はじめに
自然言語処理タスクでBERTをfinetuningして使うことが当たり前になってきました。Kaggleなどのコンペや精度要件がきつい案件を行う場合に少しでも精度を向上させたいというシーンが増えてくると考えられます。そこで、精度向上手法をまとめます。タスクとしては分類タスクを想定しています。
文字数調整
学習済みのBERTに入力可能な単語数は最大512個です。そのため、512単語以上のテキストを使用する場合は特別な工夫が必要となります。ここの処理方法の変更が精度向上に寄与することが多いので要チェックです。
例として次のテキストから6単語取得することを考えます(句点も1単語とします)
吾輩 / は / 猫 / で / ある / 。 / 名前 / は / まだ / ない / 。
1. Head-Tail
吾輩 / は / 猫 / で / ある / 。 / 名前 / は / まだ / ない / 。
How to Fine-tune BERT for Text Classificationより。先頭と最後尾、両方から単語を取得します。上図では先頭から3単語、最後尾から3単語を使用する様子を示しました。実装が簡単かつ高性能でKaggleでもよく用いられている手法です。前後何単語ずつ取ればよいかはケースバイケースです。
2. Random
吾輩 / は / 猫 / で / ある / 。 / 名前 / は / まだ / ない / 。
吾輩 / は / 猫 / で / ある / 。 / 名前 / は / まだ / ない / 。
任意の場所から連続して単語を取得します。Epochごとに取得する場所を変更すればAugmentationのような効果が期待できます。ただし、Head-Tailの手法ほど精度が上がる印象はありません。TTA(Test Time Augmentation)と組み合わせてどうかといったところ。
3. Sliding Window
吾輩 / は / 猫 / で / ある / 。 / 名前 / は / まだ / ない / 。
吾輩 / は / 猫 / で / ある / 。 / 名前 / は / まだ / ない / 。
吾輩 / は / 猫 / で / ある / 。 / 名前 / は / まだ / ない / 。
A BERT Baseline for the Natural Questionsなど、Google's Natural Question Datasetでよく用いられる手法です。上図では3単語ずつずらした場合を示しました。データを完全にカバーできるのが強み。単語数が多いデータだと学習データが多くなりすぎるのが欠点です。QAタスクなどですべての単語を使用することが重要な場合に用いられますが、分類タスクの精度向上にも寄与する可能性があります。
追加メタ情報
次のような質問と回答およびタイトルを入力する場合を考えます。
タイトル:トランプ大統領について
質問:トランプ大統領の出身地はどこですか?
回答:ニューヨークです。
4. セパレーターの追加
[CLS]トランプ大統領について[NEW_SEP]トランプ大統領の出身地はどこですか?[SEP]ニューヨークです。[SEP]
Google QUEST Q&A Labeling 19th solutionより。BERTにおいて2つ文章がある場合は[SEP]タグで区切るので大丈夫ですが、それ以上の文章には対応していません。そこで、[NEW_SEP]のように、適当な名前のトークンを定義してセパレーターに使うことで、文章の区切りを表現することができます。このようなトークンはtokenizer.add_special_tokensを使って追加できます。また、英語版のBERTの場合は[unused0]~[unused993]まで未使用トークンがあるため、それも使うことができます。
5. カテゴリ情報の追加
[CLS][CATEGORY_0]トランプ大統領の出身地はどこですか?[SEP]ニューヨークです。[SEP]
Jigsaw Unintended Bias in Toxicity Classification 1ST PLACE SOLUTIONなど。上の文章が適切な問いと回答のペアになっているかどうかを判断するタスクを解くとしましょう。質問応答のログはカテゴリ分類がなされていることが多いので特徴量に追加したいときがあります。その場合、上記のように新しいトークン[CATEGORY_0]~[CATEGORY_n](n はカテゴリ数)を定義して文章に組み込むことで精度の向上が狙えます。
また、[CATEGORY_0]のベクトルを特徴量としてカテゴリ分類をサブタスクとして実施するのも有効です。
モデル構築
BERTの通常モデルは12層のサブモジュールから構成されています。BERTをfinetuningする場合は最終層の出力の先頭 [CLS] のベクトルを特徴量とすることがデフォルトの実装です。精度としてはそれで十分なことも多いですが、他の特徴量を使うことで若干の精度向上が期待できます。
6. 最終層から4層を使用する
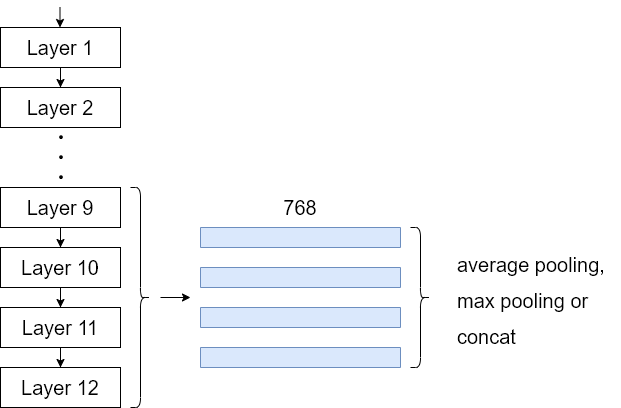
How to Fine-tune BERT for Text Classificationより。12層のうち下から4つの [CLS] ベクトルを組み合わせることでfinetuningタスクの精度向上を狙います。ベクトルはaverage pooling、max pooling、concatなどを使って最終的に768次元のベクトル(1階のテンソル)にします。
7. Learnable Weighted Sum
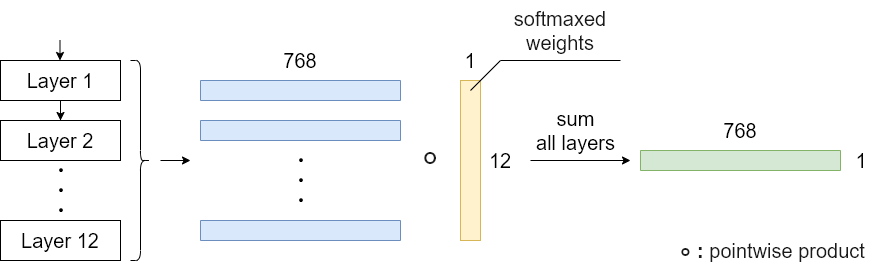
Google QUEST Q&A Labeling 1st place solutionより。学習可能な重みをモデルに設定して、すべてのBERT Layer の[CLS]ベクトルの重み付き和を計算します。単に全レイヤーの平均も十分有力な手法ではありますが、それをさらに発展させた手法と言えます。
8. CNN層を追加する
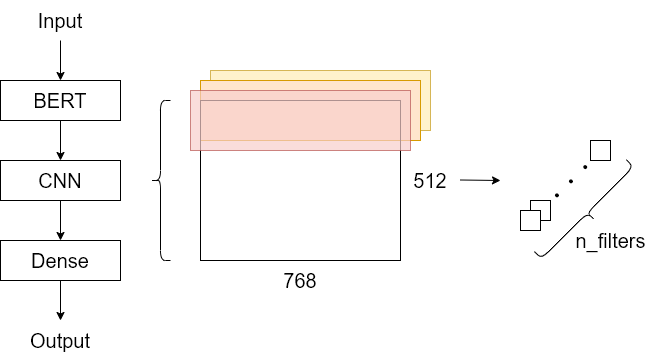
Identifying Russian Trolls on Reddit with Deep Learning and BERT Word Embeddingsなど。[CLS] のベクトルだけでなく、すべての単語のベクトルをCNNに入力するのも有力な手法のひとつです。図のように最大512個のシーケンス長に対して1次元の畳み込みを計算します。畳み込みを計算したあとはmax poolingまたはaverage poolingを行うと、次元数がfilter数の特徴量が抽出できるので、それらをDenseに入力します。CNNはAttentionと比べて周辺単語の特徴を集約することができるため、組み合わせることによって精度向上が狙えます。また、CNNだけでなくLSTMと組み合わせるのも有効です。
学習
9. BERTの重みを固定する
model_params = list(model.named_parameters())
# BERTの重みを固定する
params = [p for n, p in model_params if not "bert" in n]
optimizer = AdamW(params , lr=2e-5)
# BERTの重み固定を解除する
params = [p for n, p in model_params if "bert" in n]
optimizer.add_param_group({'params': params })
Google QUEST Q&A Labeling 19th solutionより。画像系の学習済みモデルと同様に、BERTも重みを固定して、タスク依存のレイヤーのみを学習すると精度が向上する場合があります。19th solutionでは、最初の1 epoch目だけを固定し、後から全レイヤーを学習しています。上記には、BERTの重みを固定して学習を開始するコード、途中から固定を解除して学習を再開するときに使えるコードを記載しました。
10. BERTとそれ以外のレイヤーの学習率を変更する
model_params = list(model.named_parameters())
bert_params = [p for n, p in model_params if "bert" in n]
other_params = [p for n, p in model_params if not "bert" in n]
params = [
{'params': bert_params, 'lr': params.lr},
{'params': other_params, 'lr': params.lr * 500}
]
Google QUEST Q&A Labeling 1st place solutionより。異なる学習率を採用するのも画像系の学習済みモデルと同様に有効です。1st place solutionではタスク固有のレイヤーを通常の500倍の学習率で学習しています。そのときのコードを上に示しました。
おわりに
BERTの分類タスクで精度が上がるかもしれない手法を紹介しました。ただ、どれくらい精度が向上するのかは具体的には示せなかったので、そのうち適当なデータセットで比較してみたいと思っています。上に挙げた以外にもまだまだ精度向上の手法が出てきているので引き続き調査を続けます。