.kaggle.com/competitions/us-patent-phrase-to-phrase-matching/discussion/332273
「abatement [SEP] abatement of pollution [SEP] HUMAN NECESSITIES. FURNITURE; DOMESTIC ARTICLES OR APPLIANCES; COFFEE MILLS; SPICE MILLS; SUCTION CLEANERS IN GENERAL [SEP] abatement of pollution,act of abating,active catalyst,eliminating process,forest region,greenhouse gases,increased rate,measurement level,minimising sounds,mixing core materials,multi pollution abatement device,noise reduction,pollution abatement,pollution abatement incinerator,pollution certificate,rent abatement,sorbent material,source items pollution abatement technology,stone abutments,tax abatement,water bodies」
ここが重要と.Contrastive objective的な考え方ですね。これは全く思いつかなかったです。モデルから情報を抜き出すことに注意しすぎました。モデルにより多くの情報を与えるべきでした。
BCE with binning
やってました.
AWP
? Adversarial Weight Perturbationhttps://www.kaggle.com/code/wht1996/feedback-nn-train/notebook
Didn't work well
だいたいやっていました.
・
・24th
kaggle PPPMコンペ反省会
https://speakerdeck.com/k951286/kaggle-pppmkonpefan-sheng-hui
*Transformers Hyperparameters Tips
https://www.kaggle.com/competitions/us-patent-phrase-to-phrase-matching/discussion/330119
batch sizeに敏感
学習済み層のfreeze
学習率と学習率スケジューラーは、通常のMLモデルよりもトランスフォーマーのトレーニングに大きな影響を与えます
最近、One Cycle Cosineスケジュールは、複数のNLPタスクでより良い結果を提供することが示されています。
*【Kaggleコンペ振り返り】NBME – Score Clinical Patient Notes
https://www.ai-shift.co.jp/techblog/2583
*Kaggle NBME チラシ裏雑記帳
https://medium.com/@junkoda/kaggle-nbme-%E3%83%81%E3%83%A9%E3%82%B7%E8%A3%8F%E9%9B%91%E8%A8%98%E5%B8%B3-fdbf44e878bd
*How to Outperform GPT-3 by Combining Task Descriptions With Supervised Learning
http://timoschick.com/explanatory%20notes/2020/10/23/pattern-exploiting-training.html
教え方の工夫も深い分野
*Pre-Trained Language Models and Their Applications
https://www.sciencedirect.com/science/article/pii/S2095809922006324
自然言語処理技術レビュー202209頃まで.pretrain技術探索時に
コンペ参加記録5: kaggle: Open Problems - Multimodal Single-Cell Integration
Predict how DNA, RNA & protein measurements co-vary in single cells
コンペ参加記録6: The Sensorium competition on predicting large-scale mouse primary visual cortex activity
The Sensorium competition on predicting large-scale mouse primary visual cortex activity
https://arxiv.org/abs/2206.08666
https://github.com/sinzlab/sensorium/blob/main/notebooks/dataset_tutorial/1_inspect_data.ipynb
更新中) 網膜・視神経障害による失明から回復する技術に関する 個人的妄想メモ
https://qiita.com/drafts
コンペ知識の活用
・特許の空白予測(未来の出願予測)モデルを作成することとする。
特許戦略分析には空白予測が欠かせない。現在より精度の高いモデルが欲しかった。
先例は出願予測の正解10%前後。比較しどこまでできるかな。
・ラグ特徴について改良することとする。
・個人的には、個人が自分の認知に近くかつ別の知識も持つAIをそれぞれ備え、自らの拡張をすることにより、知財含めた様々な問題の解決につながると思っている。
(他人の不確定性が高い意見は聞けなくても、自分のコピーの不確定性が高い意見は聞けるだろう。また、自分のコピーを介し認知範囲を広げることにより、他人の認知を理解し取り入れやすくもなるだろう。)
コンペに参加しているが、この体験は(事前知識系のAIが使われていなかった過去のコンペとは異なり)、このような「個人アシスタント用の個人能力拡張AI」を広いドメインでも作ってゆくことにもつながる、と思っている。
・知識の伝達とはどこまで行っても受け手の認知の限界を受ける。
受け手の認知に送り手が合わせていては、伝達の質の低下が起きる結論にしかならない。説明責任は良いが、これに理解責任を含めるべきではない。理解責任はどんな場合でも受け手に留保しておかねば先がない。
受け手が、送り手からの情報を、受けての認知に合うように、改変する必要がある。
これはではそれを行う手段がなかった。しかし今はAIがある。
送り手が合わせる時代は終わり、より質の高い伝達がなされる時代が来ると思っている。(極論の例を上げれば、例えば翻訳。送り手がどれほど説明しても受け手がその言語について認知がなければ伝達は不可能であるところ、AIは、言語音声画像質含めた、より良い伝達を可能とする。)
認知の調整が可能となることこそが革新だと思うし、コンペではそれをどう行うかに付き、模索してもいる。
(コチラ突き詰めるとbrain machine interfaceの話になる。どこか求人出してないかな…)
追記
・PyGWalker
https://github.com/Kanaries/pygwalker
https://qiita.com/hima2b4/items/dfdfb77cf3a588f4131a
jupyterなどでEDAをtableauライクに行うツール
・99 Lessons on Data Analysis from Placing Top 5 in 5 Kaggle Analytics Challenges
(Grand)Masterclass: How to Approach a Kaggle Analytics Challenge
https://towardsdatascience.com/99-lessons-on-data-analysis-from-placing-top-5-in-5-kaggle-analytics-challenges-453d5e7b4581
コンペ記録:Kaggle - LLM Science Exam
Use LLMs to answer difficult science questions
https://www.kaggle.com/competitions/kaggle-llm-science-exam/
Kaggleコンペ(LLM Science Exam)の振り返りと上位解法まとめ
https://zenn.dev/nishimoto/articles/aff1fba9c75c34
kaggle LLMコンペ 上位解法まとめ
https://zenn.dev/yume_neko/articles/7347ba6b081e93
コンペ参加記録7:第3回 空戦AIチャレンジ
シミュレータを使った空戦AIに挑戦しよう!
防衛装備庁
https://signate.jp/competitions/1198
・目的
・「本コンペは、公刊文献から得られる機体情報等に基づいて簡易的に表現したシミュレータを用いて、空対空戦闘における行動判断モデル(エージェント)を構築して頂きます」
・ランダム思いつきの繰り返しの問題点の発見のため.
・手持ちの4本足ロボット制御を,画像検知言語モデルGPT4Vを用い行うに当たり,長期知識保存先として強化学習を採用しようかと思いついた.基本知識取得のため.
・RLHF 強化学習による 認知フィードバック 参考として
・自主制限
・Google colabのみ使用.
1実験の情報を1つのノートブックにまとめる(コードの変更もノートブックから制御する)
初期EDA
解法
振り返り
コンペ参加記録8:USPTO - Explainable AI for Patent Professionals
・目的
・自主制限
初期EDA
解法
振り返り
コンペ参加記録9: Learning Agency Lab - Automated Essay Scoring 2.0
・目的
・「このコンテストの目標は、学生のエッセイを採点するモデルをトレーニングすることです」
・なろう小説コンペから2年,どのような技術が最新となったか知るため.また,tfidf cluster vis性能再確認のため
・自主制限
・特になし
初期EDA

・tfidf cluster vis使用.
・意明確にクラスタが分かれている.いくつかの明確なテーマが提示されたうえで作成されたエッセイであったのか?
・スコアを取りやすいジャンルと,スコアを取りにくいジャンルがあるようだ.明確にするとより良いだろう.
・多様な見解が許容されるジャンルと,答えが収束しているジャンルが,分かれているようにも見える.
・個人的に、クラスタの中心に高スコアのエッセイが位置しており、クラスタの周辺に低スコアのエッセイが位置しているように見える。極論や読時の言い回しが好まれない学術文献に近いエッセイなのだろうか。
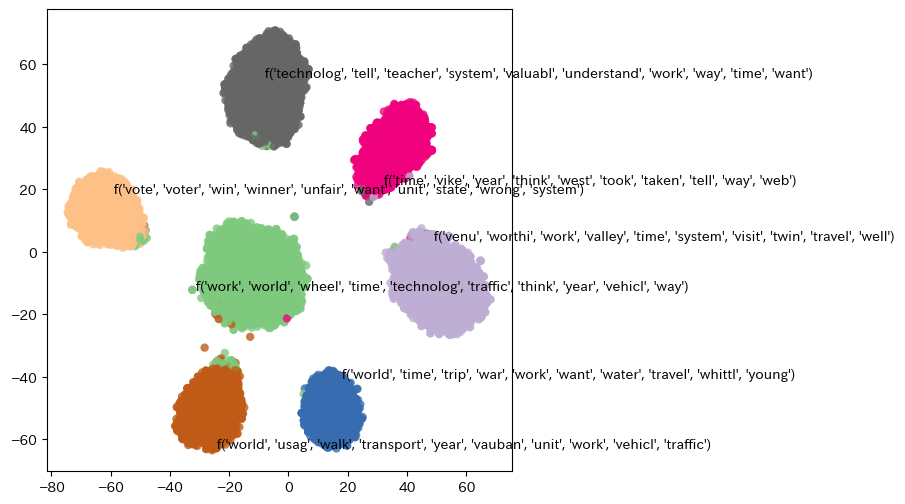
・ジャンルは,
- 日常生活や業務遂行における効率性や進歩,「modernity」(現代性)や「progress」(進歩)? [driverless] 無人運転?
0 ('work', 'world', 'wheel', 'time', 'technolog', 'traffic', 'think', 'year', 'vehicl', 'way') - 場所や訪問、旅行に関連する活動,「exploration」(探索)や「journey」(旅)? [exploring venus] 金星探索?
1 ('venu', 'worthi', 'work', 'valley', 'time', 'system', 'visit', 'twin', 'travel', 'well') - 選挙や政治システム、公平性に関するテーマ,「electoral integrity」(選挙の整合性)や「political fairness」(政治的公正性)? [dear senator] 上院議員への提言
2 ('vote', 'voter', 'win', 'winner', 'unfair', 'want', 'unit', 'state', 'wrong', 'system') - 旅行、仕事、戦争、および日常生活の要素を含む様々なテーマ,「adventure」(冒険)や「journey」(旅)? [seagoing cowboy] 戦時中の動物輸送
3 ('world', 'time', 'trip', 'war', 'work', 'want', 'water', 'travel', 'whittl', 'young') - 時間やコミュニケーション、方向性、「communication」(コミュニケーション)や「information exchange」(情報交換)? [face on mars, nasa] 火星の人面岩
4 ('time', 'vike', 'year', 'think', 'west', 'took', 'taken', 'tell', 'way', 'web') - 交通、仕事、そして持続可能な開発や計画、「sustainable urban planning」(持続可能な都市計画)? [] 車両削減
5 ('world', 'usag', 'walk', 'transport', 'year', 'vauban', 'unit', 'work', 'vehicl', 'traffic') - 教育、コミュニケーション、価値、および技術の使用,「educational technology」(教育技術)? [facial action coding system, emotion] 顔の動きと感情
6 ('technolog', 'tell', 'teacher', 'system', 'valuabl', 'understand', 'work', 'way', 'time', 'want')
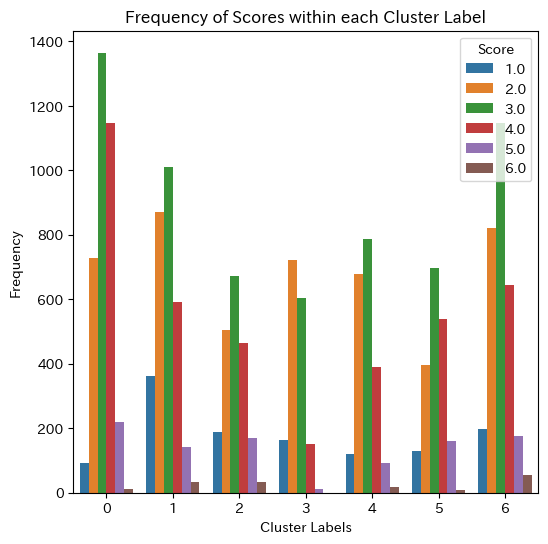
・右下に配置されたクラスタ1(金星探索旅),3(戦時動物輸送旅)は,他クラスタと比較してスコアが全体的に低い.
中央に配置されたクラスタ0(無人運転現在進歩)は,他クラスタと比較してスコアが高い.
最も最高スコアが多かったのはクラスタ6(顔の動きと感情教育技術)
・trainとprivate testの分布は同じと仮定してよいだろうか.流石に特定のテーマを落としてtrainにしタリハしていないと思うが・・・testが3件しかないのでpublicにはわからない.
解法
振り返り
HMS - Harmful Brain Activity Classification