はじめに
SIMDによる浮動小数点,整数の加算の性能について説明します.
浮動小数点の加算はAVX,整数の加算はAVX2で実行できます.
_mm256_add_ps|pd (AVX)
__m256 _mm256_add_ps (__m256 a, __m256 b)
__m256d _mm256_add_pd (__m256d a, __m256d b)
asm: vaddps ymm, ymm, ymm //ps
asm: vaddpd ymm, ymm, ymm //pd
動作
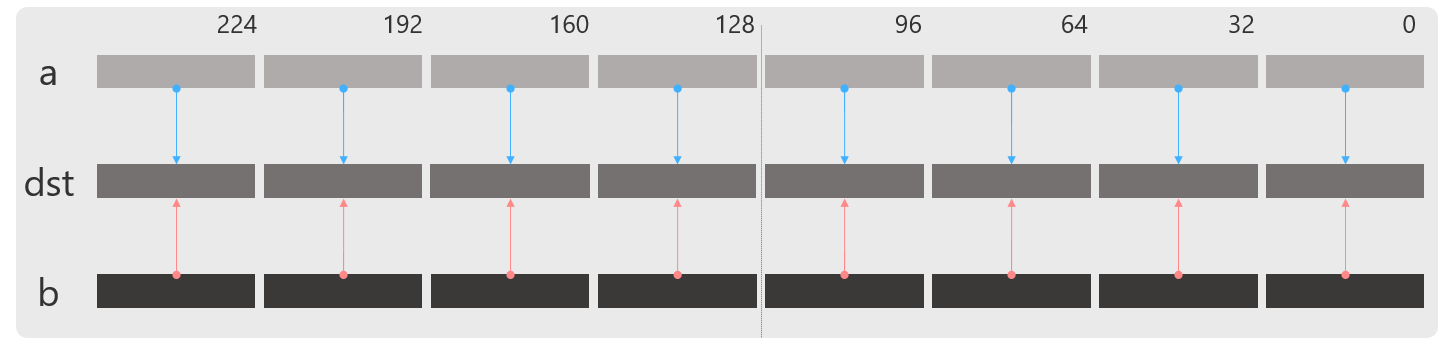
_mm256_add_ps
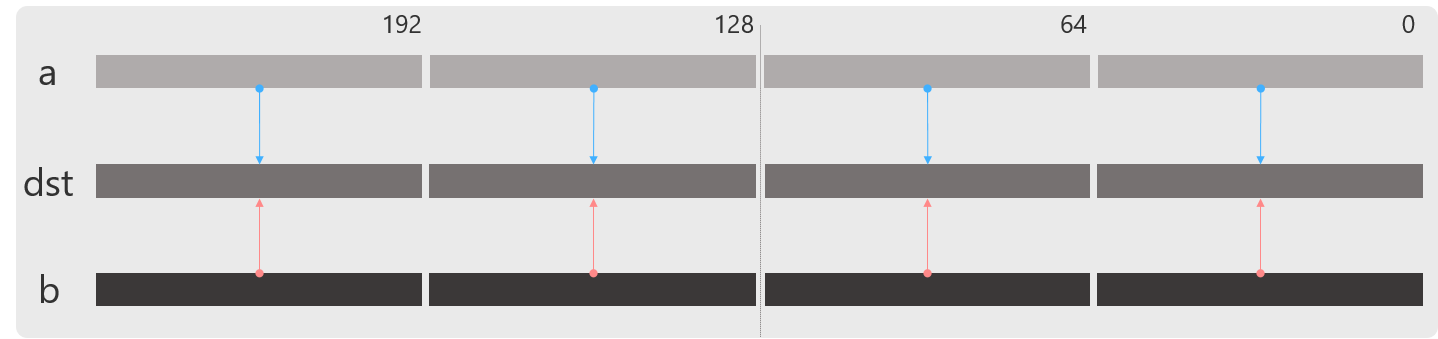
_mm256_add_pd
CPI/Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 2 | 0.5 | - |
| Icelake | 4 | 0.5 | 1 |
| Skylake | 4 | 0.5 | 1 |
| Broadwell | 3 | 1 | 1 |
| Haswell | 3 | 1 | 1 |
| Ivy Bridge | 3 | 1 | 1 |
| Sandy Bridge | 3 | 1 | 1 |
| Zen3 | 3 | 0.5 | 1 |
| Zen2 | 3 | 0.5 | 1 |
| Zen | 3 | 1 | 2 |
- SkylakeやIcelakeでは,浮動小数点の加算や乗算,FMAの計算コストは完全に同一です.
- IntelのCPUではAlderlakeから加算のレイテンシが2になっています.
説明
浮動小数点(float, double)の加算を行います.
float型,double型どちらもパフォーマンスは同じですが,同時に計算する要素数は8つと4つと違い,float型命令のほうが倍のパフォーマンスが出ます.
_mm256_add_epi8|16|32|64 (AVX2)
__m256i _mm256_add_epi8 (__m256i a, __m256i b)
__m256i _mm256_add_epi16 (__m256i a, __m256i b)
__m256i _mm256_add_epi32 (__m256i a, __m256i b)
__m256i _mm256_add_epi64 (__m256i a, __m256i b)
asm: vpaddb ymm, ymm, ymm //epi8
asm: vpaddw ymm, ymm, ymm //epi16
asm: vpaddd ymm, ymm, ymm //epi32
asm: vpaddq ymm, ymm, ymm //epi64
動作
_mm256_add_epi8

_mm256_add_epi16

__m256i _mm256_add_epi32
_mm256_add_epi64
CPI/Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 1 | 0.33 | 1 |
| Icelake | 1 | 0.33 | 1 |
| Skylake | 1 | 0.33 | 1 |
| Broadwell | 1 | 0.5 | 1 |
| Haswell | 1 | 0.5 | 1 |
| Zen3 | 1 | 0.25 | 1 |
| Zen2 | 1 | 0.33 | 1 |
| Zen | 1 | 0.67 | 2 |
- Alderlakeの整数加算の速度は,Skylakeから変わっていません.
説明
符号あり整数同士の加算を行います.
オーバーフローのための処理は何もありません.
アセンブリの末尾は,並列処理の単位を示しています.
b:バイト(8),w:ワード(16),d:ダブルワード(32),q:クアッドワード(64)
_mm256_adds_epi|epu8|16 (AVX2)
__m256i _mm256_adds_epi8 (__m256i a, __m256i b)
__m256i _mm256_adds_epu8 (__m256i a, __m256i b)
__m256i _mm256_adds_epi16 (__m256i a, __m256i b)
__m256i _mm256_adds_epu16 (__m256i a, __m256i b)
asm: vpaddsb ymm, ymm, ymm //epi8
asm: vpaddusb ymm, ymm, ymm //epu8
asm: vpaddsw ymm, ymm, ymm //epi16
asm: vpaddusw ymm, ymm, ymm //epu16
動作
_mm256_adds_epi8
_mm256_adds_epi16
CPI/Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 1 | 0.5 | 1 |
| Icelake | 1 | 0.5 | 1 |
| Skylake | 1 | 0.5 | 1 |
| Broadwell | 1 | 0.5 | 1 |
| Haswell | 1 | 0.5 | 1 |
| Zen3 | 1 | 0.5 | 1 |
| Zen2 | 1 | 0.5 | 1 |
| Zen | 1 | 1 | 2 |
- Alderlakeの整数加算の速度は,skylakeから変わっていません.
説明
符号有り・符号無しの飽和付きの加算を行います.飽和演算無しのものより動作は遅いです.
符号有りの場合,127を超えたら127で打ち切ります.
符号無しの場合,255を超えたら255で打ち切ります.
d = max(a + b, 127);
d = max(a + b, 255);
x87による加算
古の浮動小数点回路によるx87を用いた加算のパフォーマンスです.32ビットでも64ビットでもない80ビットが計算できます.
まだ一応,生きています.
なお,SIMDとは違って,1つの要素しか計算できないことに注意してください.
使い方は下記を参照してください.
x87 instruction setを使う
long doubleの話
なお,asmを簡単にはコールできないVisual Studioだとx87の演算器を使うのはかなり手間です.
また,x87使うくらいならdoubledouble演算ができるような疑似4倍精度ライブラリや精度補償計算ライブラリを使うほうが,SIMD演算使っていることや,レジスタの受け渡しの関係で,x87よりもどうやっても速くなる&精度も高いのでそちらを使うことがおすすめです.
kv - C++による精度保証付き数値計算ライブラリ
DD-AVX Library
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 3 | 1 | - |
| Icelake | 3 | 1 | - |
| Skylake | 3 | 1 | - |
| Broadwell | 3 | 1 | - |
| Haswell | 3 | 1 | - |
| Ivy Bridge | 3 | 1 | - |
| Sandy Bridge | 3 | 1 | - |
| Zen3 | 5 | 1 | - |
| Zen2 | 5 | 1 | - |
| Zen | 5 | 1 | - |
- uOpsには情報が無かったため,AIDA64のところからひとつづつピックアップ.