はじめに
こんにちは、estieで機械学習エンジニアをやっている、ぴーまんです。 最近、自分の体の細さに嫌気が差し、ジム通いを始めたものの、カウンセリングで体の状態を測定した結果「プロアスリート級」の体という診断を受け、少し満足してしまっている自分がいます。今回はestie Advent Calendar 2021 7日目の記事として、趣味で取り組んでいるデータサイエンスコンペについて書こうと思います。
データサイエンスコンペとは
まず、皆さんはデータサイエンスコンペをご存知でしょうか。有名なものだと、Kaggle社が運営するKaggleというコンペがあり、こちらは耳にしたことのある人もいるんじゃないでしょうか。(ちなみに2017年にgoogleがKaggle社を買収したらしいです。知らなんだ。)データサイエンスコンペでは、運営・企業から与えられたデータに統計手法・機械学習を駆使して、様々なお題に対して予測を行い、その精度を競います。estieも過去にKaggleの「医薬品の作用機序」を推定するコンペに出場したことがあります。その際の記事はこちら。データサイエンスコンペで一番有名なKaggle社はアメリカの企業ですが、日本にもSignateやProbspace、そして今回参加したNishikaなどがあります。
Nishikaは2019年11月にサービスをローンチした比較的歴史の浅いサイトで、ローンチコンペの「AIは芥川龍之介を見分けられるのか?」というコンペや、レコメンドエンジンの開発コンペ、仮想通貨の価格予想、日本絵画の顔分類など、ユニークなコンペを数多く開催しています。(ちなみにローンチコンペでは金メダル圏の4位に入賞しました!3位以内だと賞金がもらえたのですが。。。惜しかった。。。 下図はローンチコンペのランキングです。)

今回参加したコンペ
今回は、Nishikaが開催する「小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~」というコンペに出場しました。このコンペでは、「小説家になろう」という小説投稿サイトの各小説のあらすじやタイトル、そのジャンル情報などから、ブックマーク数を予測するお題が与えられています。書籍の小説の場合、例えば売上数を予測しようとすると、まず実売部数(発行部数ではない)は極秘事項となっていて、そもそもデータが取れなかったり、メディアや口コミでの紹介などの様々な事象に影響を受けるため、予測は非常に困難です。一方で投稿サイトの小説の場合、関連するデータが比較的オープンで網羅的に取得できるため、そこから得られる特徴量から読者数やファンの数、ブックマーク数を予測できる可能性がある、という背景で今回のコンペは開催されています。予測対象となるブックマーク数はブックマーク数を5段階にビニングしたものとして設定されており、コンペでは、各小説が5段階評価のそれぞれに入る確率を算出したものに対して、正解と比較した時の精度をMulti-class loglossを用いて計算(計算式は下図の通り)し、その精度スコアの順位で競います。

結果!!
先月末11月29日までこのコンペは開催されていましたが、最終日締め切り後に最終ランキングが発表され、私は参加者576人中54位でした。(まだ入賞候補の精査中なため、メダル圏は確定していませんが、暫定スコアベースだと銅メダル圏です! 下図は今回コンペの最終ランキングです)

構築したモデル
学習・推論パイプライン構成は下図の通りです。

設定した特徴量
最終的に予測に寄与した重要特徴量は上から順に下記のようになりました(上位10つの特徴量を記載)
- 大ジャンル
- 連載/短編
- ユーザーID
- 作者名
- キーワード数
- あらすじ内の名詞数
- あらすじの長さ
- 初回掲載日からの日数
- 投稿順
- あらすじ内の動詞数
- ・・・
与えられたtrainデータには、そのまま特徴量として採用できるものと、加工しないと機能しない特徴量が含まれています。例えば、「大ジャンル」や「小ジャンル」などは、そのままどんなジャンルだったらブックマーク数が多くなりそうか、というのはなんとなく統計的に有意差が得られそうですが、「あらすじ」「タイトル」などは特に固有の文字列の並びでしかなく、どんな「あらすじ」「タイトル」だったらブックマーク数が多くなりそうかというデータの特徴を抽出するには一工夫が必要です。
そこで文字列を単語ごとに分かち書きをしてくれるtokenizerを用い、特徴を抽出しやすい形にしています。分かち書き処理で得られたデータから抽出した特徴量の例は下記の通りです。
-
品詞ごとの使用数
- (例えば名詞は何回使われているか、もしくは否定系の助動詞が含まれているか、等)などを特徴量として採用しました。
- 頻繁に登場する単語のあらすじ/タイトル内での登場回数
-
あらすじをベクトル化したもの
- あらすじについては、より詳細な特徴を抽出するために、Doc2Vecを使用して文章を固定長のベクトルに変換しています。(Doc2Vecについてはこちらの記事がわかりやすいです。)ベクトル化をすることで、文章間の意味の類似性をベクトル間の距離で表現することができるようになります。
その他の簡単な特徴量の例は下記の通りです。
- あらすじ/タイトルの長さ
- ジャンル
- 初回掲載日から何日経っているか
-
投稿順
- この特徴量が少し面白くて、「ncode」という、そのままでは各小説の固有IDとしか使えないような特徴量が実は、投稿された順番の番号をある数式で変換したものだという情報が、コンペ内の掲示板で挙がっており、この数式を逆算することで得られる投稿順も特徴量に採用しました。
学習方法
上記で作成した特徴量データセットとそれぞれに対応するブックマーク度の正解データのセットに対して、交差検証して学習を行いました。後述しますが、ブックマーク度の分布は偏っているため、交差検証のためのデータ分割にはStratifiedKFoldを採用しています。(StratifiedKFoldについてのわかりやすい記事はこちら )これにより、データを10つのfoldに分割し、それぞれに対して学習を行います。パラメータチューニングにはOptunaを使用しました。
推論方法
上記で学習したモデル10つに対し、テストデータを投入し、結果は単純平均を採用しました。
交差検証の結果
交差検証におけるスコアは 0.808(-> 最終スコア: 0.719)でした。検証で正しいラベルを予測したデータセットと不正解のデータセットとの差を簡単に考察してみます。
まず、大ジャンルの割合について、正解のデータセットに比べて不正解のデータセットで割合が目立って大きい大ジャンルは「恋愛」「ファンタジー」「SF」等。小ジャンルの割合については「異世界〔恋愛〕」「ハイファンタジー〔ファンタジー〕」「VRゲーム〔SF〕」等が目立って不正解データセット内の割合が高い結果となりました。これらのジャンルは人気が高く、またブックマーク度のばらつきが大きいジャンルです。このばらつきによって、傾向の学習がしにくくなってしまったと考えられます。
| 大ジャンル | ブックマーク度平均 | ブックマーク度分散 |
|---|---|---|
| 恋愛 | 1.72 | 1.55 |
| ファンタジー | 1.14 | 1.21 |
| SF | 0.86 | 0.97 |
| 文芸 | 0.66 | 0.68 |
| その他 | 0.54 | 0.38 |
| ノンジャンル | 0.41 | 0.42 |
小ジャンルについても同様の考察ができそうです。
| 小ジャンル | ブックマーク度平均 | ブックマーク度分散 |
|---|---|---|
| 異世界〔恋愛〕 | 2.40 | 1.16 |
| VRゲーム〔SF〕 | 1.58 | 1.43 |
| ハイファンタジー〔ファンタジー〕 | 1.53 | 1.35 |
| 現実世界〔恋愛〕 | 1.02 | 1.00 |
| 歴史〔文芸〕 | 0.93 | 1.01 |
また、タイトルの長さ、タイトル内の単語数、キーワード数について、不正解のデータセットの方が長く、多い傾向がありました。今回、あらすじにフォーカスして自然言語処理を用いて特徴量を抽出し、タイトルに対しては最低限の単語数カウントや頻出単語の有無の分析しか行いませんでした。あらすじと比べると長さが短く、特徴が抽出しにくいタイトルですが、品詞分析を初めもう少し詳細な分析をかけることでより有効な特徴量が抽出できた可能性が考えられます。
以上、簡単にですが、今回の学習/推論結果について考察してみました。
データセット分析
コンペの本筋とは外れますが、なろう小説初心者なりに、データ全体に対して特徴量抽出の際に色々分析を行って、得られた分析結果をいくつか書いてみます。
ブックマーク度の分布

まずブックマーク度の分布は、上図のようにかなり偏っています。5段階評価で3以上(グラフでは0始まりなので2以上)の投稿は全体の1/5足らずなのがわかります。かなり評価が厳しい世界であることがわかります。
人気の(ブックマーク度が高い)ジャンル
| 小ジャンル | ブックマーク度平均 |
|---|---|
| 異世界〔恋愛〕 | 2.40 |
| VRゲーム〔SF〕 | 1.58 |
| ハイファンタジー〔ファンタジー〕 | 1.53 |
| 現実世界〔恋愛〕 | 1.02 |
| 歴史〔文芸〕 | 0.93 |
前章と同様の分析ですが、各小ジャンルのブックマーク数を集計して、上位のジャンルを見てみました。堂々の1位は「異世界 [恋愛]」。なろう小説初心者としては正直どんな話があるのかわかりませんが、異世界転生ものが流行っているというのはなんとなく聞いたことがある気がしますし、漫画サイトの広告で良くみるような。。。(ターゲティングされてる?)3位に挙がっている「ハイファンタジー [ファンタジー]」については、全く聞いたことの無いジャンルでしたが、wikipedia曰く、要は異世界ものらしいです。やっぱり異世界が人気なんですね。ちなみにハイファンタジーに対立するローファンタジーというのは、例えば現実世界に魔法が入ってるような、現実と少しリンクしているようなファンタジーのことを言うそうです。ということはハリー・ポッターとかはローファンタジーなんですかね?(私は結構ハリー・ポッター好きなんですが、小学生の頃、何もわからない同級生相手にハリー・ポッターの知識をひけらかして恐れらている子供でした。元祖マウンティング野郎です。)
あらすじの長さによるブックマーク度の分布
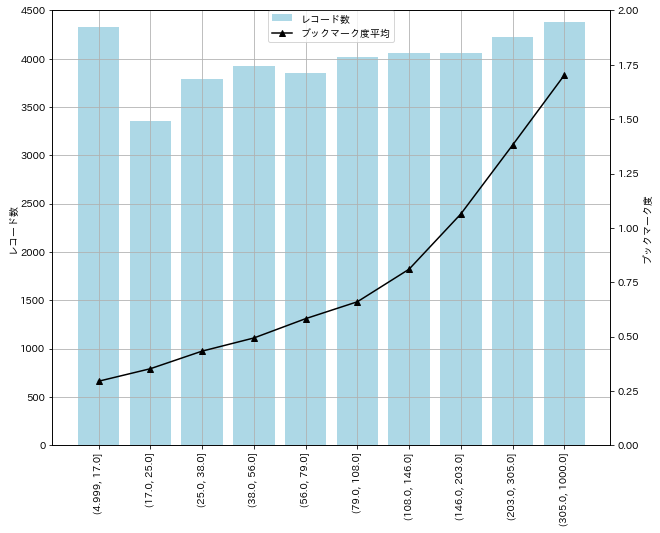
あらすじの長さごとのレコード数を揃えつつ(pandasのqcutを使用)、あらすじの長さごとのブックマーク度平均を可視化してみました。これをみると、あらすじが長い投稿ほどブックマーク度が高いようです。あらすじをしっかり書いている作者はプロットもしっかりしている傾向があるのでしょうか。この辺りは一度しっかり中身を読んでみたいところですね。
複数の作者名を使っている人
ユーザーごと・作者ごとに、作者の経験年数や文章のうまさ、ファンの多さなどでブックマーク度の傾向がありそうだというのはなんとなくわかりやすいですが、では1ユーザーで複数の作者名(ペンネーム)を使っている人はいるんだろうかという単純な興味で分析をかけてみたところ、trainデータに含まれる18630人のうち、664人が複数の作者名を使っていることがわかりました。(同一User_idで複数の作者名を持っているUser_id数をカウントしています。)さらに一番多くの作者名を持つユーザーはなんと57つも作者名を使って投稿していました。作者ごとに作風を分けたりしてるんでしょうか、と考えたり、なかなか興味深いです。(ちなみにこのユーザーごとの作者名の数も特徴量として入れましたが、予測にはほとんど効いていないようでした。。。笑)
他にもあらすじ・タイトルに含まれているキーワードごとのブックマーク数について有意差検定を取ってみたり、色々な分析をかけてみましたが、キリが無いので、この辺で終わりにしたいと思います。
さいごに
いかがでしたでしょうか。今回は、estie Advent Calendar 2021 7日目の記事として、Nishikaの「小説家になろう ブクマ数予測 ~”伸びる”タイトルとは?~」というデータサイエンスコンペに参加してみた話について書いてみました。結果として銅メダル圏内でフィニッシュできましたが、個人的には時間の都合で試せなかった特徴量やモデル選定などがあり、まだ上を目指せた部分はあったなと思っています。
普段は社内でオフィス物件の賃料推定モデルを作っており、基本的にオフィスに関するデータを毎日いじっている身としては、こういうコンペでは普段触らないようなデータに触れることができるため、非常に刺激的で楽しく、いい気分転換になります。もちろん機械学習技術やデータ加工のTIPSなど、毎回キャッチアップできることは多く、自己研鑽としても大変ためになります。引き続き、色々なコンペに参加していこうと思います。
さて、estieでは全職種でメンバーを募集しています!
我こそはestieのデータでおもろいことするんじゃという方。オフィス不動産のデータってどんなの?って興味を持たれた方、是非カジュアルにお話しさせてください。
明日は、estieが誇る最強デザイナーあらけんの、「2人目デザイナーの入社前にやったこと」です。お楽しみに!