この記事の概要
2020/09/06と2021/02/28の2回
AWS認定ソリューションアーキテクト - プロフェッショナル
(AWS Certified Solution Architect - Professional (SAP-C01))
を受験したので、その時の記録
1度不合格となり、約半年後に再挑戦しなんとか合格しました。
その時の反省も踏まえて、振り返ります。
試験の概要

プロフェッショナルレベル(一番上)の設計者向け試験です。
「AWSプラットフォームでの分散アプリケーションおよびシステムの設計における高度な技術スキルと経験を認定します。」
AWS公式より引用:引用元
◼︎ 試験要項
問題数 :75問
試験時間 :180分
受験料 :¥30,000(税別)
合格ライン:100~1000点中750点(約72%)
受験資格 :なし
有効期限 :3年
◼︎ 出題範囲
| 分野 | 出題割合 |
|---|---|
| 分野 1: 組織の複雑さに対応する設計 | 12.5% |
| 分野 2: 新しいソリューションの設計 | 31% |
| 分野 3: 移行の計画 | 15% |
| 分野 4: コスト管理 | 12.5% |
| 分野 5: 既存のソリューションの継続的な改善 | 29% |
**2021/02時点の最新バージョン(Ver.1.3)**のものです。
バージョンアップで範囲等は変更されるので、受験時は公式で確認してください。
AWS 認定 ソリューションアーキテクト - プロフェッショナル | AWS
勉強開始前の状態
AWSで動いているアプリ開発の業務経験3年(SDKによる開発を2年、インフラの設計構築は半年程度)
半年ほど前までにアソシエイト3資格を取得済み
![]() AWSソリューションアーキテクトを受験した時の話
AWSソリューションアーキテクトを受験した時の話
https://qiita.com/aminosan000/items/24c6dff9532658a5c4d5
![]() AWSデベロッパーアソシエイトを受験した時の話
AWSデベロッパーアソシエイトを受験した時の話
https://qiita.com/aminosan000/items/89bc76f77626314f3182
![]() AWS SysOpsアドミニストレーターアソシエイトを受験した時の話
AWS SysOpsアドミニストレーターアソシエイトを受験した時の話
https://qiita.com/aminosan000/items/b1765260e8ad1435a366
勉強に使ったもの
1. 試験対策本
AWS認定ソリューションアーキテクト-プロフェッショナル ~試験特性から導き出した演習問題と詳細解説
2020/08時点での唯一のプロフェッショナル対策本、前回SysOps受験時に購入した3資格対策本のシリーズなので期待して購入。
内容的にはSAA保有程度の知識を持っている人向けにSAP取得に必要なサービスと考え方を順に解説する内容が2割、問題集が4割、問題集の解答に対する解説が4割程度。オンライン問題集だと解説がないため、この解説が結構ありがたい。
2. オンライン練習問題(非公式)
AWS Certified Solution Architect Professional | Whizlabs
アソシエイト試験でもお世話になり、おもはやおなじみとなった「Whizlabs」
最新のバージョンの問題が**400問(80問×5パターン)**用意されています。
プロフェッショナルはアソシエイトより少し高いようで 29.95USD の 50%off で 14.97USD でした。(アソシエイト系も私が購入したときより 5USD 値上げされて 24.95USD になってました。それでも書籍の問題集の半額程度なのでやっぱりコスパ抜群!)
前回同様、Google翻訳で翻訳しながら日本語が怪しい部分は原文とあわせながら利用。

3. AWS公式模擬試験
4. AWSアカウント
今回はアソシエイト系に比べるときちんとした理解が必要そうなので、現時点での不足知識を補う意味で書籍の前半をゆっくり読むところから開始。
あとはひたすら問題集を解き、書籍や問題集で知らないサービスやワードが出てきたらググる、イメージが沸かないものは実際にマネコンでも触るってみる〜の流れで勉強しました。(この辺は今までと一緒)
アソシエイトの時に利用したAWS WEB問題集で学習しよう
は、フリープランだとプロフェッショナルの問題数は7問と少なく、全問(350問)利用するためにはダイヤモンドプラン:90日/¥5,480(税抜き)の登録が必要なので、今回は利用せず。
〜〜〜〜〜ここからは1回目試験受験後の追加勉強〜〜〜〜〜
5. AWS公式デジタルトレーニング「Exam Readiness: AWS Certified Solutions Architect – Professional (Japanese)」
公式から公開されているSAPの学習動画です。なんと日本語!
https://www.aws.training/Details/eLearning?id=42403
6. Udemyの模擬試験
AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集(全5回分375問)
https://www.udemy.com/share/1020WGBkAfc1xWQ3o=/
5回分解いて、解答・解説を読みながら理解の浅い部分をBlackBeltなどで勉強。
忘れそうな部分や、より理解を深めたい部分は自分の言葉で要約しながら記事にまとめてみたり、要点だけメモとしてアウトプットして、何度も見返す。
勉強時間
1回目30時間、2回目70時間のトータルで100時間ぐらい
受験後
■1回目
仕事の都合で受験日を決めてしまっていたので、Whizlabsの最後の確認テストは実施せずに受験。
勉強時間30時間程度、あと20点足りず…

おおよその内訳はこんな感じ

- 分野1「組織の複雑さに対応する設計」: IAMの権限決定ロジックやOrganizationsやCloudFormation/サービスカタログによる複数アカウントの管理、Direct ConnectとVPNを利用したハイブリッドアーキテクチャに対する理解が足りていなかった。
- 分野2「新しいソリューションの設計」: この分野は特定のサービスとかではなく、AWSのいろいろなサービスを組み合わせてセキュリティ・信頼性・パフォーマンスの高い設計ができることを求める。
類似のサービスの細かな違いやパフォーマンス向上のための機能や手法に対する理解が足りていなかった。
■2回目
1度目の受験から約5ヶ月経ってから再勉強開始、さすがに2度目の不合格は避けたかったので、追加で勉強約70時間。
今度は問題集5回分+理解の浅い部分(IAM, Organizations, Direct Connect, CloudFormationなど)をBlackBeltやネット上の記事を読み漁り、苦手分野を克服。
※Kinesisファミリーも結構勉強したんですが、ほぼ出ませんでした。

分野1と分野2は「十分な知識を有する」になりました。

正直、AWS認定試験は日本語翻訳が結構怪しくて、謎の単語が出てきたり、英語がそのままカタカナになっていたりするので、すっきり自信を持って回答できない問題もあって結構焦りました。
(「workload→作業負荷」とか、「promote→プロモート」とか)
今回の受験でいろいろと消耗したので、しばらくはAWS認定は受けないと思います…
受けるとしても、比較的軽そうな「AWS 認定セキュリティ - 専門知識(SCS-C01)」あたりですかね。
勉強になったことメモ
試験のために勉強しながら忘れないように書き溜めたメモたち
※ここに書いてあることは、あくまで私が理解が足りないと感じ、覚えたかったことで、必ずしも試験で出る範囲ではありません。試験範囲を網羅はしていません。
■組織の管理
クロスアカウント認証とアクセス戦略
IAMによる認証
ユーザ/グループ/ロール/ポリシーの違いとフェデレーション,SSOについては頻出(というかいろんな問題に絡んでくる)っぽいので要理解。
同じような選択肢で違いが「IAMユーザ」「IAMグループ」「IAMロール」のみの場合に引っかからなくなるだけでも得点率が上がる。
↓IAMは覚えることが多いので別途まとめ
AWS IAM再入門
AWS Organizations
SCPとIAMによる権限の制御については要理解
↓これも頻出、かつ普段利用機会が少ないので個別でまとめ
AWS Organization再入門
AWS Directory Service
AWS Directory Serviceを利用することで既存の組織のADとAWSの権限管理の統合など、ユーザ管理を効率化することができる。
| 選択肢 | 概要 |
|---|---|
| AWS Managed Microsoft AD | AWS上にMicrosoft ADを構築することができる、ライセンス料が含まれるためコストは高め。 |
| Active Directory Connector | オンプレ等の既存のADと接続/統合することで新規ユーザ管理を不要とする、この機能を利用して社内の既存ユーザIDを利用したAWS WorkSpaceやマネコンのSSOも実現できる。 |
| Simple Active Directory | AWS上にシンプルなマネージドのADを構築できる。Microsoft AD等と比べ機能が少ない。例えばMFAなどは利用できない。 |
AWS RAM(Resource Access Manager)
特定のAWSリソースを他のAWSアカウントと共有できる。
ハイブリッドアーキテクチャ
オンプレとVPCの接続
ハイブリッドアーキテクチャの実現や、社内イントラからAWSへのパブリックなNWを経由しないアクセスの実現のための選択肢は2つある
| 選択肢 | 概要 | メリット | デメリット |
|---|---|---|---|
| Direct Connect | データセンターや社内イントラとVPCを物理的に専用線で接続する | ・専用線なのでNW帯域を確保しやすい | ・開通までに時間がかかる ・高コスト |
| VPN接続 | 暗号化された仮想の専用線を経由する | ・即時構築、接続可能 ・低コスト |
・物理線はインターネットを経由するのでNW輻輳の影響を受ける |
それぞれにメリット・デメリットがあるので、要件に応じて選択する。
また、2つを組み合わせた冗長構成も可能なので、Direct Connectを主系経路とし、VPNを副系経路とすることで、高可用性とコスト削減を両立できる。この場合平常時はDirect Connectを優先し、障害時はVPNに自動的にフェイルオーバーさせることができる。
- 複数リージョンや複数VPCに専用線接続したい場合はDirect Connectゲートウェイを利用。
- S3やDynamoDBへのアクセスはパブリック仮想インターフェース(VPCゲートウェイエンドポイントを作成してもDirect Connectからのアクセスはできない)、VPC内へのアクセスはプライベート仮想インターフェース
■LAG(Link Aggregation Group)
LACP(Link Aggregation Control Protocol)を利用し、複数のDirect Connect接続をまとめる機能。
LAGにはいくつかルールがある。
- 全ての接続は同じ帯域幅を使用する必要がある。
- 最大4個の接続。
- すべての接続は同じDirect Connectエンドポイントで終了する必要がある。
AWS Storage Gateway
標準的なストレージプロトコルを利用してオンプレミスからAWSのストレージサービスへのアクセスを可能にするハイブリッドストレージサービス
| 種類 | 概要 |
|---|---|
| ファイルゲートウェイ | ・NFSインターフェース ・S3オブジェクトをバックエンドとしたファイルストレージ |
| ボリュームゲートウェイ | ・iSCSIブロックインターフェース ・S3およびEBSスナップショットをバックエンドとしたブロックストレージ ・オンプレのディスクデータのスナップショットをS3上に作成しDRに利用したり、ストレージの拡張として利用 |
| テープゲートウェイ | ・iSCSI仮想テープライブラリ(VTL)インターフェース ・S3とGlacierにデータを保管する仮想テープストレージとVTL管理 |
■ボリュームゲートウェイの2つのタイプ
| タイプ | 特徴 |
|---|---|
| 保管型(Gateway-Stored Volumes) | メインデータはローカルに保存、非同期でAWSにバックアップ。データ全体が高耐久ストレージに保管され、低レイテンシでアクセスできる。DRなどの目的で全体をバックアップする用途で利用する。 |
| キャッシュ型(Gateway-Cached Volumes) | プライマリデータをS3に保存、頻繁にアクセスされるデータはキャッシュしてローカルに保存。頻繁にアクセスされるデータは低レイテンシで利用できる。ローカルにキャッシュを持つ分S3利用コストは下がる。オンプレミスのストレージを低コストで拡張する目的で利用する。 |
VPCエンドポイント
VPCの内外を接続する手段、2種類に分類される
| 種類 | 概要 |
|---|---|
| インターフェイスエンドポイント(PrivateLink) | 実態はプライベートIPを持ったENI、CloudWatch LogsやSSMなどに利用、EC2上で動かす独自サービスにも利用可能(NLBにエンドポイントをアタッチ)、冗長化を考慮した設計が必要 |
| ゲートウェイエンドポイント | グローバルIPを持つタイプのサービス(S3やDynanoDBなど)にVPCの外を経由せずに接続できる |
Amazon RDS on VMware
オンプレミス環境のRDBをRDSにより管理できる。通常のRDSと同様下記のような機能が利用できる。
- AWS上のRDSへのレプリケーション
- 自動バックアップ
- CloudWatchメトリクスの利用
■データベース
Amazon Auroraのメリット
通常のMulti-AZの場合セカンダリはスタンバイ状態のためアクセスできない(Active-Stundby型)が、AuroraではプライマリDBインスタンス(Writer)とレプリカ(Reader)を同時に利用(Active-Active型)できるため、平常時もセカンダリを無駄にしない。
RDSの読み取りパフォーマンスを向上させる方法
- Amazon RDSリードレプリカを追加して、読取処理をレプリカで分散処理できるようにする。
- Elasticacheによるキャッシュ処理を追加して、読取処理が集中しているデータをキャッシュとして処理することで高速な処理を実現し、RDSへの負荷を減少させる。
- ストレージタイプをIOPSの大きなサイズに変更することで、RDS本体のI/Oパフォーマンスを向上させる。
費用対効果が高いのはRDSリードレプリカ
Aurora以外のRDBの読み込みオートスケーリング
Amazon Auroraを利用してAurora以外のRDB(RDS for MySQLやEC2上で動作するMySQL等)をオートスケーリングさせることができる。
やりかた:Auroraのクラスターを作成し、オートスケーリングを設定した上でマスターとなるRDBのレプリケーションスレーブに設定する。
スケーリングするのはレプリケーションなのでこの方法で拡張できるのは読み込みのみ。
RDSのクロスリージョンレプリケーション
RDSのクロスリージョンレプリケーションは非同期が推奨、リージョン間の距離により生じるレイテンシーによりデータベース付加が高くなるため。
AWSのグラフDB
NeptuneというマネージドグラフDBサービスがある、グラフDBはデータのリレーションシップやその方向性を探索するのに適しており、SNSの友人同士の繋がりを探索し、新しいつながりを提案するなどに利用される。
DynamoDBのグローバルテーブル
リージョンをまたいだ冗長化が可能、グローバルテーブルを使わずに複数リージョンにレプリケーションする方法として、DynamoDBストリームを生成し、ワーカー(Lambda等)で他リージョンに書き込む方法もある。
DynamoDBのセカンダリインデックス
パーティションキーを変えたい時はグローバルセカンダリインデックス、既存テーブルへの追加はできない、もう一つテーブルを作るようなもの。
ソートキーだけ追加したいときはローカルセカンダリインデックス、既存テーブルへ追加できる。
DynamoDBの1項目の上限とCU
忘れやすいのでメモ
- DynamoDBの1項目の上限は400KB
- 1RCU=4KB以下の場合、結果整合性2回/秒、強い整合性1回/秒
- 1WCU=1KB以下の場合、1回/秒
Amazon Redshift
列(カラム)指向データベース、SQLによるデータ分析に利用。
Amazon Redshiftはデータの静的な分析向けに設計されており、リアルタイムの継続的なデータ取り込み(ストリーミングデータ等)には向かない。
ElastiCache
| Type | 特徴 |
|---|---|
| Redis | ・レプリケーショングループで高可用性を実現できる。 ・暗号化できる。 ・リアルタイムゲーム処理のキャッシュ等に向いている。 |
| Memcached | ・シンプルなキャッシュ向け。 ・レプリケーションなどはできない。 |
Redisのキャッシュ戦略
| Type | 特徴 |
|---|---|
| 書き込みスルー | ・書き込みor更新時に必ずキャッシュにも反映する。 ・キャッシュミスがない。 ・キャッシュの量が膨らむ、ほぼ読み込まれないデータもキャッシュされる。 |
| 遅延読み込み | ・リクエストされて初めてキャッシュにデータが読み込まれる。 ・キャッシュミスがある。 ・初回は読み込みが遅くなる、キャッシュミス時も読み込みが遅くなる。 ・同一のデータを連続で読み込むようなケースでないとパフォーマンスは向上しない。 |
■アナリティクス
CloudSearch
マネージド型の検索機能サービス、検索機能の実装・運用工数を減らせる。
QuickSight
マネージド型のBIサービス、AWSの各サービスの利用状況などを監視するダッシュボードの提供などができる。
DataDogなどのサードパーティ製品に比べ、AWSの各サービスとの統合をしやすいというメリットがある。
AWS Glue
ETL(Extract/Transform/Load)処理(データ分析基盤構築のためのデータの読み込みや加工)をマネージド型で提供するサービス。
データをクロールし、メタデータをデータカタログに出力、このデータカタログをもとに変換を実行、という流れ。
■アプリケーション統合
Amazon SES(Simple Email Service)
マネージド型のSMTPサーバを提供する。あんまり使わなそう(個人的感想)
通常のメールサーバとの違いとして、その他のAWSサービスとの連携が行える。
会員制サービスなどで宛先が大量にある場合はSNSよりSESを利用がベストプラクティス。
(SNS=運用者向け/SES=コンシューマ向けと覚える)
SESとSNS比較
| サービス | 特徴 |
|---|---|
| SES | ・マルチメディアファイルの添付やHTMLメールの送信も可能 ・受信者の事前同意は不要 ・大量の一般ユーザ向け |
| SNS | ・事前に受信者側から登録(Subscribe)する必要あり。送信側が特定ユーザを指定して特定のメールを送信するようなやり方には向いていない。 ・一つのSNSトピックからマルチチャネルのファンアウト(メール、Chatbot、SQS、アプリPUSHなど)が可能 ・運用者や管理者への通知向け |
Amazon SWF(Simple Workflow)
マネージド型のワークフロー実行基盤サービス。
AWS Step Functions
Lambda,ECS,AWS Batch, SNS, SQSなどの複数のサービスによる一連の処理をステートマシンとしてJSONで定義し、構築・管理することができる。SWFの後継の位置付けらしい。プロセスに介入する外部信号が必要な場合と結果を親に返す子プロセスを定義したい場合、Step Functionsで実現できないのでSWFを選択することになる。それ以外はStep Functionsの利用を推奨。
■Step Functionsの2つのワークフロー
- 標準ワークフロー: 長時間実行、高耐久性、監査可能
- Expressワークフロー: 大量イベント処理ワークロード
Amazon Elastic Transcoder
マネージド型の動画の変換処理サービス。
AWS MQ
メッセージブローカー、Apache ActiveMQのマネージド。
AWSのキューイングサービスと言えばSQSだが、オンプレで既にActiveMQを利用している場合の移行先などに利用(リプラットフォーム)。
■AI
Amazon Rekognition
画像・動画認識サービス。結構新し目なのでGoogleとかWATSONに追いつくにはまだ掛かりそう?(個人的感想)
Amazon Comprehend
テキストから感情を推論するサービス。レビューなどからユーザの感情を分析するためなどに利用できる。
Amazon Personalize
ユーザ情報から「おすすめ」を推論するためのサービス。
Amazon Forecast
時系列予測サービス。需要予測などに利用できる。
Amazon Lex
テキスト・音声をインプットとするインターフェースを提供するサービス。Alexaスキルなどの対話型のアプリケーション開発に利用できる。
その他AI系
- テキストto音声:Amazon Polly
- 音声toテキスト:Amazon Transcribe
- 画像toテキスト:Amazon Textract
- 翻訳:Amazon Translate
■セキュリティ
Amazon CloudHSM
暗号化キーを生成・管理するための専用ハードウェア・キーの保管庫。セキュリティーポリシーによりパブリッククラウドでのキーの保存が許可されない場合などに利用できる。
ELBのSSL/TLS処理をオフロードすることもできる。
AWS Secrets Manager
データベースの認証情報やAPIキーなどのシークレットを管理するためのサービス。
自動ローテーションや有効期限設定の機能を備える。SSMパラメータストア経由で取得することもできる。
(/aws/reference/secretsmanager/をプレフィックスとしてIDを指定する)
SSMパラメータストアのセキュア文字列と非常に用途が近いので自動ローテーション等要件に応じて使い分ける。
参考:https://qiita.com/tomoya_oka/items/a3dd44879eea0d1e3ef5
Amazon GuardDuty
AWS上での操作や動作をモニタリングし、セキュリティ脅威を検出する。CloudTrailのログなどを解析し検知するので、AWS上で公開しているWebサービスなどへの攻撃ではなくAWSアカウントやAWS上に保存しているリソースに対する不正アクセス等から守ることが目的。
Amazon Inspector
EC2インスタンスの脆弱性を診断・検出するサービス。
Amazon Macie
AWS上に保存されている機密データを自動的に検出・分類・保護するサービス。
■管理
AWS Config
AWS上の構成変更のロギング・特定の変更操作発生時の通知、変更操作がされた場合の修復アクションの設定などができる。
AWS System Manager(SSM)
EC2インスタンスの運用・管理のための色々な機能がある
- インベントリ:インストールされたソフトウェアの情報を収集する
- オートメーション:定期的に実行が必要な運用管理タスクを自動化する
- 実行コマンド:インスタンスに対するコマンドの実行を自動化する
- セッションマネージャー:マネコンでインスタンスにSSHできる
- メンテナンスウインドウ:運用管理タスクを実行するための時間枠をスケジューリング
- パッチマネージャー:OSやSWへのパッチ適用
- ステートマネージャー:サーバ設定、ファイアウォール設定など指定された状態を維持(定期的にスクリプト実行など)
- パラメータストア:パラメータ管理
- AppConfig: アプリケーションの設定データを管理、LambdaやEC2上のアプリケーションを停止することなく安全に、設定を更新できる
AWS Personal Health Dashboard
AWSで発生している障害の状況などを確認できる。
Amazon DLM(Data Lifecycle Manager)
EBSボリュームのスナップショット取得を定期的に実行できる。
SSHポートを開けずにEC2/ECSを管理する方法
SSMのセッションマネージャー/Run Commandを利用し、マネコンから操作できる。SSMのこれらの機能はSSMの前提条件を満たして(HTTPSのアウトバウンドポートが空いている、SSMエージェントがインストールされいてる等)いれば利用できる。
CloudFormationによるIaC
↓覚えることが多いので別ページでまとめ
AWS CloudFormation再入門
OpsWorksのコンポーネント
OpsWorksはネストされたコンポーネントを持つ
スタック:最上位のコンポーネント、LB/APサーバ/DBサーバなどをまとめた1サービス単位、複数のレイヤーを含む
↓
レイヤー:その名の通り多層アーキテクチャの各層(LB/AP/DB)単位、複数のレシピを含む
↓
レシピ:LBやインスタンス内の設定やAPサーバ上のAPP定義
CloudTrail Insights
CloudTrailで取得した証跡に対し、異常なアクティビティを自動的に検出し、CloudWatch LogsとS3に出力することができる機能。2019/11~公開
2つの請求アラート
AWSの利用料が予算を超過しないようにするために通知させる手段は2つある。
- CloudWatchの請求アラーム: 請求額に対する金額やパーセンテージによる条件設定ができる
- AWS Budgetsの予算アラート: 請求額以外にもリソースごとの利用状況を細かく設定できる
コスト配分タグ
請求ダッシュボード内の「コスト配分タグ」機能を利用するとCost Explorerや請求ダッシュボードでタグ名によるフィルタリングを行い、特定のタグの付いたリソースにかかったコストを確認できる。
コスト配分タグは有効化が必要で、有効化前の請求に関してはフィルタリングできない。
Organizationsを利用している場合、マスターアカウントでコスト配分タグを有効化することで、各部門ごとの利用料管理もできる。
※タグポリシーなどで部門ごとのタグ付けが標準化されている必要がある。
コストと使用状況レポート
コストと使用状況レポートはRedshiftに取り込むかAmazon QuickSightにアップロードすることでコスト状況の分析が可能。また、Athenaとの統合を有効化することで圧縮されたレポートがS3に自動配信される。
統合請求が有効な場合、これを閲覧できるのはマスターアカウントのみ。
■移行
AWS DMS(Database Migration Service)
DBの移行のためのサービス、AWStoAWS, オンプレtoAWSどちらも対応、異なるDBエンジン間の移行も可能。移行だけでなくレプリケーションの目的でも利用できる。S3のCSVとDynamoDBのレプリケーションなども可能。
移行対象テーブル、移行方式をタスクとして設定できる。
テーブルマッピング、DMSコンソール、JSONが利用できる。
Amazon SCT(Schema Conversion Tool)
DBエンジン間でスキーマの変換を行うサービス。
AWS SMS(Server Migration Service)
オンプレ等で稼働しているVMをAMIへ変換するサービス。「リホスト」方式をサポート
下記の流れでマイグレーションを行う。
- Server Migration Connectorをオンプレ環境にインストール
- IAMユーザの設定
- AWS側からコネクタへの接続をセットアップ
- サーバーカタログをSMSへインポート
- 出来上がったAMIからEC2の起動
AWS Application Discovery Service
AWSへの移行の前準備として、オンプレ環境のアプリケーションやインフラ情報を収集するためのサービス。
VMware環境の場合エージェントレス型、それ以外の場合エージェント型(エージェントのインストールが必要)。
AWS Migration Hub
サードパーティのマイグレーションツールとの連携を行うためのサービス。
VM Import/Export
インスタンスとVMを相互変換するためのサービス。
移行戦略の6R
オンプレからクラウドへの移行にはRから始まる6つの移行戦略がある、既存のアプリケーションやインフラ構成、コンプライアンス等を考慮し、適切な戦略を選択する。複数の移行戦略を組み合わせることもある。(一部のアプリケーションのみ移行が難しい場合Replatform+Retainなど)
| 移行戦略 | 概要 | 例 | 移行難度 |
|---|---|---|---|
| Rehost (インフラの置き換え) |
アプリケーションには手を加えない、インフラのみ移行。(リフト・アンド・シフト」とも言う。) | アプリケーションを稼働させるサーバをEC2に移行する。 | 低 |
| Replatform (プラットフォームも含めた置き換え) |
ミドルウェアのPaaSへの移行を行う。 | DBをRDSに移行する。 | 中 |
| Repurchase (再購入) |
既存のアプリケーションをSaaS等に置き換える。(「使用廃止と購入」とも言う。) | 社内の業務システムをKintoneに置き換える。 | 中 |
| Refactor/Re-Architect (リファクタリング/再設計) |
アプリケーションの修正やアーキテクチャの再設計を行い、クラウドネイティブな構成にする。 | 夜間のバッチ処理を行っていたシステムをAWS BatchやLambdaでサーバレスに置き換える。 | 高 |
| Retire (廃止) |
不必要な機能やアプリケーション自体を廃止する。 | 利用者が少ないのでサービス終了する。 | 移行なし |
| Retain (保持) |
オンプレで稼働を続ける。 | 社内ルール上データをクラウドに置けないのでDBはそのままオンプレを維持する。 | 移行なし |
AWS Snowファミリー
オンプレからAWSへのデータ移行の際に、対象のデータ量がTBを超えるようなケース(ネットワーク経由の移行で1週間以上かかる場合など)はSnowファミリーの利用を検討
大きく分けて4種類
| サービス | 特徴 |
|---|---|
| Snowcone | ・テラバイト規模のデータ移行 ・A5サイズの小型デバイス ・8TB ※2020/06に発表、そろそろ試験でもでるかも?(2021/02) |
| Snowball | ・ペタバイト規模のデータ移行 ・S3へのインポートorS3からのエクスポート用 ・データはクライアント側で暗号化してから書き込み ・80TB |
| Snowball Edge | ・Snowball+コンピュート+α ・データの暗号化をEdge内で実施 ・書き込み時にLambdaによる処理が可能 ・Edge内でEC2インスタンスを起動可能 ・100TB or 42TB ・クラスター構成にしてローカルストレージとしての利用も可 |
| Snowmobile | エクサバイト規模のデータ移行、セミトレーラートラックが牽引する長さ14mの丈夫な輸送コンテナがやってくる |
Snowball Edgeはさらに2種類に分かれる
| 種類 | 特徴 |
|---|---|
| Snowball Edge Storage Optimized | ・ブロックストレージとS3両方と互換性のあるストレージ ・24個のvCPU搭載(EC2 m4.4xlargeと同等) ・100TB |
| Snowball Edge Compute Optimized | ・移行中の高度な機械学習やビデオ分析などに利用 ・52個のvCPU搭載 ・オプションでGPUも提供 ・42TB |
※2020/04/07以降、通常のSnowballはSnowball Storage Optimizedに移行(公式ブログ参照)したので、「Snowball」というサービスの中で「Snowball Edge Storage Optimized」「Snowball Edge Compute Optimized」の2つから選択する形(ややこしい、試験ではいつから統合された名称になるか不明)
AWS Licence Manager
クラウド移行の際にBring-Your-Own-License(BYOL)によりコストを削減をしつつ、ライセンス移動プロセスを効率化するためのサービス。
あたりまえだが、マネージドのサービスに移行するとライセンスを継続利用できない。
■ストレージ
S3のストレージクラス
IAとかRRSとかが忘れやすいのでメモ
| ストレージクラス | 特徴 |
|---|---|
| 標準 | 低レイテンシーかつ高スループットで高耐久(99.999999999%) |
| 標準IA(Infrequent Access) | 低頻度アクセス用、ストレージ料金は標準より安い。 |
| 1ゾーンIA | 低冗長化、低頻度アクセス(RRSは非推奨になり、低冗長は1ゾーンIAに)、ストレージ料金が標準IAよりさらに安い。 |
| Glacier | 長期保存、かつほぼアクセスしない場合用、ストレージ料金が安い代わりに読み込みが非常に遅い。(数分〜数時間※↓の表参照) |
| Glacier Deep Archive | Glacierよりさらに遅い(12時間以内or48時間以内※↓の表参照)、代わりにさらに安い。 |
| S3 Intelligent-Tiering | アクセス頻度に応じて自動的にコスト最適化してくれる、アクセス頻度が流動的で予測不可能な場合のコスト最適化に利用できる。 |
- 1ゾーン以外は3つのAZで冗長化される
- 低頻度アクセスとGlacierは取り出し時容量に応じた料金がかかる
- 標準以外は30日間~180日間の最低ストレージ期間料金(途中で移行や削除した場合も請求される料金)がある
(30日以内に削除するデータに標準以外を利用したり、コスト最適化のためにクラスを短期間で変えるのは逆にコストを上げてしまう可能性があるので注意)
Gracierの取り出しオプション
| 種類 | 概要 |
|---|---|
| 迅速(Expedited) | ・コストは上がるが読み込みが早くなる ・通常1〜5分以内 ・Deep Archiveの場合利用不可 |
| 標準(Standard) | ・デフォルトの取り出し方 ・通常3〜5時間以内 ・Deep Archiveの場合12時間以内 |
| 大量取り出し(Bulk) | ・最も安価 ・通常5〜12時間以内 ・Deep Archiveの場合48時間以内 |
■コンピューティング
EC2インスタンスタイプ
これも忘れやすい
| インスタンスタイプ | 特徴 |
|---|---|
| 汎用(T3, M5等) | バランスの取れたコンピューティング、メモリ、ネットワークのリソースを提供 Txはアイドル状態のときにCPUクレジットを蓄積し、アクティブなときにCPUクレジットを消費するバーストが可能。 |
| コンピューティング最適化(C5等) ※Compute=Cで覚える |
バッチ処理ワークロード、メディアトランスコード、高性能ウェブサーバー向け。 |
| メモリ最適化(R5, X1等) | メモリ内の大きいデータセットを処理するワークロード向け。 |
| 高速コンピューティング(G3, P4等) ※GPU=Gで覚える |
最新世代のGPUベースのインスタンス、機械学習トレーニングやグラフィック処理向け。 |
| ストレージ最適化(I3, D3等) ※I/O=Iで覚える |
低レイテンシー、高いランダムI/Oパフォーマンスと高いシーケンシャル読み取りスループット。 |
スポットフリート
EC2の購入オプションとして最もコスト効率の良いスポットインスタンスだが、インスタンス価格の高騰により、起動できなかったり、稼働中のインスタンスが中断されるリスクがある。それをカバーする方法として、「スポットフリート」というオプションがある「スポットフリート」を利用することであらかじめインスタンス数またはvCPU数を指定しておき、指定したキャパシティを維持するよう、スポットインスタンスとオンデマンドを組み合わせて起動させることができる。
プレイスメントグループ
複数のEC2インスタンス間のレイテンシを下げるための仕組みとして「プレイスメントグループ」がある。同一のプレイスメントグループ内のインスタンスは物理的に近いハードウェア上に配置され、インスタンス間で広いNW帯域が確保される。プレイスメントグループへの追加はインスタンスが停止中でないとできない。
3種類のプレイスメントグループがある。
| グループ | 説明 |
|---|---|
| クラスタープレイスメントグループ | 単一AZ内のインスタンスを論理的にグループ化したもの |
| パーティションプレイスメントグループ | 論理的なパーティションに分散されているインスタンスのグループ(複数AZにまたがる) |
| スプレッド(分散)プレイスメントグループ | それぞれ異なるハードウェアに配置されるインスタンスのグループ |
HVM(Hardware-assited VM)とPV(ParaVirtual)
HVMは完全仮想化でPVは準仮想化、HVMはCPU/NW/ストレージなどのHW拡張機能を利用できる。
遅延を減らしたい場合HVM、パフォーマンス改善の問題でまれに出る。
AWS Batch
大規模計算処理の実行・管理をするためのマネージドサービス、実際の処理はECS上で行われる。
定型業務の逐次実行などのバッチ処理向けではない。
■ネットワーク
VPCピアリング
複数のVPCを接続し、インターネット経由なしで通信可能にする。
- VPCピアリング接続は2つ以上のVPC間の推移的なピア接続をサポートしない
(VPC AとVPC B,VPC BとVPC Cがピアリングされていても、VPC AとVPC Cは通信できない) - 異なるリージョン間のピアリング機能を「インターリージョンVPCピアリング」という
(クロスリージョンではなく、インターリージョンと呼ぶらしい)
セカンダリCIDRブロック
VPC内のプライベートIPが枯渇しそうな時は、「セカンダリCIDRブロック」により拡張できる。
例えば、既存のCIDRブロック10.0.0.0/16にセカンダリCIDRブロック10.1.0.0/16を追加することで両方の範囲を利用できるVPCになる。
※セカンダリといいつつ複数つけられる。(元のCIDRがプライマリでそれ以外は全てセカンダリ)
VPCのCIDRブロック内の予約済みIP
プライベートネットワークにおいて先頭と末尾はネットワークアドレスとブロードキャストアドレスだが、VPCの場合それ以外にも3つ使えないIPがある。
各サブネット CIDR ブロックの最初の 4 つの IP アドレスと最後の IP アドレスは使用できず、インスタンスに割り当てることができません。たとえば、CIDR ブロック 10.0.0.0/24 を持つサブネットの場合、次の 5 つの IP アドレスが予約されます。
10.0.0.0: ネットワークアドレスです。
10.0.0.1: VPC ルーター用に AWS で予約されています。
10.0.0.2: AWS で予約されています。DNS サーバーの IP アドレスは、VPC ネットワーク範囲のベースにプラス 2 したものです。複数の CIDR ブロックを持つ VPC の場合、DNS サーバーの IP アドレスはプライマリ CIDR にあります。また、VPC 内のすべての CIDR ブロックに対して、各サブネットの範囲 + 2 のベースを予約します。詳細については、「Amazon DNS サーバー」を参照してください。
10.0.0.3: 将来の利用のために AWS で予約されています。
10.0.0.255: ネットワークブロードキャストアドレスです。VPC ではブロードキャストがサポートされないため、このアドレスを予約します。
引用元:VPCとサブネット
拡張ネットワーキングによるI/Oパフォーマンスの向上
シングルルートI/O仮想化(SR-IOV)を使用してネットワーク性能を上げることができる。
下記いずれかのメカニズムを選択
- ENA(Elastic Network Adapter):最大100Gpbs
- Intel 82599 Virtual Function(VF)インターフェイス:最大10Gbps
ELBの使い分け
| キーワード | 概要 |
|---|---|
| ALB(Application Load Balancer) | ・HTTP/HTTPSのみに対応した(TCPには対応していない)L7ロードバランサー ・パスやクエリなどのコンテンツベースのルーティングが可能 |
| NLB(Network Load Balancer) | ・TCP/UDPに対応したL4ロードバランサー ・高可用性/高スループット/低レイテンシ ・ソースIP/Portがターゲットまで保持される ・SGは設定できない |
| CLB(Classic Load Balancer) | ・TCPおよびSSLリスナーが利用可能ト ・アプリケーション生成の独自Cookieを使用したスティッキーセッションが可能(ALBの場合「AWSELB」という名前のCookieが自動生成される) |
- ALB/CLBでクライアントのIPを取得したい場合「X-Forwarded-For」ヘッダーから取得
BYOIP(Bring Your Own IP: 保有IP持ち込み)
既存グローバルIPをEIPとして利用できる。RIR(Regional Internet Registry)に登録し、RDAP(Registry Data Access Protocol)で証明書(ROA(Route Origin Authorization))を発行する。
■その他
障害復旧モデル
DR対策として、RTO/RPOとコストの要件に応じていくつかの方式がある。
下に行くほどコストが上がる代わりにRTO(復旧にかかる時間)が短くなる。
| 方式 | 概要 |
|---|---|
| バックアップ&リストア | バックアップのみを別リージョンに退避しておく。障害発生時はバックアップから復旧。 |
| パイロットライト | メインのリージョンよりスペックの低いDBを別リージョンに起動しデータを同期しておき、障害発生時DBをスケールアップしつつAPを立ち上げる。(DBだけは起動しておくので「コールドスタンバイ」ではない) |
| ウォームスタンバイ | AP等含めた構成を別リージョンにも起動しておき(このときコスト削減のためスペックの低い構成やインスタンス数を減らしておく)、障害発生時はスケールアップ/スケールアウトさせる。 |
| マルチサイト(ホットスタンバイ) | AP等含めメインのリージョンと同等の構成を別リージョンでも稼働させておき、障害発生時はRoute53等で向き先を切り替えるのみ。 |
Kinesisシリーズ
| サービス名 | 概要 |
|---|---|
| Kinesis Data Streams | 低レイテンシのスタンダードなデータストリーム、順序付けが可能。 |
| Kinesis Firehose | データを直接S3やRedshift, ElasticSearchに流しこめる。 (Lambdaによるデータの変換もできる) |
| Kinesis Analytics | 入力データにSQL等を適用し、再度ストリームとして出力できる。 |
| Kinesis Video Streams | 動画用、Rekognitionで画像解析をしたり、そのままURLを発行しストリーミング配信等が可能。 |
| Kinesis Agent | サーバ等にインストールしておくことで、ログファイル等の指定したファイルへの書き込み発生時に書き込まれたデータを自動的にKinesisストリームとして送信してくれる。データに対し、フィルター適用などの送信前の事前処理を設定することも可能。 |
| Kinesis Producer Library | 独自のアプリケーションからKinesisストリームを生成/送信するためのライブラリ。 |
| Kinesis Consumer Library | 独自のアプリケーションでKinesisストリームを受信するためのライブラリ。 |
- KinesisとSQSの違い:SQSはシンプルなデータキュー、Kinesisは大量データを高速に処理するためのストリーム
- Kinesisのストリーミングデータ保存期間:デフォルト24時間、最大7日間
Kinesisのようなストリーミングサービスはプロデューサー(送信側)とコンシューマー(データ処理側)を組み合わせて利用する。
■Kinesisのプロデューサー/コンシューマー
どれがプロデューサーでどれがコンシューマーか覚えておくだけでも、消去法で解答しやすくなる。
| プロデューサー | コンシューマー |
|---|---|
| ・Kinesis Data Streams ・Kinesis Video Streams ・Kinesis Producer Library(KPL) ・Kineis Agent ・Kinesis Analytics |
・Kinesis Firehose ・Kinesis Client Library(KCL) ・Kinesis Analytics |
| ※Kinesis Analyticsはストリームに対し、SQLを実行した上で再度ストリームを出力するため、コンシューマー兼プロデューサー |
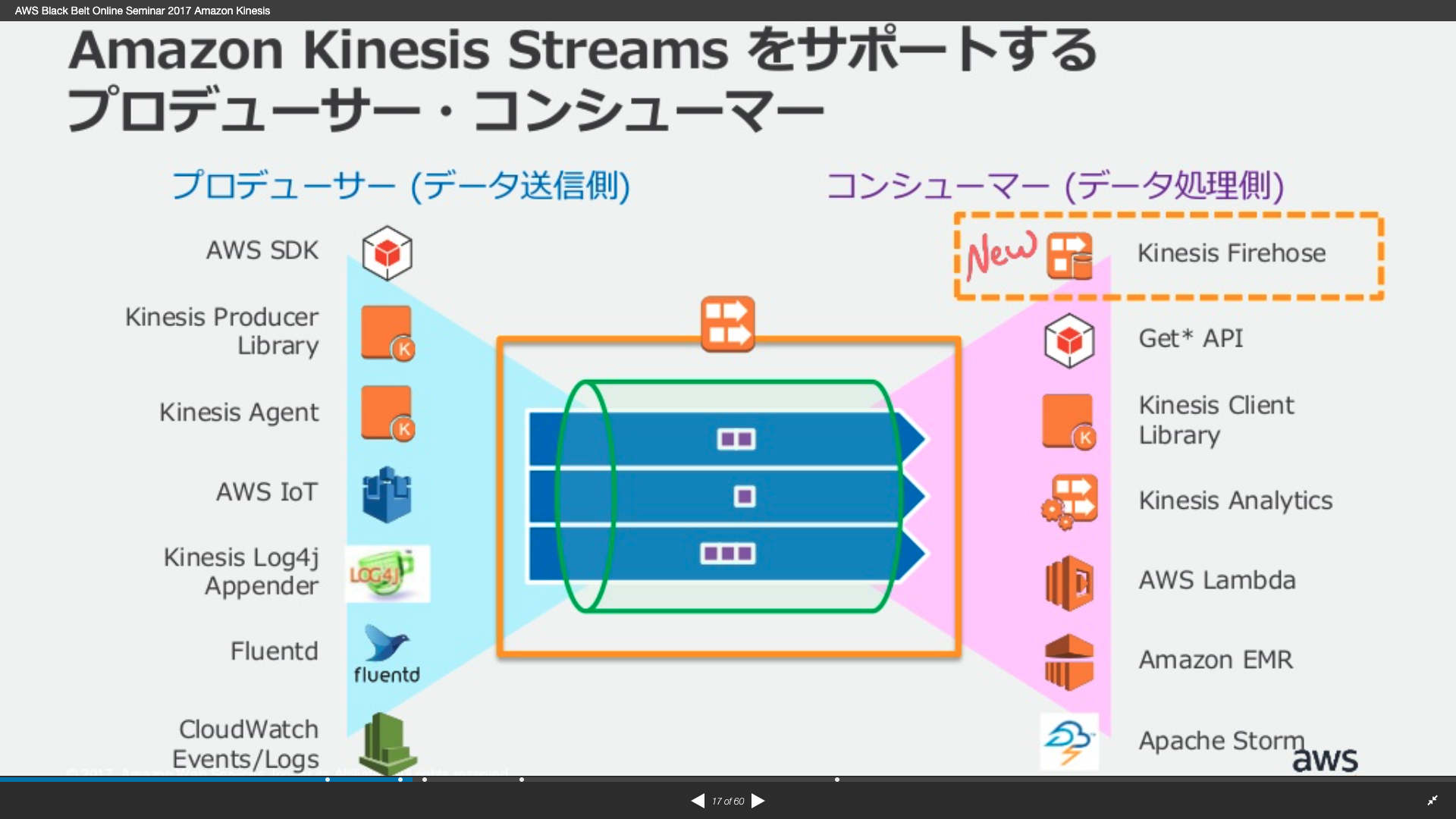
引用元:AWS Black Belt Online Seminar 2017 Amazon Kinesis
Kinesis Video Streamsの3つの利用方法
| プロデューサー | コンシューマー |
|---|---|
| GetMedia | 独自アプリケーションからKinesis Video Streamsのストリーミングデータを取得する方式、GetMedia APIを利用。 |
| HLS(HTTP Live Streaming) | 業界標準のHTTPベースのメディアストリーミング通信プロトコル。 GetHLSStreamingSession URL APIによってHLSストリーミングURLを取得できる。 このURLを利用してブラウザやHLS対応メディアプレイヤで直接再生できる。 |
| MPEG-DASH(Dynamic Adaptive Streaming over HTTP) | 従来のHTTPウェブサーバーから配信されたインターネット経由で高品質のストリーミングを可能にする適応ビットレートストリーミングプロトコル。 GetDASHStreamingSession URL APIによってMPEG-DASHストリーミングURLを取得できる。 |
■HLSとDASHの違い:
- エンコード形式:MPEG-DASHでは、任意のエンコード標準を使用できる。一方、HLSではH.264またはH.265の使用が必須。
- デバイスのサポート:HLSは、Appleデバイスでサポートされている唯一の形式。iPhone、MacBook、およびその他のApple製品は、MPEG-DASHで配信された動画を再生できない。
Cognitoの2つのプール
紛らわしいのでメモ
- ユーザープール:ユーザそのものを登録するプール、Cognitoのみで認証をする場合に必要
- IDプール:ユーザに一意のIDを作成し保存するプール、その他のSAMLやWEBIDフェデレーションで認証した結果に対し、認可をするのに利用
リモート向けの機能
- Amazon Workspace:DaaS
- Amazon AppStream:デスクトップ全体でなくアプリ単位で提供
ブロックチェーン
ブロックチェーン関連のAWSサービスについても出題されるようなのでキーワードをメモ
| キーワード | 概要 |
|---|---|
| Amazon QLDB(Quantum Ledger Database) | フルマネージドの台帳データベース |
| Amazon Managed Blockchain | フルマネージドの分散型ブロックチェーンサービス |
| AWS Blockchain Template | CloudFormationテンプレートを利用し、簡単にブロックチェーンネットワークを作成できる |
Amazon Managed BlockChainではHyperledger FabricとEthereumの2つのフレームワークに対応。
AWSの知識ではないけれど知らなかったこととか、覚えておきたいこと
- PoC:概念検証、新しいソリューションの前に実現性、効果とコストなどを検証すること、アプリケーション開発の場合プロトタイピングが該当する。
- コンバージョン率:ビジネスとして成果につながった割合のこと、商品の売り上げや会員登録などそのビジネスの目的により「成果」は異なる。
- ワークロード:英語の意味そのままだと仕事量、作業量。AWSでは「ワークロードは、リソースと、ビジネス価値をもたらすコード (顧客向けアプリケーションやバックエンドプロセスなど) の集まりです。」らしい。
参考:https://docs.aws.amazon.com/ja_jp/wellarchitected/latest/userguide/workloads.html
DR用語
どっちがどっちかわからなくなるやつ
- RPO(Recovery Point Objective):目標復旧時点(どれぐらい新しいデータまで復旧する必要があるか、大きいほど巻き戻りを許容)
- RTO(Recovery Time Objective):目標復旧時間(ダウンタイムをどれぐらい許容するか、大きいほど復旧作業に余裕ができる)
「Time」はダウンタイム、「Point」は復旧時点の点で覚える。
RAID
これもどれがどれだか忘れるのでメモ、0と1以外はこの試験ではおそらく出ないので気にしない。
- RAID0: ストライピング、信頼性は上がらないが読み書きの性能は上がる
- RAID1: ミラーリング、読み書きの性能は上がらないが、信頼性が上がる
DNSのレコードの種類
これもすぐ忘れるのでメモ、他にもあるけど省略
| レコード | 概要 |
|:---|:---|---|---|
| Aレコード | ドメインとIPを直接紐付けるレコード |
| NSレコード | ドメインの頂点(APEX)につくレコードexample.comのようにサブドメインを持たないドメインには必須 |
| CNAMEレコード | ドメインとFQDNを紐付けるレコード
Aレコードでつけたドメインをさらに別のドメインに紐付けるなどで利用 |
| ALIASレコード | CNAME同様FQDNに別のドメインを紐付けるためのものだが、CNAMEレコードでがつけられないような時(CNAMEは他のレコードと共存できないため、Zone ApexにはNSレコードが付いているのでつけられない、などの理由)に利用できる。
※DNS自体の仕様ではなくRoute53のエイリアス機能のためのレコード |
ORACLE DBの機能
- Oracle RAC(Real Application Clusters):複数台のORACLE DBサーバを1つのDBとして利用する構成、RDSでは利用不可(EC2のMarket prace AMIで利用可能)
- Oracle RMAN:バックアップ/リカバリを行うツール。RDSではバックアップからの復元はできるが、バックアップ取得は不可、RDSの自動バックアップ機能の利用を推奨。