はじめに
全てデータを交互にインタリーブする命令を説明します.
同時に,インタリーブすることによって型変換する方法を説明します.
データをそのままインタリーブするのが,unpack命令です.
2つのデータをインタリーブすると,データ量が倍になるため,下位ビットだけインタリーブする命令と上位ビットだけインタリーブする命令が用意されています.
下記のpack命令に対応した,パックをしない命令がunpackです.
一方で,データをパックして小さくして(半減にして)インタリーブするのが,packs命令です.
パックするときにデータの桁が落ちるため飽和演算(saturate)を行うためpack(s)が付いています.
データ量はそのままのため,下位ビット用,上位ビット用の命令はありません.
unpack
| float | double | epi8 | epi16 | epi32 | epi64 | |
|---|---|---|---|---|---|---|
| lo | unpacklo_ps | unpacklo_pd | unpackhi_epi8 | unpackhi_epi16 | unpackhi_epi32 | unpackhi_epi64 |
| hi | unpackhi_ps | unpackhi_pd | unpacklo_epi8 | unpacklo_epi16 | unpacklo_epi32 | unpacklo_epi64 |
unpackのps,pdへの命令はAVXから.
pack
| float | double | epi8 | epi16 | epi32 | epi64 | |
|---|---|---|---|---|---|---|
| x | x | x | packs_epi16 packus_epi16 |
packs_epi32 packus_epi32 |
x |
unpack
_mm256_unpacklo|hi_ps|pd (AVX)
__m256 _mm256_unpacklo_ps (__m256 a, __m256 b)
__m256 _mm256_unpackhi_ps (__m256 a, __m256 b)
__m256d _mm256_unpacklo_pd (__m256d a, __m256d b)
__m256d _mm256_unpackhi_pd (__m256d a, __m256d b)
asm: vunpcklps ymm, ymm, ymm
asm: vunpckhps ymm, ymm, ymm
asm: vunpcklpd ymm, ymm, ymm
asm: vunpckhpd ymm, ymm, ymm
動作
unpacklo_ps

unpackhi_ps

unpacklo_pd

unpackhi_pd

CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 1 | 1 | - |
| Icelake | 1 | 1 | 1 |
| Skylake | 1 | 1 | 1 |
| Broadwell | 1 | 1 | 1 |
| Haswell | 1 | 1 | 1 |
| Ivy Bridge | 1 | 1 | 1 |
| Sandy Bridge | 1 | 1 | 1 |
| Zen3 | 1 | 0.5 | 1 |
| Zen2 | 1 | 0.5 | 1 |
| Zen | 1 | 1 | 2 |
- UopsのサイトのみZenシリーズのレイテンシがすべて3になっています.
- 公式ドキュメントは1,Agner Fogのデータも1,instlatx64のデータも1となっているため,1に修正しています.
- なお,スループットは,Uopsも含めてすべて同一です.
- Intel,AMDともにメモリから読み込むとマククロヒュージョンされてUopsはすべて1つ減ります.
説明
2つの浮動小数点の前半の値もしくは後半の値をインタリーブして1つにブレンドして出力します.
aabbaabbに混ぜるshuffle_psでは,ababababとインタリーブするこの命令と同じ並びは実現できません.
シャフルと同じポートです.
インタリーブして出力する例
inline void _mm256_store_interleave_ps(void* dst, const __m256 d0, const __m256 d1)
{
__m256 s1 = _mm256_unpacklo_ps(d0, d1);
__m256 s2 = _mm256_unpackhi_ps(d0, d1);
_mm256_store_ps((float*)dst + 0, _mm256_permute2f128_ps(s1, s2, 0x20));
_mm256_store_ps((float*)dst + 8, _mm256_permute2f128_ps(s1, s2, 0x31));
}
_mm256_unpacklo|hi_epi8|16|32|64 (AVX2)
__m256i _mm256_unpackhi_epi8 (__m256i a, __m256i b)
__m256i _mm256_unpackhi_epi16 (__m256i a, __m256i b)
__m256i _mm256_unpackhi_epi32 (__m256i a, __m256i b)
__m256i _mm256_unpackhi_epi64 (__m256i a, __m256i b)
__m256i _mm256_unpacklo_epi8 (__m256i a, __m256i b)
__m256i _mm256_unpacklo_epi16 (__m256i a, __m256i b)
__m256i _mm256_unpacklo_epi32 (__m256i a, __m256i b)
__m256i _mm256_unpacklo_epi64 (__m256i a, __m256i b)
asm: vpunpckhbw ymm, ymm, ymm //hi_epi8
asm: vpunpckhwd ymm, ymm, ymm //hi_epi16
asm: vpunpckhdq ymm, ymm, ymm //hi_epi32
asm: vpunpckhqdq ymm, ymm, ymm //hi_ep64
asm: vpunpcklbw ymm, ymm, ymm //lo_epi8
asm: vpunpcklwd ymm, ymm, ymm //lo_epi16
asm: vpunpckldq ymm, ymm, ymm //lo_epi32
asm: vpunpcklqdq ymm, ymm, ymm //lo_epi64
動作
unpacklo_epi8

unpackhi_epi8
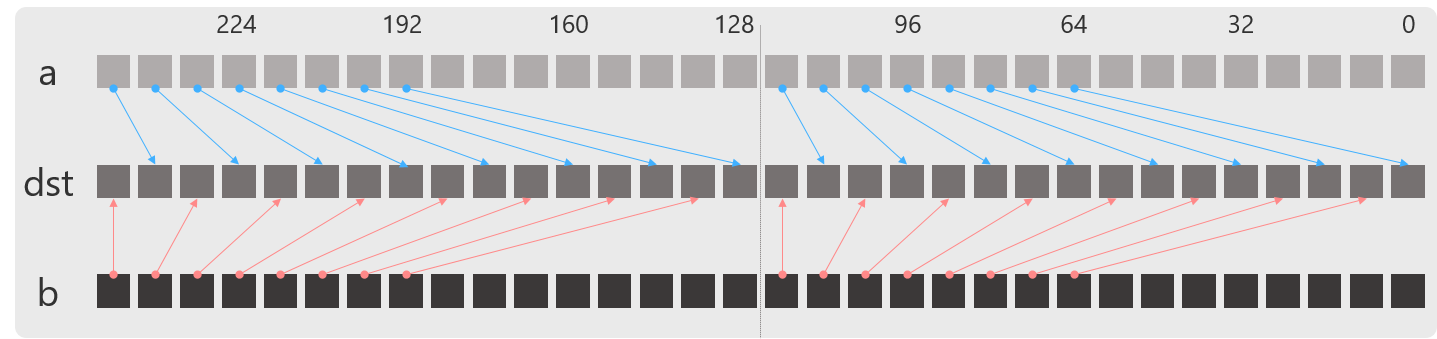
unpacklo_epi16

unpackhi_epi16

unpacklo_epi32
unpackhi_epi32
unpacklo_epi64
unpackhi_pd64
CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 1 | 0.5 | - |
| Icelake | 1 | 0.5 | 1 |
| Skylake | 1 | 1 | 1 |
| Broadwell | 1 | 1 | 1 |
| Haswell | 1 | 1 | 1 |
| Zen3 | 1 | 0.5 | 1 |
| Zen2 | 1 | 0.5 | 1 |
| Zen | 1 | 1 | 2 |
- Broadwell Haswellは,qdq命令のみマイクロフュージョンできません.
説明
2つの整数の前半の値もしくは後半の値をインタリーブして1つにブレンドして出力します.
pack
2つの整数レジスタをインタリーブしてブレンドし,上位ビットを切り詰めて出力します.
_mm256_packs|packus_epi32 (AVX2)
__m256i _mm256_packs_epi32 (__m256i a, __m256i b)
asm: vpackssdw ymm, ymm, ymm
__m256i _mm256_packus_epi32 (__m256i a, __m256i b)
asm: vpackusdw ymm, ymm, ymm
動作
packs_epi32/packus_epi32

CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 3 | 1 | - |
| Icelake | 3 | 1 | 1 |
| Skylake | 1 | 1 | 1 |
| Broadwell | 1 | 1 | 1 |
| Haswell | 1 | 1 | 1 |
| Zen3 | 1 | 0.5 | 1 |
| Zen2 | 1 | 0.5 | 1 |
| Zen | 1 | 1 | 2 |
- IcelakeとAlderlakeは,uops, AIDA64でL3, T:1で前世代よりも遅くなっています.Agnerには記載ありません.
説明
符号あり32ビット整数をインタリーブし,上位ビットを切り詰めて16ビット整数として出力します.
あふれた桁は飽和演算で打ち切られます.
aを前半に,bを後半に入れますが128ビットの壁を越えません.
packsは符号ありとして,飽和演算を行い,packusは符号なしとして飽和演算を行います.
なお,入力は両者ともに符号あり整数です.
_mm256_packs|packus_epi16 (AVX2)
__m256i _mm256_packs_epi16 (__m256i a, __m256i b)
asm: vpacksswb ymm, ymm, ymm
__m256i _mm256_packus_epi16 (__m256i a, __m256i b)
asm: vpackuswb ymm, ymm, ymm
動作
packs_epi16/packus_epi16

CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 3 | 1 | - |
| Icelake | 3 | 1 | 1 |
| Skylake | 1 | 1 | 1 |
| Broadwell | 1 | 1 | 1 |
| Haswell | 1 | 1 | 1 |
| Zen3 | 1 | 0.5 | 1 |
| Zen2 | 1 | 0.5 | 1 |
| Zen | 1 | 1 | 2 |
- Icelake:uops, AIDA64でL3, T:1で他よりも遅い.Agnerには記載なし.
説明
符号あり16ビット整数をインタリーブし,8ビット整数として出力します.
あふれた桁は飽和演算で打ち切られます.
aを前半に,bを後半に入れますが128ビットの壁を越えません.
packsは符号ありとして,飽和演算を行い,packusは符号なしとして飽和演算を行います.
なお,入力は両者ともに符号あり整数です.
主に使われる変換は,整数の型変換ですが,YMMレジスタを用いる場合は,128ビットの壁を超えるためにpermute命令が必要になります.
packs命令による整数変換には,実質,レイテンシ3,スループット1の_mm256_permute4x64_epi64が必須です.
Icelakeのレイテンシは長いですが,AVX512に対応しており,主目的の整数変換としてはより高性能となる命令が使えます.
例えば下記の16ビット整数から8ビット整数に変換する命令は,レイテンシ4,スループット2で動作します.
__m256i _mm512_cvtepi16_epi8 (__m512i a)
asm: vpmovwb ymm, zmm
また下記のあえてYMMレジスタだけで抑えて使う命令は,レイテンシ4,スループット1で動作します.
__m128i _mm256_cvtepi16_epi8 (__m256i a)
asm: vpmovwb xmm, ymm
あえてYMMレジスタだけで抑えて使う場合は,2つのデータを同時に処理できるpackのほうが動作が高速です.
unpack/packsによる型変換
unpackによる小さいサイズの整数からの大きいサイズの整数型への変換
unpack,packは2つのベクトルをインタリーブする命令です.
このunpackを用いて,全てゼロのベクトルとインタリーブすることで0拡張ができ,整数型をcharからshortへ,shortをintへ,intをlong longへと大きな型に変換することができます.
SSE4.1からcvtepixx_expxxが導入されたためそれまではunpack/pack命令を使って整数の型変換を行ってきました.
しかし,この変換は手順が多く,またレジスタも多く使います.
計算コストもcvt命令とほぼ同一で,加えて,多くのレジスタを使用することからレジスタスピルを引き起こしやすく性能が低下する可能性もあります.
変換命令が十分ではなかったSSE命令の時代とは異なり,AVXを使う限りは,cvt命令で変換すれば十分です.
packによる大きいサイズの整数からの小さいサイズの整数型への変換
packは2つのベクトルの各要素の下位ビットをインタリーブして出力する命令です.
つまり,上位ビットを切り捨てて使えば,大きな型から小さな型へ変換できます.
packを用いることでlong longをintに,intをshortに,shortをcharにと,小さな型に変換することができます.
小さいサイズへの整数型変換のintrinsicsは,AVX512からのサポートとなっており,AVX2までは,packによる整数型変換を用いないといけません.
下記に対応するinline関数を示します.
SSE命令でpacks命令を使うことで,2つの大きな整数型を1つの小さな整数型に変換することができます.
inline __m128i _mm_cvtepi32x2_epi16(__m128i a, __m128i b)
{
return _mm_packs_epi32(a, b);
}
inline __m128i _mm_cvtepi32x2_epu16(__m128i a, __m128i b)
{
return _mm_packus_epi32(a, b);
}
inline __m128i _mm_cvtepi16x2_epi8(__m128i a, __m128i b)
{
return _mm_packs_epi16(a, b);
}
inline __m128i _mm_cvtepi16x2_epu8(__m128i a, __m128i b)
{
return _mm_packus_epi16(a, b);
}
AVX2命令の場合,並び順を修正しないといけないためpermute命令も同時に発行する必要があります.
inline __m256i _mm256_cvtepi32x2_epi16(__m256i a, __m256i b)
{
return _mm256_permute4x64_epi64(_mm256_packs_epi32(a, b), _MM_SHUFFLE(3, 1, 2, 0));
}
inline __m256i _mm256_cvtepi32x2_epu16(__m256i a, __m256i b)
{
return _mm256_permute4x64_epi64(_mm256_packus_epi32(a, b), _MM_SHUFFLE(3, 1, 2, 0));
}
inline __m256i _mm256_cvtepi16x2_epi8(__m256i a, __m256i b)
{
return _mm256_permute4x64_epi64(_mm256_packs_epi16(a, b), _MM_SHUFFLE(3, 1, 2, 0));
}
inline __m256i _mm256_cvtepi16x2_epu8(__m256i a, __m256i b)
{
return _mm256_permute4x64_epi64(_mm256_packus_epi16(a, b), _MM_SHUFFLE(3, 1, 2, 0));
}
参考までに,packsとpermute4x64命令のパフォーマンスを示します.
Icelakeのpack命令はこれまでと比べて重たくなっていますが,小さな型へのキャスト命令がAVX512で用意されているため,pack命令を使って変換する必要がありません.
packus_epi16|epi32のパフォーマンス
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Icelake | 3 | 1 | 1 |
| Skylake | 1 | 1 | 1 |
| Broadwell | 1 | 1 | 1 |
| Haswell | 1 | 1 | 1 |
| Zen3 | 1 | 0.5 | 1 |
| Zen2 | 1 | 0.5 | 1 |
| Zen | 1 | 1 | 2 |
permute4x64のパフォーマンス
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Icelake | 3 | 1 | 1 |
| Skylake | 3 | 1 | 1 |
| Broadwell | 3 | 1 | 1 |
| Haswell | 3 | 1 | 1 |
| Zen3 | 6.5 | 1.25 | 2 |
| Zen2 | 6 | 1.25 | 2 |
| Zen | 2 | 2 | 3 |