更新情報 -目次-
- はやくもUI改善等 Ver.upが図られています。以下内容の記事を追加しました。
1. データフレーム表示
2. ヒストグラムの描き方
3. ダークモード対応
4. オンライン版
5. 海外のデータイノベーション支援団体でも人気
はじめに
Tableauはご存じでしょうか?
私は使ったことはありませんが、名前だけはよく耳にします。
これは、専門家でなくてもデータの収集・分析・加工ができるBI(ビジネス・インテリジェンス)ツールのひとつです。
なんと、Jupyter Notebook上(Google ColabもOK)で実行できる Tableau風 BIツール「PyGWalker」が登場しました。
Tableauそのものではありませんが、ドラッグ&ドロップの簡単な操作でデータ分析や視覚的な探索が実行できます。
こんなのが出てくるとは・・・すごい。
しかも、数行のコードで実行できる・・・早速やってみました。
用語の説明
PyGWalker
PyGWalkerは、Jupyter Notebookのデータ解析とデータ可視化を支援するライブラリ。Jupyter NotebookとGraphic Walkerを統合し、Tableauとは異なるタイプのオープンソースの代替となるもの。ドラッグ&ドロップの簡単な操作でデータ分析や視覚的な探索が実行できる。
- pandasのデータフレームをTableauスタイルのユーザインタフェースに変換することで、視覚的な探索を可能にしたもの。
- PyGWalker:Python binding of Graphic Walker(通称"Pig Walker")
Tableau
Tableauは、膨大なデータの収集・分析・加工が専門家でなくてもできるBI(ビジネス・インテリジェンス)ツールのひとつ。Tableauは2003年にスタンフォード大学のプロジェクトから誕生。BIやデータドリブンな意思決定を支援するツールとして広く利用されている。
実行条件など
-Google colabで実行
-任意のデータセットとsklearn等のデータセットを読み出せるようにしています。
実行コードについて
データ読込み等を除くと、実行コードは以下の3行だけ! です。(※データ読込み含めた実行コードは以下にあります。)
!pip install pygwalker
import pygwalker as pyg
gwalker = pyg.walk(df)
PyGWalker実行
「Titanic :binary」で実行してみました。実行するとセルに以下が出てきます。
Field Listに「Titanic :binary」データセットのカラム名が表示されています。
※2/28) UI更新により、Columns → X-Axis に、Rows → Y-Axis に変更されました。

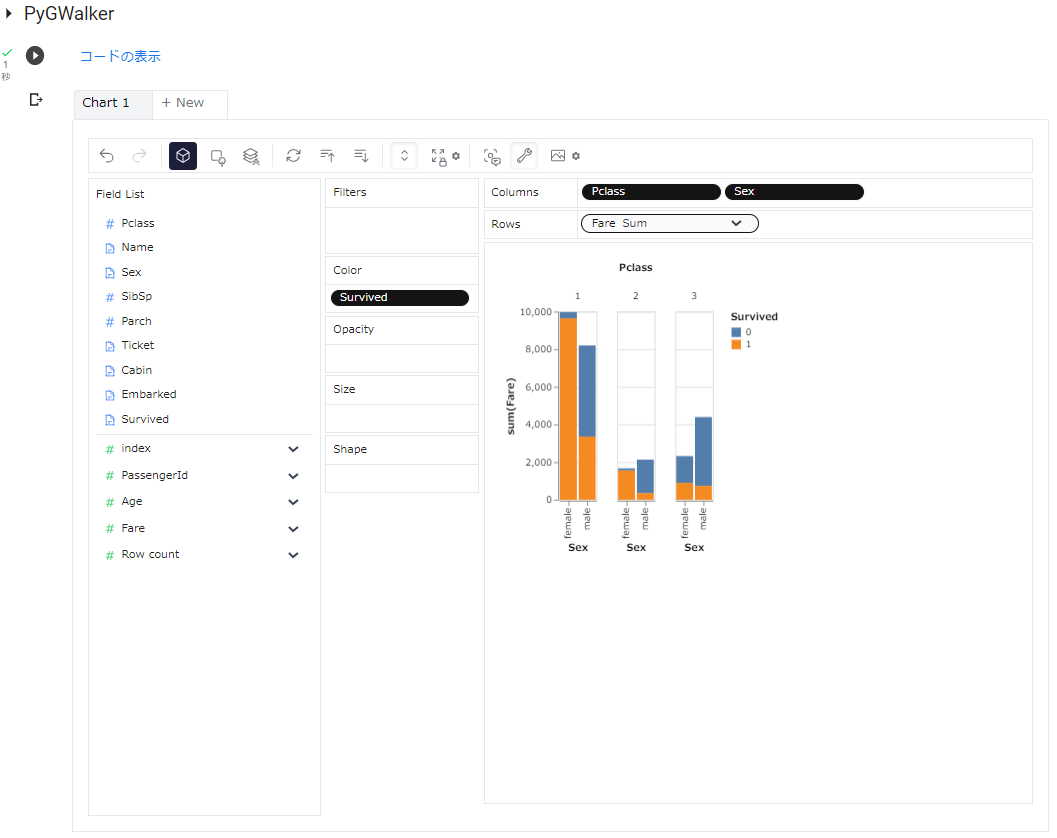
Field Listの「Pclass」と「Sex」をドラッグし、Columnsにドロップ、「Fare」をRowsにドロップ、「Survived」をColorにドロップしてみました。ドロップした状態に沿ってグラフが変わりますので、直感的でとてもわかりやすいです。
以下のようにfacet的な視覚化ができるのはありがたいなぁ。
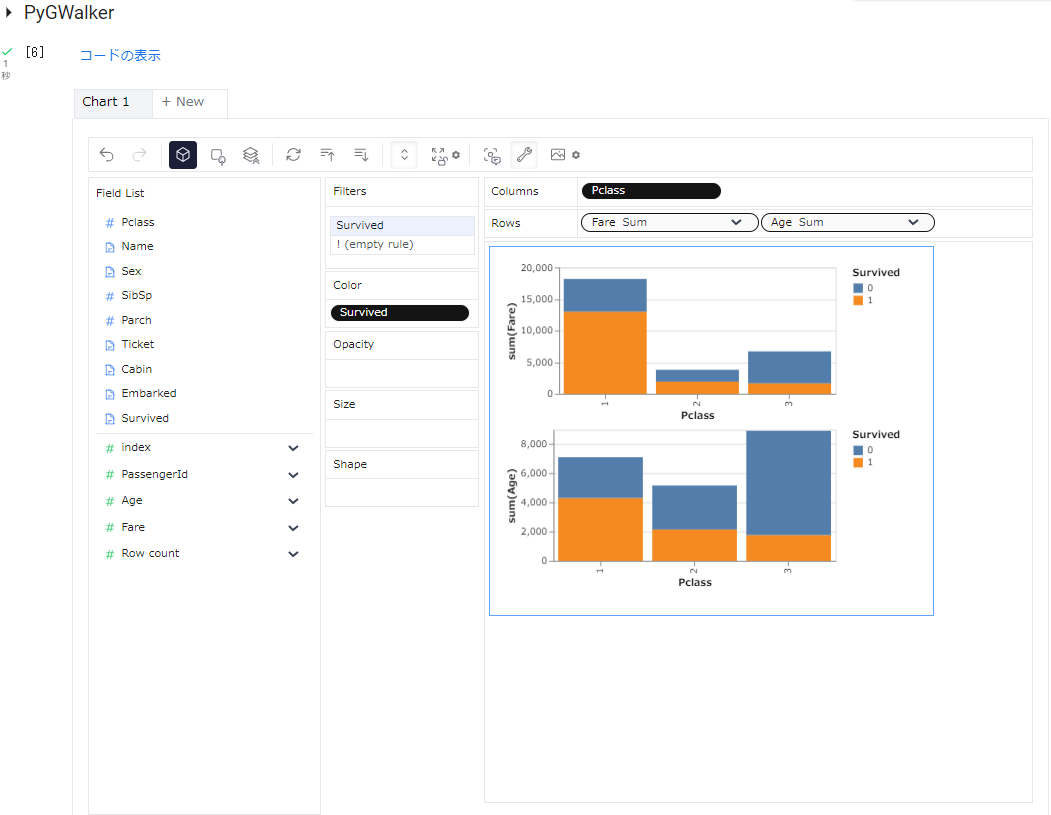
Columnsにドロップした「Sex」をドラッグし、項目欄外でドロップして設定から外し、「Age」をRowsにドロップして追加しました。以下のように2つの要素が並んで表示されます。
次は、「Age」をColumnsに、「Fare」をRowsに、「Survived」をColorに、「Sex」をOpacityにドロップし、以下のようにグラフを [Scatter](散布図)に変更し、表示させました。
グラフを囲む青い罫線をドラッグすると、グラフサイズも変えられます。右クリックで「画像をコピー」を選択すれば、グラフだけをExcel等に添付することもできます。
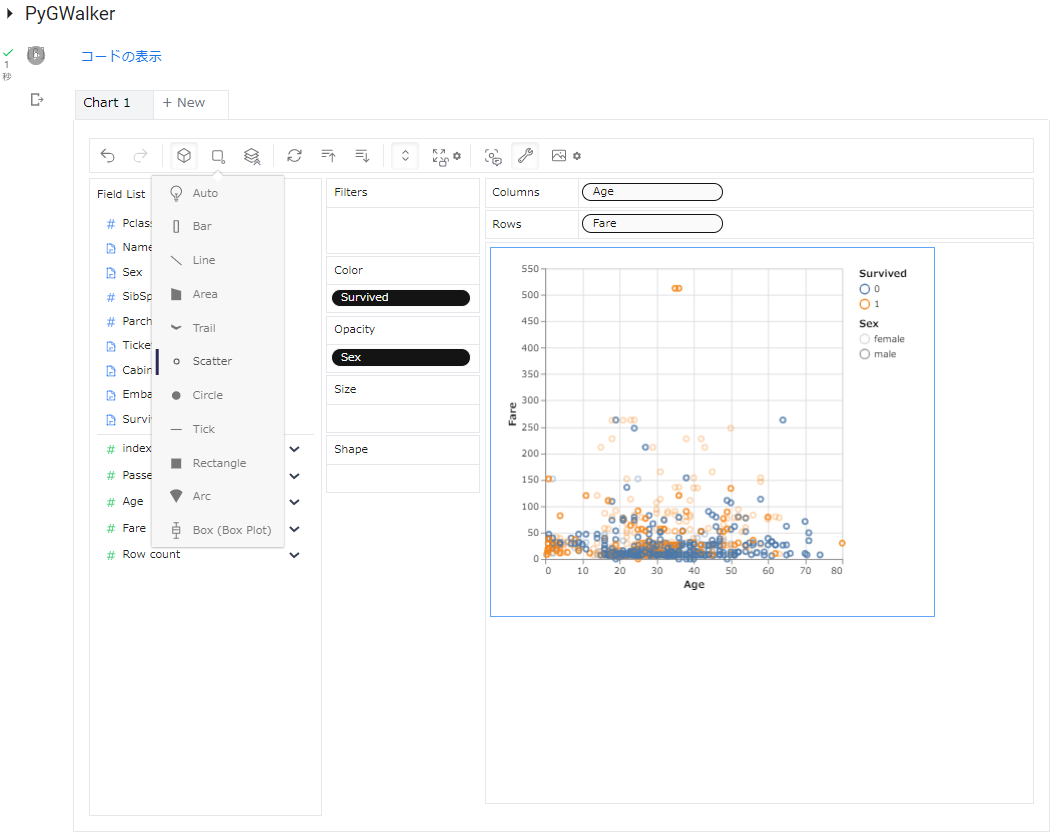
また、「Sex」をShapeにドロップすると、プロットの形が変更されます。
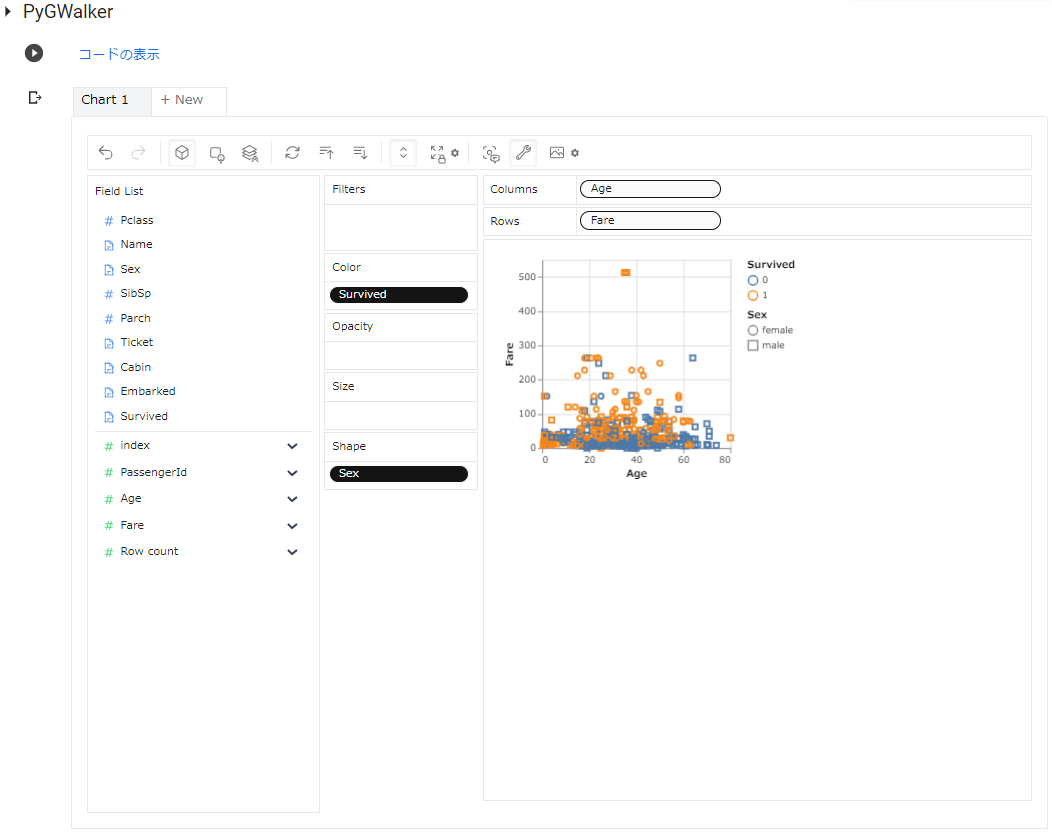
亡くなってた方(「Servived:0」)は「Fare」が安かった方が多い・・・しかも男性ばかり・・・ という状況がよくわかりますね。
また、以下のように「キューブマーク」をクリックすると、ColumnsとRowsにドラッグした表示が変わります。ドロップダウンから Mean、Max、Min、Variance等を選択することができ、選択に応じ、グラフが切り替わります。
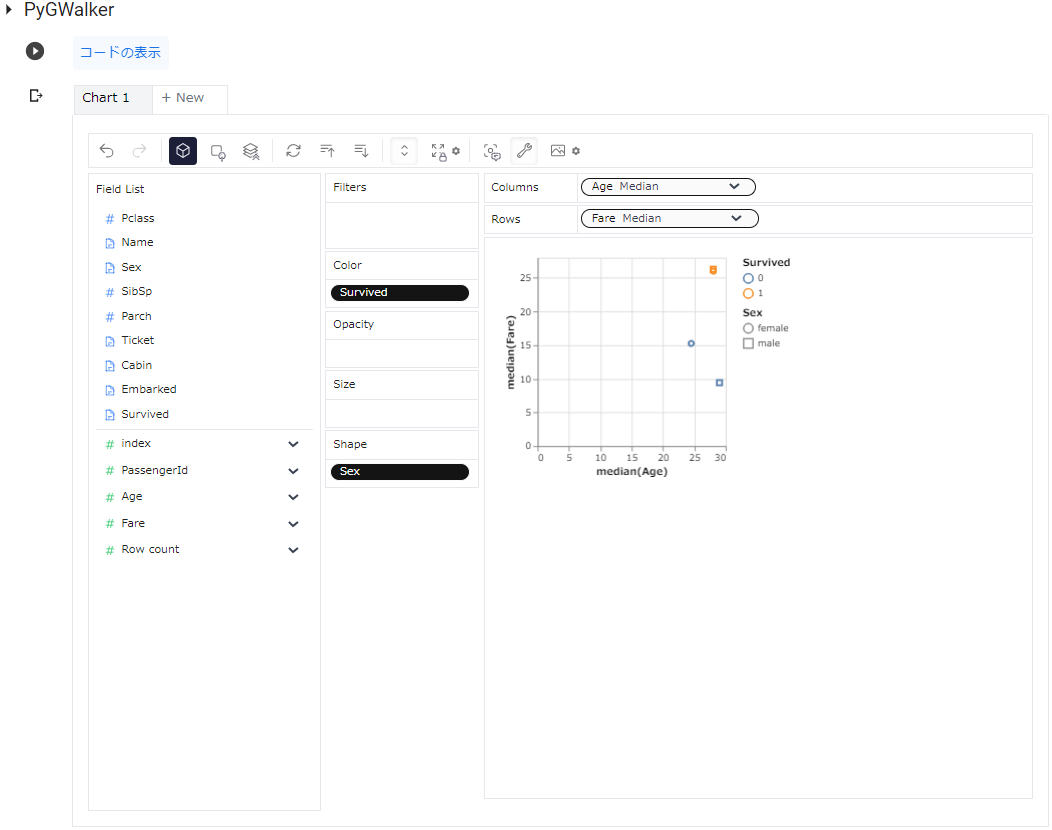
このように、PyGWalker は 手元操作で試行錯誤しながらデータが探索できますので、
ちょっとこのデータ、どんなものか見てやろう
という時に大いに活用できそうです。
最後に
視覚的データ探索が直感的にサクサクできます。すごいです。すごくいいです。
2変数の単純なグラフ化だけではなく、多角的なデータの見方を支援してくれるツールになっていますので、描くことで、視覚化することで気づきを得る可能性を高められそうです。
以下の実行コードでは、他のデータセット、任意のデータセットも読めるようにしていますので、ご興味持たれた方は、一度実行してみてください。
備考
以下は、Pythonでできるデータ視覚化に関する書籍の紹介です。
視覚化のバラエティが拡がるほど、ビジネス・インテリジェンスのスキルも向上するはず。
視覚化に興味あるけどPythonはちょっとなぁ・・・ という方、一読を検討いただければ幸いです。
実行コード
!pip install pygwalker
#@title Select_Dataset { run: "auto" }
#@markdown **<font color= "Crimson">注意</font>:かならず 実行する前に 設定してください。**</font>
dataset = 'Titanic :binary' #@param ['Boston_housing :regression', 'Diabetes :regression', 'Breast_cancer :binary','Titanic :binary', 'Titanic(seaborn) :binary', 'Iris :classification', 'Loan_prediction :binary','wine :classification', 'Occupancy_detection :binary', 'Upload']
#@title Load dataset
#ライブラリインポート
#import numpy as np #数値計算ライブラリ
import pandas as pd #データを効率的に扱うライブラリ
import seaborn as sns #視覚化ライブラリ
import warnings #警告を表示させないライブラリ
warnings.simplefilter('ignore')
'''
dataset(ドロップダウンメニュー)で選択したデータセットを読込み、データフレーム(df)に格納。
目的変数は、データフレームの最終列とし、FEATURES、TARGET、X、yを指定した後、データフレーム
に関する情報と先頭5列を表示。
任意のcsvデータを読込む場合は、datasetで'Upload'を選択。
'''
#任意のcsvデータ読込み及びデータフレーム格納、
if dataset =='Upload':
from google.colab import files
uploaded = files.upload()#Upload
target = list(uploaded.keys())[0]
df = pd.read_csv(target)
#Diabetes データセットの読込み及びデータフレーム格納、
elif dataset == "Diabetes :regression":
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
df = pd.DataFrame(diabetes.data, columns = diabetes.feature_names)
df['target'] = diabetes.target
#Breast_cancer データセットの読込み及びデータフレーム格納、
elif dataset == "Breast_cancer :binary":
from sklearn.datasets import load_breast_cancer
breast_cancer = load_breast_cancer()
df = pd.DataFrame(breast_cancer.data, columns = breast_cancer.feature_names)
#df['target'] = breast_cancer.target #目的変数をカテゴリー数値とする時
df['target'] = breast_cancer.target_names[breast_cancer.target]
#Titanic データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic :binary":
data_url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
df = pd.read_csv(data_url)
#目的変数 Survived をデータフレーム最終列に移動
X = df.drop(['Survived'], axis=1)
y = df['Survived']
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#Titanic(seaborn) データセットの読込み及びデータフレーム格納、
elif dataset == "Titanic(seaborn) :binary":
df = sns.load_dataset('titanic')
#重複データをカットし、目的変数 alive をデータフレーム最終列に移動
X = df.drop(['survived','pclass','embarked','who','adult_male','alive'], axis=1)
y = df['alive'] #目的変数データ
df = pd.concat([X, y], axis=1) #X,yを結合し、dfに格納
#iris データセットの読込み及びデータフレーム格納、
elif dataset == "Iris :classification":
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
#df['target'] = iris.target #目的変数をカテゴリー数値とする時
df['target'] = iris.target_names[iris.target]
#wine データセットの読込み及びデータフレーム格納、
elif dataset == "wine :classification":
from sklearn.datasets import load_wine
wine = load_wine()
df = pd.DataFrame(wine.data, columns = wine.feature_names)
#df['target'] = wine.target #目的変数をカテゴリー数値とする時
df['target'] = wine.target_names[wine.target]
#Loan_prediction データセットの読込み及びデータフレーム格納、
elif dataset == "Loan_prediction :binary":
data_url = "https://github.com/shrikant-temburwar/Loan-Prediction-Dataset/raw/master/train.csv"
df = pd.read_csv(data_url)
#Occupancy_detection データセットの読込み及びデータフレーム格納、
elif dataset =='Occupancy_detection :binary':
data_url = 'https://raw.githubusercontent.com/hima2b4/Auto_Profiling/main/Occupancy-detection-datatest.csv'
df = pd.read_csv(data_url)
df['date'] = pd.to_datetime(df['date']) #[date]のデータ型をdatetime型に変更
#Boston データセットの読込み及びデータフレーム格納
else:
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns = boston.feature_names)
df['target'] = boston.target
#FEATURES、TARGET、X、yを指定
FEATURES = df.columns[:-1] #説明変数のデータ項目を指定
TARGET = df.columns[-1] #目的変数のデータ項目を指定
X = df.loc[:, FEATURES] #FEATURESのすべてのデータをXに格納
y = df.loc[:, TARGET] #TARGETのすべてのデータをyに格納
#データフレーム表示
df.info(verbose=True) #データフレーム情報表示(verbose=Trueで表示数制限カット)
df.head() #データフレーム先頭5行表示
#@title PyGWalker
import pygwalker as pyg
gwalker = pyg.walk(df)
更新情報
1. データフレーム表示
以下のように、上部に [Data] と [Visualization] というタブが追加されました。
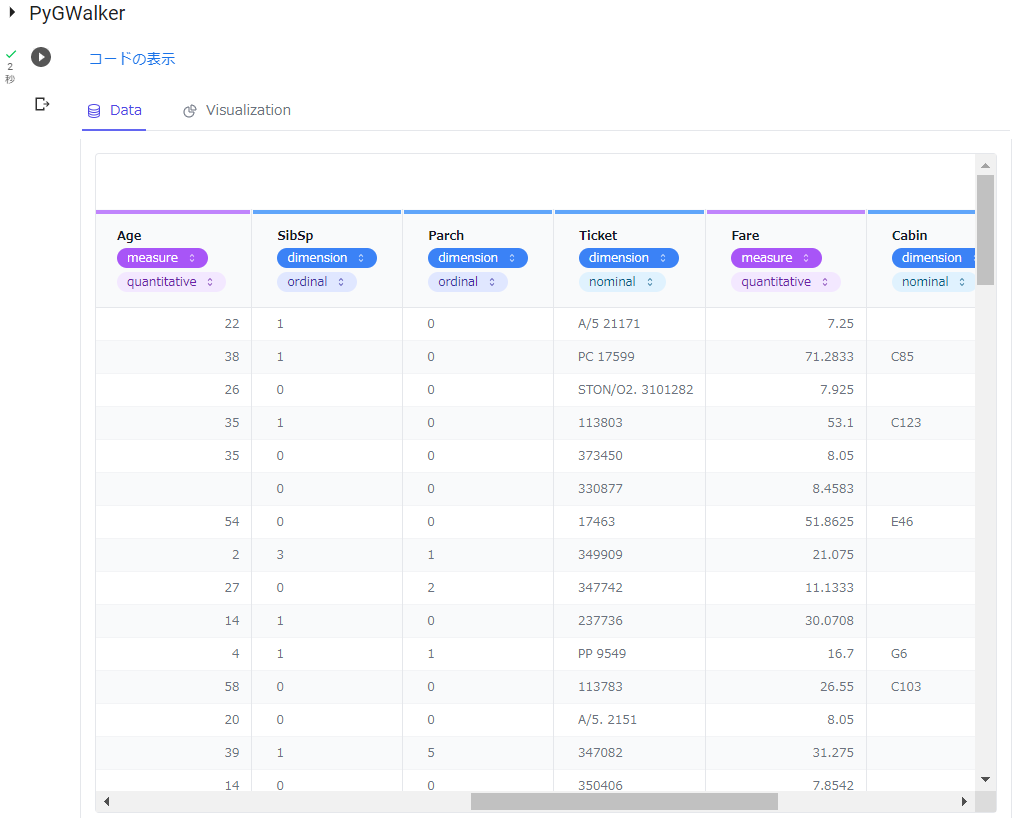
[Data]のタブをクリックすると、データフレームが表示されます。データ型も変更できそう・・・すごい。
2. ヒストグラムの描き方
以下のように、Field Listの「Fare」を左クリックすると [Bin]と[Log10] が表示され、[Bin]をクリックすると、Field Listに「bin(Fare)」が追加されます。
以下は、「bin(Fare)」をX-Axisに、「Row Count」をY-Axisにドロップし、表示させたヒストグラムです。
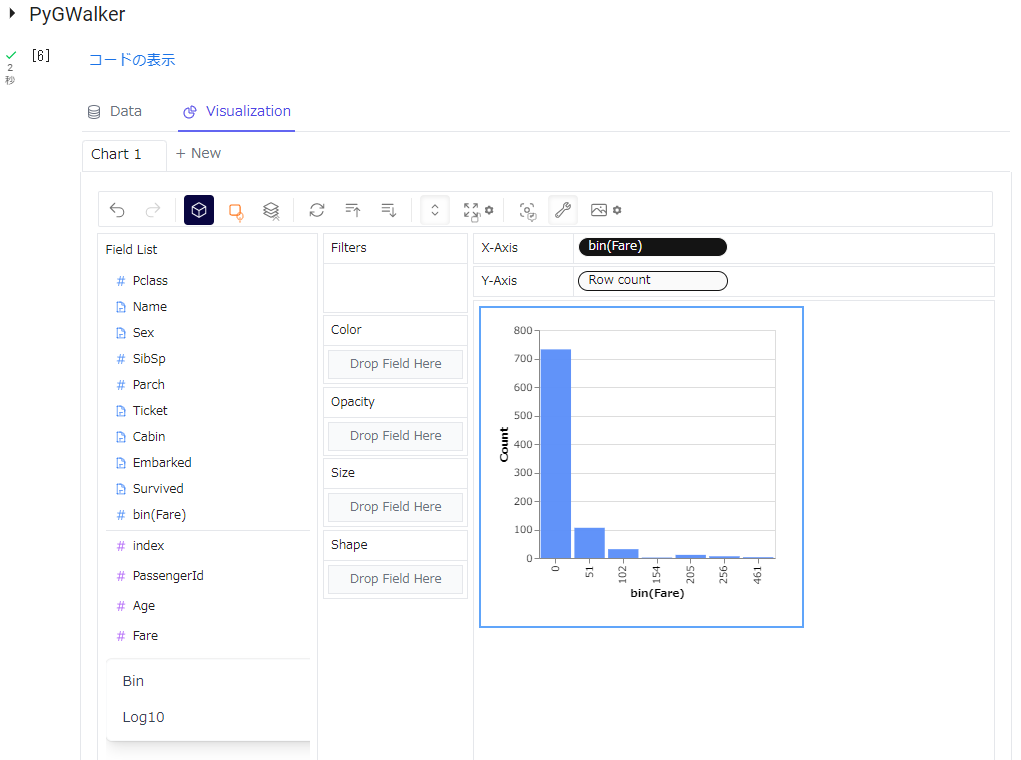
「Survived」をColorにドロップすると、以下のようになります。
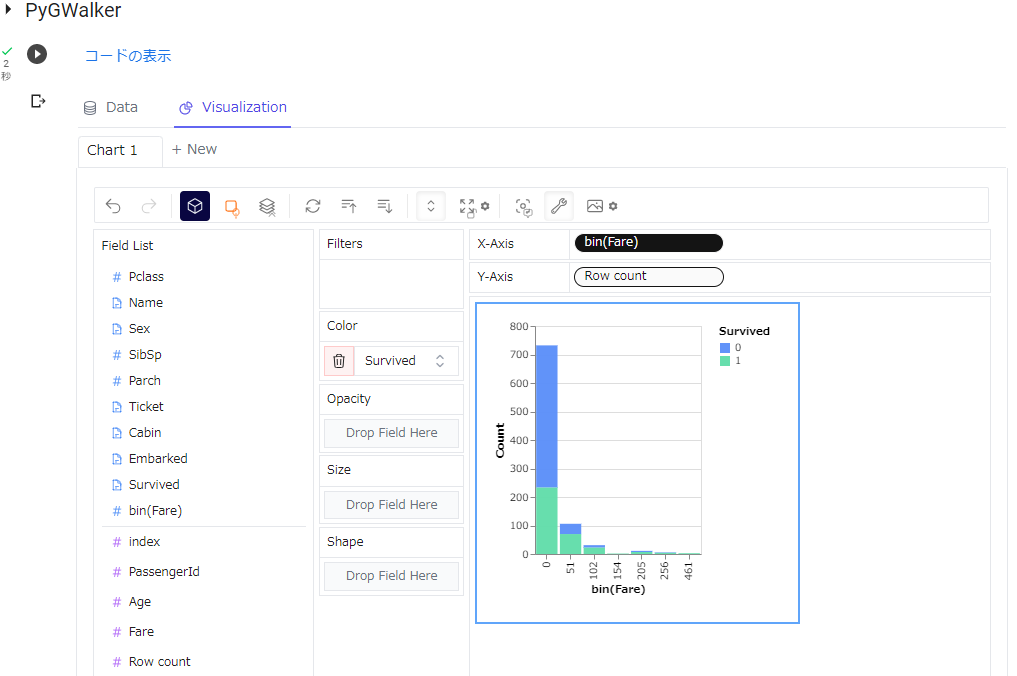
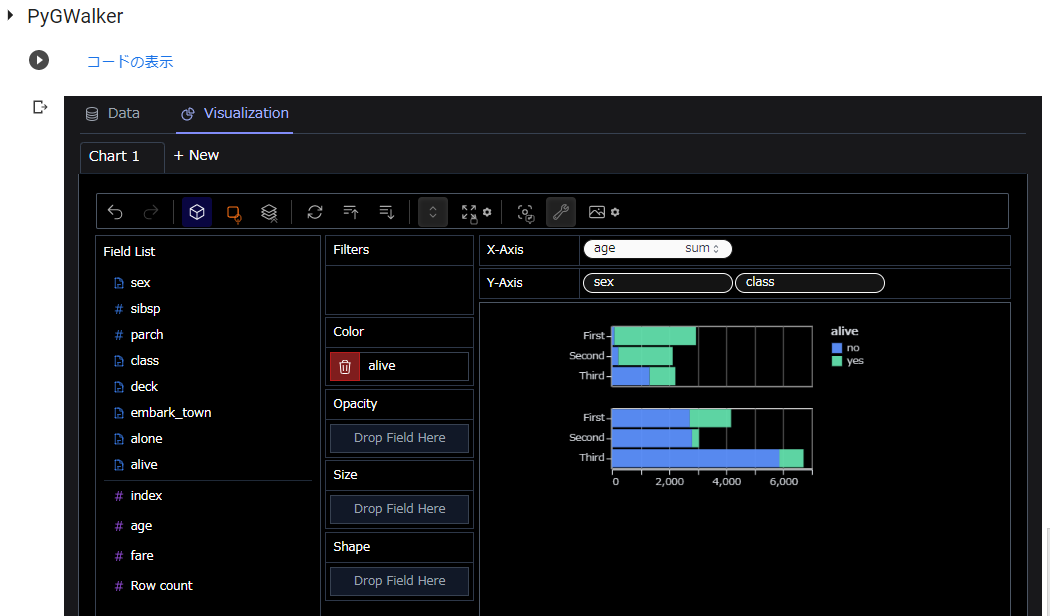
3. ダークモード対応
使用しているPCやiOSデバイス等をダークモードにすると・・・
4. オンライン版
5. 海外のデータイノベーション支援団体でも人気
参考