この記事の概要
2025/01/16 に「AWS Certified AI Practitioner(AIF-C01)」を受験しました。
その時の記録です。
試験の概要
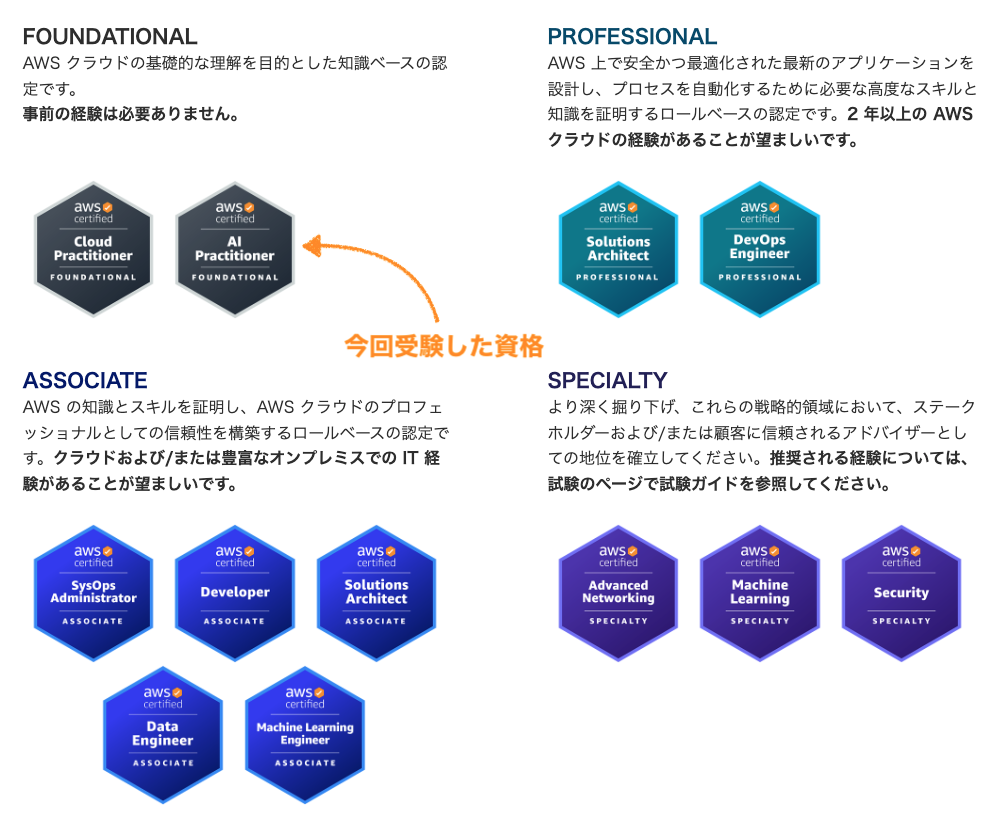
世の中のデータ活用やAIの専門知識に対する需要に合わせ、今年度は3つのAWS認定資格が追加されました。
その中で一番簡単なFOUNDATIONALレベルの資格です。
FOUNDATIONALレベルはこれまで「Cloud Plactitioner」のみだったのが、はじめて新しい資格が追加されました。
AWSの公式ガイドには
AWS Certified AI Practitioner (AIF-C01) 試験は、特特定の職務に関係なく、AI/ML、生成 AI テクノロジー、関連する AWS のサービスとツールに関する総合的な知識を効果的に実証できる個人を対象としています。
とあります。※AWS公式より引用:引用元
AWSによるAI/MLの利用や開発の入門向け資格といったところでしょう。
◼︎ 試験要項
| 項目 | 値 |
|---|---|
| 問題数 | 65問 (うち15問は採点対象外) |
| 試験時間 | 90分 |
| 受験料 | ¥15,000 (税別) |
| 合格ライン | 100~1000点中700点 |
| 受験資格 | なし |
| 有効期限 | 3年 |
※料金は為替レートに合わせて毎年4月に見直されます。アソシエイト試験は2024年度¥5,000値上がりしました。
https://aws.amazon.com/jp/certification/policies/before-testing/#Exam_pricing
「AWS Certified Machine Learning Engineer - Associate(MLA)」の下位資格の位置付けのため、3年以内にMLAに合格することでこの資格も更新されます。
https://aws.amazon.com/jp/certification/recertification/
2025/02/15まで再受験無料プロモーション実施中です。
※予約時のプロモーションコード入力による適用のため、半額バウチャーと併用は不可
◼︎ 出題範囲
| 分野 | 出題割合 |
|---|---|
| 第 1 分野: AIとMLの基礎 | 20% |
| 第 2 分野: 生成AIの基礎 | 24% |
| 第 3 分野: 基盤モデルの応用 | 28% |
| 第 4 分野: 責任あるAIに関するガイドライン | 14% |
| 第 5 分野: AIソリューションのセキュリティ、コンプライアンス、ガバナンス | 14% |
※2025/01時点の最新バージョン(Ver.1.4)のものです。
バージョンアップで範囲等は変更されるので、こちらも受験時は公式サイトをご確認ください。
AWS Certified AI Practitioner 認定
勉強開始前の状態
AWSで動いているアプリの開発/運用の業務を7年程度、現在も継続中。
AWS認定は昨年までに13個取得済み。
- AWS認定ソリューションアーキテクトを受験した時の話
- AWS認定デベロッパーアソシエイトを受験した時の話
- AWS認定SysOpsアドミニストレーターアソシエイトを受験した時の話
- AWS認定ソリューションアーキテクトプロフェッショナルを受験した時の話
- AWS認定DevOpsエンジニアプロフェッショナルを受験した時の話
- AWS認定セキュリティ - 専門知識を受験した時の話
- AWS認定データベース - 専門知識を受験した時の話
- AWS認定アドバンストネットワーキング - 専門知識を受験した時の話
- AWS認定データ分析 - 専門知識を受験した時の話
- AWS認定機械学習 - 専門知識を受験した時の話
- AWS認定SAP on AWS - 専門知識を受験した時の話
- AWS Certified Data Engineer - Associate受験時の記録
※CLFはAll Certificateのために後半で取得したので特に書くこともなく記事にしていません。
受験前に参考にした記事
新資格取得はAIF→MLAの順に受験してAI/ML関連の一般知識のり開度を少しずつ上げていくのが良さそうです。
勉強に使ったもの
1. WEB問題集(非公式)
新しい資格だとあまり選択肢がなく、セールで¥1,200程度だったので今回もWhizlabsで問題集のみ買い切り購入しました。
2. AWS公式練習問題
AWS Skill Builderで無料で提供されている20問の練習問題。実試験に近い内容が出題されるので今回も実施しておきます。
2025/01/11時点ではSkill Builderで提供されているAIF向けの日本語講座は公式模試と練習問題のみで、E-leaningはまだ日本語対応していないようでした。
公式模試は$29/月のサブスク登録が必要です。
3. AWSアカウント
学習の中で気になったところは実際にマネコンやCLIで触って確認します。
勉強(試験準備)の流れ
だいたいいつもの流れですが今回はAssociateレベルということで、ある程度の知識はすでにあるはずなので問題集を中心に進めていきます。
1. 試験ガイドを読む
今回もはじめに、公式サイトの「試験ガイド」を読みます。
各分野の対象知識に「AWSの〜」の文字は少なく、MLSと同様AWSよりもAI関連の一般知識の学習が必要そうです。
また、AIFとMLAの2試験は出題方式として、いままでの選択問題以外に
- 順序付け
- 内容一致(ペアの選択)
- 導入事例(1シナリオに複数問題)
が増えたようです。

2. 練習問題を解く
おおよその難易度や現在の理解度合いを測るのにちょうどいいので、早めに練習問題をやっておきます。
無料なので気軽に実施できます。
3. 問題集を解く
あとは問題をどんどん解いて
- 解答/解説でわからなかった部分を調べる。
- 覚えたほうが良さそうな部分はノート(デジタルのほうが速いのでデジタルで)に書き出す。
を繰り返します。
今回は問題集395問を1周実施しました。
4. 復習
試験直前にノートの再確認をしました。
勉強時間
およそ10時間程度
受験後
結果はスコア737で合格。

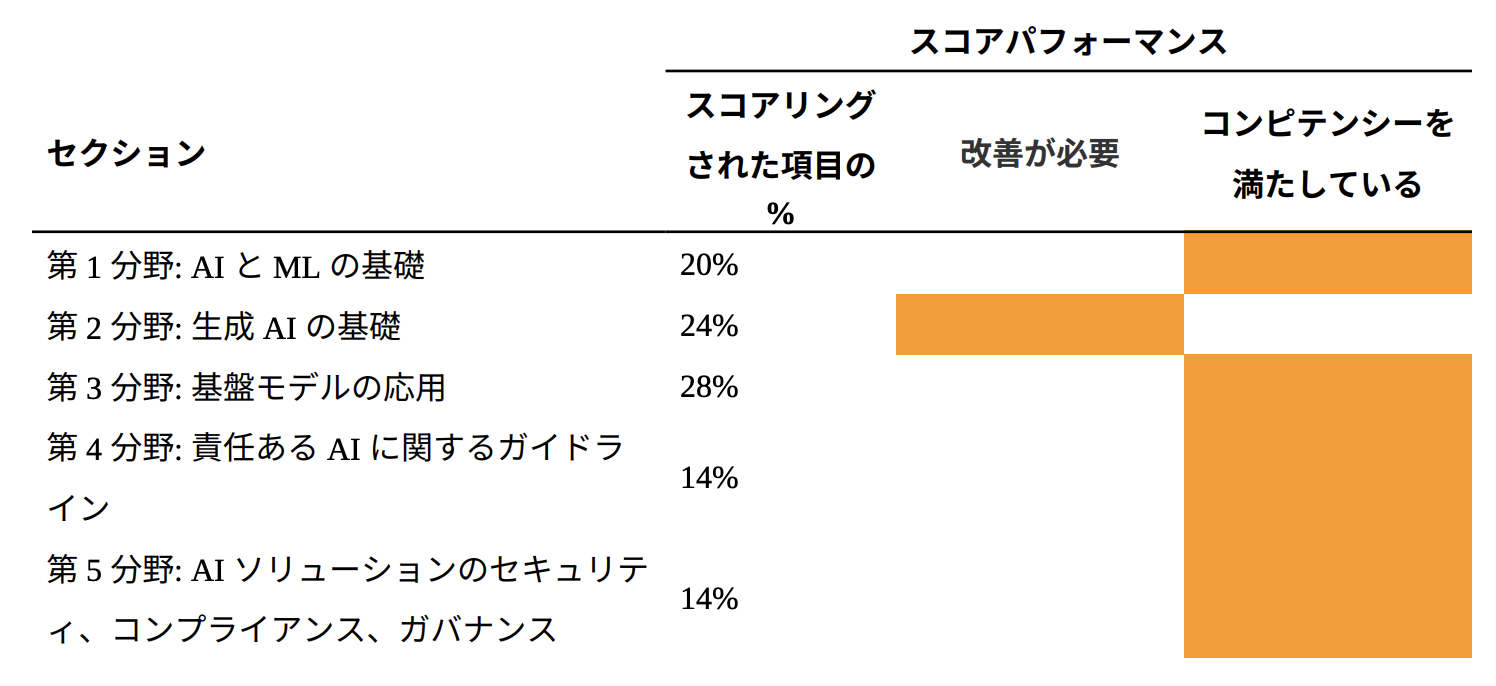
思ったより点数は低かったです。
問題集メインだったので生成AI基礎の勉強が少し足りなかったかもしれません。
次のMLAに向けて要学習ですね。
今回は正式公開から3ヶ月での受験だったのでEaly Adopterのバッジももらえました。
2025/02/15までの合格で対象になるようです。
勉強になったことメモ
試験のために勉強しながらまとめたノート
※ここに書いてあることは、あくまで私が理解が足りないと感じ、覚えたかったことだけです。試験範囲を網羅はしていません。
AI一般知識
基盤モデル(FM)
基盤モデルとは大量のラベルなしデータセットで事前トレーニング済みの大規模モデルで、テキストの翻訳から医用画像の解析までさまざまな領域に対応する。
従来の機械学習(ML)モデルでは各企業が独自でトレーニングを行っていたため、大きな時間とコストがかかっていた。
OpenAI社のGPTやAnthropic社のClaudeなどに代表される基盤モデル(FM)が公開されたことで、超高度な結果生成を行える生成AIが容易に開発できるようになった。
ファインチューニング
企業特有または分野固有のデータセットに基づいてモデルを微調整することにより、基盤モデル(FM)をカスタマイズすること。
基盤モデル(FM)の登場以降、AI開発のスタンダードとなった。
プロンプトエンジニアリング
言語モデルを効率的に使用するためのプロンプトを開発および最適化する学問分野。
基盤モデル(FM)に対し、人間の言語で追加の指示を与えることで追加のカスタマイズを行うこともできる。
低コスト/短時間で行えるが、ファインチューニングに比べると遥かに精度が低い。
プロンプトチューニング
AIによって作られた、数字の羅列で構成されるプロンプトにより、モデルのカスタマイズを行う。
このプロンプトを「ソフトプロンプト」人間が作成したプロンプトを「ハードプロンプト」と呼ぶ。
責任あるAI
AI(人工知能)は、倫理的な問題やプライバシー、セキュリティーなどにおいて、意図せずに社会や個人に深刻な影響を与える潜在的なリスクを抱えている。責任あるAI(Responsible Artificial Intelligence)とは、そういったAIの潜在的なリスクに企業や組織が責任を持って取り組み、作成したAIが安全で信頼できバイアス(偏見/偏り)がないことを保証すること、またはそのための指針として掲げる内部ポリシー(方針)や基本原則、プラクティスのことを指す。
AWSにおける責任あるAI
RAG(検索拡張生成)
LLMのトレーニングデータソースの外部にあるナレッジベースを参照することにより、LLMの品質と一貫性を向上させるプロセス。RAGは回答を生成する前に外部のナレッジベースを参照する。RAGを使用すれば、モデルから外部のナレッジソースにアクセスできるようになり、開発の労力も最小限ですむ。
コンテキスト内学習(Few-shotプロンプティング)
コンテキスト内学習とは、想定される形式や出力に即してLLMが回答できるように例をいくつか提供するプロンプトエンジニアリング手法のことで「Few-shotプロンプティング」とも呼ばれる。
反対に情報を与えずに質問だけ投げかけることを「Zero-shotプロンプティング」という。
インストラクションベースのチューニング
インストラクション(指示)ベースの微調整では、プロンプトと回答のペアによるラベル付きの例を使用して、特定のタスクで事前トレーニング済み基盤モデル(FM)のパフォーマンスを向上させる。
ハルシネーション
LLMが事実とは異なるか、または無意味な応答をもっともらしく自身を持って出力する現象。
現実やトレーニングデータに基づかない情報の「幻覚」を見ているかのようなことから名付けられた。
正確性と信頼性が重要なアプリケーションでは問題になる可能性がある。
ナレッジカットオフ
「ナレッジカットオフ(knowledge cutoff)」
基盤モデル(FM)などのLLMは特定時点までのスナップショットデータによりトレーニングされているため、最後にトレーニングデータを受け取った時点を以降の最新の情報がなく、古い回答や間違った回答を返す可能性がある。
この最後にトレーニングデータを受け取った時点のことを「ナレッジカットオフ」という。
プロンプトインジェクション
プロンプトインジェクションとは、生成AIを意図的に誤作動を起こさせるような指令入力を与え、提供側が出力を禁止している情報(開発に関する情報、犯罪に使われうる情報等)を生成させる攻撃。
これにより攻撃者はシステムの制御を奪ったり、機密情報を盗んだり、不正な操作を行ったりすることができる。
これらはAIに対する入出力のサニタイズとフィルタリングにより軽減することができる。
プロンプトリーク(Prompt-Leaking)
プロンプトインジェクションの中でも、プロンプトが保有する公開を意図していない情報を引き出し、機密情報を漏らすようにLLMに指示する手法を「プロンプトリーク」と呼ぶ。
ジェイルブレイク(脱獄)
設定された安全性や倫理的な制約を回避して、本来生成すべきでない内容を出力させる行為を「ジェイルブレイク」と呼ぶ。
防御策
プロンプトインジェクションの防御策としては、事前に敵対的プロンプティングへの防御を指示しておくなどいくつかの手法がある。
Least-to-Most
全体の問題を簡単な部分問題に分けて回答を得ることで精度を高めるプロプティング手法。
マルチモーダル検索
画像とテキストなど複数種類のデータから検索を行う機能。
ベクトル
テキストなどのデータを数値に変換したもの。
埋め込み(Embedding)
「埋め込み」とは、MLやAIシステムが人間のように複雑な知識領域を理解するために、現実世界のオブジェクトに数値表現をあたえること。
同様の意味を持つコンテンツに近いベクトルをもたせるなど、AIがコンテンツ同士の関係を理解するのに必要となり、生成モデルにとって重要な要素。
Top-K/Top-P
LLMが文書生成の際に次の単語を選択する際の基準となる値。
いずれも値が小さいほど関連性の低い単語が出力されづらくする。
温度(Temperature)
モデルがどれだけ「創造的」に応答を生成するかを調整するパラメータ。
0にすると最も可能性が高い回答を出力し、温度が高くなるほど出力にランダム性が増す。
インテント分類
テキストの一部から意図を取り出すこと。会話AIが、人が何を達成したいのかを理解するために使われる。
ML一般知識
機械学習の種類
機械学習は大きく分けて以下のようなものに分類される。
| 種類 | 概要 |
|---|---|
| 深層学習 | 大量のデータから特徴を段階的に深く学習する機械学習。 |
| 教師あり/なし学習 | 入力データと出力データの関係を学習させる際に正解ラベルをあらかじめ付与するものが教師あり学習、しないものが教師なし学習。 |
| 強化学習 | 報酬を最大化する行動を試行錯誤することで学習させる。 |
| 転移学習 | ある領域ですでに学習したこと(学習済みモデル)に別の領域に応用し、特徴の違いを再トレーニングすることで効率よく学習させる。 |
エージェントと環境
強化学習において、意思決定および行動の主体のことを「エージェント」と呼び、エージェントと相互作用を行う対象のことを「環境」と呼ぶ。
大規模言語モデル(LLM:Large Language Models)
膨大な量のデータで事前トレーニングされた、非常に大規模な深層学習モデル。
文章生成、要約、翻訳、プログラム生成や自然言語よる質問への回答などを行うことができる。
Recall-Oriented Understudy for Gisting Evaluation (ROUGE)
生成された要約を品質評価するためのメトリクス
- ROUGE-1, ROUGE-2
- ROUGE-L
- ROUGE-L-Sum
がある。
ハイパーパラメータ
MLアルゴリズムの動作を制御するために調整できる設定をハイパーパラメータと呼ぶ。
特に一般的なものとして
- ベイズ最適化
- グリッドサーチ
- ランダムサーチ
などがある。
モデル評価
モデルのトレーニングが完了後に、そのパフォーマンスと成功の指標を評価すること。
特徴量エンジニアリング
データの固有の属性はすべて「特徴」と見なされる。
特徴エンジニアリングは、機械学習または統計モデリングを使用して予測モデルを作成するときに変数を選択して変換するプロセス。特徴エンジニアリングには特徴の作成、特徴の変換、特徴の抽出、特徴の選択が含まれる。
ディープラーニングでは、特徴エンジニアリングはアルゴリズム学習の一部として自動化される。
F1スコア
F1スコアを使用するとモデルの二項分類の正解率を評価できる。F1スコアは適合率と再現率を使用して、モデルによる適正なクラスへの分類の正解率を評価する。
オーバーフィット/アンダーフィット
「オーバーフィット」とは、機械学習モデルがトレーニングデータに対して正確な予測をするが、新しいデータについては正確に予測しないという、望ましくない機械学習の動作。
機械学習モデルが正確な予測を行うのは、ドメイン内のすべてのタイプのデータに対して一般化されている場合のみだが、オーバーフィットはモデルが一般化できず、トレーニングデータセットに近すぎる場合に発生する。
反対にトレーニングデータ内の関係を識別せず、トレーニングデータの正解率も上がらない状態が「アンダーフィット」と呼ばれる。
MLライフサイクル
MLライフサイクルフェーズは以下の図のような流れになる。

HITL(Human-In-The-Loop)
MLのトレーニングやフィードバックのライフサイクルの中に人間も参加させることで、精度の向上やバイアスの解消などを行うという考え方。
AutoML
データの前処理、特徴エンジニアリング、アルゴリズム選択、ハイパーパラメータ調整、モデル評価など手間のかかる手順を自動化するアプローチ。
モデル圧縮
モデルの計算量を小さくすることで推論時間の短縮やリソース使用量の削減をする手法。
代表的な手法として以下の3つがある。
- Pruning(枝刈り)
- Quantize(量子化)
- Distillation(蒸留)
PEFT(Parameter-Efficient Fine Tuning)
PEFTとは、LLMのような事前学習済みモデルを新しいタスクに効率的に適応させるための手法。
モデルの全体ではなく、一部のパラメータだけをファインチューニングする。
RLHF(Reinforcement Learning from Human Feedback)
LLMは望ましいコンテンツと望ましくないコンテンツの両方を含む可能性のある膨大なデータでトレーニングされる。
RLHF(人間のフィードバックによる強化学習)を行うことで、事実としての正確性だけでなく、人間の価値観、論理的配慮、社会的規範に適合するようモデルを誘導できる。
Amazon SageMaker
データ処理、ML、分析、AIの統合プラットフォーム
ややこしいが、マネージドのMLサービスだった「Amazon SageMaker」は2024/12/03に「Amazon SageMaker AI」に名称変更され、新しい「Amazon SageMaker」の一部となった。
Amazon SageMaker AI
マネージドのMLサービス、旧「Amazon SageMaker」
MLモデルの構築やトレーニング、公開などができる。
Amazon SageMaker Model Dashboard
AWSアカウントのすべてのモデルを一元的に表示、検索、探索できる。
モデルのデプロイ、使用状況、パフォーマンスの追跡、モニタリングに関するインサイトなどの情報が管理できる。
Amazon SageMaker Model Cards
MLモデルに関する詳細をレコードとして一箇所にまとめて文書化できる。
Amazon SageMaker Model Monitor
本番環境における ML モデルとデータの品質をモニタリングできる。
Amazon SageMaker Role Manager
Amazon SageMaker AIコンソールから直接、一般的な機械学習のニーズに合わせてペルソナベースのIAMロールを構築および管理できる。
Amazon SageMaker Data Wrangler
データのインポート、準備、クレンジング、分析、変換などの前処理をほぼノーコードで行うことができる。
Amazon SageMaker Ground Truth
モデルのトレーニングに人間によるラベル付けを利用することでより正確性を高めたり、人間の価値観に近づけるための機能。
Amazon SageMaker Clarify
モデルのバイアスを特定し評価することができる。
Amazon SageMaker JumpStart
基盤モデル(FM)などの事前にトレーニングされたオープンソースのモデルを利用できるSageMakerの機能。
Amazon SageMaker ML Lineage Tracking
機械学習プロジェクト内のデータの詳細な履歴を保持し、MLパイプライン内のデータの経路を追跡できる。
これにより、問題に対するデバッグや再現、監査やガバナンスに対応する。
オートスケーリング
SageMaker AIはホストされたモデルの自動スケーリングに対応している。
デプロイオプション
SageMaker AIによるモデルのデプロイは目的や要件に応じ、以下の4つから選択できる。
- リアルタイム推論
- サーバレス推論
- 非同期推論
- バッチ変換
Shadow deployment
新しいバージョンのモデルを並行してデプロイし、旧バージョンへのリクエストと同じ入力を処理させるが、結果をユーザへ返さず、ログへの記録やオフラインでの分析に利用する手法。
これによりユーザに影響を与えることなく、新モデルのパフォーマンスや動作を検証できる。シャドーテストやダークローンチとも呼ばれる。
Amazon Bedrock
フルマネージドのAIサービス。
AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI、Amazonなどの大手AI企業の高性能 基盤モデル(FM)をAPI経由で利用するAIアプリケーションを少ない労力かつ短時間で構築ができる。
ガードレール
Amazon Bedrockのガードレールでは特定のトピックを回避したり、有害コンテンツをフィルターしたり、違反がないかどうかユーザー入力をモニタリングしたりすることができる。
ガードレールはユースケースやAIポリシーに合わせてカスタマイズが可能。
例えば、有害や不快な言葉の生成や個人情報/機密情報の出力などをブロックさせることができる。
ナレッジベース
RAGのドメイン固有情報を提供するデータソースとなる。
チャンキング(chanking)
ナレッジベースにおいて膨大なドキュメントを扱いやすいサイズでかつ、それぞれが意味を持つ断片に分割する。
これによりより効率的で高速な検索が可能になる。また、LLMが一度に処理できるテキスト量の制限にも対処する。
プロビジョンドスループット
プロビジョンドスループットを設定することでモデルにより高いスループットを確保することができる。
Bedrockエージェント(Agents for Amazon Bedrock)
Bedrockの拡張機能として提供されるAIエージェント。
PartyRock
シンプルなGUIで簡単に生成AIアプリケーションを作成できるサービス。
AWSが無料で公開しており、バックエンドにBedrockが利用されている。
その他AI関連AWSサービス
AWSのAI/ML関連サービスざっくりまとめ
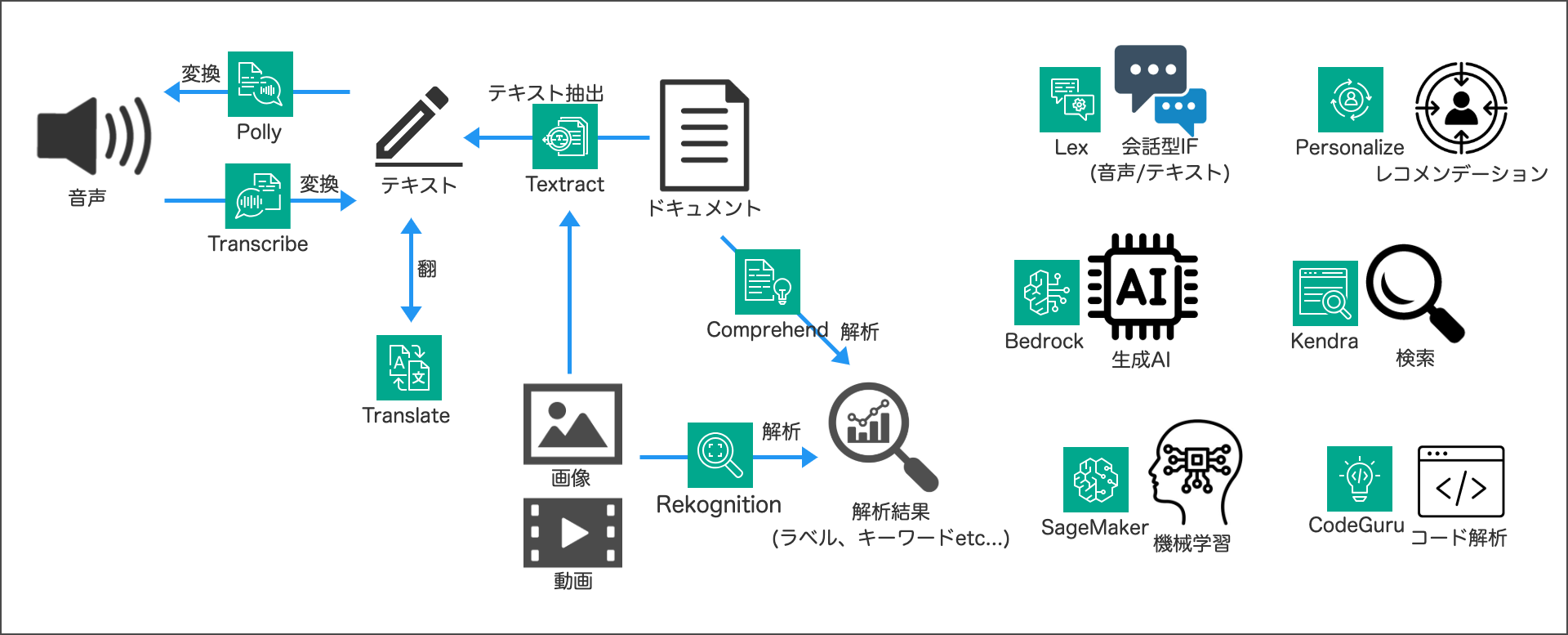
Amazon Textract
画像やPDFファイルからのテキスト抽出ができる。
「Text」+「Extract」
Rekognition
S3やストリーミングソースの画像や動画を分析しテキスト検出、物体検出、顔比較などができる。
「Rekognition」=「認識」
Amazon Comprehend
自然言語処理(NLP)を使用してドキュメントからインサイトを抽出するサービス。
ドキュメントに対して、キーワード抽出や感情分析などができる。
「Comprehend」=「理解する」
Amazon Polly
テキストを肉声に近い音声に変換するクラウドサービス。
Amazon Transcribe
機械学習モデルを使用して音声をテキストに変換する自動音声認識サービス。
「Transcript(文字起こし)」+「Describe(説明)」?
カスタム語彙(Custom vocabularies)
ブランド名や頭字語、固有名詞、 Amazon Transcribeが正しく表示できない単語など、ドメイン固有の用語を登録し、文字起こし精度を向上させられる。
Amazon Transcribe Medical
医療に特化した音声文字起こしサービス。
Amazon Translate
深層学習モデルを利用してバッチ翻訳やリアルタイム翻訳を行えるサービス。
固有の用語の定義などカスタマイズを行うこともできる。
Amazon CodeGuru
機械学習モデルによりコードレビューやコードに対する脆弱性検知などを行えるサービス。
CodeGuruセキュリティ
セキュリティポリシー違反や脆弱性を検出する静的解析ツール。
CodeGuruプロファイラー
実行中アプリケーションからパフォーマンスデータを収集し推奨事項を提供する。
CodeGuruレビュアー
GitリポジトリやS3バケット内のコードに対し、推奨事項を生成しプルリクエストへのコメント投稿などができる。
単純な構文チェックではなく、リソースリーク防止やシークレットの検出などを行う。
PythonとJavaに対応している。
Amazon A2I(Argumented AI)
Rekognition、Textract、SageMakerによるカスタムMLモデルなどに対し、信頼性の低い予測やランダムな予測サンプルについて人間によるレビューを行うことができる。
Amazon Lex
音声やテキストを使用した会話型インターフェイスをさまざまなアプリケーションに構築するためのサービス、Amazon Alexaと同じ会話型エンジンが使用できる。
Amazon Fraud Detector
オンラインのカード不正利用や偽アカウントのような詐欺行為などの不正行為を機械学習により検出するフルマネージド型の不正検出サービス。
「Fraud」=「詐欺」
Amazon Connect
コンタクトセンターの顧客とユーザーを統一されたエクスペリエンスでシームレスにつなぐAIを活用したアプリケーション。Amazon Connect管理Webサイトを使用し、コンタクトセンターを手軽に設定することができる。
Amazon Connect Wisdom
MLにより、顧客の問い合わせを分析しオペレータに課題解決のための情報提供を行う。
Amazon Q in Connect
顧客とのやり取り中に、推奨される応答、ナレッジ記事、ステップバイステップのガイドなど、エージェントによるリアルタイムの支援を提供する。
Amazon Connect Wisdomの進化系(公式Docでそう言われている)
Amazon Connect Contact Lens
AIにより通話の要約を生成したり、会話のモニタリング、分析などを行える。
Amazon Forecast
MLによる時系列予測を提供するフルマネージドサービス
※新規ユーザへの提供は終了
Amazon Kendra
SaaSやDB、ストレージを横断的に検索できる。
Amazon Macie
機械学習とパターンマッチングを使用して機密データを検出し、データセキュリティリスクを可視化し、それらのリスクに対する自動保護を可能にするデータセキュリティサービス。
Amazon Personalize
ユーザごとのレコメンデーション生成ができるフルマネージドのMLサービス。
その他AI関連用語