はじめに
遅い計算代表の除算と平方根について説明します.
除算(DIV)
浮動小数点の除算を行います.
除算は低速です.精度が不要な場合は次項目のRCPを使用してください.
逆数の計算は,近似アルゴルリズムにより高速に計算可能です.
また,整数の除算命令はハードウェア実装にはありません.
2のべき乗ならビットシフトで表現可能です.
またいくつかのアルゴリズムにより高速な実装も可能です.
任意の値で整数値で除算する場合は,SVMLにより効率的な実装が使えます.
SVMLに関しては,ソフトウェア実装の章を参照してください.
_mm256_div_ps (AVX)
__m256 _mm256_div_ps (__m256 a, __m256 b)
asm: vdivps ymm, ymm, ymm
動作
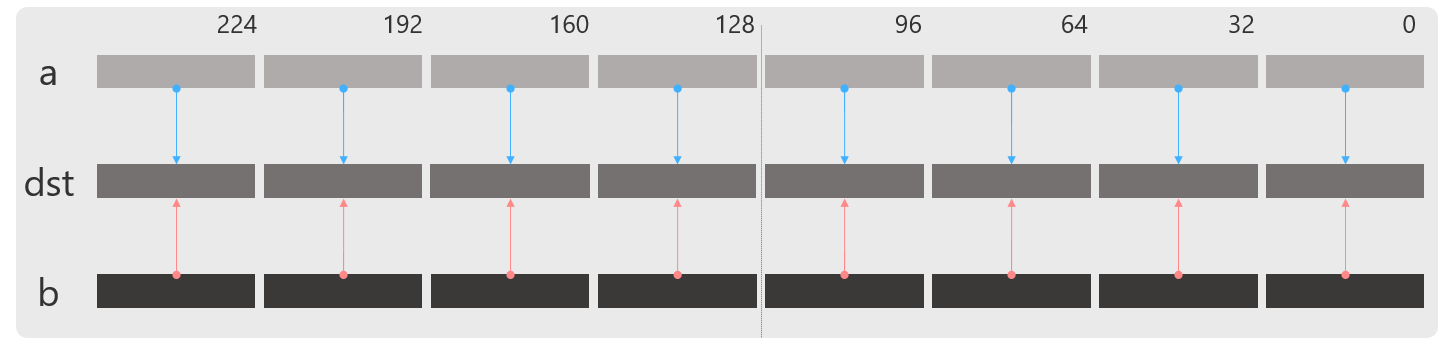
_mm256_div_ps
CPI/Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 11/6.5 | 5 | - |
| Icelake | 11/7.8 | 5 | 1 |
| Skylake | 11/8.7 | 5 | 1 |
| Broadwell | 17.2/16.6 | 10 | 3 |
| Haswell | 21.1/17.8 | 14 | 3 |
| Ivy Bridge | 21/17.8 | 14 | 3 |
| Sandy Bridge | 29.5/21.4 | 28/20 | 3 |
| Zen3 | 10.5 | 3.5 | 1 |
| Zen2 | 10.2/9.1 | 3.5 | 1 |
| Zen | 10/9.6 | 6 | 2 |
- 通常/高速:速いのは特定の数値の時です(x/2.f, x/0.5fなど)
- AIDA64 zen3 L10.5, T:2.42,UOps T:3.5
説明
8要素の浮動小数点の除算を行います.
その他の算術演算に比べて圧倒的に遅いです.
使用には注意してください.
_mm256_div_pd (AVX)
__m256d _mm256_div_pd (__m256d a, __m256d b)
asm: vdivpd ymm, ymm, ymm
動作
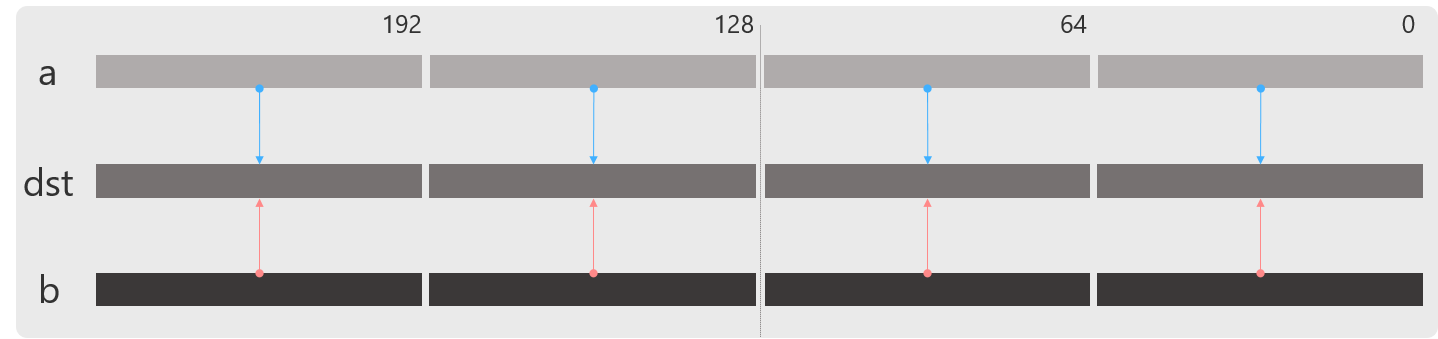
_mm256_div_pd
CPI/Uops
UOps
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 13.9/8.9 | 8 | - |
| Icelake | 15/13 | 8 | 1 |
| Skylake | 15/13 | 8 | 1 |
| Broadwell | 23/19 | 16 | 3 |
| Haswell | 35/19 | 16.12 | 3 |
| Ivy Bridge | 35/19 | 16.45 | 3 |
| Sandy Bridge | 45/21 | 20 | 3 |
| Zen3 | 13 | 4.5 | 1 |
| Zen2 | 13 | 5.0 | 1 |
| Zen | 14 | 8 | 2 |
AIDA64
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 13.9/8.9 | 8 | - |
| Icelake | 14/10 | 8 | 1 |
| Skylake | 14/10.8 | 8 | 1 |
| Broadwell | 23/19 | 16.25 | 3 |
| Haswell | 35.1/18.9 | 28.8/16.17 | 3 |
| Ivy Bridge | 35/19 | 28/16.5 | 3 |
| Sandy Bridge | 45.5/21.4 | 44/19.92 | 3 |
| Zen3 | 13.5 | 4.25 | 1 |
| Zen2 | 13.1/11.7 | 5.08 | 1 |
| Zen | 13/8 | 9/8 | 2 |
- 速いのは特定の数値の時です(x/1.f, x/2.f など)
説明
4要素の浮動小数点の除算を行います.
その他の算術演算に比べて圧倒的に遅いです.
floatの場合よりも更に低速です.
使用には注意してください.
平方根(SQRT)
引数の平方根を取ります.
除算と同様に重たい処理になります.
高速化する場合は,rsqrtを使用してください.
_mm256_sqrt_ps (AVX)
__m256 _mm256_sqrt_ps (__m256 a)
asm: vsqrtps ymm, ymm
動作
_mm256_sqrt_ps
CPI/Uops
UOps
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Icelake | 12-13 | 6 | - |
| Skylake | 12-13 | 6 | 1 |
| Broadwell | 18-21 | 14 | 1 |
| Haswell | 18-21 | 14 | 1 |
| Ivy Bridge | 18-21 | 14 | 1 |
| Sandy Bridge | 21-29 | 20 | 1 |
| Zen3 | -14 | 5.0 | 1 |
| Zen2 | -14 | 5.5 | 1 |
| Zen | 8-15 | 8 | 2 |
AIDA64
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Akderlake | 11.9 | 6 | - |
| Icelake | 12 | 6 | 1 |
| Skylake | 12 | 6 | 1 |
| Broadwell | 21 | 14.08 | 1 |
| Haswell | 21.1 | 14.17 | 1 |
| Ivy Bridge | 21 | 14.17 | 1 |
| Sandy Bridge | 29.5 | 28 | 1 |
| Zen3 | 14.5 | 3.67 | 1 |
| Zen2 | 14.2 | 5.67 | 1 |
| Zen | 14 | 10 | 2 |
説明
float型の平方根を計算します.
レイテンシとスループットがだいぶ大きな演算です.
_mm256_sqrt_pd (AVX)
__m256d _mm256_sqrt_pd (__m256d a)
asm: vsqrtpd ymm, ymm
動作
_mm256_sqrt_pd
CPI/Uops
UOps
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 17.9/12.9 | 11.92/9 | - |
| Icelake | 19/13 | 9 | - |
| Skylake | 20/13 | 9 | 1 |
| Broadwell | 35/19 | 16 | 3 |
| Haswell | 35/19 | 16.12 | 3 |
| Ivy Bridge | 35/19 | 16.45 | 3 |
| Sandy Bridge | 43/21 | 20 | 3 |
| Zen3 | -20 | 8.5 | 1 |
| Zen2 | -20 | 8.5 | 1 |
| Zen | 8-20 | 8 | 1 |
AIDA64
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 17.9/12.9 | 11.92/9 | - |
| Icelake | 18.0/13.0 | 12/9 | - |
| Skylake | 18.0/13.0 | 12/9 | - |
| Broadwell | 35.1/19.0 | 28/16.08 | - |
| Haswell | 35.1/19.1 | 28.08/16.08 | - |
| Ivy Bridge | 35/19 | 28/16.5 | - |
| Sandy Bridge | 43.3/21.5 | 43.5/19.92 | - |
| Zen3 | 20.5 | 8.5/6.75 | - |
| Zen2 | 20.1 | 8.83/8 | - |
| Zen | 20/8 | 16/8 | - |
説明
double型の平方根を計算します.
float型よりも更にレイテンシとスループットがだいぶ大きな演算です.