はじめに
このアドベントカレンダーでは,Intel/AMDのCPUで使われるSIMD命令であるAVX/AVX2/AVX512に関する記事を募集しています.
埋まらないときは,現在書いているドキュメント(AVX Complete Guide(仮))の文書の一部を抜粋してアドベントカレンダー埋めていきます.研究室のゼミ資料がベースですので,一応入門的なことが多くなります.
間違っている所などありましたらコメントいただけると幸いです.
希望があればコメント欄に書いていただければそこの記事を埋めます.
一人で埋めてるのはサビシイので,どんな記事でも歓迎です!
SIMD
SIMD (single instruction multiple data) とは,一つの命令を複数データに対して同時に発行し,並列に計算する方法のことです.例えば,SSEによる加算なら,32ビット浮動小数点の配列に入っている4つのデータを1命令で実行可能です.これがAVXになると8つのデータを,AVX-512になると16個のデータを1命令で実行可能です.つまり,データ1つづつ計算するよりもベクトル長倍(4,8,16倍)の効率で動きます.
SIMDは,英語ではシムディ,エスアイエムディ,日本語はシムド,シムディ,エスアイエムディと発音呼ばれます.SIMD演算は,MMXで64ビット,SSEで128ビット,AVXで256ビット,AVX512で512ビットのデータを1命令で並列演算できます.1つの要素が32ビットのデータ(intやfloat)で換算すると,2, 4, 8, 16並列でデータの処理が可能です.
SIMD演算は,古くはMMXと呼ばれ,64ビット整数のベクトル演算が可能でした.それがSSEにより,128ビット浮動小数点により可能になり,SSE2により128ビット整数をサポートしました.その後SSE3, SSSE3, SSE4.1, SSE4.2と拡張され,様々な命令が増えました.AVXでは256ビット浮動小数点演算のベクトル演算が可能となり,AVX2では,256ビット整数ベクトル演算が可能になりました.AVX512では,512ビットベクトル演算が可能になっています.SIMD演算の年表は以下のようになります(ARMのNEONを除く).
| Year | SIMD | CPU |
|---|---|---|
| 1997 | MMX | MMX Pentium |
| 1998 | 3DNow! | K6-2 (AMD) |
| 1999 | SSE | PnetiumIII |
| 2000 | SSE2 | Pnetium 4 |
| 2004 | SSE3 | Pnetium 4 |
| 2006 | SSSE3 | Core 2 |
| 2007 | SSE4.1 | Core 2 |
| 2007 | SSE4a | Phenom(AMD) |
| 2008 | SSE4.2 | Core i7 |
| 2011 | AVX | Core i7 2Gen |
| 2013 | AVX2 | Core i7 4Gen |
| 2016 | AVX-512 | Xeon Phi |
なお,よっぽどの限り必要ありませんが,現在はx64でコンパイルする場合,MMX命令はサポートされません.また,Xeon Phiというおもちゃは残念ながらディスコンです.
説明方法
AVX/AVX2命令は,数多くの命令があります.本稿では,命令を以下の5種類に大別して説明します.
- Move (データのロードストア)
- load, storeなど
- Arithmetic (算術演算)
- add, sub, fmaなど
- Logical/Shift/Compare (論理演算,ビットシフト,比較)
- and, sll, cmpなど
- Cast/Convert (キャスト)
- cast, cvtなど
- Swizzle (データ並び替え)
- shuffle, permuteなど
なお,通常のSIMD演算は以下の流れを取ります.
- ロード(Move)
- 適切な型に変換(Cast)およびデータの並び替え(Swizzle)
- 算術演算や論理演算(Arithmetic,Logical)
- 適切な型に変換(Cast)およびデータの並び替え(Swizzle)
- ストア(Move)
また,各命令は下位の表のようにしてレイテンシ,スループットのCPIや,μopsを載せて説明していきます.
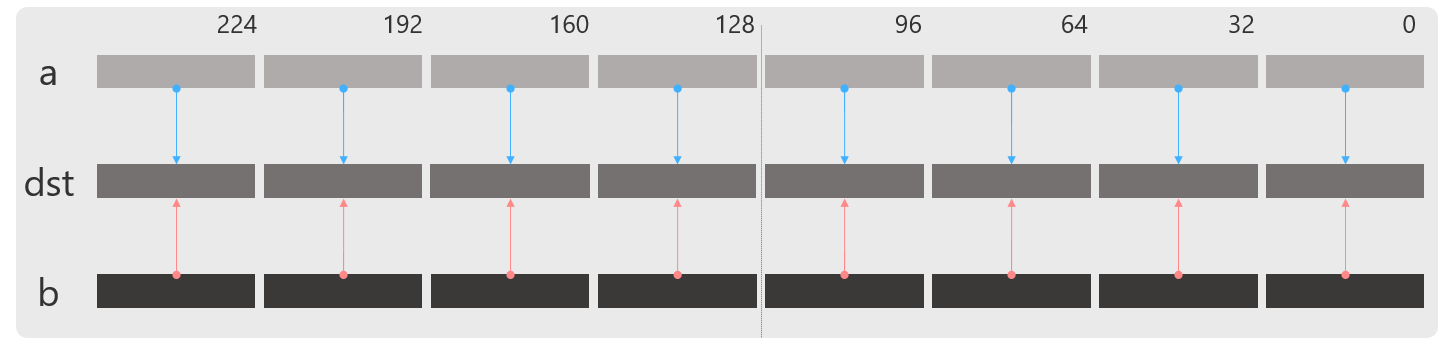
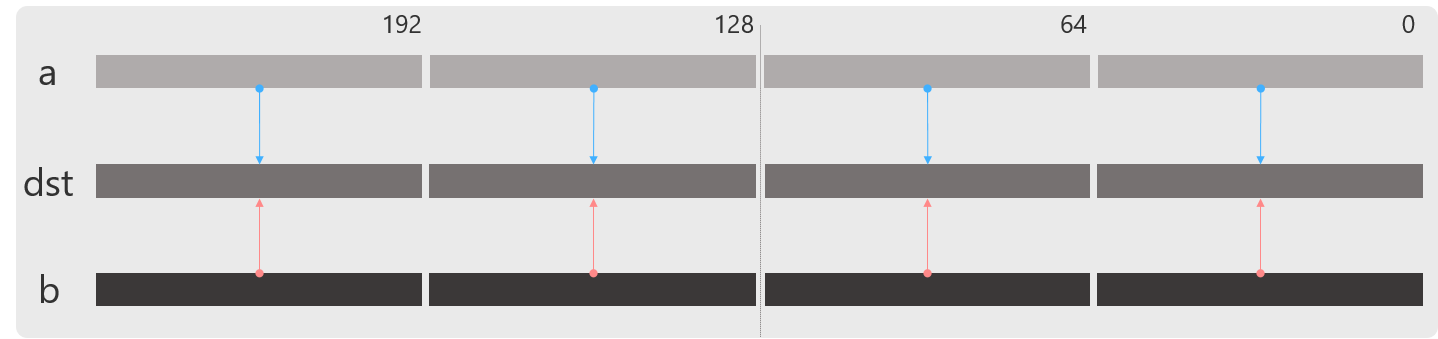
例えば,以下は浮動小数点の加算命令です.
__m256 _mm256_add_ps (__m256 a, __m256 b)
__m256d _mm256_add_pd (__m256d a, __m256d b)
asm: vaddps ymm, ymm, ymm //ps
asm: vaddpd ymm, ymm, ymm //pd
動作
_mm256_add_ps
_mm256_add_pd
CPI/Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 2 | 0.5 | 1 |
| Icelake | 4 | 0.5 | 1 |
| Skylake | 4 | 0.5 | 1 |
| Broadwell | 3 | 1 | 1 |
| Haswell | 3 | 1 | 1 |
| Ivy Bridge | 3 | 1 | 1 |
| Sandy Bridge | 3 | 1 | 1 |
| Zen3 | 3 | 0.5 | 1 |
| Zen2 | 3 | 0.5 | 1 |
| Zen | 3 | 1 | 2 |
目次
AVX Complete Guide(仮)の目次です.
リンク先は,書いたところだけ後で埋める予定です.
- Introduction
-
CPU年表
- [Intel](https://qiita.com/fukushima1981/items/4b8dded3ee57625a1645 #intel)
- [AMD](https://qiita.com/fukushima1981/items/4b8dded3ee57625a1645 #amd)
- AVX512
- アーキテクチャ
- Intel
- AMD
- Latency, Throughput, Uops
-
CPU年表
- AVX入門
- 導入
- コードの書き方による違い
- SIMDレジスタ
- 2オペラントと3オペラント
- epiとepu
- 浮動小数点のMXCSRコントロールレジスタ (SSE)
- 丸めを設定する
- 例外を捕まえる
- 非正規化数を抑制する
- 配列の初期化とアライメント
- ループアンローリング
- アンローリング
- 要素数の丸め
- レジスタブロッキング
- Move
- Load
- 128ビットよりも小さなサイズのロード
- _mm_loadu_si64/_mm_loadl_epi64 (SSE)
- _mm_loadu_si32 (SSE2)
- _mm_loadu_si16 (SSE2)
- _mm_load_ss (SSE)
- _mm_load_sd (SSE2)
- 128ビットロード
- _mm_load|loadu_ps|pd (SSE)
- _mm_load|loadu_si128 (SSE2)
- _mm_stream_load_si128 (SSE4.1)
- _mm_lddqu_si128 (SSE3)
- _mm_loadl|loadh_pi (SSE)
- _mm_loadl|loadh_pd (SSE2)
- _mm_loaddup_pd (SSE3)
- _mm_maskload_ps|pd (AVX)
- _mm_maskload_epi32|64 (AVX2)
- 256ビットロード
- _mm256_load|loadu_ps|pd|si256 (AVX)
- [_mm256_stream_load_si256 (AVX)](https://qiita.com/fukushima1981/items/a11f7882857cf3e15308 #_mm256_stream_load_si256-avx)
- [_mm256_lddqu_si256 (AVX2)](https://qiita.com/fukushima1981/items/a11f7882857cf3e15308 #_mm256_lddqu_si256-avx2)
- _mm256_loadu2_m128|m128d|m128i (AVX)
- _mm256_maskload_ps|pd (AVX)
- _mm256_maskload_epi32|64 (AVX2)
- _mm256_movemask_epi8|ps|pd
- 128ビットよりも小さなサイズのロード
- Store
- 128ビットよりも小さなサイズのストア
- _mm_storeu_si64/_mm_storel_epi64 (SSE2)
- _mm_storel|storeh_pd|pi (SSE2)
- _mm_storeu_si32 (SSE2)
- _mm_storeu_si16 (SSE2)
- _mm_store_ss (SSE2)
- _mm_store_ss (SSE)
- 128ビットストア
- _mm_store|storeu_ps|pd|si256 (SSE/SSE2)
- _mm_stream_ps|pd|si128 (SSE/SSE2)
- _mm_maskstore_ps|pd (AVX)
- _mm_maskstore_epi32|epi64 (AVX2)
- 256ビットストア
- [_mm256_store|storeu_ps|pd|si256 (AVX)](https://qiita.com/fukushima1981/items/467f8a796b8d0abc9d95 #_mm256_storestoreu_pspdsi256-avx)
- [_mm256_stream_ps|pd|si256 (AVX)](https://qiita.com/fukushima1981/items/467f8a796b8d0abc9d95 #_mm256_stream_pspdsi256-avx)
- _mm256_storeu2_m128|m128d|m128i (AVX)
- _mm256_maskstore_ps|pd (AVX)
- _mm256_maskstore_epi32|epi64 (AVX2)]
- 128ビットよりも小さなサイズのストア
- Set
- SSE
- AVX
- _mm256_setzero_si256|ps|pd
- _mm256_set1_epi8|16|32|64x|ps|pd
- _mm256_set|setr_epi8|16|32|64x|ps|pd
- _mm256_set|setr_m128|m128i|m128d
- Gather/Scatter
- Gather
- _mm256_i32gather_ps (AVX2)
- gatherでepu8を取り込む
- setによるgather
- Scatter
- _mm256_i32|i64scatter_ps|pd|epi32|epi64 (AVX512F + AVX512VL)
- Gather
- Load
- Arithmetic
- 垂直演算
-
加算(ADD)
- [_mm256_add_ps|pd (AVX)](https://qiita.com/fukushima1981/items/201442864dfb5ce9039f #_mm256_add_pspd-avx)
- [_mm256_add_epi8|16|32|64 (AVX2)](https://qiita.com/fukushima1981/items/201442864dfb5ce9039f #_mm256_add_epi8163264-avx2)
- [_mm256_adds_epi|epu8|16 (AVX2)](https://qiita.com/fukushima1981/items/201442864dfb5ce9039f #_mm256_adds_epiepu816-avx2)
- 減算(SUB)
- _mm256_sub_ps|pd (AVX)
- _mm256_sub_epi8|16|32|64 (AVX2)
- _mm256_subs_epi|epu8|16 (AVX2)
- 乗算(MUL)
- [_mm256_mul_ps|pd (AVX)](https://qiita.com/fukushima1981/items/c9d18ba576b728f5abed #_mm256_mul_pspd-avx)
- [_mm256_mul_epi|epu32 (AVX2)](https://qiita.com/fukushima1981/items/c9d18ba576b728f5abed #_mm256_mul_epiepu32-avx2)
- _mm256_mullo_epi32 (AVX2)
- [_mm256_mullo|mulhi_epi16|epu16 (AVX2)](https://qiita.com/fukushima1981/items/c9d18ba576b728f5abed #_mm256_mullomulhi_epi16epu16-avx2)
- _mm256_mulhrs_epi16
- 交互加減算(ADDSUB)
- _mm256_addsub_ps|pd (AVX)
- 融合積和(FMA)
- _mm256_fmadd_ps|pd (FMA)
- よくあるFMAのパターン:ホーナー法
- 除算(DIV)
- [_mm256_div_ps (AVX)](https://qiita.com/fukushima1981/items/934f2ef109a9388c6697 #_mm256_div_ps-avx)
- [_mm256_div_pd (AVX)](https://qiita.com/fukushima1981/items/934f2ef109a9388c6697 #_mm256_div_pd-avx)
- 逆数(RCP)
- [_mm256_rcp_ps (AVX)](https://qiita.com/fukushima1981/items/ed2e14dd346e03de24d8 #_mm256_rcp_ps-avx)
- 平方根(SQRT)
- [_mm256_sqrt_ps (AVX)](https://qiita.com/fukushima1981/items/934f2ef109a9388c6697 #_mm256_sqrt_ps-avx)
- [_mm256_sqrt_pd (AVX)](https://qiita.com/fukushima1981/items/934f2ef109a9388c6697 #_mm256_sqrt_pd-avx)
- 逆数平行根(RSQRT)
- [_mm256_rsqrt_ps (AVX)](https://qiita.com/fukushima1981/items/ed2e14dd346e03de24d8 #_mm256_rsqrt_ps-avx)
- 最大・最小(MAX/MIN)
- _mm256_max_ps|pd (AVX)
- _mm256_min_ps|pd (AVX)
- _mm256_max_epi|epu8|16|32 (AVX2)
- _mm256_min_epi|epu8|16|32 (AVX2)
- 平均(AVE)
- _mm256_ave_epu8|16 (AVX2)
- 絶対値(ABS)・符号(SIGN)
- abs_epi8|16|32 (AVX2)
- 浮動小数点の絶対値
- _mm256_sign_epi8|16|32 (AVX2)
- 浮動小数点の符号
- 丸め(ROUND/CEIL/FLOOR)
- _mm256_round_ps|pd (AVX)
- _mm256_ceil|floor_ps|pd]
-
加算(ADD)
- 水平演算
- 水平加算(HADD)
- _mm256_hadd_ps|pd (AVX2)
- _mm256_hadd|hadds_epi16|32 (AVX2)
- 水平減算(HSUB)
- _mm256_hsub_ps|pd (AVX2)
- _mm256_hsub\hsubs_epi16|32
- 内積(DP)
- _mm256_dp_ps (AVX)
- 整数積和(MADD)
- 絶対誤差の総和(SAD)
- _mm_sad_epu8 (SSE)
- _mm256_sad_epu8 (AVX2)
- _mm_mpsadbw_epu8 (SSE4.1)
- _mm256_mpsadbw_epu8 (AVX2)
- _mm_minpos_epu16 (SSE4.1)
- 水平加算(HADD)
- ソフトウェア実装
- 命令の複合
- 整数の絶対値誤差
- Scanパターンの並列化
- SVML
- テーブル参照
- 命令の複合
- 垂直演算
- Logical/Shift/Compare
- Logical
- 論理演算
- [_mm256_and|or|xor|andnot_ps|pd (AVX/AVX2)](https://qiita.com/fukushima1981/items/2b8d27032607289ef99f #_mm256_andorxorandnot_pspd-avxavx2)
- [_mm256_and|or|xor|andnot_si256 (AVX2)](https://qiita.com/fukushima1981/items/2b8d27032607289ef99f #_mm256_andorxorandnot_si256-avx2)
- not演算の作成
- 浮動小数点の符号の取得
- 論理演算
- Shift
- ビットシフト
- _mm256_slli|srli|srai_epi16|epi32|epi64
- _mm256_sll|srl|sra_epi16|epi32|epi64
- _mm256_sllv|srlv|srav_epi32|epi64
- バイトシフト
- _mm256_bslli|bsrli_epi128
- _mm256_alignr_epi8 (AVX2)
- _mm_alignr_epi8 (SSSE3)
- ビットシフト
- Compare
- 浮動小数点比較命令
- [_mm256_cmp_ps](https://qiita.com/fukushima1981/items/5001079900b328696859 #_mm256_cmp_ps)
- [_mm256_cmp_pd](https://qiita.com/fukushima1981/items/5001079900b328696859 #_mm256_cmp_pd)
- 整数比較命令
- [_mm256_cmpgt_epi8/16/32 (AVX2)](https://qiita.com/fukushima1981/items/4d77e24749edb8ea3d2b #_mm256_cmpgt_epi81632-avx2)
- [_mm256_cmpgt_epi64](https://qiita.com/fukushima1981/items/4d77e24749edb8ea3d2b #_mm256_cmpgt_epi64)
- [_mm256_cmpeq_epi8/16/32](https://qiita.com/fukushima1981/items/4d77e24749edb8ea3d2b #_mm256_cmpeq_epi81632)
- [_mm256_cmpeq_epi64](https://qiita.com/fukushima1981/items/4d77e24749edb8ea3d2b #_mm256_cmpeq_epi64)
- 符号無し整数比較命令
- 4要素以下の比較命令
- 比較結果のカウント方法
- 浮動小数点比較命令
- test
- AVX
- _mm256_testc_si256 (AVX)
- AVX
- Logical
- Cast/Convert
- Cast
- Convert
- 整数型変換
- [_mm256_cvtepi8|epu8_epi16|epi32|epi64 (AVX2)](https://qiita.com/fukushima1981/items/d7ed1440ee2ae51f1a8b #_mm256_cvtepi8epu8_epi16epi32epi64-avx2)
- [_mm256_cvtepi16|epu16_epi32|epi64 (AVX2)](https://qiita.com/fukushima1981/items/d7ed1440ee2ae51f1a8b #_mm256_cvtepi16epu16_epi32epi64-avx2)
- [_mm256_cvtepi32|epu32_epi64 (AVX2)](https://qiita.com/fukushima1981/items/d7ed1440ee2ae51f1a8b #_mm256_cvtepi32epu32_epi64-avx2)
- [_mm256_cvtsi256_si32|si64 (AVX)](https://qiita.com/fukushima1981/items/d7ed1440ee2ae51f1a8b #_mm256_cvtsi256_si32si64-avx)
- unpackによる小さいサイズの整数からの大きいサイズの整数型への変換
- packによる大きいサイズの整数からの小さいサイズの整数型への変換
- 整数・浮動小数点型変換
- [_mm256_cvtepi32_ps (AVX)](https://qiita.com/fukushima1981/items/041ed1b8aa6a4575abe3 #_mm256_cvtepi32_ps-avx)
- [_mm256_cvt|cvttps_epi32 (AVX)](https://qiita.com/fukushima1981/items/041ed1b8aa6a4575abe3 #_mm256_cvtcvttps_epi32-avx)
- [_mm256_cvtepi32_pd (AVX)](https://qiita.com/fukushima1981/items/041ed1b8aa6a4575abe3 #_mm256_cvtepi32_pd-avx)
- [_mm256_cvtpd|cvttpd_epi32 (AVX)](https://qiita.com/fukushima1981/items/041ed1b8aa6a4575abe3 #_mm256_cvtpdcvttpd_epi32-avx)
- _mm_cvt|cvttss_si32|si64 (SSE)
- _mm_cvt|cvttsd_si32|si64 (SSE2)
-
浮動小数点型変換
- _mm256_cvtps_pd (AVX)
- _mm256_cvtpd_ps (AVX)
- _mm256_cvtss_f32|sd_f64 (AVX)
-
半浮動小数点型変換
- _mm256_cvtps_ph (FP16C)
- _mm256_cvtph_ps (FP16C)
- AVX512からサポートされる型変換
- 整数型変換
- Swizzle
- shuffle/permute
- float: __m256
- _mm256_permute2f128_ps (AVX)
- [_mm256_shuffle_ps (AVX)](https://qiita.com/fukushima1981/items/496b0e0417d37f13c5fd #_mm256_shuffle_ps-avx)
- [_mm256_permute_ps (AVX)](https://qiita.com/fukushima1981/items/496b0e0417d37f13c5fd #_mm256_permute_ps-avx)
- [_mm256_permutevar_ps (AVX)](https://qiita.com/fukushima1981/items/496b0e0417d37f13c5fd #_mm256_permutevar_ps-avx)
- [_mm256_permutevar8x32_ps (AVX2)](https://qiita.com/fukushima1981/items/496b0e0417d37f13c5fd #_mm256_permutevar8x32_ps-avx2)
- double: __m256d
- _mm256_permute2f128_pd (AVX)
- [_mm256_shuffle_pd (AVX)](https://qiita.com/fukushima1981/items/496b0e0417d37f13c5fd #_mm256_shuffle_pd-avx)
- [_mm256_permute_pd (AVX)](https://qiita.com/fukushima1981/items/496b0e0417d37f13c5fd #_mm256_permute_pd-avx)
- [_mm256_permutevar_pd (AVX)](https://qiita.com/fukushima1981/items/496b0e0417d37f13c5fd #_mm256_permutevar_pd-avx)
- [_mm256_permute4x64_pd (AVX2)](https://qiita.com/fukushima1981/items/496b0e0417d37f13c5fd #_mm256_permute4x64_pd-avx2)
- 整数: __m256i
- [_mm256_shuffle_epi32 (AVX2)](https://qiita.com/fukushima1981/items/6a462284769fe1ad62a3 #_mm256_shuffle_epi32-avx2)
- [_mm256_shufflelo_epi16 (AVX2)](https://qiita.com/fukushima1981/items/6a462284769fe1ad62a3 #_mm256_shufflelo_epi16-avx2)
- [_mm256_shufflehi_epi16 (AVX2)](https://qiita.com/fukushima1981/items/6a462284769fe1ad62a3 #_mm256_shufflehi_epi16-avx2)
- [_mm256_shuffle_epi8 (AVX2)](https://qiita.com/fukushima1981/items/6a462284769fe1ad62a3 #_mm256_shuffle_epi8-avx2)
- _mm256_permute2f128_si256 (AVX)
- _mm256_permute2x128_si256 (AVX2)
- [_mm256_permute4x64_epi64 (AVX2)](https://qiita.com/fukushima1981/items/6a462284769fe1ad62a3 #_mm256_permute4x64_epi64-avx2)
- [_mm256_permutevar8x32_epi32 (AVX2)](https://qiita.com/fukushima1981/items/6a462284769fe1ad62a3 #_mm256_permutevar8x32_epi32-avx2)
- float: __m256
- unpack/packs/movedup
- unpack
- [_mm256_unpacklo|hi_ps|pd (AVX)](https://qiita.com/fukushima1981/items/407dc2c635597ec26fd1 #_mm256_unpacklohi_pspd-avx)
- [_mm256_unpacklo|hi_epi8|16|32|64 (AVX2)](https://qiita.com/fukushima1981/items/407dc2c635597ec26fd1 #_mm256_unpacklohi_epi8163264-avx2)
- pack
- [_mm256_packs|packus_epi32 (AVX2)](https://qiita.com/fukushima1981/items/407dc2c635597ec26fd1 #_mm256_packspackus_epi32-avx2)
- [_mm256_packs|packus_epi16 (AVX2)](https://qiita.com/fukushima1981/items/407dc2c635597ec26fd1 #_mm256_packspackus_epi16-avx2)
- movedup
- _mm256_movel|hdup_ps (AVX)
- _mm256_movedup_pd (AVX)
- unpack
- blend/blendv
- blend
- [_mm256_blend_ps|pd (AVX)](https://qiita.com/fukushima1981/items/d99a718f29cf4b004bb1 #_mm256_blend_pspd-avx)
- [_mm256_blend_epi32 (AVX2)](https://qiita.com/fukushima1981/items/d99a718f29cf4b004bb1 #_mm256_blend_epi32-avx2)
- [_mm256_blend_epi16 (AVX2)](https://qiita.com/fukushima1981/items/d99a718f29cf4b004bb1 #_mm256_blend_epi16-avx2)
- [64ビット整数のブレンドを作る:_mm256_blend_epi64](https://qiita.com/fukushima1981/items/d99a718f29cf4b004bb1 #64ビット整数のブレンドを作る_mm256_blend_epi64)
- blendv
- [_mm256_blendv_ps|pd (AVX)](https://qiita.com/fukushima1981/items/d99a718f29cf4b004bb1 #_mm256_blendv_pspd-avx)
- [_mm256_blendv_epi8 (AVX2)](https://qiita.com/fukushima1981/items/d99a718f29cf4b004bb1 #_mm256_blendv_epi8-avx2)
- 16ビット~64ビットのblendv命令を作る
- ビット演算によるブレンド
- [任意の値とのブレンド](https://qiita.com/fukushima1981/items/d99a718f29cf4b004bb1 #任意の値とのブレンド)
- [0とのブレンド](https://qiita.com/fukushima1981/items/d99a718f29cf4b004bb1 #0とのブレンド)
- blend
- broadcast
- 浮動小数点
- _mm256_broadcast_ps|pd (AVX)
- _mm|mm256_broadcast_ss (AVX)
- _mm|mm256_broadcastss_ps (AVX2)
- _mm256_broadcast_sd (AVX)
- _mm|mm256_broadcastsd_pd (AVX2)
- 整数
- _mm256_broadcastsi128_si256 (AVX2)
- _mm|mm256_broadcastq_epi64 (AVX2)
- _mm|mm256_broadcastd_epi32 (AVX2)
- _mm|mm256_broadcastw_epi16 (AVX2)
- _mm|mm256_broadcastb_epi8 (AVX2)
- 浮動小数点
- extract/insert
- insert
- _mm256_insertf128_ps|pd|si256 (AVX)
- _mm256_inserti128_si256 (AVX2)
- _mm256_insert_epi64 (AVX2)
- _mm256_insert_epi32 (AVX2)
- _mm256_insert_epi16 (AVX2)
- _mm256_insert_epi8 (AVX2)
- _mm_insert_ps (SSE4.1)
- _mm_insert_epi8|16|32|64 (SSE)
- extract
- _mm256_extractf128_ps|pd|si256 (AVX)
- _mm256_extracti128_si256 (AVX2)
- _mm256_extract_epi64 (AVX2)
- _mm256_extract_epi32 (AVX2)
- _mm256_extract_epi16 (AVX2)
- _mm256_extract_epi8 (AVX2)
- _mm_extract_ps (SSE4.1)
- _mm_insert_epi8|16|32|64 (SSE)
- insert
- shuffle/permute
- ETC