はじめに
2つのレジスタの値の位置を変えずに任意の値を混ぜるためのblend命令を説明します.
即値指定によるblend命令と変数による指定が可能なblendv命令があります.
以下にブレンド命令の一覧を示します.vは,マスク指定が可能な命令です.
| intrinsic | bit | v |
|---|---|---|
| blend_ps | 32 | |
| blendv_ps | 32 | x |
| blend_pd | 64 | |
| blendv_pd | 64 | x |
| blend_epi32 | 32 | |
| blend_epi16 | 16 | |
| blendv_epi8 | 8 | x |
- 8ビット整数に対するepi8はblend命令がありません.blendv命令だけです.
- 64ビット整数に対するblend命令がありません.pdの命令をキャストして使用するかepi32で作成する必要があります.
- 整数のblendv命令は最小単位の8ビット命令があるため,全ビットに対してmaskを修正すれば使用可能です.
blendv命令は,マスク生成のために余分なコストがかかり,そもそものスループットとレイテンシも大きくなる傾向があります.
ブレンドする状態が事前にわかる場合は,可能な限り即値で対応することが高速化につながります.
blend
即値による二つのレジスタの値を,位置を変えずに任意にブレンドする命令です.
aabbaabbとブレンドする場合はshuffle命令でも実行可能です.
移動とセットでブレンドする場合はshuffle命令でブレンドしたほうが速くなりやすいです.
ただし,shuffleのポートはSkylakeまでは1つしかないため,スループットが低くなります.(Icelake以降は2つあります.一方,AMDのZenはより多くのポートを持ちます.)
その場合,可能な限りshuffle命令をblend命令に置き換えると高速化につながります.
インテル64およびIA-32アーキテクチャ最適化リファレンスマニュアルにも
shuffleをblendに置き換えるというセクションがあります.
このshuffleとblendの比率の例として転置の話があります.
_mm256_blend_ps|pd (AVX)
__m256 _mm256_blend_ps (__m256 a, __m256 b, const int imm8)
__m256d _mm256_blend_pd (__m256d a, __m256d b, const int imm8)
asm: vblendps ymm, ymm, ymm, imm8
asm: vblendpd ymm, ymm, ymm, imm8
動作
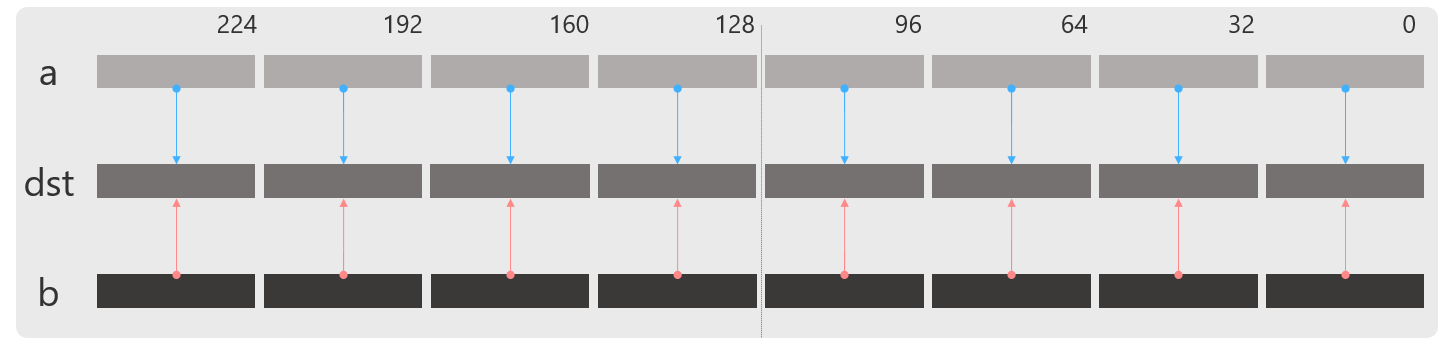
blend_ps
blend_pd
CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 1 | 0.33 | - |
| Icelake | 1 | 0.33 | 1 |
| Skylake | 1 | 0.33 | 1 |
| Broadwell | 1 | 0.33 | 1 |
| Haswell | 1 | 0.33 | 1 |
| Ivy Bridge | 1 | 0.5 | 1 |
| Sandy Bridge | 1 | 0.5 | 1 |
| Zen3 | 1 | 0.25 | 1 |
| Zen2 | 1 | 0.33(0.5) | 1 |
| Zen | 1 | 1 | 2 |
- Intel CPUは,Ivy Bridgeまでは,ポート0, 5で実行し,Haswellからポート0, 1, 5で実行可能です.
- uops: blend_psのZen2, Zen 3のレイテンシが3
- Zen2のdoubleはFP0,1のみなのでスループット0.5です.
- IntelCPUはマイクロフュージョンされないため,メモリから入力するとuopsが増えます.
- AMDはそのまま変わりません.
説明
imm8に従って2つのレジスタの値をブレンドします.
imm8は0bxxxxの2進数表現で使用すると直感的に利用できます.
0がaを出力し,1がbを出力します.
shuffle命令,permute命令よりも高速に動作します.
_mm256_blend_epi32 (AVX2)
__m256i _mm256_blend_epi32 (__m256i a, __m256i b, const int imm8)
asm: vpblendd ymm, ymm, ymm, imm8
動作
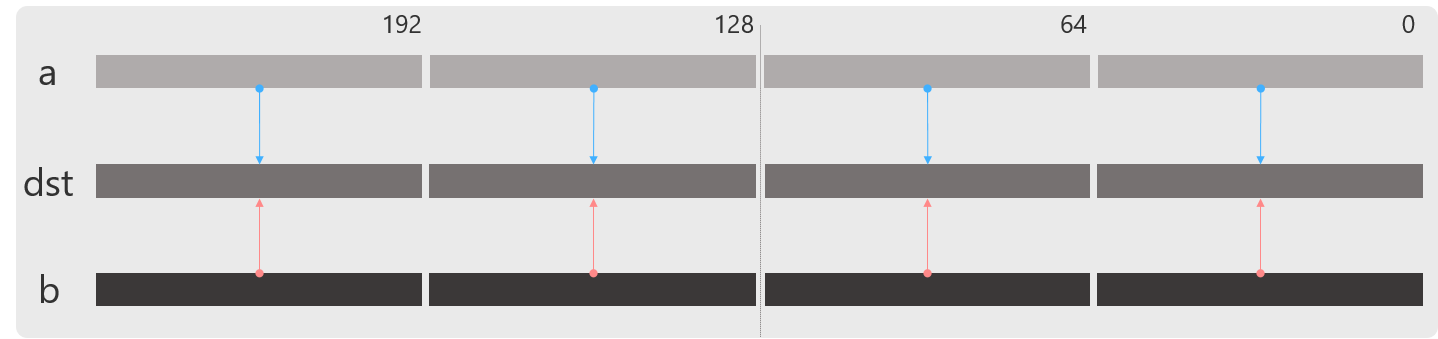
blend_epi32
CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 1 | 0.33 | - |
| Icelake | 1 | 0.33 | 1 |
| Skylake | 1 | 0.33 | 1 |
| Broadwell | 1 | 0.33 | 1 |
| Haswell | 1 | 0.33 | 1 |
| Zen3 | 1 | 0.25 | 1 |
| Zen2 | 1 | 0.33 | 1 |
| Zen | 1 | 0.67 | 2 |
説明
int型の整数に対してブレンドします.
Intel CPUの場合epi16よりもスループットが高いです.
_mm256_blend_epi16 (AVX2)
__m256i _mm256_blend_epi16 (__m256i a, __m256i b, const int imm8)
asm: vpblendw ymm, ymm, ymm, imm8
動作
blend_epi16

CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 1 | 0.5 | - |
| Icelake | 1 | 0.5 | 1 |
| Skylake | 1 | 1 | 1 |
| Broadwell | 1 | 1 | 1 |
| Haswell | 1 | 1 | 1 |
| Zen3 | 1 | 0.25 | 1 |
| Zen2 | 1 | 0.33 | 1 |
| Zen | 1 | 0.67 | 2 |
説明
short型の整数に対してブレンドします.
Intel CPUは,32bitでの動作よりも遅いです.
64ビット整数のブレンドを作る:_mm256_blend_epi64
64ビット整数向けのブレンド命令はありません.
最も簡単なのは,ブレンド命令はビット単位の命令のため,浮動小数点命令であってもそのまま使えるためdouble用の命令をキャストして使うことです.
inline __m256i _mm256_blend_epi64 (__m256i a, __m256i b, const int imm8)
{
return _mm256_castpd_si256(_mm256_blend_pd (_mm256_castsi256_pd(a), _mm256_castsi256_pd(b), imm8));
}
もう一つは,32ビット整数ブレンド命令のマスクを工夫することです.
呼び出す関数は完全に同じで_mm256_blend_epi32を呼び出しますが,引数のimm8だけ変えます.
inline __m256i _mm256_blend_epi64 (__m256i a, __m256i b, const int imm8)
{
return _mm256_blend_epi32(a, b, imm8)
}
4つの要素をababとブレンドするためにdoubleのケースのように0b1010と指定したい場合は,0b11001100と値をデプリケートして入れれば所望の動作をします.
多くの場合で,整数への演算は,浮動小数点にキャストせず,他の整数命令で代用したほうが良い場合が多いです.
blendv
即値ではない変数に対応するブレンド命令です.
maskの最上位ビットが0の時aを,1の時bを出力します.
即値の場合よりも若干低速です.
_mm256_blendv_ps|pd (AVX)
__m256 _mm256_blendv_ps (__m256 a, __m256 b, __m256 mask)
__m256d _mm256_blendv_pd (__m256d a, __m256d b, __m256d mask)
asm: vblendvps ymm, ymm, ymm, ymm //ps
asm: vblendvpd ymm, ymm, ymm, ymm //pd
動作
blendv_ps
blendv_pd
CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 1 | 0.37 | - |
| Icelake | 1 | 0.33 | 1 |
| Skylake | 1 | 0.33 | 1 |
| Broadwell | 1 | 0.33 | 1 |
| Haswell | 1 | 0.33 | 1 |
| Ivy Bridge | 1 | 0.5 | 1 |
| Sandy Bridge | 1 | 0.5 | 1 |
| Zen3 | 3 | 0.25 | 1 |
| Zen2 | 3 | 0.38 | 1 |
| Zen | 1 | 1 | 2 |
- AIDA64 Icelake L:1,T:0.37, Alderlake L:1,T:0.37
説明
浮動小数点型に対してブレンドします.
マスクは__m256であり,各maskの最上位ビットが0の時aを,1の時bを出力します.
浮動小数点の最上位ビットは符号ビットであるため,マスクは負の値か正の値かで判断するマスクを作る必要があります.
マスクは比較演算で0と比較して生成してできます.
//topsign broadcast
inline __m256 _MM_BLENDMASK(const float v0, const float v1, const float v2, const float v3, const float v4, const float v5, const float v6, const float v7)
{
__m256 a = _mm256_set_ps(v0, v1, v2, v3, v4, v5, v6, v7);
return _mm256_cmp_ps(a, _mm256_setzero_ps(), 4);//!=0
}
//topsign broadcast
inline __m256d _MM_BLENDMASK(const double v0, const double v1, const double v2, const double v3)
{
__m256d a = _mm256_set_pd(v0, v1, v2, v3);
return _mm256_cmp_pd(a, _mm256_setzero_pd(), 4);//!=0
}
_mm256_blendv_epi8 (AVX2)
__m256i _mm256_blendv_epi8 (__m256i a, __m256i b, __m256i mask)
asm: vpblendvb ymm, ymm, ymm, ymm
動作
blendv_epi8

CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 3 | 1 | - |
| Icelake | 2 | 1 | 2 |
| Skylake | 2 | 1 | 2 |
| Broadwell | 2 | 2 | 2 |
| Haswell | 2 | 2 | 2 |
| Zen3 | 1 | 0.5 | 1 |
| Zen2 | 1 | 1 | 1 |
| Zen | 1 | 2 | 2 |
- AIDA64 Icelake L:2,T:1, Skylake L:2,T:1
- Alderlakeで遅くなっている可能性
説明
バイト型の値に大して要素ごとにブレンドし,各maskの最上位ビットが0の時aを,1の時bを出力します.
マスクの最上位ビットしか見ないため,全てをFにする必要はありません.
ただし,-1は0xFFFFF...の全てがFとなる値です.
blendv命令は,整数向けには,epi8しかなく,epi16や32,64に対しては,maskを修正することでblendv_epi8を呼び出すことになります.
最上位ビットが0か1で判定しているため,算術シフト命令で,最上位ビットを必要なところまでビットシフトする必要があります.
しかしながら,マスクが0x00と0xFFで作られているような,cmp命令によるマスク生成は,どのビットの出力であっても最上位ビットの符号がコピーされていることに相当しているため,何も処理をしなくても条件を満たしています.
そのままepi16,32,64に大して命令を発行すれば良いでしょう.
現在のCPUではすでに必要ないテクニックですが,epi32やepi64はfloat向け,double向け演算をキャストして使用することもできます.
論理演算によるブレンド命令の代替
ここでは,blend命令をあえて使わず,ビット演算だけでブレンドを実現する方法を説明します.
任意の値とのブレンド
説明
マスクが,0x00と0xFFで作られているという制約があれば,blendはビット演算3回で実現できます.
これは,マスクとブレンドしたいベクトルをandnot, and, orの順で実行することで実現し,任意のビット幅を持つ命令に対して実行可能です.
Intel CPUは,SkylakeやIcelakeのポートが3つ,レイテンシ1ですので,レイテンシ3,スループット1のブレンドが作れます.
AMD CPUは,Zen2,Zen3はポートが4つで,レイテンシ1ですので,レイテンシ3,スループット0.75のブレンドが作れます.
しかしながら,どちらも,専用ハードウェアのblend命令よりも遅いため,現在必要な場面はありません.
整数に対する論理演算のレイテンシとスループット(再掲)
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Icelake | 1 | 0.33 | 1 |
| Skylake | 1 | 0.33 | 1 |
| Broadwell | 1 | 0.33 | 1 |
| Haswell | 1 | 0.33 | 1 |
| Zen3 | 1 | 0.25 | 1 |
| Zen2 | 1 | 0.25 | 1 |
| Zen | 1 | 0.5 | 2 |
inline __m256i _mm256_blendv_logic_si256(__m256i a, __m256i b, __m256i mask)
{
__m256i da = _mm256_andnot_si256(mask, a);
__m256i db = _mm256_and_si256(mask, b);
return _mm256_or_si256(da, db);
}
inline __m256 _mm256_blendv_logic_ps(__m256 a, __m256 b, __m256 mask)
{
__m256 da = _mm256_andnot_ps(mask, a);
__m256 db = _mm256_and_ps(mask, b);
return _mm256_or_ps(da, db);
}
inline __m256d _mm256_blendv_logic_pd(__m256d a, __m256d b, __m256d mask)
{
__m256d da = _mm256_andnot_pd(mask, a);
__m256d db = _mm256_and_pd(mask, b);
return _mm256_or_pd(da, db);
}
0とのブレンド
説明
論理演算によるブレンドの考え方は,0とのブレンドの場合のみ有効です.
該当するのは下記のような,条件を満たさないときは0に落とすような処理です.
b = (a>thresh)?a:0
論理演算によるブレンド処理は,論理演算によって必要なビットの場所を残し,それ以外を0に落とした後,or演算で結合する処理です.
つまり,0とのブレンドは1度目の論理演算ですでに達成しています.
0x00と0xFFのマスクを持つとき,andやandnot命令の1命令で,0のマスクを持つ・持たないところをだけ0に落とすことができます.
一部のアーキテクチャではblend命令よりも論理演算命令のほうがスループットが速いです.
加えて,ゼロとのブレンドは,実際はゼロのマスクを生成しなくてはならず,これはxorのビット演算で作るためゼロコストではありません.
つまりゼロとのブレンドは,すべてのアーキテクチャでこちらのほうが高速です.
下記に例を示します.
なお,_mm_xxxxは任意の命令です.
__m128 blendzero_nz_ps(__m128 input)
{
__m128 mask = _mm_cmpeq_ps(_mm_setzero_ps(), input);
__m128 val = _mm_xxxxxx_ps(input);
return _mm_andnot_ps(mask, val);
}