追記2: EfficientNetV2も仲間に入るってTwitterで言うてるんで、さらに追記。
追記: ViTの中の人から物言いが入ってるんで、追記しました。
ViTが出てから、画像認識向けでもTransformer系が一気に流行り、Swine Transformerで、ピラミッド構造ありTransformer系がSOTAという流れになってたけれど、比較対象のCNNが古いResNetってどうよ? もう2020年代に入って随分経つんだし、ちゃんと新しい手法入れたConvと比べようよ。ってことで、FAIRからConvNeXtってのが出ました。
A ConvNet for the 2020s
同規模間の画像認識でSOTAだそうです。
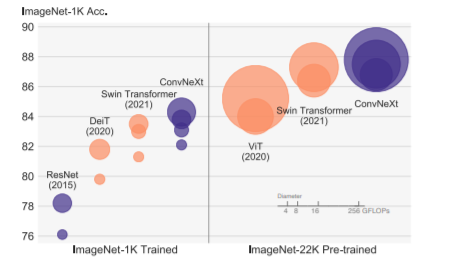
Object detectionでもinstance segmentationでもsemantic segmentationでも、今までのと同じくらいか、更に良いそう。
TransformerだMLPだと、あれだけ言って、結局Convに戻って来たなら、なかなか面白い。
と、言うことで、ちょっと詳しく見て行こうと思う。
あ、注意、普通のConvはなくて、Depthwise Convを使っている。
追記: ViTの中の人がTwitter上で、ViTの実力は、そんなんじゃないとおっしゃっているので、そちらも。まあ、そもそもViTの学習手法は、すぐさまDeiTに塗り替えられたわけで、どれをオフィシャルと言うかは、いろいろありそうだけれども。Twitterの中で、Referしてる論文は以下。
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers

追記2: EfficientNetV2の中の人が仲間に入りたいそうで。さすがに、NAS系は仲間外れで良いんじゃないかとは思うけど。
EfficientNetV2: Smaller Models and Faster Training
新しい学習手法を使う
ResNetの時代から、どんどん進化している学習手法をきちんと追加。
- AdamW optimizer
- data augmentation: Mixup, Cutmix, RandAugment, RandomErasing
- regularization: SStochastic Depth, Label Smoothing
- 300 Epoch学習(元は90)
と、ここまでやると、元のResNet-50が、76.1%から78.8%に上がる。
これだけで、かなりの上がり具合。
大きく構造を変える
今までのCNN構造の英知を集め、更にTransformer系のピラミッド構造を元に、手を加える。
ピラミッド構造の層を変更
今までのResNet-50のピラミッド構造は、(3, 4, 6, 3)だったけど、これをSwine Transformerの構造を元に(3, 3, 9, 3)に変更。
計算量は、Swin-Tくらいになる。
これで、精度が78.8%から79.4%に。
STEMを変更
Swine TransformerのSTEMを元に、今までのSTEM:
7x7 Conv stride=2
3x3 maxPool stride=2
を
4x4 non overlapping conv stride=4
に変更。
計算量がちょっと減って、精度がちょっと上がる。
いろんなConvのアイディアを入れる
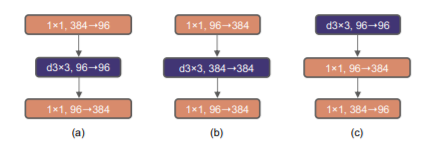
ResNeXtのアイディアを使い、Depthwise Convにして、代わりにWidthを大きくする。(a)
ResNet-50のチャンネル数は、Swin-Tに合わせる。
これで、精度は、79.5%から、80.5%に。
次に、ResNetのBottleneck構造をInverted Bottleneck構造に変えて、計算量を削減。(b)
何故か、これでも精度が上がり、80.6%に。ResNet-200の方は、更に大きく良くなっている。
更に、3x3 Depthwise Convの位置を変えて、TransformerのMSA blockとMLP blockのようにして、計算量を削減。(c)
これだけだと精度が下がるが、この後、カーネルサイズを3x3から大きくして行く。7x7で80.6%に戻るが、計算量は増えない。
これらのアイディアを図示すると以下。
更に細かく変更
これまでのいろいろなNNのアイディアを入れていく。
ReLUはGELUに変更。BNはLNに変更。
Transformerを見るとReLUもBNもCNNと比較してずいぶん少ないので、以下のように減らしてみる。
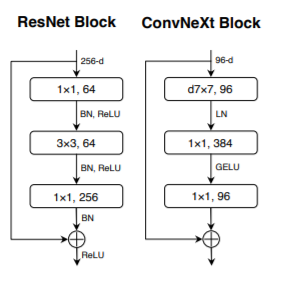
ReLUからGELUに変更して、GELUを減らすだけで、0.7%良くなる。
それから、BNをLNに変更して、LNを減らすと更に良くなる。
downsamplingをSwine Transformerのように、層の間に2x2 Conv stride=2に変更すると、そのままでは、学習がうまく行かないので、LNを入れて安定化させる。これで、更に精度が上がる。
まとめ
ということで、これらのステップをまとめた結果がこちら。
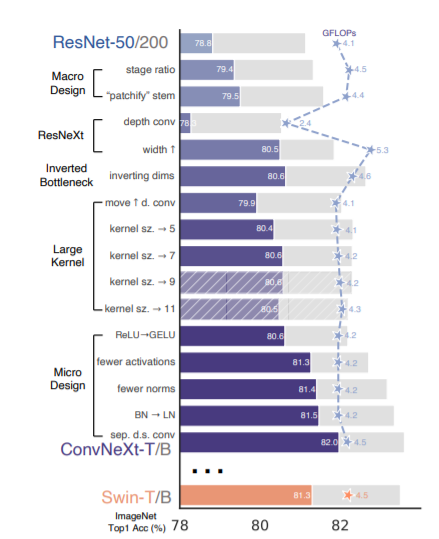
新しい子の名前はConvNeXtだそうです。