この記事の概要
2026/02/06
AWS Certified Generative AI Developer - Professional (AIP-C01)
を受験したので、その時の記録
復習用ノートとして、また後で見返して今後の資格試験受験時の参考用にまとめます。
試験の概要

2025/11/18 よりベータ登録が始まった生成AI関連のProfessionalレベルの資格です。
◼︎ 試験要項
問題数 :85問 ※ベータ試験期間のため10問追加
試験時間 :205分 ※ベータ試験期間のため25分追加
受験料 :¥20,000(税別) ※ベータ試験期間のため半額
合格ライン:100~1000点中750点(約72%)
受験資格 :なし
有効期限 :3年
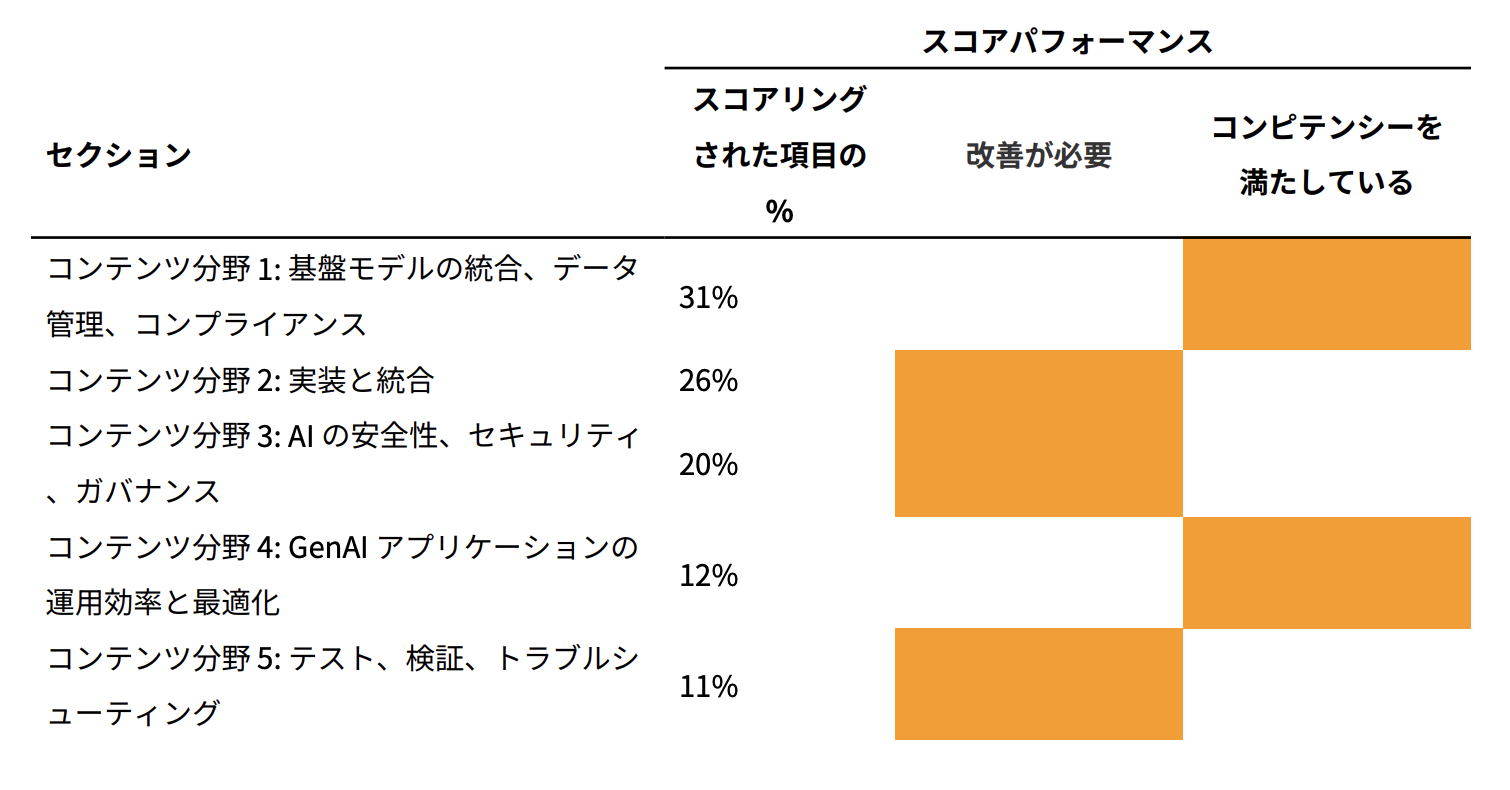
◼︎ 出題範囲
| 分野 | 出題割合 |
|---|---|
| 第 1 分野: 基盤モデルの統合、データ管理、コンプライアンス | 31% |
| 第 2 分野: 実装と統合 | 26% |
| 第 3 分野: AI の安全性、セキュリティ、ガバナンス | 20% |
| 第 4 分野: GenAI アプリケーションの運用効率と最適化 | 12% |
| 第 5 分野: テスト、検証、トラブルシューティング | 11% |
2026/02時点の最新バージョン(Ver.1.0) 試験ガイドに記載されているものです。
バージョンアップで範囲等は変更されるので、受験時は公式の試験ガイドを確認してください。
AWS Certified Generative AI Developer - Professional (AIP-C01) 試験ガイド
◼︎ 出題形式
新しいAWS認定試験のため「択一選択問題」「複数選択問題」に加えて「並べ替え」と「内容一致」の問題も出題されます。

勉強開始前の状態
AWSで動いているアプリケーションの開発/運用の業務を8年程度、現在も継続中。
AWS認定は15個取得済み。(うち4個は廃止済み)
- AWS認定ソリューションアーキテクトを受験した時の話
- AWS認定デベロッパーアソシエイトを受験した時の話
- AWS認定SysOpsアドミニストレーターアソシエイトを受験した時の話
- AWS認定ソリューションアーキテクトプロフェッショナルを受験した時の話
- AWS認定DevOpsエンジニアプロフェッショナルを受験した時の話
- AWS認定セキュリティ - 専門知識を受験した時の話
- AWS認定データベース - 専門知識を受験した時の話
- AWS認定アドバンストネットワーキング - 専門知識を受験した時の話
- AWS認定データ分析 - 専門知識を受験した時の話
- AWS認定機械学習 - 専門知識を受験した時の話
- AWS認定SAP on AWS - 専門知識を受験した時の話
- AWS Certified Data Engineer - Associate受験時の記録
- AWS Certified AI Practitioner(AIF)受験時の記録
- AWS Certified Machine Learning Engineer - Associate受験時の記録
※CLFはAll Certificateのために後半で取得したので特に書くこともなく記事にしていません。
勉強に使ったもの
1. AWS Skill Builder
AWS公式のE-Learningと問題集が無料で提供されているので、対象資格の関連コースを見ておきます。
2026/01/17時点では日本語の教材は有償のものしかありませんでした。
英語の教材は無償のものもいくつかありました。翻訳して使っていきます。
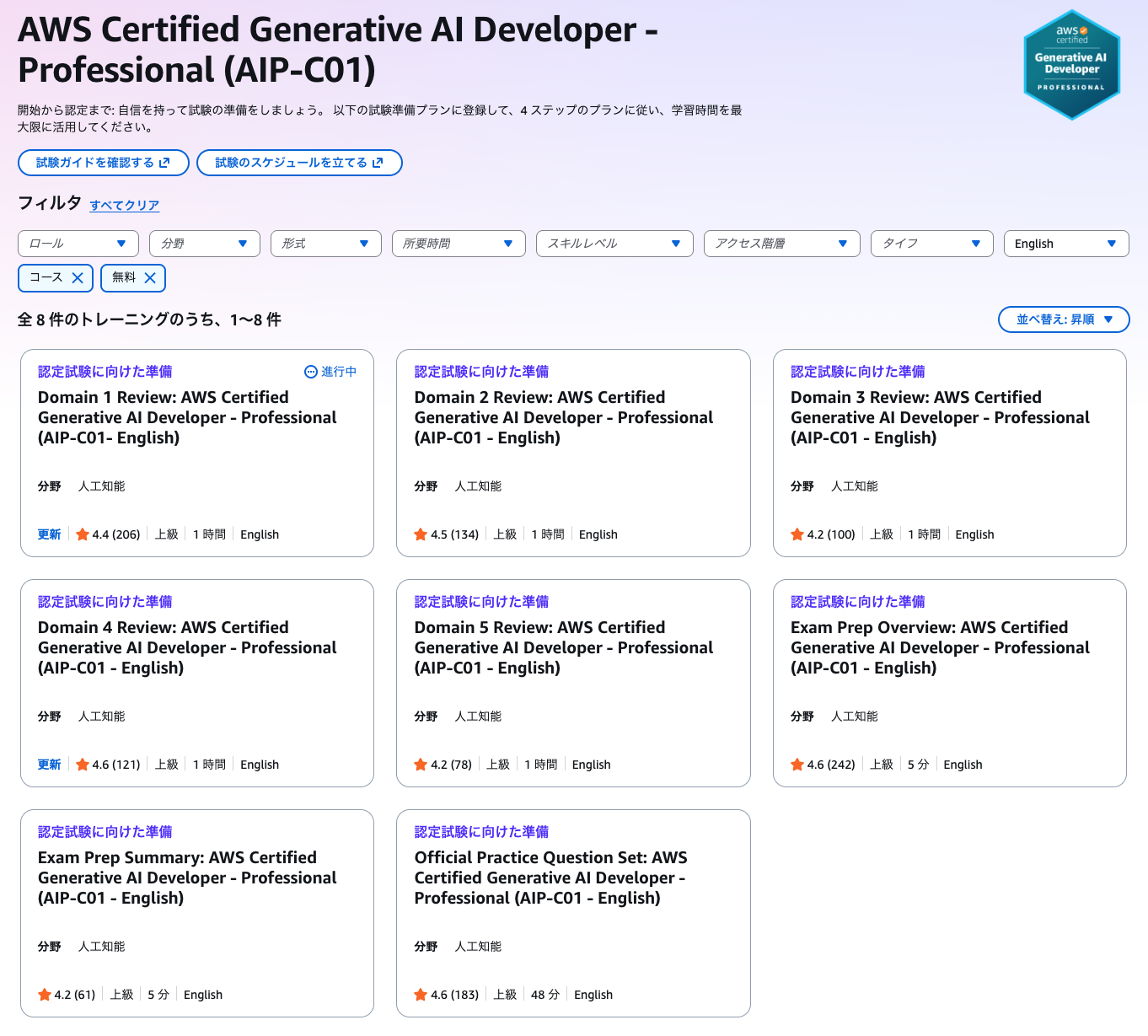
「Official Practice Question Set」が練習問題、「Domain 1~5 Review」が分野ごとのE-Learningコースです。
E-Learningの動画部分は字幕も英語ですが、動画の下に文字起こし結果が付いているので一応翻訳して読みながら見ることはできます。
「Exam Prep」は試験ガイドに書かれている出題形式など試験概要の解説コースなので飛ばしても大丈夫です。
2. オンライン問題集1(非公式)
Wizlabsはまだ75問(無料問題25問+通常問題50問)しか用意されていないようなので、無料問題25問だけ利用しました。
3. オンライン問題集2(非公式)
Udemyの問題集で評価が高いものを選びました。日本語の問題集はあまり評価が高くなかったので英語の問題集を翻訳して使います。
¥4,800で275問(85問×3セット+20問1セット)、時々セールで69%オフになるようです。今回はセール中に購入したので¥1,500でした。
序盤はやさしい内容で、解説を読んで理解度が上がるのに合わせるように少しずつ難易度が上がっていく構成になっており、解説もしっかりしていてなかなかいい内容でした。
4. 書籍
昔(2024/07頃)購入した生成AIアプリ開発入門の本を読み返しました。
2025/10に同じシリーズの新しい本が発売されていたので、こちらも購入し読んでおきました。
このシリーズはAI関連の概念や用語についてわかりやすく噛み砕いた説明が多く、具体的なAWSサービスやツールを例に書かれているのでイメージしやすく、勉強になりました。
AI関連の書籍は流行のアップデートの早さに追いつけている作者が少ないのか、レビュー評価が低めのものが多いなか、書かれている方がきっちり技術に触れて理解されているんだろうなーという印象です。
5. Amazon Q Developer
AWSの提供するAmazon Q DeveloperはAWSについて学習済みなので、AWSサービスに関する質問には素早く答えてくれます。わからないことがあったらすぐに質問できて非常に便利です。
設定方法は ![]() こちらのページがわかりやすかったです。
こちらのページがわかりやすかったです。
6. MCPサーバー
AWSでは公式ドキュメント内を検索できるMCPサーバーが用意されているので、これを活用してAmazon Q DeveloperなどのAIエージェントで検索させると目的のページに早くたどり着けたり、内容を要約してもらえたりして学習効率が大きく向上します。
ベータ版試験では最近発表されたサービスなども出題範囲に入っているので、Amazon Q Developerが未学習の情報はMCPサーバーで検索させると見つかったりします。
7. AWSアカウント
実際に触ってみないとイマイチイメージしづらかったり、覚えづらい部分もあるので普段触らないサービスはチュートリアルなどで少し触っておきます。
時間がないときは対象AWSサービスの「リソース作成」画面だけでも触っておくと設定項目として登場する用語や概念を知ることができます。
勉強時間
約40時間
あまり期間に余裕がなかったので、E-Learning→書籍→問題集の座学メインで学習しました。
Bedrockは構築をほとんどやらなかったので、もう少し触っておきたかったです。
受験後
スコアは763で合格 ![]()

先着5,000名のEarly Adopterもゲットできました。
時間いっぱい使って見直ししたので約3時間半ぶっ通しでなかなかつらかったです。
さすがにProfessionalだけあってそれなりに難易度は高く、スコアは結構ギリギリでした。

なんとか今年も全冠維持できました ![]()
ベータ期間中は1度しか受験できないらしいので落ちたら年度内再受験不可でMLSの再取得になることも覚悟していましたが、ギリギリ回避できて安心しました ![]()
期限を見るとわかるのですが、下位資格にあたる4つの資格が合わせて更新されています ![]()
Specialtyが減って下位資格がセットで更新されるものが多くなってきたので維持は少し楽になりましたね ![]()
勉強ノート
試験のために勉強しながらまとめたノート
※ここに書いてあることは、あくまで私が理解が足りないと感じ、覚えたかったことだけです。試験範囲を網羅はしていません。
※以下の内容はAIにより生成されたコンテンツを含みます。
ML復習
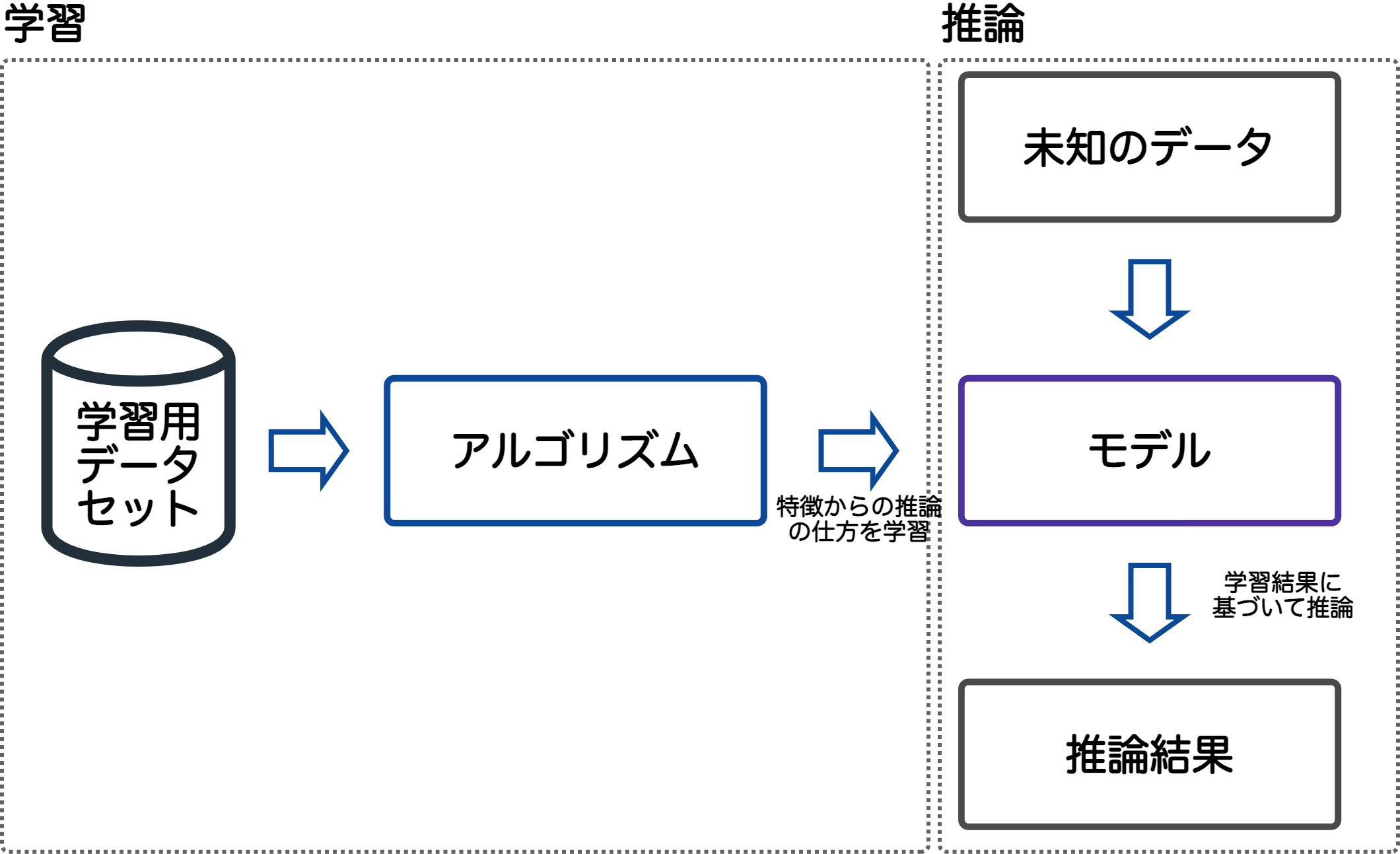
AIはMLの技術により成り立っているため、AIについて学ぶためにまずはMLの理解が必要
過去の学習をふりかえり思い出しておく
↓この「推論」部分の「モデル」にLLMを利用し、ユーザープロンプトを「未知のデータ」とし、推論結果の文章出力を気軽に使えるようなチャットUIを付けて提供したものがいわゆる生成AIツールとなる
用語
AI関連の基本的用語を頭に入れておく
| カテゴリ | 用語 | 説明 |
|---|---|---|
| 基盤モデル | LLM (Large Language Model) | 大規模なテキストデータで学習された言語モデル |
| トークン | テキストを分割した最小単位(単語や文字の一部) | |
| パラメータ | モデルが学習する重み。数が多いほど高性能だが計算コストも増加 | |
| コンテキストウィンドウ | モデルが一度に処理できる入力テキストの最大長 | |
| 学習・調整 | 事前学習 | 大規模データセットでモデルの基礎能力を学習 |
| ファインチューニング | 特定タスクやドメインに合わせてモデルを再学習 | |
| プロンプトエンジニアリング | 適切な指示文を設計してモデルの出力を最適化 | |
| Few-shot学習 | 少数の例を示してタスクを学習させる手法 | |
| Zero-shot学習 | 例を示さずに指示のみでタスクを実行 | |
| 生成技術 | Temperature | 出力のランダム性を制御(高いほど創造的、低いほど確定的) |
| Top-p (Nucleus Sampling) | 累積確率がp以下のトークンから選択する手法 | |
| Top-k | 確率上位k個のトークンから選択 | |
| ビームサーチ | 複数の候補を並行探索して最適な出力を生成 | |
| アーキテクチャ | Transformer | 注意機構を用いた現代的なニューラルネットワーク構造 |
| Attention機構 | 入力の重要な部分に注目して処理する仕組み | |
| エンコーダー・デコーダー | 入力を理解する部分と出力を生成する部分 | |
| 埋め込み (Embedding) | テキストや画像を数値ベクトルに変換 | |
| 応用パターン | RAG (Retrieval-Augmented Generation) | 外部知識を検索して回答に組み込む手法 |
| エージェント | 自律的にツールを使用してタスクを実行するAI | |
| チェーン | 複数のプロンプトやモデル呼び出しを連結 | |
| マルチモーダル | テキスト、画像、音声など複数の形式を扱う | |
| 評価・品質 | ハルシネーション | モデルが事実でない情報を生成する現象 |
| グラウンディング | 外部情報源に基づいて回答の正確性を確保 | |
| バイアス | 学習データに含まれる偏りがモデルに反映される問題 | |
| 推論 (Inference) | 学習済みモデルを使って予測や生成を実行 | |
| 最適化 | 量子化 | モデルの精度を下げてサイズと速度を改善 |
| 蒸留 | 大きなモデルの知識を小さなモデルに転移 | |
| プルーニング | 不要なパラメータを削除してモデルを軽量化 | |
| LoRA | 少数のパラメータのみを学習する効率的なファインチューニング |
生成AIのアーキテクチャ
なんとなく理解したつもりだとAIの安全性や情報の正当性について問われても答えられない
生成AIがどういったアーキテクチャで実現されているのかを理解しておく
生成AIツール例:Amazon Q Developerのアーキテクチャ
Amazon Q DeveloperはRAGアーキテクチャを採用しており、ローカルのワークスペースの情報をベクトルDBに保存し、そこから検索した情報を回答に利用している。
Amazon Q Developer自信にそのシーケンスとデータフローを図示してもらった。
RAG関連技術
2つの検索
RAGでは主にセマンティック(意味)検索とキーワードマッチング検索の2つの検索方法がある
2つを組み合わせた検索をハイブリッド検索という
チャンキング
FMではコンテキストウィンドウ(入力と出力の合計トークン数)が限られており、大きなドキュメントは全体を一度に処理できないため
事前に意味のあるセグメント(=チャンク)に分割する
一定の長さの反復になるようなデータ出ない限り、固定長での分割は大きなドキュメントの意味を読み取れなくしてしまう可能性があるため、意味を持った塊で区切る(セマンティックチャンキング)
このサイズを調整することで回答生成の品質が向上する
明確な構造階層(章、節、小節)を持つ文書に対しては階層的チャンキングという手法もある
メタデータ
ドキュメントに説明の付加情報「メタデータ」を付与することでメタデータからフィルタリングできるようにする
リランク
RAGの検索結果を関連性が高い順に並べることで回答品質を高める
RAGでのクエリ結果に対して、リランカーモデルでさらにチャンクとクエリの関連性を計算し、結果を並べかえる
RAGフュージョン
入力を複数の文章に変換し、複数のクエリ結果を集約することで回答を生成する
Rewrite-Retrieve-Read
入力を検索向けに変換してからクエリする
HyDE(Hypothetical Document Embeddings)
仮の回答をLLMに出力させてから、それを用いて検索する
pgvector
PostgreSQLのDBにベクターデータを保存することでSQLによるベクトル検索を可能にするPostgreSQLの機能
Amazon Auroraではpgvector拡張機能を有効にすることでこの機能を利用できる
Small-to-Big検索
高度なRAG(検索拡張生成)システムで用いられる手法で、「検索」と「生成」に最適なチャンクサイズ(情報単位)が異なるという課題を解決するためのアプローチ
「検索には小さな単位」「回答生成には大きな(文脈を含む)単位」を用いることで、検索精度と回答の質の良いとこ取りを目指す
主に以下の2つの手法がある
- 親子チャンク(Parent-Child Indexing): Small-to-Bigの代表的な実装手法。子チャンクで検索し、親チャンクを取得する。
- Hierarchical Indexing(階層的インデックス): 情報を多階層で持ち、小さな単位から大きな単位へ展開する。
RAG評価指標
| 指標 | 説明 |
|---|---|
| 正確性(Correctness) | 期待される回答と一致しているか(正解率) |
| 完全性(Completeness) | 必要な情報をもれなく伝えているか |
| 有用性(Helpfulness) | ユーザーの目的を効果的に達成できているか |
| 論理的一貫性(Logical coherence) | 論理的な欠落、矛盾がないか |
| 忠実性(Faithfulness) | 事実に即している(ハルシネーションがない)か |
| 引用精度(Citation precision) | 引用された文章のうち正しく引用されている数 |
| 引用範囲(Citation coverage) | 回答が引用された文章によってどの程度裏付けられているか |
| 有害性(Harmfulness) | 憎悪的、侮辱的、暴力的であるか ※低いほうが有害でない |
| ステレオタイプ化(Stereotyping) | 回答に社会的バイアスがかかっているか ※低いほうがバイアスが少ない |
| 拒否(Refusal) | 質問に対して回避的な回答をしているか ※低いほうが回避的でない |
その他の評価指標
| 指標 | 説明 |
|---|---|
| 堅牢性(Robustness) | 攻撃的なプロンプトや予期しない入力など厳しい条件下でも壊れない(誤判断しない)か |
AIエージェント
単純な質問への回答だけでなく、外部サービス連携やファイルの編集、コマンド実行などの操作を代わりに行う
ReActパターン
「Reasoning(推論/思考)」、「Acting(行動)」、「Observation(観察)」の3つのステップを繰り返し行う
これによりエージェントの自律的な問題解決の性能を向上させる
Chain of Thought (CoT)パターン
複雑な問題を複数の個別の思考ステップに分解し、順番に処理する
複雑な推論タスクにおいて、早い段階で解決策に飛びついてしまい論理エラーやハルシネーションが発生する場合にCoTパターンを取り入れることで解決できることがある
カスタムモデル
ファインチューニング
ラベルありデータセットにより特定タスクの精度を高める
継続的な事前トレーニング
ラベルなしデータセットにより特定領域の知識を追加する
ファインチューニングよりも多くのデータセットを必要とする
セーフガード
ウォーターマーク検出
AI生成された画像を識別する
ガードレール
- コンテンツフィルター:有害コンテンツをフィルタリングする
- 拒否されたトピック:望ましくないトピックを事前に指定し入出力させない
- 単語フィルター:入出力をブロックする単語セットを指定する
- 機密情報フィルター:個人情報種別や正規表現を指定しブロック及びマスクする
HITL(Human-in-the-loop)
AIや自動化システムの判断・動作プロセスに人間が介入し、フィードバック、監視、修正を行う協働的な設計思想
AWSではSageMaker AIやBedrockでワークフォースと呼ばれるグループを作成し、Amazon Mechanical Turkや社内の評価チームによる人間のモデル評価などを行うことができる
RLHF(Reinforcement Learning with Human Feedback)
モデルの出力をより人間に好まれるものにするために、人間の評価がより高くなるような回答に高い報酬を設定した強化学習を行うこと、RLHFはHITLの手法の1つ
Bedrockの機能
Amazon Bedrock Prompt Management
プロンプトアセットを一元管理するためのサービス、パラメータ化されたテンプレートをバージョン管理できる
インテリジェントプロンプトルーティング
ルーティング用のモデルで入力プロンプトの複雑さを評価し、FMファミリー(Haiku, Sonnetなど)の中で最もコスト効率の高いモデルにルーティングする
プロンプトキャッシュ
頻繁に利用されるプロンプトプレフィックス(システム指示、企業ポリシー、大規模なコンテキストドキュメントなど)をキャッシュして再利用することができる機能
キャッシュから利用されたプロンプトは課金対象のトークン数にカウントされないため、コストを削減することができる
Amazon Bedrock knowredgebase
マネージドでRAG用のナレッジベースを構築できる
ConfluenceやSharePoint、Salesforce、Webクローラーなどのデータソースコネクタを利用することで少ない労力で外部のデータソースとの連携も可能
S3などのAWSサービスもデータソースに設定できる
S3の更新を自動的に動悸する機能はないため、リアルタイムで同期するためにはS3の変更を検知し「StartIngestionJob API」を呼び出すような仕組みが必要
Amazon Bedrock Guardrails
ガードレールを設定すると条件を満たした際に回答を拒否するメッセージを返したり、機密情報をマスクすることができる
Bedrockガードレールは、介入アクションを「NONE」に設定することで検出のみでブロックはせずに、検知だけ行うモードも選択できる
ハルシネーションのチェックを行い、事実に即さない回答をブロックすることもできる
Amazon Bedrock Data Automation
ドキュメント解析(OCR)、基盤モデルを用いたインテリジェントなデータ抽出、そして構造化出力生成を組み合わせたフルマネージドサービス
Amazon Bedrock Prompt Flows(Bedrock Flows)
GUIのフロービルダーインターフェイスを利用してプロンプトシーケンスを構築・テスト・デプロイできる
これによりノーコードで生成AIワークフローを構築できる
Amazon Bedrock Converse API
FMの種類に依存しない共通リクエストができるAPI
Agent Squad
Amazon Bedrockエージェントにはマルチエージェントコラボレーション(またはAgent Squad)をサポートしている
スーパーバイザーエージェントが複数のコラボレーターエージェントに対し入力プロンプトに応じたルーティングを行う、スーパーバイザーは会話の履歴を保持し、関連する情報をコラボレーターへ渡す
Amazon Bedrock Data Automation
非構造化マルチモーダルコンテンツ (ドキュメントや画像など) からインサイトや構造化データを自動的に生成するために特別に設計されたフルマネージド機能
トレーニングデータの前処理やナレッジベースの前処理として利用できる
クロスリージョン推論
モデルを複数リージョンで有効化し、リクエストを動的にルーティングする
これにより、トラフィックのスパイク発生時にリージョン単位のクォータによるスロットリングやパフォーマンス低下を回避することができる
Bedrock Agentのトレース
エージェント呼び出しの際のパラメータとしてenableTraceにtrueを指定することでレスポンスにトレースが返される、どういった思考の結果その回答を返したのか説明可能にするために利用できる
またGuardrailsにもトレースの機能があり、guardrailConfigパラメータで{"trace":"enabled"}を設定することで有効にできる
Bedrockの通常のログでは特定できない「どのポリシーでブロックされたか」などを追跡できる
モデル呼び出しのログ
Amazon Bedrockのモデル呼び出しの履歴はCloudWatch LogsまたはS3へログ出力させる設定ができる
アクショングループ
エージェントがアクションを実行するために呼び出すツールとAPIを定義する
レスポンスストリーム
Bedrockのモデル呼び出しはストリーミング方式でレスポンスを返すこともできる
API GatewayのWebソケットAPIと組み合わせることで生成途中のレスポンスチャンクを順次返し、画面表示するなどの使い方ができる
呼び出しには「InvokeModelWithResponseStream API」を利用する
Amazon Bedrock Model Evaluation
Amazon Bedrockでは出力結果に対する評価メトリクスを表示することができる
AI
LLM-as-a-Judge
モデルの出力結果の精度を高性能なLLMに評価させる手法
ゴールデンデータセット
厳選された質問と正しい回答のデータセット、これを用いてモデルの出力の品質を検証する
セマンティックキャッシング
正確な文字列一致ではなく、意味(セマンティック)的な類似性のある質問に対してもキャッシュされた応答を返す
モデルカスケーディング
単純なタスクと複雑なタスクを区別し、高コストなモデルは複雑なタスクにのみ割り当てることでLLMの利用コストを下げる手法、単純なルーティングではなく小さなモデルから順に適用する手法を「カスケーディング」という
コンテキストプルーニング
モデルへのプロンプト入力の前処理として不要な情報を削除するなどして、入力トークン数を減らす手法
これにより、LLM利用コストの削減や回答品質の向上につながる
K-NN検索
k-NN検索(k-Nearest Neighbor Search、k近傍探索)は、クエリベクトルに最も近いk個のデータポイントを見つける検索手法
ベクトル空間内で距離や類似度を計算し、最も類似した上位k件を返す
セマンティック検索やRAGシステムで広く使用され、HNSWやIVFなどのインデックス手法で高速化される
Amazon OpenSearch ServiceやAmazon Kendraなどで実装されている
RAGなどで効率よく類似検索をする場合はk-NN検索
近似最近傍 (ANN) アルゴリズム
近似最近傍(ANN)アルゴリズム(Approximate Nearest Neighbor)は、厳密なk-NN検索の精度を若干犠牲にして検索速度を大幅に向上させる手法。
HNSW(階層的ナビゲート可能スモールワールド)やIVF(逆ファイルインデックス)などのアルゴリズムで、数百万〜数十億規模のベクトルデータからミリ秒単位で近傍を検索できる。
大規模なセマンティック検索やRAGシステムでスピードと精度のトレードオフを最適化し、大規模ベクトル検索するのに利用する
BM25
BM25(Best Matching 25)は検索エンジンで文書の関連度をスコアリング(順位付け)するためのアルゴリズム
これを利用しキーワードベースの検索を行うことで意味的類似性によるベクトル検索だと正確性にかけるような場合に回答精度を上げることができる
Hugging Face
AI開発者が機械学習モデルやデータセットを保存、共有したり、AIアプリを公開できるAIコミュニティ向けのプラットフォーム
LoRA
低ランク適応(LoRA)(Low-Rank Adaptation)は、大規模言語モデルを効率的にファインチューニングする手法。元のモデルの重みを固定し、小さな低ランク行列のみを学習(通常0.1%〜1%のパラメータ)することで、メモリ使用量を大幅削減しながら特定タスクへの適応を実現する。
Amazon Bedrockのカスタムモデル機能で利用可能。
AWS
AWS Glue Data Quality
品質ルール(必須フィールドや日付フォーマットなど)を定義し、これらのルールに照らしてデータを自動的に評価できる
入力プロンプトの一貫した検証などに利用できる
データ品質定義言語(DQDL)を利用してルールセットを定義する
Amazon SageMaker Data Wrangler
ローコードUIでデータをインポートし、品質レポート(ヒストグラム、外れ値検出、欠損値統計)を自動生成することで、データサイエンティストが「FM 利用における品質基準」を視覚的に検証できるようにする
Amazon Comprehend
テキストに対する意味抽出やPIIフィルタリングなどを行える
入力プロンプトに対する前処理などで活用できる
Amazon Comprehend Custom Entity Recognizer
一般的な言語モデルに含まれないドメイン固有の用語を識別するツール
特定のエンティティを抽出し、構造化メタデータとして保存することで「ハイブリッド検索」または「メタデータフィルター」によりドメイン固有の用語の一致による検索精度を上げられる
StepFunctionsによる人間の承認ワークフロー
ステートにwaitForTaskTokenを設定することでタスクが成功になることを待つ状態に移行する
API Gateway + Lambdaによりステートを更新するWeb APIを実装し、承認または否認操作が行われた際にこのAPIを呼び出すことで状態を更新する
AWS Lake Formation
S3などのストレージやDBをデータレイクとして管理できる
データの列単位でのアクセス制御はIAMだけではできないので、Lake Formationを利用する
Amazon SageMaker Clarify
バイアス検出とモデルの説明可能性のためのツール
モデルに対しバイアスメトリクスを計算し、S3へレポートを出力する
SageMaker AIのモデルだけでなくBedrockにも利用できる
Amazon SageMaker Model Cards
モデル情報(使用目的、リスク、系統、メトリクス)を文書化するために特別に設計された AWS ネイティブガバナンスツール
SageMakerのモデルだけでなく外部やBedrockのモデルもサポートしている
Amazon SageMaker ML Lineage Tracking
機械学習ワークフローの各ステップに関する情報を作成および保存する機能
S3データ、モデル、エンドポイントなどのエンティティをアソシエーション(「Produced」や「ContributedTo」などの関係性)を介してリンクするグラフ構造を作成する
Amazon MemoryDB for Redis
ミリ秒未満のレイテンシでデータ取得が可能なインメモリDB
Amazon S3ベクターバケット
ベクターデータ用のフルマネージドのストレージ、S3の機能の一部として提供されており料金体系もS3に近い完全従量課金のため、オフピークのコストを最大限削減できる
Amazon Q Developerカスタマイズ
管理者は企業固有のコーディング標準、アーキテクチャパターン、セキュリティガイドラインを定める組織レベルのカスタマイズを作成できる
これによって開発者は社内のコーディング規約に沿ったコードを生成させることができる
その他メモ
AWS WAF + API Gateway
AWS WAF + API Gatewayの場合はリージョン単位での保護しかできない
前段にCloudFrontを置くことでAPI Gatewayのあるリージョン以外からのリクエストに対しても対策できる
Noisy Neighbor
ノイジーネイバー(Noisy Neighbor)は、ITの仮想化・クラウド環境において、1つの共有リソース(ストレージ、CPU、ネットワーク)を複数のユーザーやアプリケーション(隣人)で共有する際、特定の「隣人」が過剰にリソースを消費し、他者のパフォーマンスを低下させる現象。解決策には、QoS(品質保証)の設定、リソースの制限、モニタリング強化などがある。
機械学習関連用語
ここから下はAmazon Q Developerによる用語に対する概要説明
埋め込みモデル
埋め込みモデル(Embedding Model)は、テキスト、画像、音声などのデータを数値ベクトルに変換する機械学習モデルです。似た意味を持つデータはベクトル空間上で近い位置に配置され、セマンティック検索、RAG、レコメンデーション、類似度計算などに活用されます。代表例はAmazon Titan EmbeddingsやBERTです。
埋め込みモデルは、人間が理解できる情報を機械が処理・比較できる形式に変換する橋渡し役として機能します。
低ランク適応(LoRA)
低ランク適応(LoRA)(Low-Rank Adaptation)は、大規模言語モデルを効率的にファインチューニングする手法です。元のモデルの重みを固定し、小さな低ランク行列のみを学習(通常0.1%〜1%のパラメータ)することで、メモリ使用量を大幅削減しながら特定タスクへの適応を実現します。Amazon Bedrockのカスタムモデル機能で利用可能です。
LoRAは、大規模モデルを低コストで自分のユースケースに適応させる実用的な手法として広く採用されています。
堅牢性スコア
堅牢性スコア(Robustness Score)は、機械学習モデルやシステムが予期しない入力や異常な状況に対してどれだけ安定して動作するかを測定する指標です。
低いほどモデルの安定性が高い、高いと入力値の変化に敏感になります。
堅牢性スコアが高いモデルは、実世界の多様で予測不可能な状況下でも安定したパフォーマンスを発揮します。
マルチモデルアンサンブル戦略
マルチモデルアンサンブル戦略(Multi-Model Ensemble Strategy)は、複数の異なるモデルの予測結果を組み合わせて最終的な出力を生成する手法です。投票、平均化、重み付けなどで各モデルの強みを活かし、単一モデルより高い精度と堅牢性を実現します。Amazon Bedrockでは複数の基盤モデルを組み合わせて使用することで、タスクごとに最適な結果を得られます。
クエリ拡張
クエリ拡張(Query Expansion)は、ユーザーの検索クエリに関連する同義語や類似表現を追加して検索範囲を広げる技術です。元のクエリだけでは見逃される可能性のある関連文書を取得し、検索の再現率を向上させます。RAGシステムでは、LLMを使ってクエリを複数のバリエーションに展開することで、より包括的な情報検索を実現します。
クエリ拡張は、限定的な検索語を豊かにして検索結果の網羅性を高める手法です。
カスタム階層チャンク
カスタム階層チャンク(Custom Hierarchical Chunking)は、文書を意味的な階層構造に基づいて分割する手法です。章、セクション、段落などの文書構造を保持しながらチャンク化することで、コンテキストの一貫性を維持します。RAGシステムでは、親チャンクで検索して子チャンクの詳細を取得するなど、検索精度と文脈理解を向上させます。
カスタム階層チャンクは、文書の自然な構造を活かして意味的なまとまりを保つ分割手法です。
k-NN 検索
k-NN検索(k-Nearest Neighbor Search、k近傍探索)は、クエリベクトルに最も近いk個のデータポイントを見つける検索手法です。ベクトル空間内で距離や類似度を計算し、最も類似した上位k件を返します。セマンティック検索やRAGシステムで広く使用され、HNSWやIVFなどのインデックス手法で高速化されます。Amazon OpenSearch ServiceやAmazon Kendraなどで実装されています。
k-NN検索は、ベクトル類似度に基づいて最も関連性の高いデータを効率的に取得する基本的な検索アルゴリズムです。
近似最近傍 (ANN) アルゴリズム
近似最近傍(ANN)アルゴリズム(Approximate Nearest Neighbor)は、厳密なk-NN検索の精度を若干犠牲にして検索速度を大幅に向上させる手法です。HNSW(階層的ナビゲート可能スモールワールド)やIVF(逆ファイルインデックス)などのアルゴリズムで、数百万〜数十億規模のベクトルデータからミリ秒単位で近傍を検索できます。大規模なセマンティック検索やRAGシステムで不可欠な技術です。
ANNアルゴリズムは、スピードと精度のトレードオフを最適化し、大規模ベクトル検索を実用的にする技術です。
思考連鎖(CoT)推論
思考連鎖(CoT)推論(Chain-of-Thought Reasoning)は、LLMに問題解決の過程を段階的に説明させるプロンプト技法です。「ステップバイステップで考えましょう」などの指示で、モデルが中間的な推論ステップを明示的に出力し、複雑な論理問題や数学的計算の精度を大幅に向上させます。推論過程が可視化されるため、解釈可能性とデバッグ性も向上します。
思考連鎖推論は、LLMに思考プロセスを言語化させることで複雑な問題解決能力を引き出す技法です。
ReAct(推論と行動)パターン
ReAct(推論と行動)パターン(Reasoning and Acting)は、LLMが推論(Reasoning)と行動(Acting)を交互に実行するフレームワークです。モデルが思考を言語化し、必要に応じて外部ツールやAPIを呼び出して情報を取得し、その結果を基に次の推論を行います。Amazon Bedrock Agentsで実装され、動的な問題解決と自律的なタスク実行を可能にします。
ReActパターンは、思考と行動を組み合わせてLLMに自律的な問題解決能力を与えるエージェント設計手法です。
モデル量子化
モデル量子化(Model Quantization)は、モデルのパラメータ精度を低減してサイズとメモリ使用量を削減する最適化手法です。32ビット浮動小数点から8ビット整数や4ビット整数に変換することで、モデルサイズを最大75%削減し、推論速度を向上させます。精度の若干の低下と引き換えに、エッジデバイスでの実行やコスト削減を実現します。Amazon SageMakerやBedrockで量子化モデルをデプロイできます。
モデル量子化は、精度を保ちながらモデルを軽量化して高速・低コストな推論を可能にする圧縮技術です。
DeepSpeed
DeepSpeedは、Microsoftが開発した大規模深層学習モデルの分散トレーニングを最適化するオープンソースライブラリです。**ZeRO(Zero Redundancy Optimizer)**技術により、メモリ効率を劇的に向上させ、数千億パラメータのモデルを限られたGPUリソースで学習可能にします。3D並列化(データ、モデル、パイプライン並列)、勾配圧縮、混合精度学習をサポートし、Amazon SageMakerやEC2 UltraClusterで利用できます。
DeepSpeedは、メモリ効率と学習速度を最大化して超大規模モデルの分散トレーニングを実現する最適化フレームワークです。
バイアスドリフト監視
バイアスドリフト監視(Bias Drift Monitoring)は、本番環境でMLモデルの公平性が時間経過とともに変化することを検出する監視手法です。人口統計学的パリティ、機会均等性、予測的パリティなどの公平性メトリクスを継続的に測定し、トレーニング時のベースラインと比較します。特定の保護属性(性別、人種、年齢など)に対する予測の偏りが増加した場合にアラートを発行します。SageMaker Clarifyと統合し、責任あるAI運用と規制遵守を実現します。
バイアスドリフト監視は、本番モデルの公平性を継続的に追跡して差別的な予測の発生を早期に検出する倫理的AI監視機能です。
トークンレベル編集
トークンレベル編集(Token-level Redaction)は、テキストから機密情報を個別のトークン単位で検出・削除または置換する技術です。PII(個人情報)、クレジットカード番号、社会保障番号、医療情報などを、文字列全体ではなくトークン(単語や部分文字列)レベルで精密に特定します。Amazon Comprehend、Textract、Bedrock Guardrailsで実装され、[REDACTED]やプレースホルダーで置換または完全削除します。文脈を保持しながらプライバシー保護とコンプライアンスを実現します。
トークンレベル編集は、テキストの意味構造を保ちながら機密情報を細粒度で除去するプライバシー保護技術です。
AI関連用語
スーパーバイザーエージェントパターン
スーパーバイザーエージェントパターン(Supervisor-Agent Pattern)は、1つの統括エージェントが複数の専門エージェントを管理するマルチエージェント協調の設計パターンです。スーパーバイザーがユーザーリクエストを解釈し、適切なコラボレーターエージェントにタスクを振り分け、結果を統合して応答します。Amazon Bedrock Agentsのマルチエージェント協調で実装され、階層的な役割分担と集中管理により複雑なタスクを効率的に処理します。
スーパーバイザーエージェントパターンは、指揮官と専門家チームの関係を模倣した階層型マルチエージェントアーキテクチャです。
OWASP Top 10 for LLM セキュリティ
OWASP Top 10 for LLM セキュリティは、大規模言語モデル(LLM)アプリケーションの主要なセキュリティリスクをまとめた標準ガイドラインです。主なリスクには、プロンプトインジェクション(悪意ある指示の注入)、データ漏洩(学習データや機密情報の露出)、サプライチェーン脆弱性(サードパーティモデル・データの問題)、過度な権限付与(エージェントの権限過剰)、不適切な出力処理(有害コンテンツの生成)などが含まれます。Amazon Bedrock Guardrailsなどで入力検証、出力フィルタリング、アクセス制御を実装し、LLMアプリケーションの安全性を確保します。
OWASP Top 10 for LLMは、生成AIアプリケーション特有のセキュリティ脅威を体系化した業界標準のリスク管理フレームワークです。
コンテキストプルーニング
コンテキストプルーニング(Context Pruning)は、LLMへの入力から不要な情報を削除してトークン数を削減する最適化技術です。関連性スコアリングにより、クエリに対して重要度の低い文章や段落を自動除去し、コンテキストウィンドウを効率的に活用します。RAGシステムで特に有効で、検索結果の冗長部分を削除しながら回答品質を維持します。推論コスト削減、レイテンシ短縮、トークン制限対応を実現し、Amazon BedrockのPrompt Optimization機能で実装できます。
コンテキストプルーニングは、LLM入力の冗長性を削減して効率とコストを最適化しながら応答品質を保つトークン最適化技術です。
推論パストレーシング
推論パストレーシング(Inference Path Tracing)は、AIエージェントやLLMの推論プロセスを段階的に記録・可視化する技術です。思考ステップ、ツール呼び出し、中間結果、意思決定ポイントを時系列で追跡し、エージェントがどのように目標に到達したかを透明化します。ReActパターンの各サイクル、API呼び出し、エラーハンドリングを記録し、デバッグ、パフォーマンス最適化、説明可能性を向上させます。Amazon Bedrock Agentsで実装され、トレースログとして出力されます。
推論パストレーシングは、AIエージェントの思考と行動の全プロセスを可視化してデバッグと透明性を実現する追跡技術です。
スキーマ検証
スキーマ検証(Schema Validation)は、データ構造が事前定義されたルールや形式に準拠しているかを自動チェックする技術です。JSON Schema、XML Schema、Avro Schemaなどを使用して、データ型、必須フィールド、値の範囲、フォーマットを検証します。Amazon Bedrock Agentsではツール入出力の構造を定義し、API Gatewayではリクエスト/レスポンスの妥当性を検証します。データ品質保証、エラー早期検出、API契約の強制を実現し、不正データの処理を防止してシステムの信頼性を向上させます。
スキーマ検証は、データ構造の整合性を自動的に確認してシステムの堅牢性とデータ品質を保証する検証技術です。
埋め込みドリフト
埋め込みドリフト(Embedding Drift)は、ベクトル埋め込みの分布が時間経過とともに変化する現象です。モデル更新、データソース変更、言語の進化により、同じテキストでも異なるベクトル表現が生成される可能性があります。RAGシステムで特に問題となり、検索精度の低下、セマンティック検索の不整合を引き起こします。ベースライン埋め込みとの距離測定、コサイン類似度の変化監視で検出し、ベクトルデータベースの再インデックス化で対処します。Amazon Bedrockの埋め込みモデル更新時に注意が必要です。
埋め込みドリフトは、ベクトル表現の一貫性が失われることでRAGシステムの検索品質が劣化する現象です。
Stop Sequence
Stop Sequence(停止シーケンス)は、LLMのテキスト生成を特定の文字列で強制終了させるパラメータです。カスタムトークンや区切り文字(例: \n\n、###、END)を指定することで、不要な続きの生成を防止します。構造化出力の制御、トークン消費の削減、応答フォーマットの統一に有効で、プロンプトエンジニアリングで頻繁に使用されます。Amazon BedrockのInvokeModel APIでstopSequencesパラメータとして設定でき、複数の停止条件を配列で指定可能です。
Stop Sequenceは、LLM生成を指定文字列で打ち切ることで出力を精密に制御するテキスト生成制御パラメータです。
ゴールデンデータセット
ゴールデンデータセット(Golden Dataset)は、高品質で正解ラベル付きの評価用基準データセットです。人間の専門家が検証・承認した入力と期待される出力のペアで構成され、モデル評価、ベンチマーク、回帰テストの基準として使用されます。LLMやRAGシステムではプロンプト-応答ペア、質問-正解ペアを含み、精度測定、A/Bテスト、ファインチューニング検証に不可欠です。Amazon Bedrock Model Evaluationでカスタムゴールデンデータセットをアップロードして評価を実行できます。
ゴールデンデータセットは、AIモデルの性能を客観的に測定するための信頼性の高い評価基準データセットです。
システム関連用語
グレースフルデグラデーション
グレースフルデグラデーション(Graceful Degradation)は、システムの一部に障害が発生しても完全停止せず、機能を段階的に縮退させながら基本サービスを継続する設計手法です。例えば、推奨機能が使えない時はキャッシュデータで応答、高度な機能が障害時は基本機能のみで動作を継続します。可用性と信頼性の向上に貢献します。
サーキットブレーカーパターン
サーキットブレーカーパターン(Circuit Breaker Pattern)は、外部サービスへの呼び出しが繰り返し失敗する際に一定期間呼び出しを遮断し即座にエラーを返す設計パターンです。Closed(正常)、Open(遮断中)、Half-Open(回復テスト中)の3状態を持ち、障害の連鎖を防止してシステム全体のレジリエンスを向上させます。
アダプターパターン
アダプターパターン(Adapter Pattern)は、互換性のないインターフェース間を橋渡しするデザインパターンです。既存のクラスやシステムを変更せずに、異なるインターフェースを持つコンポーネント同士を連携させます。例えば、レガシーシステムと新システムの統合や、サードパーティAPIのラッパー実装などに使用され、再利用性と保守性を向上させます。
データレジデンシーコンプライアンス
データレジデンシーコンプライアンス(Data Residency Compliance)は、データを特定の地理的領域内に保管・処理することを義務付ける法規制や組織ポリシーへの準拠です。GDPR、HIPAA、PCI DSSなどの規制に対応し、データ主権(Data Sovereignty)を確保します。AWSでは、リージョン選択、AWS Outposts、ハイブリッドアーキテクチャにより実現し、予防的・検出的コントロールでデータの物理的位置を管理します。Well-Architected FrameworkのData Residency Lensがベストプラクティスを提供します。
データレジデンシーコンプライアンスは、法規制やデータ主権要件に基づいてデータの保管場所を制御・証明する規制遵守の枠組みです。
コンテンツモデレーション
コンテンツモデレーション(Content Moderation)は、不適切、有害、攻撃的なコンテンツを自動検出・フィルタリングする技術です。Amazon Rekognitionで画像・動画を分析し、機械学習で全体の95-99%を自動処理、人間レビューは1-5%に削減します。カスタムモデレーションで独自基準に適応でき、Amazon Augmented AIと統合してヒューマン・イン・ザ・ループを実現します。ソーシャルメディア、広告、Eコマースでユーザー体験向上、ブランド保護、規制遵守を支援します。
コンテンツモデレーションは、AIと人間の協働により大規模かつ高精度に有害コンテンツを検出・除去する安全性確保の仕組みです。
AWSのAI関連用語
Amazon Augmented AI
Amazon Augmented AI(Amazon A2I)は、機械学習の予測に人間によるレビューを組み込むマネージドサービスです。信頼度が低い予測や重要な判断を人間の作業者に送り、レビュー結果をワークフローに統合します。Amazon Rekognition、Textract、SageMakerと連携し、カスタムMLワークフローにも対応します。コンテンツモデレーション、文書処理、品質保証などで、AIと人間の判断を組み合わせた高精度システムを構築できます。
Amazon Augmented AIは、機械学習に人間の監視と判断を統合してAIシステムの精度と信頼性を向上させるヒューマン・イン・ザ・ループサービスです。
Amazon Titan Embeddings
Amazon Titan Embeddingsは、AWSが提供するマネージド型の埋め込みモデルです。Amazon Bedrockを通じて利用でき、テキストを最大8,192トークンまで処理して高次元ベクトルに変換します。25以上の言語をサポートし、セマンティック検索やRAGアプリケーションに最適化されています。従量課金制で、インフラ管理不要で簡単に統合できます。
Amazon Titan Embeddingsは、AWSネイティブで多言語対応の高性能埋め込みモデルサービスです。
Amazon Bedrock reranker
Amazon Bedrock Rerankerは、検索結果をクエリとの関連性に基づいて再順位付けするマネージドサービスです。初期検索で取得した候補文書を、より高精度なモデルで意味的関連性を再評価し、最も関連性の高い結果を上位に配置します。RAGシステムで検索精度を大幅に向上させ、LLMへの入力品質を改善します。
Amazon Bedrock Rerankerは、検索結果の質を高めるための二段階検索の要となるサービスです。
Amazon Bedrock Guardrails
Amazon Bedrock Guardrailsは、生成AIアプリケーションに安全性とコンプライアンスのポリシーを適用するマネージドサービスです。有害コンテンツのフィルタリング、PII(個人情報)の検出・マスキング、トピック制限、禁止ワードの設定などを実装でき、入力と出力の両方を保護します。複数のモデルで再利用可能なガードレールを作成し、責任あるAI利用を実現します。
Amazon Bedrock Guardrailsは、生成AIの安全性とコンプライアンスを確保するための包括的な保護レイヤーです。
Amazon Bedrock Prompt Management
Amazon Bedrock Prompt Managementは、プロンプトの作成、保存、バージョン管理、共有を一元管理するサービスです。プロンプトテンプレートを作成して変数やプレースホルダーで動的に変更でき、複数バージョンを管理してA/Bテストや改善を追跡できます。チーム間でプロンプトを共有し、ベストプラクティスの標準化と再利用性を向上させます。
Amazon Bedrock Prompt Managementは、プロンプトエンジニアリングのライフサイクル全体を効率化する管理プラットフォームです。
Amazon Bedrock Prompt Flows
Amazon Bedrock Prompt Flowsは、複数のプロンプトとモデル呼び出しを視覚的にオーケストレーションするワークフロー構築サービスです。ドラッグ&ドロップで条件分岐、ループ、並列処理を含む複雑なAIワークフローを作成でき、Knowledge Bases、Lambda関数、外部APIとの統合も可能です。コード不要でマルチステップのAIアプリケーションを構築できます。
Amazon Bedrock Prompt Flowsは、複雑な生成AIワークフローをノーコードで設計・実行するビジュアルオーケストレーションツールです。
Step Functionsでもオーケストレーションは可能、Bedrock以外との統合や複雑なロジック・ビジネス要件がある場合はStep Functionsを選択する。
Amazon Bedrock Agents
Amazon Bedrock Agentsは、自律的にタスクを実行するAIエージェントを構築するマネージドサービスです。ReActパターンを実装し、LLMが目標を理解→計画立案→ツール呼び出し→結果評価のサイクルを自動実行します。Knowledge Bases、Lambda関数、外部APIと統合でき、複数ステップのタスクを自律的に完遂します。予約システム、データ分析、カスタマーサポートなどに活用されます。
Amazon Bedrock Agentsは、LLMに自律的な意思決定とアクション実行能力を与える統合エージェントプラットフォームです。
Amazon Bedrock Model Evaluation
Amazon Bedrock Model Evaluationは、基盤モデルの性能を自動的かつ体系的に評価するマネージドサービスです。自動評価(ROUGE、BERTScore、正確性メトリクス)と人間評価(カスタムワークフロー)の両方をサポートします。LLM-as-a-judge、カスタムデータセット、ベンチマークデータセットを使用して、要約、質問応答、テキスト生成、分類タスクの品質を測定します。複数モデルのA/Bテスト、ファインチューニング効果検証、プロンプト最適化を実行し、コスト、レイテンシ、品質のトレードオフを可視化します。
Amazon Bedrock Model Evaluationは、基盤モデルの品質を多角的に評価して最適なモデル選択とチューニングを支援する評価プラットフォームです。
Amazon Bedrock AgentCore
Amazon Bedrock AgentCoreは、AIエージェントの中核機能を提供するランタイムエンジンです。ReActパターンの実装、ツール呼び出しオーケストレーション、メモリ管理、エラーハンドリングを自動化します。推論ループ、アクション実行、観察処理を管理し、エージェントが自律的に目標達成まで反復実行できるようにします。Bedrock Agentsの基盤として機能し、カスタムエージェント開発のコア機能を提供します。
Amazon Bedrock AgentCoreは、自律型AIエージェントの推論・実行サイクルを管理する中核ランタイムエンジンです。
Amazon Bedrock Model Invocation Logs
Amazon Bedrock Model Invocation Logsは、基盤モデルへのすべてのAPI呼び出しを記録する監査・分析機能です。入力プロンプト、出力応答、メタデータ(モデルID、タイムスタンプ、トークン数、レイテンシ)をCloudWatch LogsまたはS3に自動保存します。コンプライアンス監査、使用状況分析、コスト最適化、トラブルシューティングに活用でき、Guardrails適用結果やエラー情報も記録します。データガバナンス、セキュリティ監視、パフォーマンス分析を実現し、生成AIアプリケーションの透明性と説明責任を強化します。
Amazon Bedrock Model Invocation Logsは、基盤モデルの全API呼び出しを記録してガバナンス・監査・最適化を支援するロギング機能です。
pgvector
pgvectorは、PostgreSQLでベクトルデータの保存と類似度検索を可能にする拡張機能です。埋め込みベクトルをネイティブに扱い、コサイン類似度やユークリッド距離などで高速検索を実行できます。RAGアプリケーションやセマンティック検索に最適で、Amazon RDS for PostgreSQLやAmazon Auroraで利用可能です。既存のPostgreSQLインフラを活用できるため、導入が容易です。
pgvectorは、PostgreSQLをベクトルデータベースに変える強力な拡張機能です。
Strands Agents
AWS Strands(正式名称: Strands Agents)は、AWSが2025年にリリースしたオープンソースのAIエージェント構築SDKです。モデルファースト設計で自律的なAIエージェントを構築でき、Amazon Bedrock、Lambda、Step Functionsなどとネイティブ統合します。マルチエージェント協調パターン(Swarm、Graph、Workflow)、MCP(Model Context Protocol)サポート、マルチモーダル機能を提供し、エンタープライズグレードの自律型AIシステム構築を実現します。
Strands Agentsは、AWSサービスとシームレスに統合された次世代の自律型AIエージェント開発フレームワークです。
公式E-learningの中で「AWS Strands」という呼び方が使われているので本番問題でもこの呼び方で出題される可能性がある。
Agent Squad
複数のエージェントを組み合わせて複雑な会話を処理するフレームワーク
Amazon EC2 UltraCluster
Amazon EC2 UltraClusterは、複数のAmazon EC2インスタンスを低レイテンシ・高帯域幅のアクセラレータインターコネクトで接続する構成です。大規模AI/MLワークロードに特化して設計され、膨大な処理能力を必要とする分散学習や推論を実行します。GPU/TPUなどのアクセラレータ間の高速通信により、スケーラブルな並列処理を実現し、大規模言語モデルのトレーニングや複雑なAIタスクに最適化されています。
Amazon EC2 UltraClusterは、高性能インターコネクトで結合された複数EC2インスタンスによる超大規模AI/ML専用コンピューティングクラスターです。
AWSの公式E-learningではUltraServersという呼び方をされていた。
Amazon Verified Permissions
Amazon Verified Permissionsは、アプリケーションにきめ細かいアクセス制御を実装するマネージドサービスです。Cedarポリシー言語を使用して、属性ベースアクセス制御(ABAC)やロールベースアクセス制御(RBAC)を定義します。ポリシーを一元管理し、リアルタイムで認可判断を実行。Amazon Cognito、IAM Identity Centerと統合でき、マイクロ秒単位の高速な権限チェックで、セキュアなアプリケーション構築を支援します。
Amazon Verified Permissionsは、Cedarポリシー言語による宣言的で監査可能なきめ細かい認可管理サービスです。
Amazon Comprehend Medical
Amazon Comprehend Medicalは、医療テキストから医学的情報を自動抽出する自然言語処理サービスです。診断、治療、投薬、検査結果、解剖学的部位などを識別し、HIPAA適格で保護医療情報(PHI)を安全に処理できます。電子カルテ(EMR)、臨床試験文書、医師のメモから病名、薬剤名、用量、投与経路、症状などを構造化データに変換します。ICD-10-CM、RxNorm、SNOMED CTなどの医療オントロジーにリンクし、医療データ分析や臨床研究を効率化します。
Amazon Comprehend Medicalは、非構造化医療テキストを構造化データに変換してヘルスケア分野のデータ活用を加速する医療特化型NLPサービスです。
Amazon SageMaker ML Lineage Tracking
Amazon SageMaker ML Lineage Trackingは、機械学習ワークフローの系譜(リネージ)を自動追跡・可視化する機能です。データセット、コード、ハイパーパラメータ、モデル、エンドポイント間の依存関係を記録し、トレーニングから本番デプロイまでの完全な履歴を管理します。監査証跡、再現性確保、コンプライアンス対応に不可欠で、モデルのドリフトやバイアス検出時に元データやトレーニング条件を即座に特定できます。SageMaker Experimentsと統合し、ガバナンスと透明性を強化します。
Amazon SageMaker ML Lineage Trackingは、MLライフサイクル全体の成果物と依存関係を追跡してモデルの再現性とガバナンスを実現する系譜管理機能です。
Amazon SageMaker Model Cards
Amazon SageMaker Model Cardsは、機械学習モデルのドキュメントを標準化して透明性を確保する機能です。モデルの目的、性能指標、トレーニングデータ、評価結果、制限事項、倫理的配慮を一元的に記録します。バイアス評価、公平性メトリクス、意図された用途と不適切な用途を明示し、責任あるAI(Responsible AI)の実践を支援します。規制当局や利害関係者への説明責任とガバナンスを強化し、モデルのライフサイクル全体で透明性を維持します。
Amazon SageMaker Model Cardsは、MLモデルの特性とリスクを体系的に文書化して責任あるAI運用を実現するモデルドキュメンテーション機能です。
Amazon SageMaker Model Monitor
Amazon SageMaker Model Monitorは、本番環境のMLモデルを継続的に監視して品質劣化を検出する機能です。データドリフト(入力データの分布変化)、モデルドリフト(予測精度の低下)、バイアスドリフト(公平性の変化)、特徴量の異常を自動検出します。ベースライン統計と比較して逸脱を検知し、CloudWatchアラームで通知します。スケジュール実行で定期監視し、問題発生時に再トレーニングや再デプロイを自動トリガーできます。MLOpsの継続的モデル評価を実現します。
Amazon SageMaker Model Monitorは、本番モデルの品質とパフォーマンスを自動監視してドリフトを早期検出するMLOps監視機能です。
Amazon SageMaker Clarify
Amazon SageMaker Clarifyは、機械学習モデルのバイアス検出と説明可能性を提供するツールです。トレーニング前後のデータバイアス分析、特徴量の重要度計算(SHAP値)、予測の説明生成を自動化します。人口統計学的パリティ、機会均等性、条件付き人口統計学的差異などの公平性メトリクスを測定し、保護属性(性別、人種、年齢)に対する偏りを定量化します。Model Monitorと統合して本番環境でのバイアスドリフト監視も実行し、責任あるAI開発とコンプライアンスを支援します。
Amazon SageMaker Clarifyは、MLモデルの公平性と透明性を確保するバイアス検出・説明可能性分析ツールです。
Amazon SageMaker Model Dashboard
Amazon SageMaker Model Dashboardは、本番環境の全MLモデルを一元的に可視化・管理する統合ダッシュボードです。モデルの品質メトリクス、ドリフト検出結果、バイアス評価、エンドポイント状態をリアルタイムで表示します。Model Monitor、Clarify、Model Cardsの情報を集約し、複数モデルのパフォーマンス比較とアラート管理を一画面で実行できます。ガバナンス、コンプライアンス、運用効率を向上させ、MLOpsチームがモデルの健全性を包括的に監視できる中央管理コンソールです。
Amazon SageMaker Model Dashboardは、本番モデルの監視・評価・ガバナンス情報を統合して可視化するMLOps統合管理ダッシュボードです。
その他AWSサービス
Amazon CloudWatch Evidently
Amazon CloudWatch Evidentlyは、機能フラグとA/Bテストを管理するマネージドサービスです。新機能の段階的ロールアウト、カナリアリリース、トラフィック分割を実装し、ユーザーセグメント別に異なる機能バリエーションを配信します。CloudWatchメトリクスと統合して、コンバージョン率、レイテンシ、エラー率などのビジネス・技術指標を自動収集し、統計的有意性を計算します。リスクを最小化しながら新機能をテストし、データドリブンな意思決定で最適なバリエーションを特定します。
Amazon CloudWatch Evidentlyは、機能フラグとA/Bテストで安全な機能リリースとデータ駆動型の最適化を実現する実験管理サービスです。
CloudWatch Anomaly Detection
Amazon CloudWatch Anomaly Detectionは、機械学習を使用してメトリクスの異常を自動検出する機能です。過去のメトリクスデータから正常なパターンを学習し、季節性、トレンド、時間帯変動を考慮した動的な予測バンド(上限・下限)を生成します。実際の値がバンドを逸脱すると異常として検出し、CloudWatchアラームで通知します。静的閾値設定が不要で、トラフィック急増、パフォーマンス劣化、コスト異常を自動検知します。EC2、Lambda、RDS、カスタムメトリクスに対応し、運用の自動化を実現します。
Amazon CloudWatch Anomaly Detectionは、機械学習で動的にメトリクスの正常範囲を学習して異常を自動検出する予測型監視機能です。
CloudWatch Application Signals
CloudWatch Application Signalsは、アプリケーションの健全性を自動的に可視化・監視するマネージドサービスです。レイテンシ、エラー率、可用性、トランザクション量などのゴールデンシグナルを自動収集し、サービスマップ、依存関係グラフ、SLO(Service Level Objectives)追跡を提供します。コード変更不要で、**AWS Distro for OpenTelemetry(ADOT)**を使用して自動計装します。マイクロサービス、コンテナ、Lambdaに対応し、異常検出、根本原因分析、パフォーマンス最適化を実現します。
CloudWatch Application Signalsは、アプリケーションの重要メトリクスを自動収集してサービス健全性を包括的に監視する可観測性サービスです。