この記事の概要
2022/12/03
AWS認定データ分析 - 専門知識
(AWS Certified Data Analytics - Specialty(DAS-C01))
を受験したので、その時の記録
復習用ノートとして、また後で見返して今後の資格試験受験時の参考にしたり仕事で使いたくなったとき思い出せるようにまとめます。
試験の概要
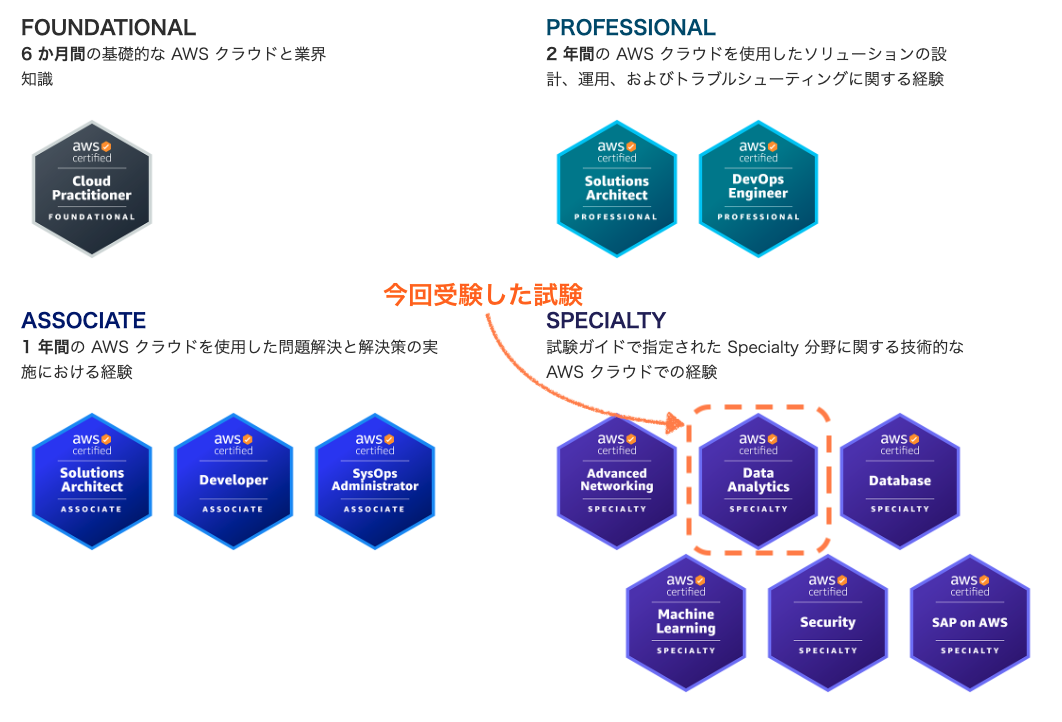
SPECIALTYカテゴリの試験で、この試験では「AWS データレイクと分析サービスを利用して、データからインサイトを得るための専門知識を認定します。」とのこと。
AWS公式より引用:引用元
◼︎ 試験要項
問題数 :65問(うち15問は採点対象外)
試験時間 :180分
受験料 :¥30,000(税別)※公式サイトでは「300USD」の表記ですが、為替レートに関わらず税別¥30,000です。
合格ライン:100~1000点中750点(約72%、採点対象の問題37/50正解で合格)
受験資格 :なし
有効期限 :3年
◼︎ 出題範囲
| 分野 | 出題割合 |
|---|---|
| 第 1 分野: 収集 | 18% |
| 第 2 分野: ストレージとデータ管理 | 22% |
| 第 3 分野: 処理 | 24% |
| 第 4 分野: 分析と可視化 | 18% |
| 第 5 分野: セキュリティ | 18% |
2022/11時点の最新バージョン(Ver.2.0) のものです。
バージョンアップで範囲等は変更されるので、受験時は公式サイトの「試験ガイド」を確認してください。
AWS Certified Data Analytics - Specialty 認定
勉強開始前の状態
AWSで動いているアプリの保守開発/運用の業務を5年程度、現在も継続中。データ分析の経験はゼロ。
AWS認定はこれまで9個取得済み。
- AWS認定ソリューションアーキテクトを受験した時の話
- AWS認定デベロッパーアソシエイトを受験した時の話
- AWS認定SysOpsアドミニストレーターアソシエイトを受験した時の話
- AWS認定ソリューションアーキテクトプロフェッショナルを受験した時の話
- AWS認定DevOpsエンジニアプロフェッショナルを受験した時の話
- AWS認定セキュリティ - 専門知識を受験した時の話
- AWS認定データベース - 専門知識を受験した時の話
- AWS認定アドバンストネットワーキング - 専門知識を受験した時の話
勉強に使ったもの
1. AWS公式模擬試験(AWS Certified Data Analytics - Specialty Official Practice Question Set (DAS-C01 - Japanese))
AWS Skill Builderで無料で提供されている20問の模擬試験。何度でも実施できるのではじめに実施します。
2. AWS公式E-learning(Exam Readiness: AWS Certified Data Analytics - Specialty (Japanese))
AWS Skill Builderで無料で提供されている試験対策の公式E-learning、試験範囲についてサンプル問題をはさみながら教えてくれます。試験範囲の要点について知ることができるので、受講する価値はあると思います。
3. オンライン問題集(非公式)
AWS認定受験時に毎回購入している「Whizlabs」
DASのコースは最新のバージョンの問題が 265問(65問×3パターン+セクション問題が50問+お試し問題が20問) 用意されています。
18.95USDからクーポン利用で30%offの13.27USD(日本円で¥2,000ぐらい) でした。
円安の影響もあり昔に比べて少し高くなりましたね、買い切りで内容の更新もされるのでXmasやBlackFlidayなどで割引率が高いクーポンが出てきたときに買っておくと少しお得になりますが、今回は11月中に受験したかったので、30%offで我慢します。
いつもどおり、Google翻訳で翻訳して利用。
勉強(試験準備)の流れ
1. 試験ガイドを読む
はじめに、公式サイトの「試験ガイド」を読みます。
メインは↓の「アナリティクス」関連のサービスですね、きっと。
アナリティクス:
- Amazon Athena
- Amazon CloudSearch
- Amazon Elasticsearch Service (Amazon ES)
- Amazon EMR
- AWS Glue
- Amazon Kinesis (Kinesis Video Streams を除く)
- AWS Lake Formation
- Amazon Managed Streaming for Apache Kafka
- Amazon QuickSight
- Amazon Redshift
全く触れたことがないサービスもあるので、要勉強です。
2. サンプル問題と模試を実施する
次に、公式のサンプル問題と模試をやってみます。
無料なので気軽に実施できます。これで問題のレベル感と自分のレベル感、そのギャップを確認します。
もちろんここでわからなかった部分はメモしておいて後で調べます。覚えたほうが良さそうな部分はノートに書き出します。
3. Exam Readinessを受講する
公式E-Learningはためになることが多いので、受講しておきます。
4. 練習問題を解く
すでに基礎知識はあるので、練習問題を解いてわからないところを集中的に勉強します。
全問解いてから回答の確認をしていると問題文を2回ずつ読むことになって効率が悪いので、practice modeでその場で回答を確認し、間違っていた場合メモしたりすぐに調べるようにしています。
5. 復習する
ここまで勉強しながらまとめたノートと練習問題の回答/解説を見返しながら、覚え直し+まだ足りなそうな部分の勉強をします。
今回は
- Amazon EMR
- Amazon Kinesis
- Amazon Redshift
- Amazon QuickSight
- Amazon Elasticsearch Service
- AWS Glue
のBlackBelt過去動画を見て勉強。2倍速で再生しながら気になったところで止めてメモしたりします。
いつも書いていませんでしたが、はじめにこの記事を途中まで書いて、試験準備としてやるべきこととそれにかかる時間を計算して、スケジューリングしたりしています。
例えば問題集が265問あるので、だいたい10問で1hとして26.5時間+模試1h+E-learning6hで33.5hが最低ライン = 2.5週間(平日1h/日, 休日5h)
プラス理解不足の解消でBlackBeltを見たりするともう1週間増えて3週間〜とか、カレンダーに置きながら計画します。
勉強時間
約45時間
受験後
結果はスコア794で合格。
自信を持って答えられない問題も多く、150分間使って回答したあと30分間見直しで制限時間ギリギリまで使いました。



AWS認定は試験終了後、その場で合否が画面に表示されるときとされないときがあるんですが、今回は表示されるやつでした。
最近更新されたものは表示されない?
AWS認定12種、残りはMLとSAP on AWSの2つ、MLはDAと近い分野なのでこのまま勉強を続けて近いうちに受験予定です。
勉強ノート
試験のために勉強しながらまとめたノート
※ここに書いてあることは、あくまで私が理解が足りないと感じ、覚えたかったことだけです。試験範囲を網羅はしていません。
データ分析関連用語
| 用語 | 説明 |
|---|---|
|
データレイク (Data Lake) |
データの構造や大きさ、性質、種類などにかかわらず、あらゆるデータを未加工の生データの形で集めるDB/ストレージ(そのままのデータたちが漂う湖) |
|
データウェアハウス (DWH:Data Ware House) |
分析しやすいよう変換/構造化されたデータを格納するDB(きれいに箱詰めされて整頓されたデータたちが保管される倉庫) |
|
データマート (Data Mart) |
用途に応じて分析に必要なデータだけに素早くアクセスできるように分割した小規模なDB(ジャンルごとの商品を並べる市場) |
|
BIツール (ビジネスインテリジェンスツール) |
さまざまなデータを集約し、分析/視覚化を行いビジネスに活用するためのツール、グラフやテーブルを表示するダッシュボードを提供する。 |
|
インサイト (洞察/Insights) |
データ分析から導き出される本質的需要 |
| 巡回セールスマン問題 | ある箇所から複数の地点を巡って戻ってくる際の最短経路を求める問題 |
|
サイロ化 (silos) |
データやシステムが部署などで分割され、連携/集約による活用ができていない状態、あるいは意図的に相互に分離された状態。 |
データ分析ワークロードのアーキテクチャ
AWSを利用したデータ分析ワークロードはデータソースや利用目的によりアーキテクチャに最適なサービスが異なる。
この試験では要件に応じた最適なアーキテクチャを選択する問題も出題される。
これはデータ分析に限らず、大きなデータを集計/取り込み/出力するバッチ処理の設計にも活かせるので覚えておく。
- データソースの種類(input)
- 中間処理のリアルタイム性
- 分析結果の利用方法(output)
などに注目する。
まず「データソース」
- RDB: DMSの「継続的なレプリケーション」または「変更データキャプチャ (CDC)」によりS3へデータの変更を同期する
- オンプレ: DataSyncエージェントをインストールし、S3へ変更を同期する
- DynamoDB: GlueでS3へ出力、またはDynamoDBストリーム→Lambda→Kinesis Data FirehoseでS3やKinesis Data Analyticsへストリームを出力する
- IoTデバイス: Kinesisへストリーミングまたは、IoT Coreを通してDynamoDB,S3,Lambda,OpenSearch等に送信
次に「リアルタイム性」
- リアルタイム: Kinesis Data Analytics等のストリームで処理する
- バッチ処理: Glue、EMR等で大量データを一括で処理する
そして「出力先」
- アドホッククエリ: 蓄積したデータに対し必要に応じた(アドホック)クエリをしたい場合、RedshiftやS3に格納し、Redshiftの場合直接、S3の場合Athenaでクエリする
- ダッシュボード(視覚化): ダッシュボードを作成し、必要なデータをグラフで視覚化する場合、上記のRedshiftやAthenaをソースにQuickSightでダッシュボードを作成するか、OpenSearchに送信しKibanaでダッシュボードを作成する
データ分析関連のサービスとその他のサービスの関係を書き出してみる。
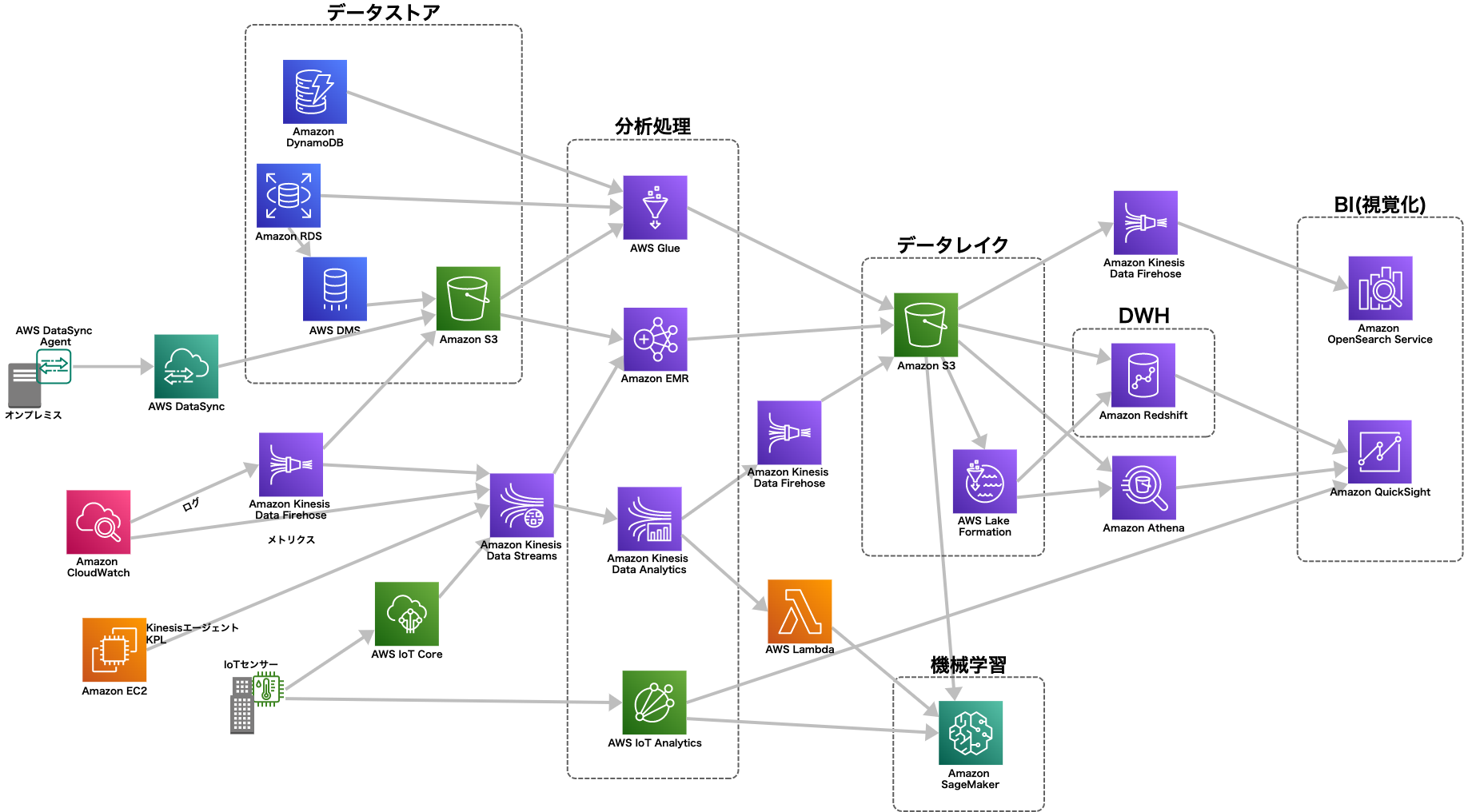
※この中にない入出力も可能だが、AWS推奨のプラクティスとしてよく登場するようなデータの流れを図にした
※Kinesis Data Firehoseは出力先にRedshiftを指定できるが、内部ではS3に一度出力しCOPYコマンドを呼び出しているため、Redshiftへの直接出力ではない
Amazon EMR
Apache HadoopやApache Sparkなどのビッグデータフレームワークを使用して大量データを処理/分析するインスタンス群を構築/管理できるサービス。
Apache Hadoopエコシステムはバッチ処理やリアルタイム処理、ML、インタラクティブな処理などを行えるOSS群。
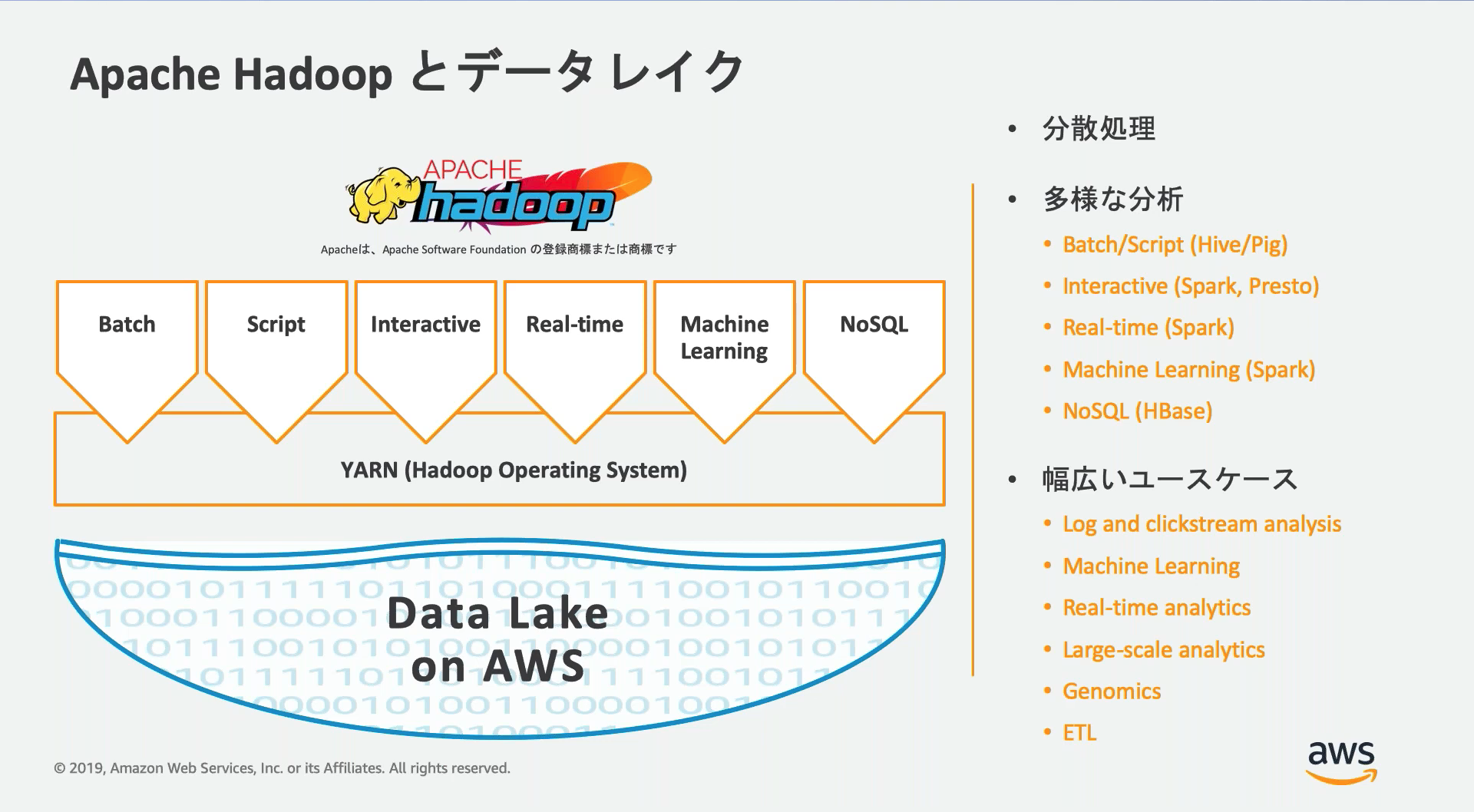
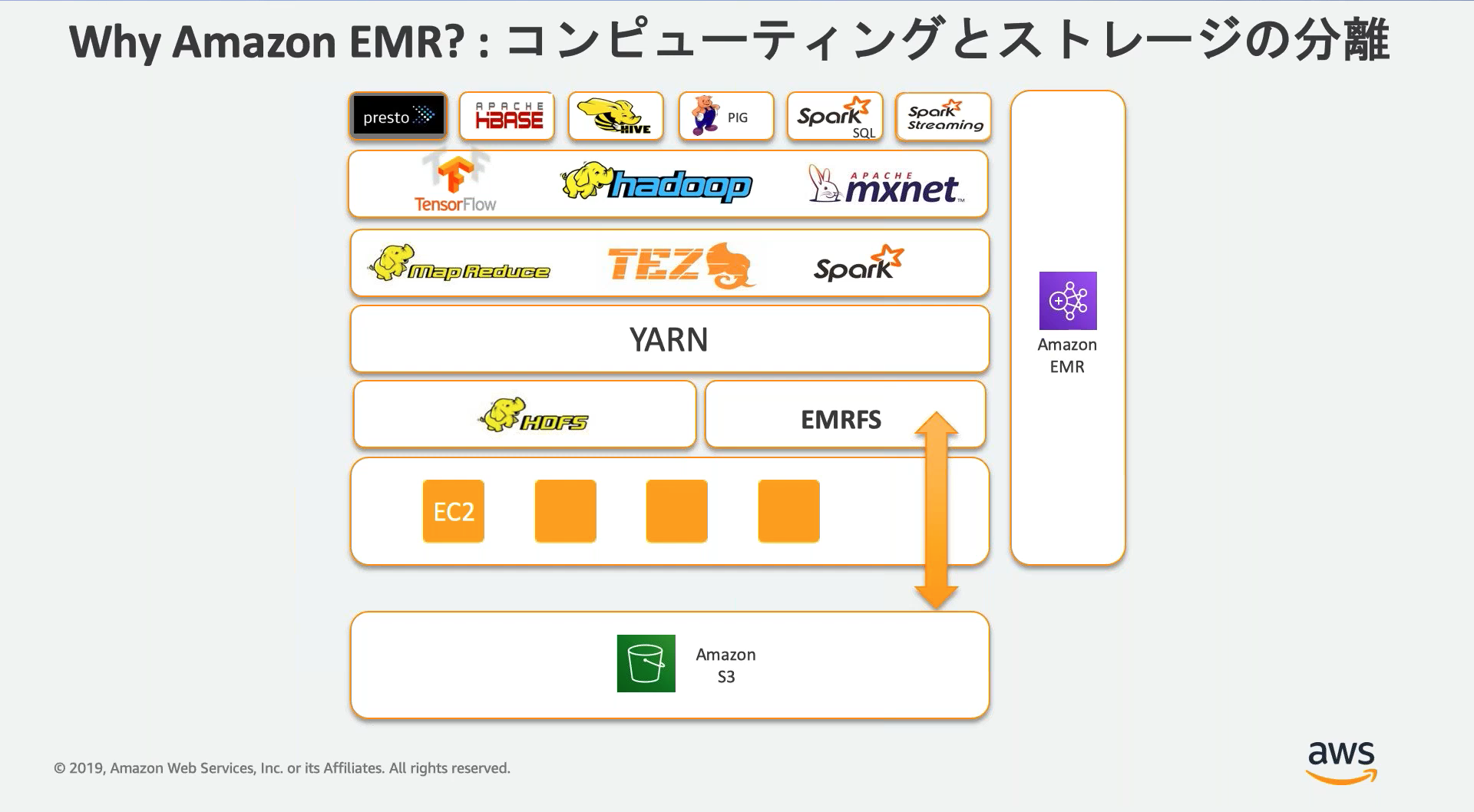
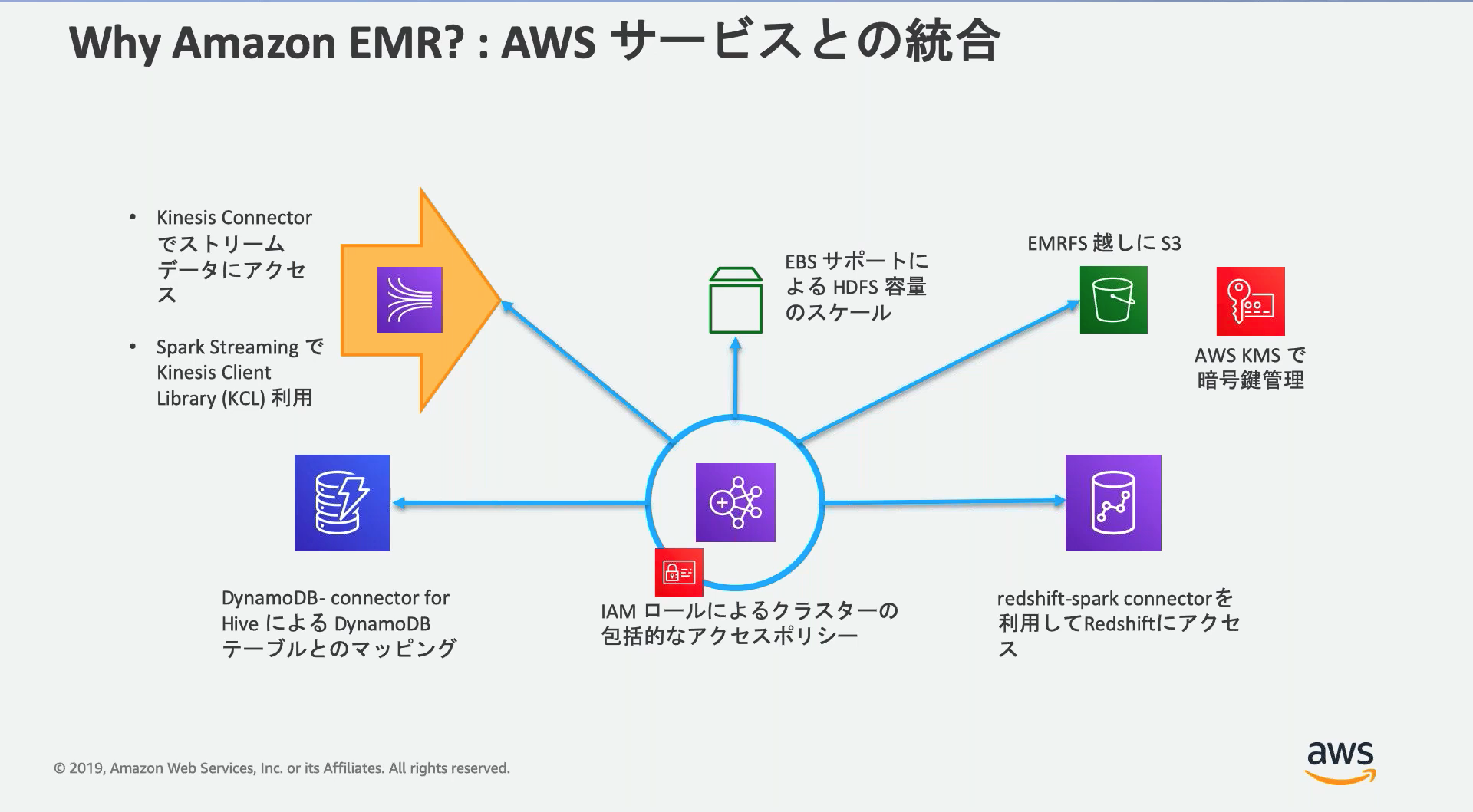
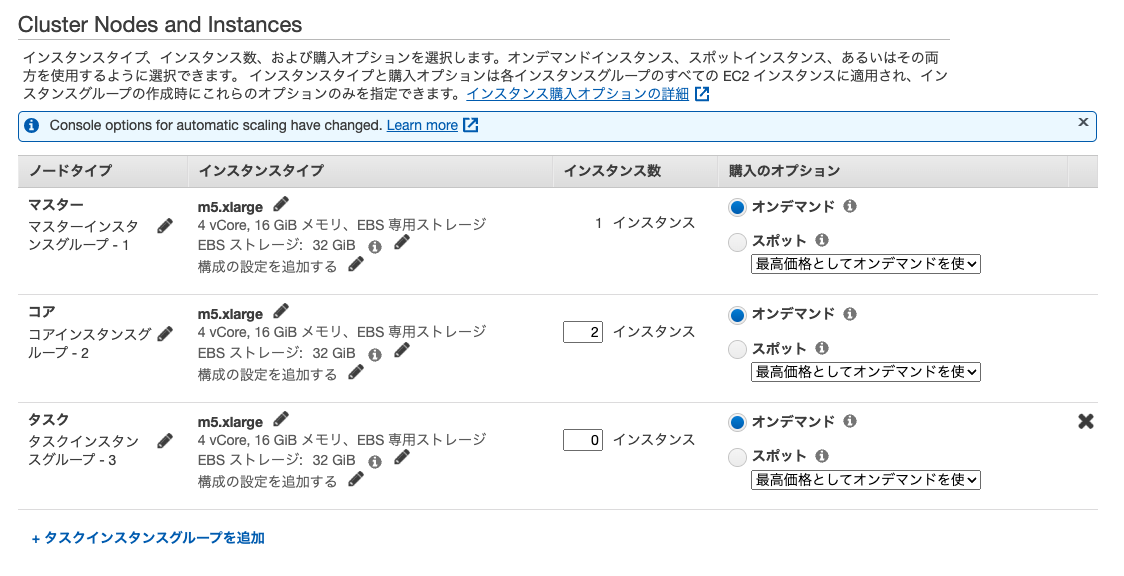
■構成イメージ図
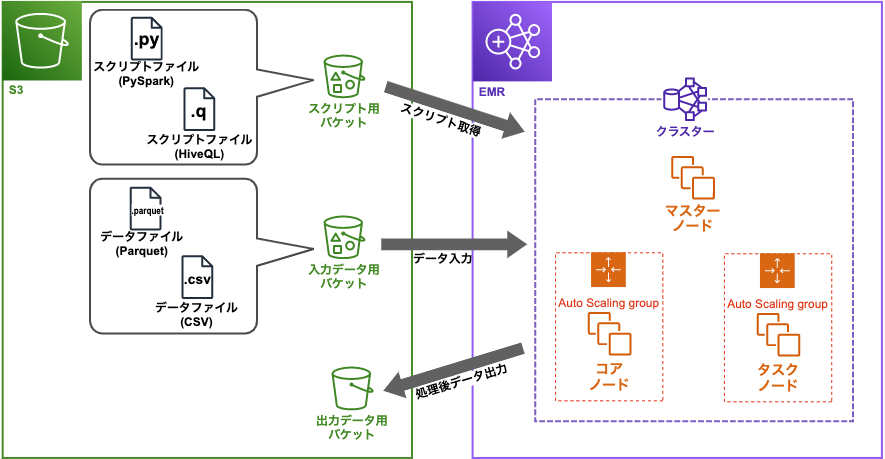
ノード
EMRのクラスターには3つのノードタイプが存在し、クラスター作成時にそれぞれのスペックや数を設定する。
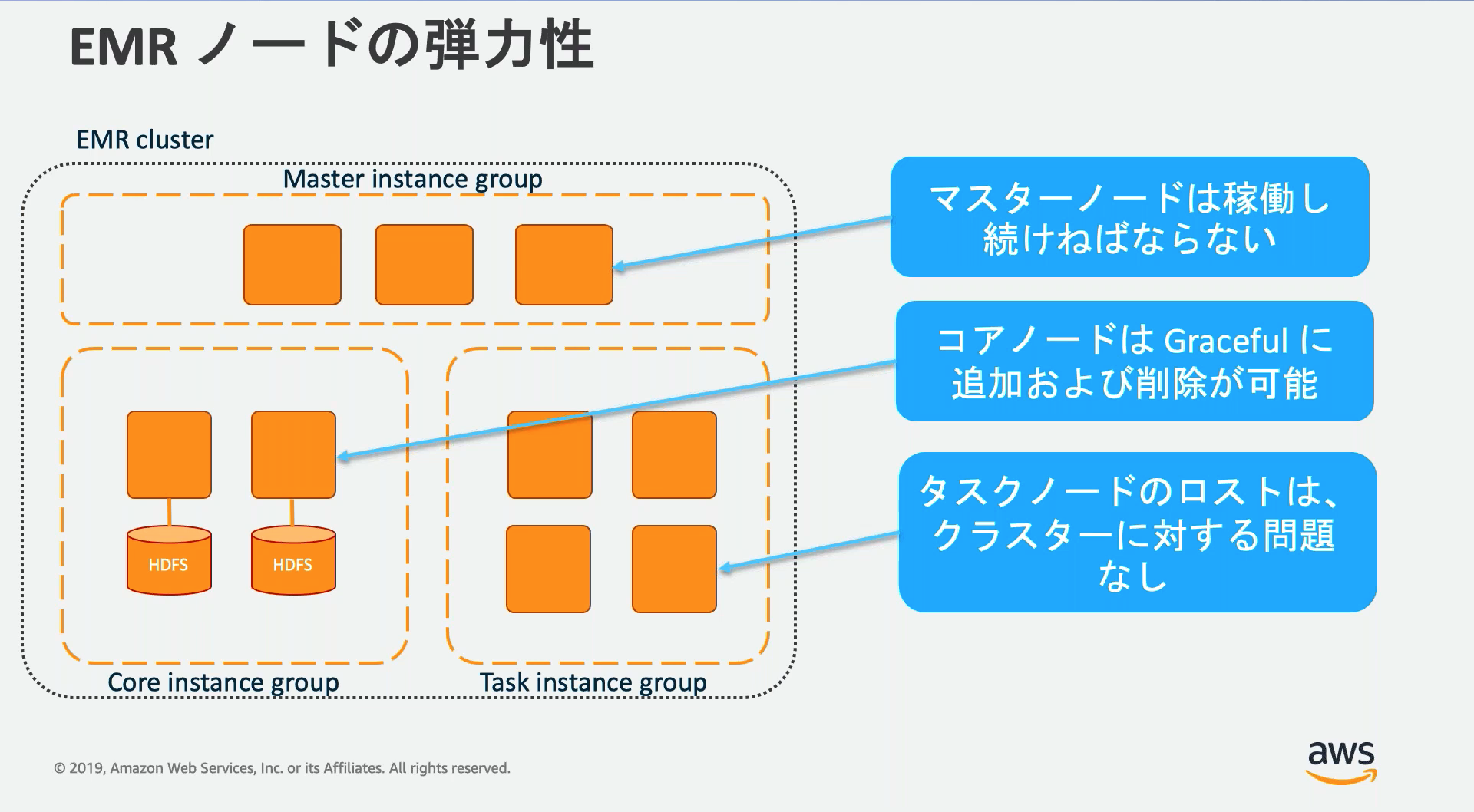
| ノードタイプ | 説明 |
|---|---|
| マスターノード | クラスターを管理するノード。マスターノードが1つの場合単一障害点となる。マルチマスターモードを選択するとマスターノードは3つになり障害時自動的にフェイルオーバーする。 |
| コアノード | マスターノードによって管理される。実行中のコアノード停止はデータ損失となるるためスポットインスタンスの利用時は注意。 |
| タスクノード | 計算タスクを実行するためのノード。エフェメラルストレージへのデータ保存などを行わないため、スポットインスタンスなどで途中で終了されても問題ない。 |
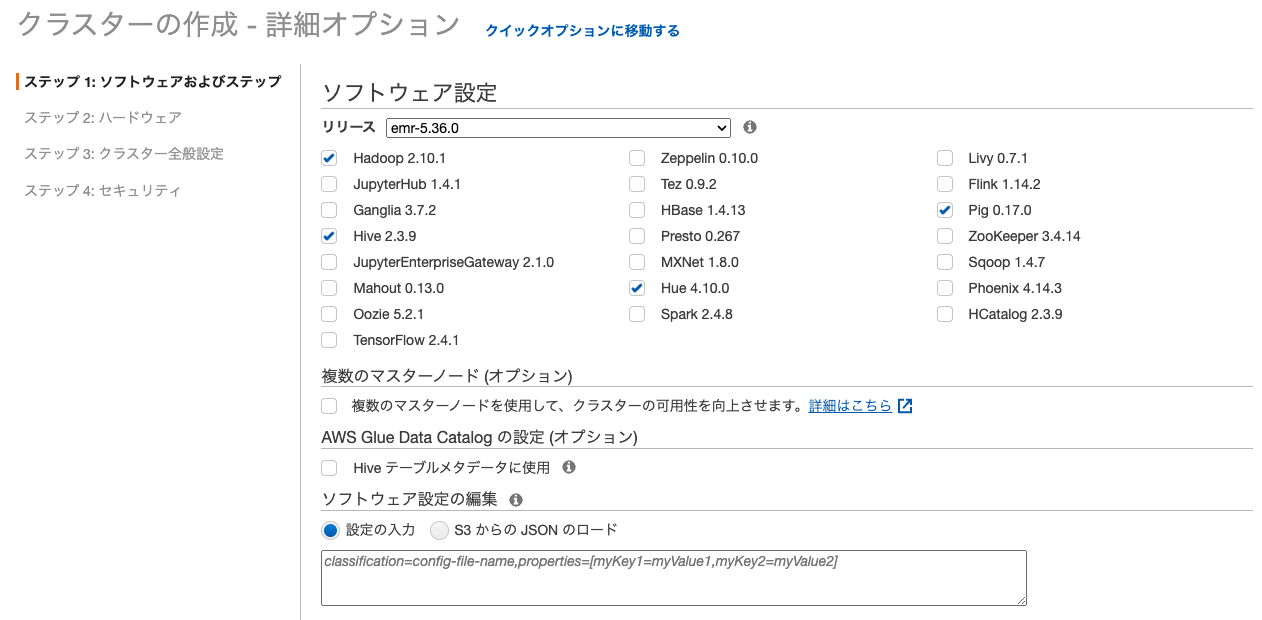
ソフトウェア
クラスター構成時にHadoop、Hive、Jupyter、SparkなどのHadoopエコシステムのソフトウェアから有効にするものを選択する。
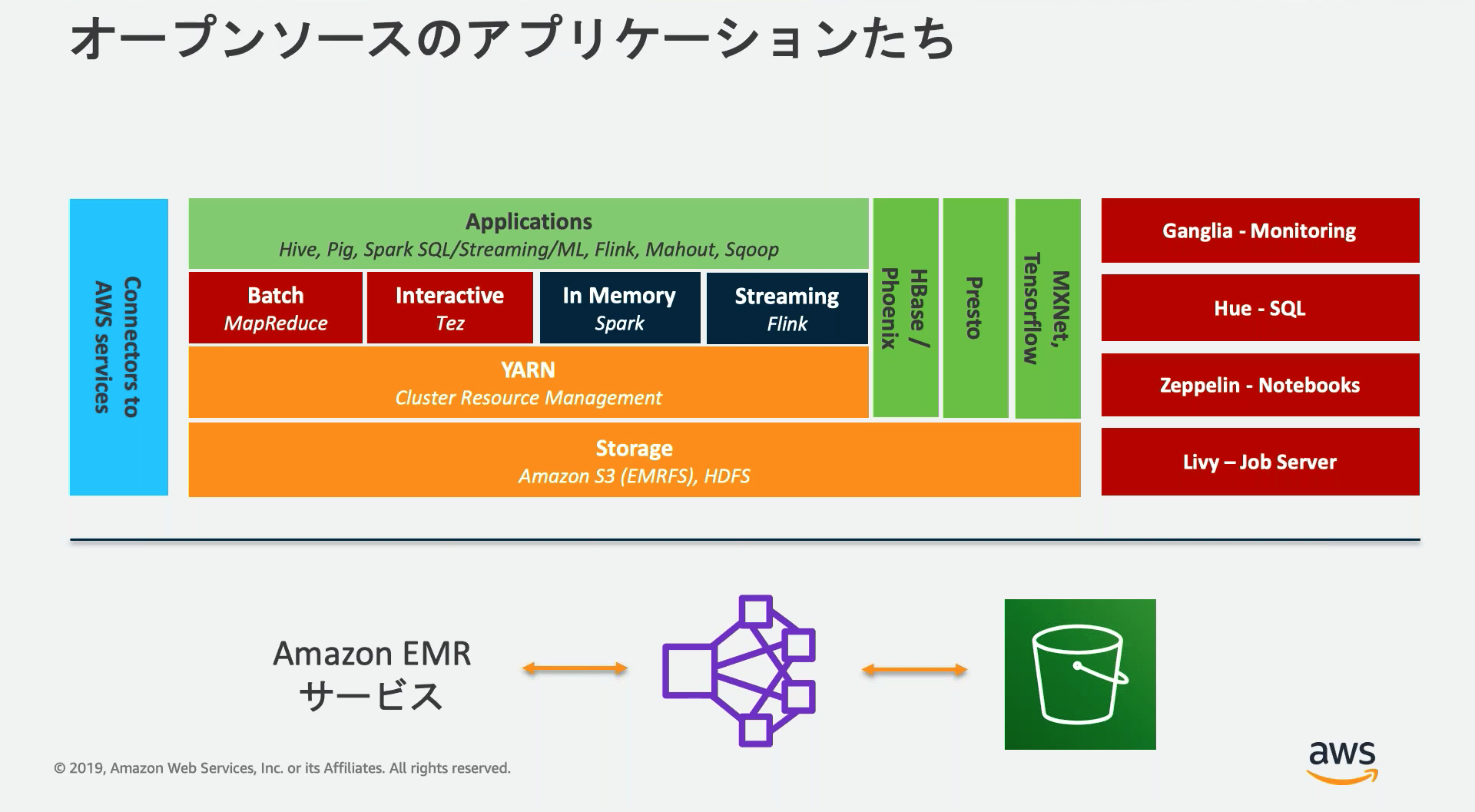
■各ソフトウェアの概要
| ソフトウェア | 概要 |
|---|---|
| Hadoop | 大規模データの蓄積・分析を分散処理技術によって実現するオープンソースのミドルウェア。 |
| JupyterHub | シングルユーザーモードのJupyterノートブックサーバーの複数のインスタンスをホストできる。 |
| Ganglia | Hadoopのメトリクスを監視する。 |
| Hive | HDFSで大規模なデータセットのクエリを実行するのに役立つSQLライクなデータウェアハウジングシステム |
| JupyterEnterpriseGateway | 遠隔地にあるノートブックに代わってカーネルを起動することができるWebサーバー。 |
| Mahout | Hadoopの機械学習ライブラリの1つ |
| Oozie | Hadoopのジョブスケジュールに使用される、JavaのWebアプリケーション。 |
| TensorFlow | Googleが開発した機械学習ライブラリ、TonY(TensorFlow on YARN)によりHadoop上での分散処理ができる。 |
| Zeppelin | インタラクティブなデータ検索用のノートブック。 |
| Tez | YARNをベースにした、高パフォーマンスのバッチおよびインタラクティブなデータ処理アプリケーションのためのフレームワーク。 |
| HBase | HDFSの最上位に位置する列指向の非リレーショナルデータベース。 |
| Presto | 複数のソースからの大量のデータセットの対話型分析クエリ用に設計された高速のSQLクエリエンジン。 |
| MXNet | ニューラルネットワークやその他のディープラーニングアプリケーションを構築するために設計されたアクセラレーションライブラリ。 |
| Hue(Hadoop User Experience) | クラスターで異実行されるアプリケーションのフロントエンドとして動作し、複数の異なるHadoopエコシステムプロジェクトをWebベースの1つのGUIにまとめる。 |
| Spark |
機械学習、ストリーム処理、グラフ分析に役立つビッグデータの分散処理システム。データをインメモリにアクティブにキャッシュするため、特定のアルゴリズムやインタラクティブクエリの場合にパフォーマンスが向上する。 Scala、Java、およびPythonをネイティブでサポートしている。 またSQL(Spark SQL)、機械学習(MLlib)、ストリーム処理(Spark Streaming)、グラフ処理(GraphX)用のライブラリが含まれている。 |
| Livy | Sparkを実行するEMRクラスターを、RESTインターフェイスによって操作できるようにする。 |
| Flink | 高スループットのデータソースでリアルタイムのストリーム処理ができるストリーミングデータフローエンジン。 |
| Pig | Pigは複雑な結合やクエリを簡単に実行できるようにする。SQLに近い「Pig Latin」という言語でクエリを行う。 |
| Zookeeper | 分散システムを調整するサービス。設定情報を集中管理する。 |
| Sqoop | RDBとの間のデータのエクスポートとインポートに使用する。 |
| Phoenix | OLTPと業務分析に使用され、Apache HBaseバッキングストアと連携して標準SQLクエリおよびJDBC APIが使用できるようにする。 |
| HCatalog | Pig、Spark SQL、MapReduceアプリケーション内のHiveメタストアテーブルにRESTまたはCLIでアクセスできるようにするツール。 |
Hiveメタストア
Hiveのメタストア情報はデフォルトではマスターノードのMySQL(エフェメラルストレージ)になる。
そのため、永続化が必要な場合は外部メタストアを設定する。
外部メタストアに選択できるのは以下の2つ
- AWS Glue Data Catalog
- Amazon RDS または Amazon Aurora
ファイルシステム
要件に応じてファイルシステムを選択する。
| ファイルシステム | 概要 |
|---|---|
| HDFS | Hadoop用ファイルシステム、処理が高速、ストレージはエフェメラル(揮発性) |
| EMRFS | S3にファイルを読み書きする、データを永続化できるがHDFSより遅い。 |
| ローカルファイルシステム | インスタンスストアにデータを保存する。 |
| S3BFS(ブロックファイルシステム) | 現在は非推奨のレガシーな設定 |
S3DistCp
S3からEMRクラスターへのデータコピーにはEMRクラスターにデフォルトでインストールされているS3DistCpを利用する。
マネコンやCLIでEMRクラスターにS3DistCpステップを追加することで実行できる。
aws emr add-steps --cluster-id j-3GYXXXXXX9IOK --steps file://./myStep.json
[
{
"Name":"S3DistCp step",
"Args":["s3-dist-cp","--s3Endpoint=s3.amazonaws.com","--src=s3://mybucket/logs/j-3GYXXXXXX9IOJ/node/","--dest=hdfs:///output","--srcPattern=.*[a-zA-Z,]+"],
"ActionOnFailure":"CONTINUE",
"Type":"CUSTOM_JAR",
"Jar":"command-runner.jar"
}
]
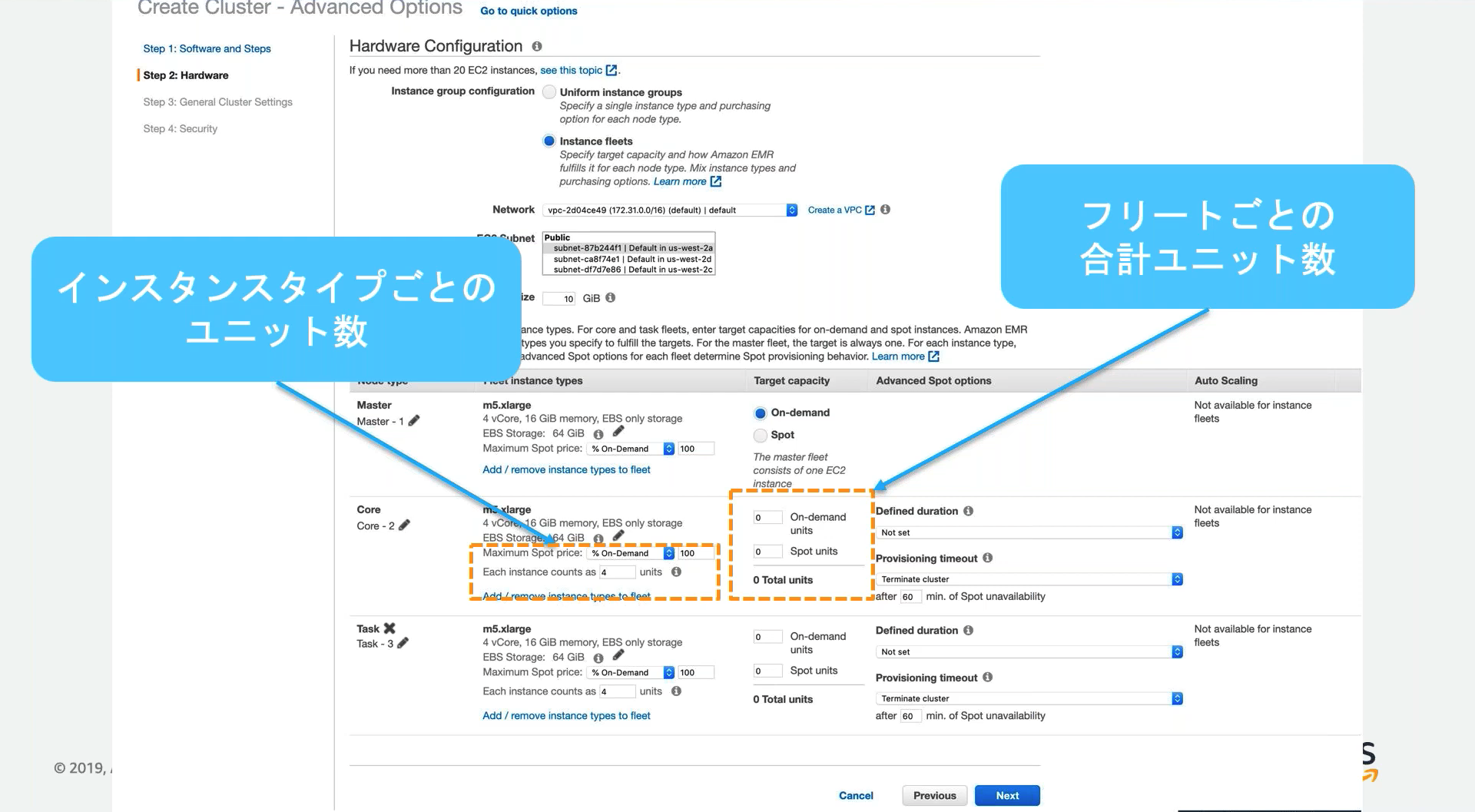
時間制限があるワークロードでのスポットインスタンス活用
EC2インスタンスフリートに「プロビジョニングタイムアウト」を定義することで、クラスターがターゲットキャパシティを満たすのに十分なスポットインスタンスがない場合、オンデマンドに切り替わることでSLAを守る。
スポットインスタンスが足りている場合は、スポットインスタンスでコストを削減できる。

スポットインスタンスが不足した場合、オンデマンドに切り替える or 起動を諦める なども設定できる。
Apache Livy
EMRクラスターにApache Livyをインストールすると、RESTインターフェイスでEMRクラスターのSparkジョブを実行できる。
Livyへは以下のURIでリクエストする。
http://:8998/master-public-dns-name
その他メモ
- 暗号化オーバーライド機能を使うと保存先のS3ごとに異なる暗号化方法を利用できる
https://docs.aws.amazon.com/ja_jp/emr/latest/ManagementGuide/emr-data-encryption-options.html - クラスターを利用時以外停止することでコスト削減でしたい場合、CloudWatchのIsIdleメトリクスで終了を検知する
- EMRFSではSSE-Cは使用できない
- EMRの同時実行数は2~256
- YARN(Yet Another Resource Negotiator): リソースの管理とスケジュールを担い、各データノードで何が起こるべきかを決定する。
Amazon Redshift
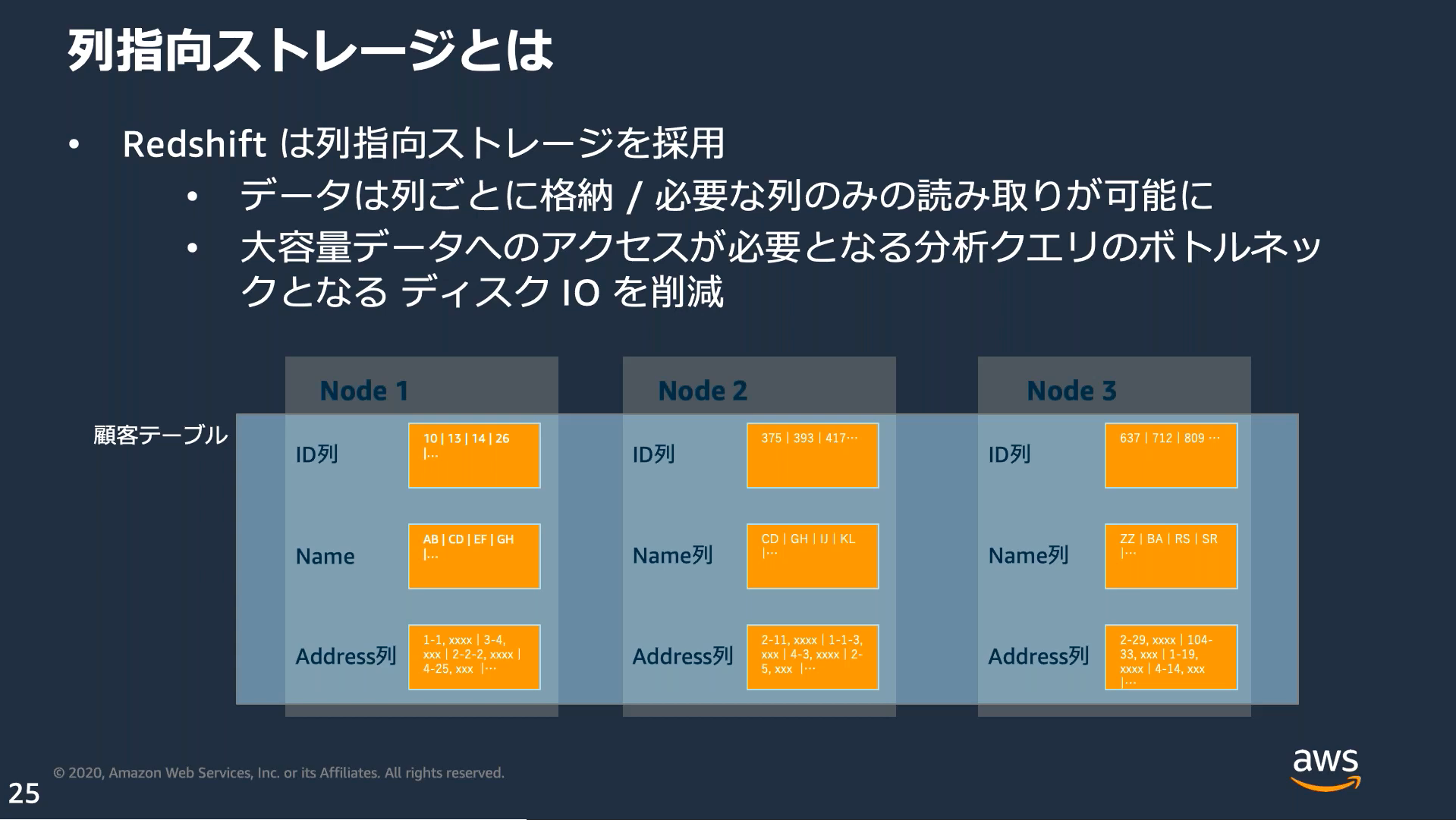
DWH(データウェアハウス)に最適化されたフルマネージドなPostgreSQLベースの列指向DB。
リーダーノード、コンピュートノード、ストレージの3層に分かれており、必要に応じてコンピュートノードとストレージをスケーリングする。
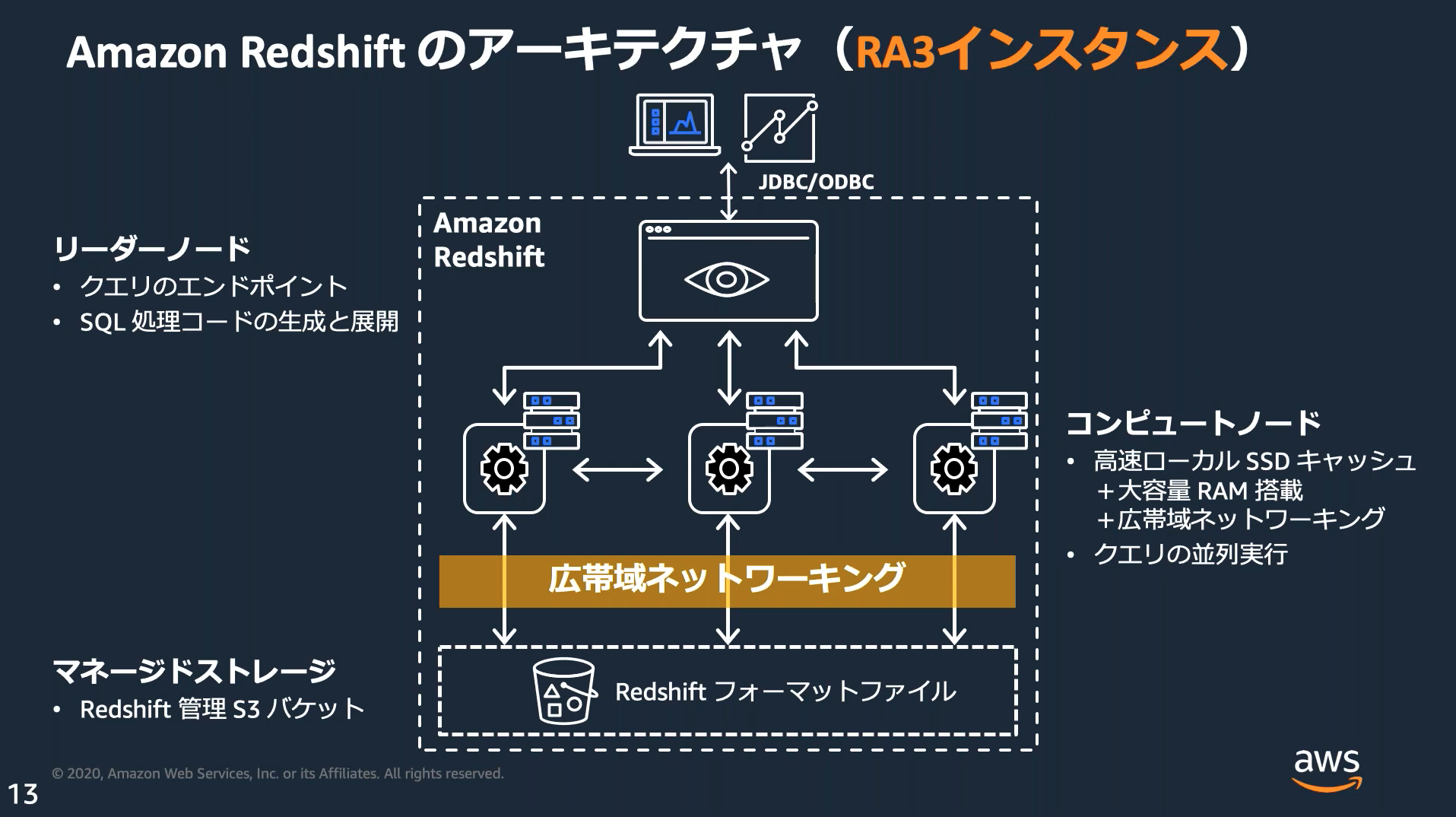
ノードタイプ
| 世代 | タイプ | 特徴 |
|---|---|---|
| 第2世代 | DC2 | ・各コンピューティングノードが個別のSSDストレージを持つ ・速度が速い(C=computeで覚える) |
| 第2世代 | DS2 | ・各コンピューティングノードが個別のHDDストレージを持つ ・大容量(S=storageで覚える) |
| 第3世代 | RA3 | ・データ処理とストレージを独立させる方式 ・各ノードは個別のストレージを持たない代わりに、RMS(Redshift Managed Storage)と呼ばれるSSDを共有利用する ・SSDに入り切らないデータはS3に自動でオフロードされる ・RA3でしか使えない機能もあり、今後構築する場合はRA3推奨 |
RA3のスペックと料金
| サイズ | vCPU | メモリー | ストレージ上限 | I/O | 価格(東京リージョン) |
|---|---|---|---|---|---|
| ra3.xlplus | 4 | 32 GiB | 32TB RMS | 0.65GB/秒 | 1.278USD/h |
| ra3.4xlarge | 12 | 96 GiB | 64TB RMS | 2GB/秒 | 3.836USD/h |
| ra3.16xlarge | 48 | 384 GiB | 64TB RMS | 8GB/秒 | 15.347USD/h |
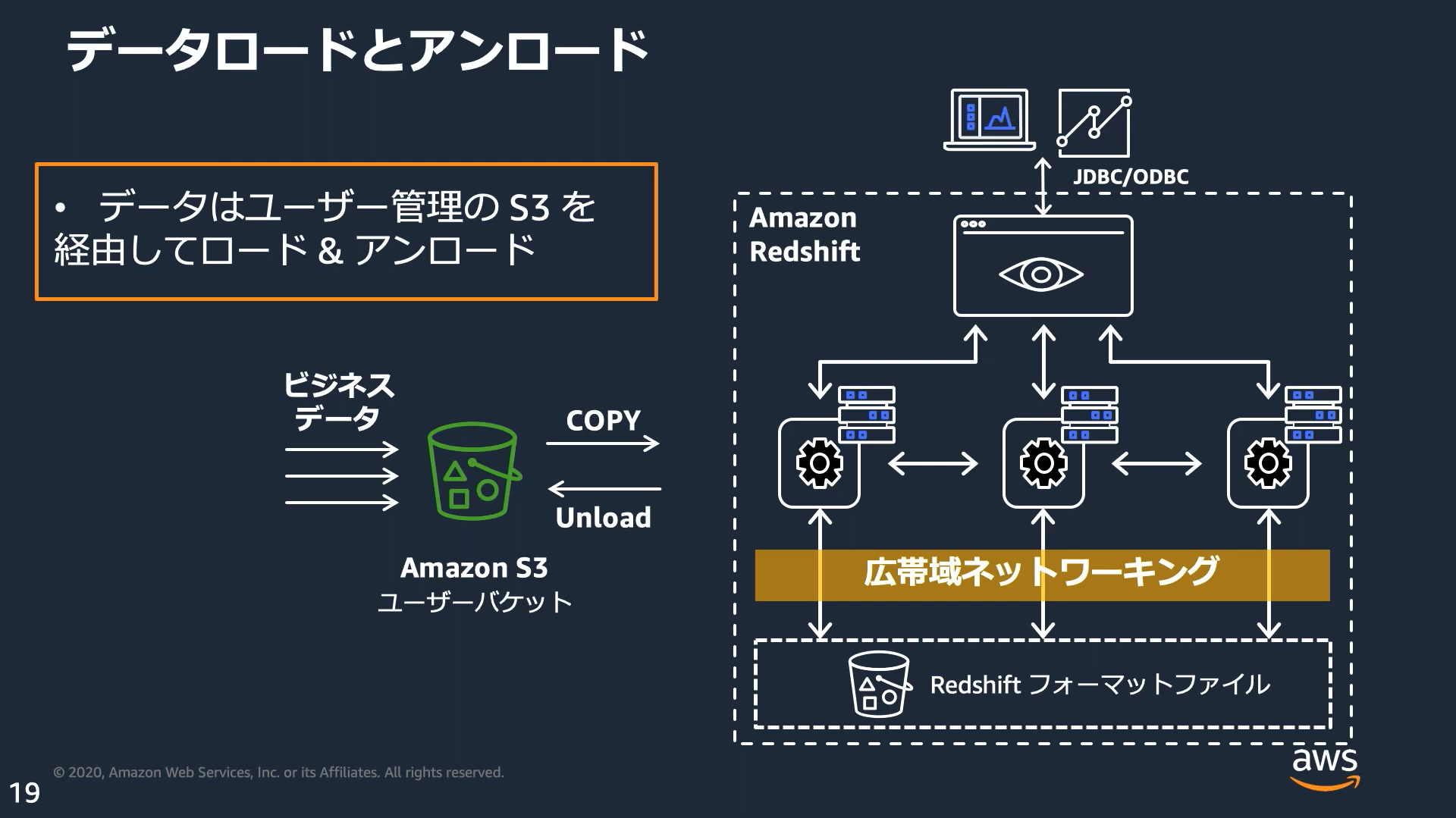
データロード
COPYコマンドを利用しS3、DynamoDB、EMR、SSH接続可能なサーバからデータをロードできる。
この際、利用するIAMロールや区切り文字、フォーマットなどを指定する。
PurquetやORCなどのフォーマットも指定することができる。
COPY table_name
FROM 's3://mybucket/data/parquet/'
IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole'
DELIMITER ','
FORMAT AS PARQUET
REGION 'ap-northeast-1';
INSERTコマンドでデータを投入することもできる。
大量データの場合COPYより時間がかかる。
テーブル未作成で既存テーブルからコピーしたい場合、CREATE TABLE ASでも可能。
INSERT INTO dst_table_name
(SELECT * FROM src_table_name);
INSERT INTO category_stage VALUES
(13, 'Concerts', 'Other', default);
アプリケーションからのクエリ
RedshiftへのクエリはData APIを利用する。
永続的な接続は行わず、SDKを介してHTTPエンドポイントへ非同期のリクエストを行う。
認証にはSecrets Managerに保存された認証情報または一時的なDB認証情報を利用する。
DR対策
RedshiftのDR対策として自動スナップショットを有効にし、異なる1つのリージョンへ自動的にコピーさせることができる。
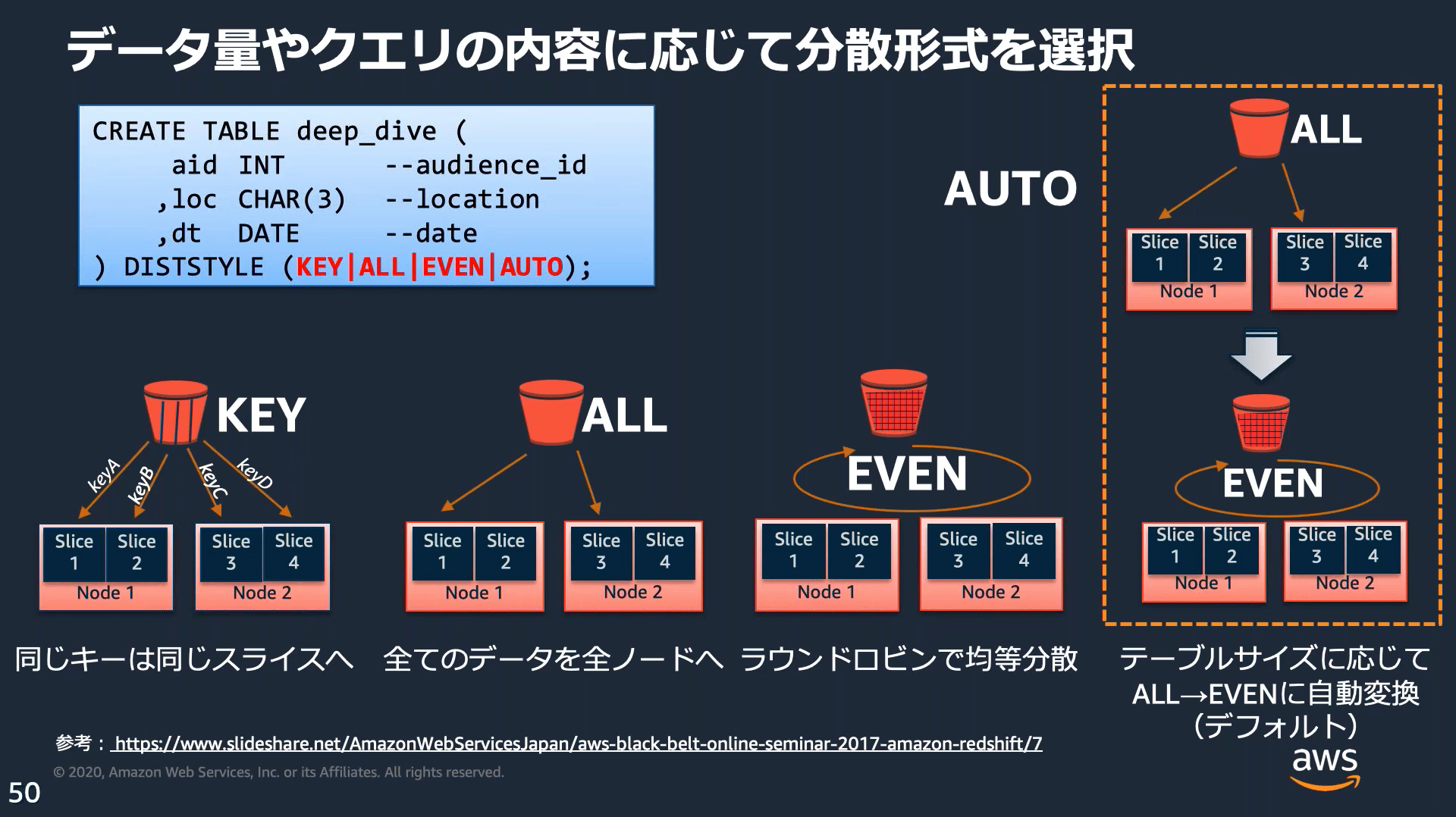
分散スタイル
テーブル作成時に4つの分散スタイルのいずれかを指定する。指定しない場合はAUTO分散になる。
| スタイル | 特徴 |
|---|---|
| AUTO分散 | テーブルデータのサイズに基づいて最適な分散スタイルを割り当てる。 |
| EVEN分散 | テーブルが結合に参加しない場合に適している。 |
| キー分散 | テーブル間で結合を行う場合に適している。 |
| ALL分散 | マスターなどの更新の少ない大きなテーブルに適している。 |
列圧縮
データ保存時に圧縮することでディスクI/Oが減少し、クエリパフォーマンスが向上する。
デフォルトではENCODE AUTOとなっており、圧縮エンコードは自動的に管理される。
テーブル作成時に列に対し圧縮タイプまたはエンコードを指定できる。
CREATE TABLE product(
product_id INT ENCODE RAW,
product_name CHAR(20) ENCODE BYTEDICT
);
COPYコマンドでCOMPUPDATEにONを指定すると自動圧縮を有効にできる、データが含まれているテーブルに自動圧縮は適用できない。
COPY biglist FROM 's3://mybucket/biglist.txt'
IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole'
DELIMITER '|' COMPUPDATE ON;
自動スナップショット
Redshiftで自動スナップショットを設定するとデフォルトでは8時間ごとにスナップショットが作成される。
スケジュールをcron式で設定する事もできる。
cron(分 時間 曜日)
で指定する。
# 平日の16:00から22:00まで1時間おき
cron(0 16-22/1 MON-FRI)
# 毎日12:30から4時間おき
cron(30 12/4 *)
# 毎週土曜日の21:00
cron(0 21 土)
CLIによるスケジュールの定義はcreate-snapshot-scheduleコマンドを実行する。
create-snapshot-schedule --schedule-identifier "my-test" --schedule-definition "cron(0 17 SAT,SUN)" "cron(0 9,17 MON-FRI)"
バキューム処理
VACUUMコマンドを実行すると、行を再ソートしてスペースを再利用できる。これによりパフォーマンスが改善される可能性がある。
VACUUM実行中はCPUとディスクに負荷がかかるため、夜間などの使用率の低い時間帯に実行する。
また、ANALYZEを実行することで、クエリの実行計画のためのメタデータが更新される。そのため1日1回程度VACUUM後にANALYZEをセットで実行することが推奨される。
Amazon Redshift Spectrum
Redshift Spectrumを使用すると、Redshiftテーブルにデータをロードすることなく、S3のファイルから直接データを取得できる。Redshift Spectrumクエリでは超並列処理を採用しており、大きなデータセットに対する処理が非常に高速で実行される。
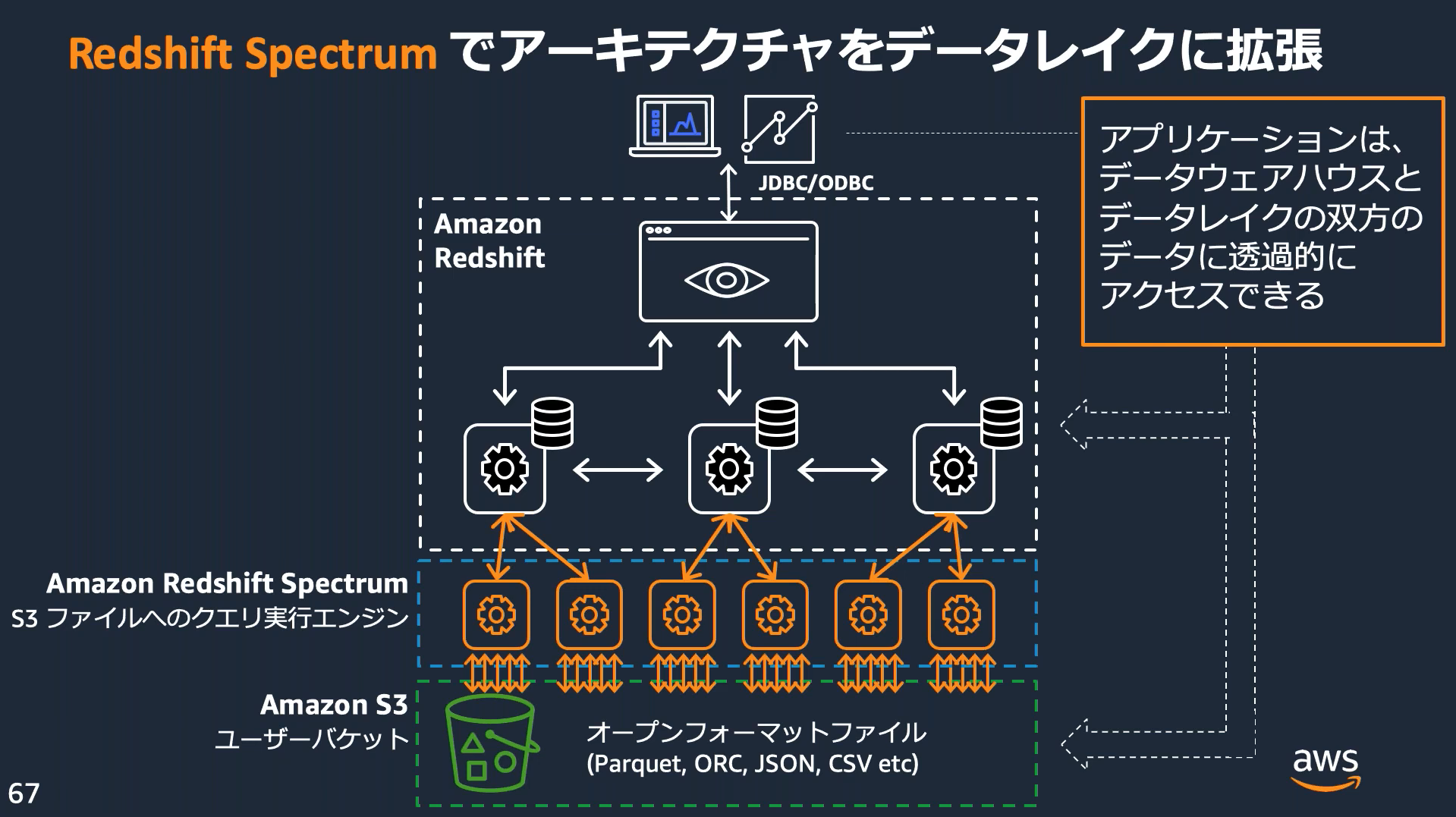
Redshift Spectrumを利用するには
- IAMロールとクラスターの関連付け
- 外部スキーマの作成
- 外部テーブルの作成
が必要となる。
外部スキーマと外部テーブルはCREATEクエリで作成する。
CREATE EXTERNAL SCHEMA myspectrum_schema
FROM DATA CATALOG
DATABASE 'myspectrum_db'
IAM_ROLE 'arn:aws:iam::123456789012:role/myspectrum_role'
CREATE EXTERNAL DATABASE IF NOT EXISTS;
CREATE EXTERNAL TABLE myspectrum_schema.sales(
salesid INTEGER,
listid INTEGER,
sellerid INTEGER,
buyerid INTEGER,
eventid INTEGER,
dateid SMALLINT,
qtysold SMALLINT,
pricepaid DECIMAL(8,2),
commission DECIMAL(8,2),
saletime TIMESTAMP
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION 's3://redshift-downloads/tickit/spectrum/sales/'
TABLE PROPERTIES ('numRows'='172000');
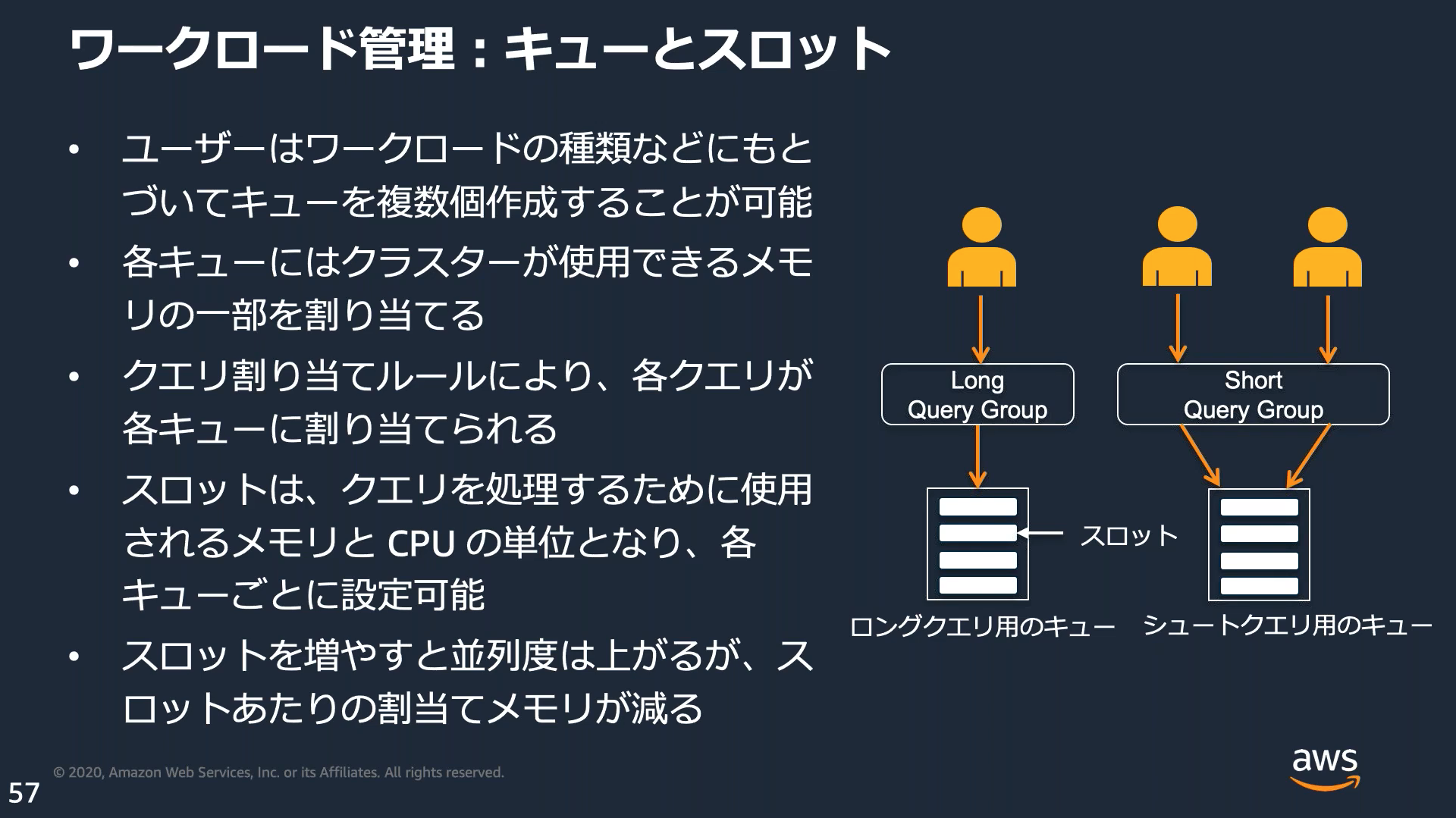
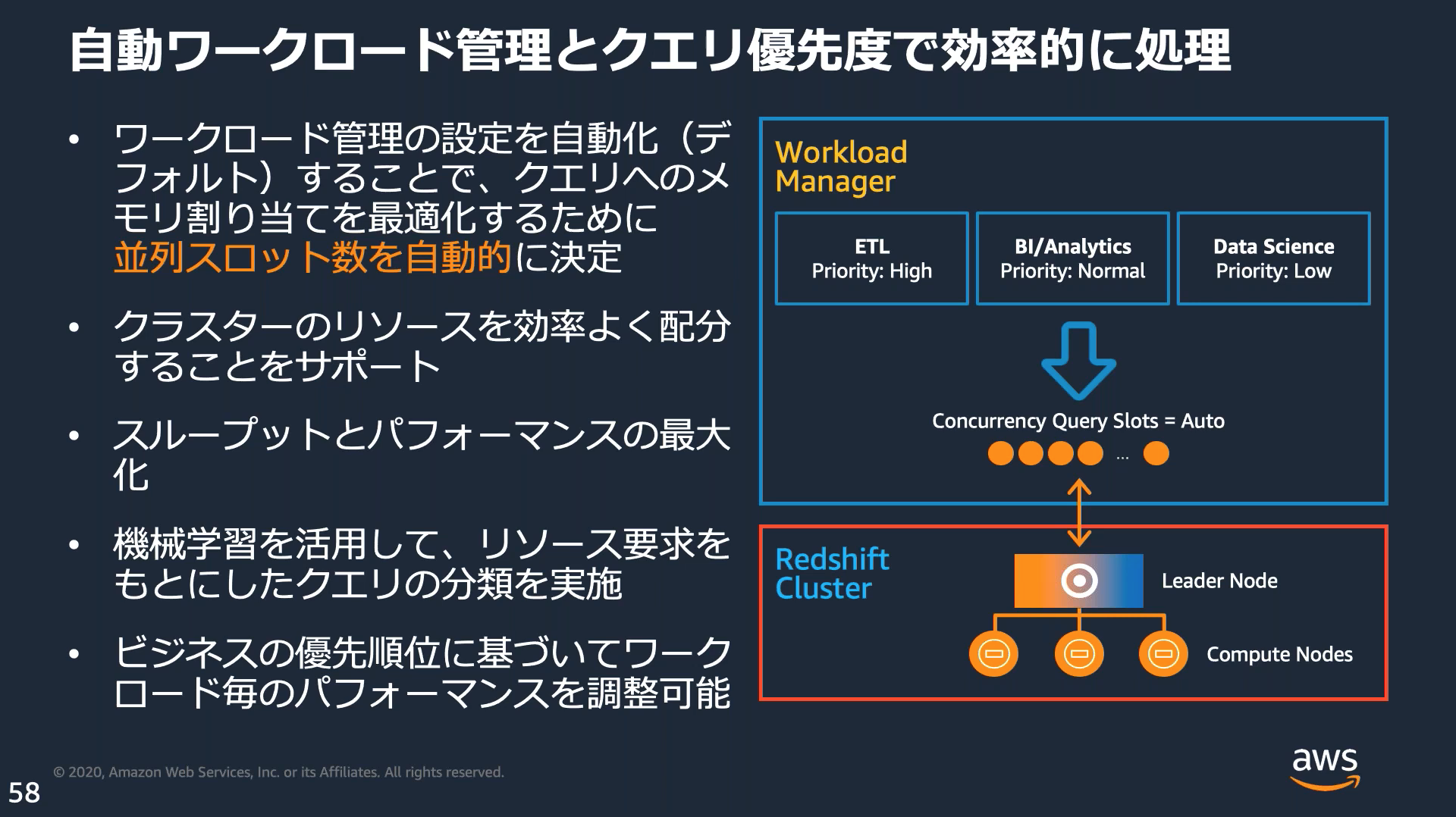
ワークロード管理(WLM:Work Load Management)
複数のワークロードが1つのクラスターを利用する際競合しないよう、自動でコントロールする機能がある。
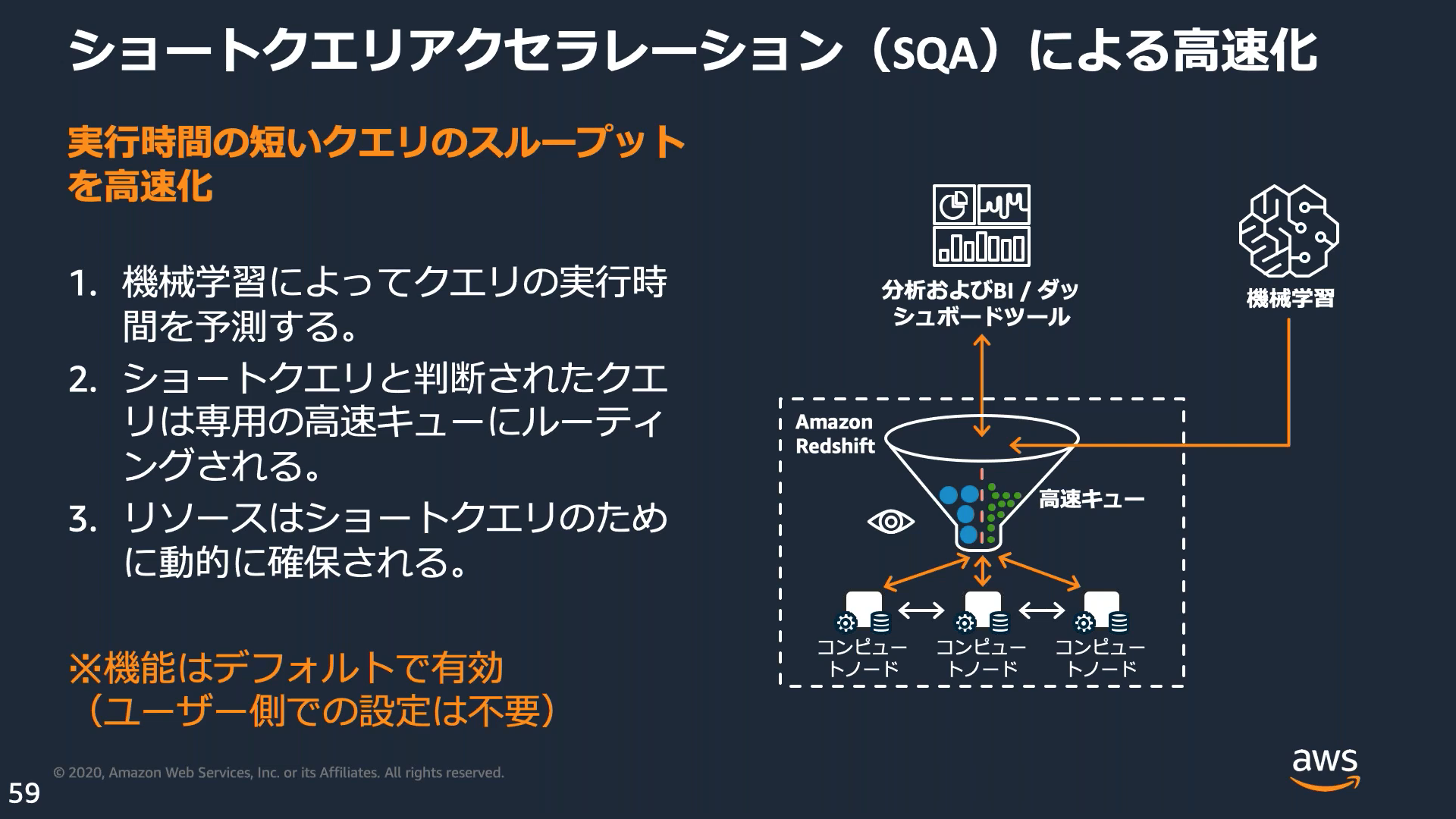
ショートクエリアクセラレーション(SQA)
SQAを有効にすると機械学習アルゴリズムを使用してクエリの実行時間を予測し、実行時間が短い一部のクエリを実行時間が長いクエリより優先する。
デフォルトのパラメータグループおよび新しいパラメータグループではデフォルトで有効になっている。
その他メモ
- 最大同時実行レベルは50
- キューは最大8
AWS Glue
ETLやデータからスキーマの自動生成、データのクリーニングなど、分析、機械学習、アプリケーション開発のためのデータ検出、準備、結合ができるサーバレスなデータ統合サービス。
GlueジョブやGlue DataBrew、Glueデータカタログなど複数の機能を含んでいる。
ETLジョブの種類
| 種類 | 概要 |
|---|---|
| Apache Spark | 最低2DPU必要、最小請求単位1分 |
| Sparkストリーミング | 1または0.0625DPUを使用、 最小請求単位1分 |
| Pythonシェル | 小規模から中規模の一般的なタスクに最適、Sparkより安価、最低2DPU必要、最小請求単位10分 |
ワーカータイプ
| タイプ | 概要 |
|---|---|
| Standard | このタイプを選択する場合は最大キャパシティー(実行時に割り当てることができるDPUの数)を指定する。50GBのディスクと2個のエグゼキュターがある。 |
| G.1X | このタイプを選択する場合はワーカー数を指定する。各ワーカーには1DPUが割り当てられ、ワーカーごとに1個のエグゼキューターがある。メモリを大量に消費するジョブに推奨。AWS Glue2.0以降のデフォルト。 |
| G.2X | このタイプを選択する場合はワーカー数を指定する。各ワーカーには2DPUが割り当てられ、ワーカーごとに1個のエグゼキューターがある。機械学習変換を実行するジョブに推奨。 |
| G.025X | このタイプを選択する場合はワーカー数を指定する。各ワーカーには0.25DPUが割り当てられ、ワーカーごとに1個のエグゼキューターがある。少量のストリーミングジョブに推奨。AWS Glue3.0のストリーミングジョブでのみ使用可能。 |
※1DPU = 4vCPU, 16GBのメモリ, 64GBのディスク
AWS Glue DataBrew
データのクレンジングや正規化など、分析用データの準備を自動化したり素早く行うためのサービス。
マネジメントコンソール上でインタラクティブにデータの変換を行ったり、作成した変換ジョブをStep FunctionsのStepに組み込むなどができる。

Glue ML Transforms(機械学習変換)
機械学習タスクを実行し、潜在的重複(インクリメンタルマッチ)の検出などデータをクリーニングするために利用できる。
その他メモ
- AWS Glue Schema Registryは、データストリームスキーマを一元的に検出、制御し、発展させることができる。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/schema-registry.html - ワークフローを利用すると依存関係のある複数のジョブを管理できる
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/orchestrate-using-workflows.html
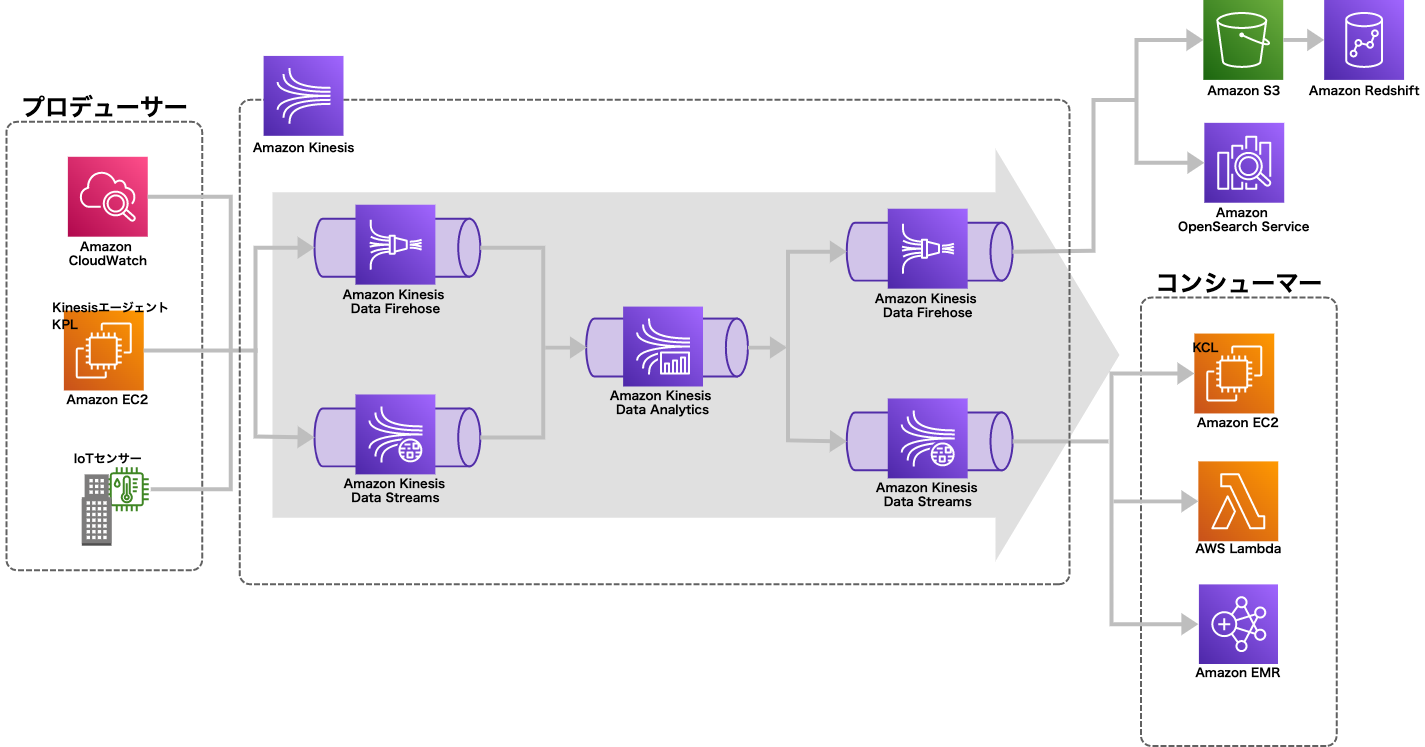
Amazon Kinesis
モバイルアプリやIoT機器などからのストリーミングデータを扱うためのサービス群

■Kinesisプラットフォームの構成イメージ
Amazon Kinesis Data Streams
シンプルなストリームを扱うサービス、ストリームに出し入れする(プロデューサー&コンシューマー)その他サービスと組み合わせて利用する。
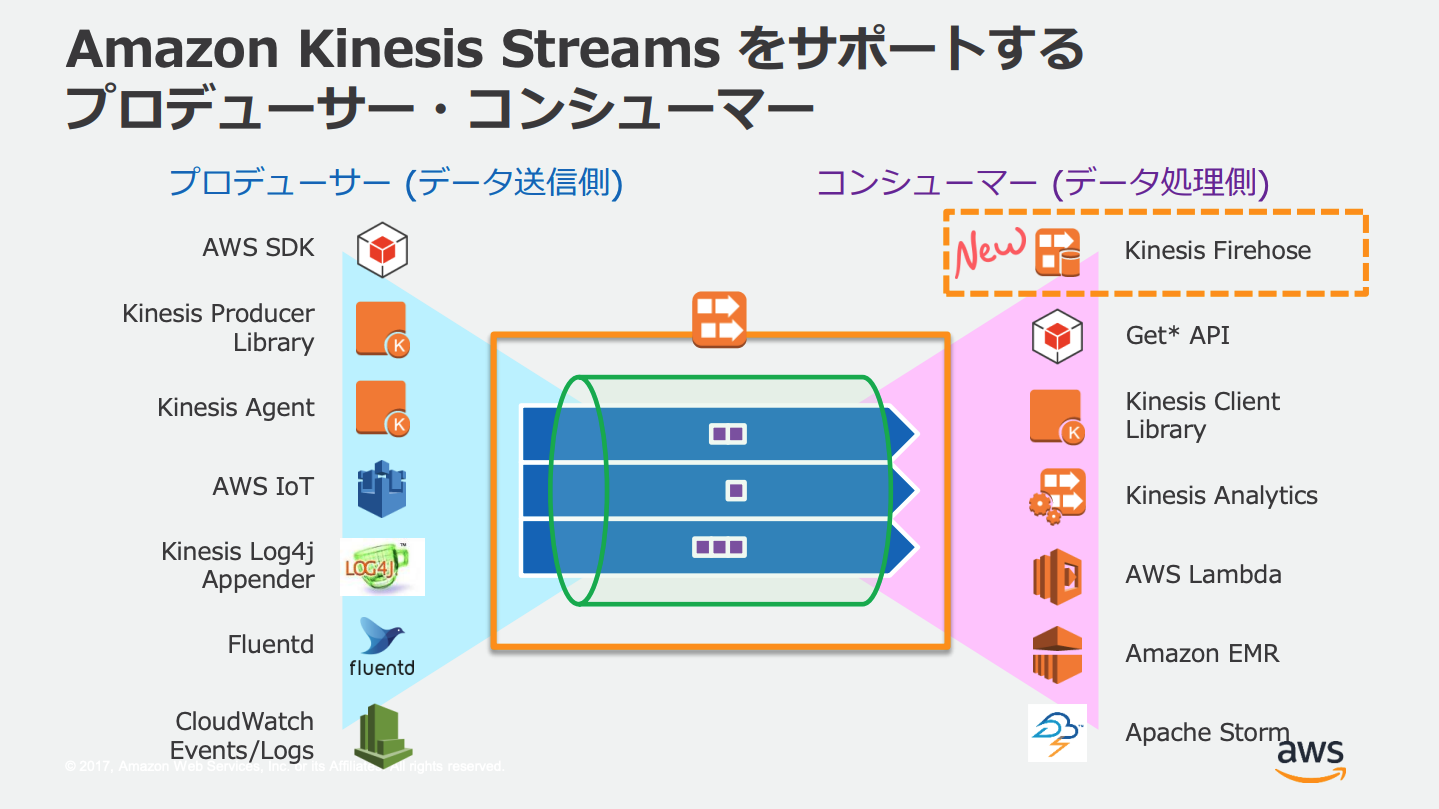
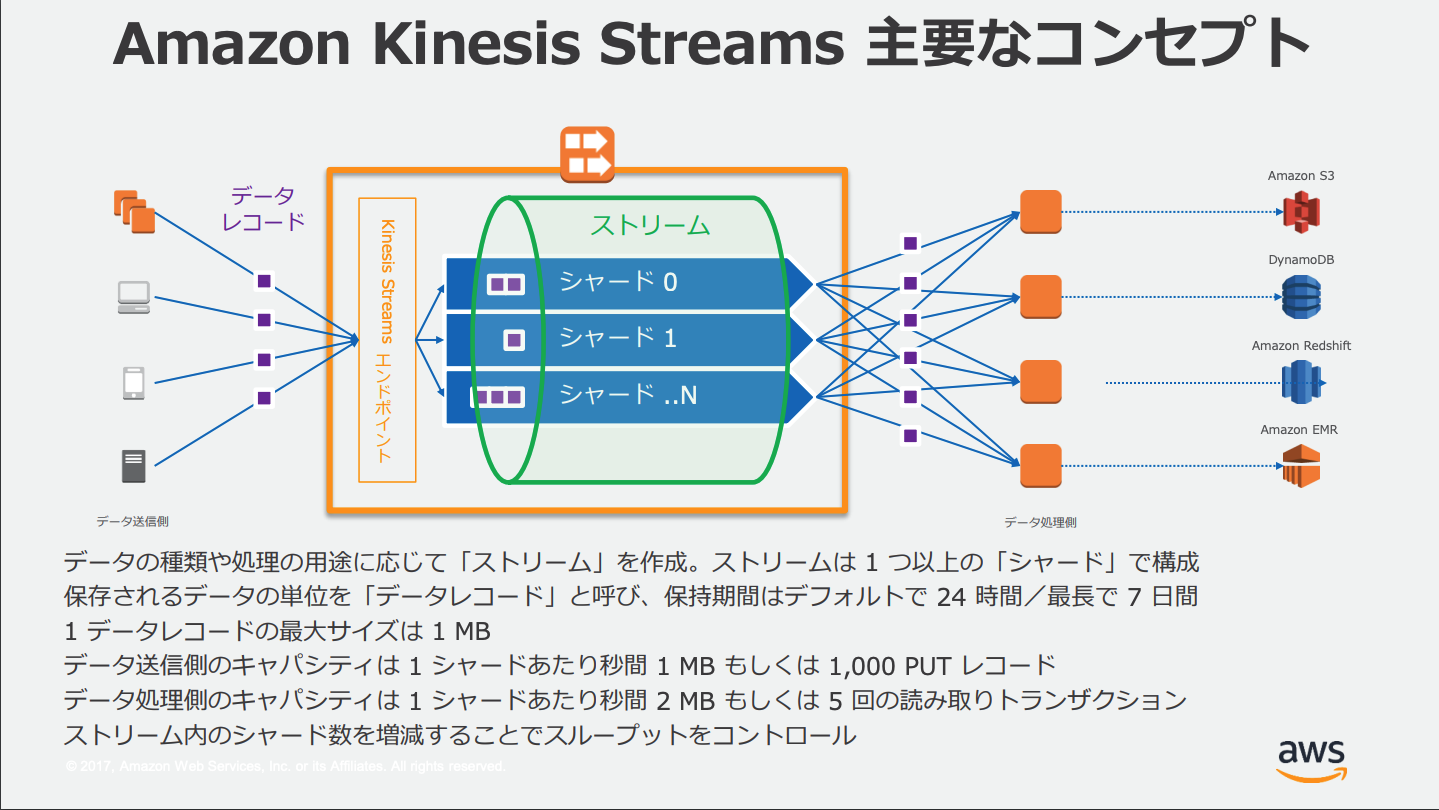
ストリームのタグ付け
Kinesis Data Streamには「タグ」として独自のメタデータを付与することができる。
タグはキーと値のペアの形でストリームに定義する。
拡張ファンアウト
Kinesis Data Streamsでは拡張ファンアウトと呼ばれる機能がある。これを使用することでコンシューマーは、シャードごとに毎秒最大2MBのレコードを受信できる。これによりスケーラビリティとパフォーマンスを上げられる。
KPL/KCL
- Kinesis Producer Library(KPL): Kinesisストリームへデータを出力するアプリケーションの開発用ライブラリ
- Kinesis Client Library(KCL): Kinesisストリームからデータを取得し処理するアプリケーションの開発用ライブラリ
通常のKPL/KCLはJava用のライブラリだが、Lambda+Python用の「Kinesis Producer LibraryAWS Lambda」もある
KPLの設定
KPL利用時に設定できる値がいくつかある。
この値を変更することで動作を調整できる。
例えば、RecordMaxBufferedTimeを高い値にするとパッケージ合計サイズが大きくなり、スループットが向上する。設定値を変更する場合KPLアプリケーションの再起動が必要。
KinesisProducerConfiguration config = new KinesisProducerConfiguration()
.setRecordMaxBufferedTime(3000)
.setMaxConnections(1)
.setRequestTimeout(60000)
.setRegion("us-west-1");
final KinesisProducer kinesisProducer = new KinesisProducer(config);
KinesisProducerConfiguration config = KinesisProducerConfiguration.fromPropertiesFile("default_config.properties");
RecordMaxBufferedTime = 100
MaxConnections = 4
RequestTimeout = 6000
Region = us-west-1
KPL(Kinesis Puroducer Library)PutRecords操作は書き込み失敗したレコードを自動的にKPLバッファーに追加し、再試行できるようにする
KCLのリーステーブル
KCLはKinesis Data Streamsアプリケーションごとに一意のDynamoDBテーブルを作成する。
これを利用してKCLコンシューマアプリケーションで処理されたシャードを追跡する。
読み取りの途中で失敗した場合は、新しいワーカーが失敗したレコードから再開できる。

順序保証
PutRecordsで複数のレコードを送信した場合、1つのレコードが失敗しても後続の処理は停止しない、そのため順序が保証されない。ストリームの書き込みと読み込みの順序を保証する場合PutRecordを使用する。
IoT機器からのストリーム
IoT機器からKinesisストリームへの出力はAWS IoT(サービス)を利用する。
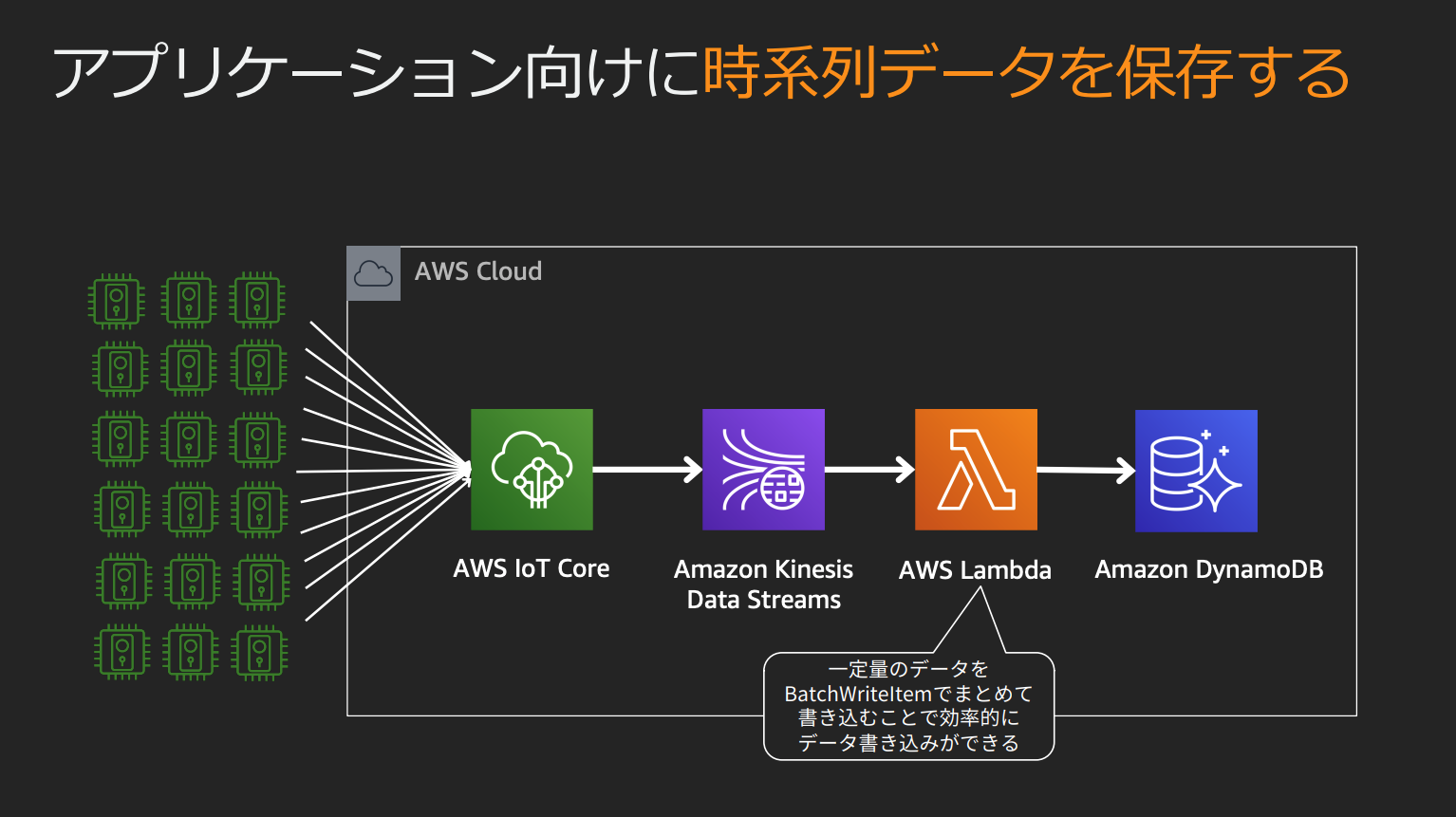
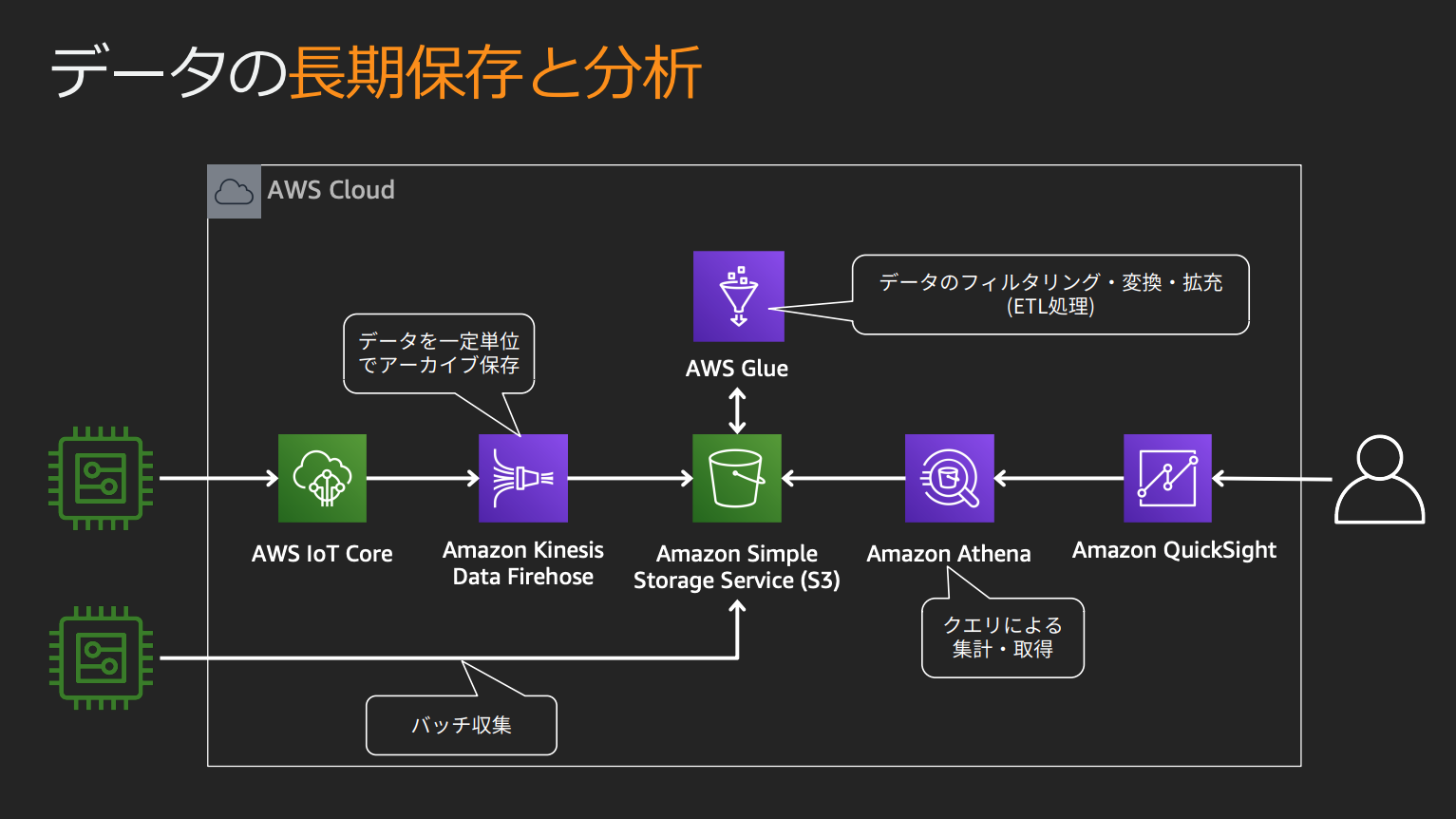
Amazon Kinesis Data Firehose
Kinesisストリームは
- S3
- Redshift(S3経由)
- Amazon ES
- HTTPエンドポイント
- その他サードパーティのSaaS
などに直接出力することはできない、ストリームを受け取って変換するためにKinesis Data Firehoseを間に挟む必要がある。
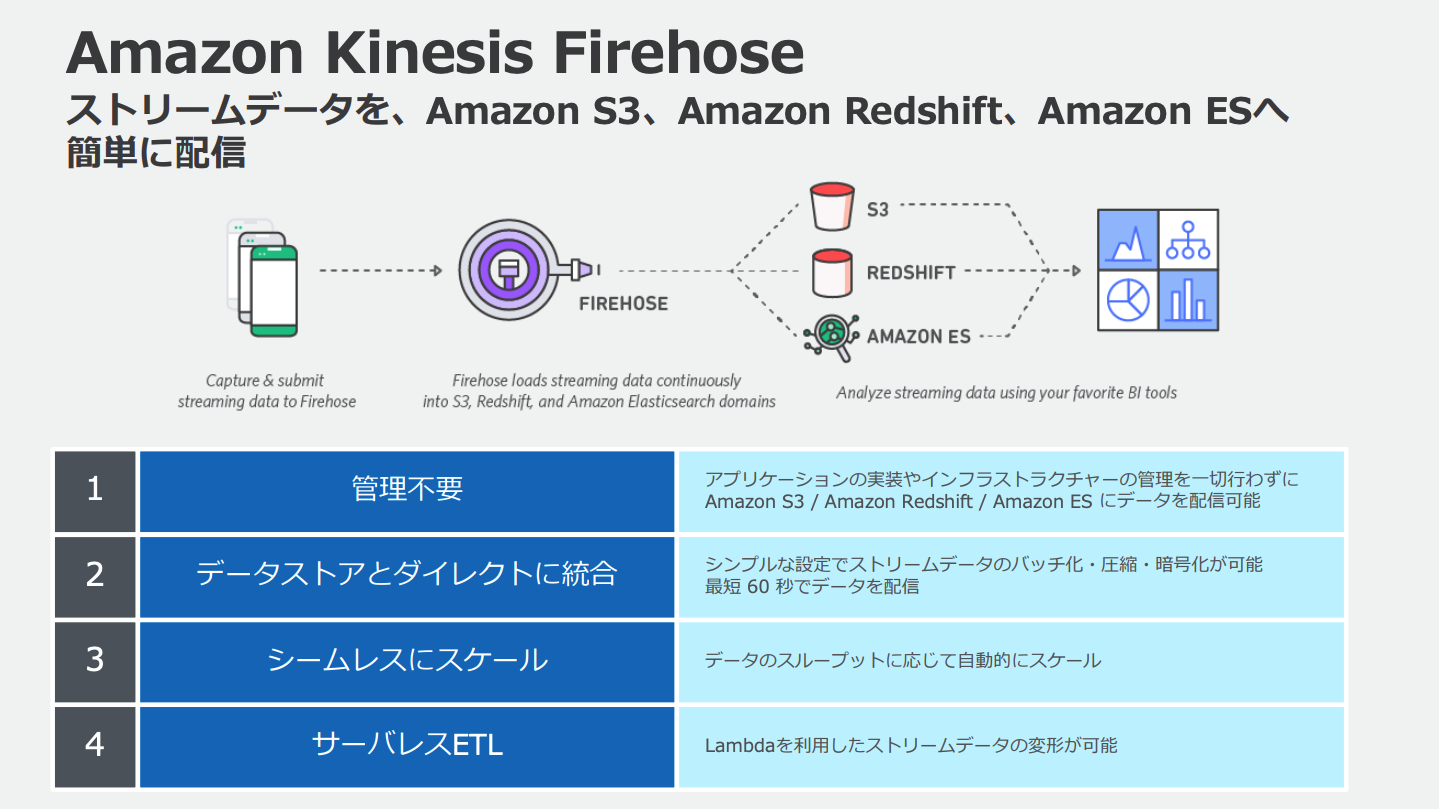
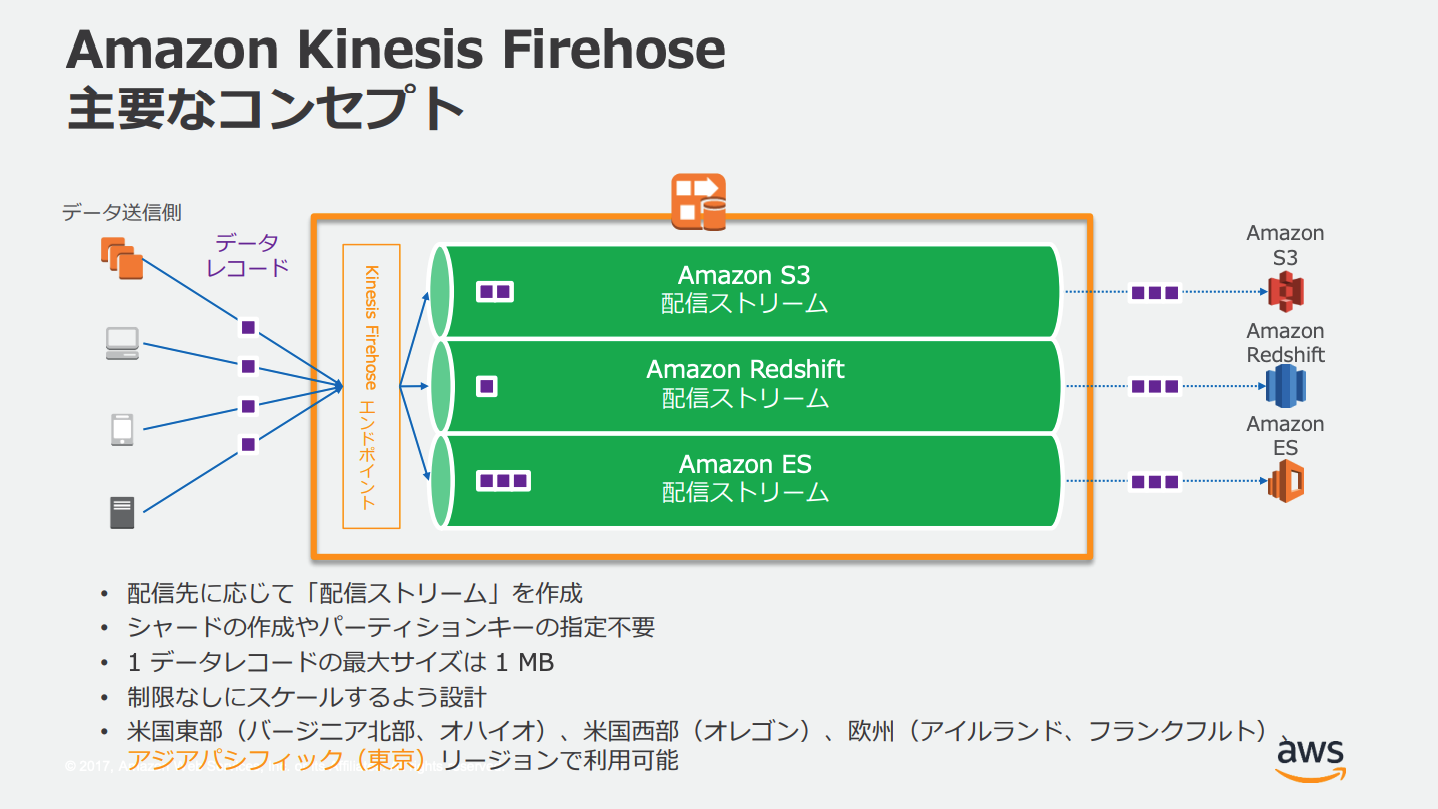
Kinesis Data FirehoseではLambda関数によるデータの変換を設定することができる。
LambdaはKinesis Data Firehoseに変換されたデータを返し、返されたデータをKinesis Data Firehoseが出力先に出力する。この際変換前のデータも出力するよう設定することもできる。
Kinesis Data Firehoseは複数のAZに冗長化されている。
Amazon Kinesis Data Analytics
ストリームに対して実行するSQLを定義し、SQLにより分析や変換されたストリームを出力する。
リアルタイム分析用サービス。
入力元と出力元はいずれもKinesis Data Streams or Kinesis Data Firehose。ストリームとストリームの間に挟む。
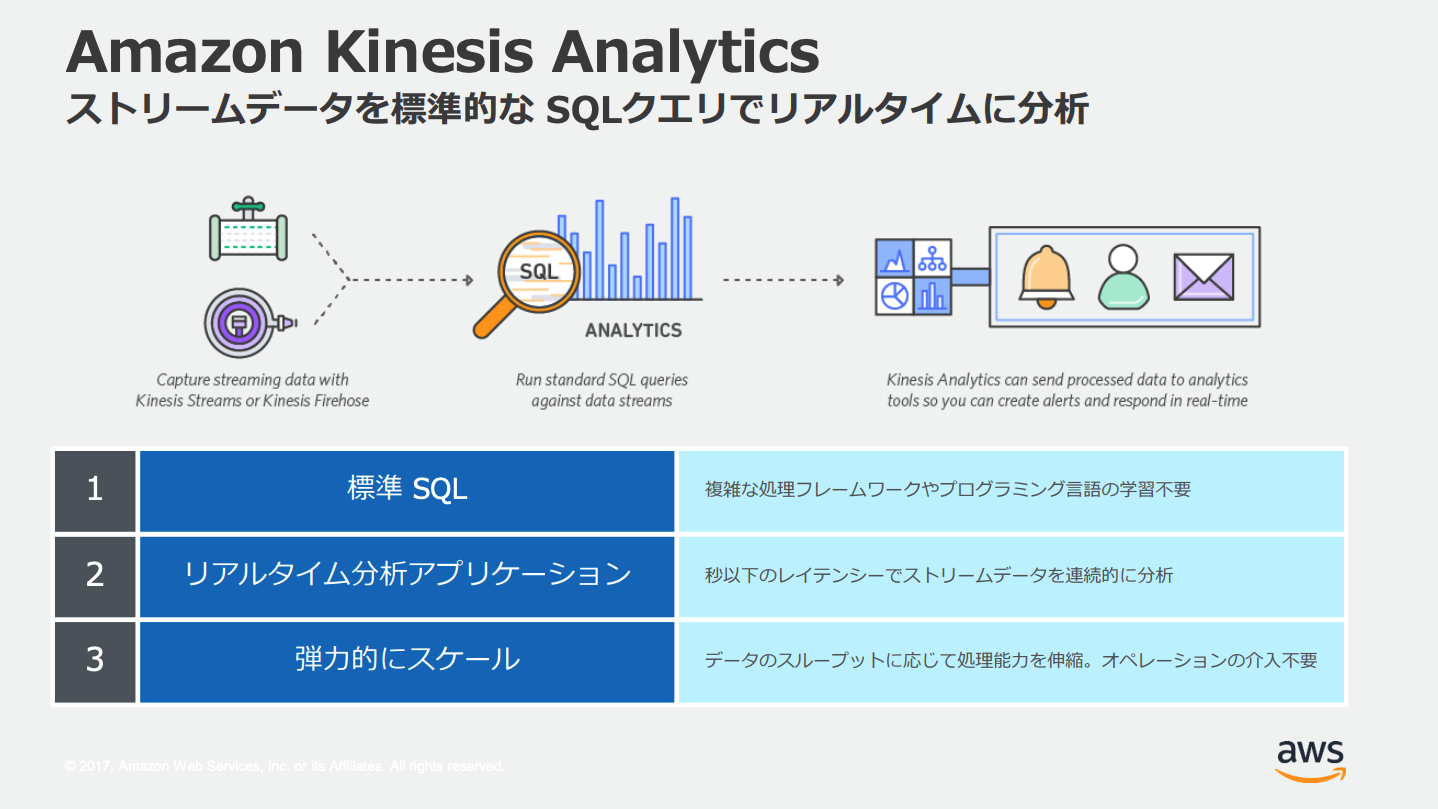
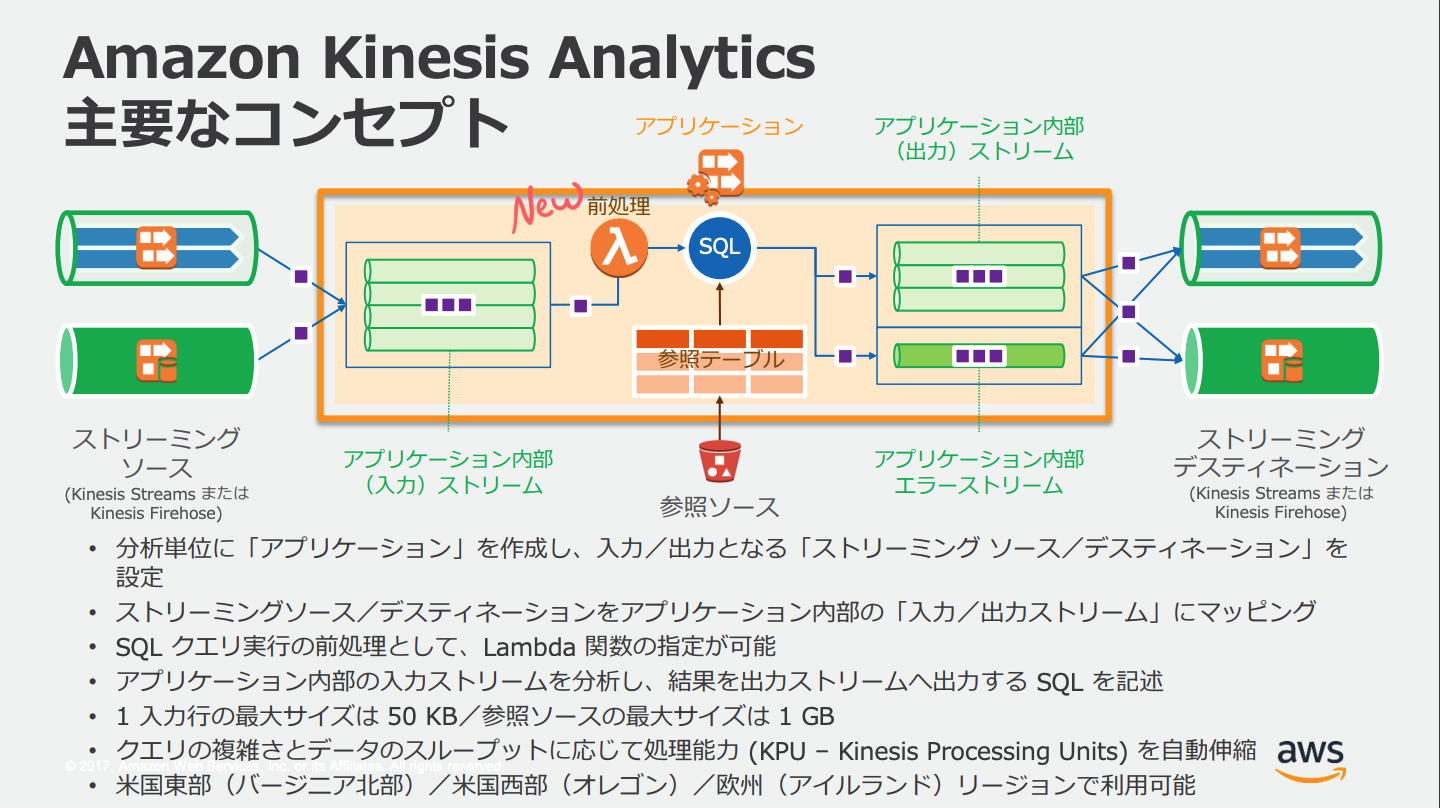
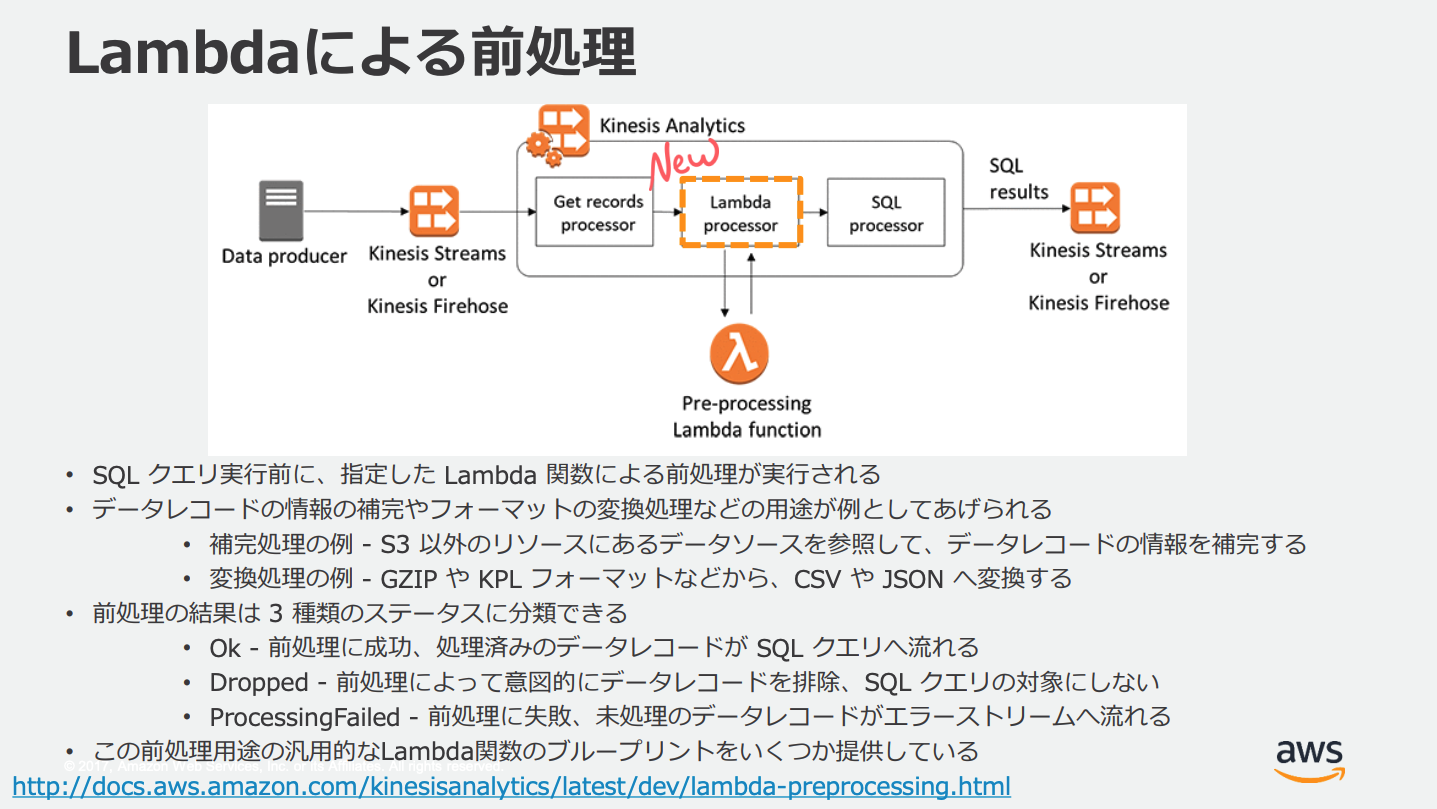
Lambdaによる前処理
Kinesis Data AnalyticsではSQL実行の前にLambdaによる変換やデータ補完などが設定できる。
ウィンドウクエリ
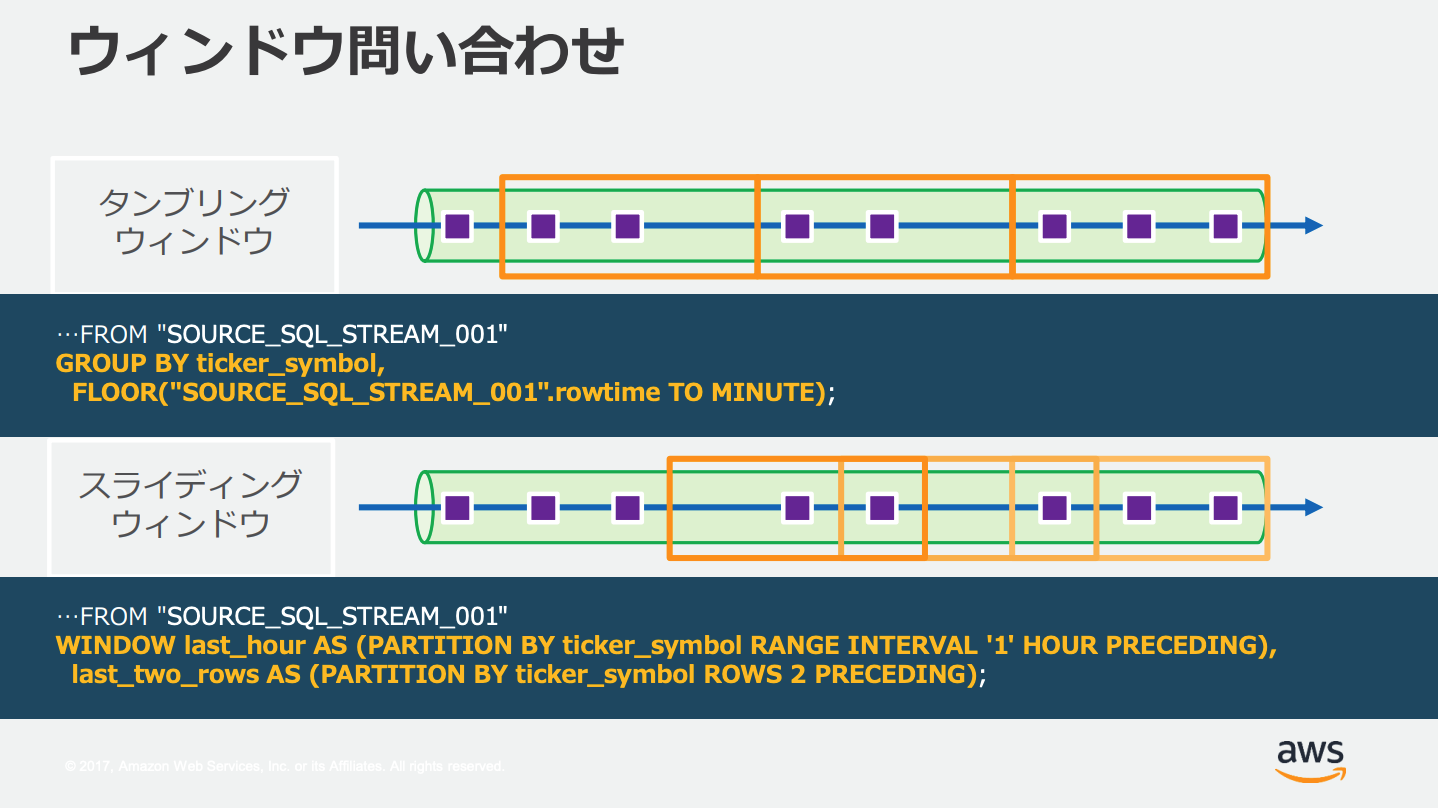
Kinesis Data Analyticsでは常に流れてくるストリームに対して、時間と行の条件によって取得する範囲を指定する、これを「ウィンドウクエリ」や「ウィンドウSQL」という。
AWSでは3つのウィンドウタイプがサポートされている。
| ウィンドウタイプ | 概要 |
|---|---|
| Stagger(ずらし)ウィンドウ | 一貫性のない時間に届くデータに対して、時間ベースの集計をする |
| タンブリング(重複しない)ウィンドウ | 範囲が重複しない固定の周期で集計する |
| スライディングウィンドウ | 固定サイズのウィンドウを時間とともにスライドする |
スキーマエディタ
Amazon Kinesis Data Analytics アプリケーションの入力ストリームのスキーマはコンソールから定義できる。指定できる形式は以下の3種類。
- JSON入力ストリームのJSONPath式
- カンマ区切り値 (CSV) 形式の入力ストリームの列番号
- アプリケーション内データストリームの列名とSQLデータ型
IoT Core
IoTデバイスとAWSサービスを統合するためのフルマネージドサービス
AWS IoTルール
IoTデバイスから受け取ったデータに対し、以下のAWSサービスへデータのPUTや実行を行える。
- DynamoDB
- S3
- SNS
- SQS
- Lambda
- Kinesis Data Stream
- Kinesis Data Firehose
- OpenSearch Service
- CloudWatchメトリクス
- CloudWatchアラーム
- Step Functions
- Timestream
- AWS IoT Analytics
- AWS IoT Events
- AWS IoT SiteWise
その他にもAWS IoTによるフィルタリングやHTTPエンドポイントへのリクエストなどもできる。
Amazon CloudSearch
フルマネージドの検索エンジンサービス、CSV/JSON/XMLなどのデータの集まりをアップロードし、HTTP/HTTPSのエンドポイントにリクエストすることで検索を実行できる。
データ量やリクエストトラフィックに合わせて自動的にスケーリングする。
要素
CloudSearchに登場する要素たち
| 要素 | 概要 |
|---|---|
| 検索ドメイン | データを管理/保管する場所(RDBでいうところのDBサーバ) |
| コーパス | 検索対象のデータのコレクション(集まり) |
| インデックス | ひとかたまりのデータスキーマ(RDBでいうところのテーブル)ドキュメントから自動生成できる |
| ドキュメント | ページや投稿などの1項目(RDBでいうところのレコード) |
| ファセット | 絞り込みとフィルタ処理のためのカテゴリを表すインデックスフィールド |
分析スキーム
分析スキームを個別に設定し、下記の検索オプションを追加することができる。
| オプション | 概要 |
|---|---|
| アルゴリズムによるステミング | アルゴリズムによるステミング実行レベルを指定 ※ステミング=異なる語形でも意味が同じワードを語幹でマッチングさせる(swims, swimmingどちらで検索しても双方にヒットさせるなど) |
| ステミングディクショナリ | アルゴリズムによるステミングの結果を辞書でオーバーライドする |
| ストップワード | インデックス作成時及び検索中に無視する単語 |
| シノニム | 異なるワードで同じ意味の単語を指定して同じ検索結果を得られるようにする |
AWS Lake Formation
S3やRDB,NoSQLからS3へデータを読み込み、データレイクを構築/管理できるサービス。
アクセス管理された中央データストアを作成できる。
Lake FormationはGlueの機能を多数利用しており、Glueの拡張機能とも言える。
用語
Lake Formationの用語
| 用語 | 概要 |
|---|---|
| データレイク | Lake Formationによって管理される永続データ |
| データアクセス | IAMポリシーによりアクセスは制御される |
| ブループリント | データレイクにデータを簡単に取り込めるようにするデータ管理テンプレート |
| ワークフロー | 一連の関連するAWS Glueのジョブ、クローラ、およびトリガーのためのコンテナ |
| Data Catalog | 永続的なメタデータストア |
| 基盤となるデータ(Underlying Data) | Data Catalog テーブルがポイントするソースデータまたはデータレイク内のデータ |
| プリンシパル | IAMユーザーもしくはロール、またはADユーザー |
| データレイク管理者 | あらゆるData Catalogリソースまたはデータロケーションに対する許可を任意のプリンシパル(自分自身を含む)に付与できるプリンシパル |
ブループリント
ワークフローはGlueまたはブループリントから作成できる
ブループリントのタイプは以下
| タイプ | 概要 |
|---|---|
| Database snapshot(データベーススナップショット) | すべてのテーブルからのデータを、JDBC ソースからデータレイクにロードまたは再ロードします。除外パターンに基づいて、一部のデータをソースから除外することもできる |
| Incremental database(増分データベース) | 以前に設定されたブックマークに基づいて、新しいデータだけを JDBC ソースからデータレイクにロードする |
| Log file(ログファイル) | AWS CloudTrail、Elastic Load Balancing ログ、Application Load Balancer ログなどのログファイルソースからのデータを一括でロードする |
Amazon Forecast
統計アルゴリズムと機械学習アルゴリズムを使用して、非常に正確な時系列予測を実現するフルマネージドサービス。
Amazon Athena
S3のJSON, CSV, Parquetなどのファイルに対し、SQLを実行することができる。
また、データソースコネクタを作成しフェデレーテッドクエリを利用するとCloudWatch LogsやDynamoDB、RDS、DocumentDB、OpenSearchなどに直接クエリすることもできる。複数のデータソースのデータを結合することもできる。
ワークグループ
ワークグループは、ユーザー、チーム、アプリケーション、またはワークロードを分離するための機能。
ワークグループごとにクエリ結果の出力先、暗号化設定、コスト、データ量の上限などを個別に設定できる。
その他メモ
- Parquetは列ごとの圧縮が可能なため、S3から読み取られるバイト数を減らしクエリのパフォーマンス改善が期待できる。データの分割もできる。
- Glacierにはクエリできない。
- S3のSSEが有効な場合、異なるリージョンのAthenaからクエリはできない(複合権限がないため)
- バケットのバージョニングが有効な場合、最新バージョンにしかクエリできない。
- 列形式でビューを作成した場合、出力フォーマットはParquetまたはORCとなる。
Amazon QuickSight
フルマネージドのBI(ビジネスインテリジェンス)サービス。
AWS内外の複数のデータソースの情報を単一のダッシュボードとして視覚化(グラフや表に)することができる。
データソース
QuickSightで指定できる主なデータソースは以下
- Amazon RDS
- Amazon Athena
- Amazon OpenSearch Service
- Amazon Redshift
- Amazon S3
- AWS IoT Analytics
- Timestream
DynamoDBをデータソースにはできない
SPICE
データソースから読み込みの多いデータを取り込んでおくことで応答速度を上げるためのインメモリDB
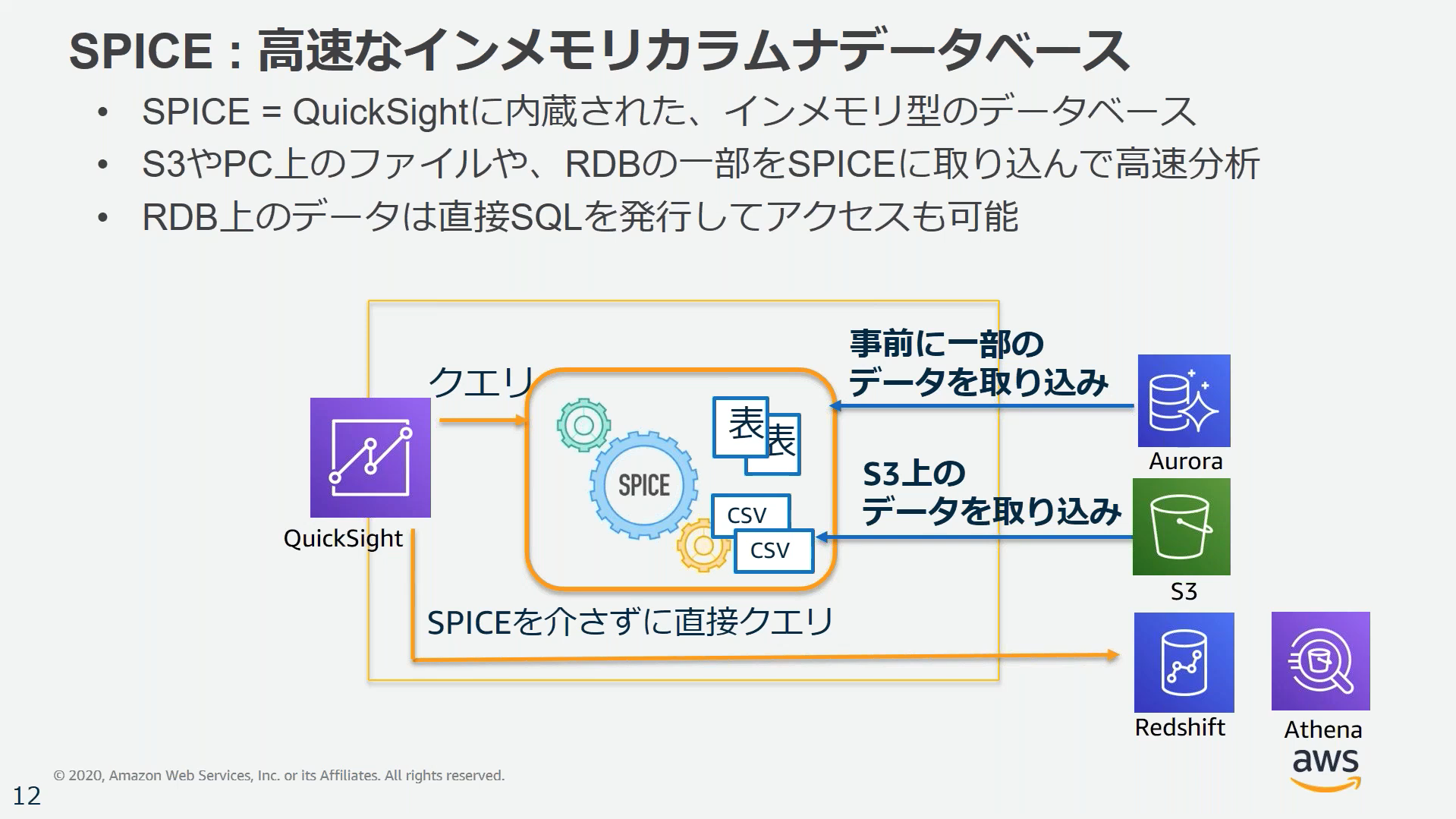
ファイルデータのインポート
S3またはオンプレのファイルをデータソースとしてインポートできる。
このとき、JSONやCSV/TSVだけでなく、Excelファイル(.xlsx)やzip/gzip圧縮されたファイルもそのまま読み込める。
ML(機械学習)インサイト
QuickSightには機械学習を使用して、データ内の隠されたインサイトや傾向をダッシュボードに反映する機能がある。
機械学習インサイトは以下の3つの主要機能を持つ。
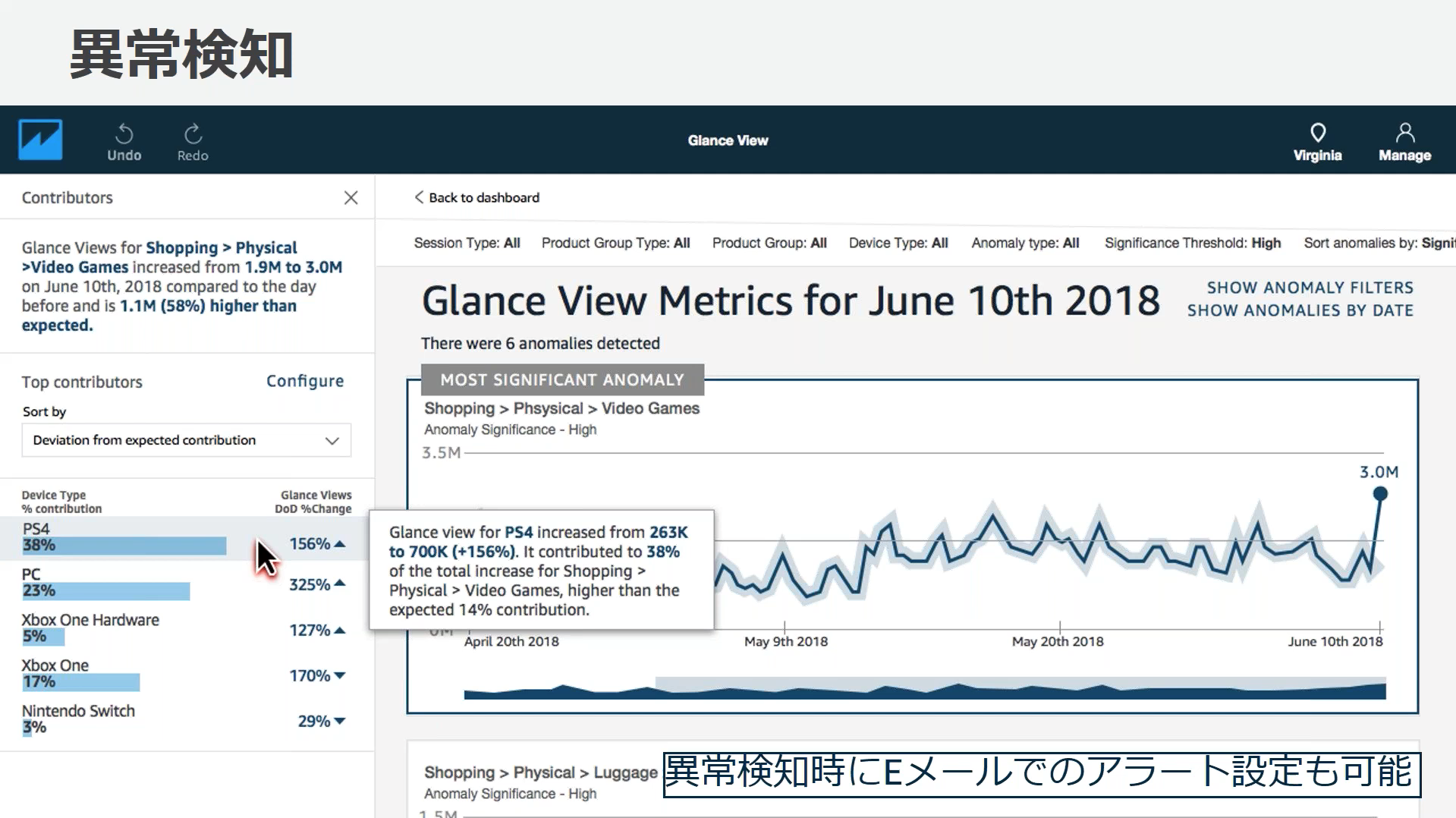
- MLを使用した異常検出: データを継続的に分析し異常 (外れ値) を検出
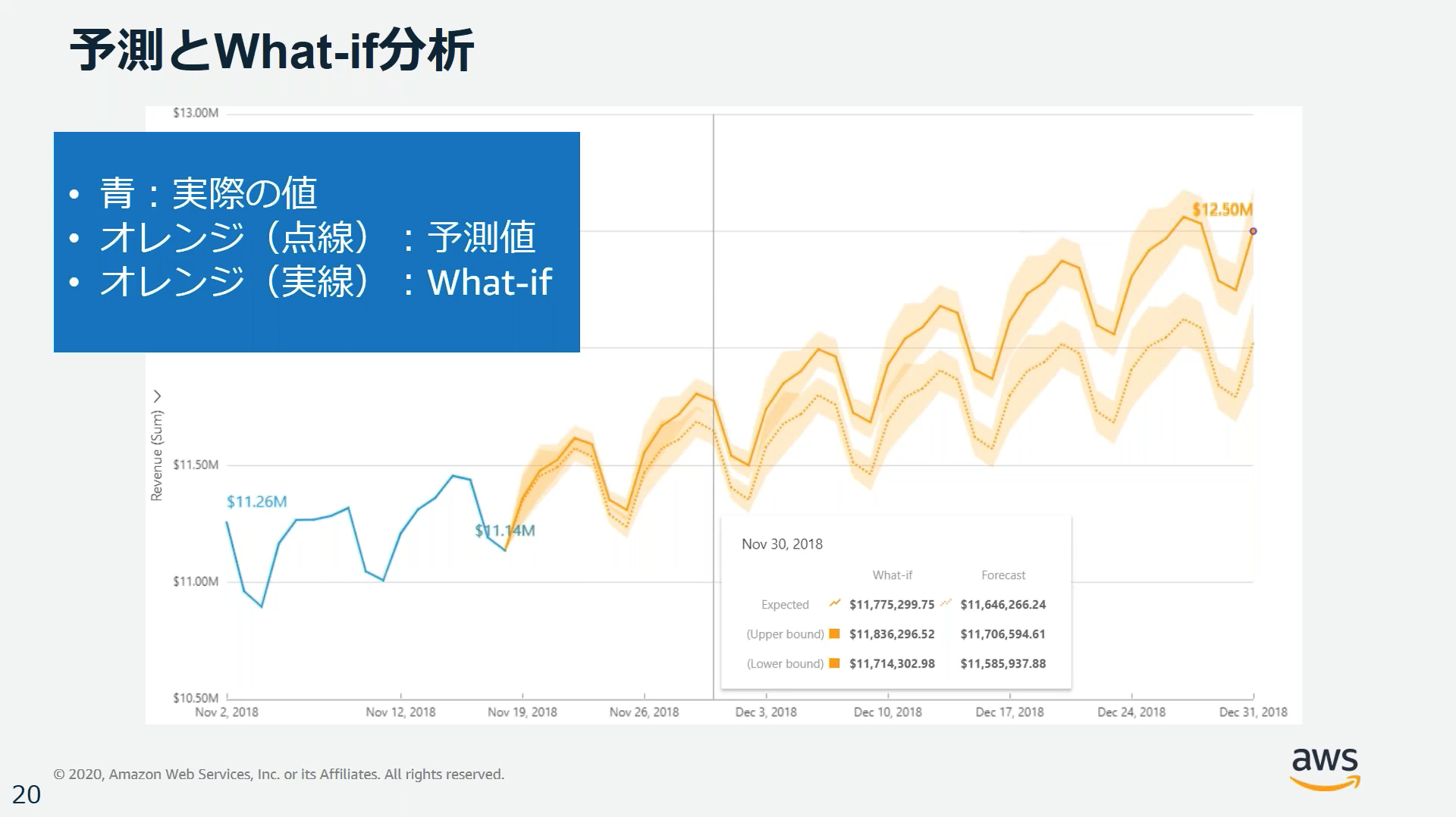
- MLを使用した予測: 内蔵の機械学習Random Cut Forestアルゴリズムにより、外れ値を除く季節性や傾向の検出、欠損値の入力など、複雑な現実のシナリオを自動的に処理し変化を予測する。
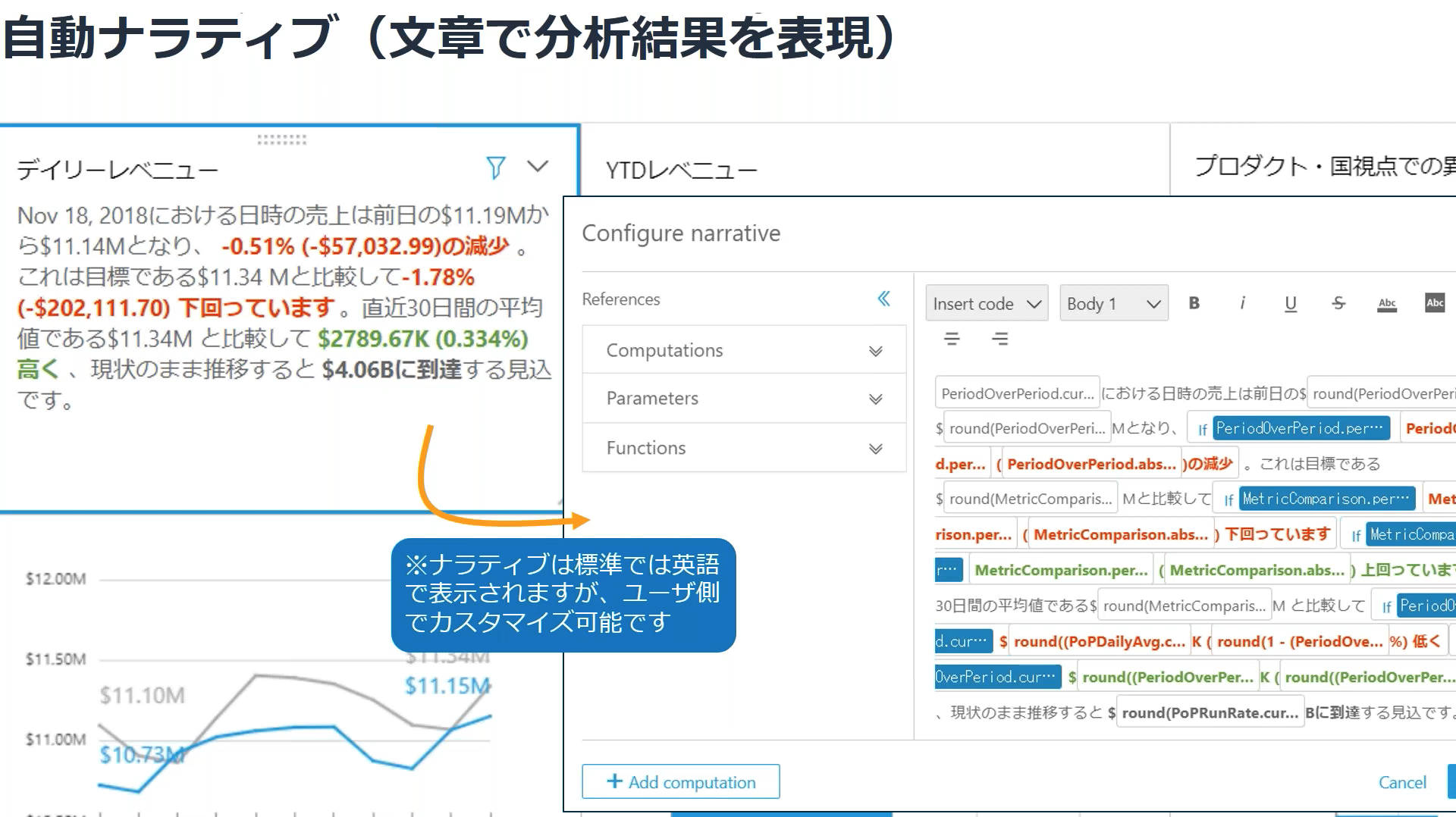
- 自動ナラティブ(説明文): ダッシュボードに自動的に生成した説明文を追加してくれる。
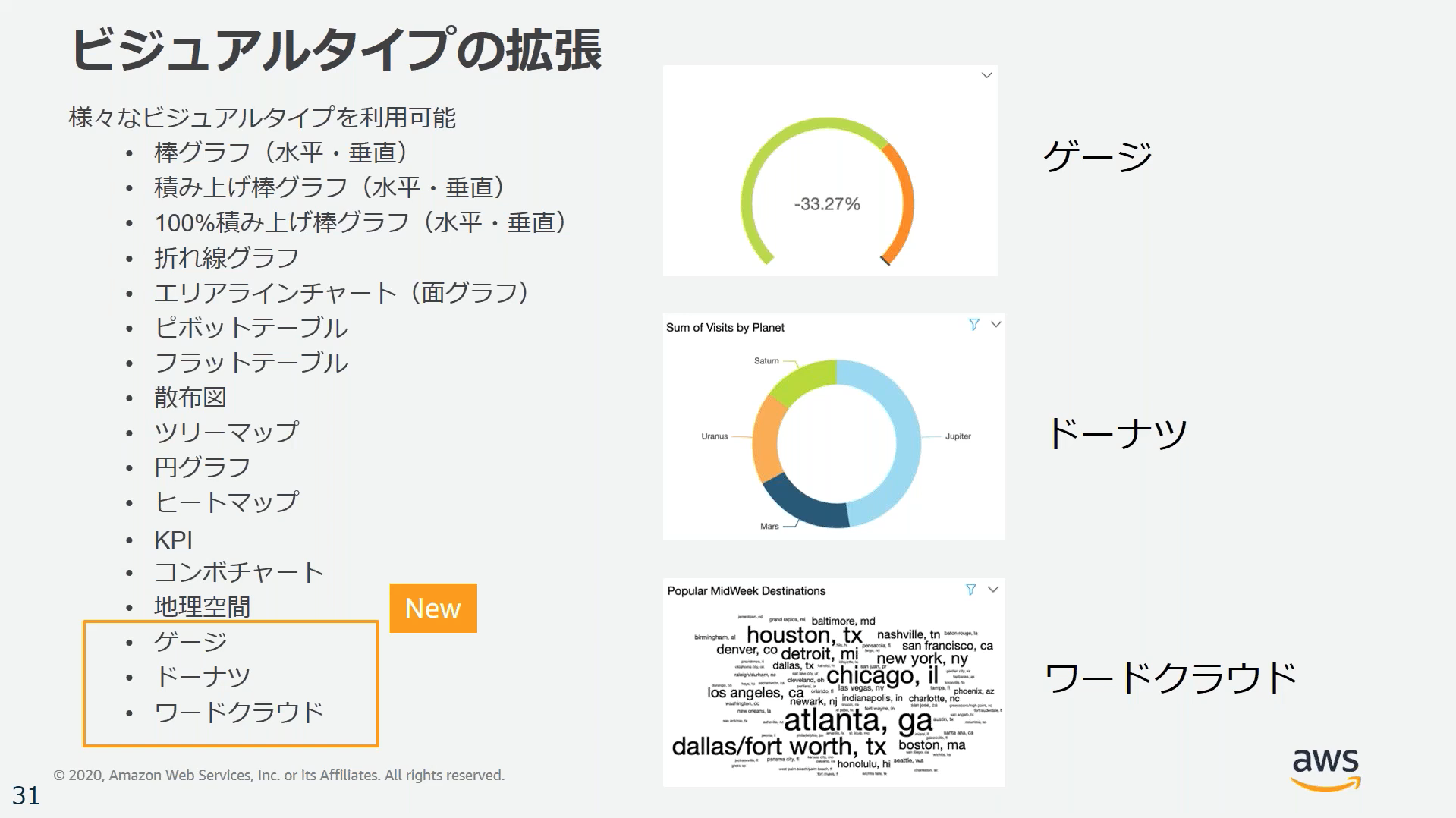
ビジュアルタイプ
ビジュアルにはさまざまなタイプのグラフなどを表示できる。
Presto
オープンソースの分散型SQLクエリエンジン、高速な分析クエリを実行でき、RDB/NoSQLともにサポートしている。
EMR, S3, RDS, Redshiftなどにクエリできる。
EMRとPrestoを利用することでビッグデータの視覚化ができる。
AWS DataSync
以下の3つのデータ転送を行うことができる
- オンプレとAWS間
- AWSストレージサービス間
- クラウドストレージとAWS間
オンプレからの移行先に指定できる主なサービスは以下の3つ
- S3
- EFS
- Amazon FSx
その他サポートされる送信元と宛先の一覧は以下のページ参照
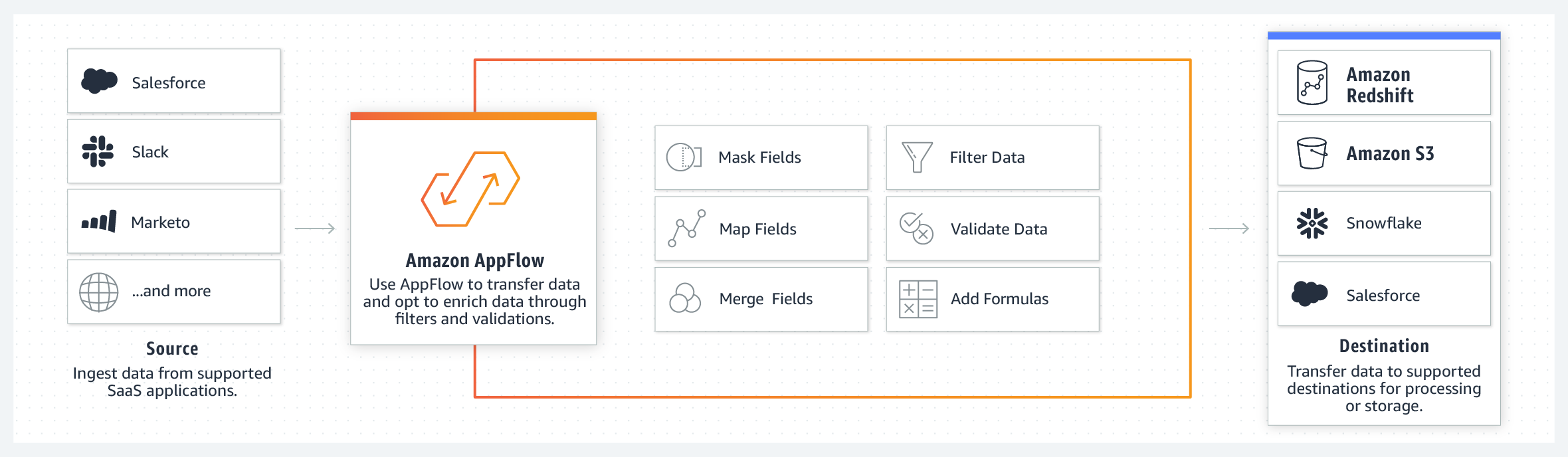
AppFlow
サードパーティのSaaSアプリケーションとAWSサービスの間でデータを転送する。
- Salesforce
- Slack
- Datadog
- Google Analytics
などのSaaSと
- S3
- Redshift
などのAWSサービスが対象。
その他メモ
- 複数バケットへの転送も可能
- データ移行時にS3 Transfer Accelerationはサポートしていない
Amazon Opensearch Service(Elasticsearch Service)
OpenSearch(旧Elasticsearch)はログやクリックストリームなどの分析などに利用できるOSSの分散型全文検索エンジン。
Amazon Opensearch ServiceはAWSによりマネージドでOpenSearch環境を構築管理できるようにしたもの。
Amazon OpenSearchでドメインを作成すると、OpenSearchと連携できるBIツールのKibanaも自動的に立ち上がる。
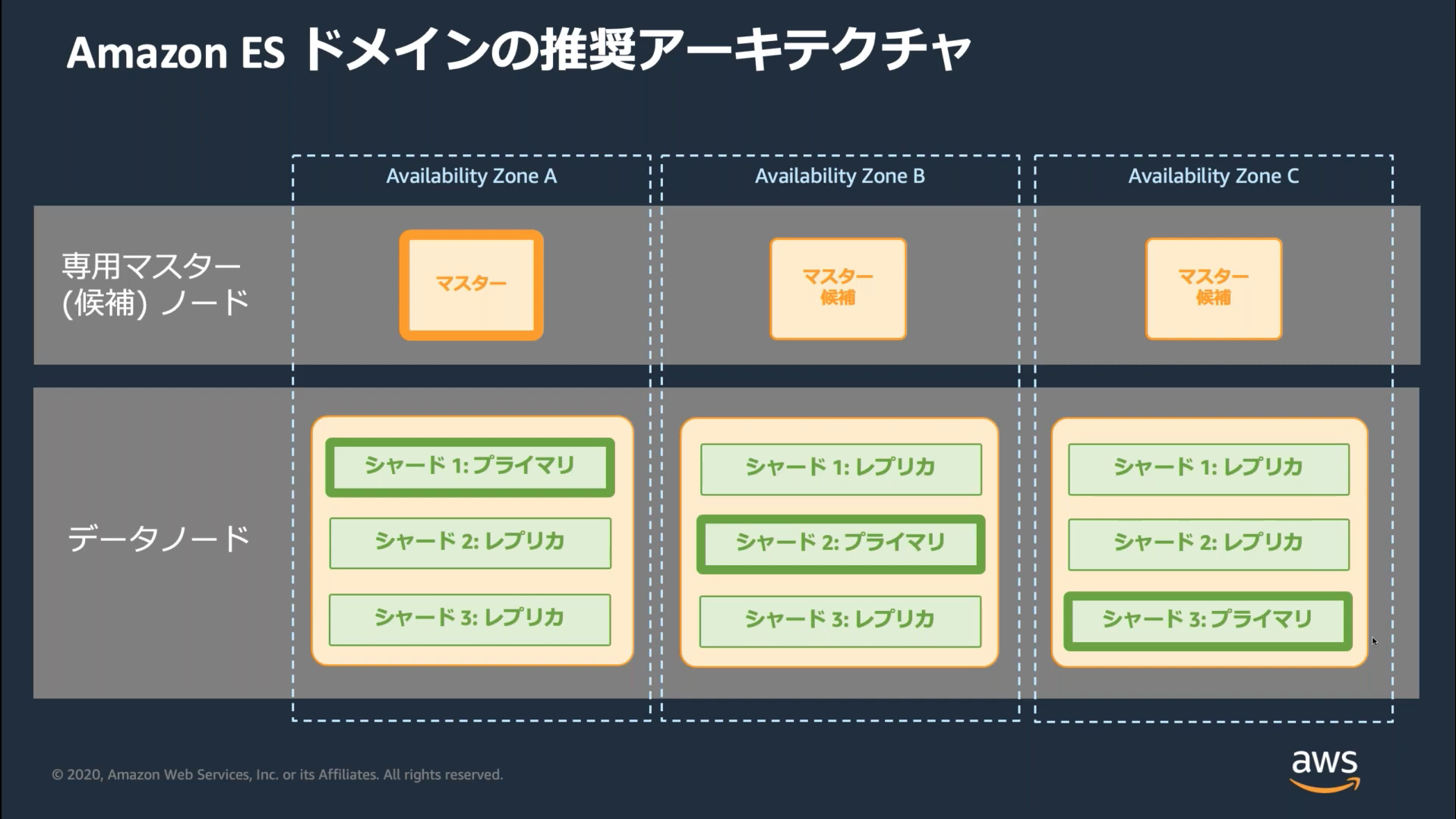
Opensearchでは分散型の設計思想として3つのマスターノードを用意することが推奨される。
シャード数の最適化
シャード数 = インデックスサイズ / 30GB で計算する
例えばインデックスが5GBの場合1以下なので切り上げ1、70GBの場合切り上げ3
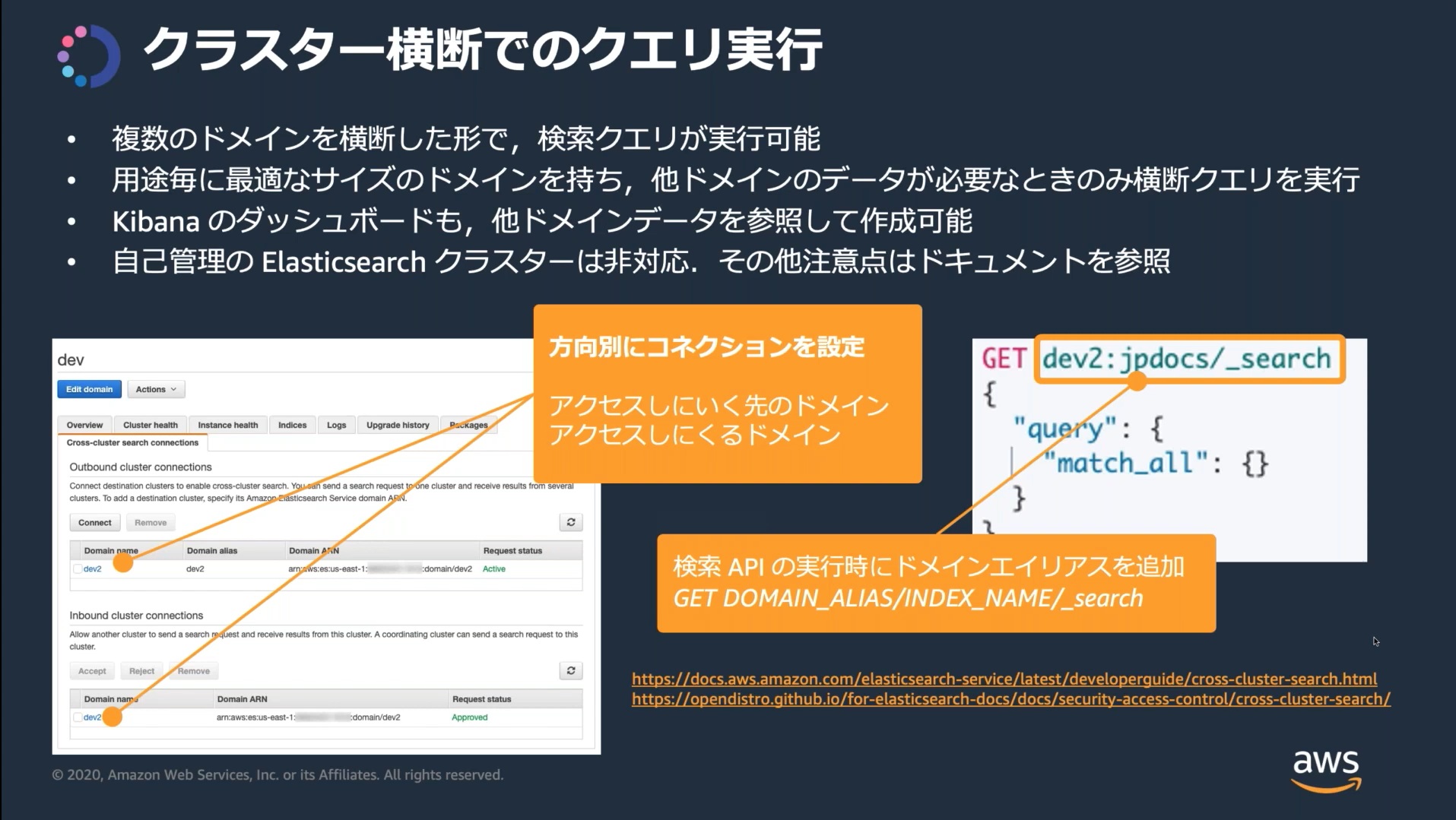
クラスター間検索
クラスター間検索を利用すると複数のドメインにまたがってクエリと集計を実行できる。
検索を実行するソースドメインからターゲットドメインへの接続を設定する。
双方向に検索したい場合は2つの接続を設定する必要がある。

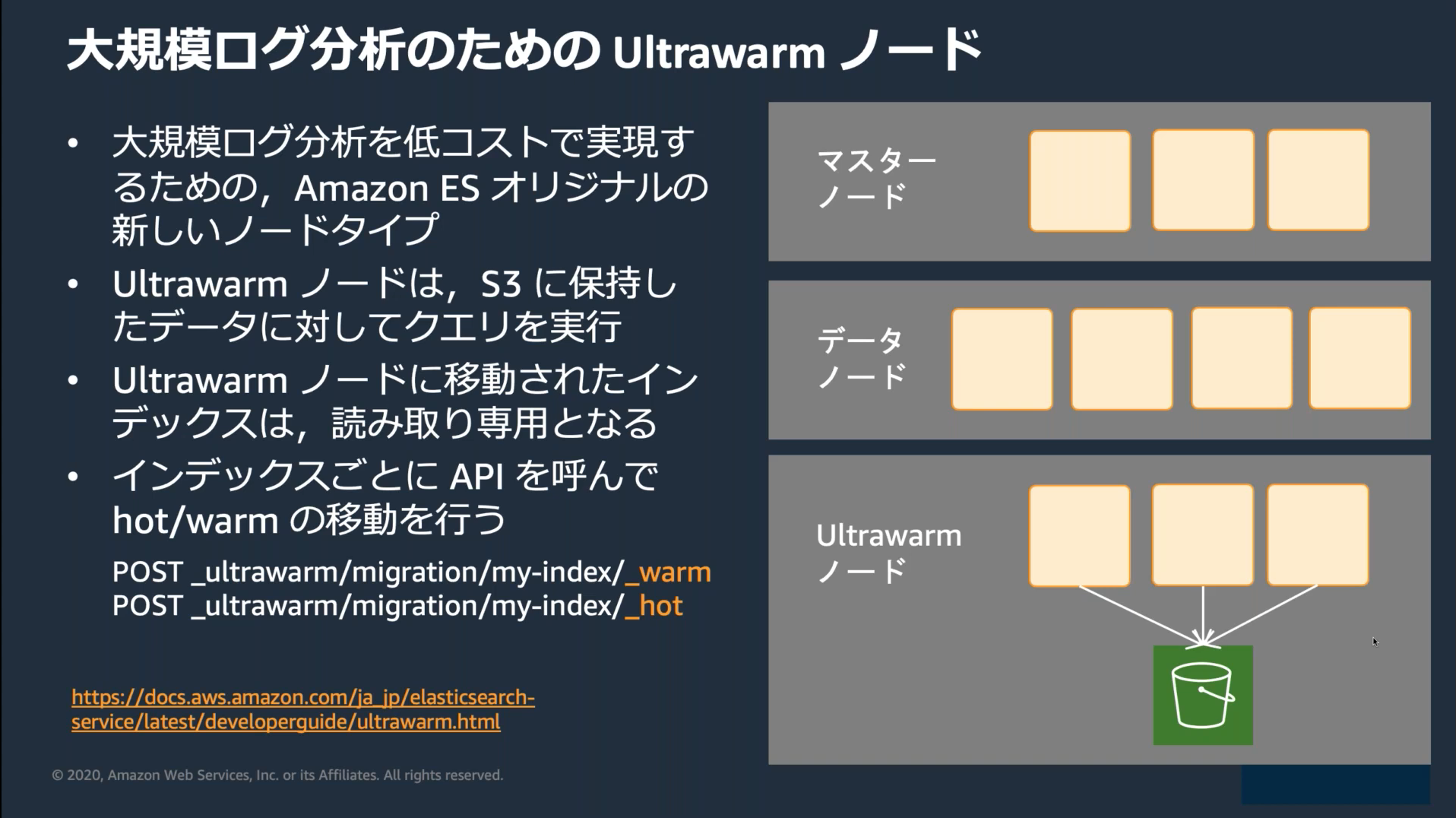
UltraWarmノード
ドメイン作成時にUltraWarmを有効にすると大量の読み取り専用データをコストパフォーマンスに優れた方法で保存できる。
UltraWarmノードではS3をストレージとして利用する。
Amazon MSK
Amazon Managed Streaming for Apache Kafka (Amazon MSK) は、Apache Kafkaを使ってストリーミングデータを処理するアプリケーションの構築および実行を可能にする、フルマネージドサービス。
AWS IoT Analytics
IoTデータの分析をかんたんに実行するためのフルマネージドサービス
データストアにはJSONとParquet形式のファイルを保存可能
DWH基礎
- ファクトテーブル: DWHに1つ以上存在し集計したい値を持つ、複数のディメンションテーブルと1対多の関係になる
- ディメンションテーブル: ファクトテーブルに対し一対他の関係で結びつき、分析の観点を与えるテーブル
AWS Elemental MediaStore
ライブ配信に必要な高パフォーマンスと即時の整合性を実現する、動画配信およびストレージサービス
その他
- DAXは変更前後両方の項目を出力する
- 各サービスのデータ整合性
- Apache Kafka/Amazon MSK: 順序保証あり/少なくとも1回
- SQS(FIFO): 順序保証あり/正確に1回
- SQS(スタンダード): 順序保証なし/少なくとも1回
- Kinesis Data Streams: 順序保証あり/少なくとも1回
- Kinesis Data Firehose: 順序保証なし/少なくとも1回
- DynamoDBストリーム: 順序保証あり/正確に1回
- Athenaはクエリのたびに料金が発生するため、アクセス頻度の高いレポートはAthenaよりRedshiftのほうが費用対効果が高い