はじめに
浮動小数点比較命令を説明します.
compare命令は,要素a,bを比較し,比較結果が真なら0xFFFFFFFFを,偽なら0x00000000を示すマスクを返してベクトルに格納する命令です.
_mm256_cmp_ps|pd(a,b,option)で呼び出すことが可能です.
また,比較演算の>, <, ==, >=, <=, !=は,オプションで指定可能です.
オプションは,以下の通り31通りあります.
0: OP := _CMP_EQ_OQ
1: OP := _CMP_LT_OS
2: OP := _CMP_LE_OS
3: OP := _CMP_UNORD_Q
4: OP := _CMP_NEQ_UQ
5: OP := _CMP_NLT_US
6: OP := _CMP_NLE_US
7: OP := _CMP_ORD_Q
8: OP := _CMP_EQ_UQ
9: OP := _CMP_NGE_US
10: OP := _CMP_NGT_US
11: OP := _CMP_FALSE_OQ
12: OP := _CMP_NEQ_OQ
13: OP := _CMP_GE_OS
14: OP := _CMP_GT_OS
15: OP := _CMP_TRUE_UQ
16: OP := _CMP_EQ_OS
17: OP := _CMP_LT_OQ
18: OP := _CMP_LE_OQ
19: OP := _CMP_UNORD_S
20: OP := _CMP_NEQ_US
21: OP := _CMP_NLT_UQ
22: OP := _CMP_NLE_UQ
23: OP := _CMP_ORD_S
24: OP := _CMP_EQ_US
25: OP := _CMP_NGE_UQ
26: OP := _CMP_NGT_UQ
27: OP := _CMP_FALSE_OS
28: OP := _CMP_NEQ_OS
29: OP := _CMP_GE_OQ
30: OP := _CMP_GT_OQ
31: OP := _CMP_TRUE_US
オプションの文字列が意味するのは,CMP以下の1つ目の項は以下の通りです.
EQ: a==b
NEQ: a!=b
GE: a>=b
GT: a>b
LE: a<=b
LT: a<b
NGE: !(a>=b)
NGT: !(a>b)
NLE: !(a<=b)
NLT: !(a<b)
また,2つ目の項は,要素にNaNが入っていた場合の処理のオプションであり,NaNが入っていなければどれを選んでも処理速度も結果も変わりません.
比較最後のO/U/Q/Sのオプションは,真の時に返す0xFFFFFFFFがNaNを示しており,それが入力に入ってきたときにうまくハンドリングするための対策のためのオプションです.
通常の演算では,0/0=NaN, +a/0 = +inf, -a/0 = -infが返くるため,これらをハンドリングするための処理です.
まず,O: ordered,U: unorderedをそれぞれ示しており,EQとNEQにそのオプションの選択肢が存在します.
なお,その他の比較は,ordered,not付き比較はunorderedのみが実装されています.
EQでorderedの場合は,NaNと数値比較した結果は0が返ってきて,unorderedの場合はNaNが返ってきます.
簡単に説明すると,orderedはNaNとのAnd演算であり,unorderedはNaNとのOr演算となります.
また,Q: quietとS: signalingは,Sの場合に例外を生じさせ,Qの場合は無視します.
注意:SSEの場合は,_mm_cmp_psのオプションを変えるのではなく,以下の関数を使い分ける.
AVXが対応する世代のCPUではAVXの関数と同様にオプションを変えるだけで関数が切り替えられる.
_mm_cmpeq_ps: a==b_mm_cmpneq_ps: a!=b_mm_cmpge_ps: a>=b_mm_cmpgt_ps: a>b_mm_cmple_ps: a<=b_mm_cmplt_ps: a<b
_mm256_cmp_ps|pd
__m256 _mm256_cmp_ps (__m256 a, __m256 b, const int imm8)
__m256d _mm256_cmp_pd (__m256d a, __m256d b, const int imm8)
Instruction: vcmpps ymm, ymm, ymm, imm8 //ps
Instruction: vcmppd ymm, ymm, ymm, imm8 //pd
動作
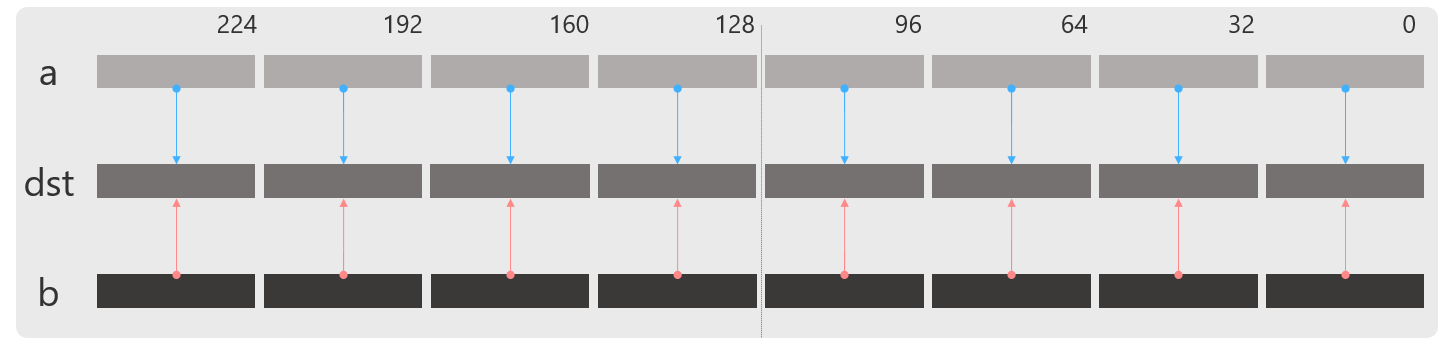
_mm256_cmp_ps
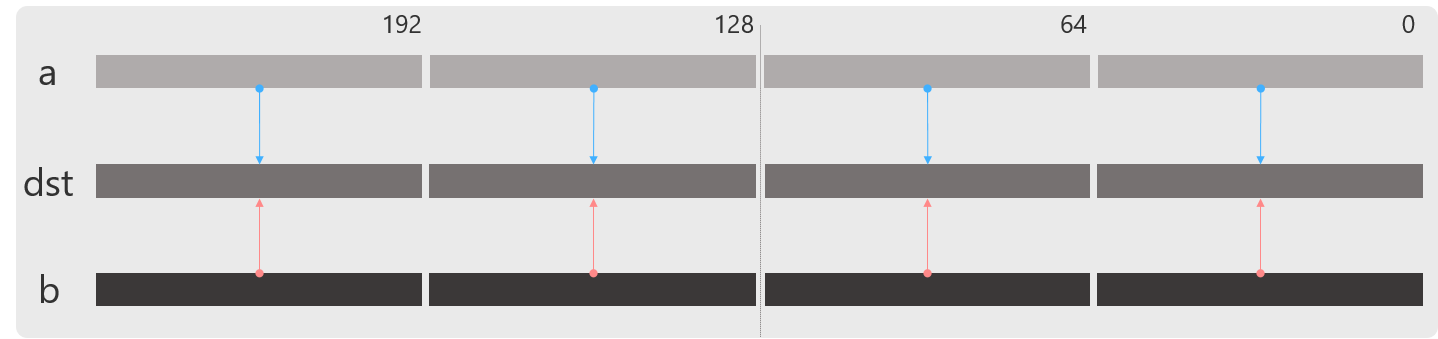
_mm256_cmp_pd
CPI, Uops
| Architecture | Latency | Throughput | Uops |
|---|---|---|---|
| Alderlake | 4 | 0.5 | - |
| Icelake | 4 | 0.5 | 1 |
| Skylake | 4 | 0.5 | 1 |
| Broadwell | 3 | 1 | 1 |
| Haswell | 3 | 1 | 1 |
| Ivy Bridge | 3 | 1 | 1 |
| Sandy Bridge | 3 | 1 | 1 |
| Zen3 | 1 | 0.5 | 1 |
| Zen2 | 1 | 0.5 | 1 |
| Zen | 1 | 1 | 2 |
- 整数に比べて遅いです
- AMDのZenシリーズのレイテンシは短いです
説明
float/doubleに対する比較命令を行います.
dst[i+31:i] := ( a[i+31:i] OP b[i+31:i] ) ? 0xFFFFFFFF : 0 //ps
dst[i+63:i] := ( a[i+63:i] OP b[i+63:i] ) ? 0xFFFFFFFFFFFFFFFF : 0 //pd