Nishika株式会社が主催「小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~」コンペに参加しました。本記事で私の取り組みの共有と振り返りをしたいと思います。
コンペ概要
本コンペでは、日本最大級の小説投稿サイトである「小説家になろう」のデータを用いて、ジャンルや作者名などの関連データから各小説のブックマーク数を予測することをテーマとします。予測対象となるブックマーク数を5段階にビニングし、予測確率とのMulti-class loglossが評価指標とされています。
コンペ結果
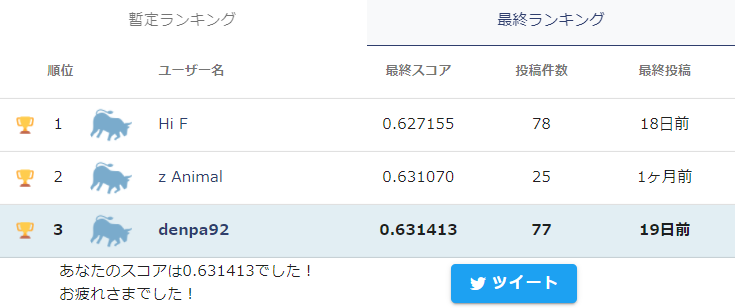
最終ランキングでは参加者575人中3位で入賞させていただきました。
データ
小説名・あらすじのようなテキスト特徴量とジャンル・キーワードのような非テキスト特徴量を含むデータセットになります。
| 説明 | |
|---|---|
| ncode | 小説のNコード |
| general_firstup | 初回掲載日 |
| title | 小説名 |
| story | 小説のあらすじ |
| keyword | キーワード |
| userid | 作者のユーザID(数値) |
| writer | 作者名 |
| biggenre | 大ジャンル |
| genre | ジャンル |
| novel_type | 連載の場合は1、短編の場合は2 |
| end | 短編小説と完結済小説は0となっています。連載中は1 |
| isstop | 長期連載停止中なら1、それ以外は0 |
| isr15 | 登録必須キーワードに「R15」が含まれる場合は1、それ以外は0 |
| isbl | 登録必須キーワードに「ボーイズラブ」が含まれる場合は1、それ以外は0 |
| isgl | 登録必須キーワードに「ガールズラブ」が含まれる場合は1、それ以外は0 |
| iszankoku | 登録必須キーワードに「残酷な描写あり」が含まれる場合は1、それ以外は0 |
| istensei | 登録必須キーワードに「異世界転生」が含まれる場合は1、それ以外は0 |
| istenni | 登録必須キーワードに「異世界転移」が含まれる場合は1、それ以外は0 |
| pc_or_k | 1はケータイのみ、2はPCのみ、3はPCとケータイで投稿された作品 |
| fav_novel_cnt_bin | ブックマーク度(目的変数) |
解法
全体の考え方は以前Nishika様が主催しました「 AIは芥川龍之介を見分けられるのか?」コンペの2nd Solution を踏襲していました。
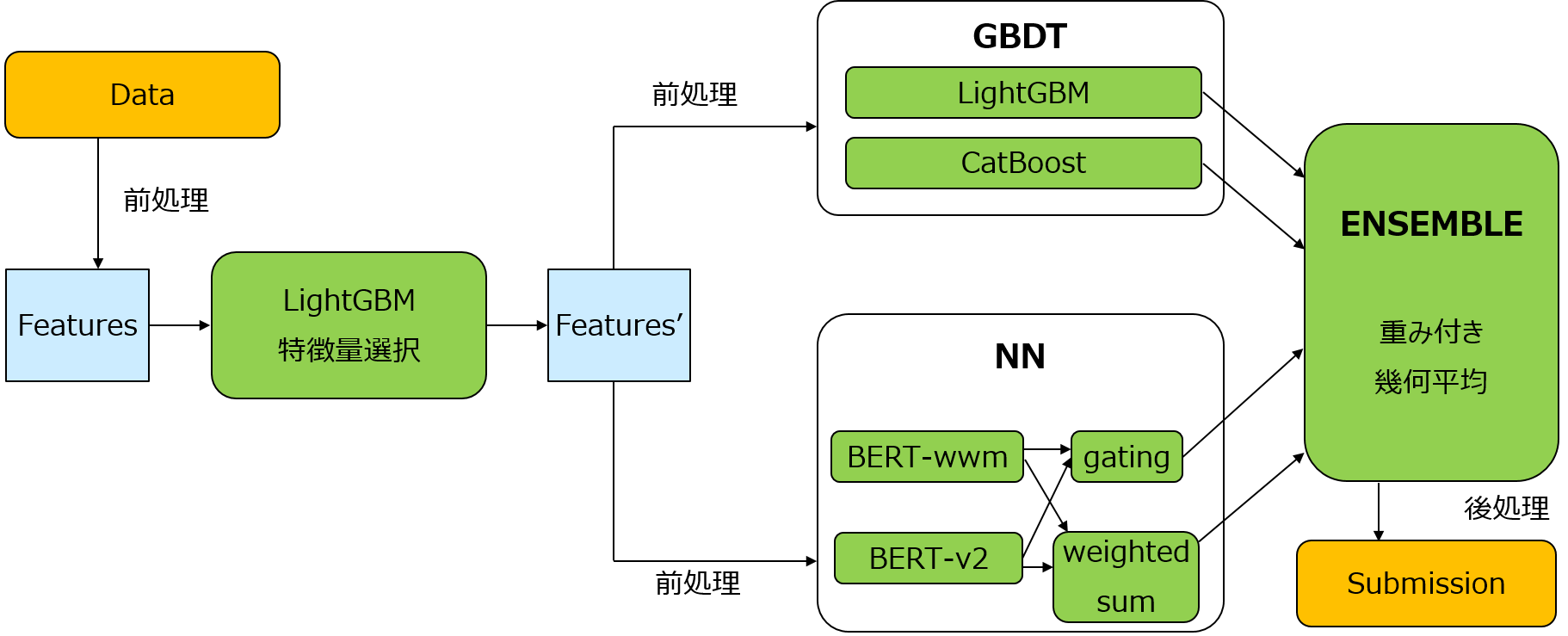
LightGBMを用いて特徴量選定を行い、実際の分類モデルではLightGBM、CatBoostとBERTを使いました。最終的に各モデル出力の重み付き幾何平均を利用し、後処理では5-foldのCVスコアを参照として各クラスの予測確率をn乗(n=0.95~1.00)する処理を加えました。
データセットに対するEDAは下記他の方の記事で詳しく説明されましたため、今回では独自の取り組みを中心に紹介したいと思います。
・【AI Shift Advent Calendar 2021】Nishikaコンペ振り返り 小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~
・Nishikaコンペ参加記録 小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~
Trust LB/CV ?
Tips and tricks to win kaggle data science competitions において、時系列データコンペにおけるリーダーボードのスコアを信用する/信用しないパターンを分析しました。今回のコンペにおいて、学習データは2021/08/12の8時より前のデータで、PublicとPrivateはそれ以降のデータからサンプリングしたもののため、以下の図の「MUST TRUST LB」に該当します。実際PrivateとPublicの全体順位もあまりshakeしませんでした。このパターンでは早期参戦することで多数Submitによる試行錯誤がアドバンテージになります。

特徴量
- useridから同じ作家が過去投稿した作品のブックマーク数に対するTarget Encoding
作成した特徴量の中で圧倒的にスコアに寄与した特徴量であり、このコンペにおけるMagicと言っても過言ではないくらい差があります。これは流行りのタイトルやジャンルを狙うより、結局はクリエイターの質によって作品の人気が決まることになります。実際投稿した小説家の中にも「他人の評価を優先」タイプと「自己満足を優先」タイプに分かれているため、ブックマーク数もそれに応じて分かれています。ただしリークになりやすいため利用時には注意する必要があります。今回はout-of-fold target encodingを利用しました。
- 同じ作家の一つ前に投稿した作品の情報を学習データを加える
前述したTarget Encoding特徴量は強力ですが、欠点としてテストデータの期間(2021/08/12以降)ではじめて投稿した作家の作品では
すべて欠損値になるため、それを補うため「一つ前の投稿までの日数」「一つ前の投稿作品のタイトル」などを追加しました。実際一日に複数の投稿を行う作家の作品の評価が低い傾向を示しているほか、タイトルの類似度が高いものはシリーズ作品としてブクマ数が同じ傾向が見られることが多いです。
- 複数のペンネームを使用しているか
こちらの記事にも言及されていますが、作者のユーザIDと作者名のnunique数は一致していません。約600名のユーザは複数のペンネームで投稿していますが、実は複数のペンネームを使用する/使用しないには大きな差があります。「小説家になろう」サイトの仕様上、ペンネーム欄を入力せず投稿すると、小説情報ページでは「作者名 = ユーザ名」と表示され、作者名のリンクをクリックしたら、その作者の過去の投稿作品の情報を確認できますが、ペンネームを入力すると作者名のリンクが付与されなくなり、読者はそこから過去の投稿作品の情報を確認できなくなります。 作品のブクマ数と過去作の評価には大きな相関があると分かった以上、これは大きなハンデと言わざるを得ません。
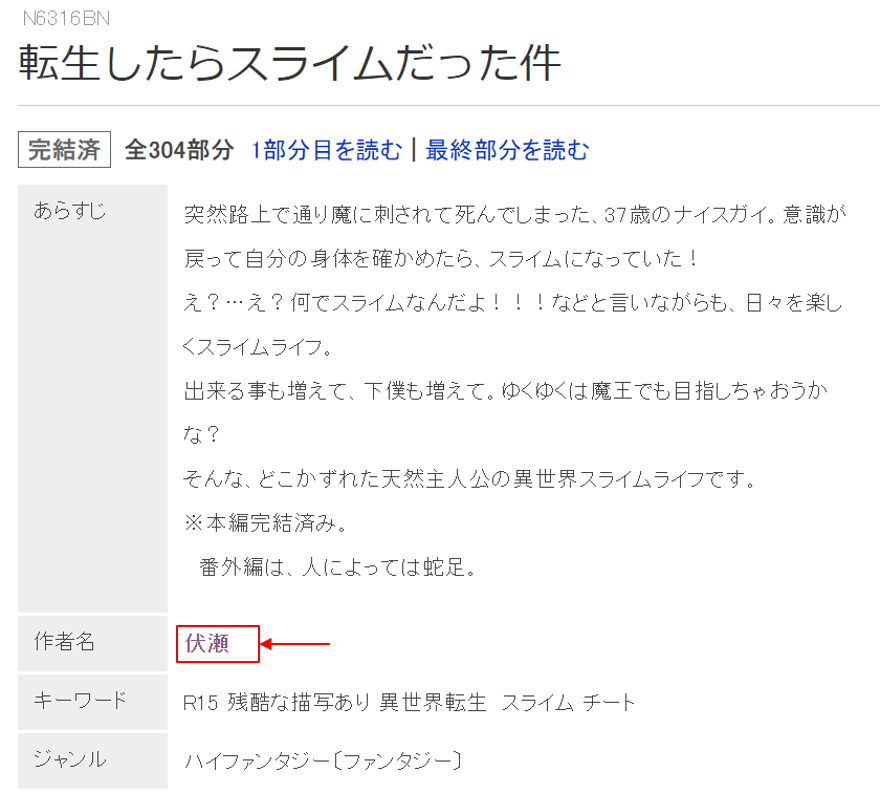
作者名にリンクが付与されている事例 (https://ncode.syosetu.com/novelview/infotop/ncode/n6316bn/)
モデル
- 事前学習済みモデルの選定
BERTなどの事前学習済みモデルを利用する手法は今はもはやデファクトスタンダードになっていますが、
計算コストが多いため、事前にタスクのドメインに適するモデルの選定が必要です。
HuggingFaceのHosted inference APIを使えばある程度モデルとドメインの相性を事前に確認することがてきます。
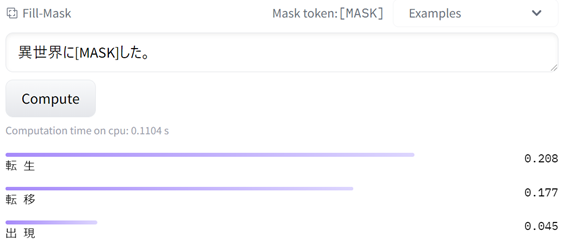
以下はcl-tohoku/bert-base-japanese-v2 と rinna/japanese-roberta-base がHosted inference APIのFill-Maskタスクにおける結果を表示しています。
①cl-tohoku/bert-base-japanese-v2
② rinna/japanese-roberta-base

①の結果がより期待した出力に近いため、本コンペのドメインにおいて①モデルをFine-tuningしたものがより良い性能が得られる可能性が高いことが分かりました。ダウンロードする前にモデルのドメイン適正を味見することで、試行錯誤の回数を減らすことが可能です。
- テキスト情報と非テキスト情報の結合
GBDTモデルにおいてテキスト情報の利用方法は下記記事できれいにまとめらています。
一方、BERTなどのモデルにおいてカテゴリ・数値特徴などの非テキスト情報を取り込む方法はまだ確立されていないようです。
Jigsaw Unintended Bias in Toxicity Classificationの1st Solution のように、カテゴリ情報をTransformerの追加トークンとして入力する手法が使われていますが、以下2つの懸念点があります。
- 事前学習のタスクと違うため小規模データセットでのFine-tuning性能が期待できない
- Denseなテキスト分散表現に対してカテゴリ・数値特徴量はSparseであることが多い
今回実装したモデルのおいて、小説名とあらすじを連結したテキストをBERTでエンコードした埋め込みに対して、ジャンルなどのカテゴリ特徴を付随条件として与えられた際、テキストの意味の変化をベクトル空間上の変位として表現し、埋め込みを変位ベクトルで補正する形で実装しました。結果、シングルモデルのスコアではGBDT系モデルに及びませんでしたが、GBDTとのアンサンブルでLB/CVスコアが大きな向上が見られました。
おわりに
- 言語情報と非言語情報のマルチモーダルデータを扱うコンペとして非常に面白かったです。
- 時系列情報に関していろんなアプローチを試しましたが、あまり効果がなかったため活用した方の解法に気になります。
- 本コンペで稼いた賞金が全部とある「なろう」発小説に還元しましたので、これからも「小説家になろう」を応援いたします。