はじめに
乗算について説明します.
_mm256_mul_ps|pd (AVX)
__m256 _mm256_mul_ps (__m256 a, __m256 b)
__m256d _mm256_mul_pd (__m256d a, __m256d b)
asm: vmulps ymm, ymm, ymm //ps
asm: vmulpd ymm, ymm, ymm //pd
動作
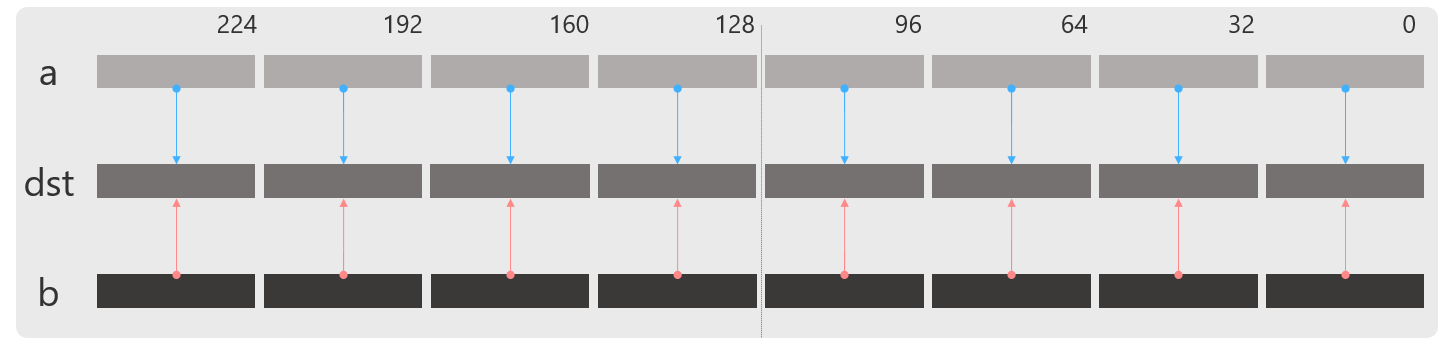
_mm256_mul_ps
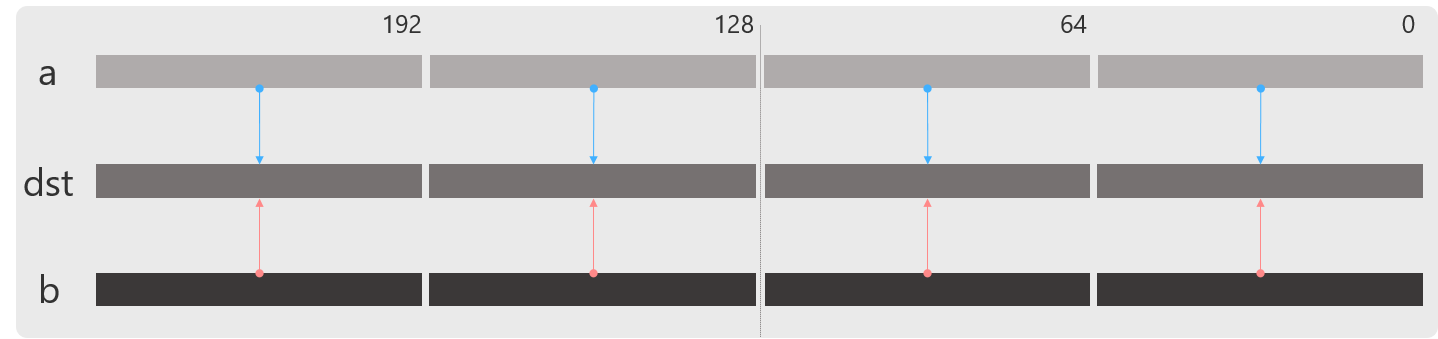
_mm256_mul_pd
CPI/Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 4 | 0.5 | - |
| Icelake | 4 | 0.5 | 1 |
| Skylake | 4 | 0.5 | 1 |
| Broadwell | 3 | 0.5 | 1 |
| Haswell | 5 | 0.5 | 1 |
| Ivy Bridge | 5 | 1 | 1 |
| Sandy Bridge | 5 | 1 | 1 |
| Zen3 | 3 | 0.5 | 1 |
| Zen2 | 3 | 0.5 | 1 |
| Zen | 3(4) | 1 | 2 |
- BroadwellとHaswellでレイテンシが異なります.uops, Agner, AIDA64全てで一致しています.
- Zenだけ,floatとdoubleでレイテンシが異なり,doubleのレイテンシは4です.
- Addと異なり,AlderLakeの乗算は,Icelakeと変わりません.(AlderlakeはFADDという高速な加算回路だけ追加されています)
説明
浮動小数点の乗算を行います.
_mm256_mul_epi|epu32 (AVX2)
__m256i _mm256_mul_epi32 (__m256i a, __m256i b)
__m256i _mm256_mul_epu32 (__m256i a, __m256i b)
asm: vpmuldq ymm, ymm, ymm //epi32
asm: vpmuludq ymm, ymm, ymm //epu32
動作
作成中
CPI/Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 5 | 0.63 | 1 |
| Icelake | 5 | 0.5 | 1 |
| Skylake | 5 | 0.5 | 1 |
| Broadwell | 5 | 1 | 1 |
| Haswell | 5 | 1 | 1 |
| Zen3 | 3 | 0.5 | 1 |
| Zen2 | 3 | 1 | 1 |
| Zen | 3 | 2 | 2 |
- AIDA64ではSkylake, IcelakeのThroughputも0.63です.
説明
符号あり・なし32ビット整数の下位4つを乗算し,64ビットで出力します.
結果の符号の有無はepiは有り,epuは無しになります.
mulhiはありません.
floatと同じ32ビットの乗算ですが,要素数4つの乗算です.
レイテンシもfloatの場合よりも長いです.
32ビットの乗算が大量に必要な場合,整数演算よりも,浮動小数点で行ったほうが有利になりやすいです.
__m256i a = _mm256_setr_epi32(0, 1, 2, 3, 4, 5, 6, 7);
__m256i b = _mm256_setr_epi32(0, 0, 2, 0, 4, 0, 6, 0);
__m256i c = _mm256_setr_epi32(2, 2, 4, 4, 6, 6, 8, 8);
__m256i d = _mm256_mul_epi32(a, c);
__m256i e = _mm256_mul_epi32(b, c);
print_int(a);
print_int(b);
print_int(c);
print_long(d);
print_long(e);
0 1 2 3 4 5 6 7
0 0 2 0 4 0 6 0
2 2 4 4 6 6 8 8
0 8 24 48
0 8 24 48
_mm256_mullo_epi32 (AVX2)
__m256i _mm256_mullo_epi32 (__m256i a, __m256i b)
asm: vpmulld ymm, ymm, ymm
動作
_mm256_mullo_epi32
CPI/Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 9.9 | 0.39 | - |
| Icelake | 10 | 1 | 2 |
| Skylake | 10 | 1 | 2 |
| Broadwell | 10 | 2 | 2 |
| Haswell | 10 | 2 | 2 |
| Zen3 | 3 | 0.5 | 1 |
| Zen2 | 4 | 2 | 1 |
| Zen | 4 | 4 | 2 |
- AIDA64 だとSkylakeもIcelakeもThrouputは0.4です.
説明
8要素の符号あり32ビット整数を乗算し,計算結果の下位32ビットを保存します.
演算結果の上位ビットは無視されます.
浮動小数点の演算と同じ並列数ですが,Intel CPUの場合はパフォーマンスは非常に低く,決定的な差があります.
Intel CPUはvpmuldqを2回発行しているのと同じレイテンシとスループット,Uopsを示しています.
一方Zenは倍近くの性能で動作します.
__m256i a = _mm256_setr_epi32(0, 1, 2, 3, 4, 5, 6, 7);
__m256i b = _mm256_setr_epi32(0, 0, 2, 0, 4, 0, 6, 0);
__m256i c = _mm256_setr_epi32(2, 2, 4, 4, 6, 6, 8, 8);
__m256i d = _mm256_mullo_epi32(a, c);
__m256i e = _mm256_mullo_epi32(b, c);
print_int(a);
print_int(b);
print_int(c);
print_int(d);
print_int(e);
0 1 2 3 4 5 6 7
0 0 2 0 4 0 6 0
2 2 4 4 6 6 8 8
0 2 8 12 24 30 48 56
0 0 8 0 24 0 48 0