この記事の概要
2022/07/31
AWS認定データベース - 専門知識
(AWS Certified Database - Specialty (DBS-C01))
を受験したので、その時の記録
復習用ノートとして、また後で見返して今後の資格試験受験時の参考にしたり仕事で使いたくなったとき思い出せるようにまとめます。
基本的に仕事で今後活用するかもしれない前提で学習をしています、資格取得だけを目的にする場合もっと効率のいい方法があるかもしれません。
試験の概要
SPECIALTYカテゴリの試験で、AWSにおけるRDB/NoSQLサービスの違いを理解し、目的に応じた最適なソリューションを選択する知識などが問われます。
この試験では「最適な AWS データベースソリューションを推奨、設計、維持するための専門知識が認定されます。」とのこと。
AWS公式より引用:引用元
◼︎ 試験要項
問題数 :65問(うち15問は採点対象外)
試験時間 :180分
受験料 :¥30,000(税別)※公式サイトでは「300USD」の表記ですが、為替レートに関わらず税抜¥30,000です。
合格ライン:100~1000点中750点(約72%、採点対象の問題37/50正解で合格)
受験資格 :なし
有効期限 :3年
◼︎ 出題範囲
| 分野 | 出題割合 |
|---|---|
| 第 1 分野: ワークロード固有のデータベース設計 | 26% |
| 第 2 分野: デプロイと移行 | 20% |
| 第 3 分野: マネジメントとオペレーション | 18% |
| 第 4 分野: モニタリングとトラブルシューティング | 18% |
| 第 5 分野: データベースセキュリティ | 18% |
2022/07時点の最新バージョン(Ver.2.1) のものです。
バージョンアップで範囲等は変更されるので、受験時は公式サイトで確認してください。
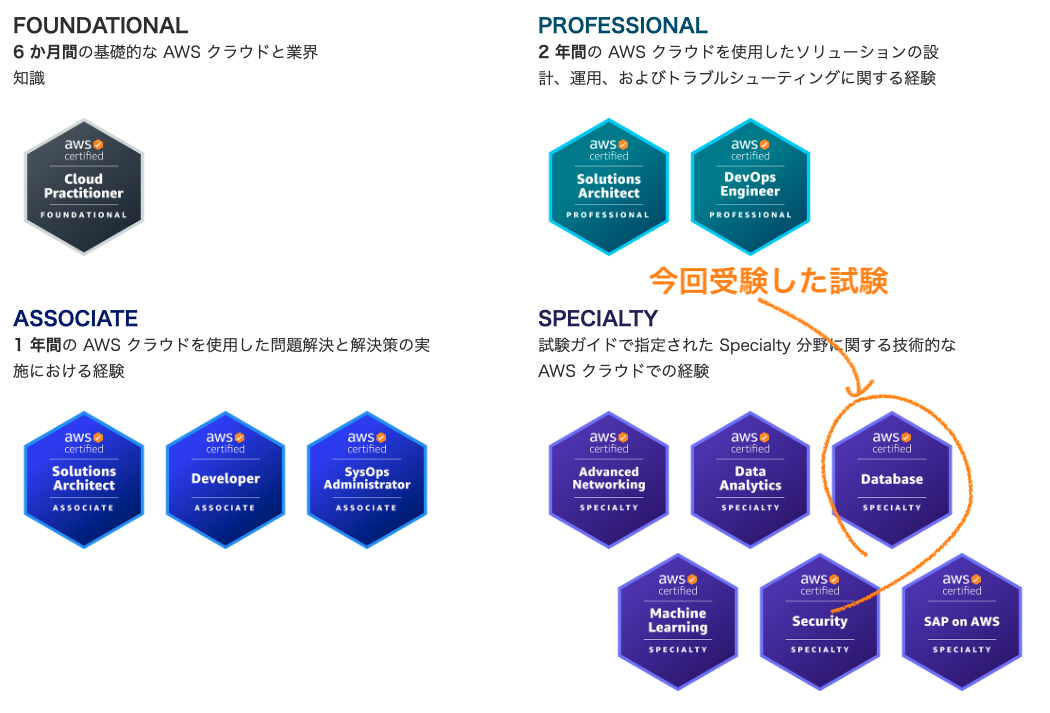
AWS Certified Database - Specialty 認定
勉強開始前の状態
AWSで動いているアプリの保守開発/運用の業務を5年程度、現在も継続中
AWS認定はこれまで6個取得済み
- AWS認定ソリューションアーキテクトを受験した時の話
- AWS認定デベロッパーアソシエイトを受験した時の話
- AWS認定SysOpsアドミニストレーターアソシエイトを受験した時の話
- AWS認定ソリューションアーキテクトプロフェッショナルを受験した時の話
- AWS認定セキュリティ - 専門知識を受験した時の話
- AWS認定DevOpsエンジニアプロフェッショナルを受験した時の話
勉強に使ったもの
1. AWS公式模擬試験(Skill Builder)
AWS Skill Builderで20問の模擬試験を無料で受けられます。何度でも実施できるのではじめに実施します。
2. Exam Readiness: AWS Certified Database - Specialty (Japanese)
AWS Skill Builderで無料で提供されている「AWS認定データベース – 専門知識試験」対策のAWS公式E-learning、試験範囲についてサンプル問題をはさみながら教えてくれる。DBSのExam Readinessは動画なし、テキストと図のみで、SAPなどに比べるとクオリティが低かったです。が、一応試験範囲の要点については知ることができるので、受講する価値はあると思います。
3. オンライン問題集(非公式)
AWS認定受験時に毎回購入している「Whizlabs」
DBSのコースは最新のバージョンの問題が 180問(65問×2パターン+セクション問題が35問+お試し問題が15問) 用意されています。
19.95USDからクーポン利用で30%offの13.96USD(日本円で¥1,900ぐらい) でした。
他のAWS認定のコースに比べて問題数が少ないです。それぐらい出題パターンが少ないのかもしれません。
いつもどおり、Google翻訳で翻訳して利用。
以前買ったSysOpsの講座はいつのまにかC02にバージョンアップされていました。買い切りなのにバージョンはちゃんと上がっていくようです。
今後の更新時も最新の問題集として利用できるので、更新する予定のある方には大変お得です。
4. AWS Black Belt Online Seminar過去動画
試験範囲の中であまり詳しくないサービス、触ったことがないサービスの過去動画を視聴。
5. AWSアカウント
練習問題の回答/解説やBlack Beltで学習したものを実際にマネコンで触ってみる。
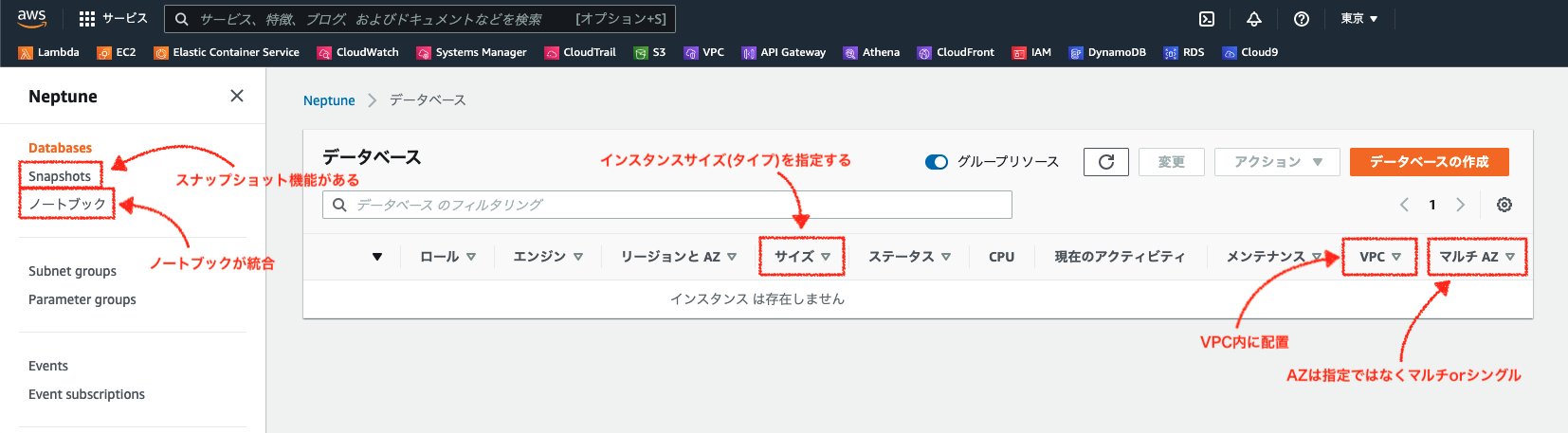
触ったことがあるのとないので理解度が大きく変わります。時間に余裕のある場合は各サービスのチュートリアルを1度やってみるのがいいかと思いますが、時間がない人はとりあえずコンソール画面とリソース作成画面だけでも眺めておくと、それだけで得られる情報も結構あると思います。視覚情報が紐づくので記憶にも残りやすくなります。
例えばAmazon Neptuneの場合、コンソールのデータベース画面を見るだけで ![]() のような情報が得られます。「データベースの作成」を押してみると更に情報が増えます。
のような情報が得られます。「データベースの作成」を押してみると更に情報が増えます。
勉強(試験準備)の流れ
1. 試験ガイドを読む
はじめに、公式サイトの「試験ガイド」を読みます。
まず確認するのが「受験対象者にとって試験の範囲外とみなされるもの」と「範囲外のAWSのサービスと機能」です。ここには、試験範囲に含まれていそうで含まれていないものを書いてくれています。
これらは学習対象から除外できます。もし、本番でここに書かれているサービスを主題とした問題が出題された場合、「スコアに影響しない採点対象外の設問」だと思って気軽に回答しましょう。
※AWS認定では今後の試験への情報収集のため「採点対象外の設問」が一定数出題されます。(試験ガイド2ページ目参照)
さらに「試験の対象となる主要なツール、テクノロジー、概念」の「AWSのサービスと機能」には試験で出題される可能性のあるAWSサービスが箇条書きされています。ここに載っているものでどんなサービスなのか概要すら知らないものはとりあえず「こんなサービス」と説明できる程度の概要だけでも調べておきましょう。
概要を知っているだけで選択肢から除外できるケースもあります。
また、ここに載っている比較的メジャーなサービスで理解が怪しそうなものは、Black BeltやDevelopersIOなどを見て勉強します。
今回の場合、DBの試験なので「データベース」として載っているものを優先して勉強します。

2. サンプル問題と模試を実施する
次に、公式のサンプル問題と模試をやってみます。
無料なので気軽に実施できます。これで問題のレベル感と自分のレベル感、そのギャップを確認します。
もちろんここでわからなかった部分はメモしておいて後で調べます。覚えたほうが良さそうな部分はノートに書き出します。
3. Exam Readinessを受講する
公式E-Learningはためになることが多いので、受講しておきます。
ここでも知識が足りなさそうな部分をメモしておきます。
4. 知識が不足している範囲を勉強し直す
すでに他のAWS認定試験の対策で勉強している範囲や仕事で使ったことのあるものもあるので、それ以外の知識の足りない部分を補強しておきます。
今回の場合、試験ガイドや模試の中で特に勉強が必要そうだと感じたのは
- Amazon DocumentDB
- Amazon Neptune
- Amazon Timestream
- Amazon Redshift
- Amazon ElastiCache
- AWS DMS
- RDS(Aurora含む)のリージョンをまたいだ冗長化やセキュリティなど細かいところ
- Amazon DynamoDBのDAX、SIなど細かいところ
あたりです。Specialtyはカテゴリがはっきりしているので、DB関連で「使ったことがないもの」「使ったことがない機能」と勉強範囲を絞れます。
今回は特に理解が浅く出題率の高そうな下記のBlack Belt過去資料を視聴しました。
- Amazon DocumentDB
- Amazon Neptune
- Amazon Timestream
- Amazon Redshift
- Amazon ElastiCache
5. 練習問題を解く
試験対策で一番大事なのが練習問題です。Wizlabsは類似の問題が連続して出題されたり、問題のカテゴリが偏っているので用意されている問題は全て解かないと対象範囲を網羅できません。最低限1回ずつは解いてから試験に挑むようにします。DBSは練習問題の分量が少ないので、解答解説を読んだ後、より理解を深めるために公式ドキュメントなどを読む時間を多くとり、じっくり進めていきます。
全問解いてから回答の確認をしていると問題文を2回ずつ読むことになって効率が悪いので、practice modeでその場で回答を確認し、間違っていた場合メモしたりすぐに調べるようにしています。
6. 復習する
ここまで勉強しながらまとめたノートと練習問題の回答/解説を見返しながら、覚え直し+まだ足りなそうな部分の勉強をします。
勉強時間
約27時間
練習問題の数が少なかったこともあり、比較的勉強時間は短めでした。
受験後
結果はスコア804で合格、120分で全問解き終わり、残り60分でちょうど見直しが終わるぐらいでした。
セキュリティの時に比べると勉強時間が少なかったせいか、少し回答に悩む問題も多く、スコアも下がりました。

一番出題数が多い分野1が「改善が必要」、分野1には「災害対策と高可用性の戦略を決定する」を含まれているので、リージョン間の冗長化やリージョンをまたいだリカバリなどの理解が浅かったのが、結果に表れたのかなと思います。
業務でもリージョンをまたぐ設計/構築/運用をすることはないので、この辺りは苦手分野ですね。
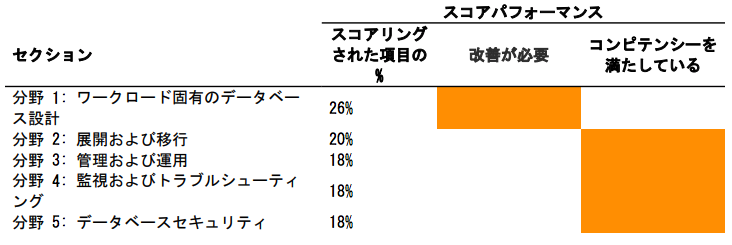
RDS, Aurora, DynamoDB に関する出題が多く、DRや移行に関してはもう少し勉強しておけばよかったと思いました。(DMSやSCTはドキュメントなどほとんど読まなかった・・・)
Specialty試験は試験範囲が狭く深いので比較的勉強しやすいです。
とくにソリューションアーキテクトを取得した後にSpecialtyの勉強をすると広く浅く理解した基礎に、さらに深い知識が載せられていくのでサクサク勉強できる気がします。
きっと、AWS認定を作っている人たちもうまく知識が広く深くなっていくように考えているのでしょう。
12冠まであと5個!
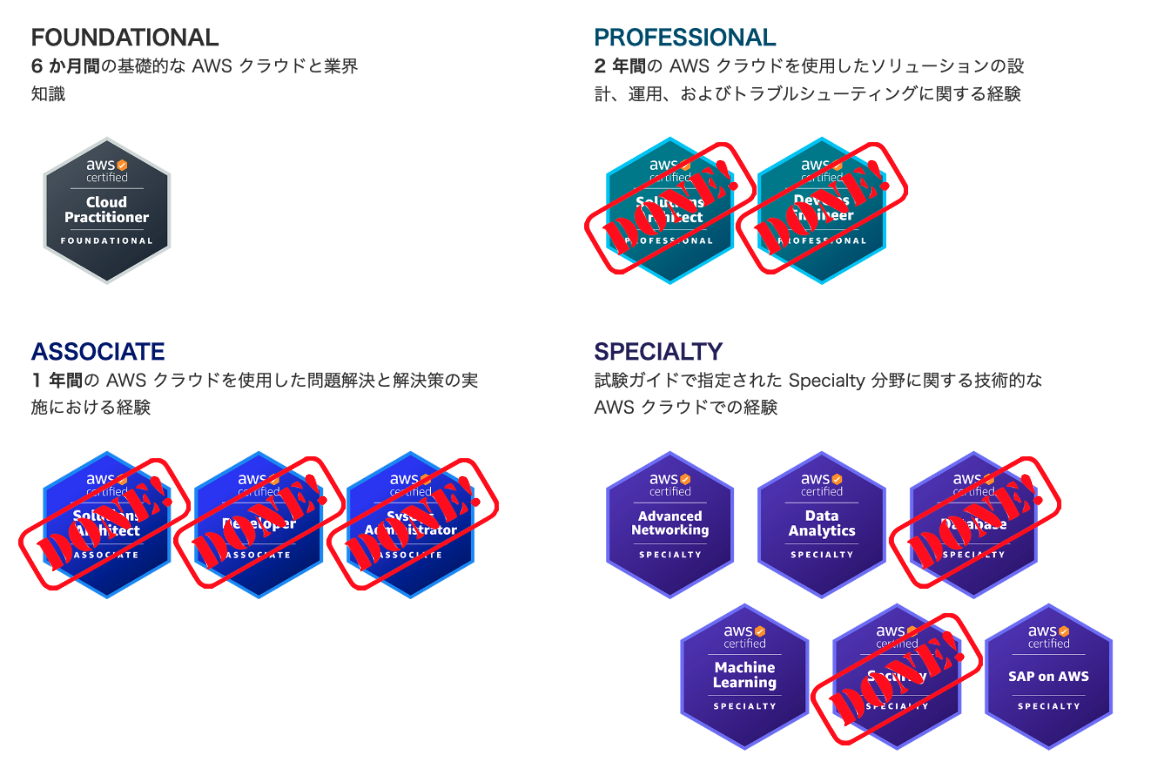
次は「AWS Certified Advanced Networking - Specialty」を受けます!
勉強ノート
試験のために勉強しながらまとめたノート
※ここに書いてあることは、あくまで私が理解が足りないと感じ、覚えたかったことだけです。試験範囲を網羅はしていません。
Amazon RDS
言わずもがな、RDBMSをマネージドで利用できるサービス。
MySQL、MariaDB、PostgreSQL、Oracle、Microsoft SQL Server、Amazon Auroraに対応。
※独自進化を遂げて違いが大きくなっているが、一応AuroraはRDSの一部
インスタンスタイプ
インスタンスタイプはざっくりでも覚えておくと得点が拾える場合があるので覚えておく。
| インスタンスファミリー | タイプ | 特徴 | ユースケース |
|---|---|---|---|
| メモリ最適化 | R4, R5, R5b, R5d, R6g, X1, X1e, X2g, Z1d | メモリ内の大きいデータセットを処理するワークロードに対して高速なパフォーマンスを実現 | メモリ負荷が高く、ハイパフォーマンスを求められるワークロード |
| 汎用 | M4, M5, M5d, M6g | バランスの取れたコンピューティング、メモリ、NWリソース | 一般的な商用データベースなど |
| 汎用(バーストパフォーマンス) | T2, T3, T4g | 通常時に蓄積したクレジットをスパイク時に消費することで一時的にパフォーマンスを引き上げられる | 予測不可能なワークロード、試験環境等の小規模データベース |
ストレージタイプ
| ストレージタイプ | 特徴 | ユースケース |
|---|---|---|
| 汎用SSD | コスト効率が高くバランスの良いタイプ、ボリュームサイズによりIOPSパフォーマンスベースライン(発揮できるIOPSの上限)が決まる | 一般的な用途、コスト削減が求められる場合 |
| プロビジョンドIOPS | 低I/Oレイテンシーで一貫したI/Oスループットを実現 | DBI/O負荷の高いワークロード |
| マグネティック | 磁気ディスクを利用するタイプ、下位互換性のために残されているが、最大サイズが3TiBで最大IOPSが1,000など、いくつかの制限がある | 新規の作成は非推奨、ストレージ料金は汎用SSDより安いが、IOにも料金がかかるため結果的に割高になる |
通信の暗号化
SQLクライアントからRDS(Aurora含む)へSSL/TLSで接続するためにはAWSにより公開されているルート証明書をDLし、クライアントに設定する
(mysqlコマンドの場合、--ssl-caパラメータで証明書を指定)
mysql -h myinstance.123456789012.rds-us-east-1.amazonaws.com --ssl-ca=full_path_to_CA_certificate --ssl-mode=VERIFY_IDENTITY
SSL/TLSを有効にしない接続を拒否するには、クラスターのrequire_secure_transportパラメータをONに設定する。※MySQL5.7のみ
![]() 公式ドキュメント(RDSとAuroraそれぞれのドキュメントがあるがほぼ同じ)
公式ドキュメント(RDSとAuroraそれぞれのドキュメントがあるがほぼ同じ)
証明書の検証によるMan-in-the-middle(MITM)攻撃対策
より安全にSSL接続を行うためには、証明書検証を有効にすることでMan-in-the-middle(MITM)攻撃へ対策する。
証明書検証を有効にする方法はDB製品毎に異なる。
| DB | 方法 |
|---|---|
| MySQL |
--ssl-modeパラメータにVERIFY_CAまたはVERIFY_IDENTITYを指定する。 |
| PostgreSQL |
--ssl-modeパラメータにverify-fullを指定する。 |
| Microsoft SQL Server | 接続文字列でtrustServerCertificateパラメータをfalseにする。(trueだと検証なしで常に信用する) |
| Oracle DB | クライアント接続にssl_server_dn_match TRUEのプロパティを追加する。 |
![]() 公式ドキュメント
公式ドキュメント
IAM認証
DBへの接続をユーザ+パスワードではなくIAMクレデンシャルによって行うことができる。
![]() IAM認証利用の流れ
IAM認証利用の流れ
- 対象のインスタンス/クラスターで「IAMデータベース認証」を有効化する
- IAMユーザまたはIAMロールの作成(利用する対象に合わせて作成)
- DB内で
CREATE USER時にIDENTIFIED WITH句でAWSAuthenticationPluginを指定する - RDS APIで
generate-db-auth-tokenを呼び出し、認証トークンを取得する - 接続時のパスワードとして認証トークンを渡して接続する
CREATE USER jane_doe IDENTIFIED WITH AWSAuthenticationPlugin AS 'RDS';
RDSHOST="mysqlcluster.cluster-123456789012.us-east-1.rds.amazonaws.com"
TOKEN="$(aws rds generate-db-auth-token --hostname $RDSHOST --port 3306 --region us-west-2 --username jane_doe)"
mysql --host=$RDSHOST --port=3306 --ssl-ca=/sample_dir/global-bundle.pem --enable-cleartext-plugin --user=jane_doe --password=$TOKEN
![]() 公式ドキュメント(RDSとAuroraそれぞれのドキュメントがあるが内容はほぼ同じ)
公式ドキュメント(RDSとAuroraそれぞれのドキュメントがあるが内容はほぼ同じ)
パラメータグループとオプショングループ
RDSインスタンス/クラスターの作成時にパラメータグループとオプショングループを指定する。
それぞれ、デフォルトとカスタムから選択できる。
| 名前 | 説明 |
|---|---|
| パラメータグループ | キャッシュサイズやタイムゾーンなど、通常.cnfファイルで設定するようなRDB製品ごとのサーバパラメータの値はここで変更する |
| オプショングループ | DBエンジン固有の追加機能の有効化などの設定を行う |
動的パラメータは「すぐに適用」で適用されるが、静的パラメータはインスタンスを再起動するまで適用されない。
バックアップと復元
RDSには自動バックアップと手動スナップショットがある。
ポイントをいくつか覚えておく。
- 自動バックアップの最大保持日数は35日、それ以上保持したい場合Lambdaなどで定期的にスナップショットを作成する
- 自動バックアップはS3等へコピーできない
- 自動バックアップはインスタンスと同一のリージョンにしか作成できない
- 自動バックアップはレプリケーションを有効にすることで別リージョンへコピーすることができる
- 自動バックアップを削除したい時は、保持期間を0にする
- スナップショットはS3等へコピーできない
- スナップショットは別リージョンへコピーできる
- スナップショットからデータをS3へエクスポートし、Athena, Redshiftなどで利用することができる
移行
オンプレなどからRDSへ移行する方法はいくつかある。
- mysqldumpによる移行は時間はかかるが、低コスト
- 短時間での移行が求められる場合、
Percona XtraBackupが推奨
![]() 公式ドキュメント
公式ドキュメント
Performance Insights
インスタンスまたはクラスター単位で有効化しておくことで、負荷のかかっているクエリなどをモニタリングできる。
作成済みインスタンス/クラスターに対して、後から有効化することもできる。
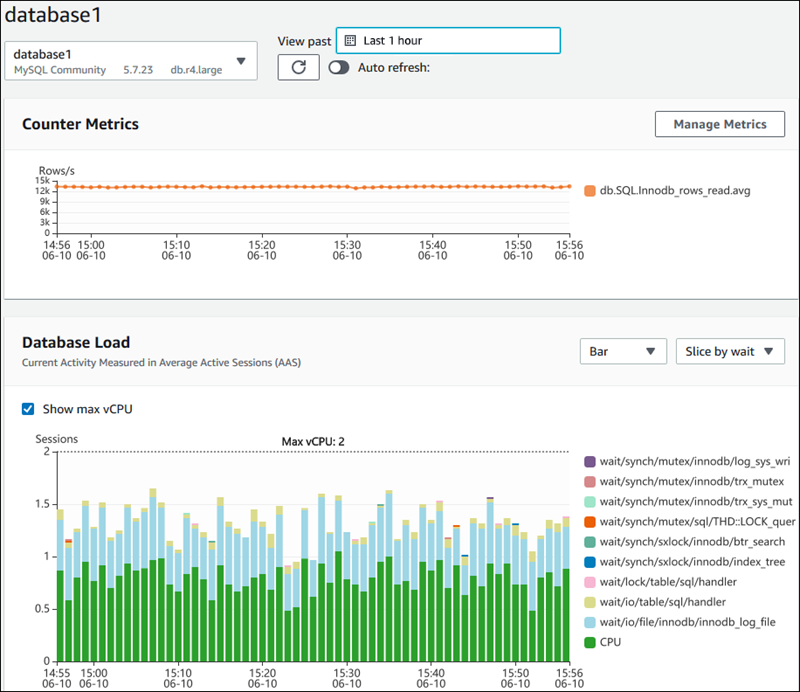
![]() 公式ドキュメント
公式ドキュメント
![]() 参考になるサイト
参考になるサイト
AWS Trusted AdvisorによるRDSコスト最適化
Trusted AdvisorはRDSのデータベースインスタンス、リードレプリカ、データベースパラメータグループなどのデータベースリソースに対して自動化された推奨事項を提示してくれる。
その他ポイントメモ
- パブリックアクセスはダウンタイムゼロで削除できる(パブリックアクセスする構成で稼働開始してしまったが、安全のためプライベートからしかアクセスしない構成にしたいときなど)
- RDSのTZの変更はリブートを必要としない、新しいセッションから有効になる
-
reserved-memory-percentパラメータを指定することでデータ以外に使用できるメモリ量を変更できる - 拡張監査の有効化: https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Auditing.html
- マルチAZは同期レプリケーション、リードレプリカは非同期レプリケーション
Amazon Aurora
MySQL, PostgreSQLをベースにAmazonが独自に拡張したRDB。
通常のRDS for MySQLやRDS for PostgreSQLとはアーキテクチャが異なる。
特にストレージレイヤがクラスタ化されていることがAurora以外のRDSとの大きな違いで、これにより本来RDBMSが苦手とする柔軟な垂直スケーリングを可能にしている。
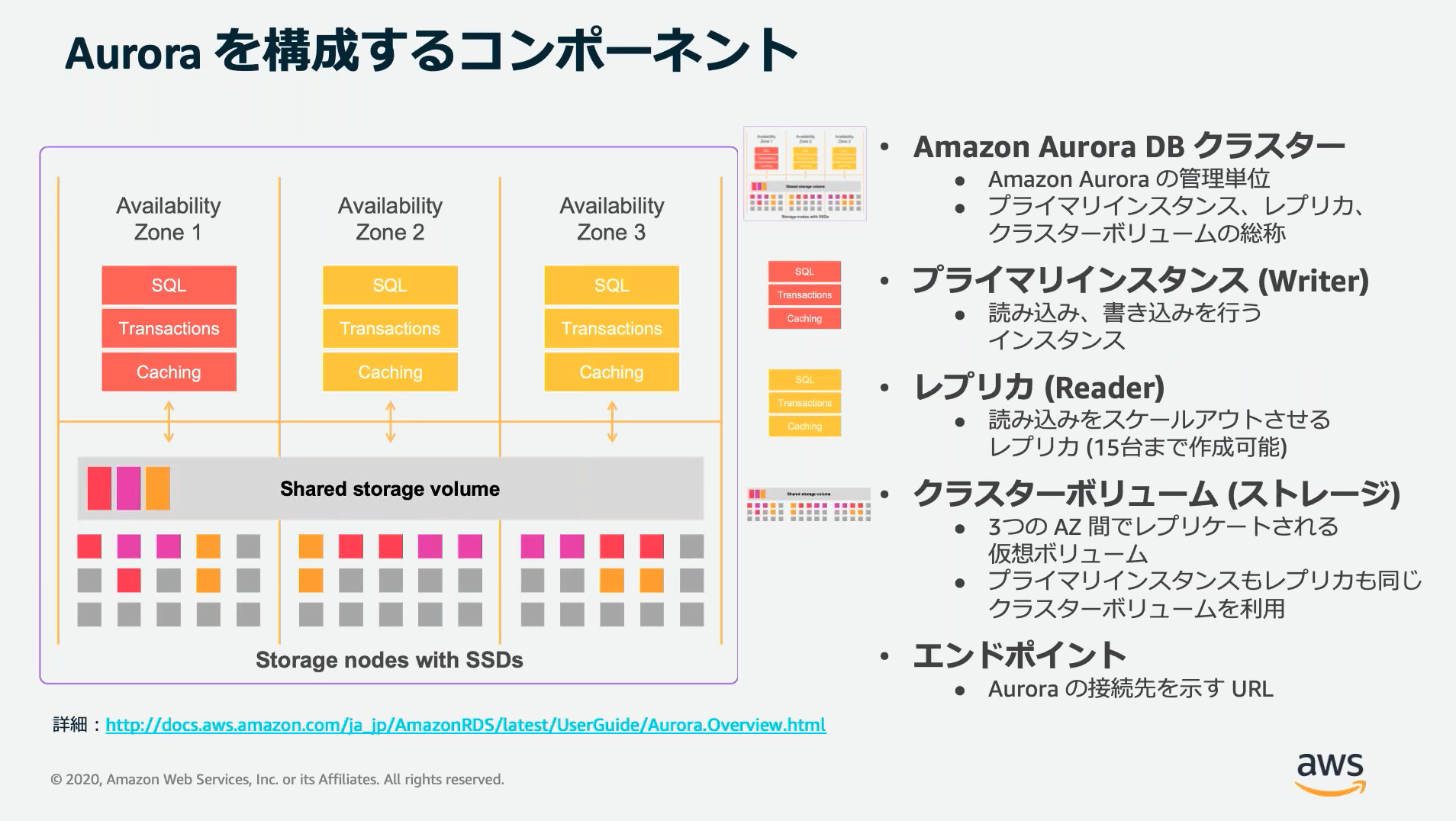
![]() 参考資料
参考資料
RDSからAuroraへの移行
RDSからAuroraへの移行方法としては下記の2つが推奨、どちらも無停止で簡単に行える。
- RDSスナップショットからAuroraクラスターを作成
- RDSのリードレプリカをAuroraのライターへ昇格(プロモート)
Auroraグローバルデータベース
複数のリージョンにまたがる単一のAuroraデータベースを作成し、グローバルに分散したアプリケーションを実行できる。
Auroraグローバルデータベースは書き込みのできるプライマリリージョンのプライマリDBクラスターを1つと、読み取り専用の最大5つのセカンダリリージョンのDBクラスターで構成される。
セカンダリリージョンへのレプリケートのレイテンシは1秒未満。
![]() 公式ドキュメント
公式ドキュメント
リージョンをまたいだフェイルオーバー
プライマリリージョンが正常に稼働している状態でプライマリリージョンを他のリージョンに切り替えたい場合、マネコンからクラスターを選択し「アクション」から簡単にフェイルオーバーさせられる。
プライマリリージョンが停止してしまった場合のリージョンをまたいだフェイルオーバーは少し複雑になる。手順は下記
- 新しくプライマリリージョンにしたいリージョンのクラスターをグローバルデータベースから削除(デタッチ)する
- データの不整合を防ぐため、その他のリージョンもデタッチしておく
- アプリケーションの書き込み先をフェイルオーバ先のリージョンのエンドポイントに変更する
- フェイルオーバ先のクラスターで「リージョンの追加」を行うことで新しいグローバルデータベースが構成される
クエリの監視
Auroraではアクティビティストリーミング機能を利用することでリアルタイムでSELECTやINSERTなどのアクティビティを監視し、証跡を保存できる。
アクティビティストリーミングはKinesisデータストリームとして取得できるため、S3などに出力し保存することができる。
![]() 公式ドキュメント
公式ドキュメント
Fault injection(障害挿入)クエリ
AuroraではFault injection(障害挿入)クエリと呼ばれるSQLを利用して障害イベントの発生をシミュレートできる。
SIMULATEを指定することで、レプリカの自動プロモートなどのフェイルオーバーをテストできる。CRASHの場合、フェイルオーバーは発生しない。
ALTER SYSTEM CRASH INSTANCE;
-- ディスクの50%を2時間障害状態にする
ALTER SYSTEM SIMULATE 50 PERCENT DISK FAILURE
FOR INTERVAL 2 HOUR;
![]() 公式ドキュメント
公式ドキュメント
MySQLバージョンのアップデート
AuroraではMySQLバージョンのインプレースアップデートが行える。ダウンタイムが発生するが、その他の方法でも無停止でのアップデートはできないため、この方法が一番シンプルで停止時間を短くできる。
![]() 公式更新情報
公式更新情報
クローンの作成
Auroraでは既存のDBと同一のDBを新しく作成したいときに利用できる「クローン」という機能がある。
「クローン」は作成元のクラスターとストレージを共有するため、ストレージを無駄にしないうえ短時間で作成することができる。
この方式を「コピーオンライト」という。
![]() Aから作成されたクローンBはクローン後のBに対して行われた更新差分のみ別の場所に書き出し、Aへの更新は読み込まない。
Aから作成されたクローンBはクローン後のBに対して行われた更新差分のみ別の場所に書き出し、Aへの更新は読み込まない。
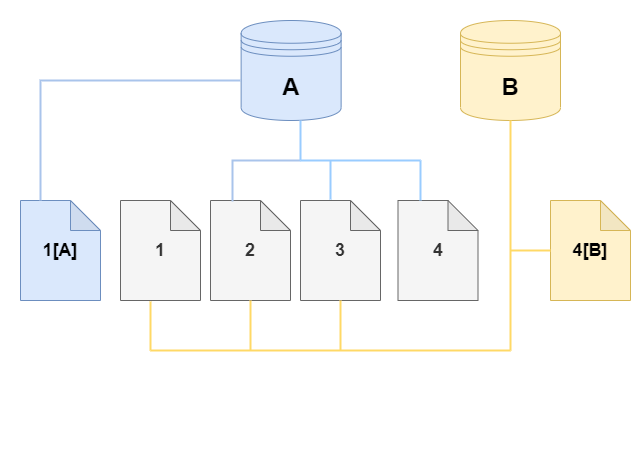
本番環境に影響を与えず本番のデータで検証や調査をしたい時など、スナップショットからの復元などの単純な複製より低コスト/短時間で利用できる。
![]() 公式ドキュメント
公式ドキュメント
その他ポイントメモ
- マルチマスタークラスター:Auroraでは同一リージョン内に2つのライタを作成できる
- Auroraでは自動でロードバランシングされるリーダーエンドポイントが利用可能
Amazon DynamoDB
2012/01から提供されているAWS独自のフルマネージドNoSQLサービス、基本的なところはいまさらなので割愛。
![]() 参考になるサイト
参考になるサイト
セカンダリインデックス
DynamoDBはKVSなのでキー指定以外でのデータ取得はパフォーマンスが落ちる。(フルスキャンし、その中から抽出する形になってしまう)
そのため、パーティションキーとソートキーを変更したテーブルの属性のサブセットを作成できる。これを「セカンダリインデックス」という。
セカンダリインデックスにはLSI(ローカルセカンダリインデックス)とGSI(グローバルセカンダリインデックス)の2種類ある。
| 種類 | 説明 | ユースケース |
|---|---|---|
| LSI(ローカルセカンダリインデックス) | パーティションキーはベーステーブルと同一で、異なるソートキーを設定したもの | ベーステーブルのパーティションキー+その他の属性で絞り込みたい場合 |
| GSI(グローバルセカンダリインデックス) | ベーステーブルと異なるパーティションキーを設定したもの | ベーステーブルのパーティションキーを使わずにその他の属性で絞り込みたい場合 |
- GSIは独自のスループット設定を持つため、ベーステーブルと同じ頻度の読み書きが発生する場合、コストはおよそ倍になると思っていい。
- LSIはベーステーブルのスループット設定を共有する。
- GSIは結果整合性しか担保しない、強い整合性が必要な場合別のテーブルを作成する。
![]() 公式ドキュメント
公式ドキュメント
プロビジョニングモードのCU計算
CU(キャパシティユニット)の計算問題は他の認定試験でも何度か見たので、覚えておく。
| R or W | 説明 |
|---|---|
| 1RCU | ・4KB以下の1秒あたり1回の強い一貫性の読み込み、1秒あたり2回の結果整合性読み込み ・トランザクション読み込みの場合は強い一貫性の2倍消費 |
| 1WCU | ・1KB以下の1秒あたり1回の書き込み ・トランザクション書き込みの場合は2倍消費 |
例) 10KB/sのトランザクション読み込みの場合
10KB / 4KB = 3 ←切り上げ
3 * 2 = 6RCU ←トランザクションで2倍
WCUは「1 回/ 1 KB/ 1 秒」なので覚えやすい。
RCUは強い一貫性を基準に、消費量が
「トランザクションは倍」 > 「強いのが4」 > 「弱いのは半分」
(複数アイテムの整合性 > 1アイテムの強い整合性 > 1アイテムの弱い整合性)
で覚える。
DAX(DynamoDB Accelerator)
DAXはDynamoDBの読み込み性能を向上させるためのインメモリキャッシュ
DAXなしの場合1桁台のミリ秒単位 → DAX利用によりマイクロ秒単位まで応答時間を短縮
キャッシュのため、繰り返し読み込みが発生するようなユースケースで特に性能向上やコスト削減に活用できる。
反対に書き込みの多いワークロードの場合、コストが大幅に上昇する可能性がある。
強い結果整合性には対応していない。
その他ポイントメモ
- グローバルテーブルはマルチリージョン、マルチマスター、各リージョンのレプリカテーブル同士で変更を伝播し合う
- TTLによって削除された項目をアーカイブなどしたい場合、DynamoDB Streamを有効にし、
Filterでdynamodb.amazonaws.comがprincipalIdとなっているものだけ抽出することでTTLによって削除された項目を特定できる: https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/time-to-live-ttl-streams.html - DynamoDBには自動バックアップ機能はない、PITRは最大35日間、それ以上の自動バックアップを行いたい場合、DynamoDB Stream + Kinesis Firehose + Lambdaなどで実現
- PITRの復元は異なるリージョンでも行うことができる、これによりリージョン間のテーブルコピーも可能
- DynamoDBのテーブル設計のポイントはホットパーティションが発生しない(多重度(カーディナリティ)の高くなるキーを設定)ようパーティションキーを設計すること、GSIのパーティションキーも同様
- Projection Expression(射影式): https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Expressions.ProjectionExpressions.html
- トランザクション読み込み/書き込み: https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/transaction-apis.html
- VPCエンドポイントはゲートウェイエンドポイントとインターフェイスエンドポイントがあるが、DynamoDBはゲートウェイエンドポイント
- バックアップからの復元時は、オートスケーリング、TTL、リソースポリシー、タグ、アラーム、DynamoDB Streamの設定は引き継がれない
- 1アイテムは最大400KB
Amazon Redshift
PostgreSQLをベースにデータの集計・分析(OLAP)用に拡張したマネージドのデータウェアハウス/データレイク分析サービス
![]() 参考資料
参考資料
特徴
- VPC内で動作(=SGなどで保護)
- クエリ先のデータはS3に保存する
- データ分析の効率化のため、データは列指向で保持される
- データは保存時に自動圧縮される
- 結果はコンピュートノードでキャッシュされる
- SQLを利用でき、マネコン上でSQLを実行できる「クエリエディタ」が用意されている
- Elastic Resize機能を使うと短時間でノード数のスケールイン/スケールアウトが可能、スケジュール設定もできる
アーキテクチャ
リーダーノード、コンピュートノード、ストレージの3層に分かれており、必要に応じてコンピュートノードとストレージをスケーリングする。
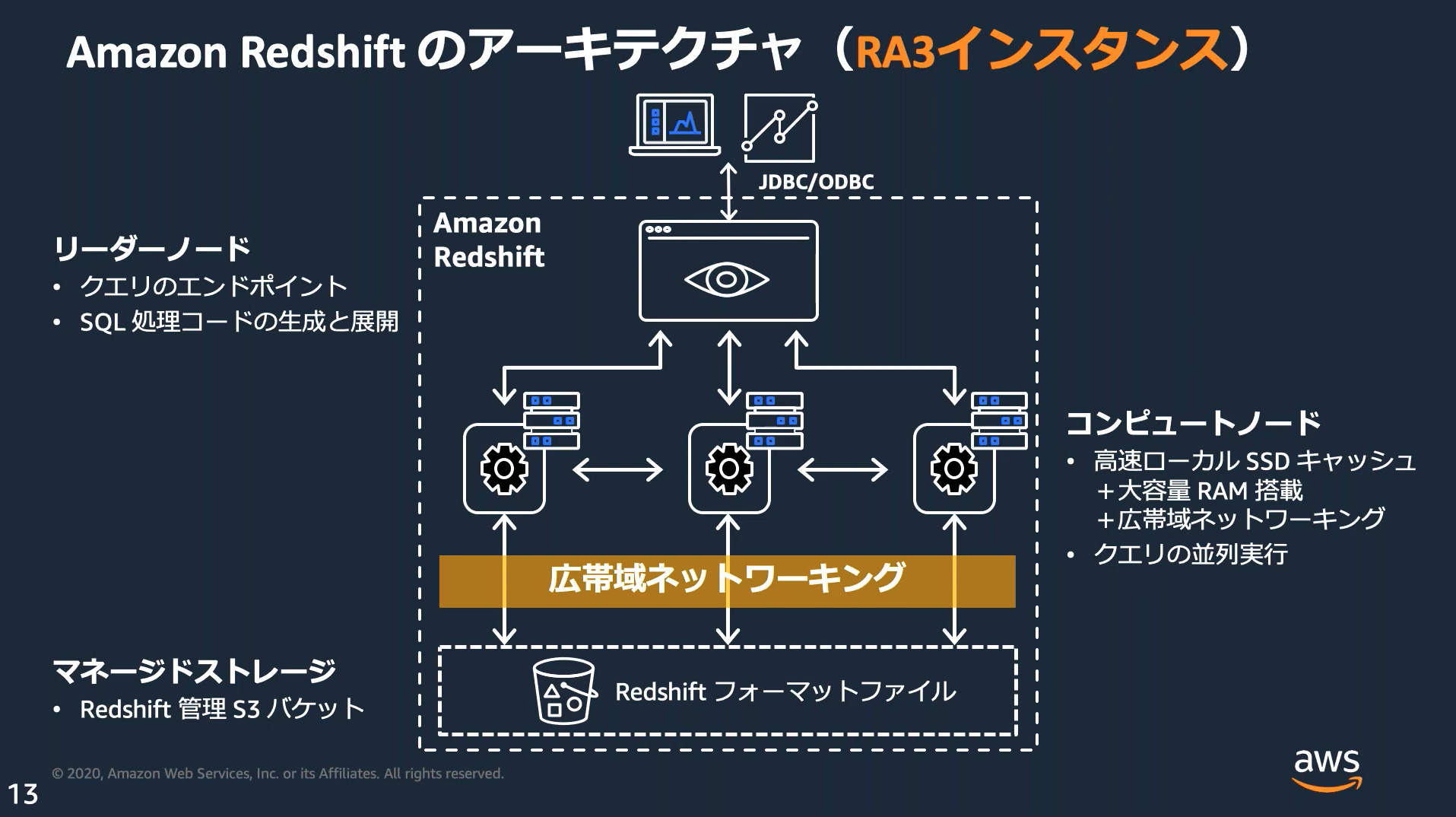
Concurrency Scaling
Concurrency Scaling(同時実行スケーリング)を利用すると負荷に応じて自動的にクラスターをスケールイン/スケールアウトする。
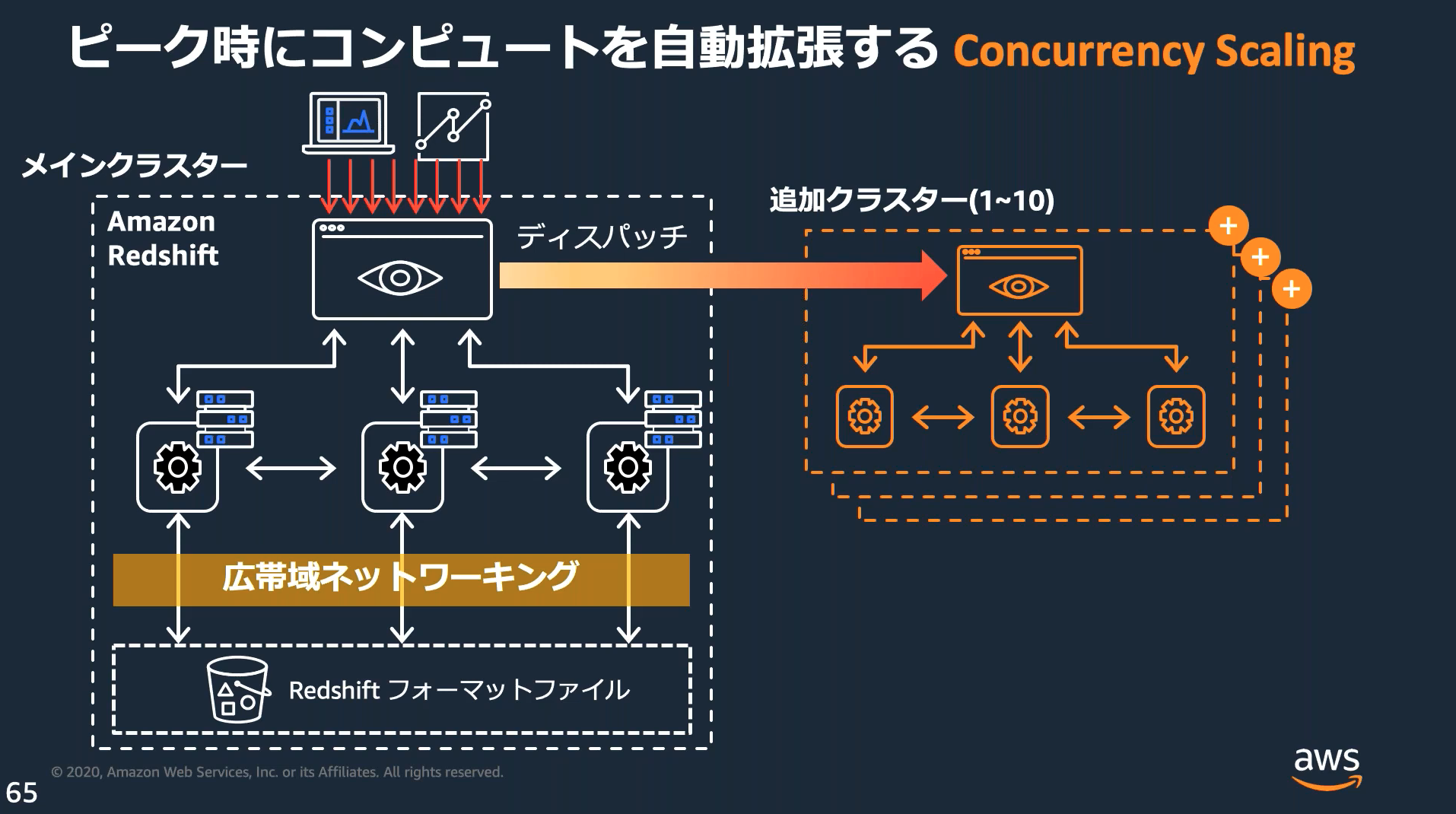
Amazon Redshift Spectrum
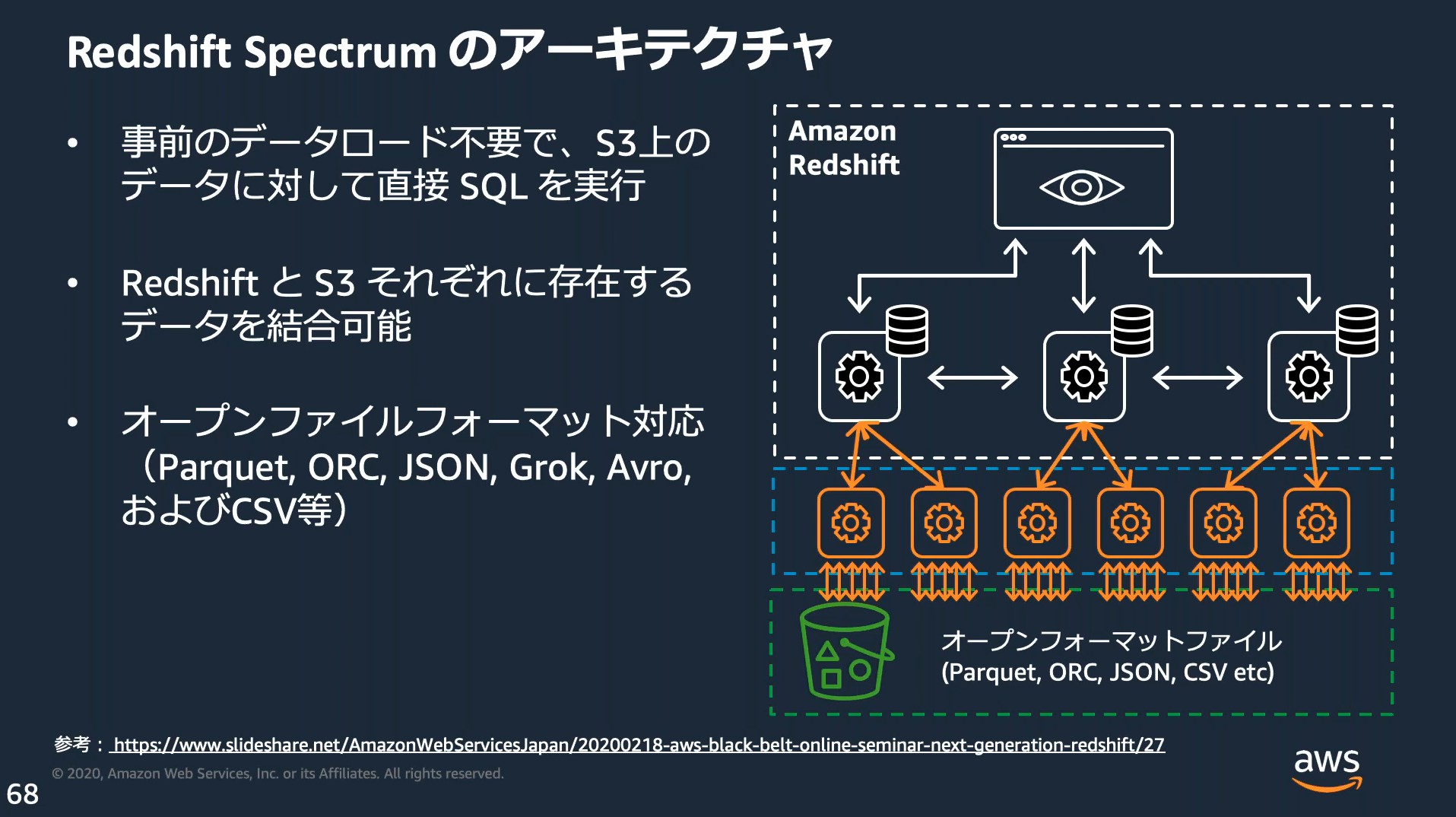
ユーザ管理のS3バケットに配置したファイルに対し、Redshiftから直接クエリできる。
Parquet形式(データ分析用の共通フォーマット)でファイルを出力しておくと、Redshift以外でも扱いやすい。
Kinesis FirehoseやGlueはこのフォーマットでの出力をサポートしている。

Amazon Redshift Advisor
作成済みのクラスターに対し、ソートキーや圧縮エンコードなどパフォーマンスの最適化のための改善事項をサジェストしてくれる「アドバイザー」という機能がある
![]() 公式ドキュメント
公式ドキュメント
Amazon ElastiCache
フルマネージドの分散インメモリキャッシュサービス、memcachedとRedisから選択可能
![]() 参考になるサイト
参考になるサイト
特徴
- VPC内で動作(=SGなどで保護)
- よりシンプルなキャッシュにはmemcachedを、高機能なキャッシュを求める場合Redisを選択する
- 必要なメモリとNWパフォーマンスに応じて、ノードタイプを選択する
シャード/ノード/クラスター
シャード、ノード、クラスターの関係は以下
| 要素 | 説明 |
|---|---|
| ノード(Node) | ElastiCacheの最小単位で、保存領域(RAM)を持つ。 設定したノードタイプによってCPU性能や保存領域のサイズが異なる。ノードの最大数は90(クラスタモード有効時の全シャードの合計) |
| シャード(Shard) | 複数のノードをまとめるグループ、読み書き可能な1つのプライマリノードと読み込み専用の0~5個のセカンダリノードを持つ。 |
| クラスター(Cluster) | 複数のシャードをまとめるグループ、クラスタモードを無効にするとシャードが常に1つになる。 |
クラスターモードを有効にすると書込み可能なプライマリノードが複数に分散されるため、クラスターモードは書き込みが多いワークロードに適している。
クラスターモードの有効化はクラスター作成時しかできない。

![]() 公式ドキュメント
公式ドキュメント
Global Datastore
Global Datastoreを利用することで、リージョンをまたいだクラスターのレプリケーションが行える。
リージョン障害の際にセカンダリクラスターをプライマリにプロモート(昇格)する。
![]() 公式ドキュメント
公式ドキュメント
キャッシュ戦略
ElastiCache固有の話ではないが、キャッシュの設計をする際はキャッシュ戦略を意識する。
| 戦略 | 説明 | 特徴 |
|---|---|---|
| リードスルー(Read-through) ※遅延読み込みとも言う |
読み込み時にキャッシュにない、またはキャッシュ期限が切れていたらオリジナルから読み込み、キャッシュも更新する | キャッシュミスによる読み込み遅延が発生する、書き込み時はキャッシュを更新しないので性能影響がない |
| ライトスルー(Write-through) | 更新の際に常にキャッシュも更新する | 読み込みへの性能影響が減るが、書き込みが遅くなり、キャッシュに利用するストレージ容量がかさむ |
| ライトバック(Write-back) ※ライトビハインドとも言う |
データ書き込み時にキャッシュのみ更新しておき、キャッシュが期限切れなどで追い出される際や一定時間後に時間差でオリジナルに書き込む | 書き込み時の性能影響が少ないが、オリジナルが常に最新ではないことを許容する必要がある |
Amazon DocumentDB
マネージドのドキュメント指向DB(MongoDB)
![]() 参考資料
参考資料
そもそもMongoDBってなんだっけ?となったら↓この辺の記事を読む。
特徴
- VPC内で動作(=SGなどで保護)
- MongoDB CE3.6互換
- 15台までリードレプリカを作成可能、リードレプリカ昇格による自動フェイルオーバも可能
- メモリは15~768GiBで設定可能
- ストレージ容量は10GB~64TBで自動拡張
- S3へのストリームバックアップと最大35日のPITR、バックアップは性能影響なし
- 手動のスナップショット作成により35日以上バックアップ保存も可能
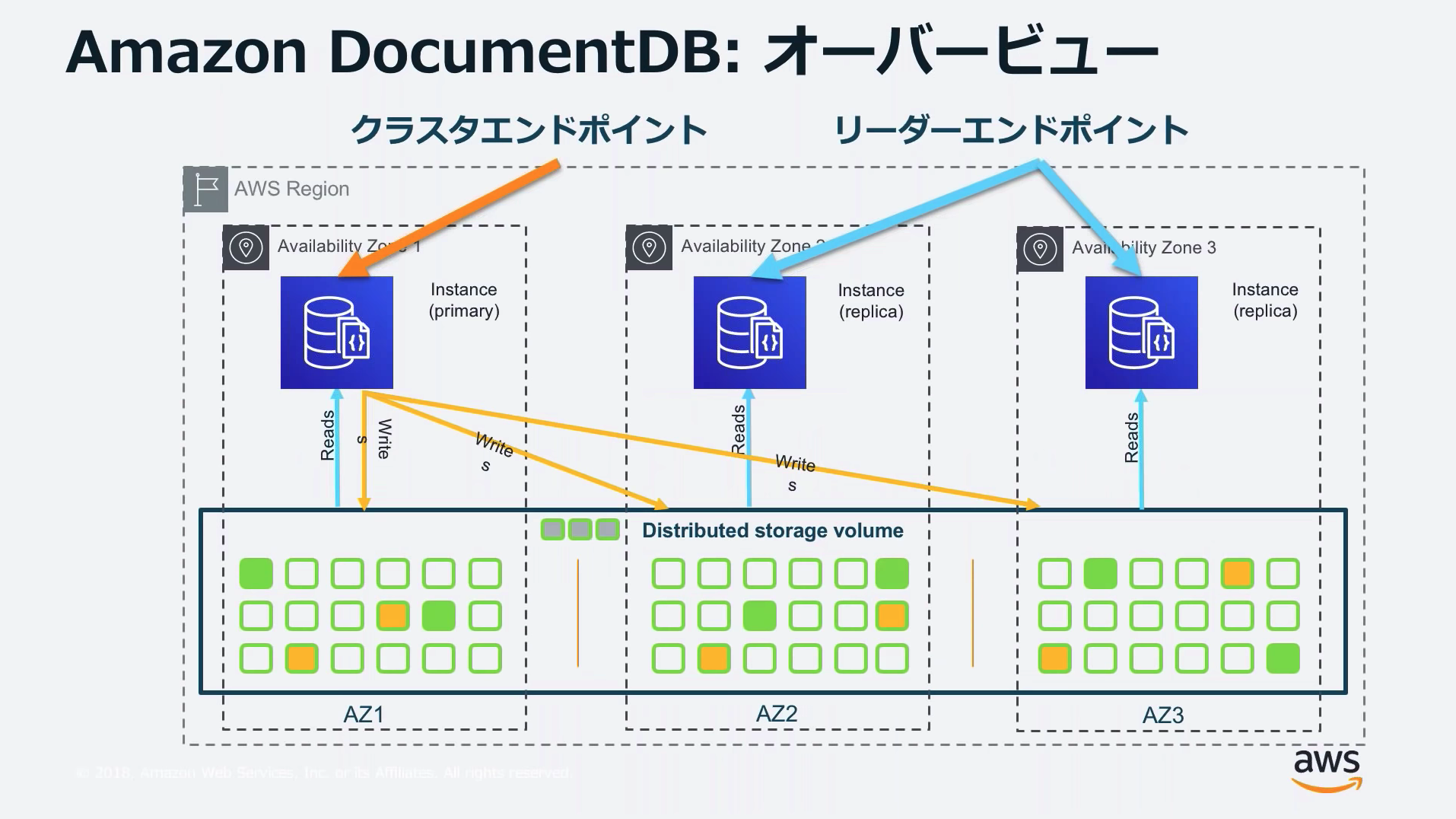
アーキテクチャ
1つのライタと複数のリーダを持つクラスタを作成し、クラスタ全体のエンドポイントとリード用のエンドポイントをクライアントが使い分ける。
Auroraの構成に似ている。
DynamoDBとの使い分け
DynamoDBでもドキュメント型をサポートしていて、ドキュメント内の属性に対して条件を指定したクエリもできるが、DocumentDBのほうがアプリケーション側がシンプルになる(らしい)。
既存でMongoDBを使っていて移行したい場合や、ネストされた複雑なJSONを保存し、内側の属性を条件にしたフィルタリングを行いたい場合以外ではDynamoDBのほうが優位というのが個人的な感想。

プロファイラー
個々のクエリパフォーマンスとクラスター全体のパフォーマンスをモニタリングする機能として「プロファイラー」がある。
「プロファイラー」を有効にするとスロークエリログがCloudwatch Logsに出力される。
![]() 公式ドキュメント
公式ドキュメント
Amazon Neptune
マネージドのグラフ指向DB
![]() 参考資料
参考資料
グラフ指向DB
SNSのユーザ同士の繋がりなど「多対多」の情報を格納するのに適している
![]() 参考資料
参考資料
グラフ理論に基づくデータモデル
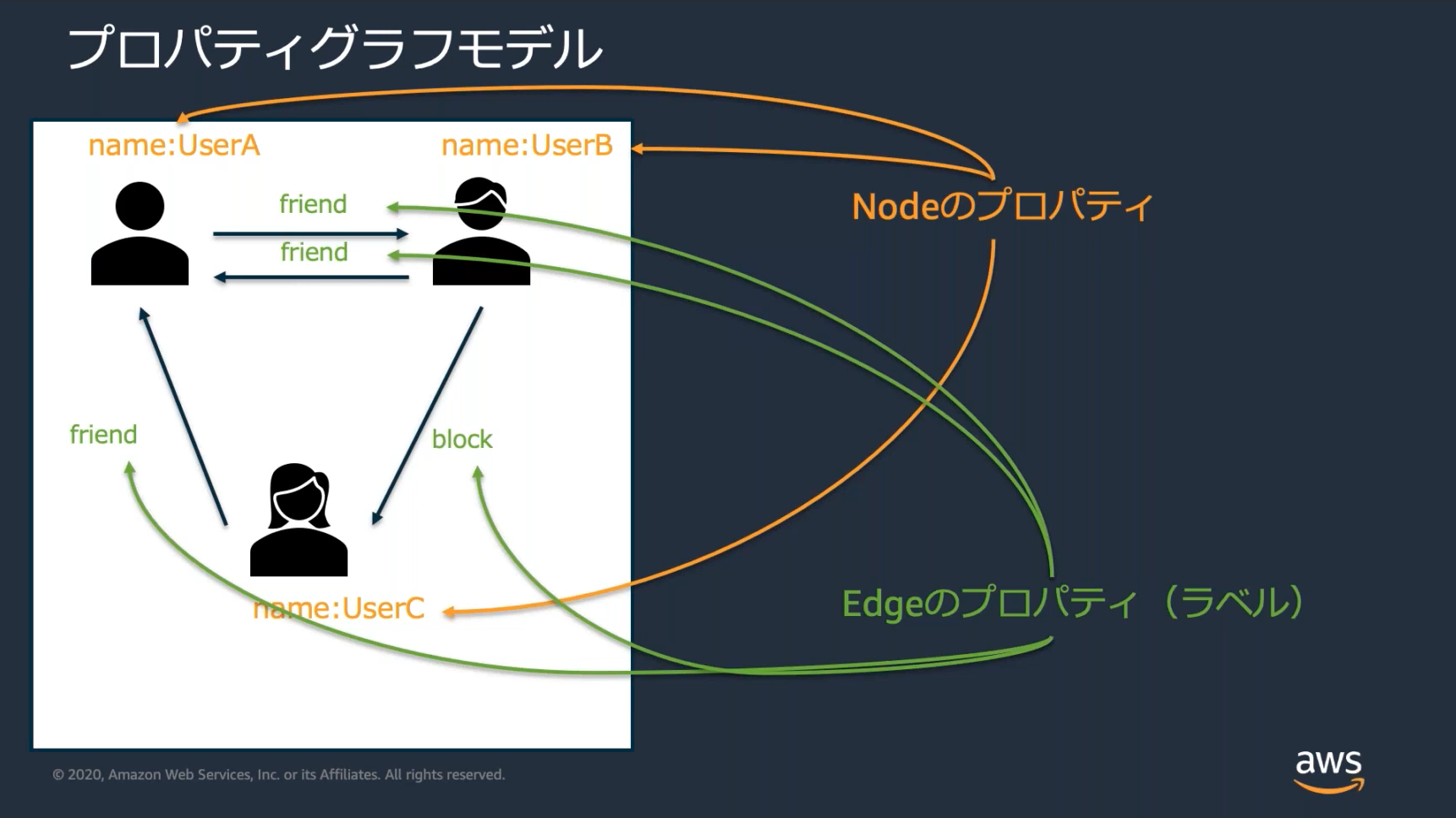
「関連するデータに更に関連するデータ」など探索的なデータ抽出を簡潔に行えるのがグラフ指向のメリット
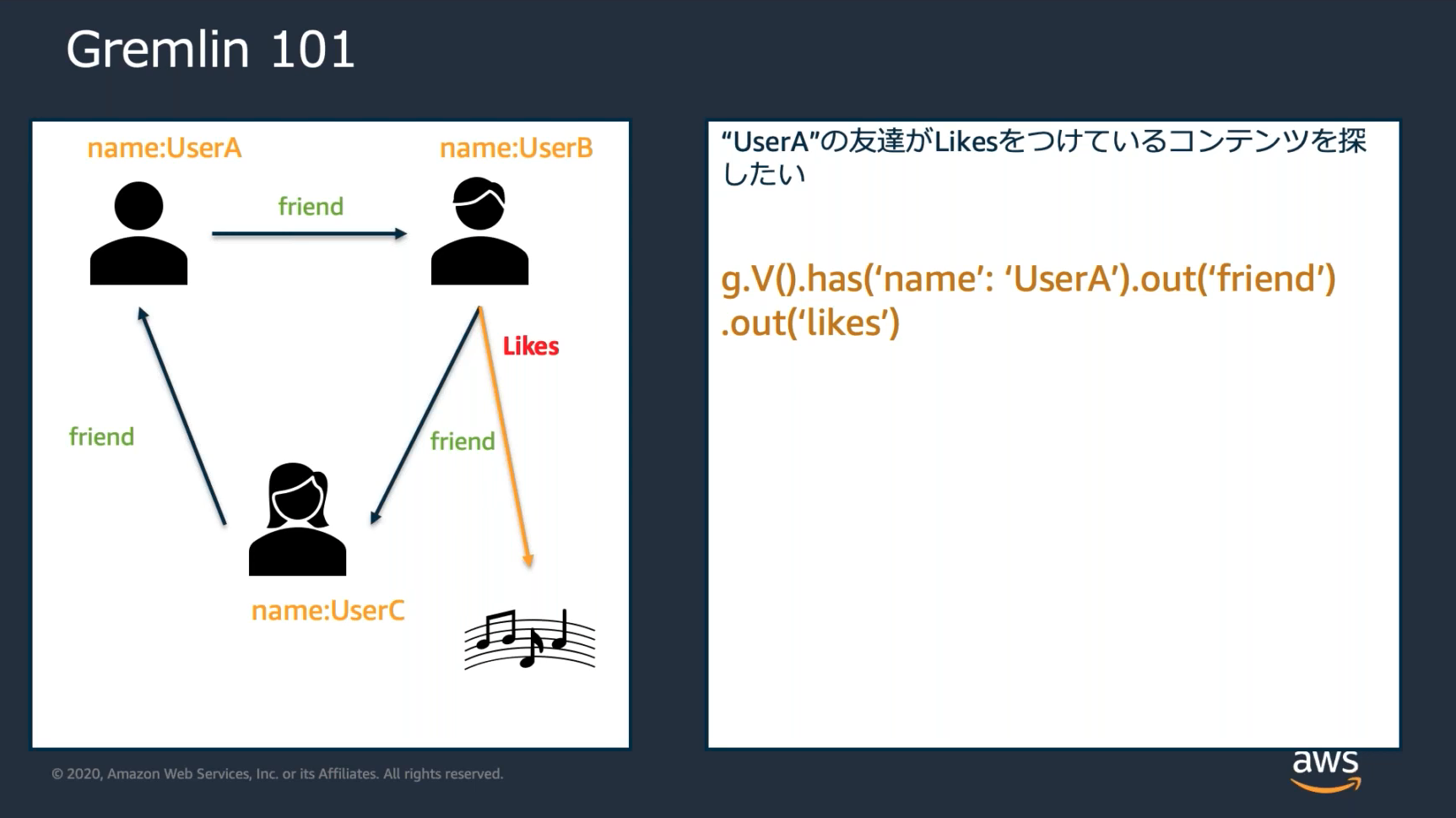
![]() グラフ指向DBのもっと詳しい話
グラフ指向DBのもっと詳しい話
https://www.imagazine.co.jp/12805-2/
特徴
- VPC内で動作(=SGなどで保護)
- OLTPに最適化され、毎秒100,000件のクエリをサポート
- 15台までリードレプリカを作成可能、リードレプリカ昇格による自動フェイルオーバも可能
- インデックスは自動作成/管理され、実行計画/プロファイルはクエリで取得可能
- ストレージ容量は10GB~64TBで自動拡張
- S3へのストリームバックアップとPITR
2つのクエリ言語
Neptuneでは2つのクエリ言語を利用できる
| 言語 | 説明 |
|---|---|
| グレムリン | PG(プロパティグラフ)に利用できる |
| SPARQL | RDF(リソース記述フレームワーク)に利用できる |
クライアント
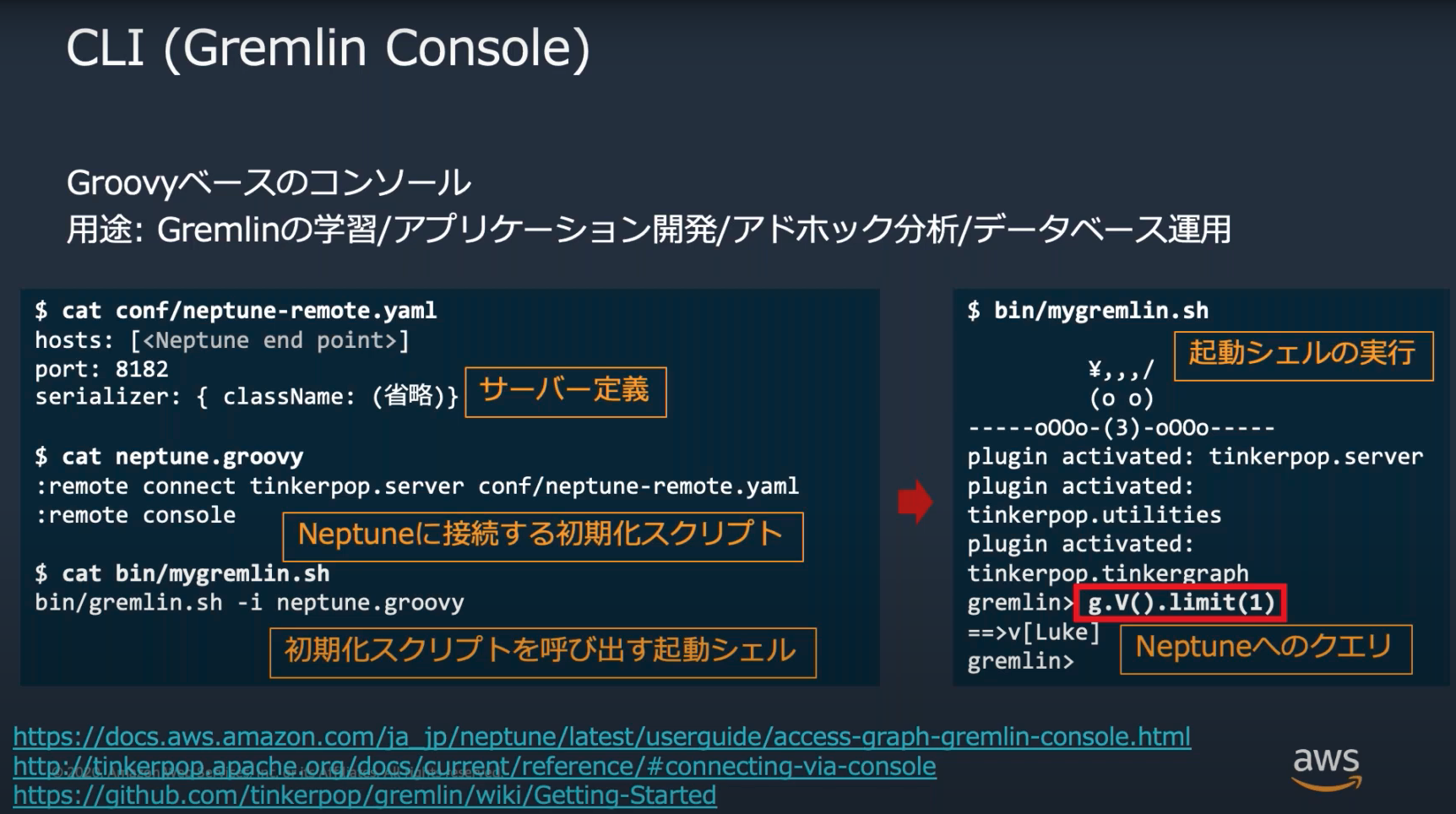
Gremlinクライアントによるクエリ等の操作が可能
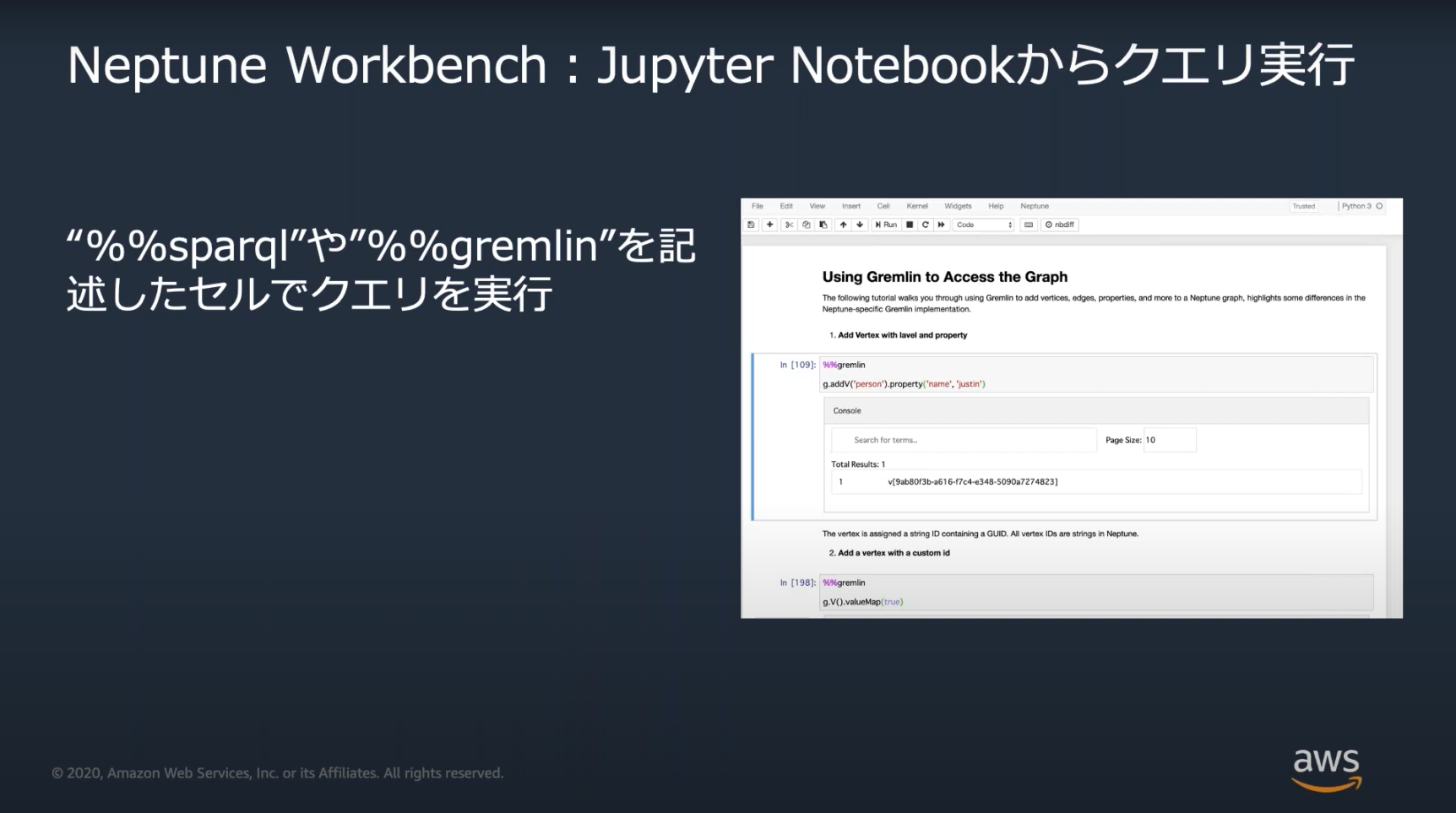
AWSではCUIのGremlinコンソールとGUIのNeptune Workbench(JupyterNotebook上で対話形式でクエリできるツール)を提供
Gremlinコンソール
Neptune Workbench
NeptuneのコンソールはSageMakerノートブックと統合されており、簡単に「Neptune Workbench」を作成できるようになっている
チューニング
Neptuneのチューニングのための方法としてexplain(実行計画)の取得とprofileの取得がある。
詳しいチューニングの方法まではおそらく出題されない。この2つの使い方だけ覚えておく。
![]() 公式ドキュメント
公式ドキュメント
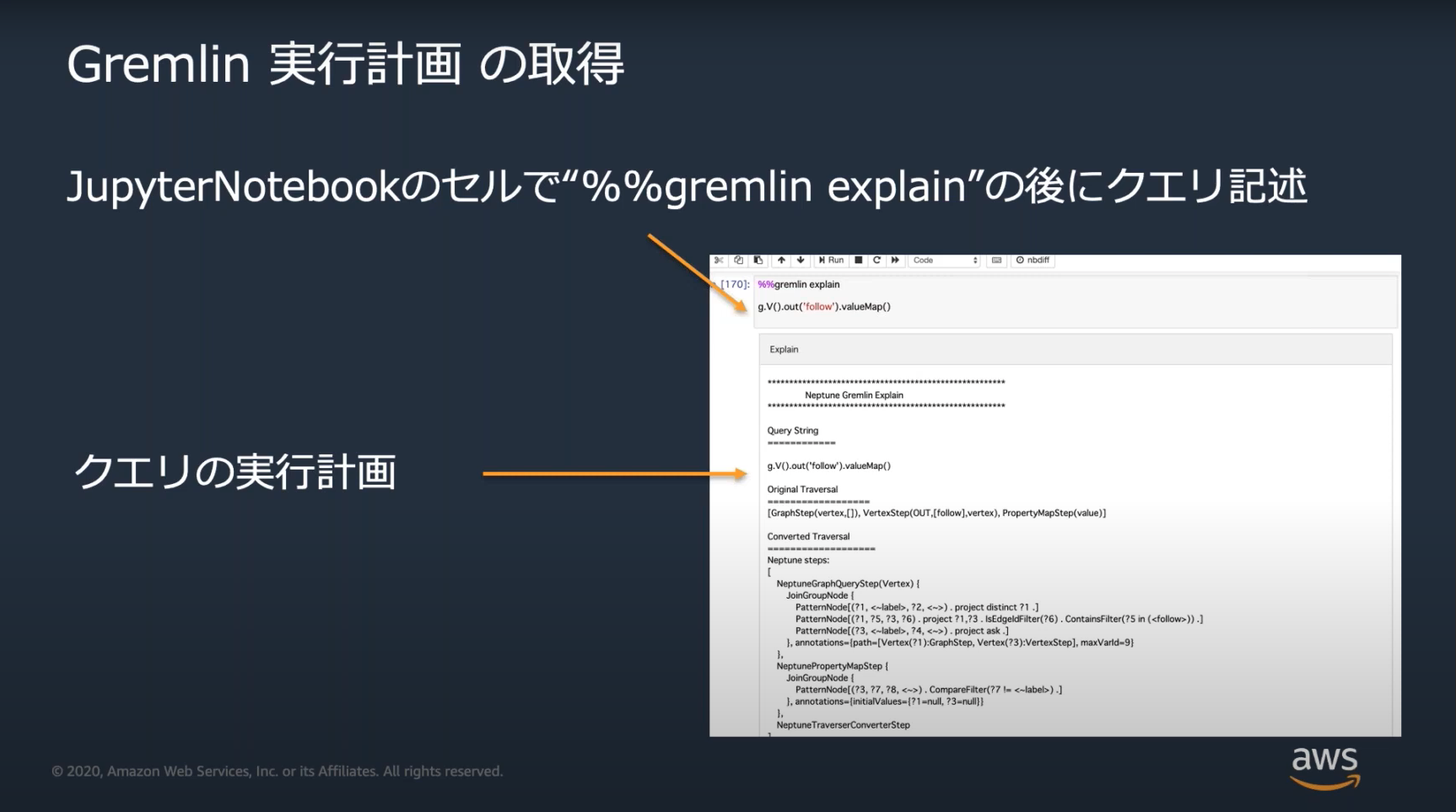
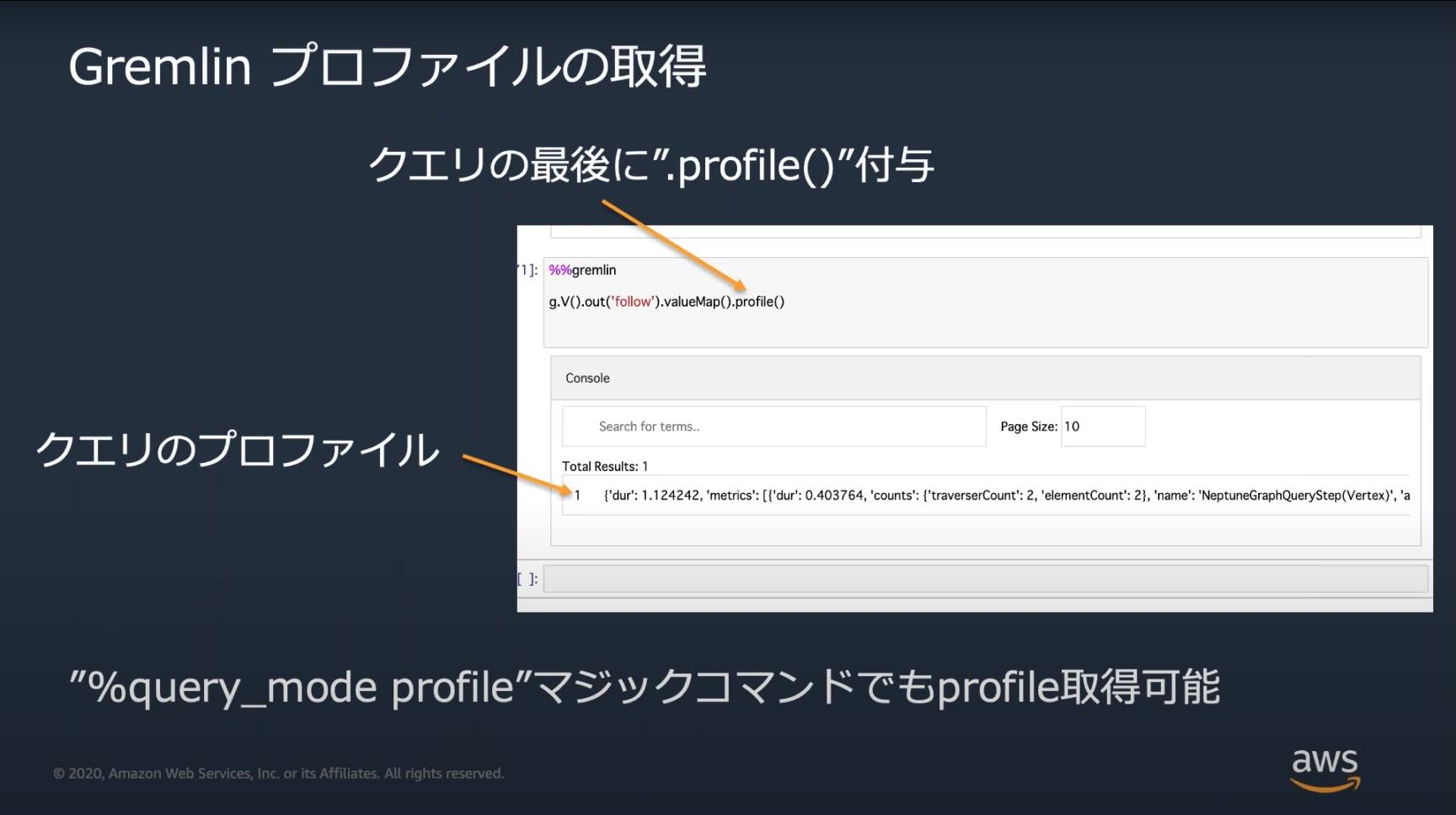
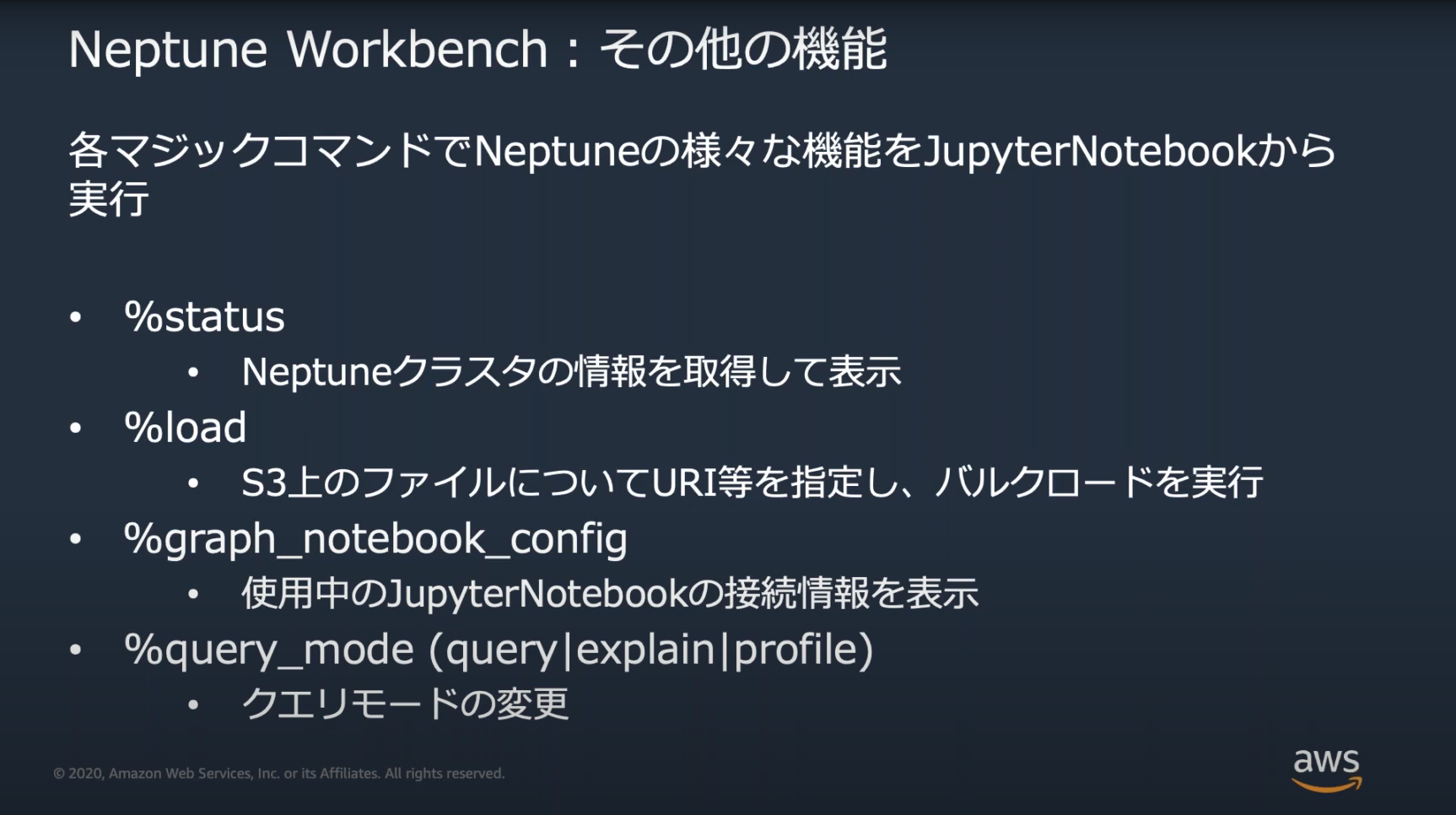
Neptune Workbenchのマジックコマンド
Neptune WorkbenchではNeptuneの操作をするためのいくつかのマジックコマンドが用意されている。
※マジックコマンド=JupyterNotebookで利用できるコマンド、先頭に%がつく。
Black Beltで紹介されるような基本的なコマンドは出題されそうなので、覚えておく。
Neptuneへの移行
オンプレなどで利用しているグラフDBからの移行、または新規サービス開始時に事前データ投入を行いたい場合、下記の方法がある
- S3にCSVを配置し、Neptune Loaderでロード
- AWS DMSで読み込み
Neptuneからテキストファイルに出力する「Neptune Export」もある
Amazon Timestream
2020/10に公開された時系列データベース
![]() 参考資料
参考資料
2022年に東京リージョンにも対応
時系列DB
参照時点での状態だけでなく、過去の履歴を秒単位の時系列で追跡するようなデータを保持するのに適している。
※IOTセンサによる観測値や為替レートなど
特徴
- フルマネージドのサーバレス構成(DynamoDBのオンデマンドに近い)、インスタンスやストレージは意識する必要がない
- スキーマの事前定義は不要、挿入されたデータに応じて格納される
- SQLを利用でき、マネコン上でSQLを実行できる「クエリエディタ」が用意されている※複数テーブルのJOIN、UPDATE、DELETEはできない
- SDKやAPI、IoT Core、Kinesisでデータ挿入できる
- SDKやCLI、SQLクライアントで出力できる
- S3へ常に自動バックアップされており、障害発生時は自動復元される。手動バックアップ/復元機能はない
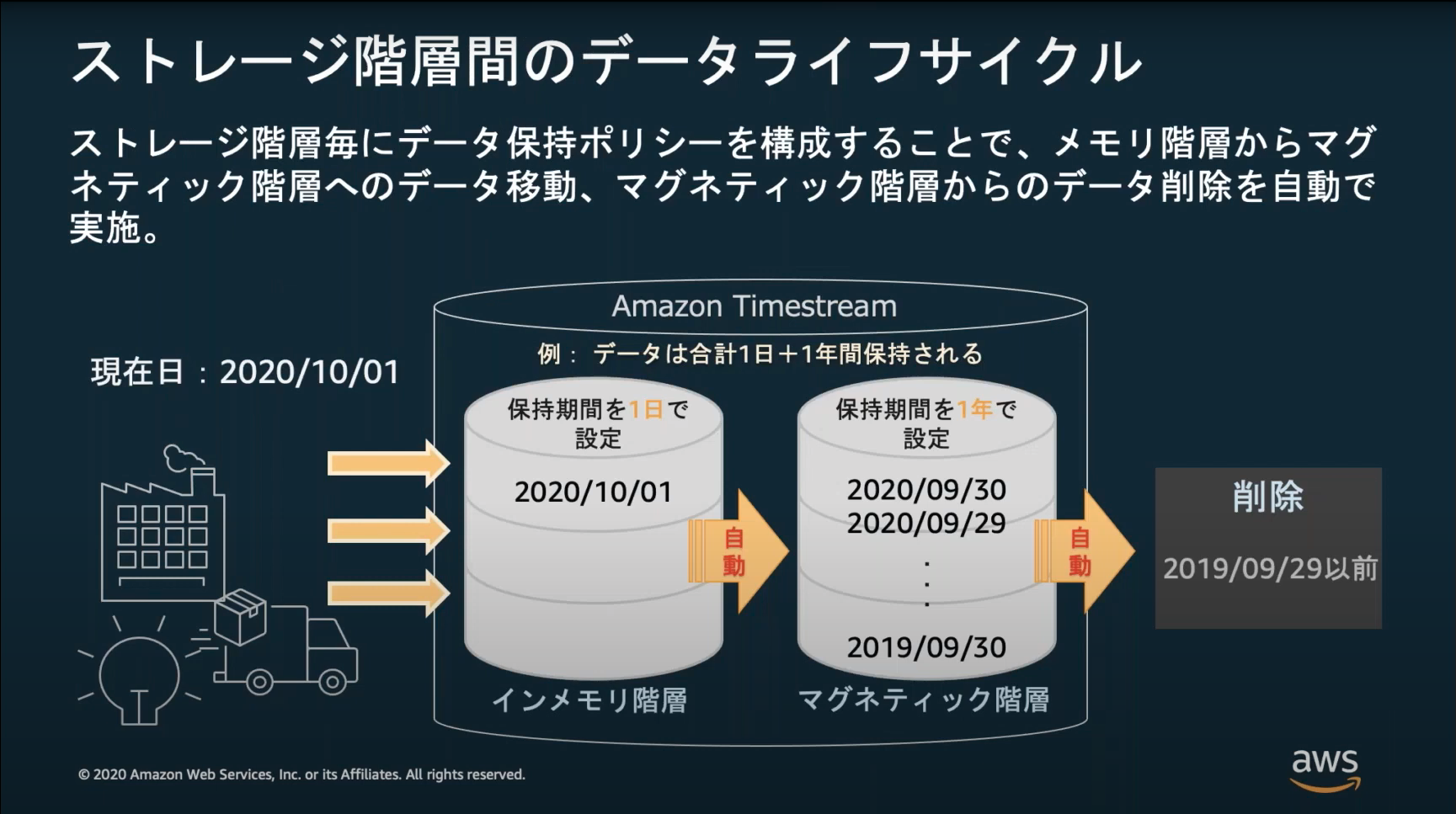
ストレージ階層
インメモリとマグネティックの2つのストレージ階層があり、コストが異なる(インメモリ=$0.036/時間, マグネティック=$0.03/月)のでライフサイクル設定により適したストレージに格納させる。
未来のタイムスタンプやマグネティック階層で保持される日時のタイムスタンプでデータ挿入はできない。
秒単位で履歴を残していく場合、格納するデータ量は大容量になる可能性があるので上記を考慮したライフサイクル設定は重要。

構成要素
構成要素や概念がRDS等とは異なるので覚えておく
| 構成要素名 | 説明 |
|---|---|
| データベース(Database) | 複数のテーブルを1つにまとめる場所、データベース単位で行えるのは暗号化設定とメトリクスの表示とタグの設定 |
| テーブル(Table) | データベース内に複数作成できる、ライフサイクルはテーブル単位で設定する |
| タイムシリーズ(Time-Series) | ディメンションをキーに複数レコードをまとめたもの、CREATE_TIME_SERIES()関数でタイムシリーズ単位の時系列モデルとして出力することで時系列データ分析を行う |
| レコード(Record) | ディメンション+タイムスタンプ+メジャーの1セット |
| ディメンション(Dimention) | 測定値を識別するための属性情報セット |
| メジャー(Measure) | 測定値、名前(measure_name)と値(measure_value)のセット |
| バージョン(Version) | レコードの新旧を判定するためのパラメータ、キー情報(ディメンション+タイムスタンプ+メジャー名)が同一のレコードが挿入された場合、バージョンが大きい時のみ更新される |

DB移行
AWS DMS(Database Migration Service)
同種の移行(Oracle→Oracleなど)、および異なるデータベースプラットフォーム間の移行(Oracle→Auroraなど)をサポート
- 異種システム間のレプリケーションの場合CPUリソースを多く利用するためC4インスタンスが適している。
AWS SCT(Schema Conversion Tool)
DBスキーマだけでなく、ビュー、ストアドプロシージャ、関数を含むデータベースコードオブジェクトの大部分を、移行先データベースと互換性のあるフォーマットに自動的に変換する
ソースとターゲットの組み合わせとして、下記を覚えておく。
- ソースにAuroraは指定できない
- ターゲットにOracleを指定できるのはソースがOracleのときのみ
- ターゲットにMicrosoft SQL Serverを指定できるのはソースがMicrosoft SQL Serverのときのみ
AWS WQF(Workload Qualification Framework)
異なるデータベースプラットフォームへの移行の際に、移行戦略と移行ツールを分析してくれるツール。
AWSサービスではなく、ツールのインストールされたAMIとしてAWS Marketplaceで提供されている。
![]() 公式ブログ
公式ブログ
Cloudwatch Contributor Insights
Cloudwatch Logsのログに対してアクセスが多いものや人を抽出することができるサービス。
DynamoDBとも統合されており、DynamoDBへのGET履歴に対する抽出も行える。※2022/07時点では統合されているサービスはDynamoDBのみ
その他
- OLTP(OnLine Transaction Processing): 複数ユーザに同時に提供されるアプリのサーバサイド処理など、多数のトランザクションを同時に実行するデータ処理
- OLAP(Online Analytical Processing): 大規模なデータベースに蓄積された膨大なデータに対して、複雑な集計・分析を行い、結果を出力する処理
RAID
どっちがどっちだか忘れるのでメモ、0と1以外はAWS認定試験ではおそらく出ないので気にしない。
| 種類 | 説明 |
|---|---|
| RAID0 | ストライピング、信頼性は上がらないが読み書きの性能は上がる |
| RAID1 | ミラーリング、読み書きの性能は上がらないが、信頼性が上がる |
他の試験の時も覚えたのに忘れていたので覚え方を考えてみた。小さなカイゼン。
バックアップの数と紐付けて、1つあるのがRAID1、ないのがRAID0と覚える。