はじめに
今回はWord2Vecの発展としてDoc2Vecを勉強しました。
自然言語処理でよく求められるタスクとして「文書分類」や「文書のグルーピング(クラスタリング)」がありますが、それらを実施するには文書そのものの分散表現が必要となります。
Doc2Vecを用いればその分散表現を直接獲得することができます。
参考
Doc2Vecを理解するに当たって下記を参考にさせていただきました。
- doc2vec(Paragraph Vector) のアルゴリズム
- Distributed Representations of Sentences and Documents (元論文)
- Doc2Vecの仕組みとgensimを使った文書類似度算出チュートリアル
- 自然言語処理技術の活用法 ーDoc2VecとDANを使って論文の質を予測してみた!ー
Doc2Vec
Doc2Vecとは何か
Doc2Vecは任意の長さの文章を固定長のベクトルに変換する技術です。
Word2Vecが単語の分散表現を獲得するものだったのに対し、Doc2Vecは文章や文書の分散表現を獲得します。文章の分散表現を獲得する手法としては古典的なものとしてはBag-of-WordsやTF-IDFがありますが、それらは下記のような弱点を有しています。
- 文章内の単語の語順情報を有していない
- 同義語でも完全に異なる独立した単語として認識する
これらはカウントベースと呼ばれる手法ですが、Doc2Vecは上記弱点を克服すべく違うアプローチで文章の分散表現の獲得を試みています。
Doc2Vecのアルゴリズム
Doc2Vecは下記2つのアルゴリズムを総称したものになります。
- PV-DM(Distributed Memory Model of Paragraph Vectors)
- PV-DBOW(Distributed Bag of Words version of Paragraph Vector)
以下で簡単にそれぞのアルゴリズムに関して説明します。
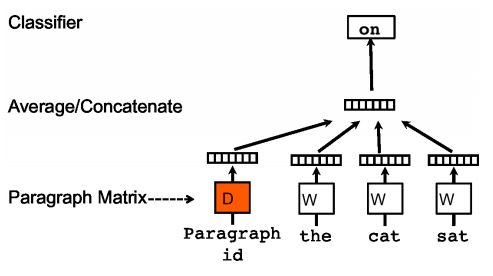
PV-DM
PV-DMはWord2VecのCBOWに対応するようなアルゴリズムです。
文章のidと単語を複数個渡し、次に出てくる単語を予測するというタスクを解きながら文章の分散表現を獲得します。
私の調べた限りだと下記のような手順で学習を行なっているようです。
- 文章のベクトルと文書の中から一部をサンプリングした単語のベクトルを用意
- 1で用意したベクトルを中間層で結合(平均又は連結、gensimでは選択可能)
- サンプリングした単語に続く次の単語を予測
- 文章ベクトルおよび中間層→出力層の重みを更新
イメージ図は下記なります。(「参考」に記載の元論文より引用)
PV-DBOW
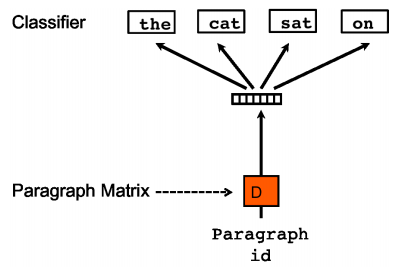
PV-DBOWはWord2Vecのskip-gramに対応するようなアルゴリズムです。
PV-DBOWは単語のベクトルを学習の際に用いる必要がないため、PV-DMよりも早く学習が可能です。ただPV-DBOWは学習の際に語順を無視するかたちになっているため、PV-DMの方が精度が良いとされています。
私の調べた限りだと次のような手順で学習を行なっているようです。
- 同一文章から任意の個数の単語をサンプルしてくる
- サンプルした単語を予測するように文章ベクトルと中間層→出力層の重みを最適化する
イメージ図は下記なります。(「参考」に記載の元論文より引用)
上記簡単に2つのアルゴリズムについてまとめましたが調べても細かいところでよくわかない部分がありました。どなたかわかる方はコメントで教えていただけると嬉しいです。。。
調べてもわからなかったところ
- 最初に入力として与える文書ベクトルはどのような形式なのか、単純に文章のidだけを渡しているという認識で問題ないのか
- この学習の結果、最終的に得ることのできる文章の分散表現(Paragraph Vector)はどこから取ってきているのか(Word2Vecでは入力から中間層に変換する重みベクトルを単語の分散表現としている)
ライブラリを用いたDoc2vecモデルの作成
以下ではライブラリを用いて実際にDoc2Vecのモデルを作成していきます。
使用したライブラリ
gensim 3.8.1
データセット
pythonのライブラリであるgensimを用いて簡単にDoc2Vecのモデルを簡単に作成することが可能です。今回データセットは「livedoor ニュースコーパス」を使用させていただきます。データセットの詳細やその形態素解析の方法は以前投稿した記事で投稿しているの気になる方そちらをご参照いただければと思います。
日本語の場合は事前に文章を形態素単位に分解する前処理が必要となるため、全ての文章を形態素に分解した後下記のようなデータフレームに落とし込んでいます。
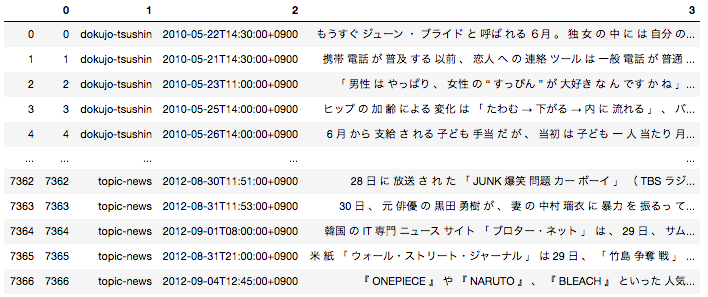
一番右のカラムが文章を全て形態素解析して半角スペースごとに区切ったものになります。こちらを用いてDoc2Vecモデルを作成します。
モデルの学習
gensimを用いてWord2vecのモデルの作成を行います。下記がモデルを作成するに当たっての主要なパラメータになります。
| パラメーター名 | パラメータの意味 |
|---|---|
| dm | 1ならPV=DMで0ならPV-DBOWで学習する |
| vector_size | 文章を何次元の分散表現に変換するかを指定 |
| window | 次の単語の予測に何単語を用いるか(PV-DMの場合) 又は、文書idから何単語を予測するか(PV-DBOWの場合) |
| min_count | 指定の数以下の出現回数の単語は無視する |
| wokers | 学習に用いるスレッド数 |
下記がDoc2Vecのモデルを作成するコードになります。投入するテキストさえ作成できていれば一行でモデルの作成が可能です。
sentences = []
for text in df[3]:
text_list = text.split(' ')
sentences.append(text_list)
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(sentences)]
model = Doc2Vec(documents, vector_size=2, window=5, min_count=1, workers=4)
Doc2Vecでできること
Doc2Vecのモデルによって文章の分散表現を獲得することができました。文章の分散表現を用いると文章間の意味的な距離を定量的に表すことができます。
先ほど作成したモデルで下記ニュース記事と近い内容記事はどんなものがあるかを調べて見ます。
'19日(土・日本時間)南アフリカW杯・日本×オランダ戦は、日本代表の健闘空しく、
後半にはスナイデルのゴールでリードを許すと、ばん回できないまま0-1で敗れた。
試合後、テレビ朝日の中継で解説を担当した元日本代表の司令塔・中田英寿氏は、
「まあ、0-1で負けたとはいえ、一戦目に比べるとチームも格段にいい戦いになって、特に後半なんかは日本もいい攻めをしていましたし、次に繋がる一戦になったのではないかと思います」と感想を述べた。
また、「(ズルズルと失点するケースもあるが)そこをきちんと守りきった上で自分達の攻撃を繋げていく。
特に最後は岡田監督も攻撃の選手を早いうちから使い、その姿勢というのは次の試合に繋がっていく。
この試合は負けてもいいわけじゃなく、勝ちにいく姿勢が見えたっていうのは大きい」と語った。'
下記で指定のドキュメントと似ているドキュメントを出力することができます。
# ドキュメントのidを渡してそれと距離の近いドキュメントを出力(今回の場合5792が上記記事のid)
model.docvecs.most_similar(5792)
出力はこちら。ドキュメントのidとそれとのコサイン類似度をセットで返します。
[(6084, 0.8220762014389038),
(5838, 0.8150338530540466),
(6910, 0.8055128455162048),
(351, 0.8003012537956238),
(6223, 0.7960485816001892),
(5826, 0.7933120131492615),
(6246, 0.7902486324310303),
(6332, 0.7871333360671997),
(6447, 0.7836691737174988),
(6067, 0.7836177349090576)]
類似度上位の記事の中身を見てみます。
## 6084の記事内容
'ロンドン五輪出場を目指すサッカー・U-22日本代表。
二次予選はクウェート一カ国と戦うホーム&アウェイ戦となっている。
注目を集めるのは、U-22代表戦11試合で8ゴールを誇る日本のエース・永井謙佑(名古屋グランパス)だ。
18日深夜放送、TBS「S-1」は、50mを5.8秒で駆け抜ける期待の俊足FWに迫った。
「よーいドンは負けない」という永井は「自分ではよく分からないですけど、速いみたいですね。
(足が速くなったのは)高校2年くらいです」と他人事のように語るも、“永井のスピード伝説”として、高校時代を知る友人は、番組のカメラに「車、40キロくらいを追い付く。
あいつ走って」と話し、九州国際大付属高校時代の恩師・杉山公一監督は「自分で出したスルーパスに逆サイドの子がオフサイドだったので、そのまま自分で追いかけてドリブルになったりとか、そういうことはよくありました」と明かした。
また、俊足サッカー選手と言えば、“野人”岡野雅行があまりにも有名だが、岡野について訊かれた永井は「あんなに速くないですよ」と苦笑い。
高校入学時は、小柄で足も速くなかったという永井は、「よく倒れたり、戻したりしてました」、「タイミングが合ったというか、彼の成長が、身体の成長とトレーニングがうまくあったのかも知れません」と杉山監督が振り返る同高校の名物=坂道&階段を使った地獄のトレーニングによって、その能力が開花したようだ。'
## 5838の記事内容
'29日深夜放送、TBSのスポーツ番組「S1」では、ゲスト解説のラモス瑠偉が、日本代表監督が決まらぬ現状に怒りを露わにした。
W杯出場国で代表監督が決まっていない国が、日本と北朝鮮のみという現状、「いや、情けなさすぎるよ。特に選ばれた選手達のモチベーションは下がります。
今回のメンバーを見ていると、稲本と玉田、どういう理由で選ばれていないのか」と露骨にムッとした表情で話しはじめるラモス。
「ラモスさん、やっちゃえばいいじゃないですか?」という声がかかると、「いや、やりたいですよ。それは間違いないです」とキッパリ言い放ち、また、「僕だったら、選ばれてもいかない。現役の時だったら。遅すぎる。本当に情けない。寂しい」と続けるのだった。'
上位2つはどちらともサッカーの話題であることがわかります。また学習したコーパスは9つのニュースサイトの記事から構成されていますが、類似度上位10件中8件がスポーツのニュースサイトの記事となっていました。
このように文章を固定長のベクトル表現に変換することができれば、クラスタリングや分類など様々な機械学習アルゴリズムに適用させることが可能になります。
自然言語処理の世界ではいかに表現力の高いベクトル表現を獲得するか、という点が非常に重要で、今回ご紹介したDoc2Vecをはじめとして様々なアルゴリズムが開発されています。
Next
このDoc2Vecのモデルを使用して、様々な自然言語処理タスクに挑戦してみようと思います。