この記事の概要
2025/02/13 に「AWS Certified Machine Learning Engineer - Associate
(MLA-C01)」を受験しました。
その時の記録です。
試験の概要
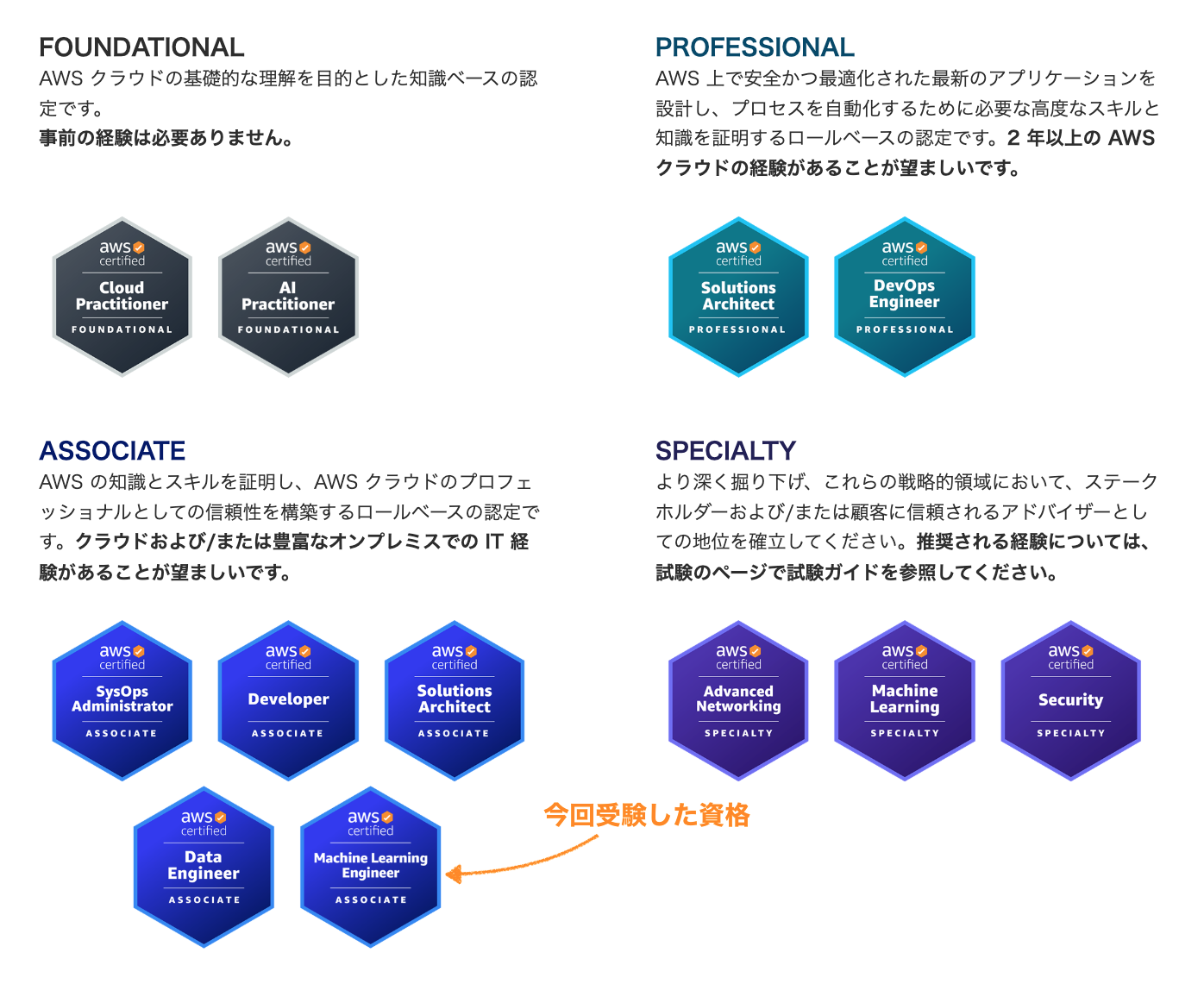
世の中のデータ活用やAIの専門知識に対する需要に合わせ、今年度は3つのAWS認定資格が追加されました。
その中のASSOCIATEレベルの資格です。
2024年からASSOCIATEレベルが5つに増えました。
AWSの公式ガイドには
AWSクラウドを使用した機械学習 (ML) ソリューションとパイプラインの構築、運用化、デプロイ、保守についての受験者の能力を検証します。
とあります。※AWS公式より引用:引用元
以前からあるMLSに比べ、ML一般知識の問われる深さが浅くなった感じでしょうか?
◼︎ 試験要項
| 項目 | 値 |
|---|---|
| 問題数 | 65問 (うち15問は採点対象外) |
| 試験時間 | 90分 |
| 受験料 | ¥20,000 (税別) |
| 合格ライン | 100~1000点中720点 |
| 受験資格 | なし |
| 有効期限 | 3年 |
※料金は為替レートに合わせて毎年4月に見直されます。アソシエイト試験は2024年度¥5,000値上がりしました。
「AWS Certified AI Practitioner(AIF-C01)」の上位資格の位置付けのため、AIFを保持している状態でこの試験に合格するとAIFも合わせて期限が更新されます。
「AWS Certified Machine Learning - Specialty (MLS-C01) 」の下位資格という位置付けではないため、MLSとMLAは両方更新が必要です。
◼︎ 出題範囲
| 分野 | 出題割合 |
|---|---|
| 第 1 分野: 機械学習 (ML) のためのデータ準備 | 28% |
| 第 2 分野: ML モデルの開発 | 26% |
| 第 3 分野: ML ワークフローのデプロイとオーケストレーション | 22% |
| 第 4 分野: ML ソリューションのモニタリング、保守、セキュリティ | 24% |
※2025/01時点の最新バージョン(Ver.1.4)のものです。
バージョンアップで範囲等は変更されるので、こちらも受験時は公式サイトをご確認ください。
AWS Certified Machine Learning Engineer - Associate 認定
勉強開始前の状態
AWSで動いているアプリの開発/運用の業務を7年程度、現在も継続中。
AWS認定は昨年までに14個取得済み。
- AWS認定ソリューションアーキテクトを受験した時の話
- AWS認定デベロッパーアソシエイトを受験した時の話
- AWS認定SysOpsアドミニストレーターアソシエイトを受験した時の話
- AWS認定ソリューションアーキテクトプロフェッショナルを受験した時の話
- AWS認定DevOpsエンジニアプロフェッショナルを受験した時の話
- AWS認定セキュリティ - 専門知識を受験した時の話
- AWS認定データベース - 専門知識を受験した時の話
- AWS認定アドバンストネットワーキング - 専門知識を受験した時の話
- AWS認定データ分析 - 専門知識を受験した時の話
- AWS認定機械学習 - 専門知識を受験した時の話
- AWS認定SAP on AWS - 専門知識を受験した時の話
- AWS Certified Data Engineer - Associate受験時の記録
- AWS Certified AI Practitioner(AIF)受験時の記録
※CLFはAll Certificateのために後半で取得したので特に書くこともなく記事にしていません。
受験前に参考にした記事
新資格取得はAIF→MLAの順に受験してAI/ML関連の一般知識の理解度を少しずつ上げていくのが良さそうです。
勉強に使ったもの
1. WEB問題集(非公式)
AIFの受験時にセールで安くなっていたので、こちらも合わせて購入しておきました。
7.98USD(¥1,247)でした。
問題数は165問と少し少なめですが、買い切りでもアップデートはあるので今後増えていくと思います。(2025/02/08時点)
並べ替え問題は公式ドキュメントの手順をそのまま使っているようで、途中の順序を変えても正解になりそうな問題がいくつかあり、本番で本当にこのような問題が出題されるのかは疑問に思いました。
2. AWS公式練習問題
AWS Skill Builderで無料で提供されている20問の練習問題。実試験に近い内容が出題されるので今回も実施しておきます。
1月はじめ頃にはなかった日本語のE-leaningも追加されていました。
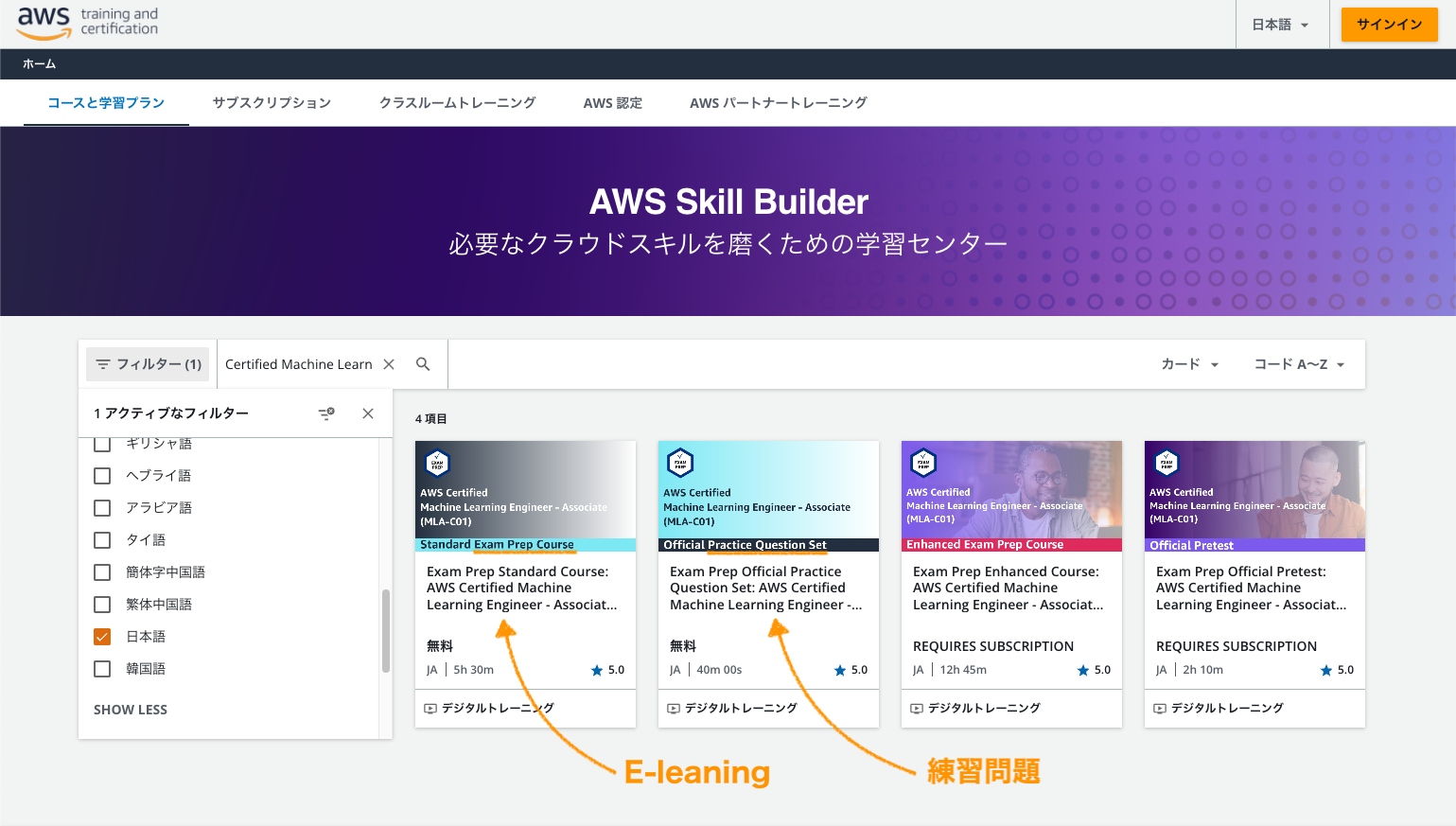
ちょっと内容を見てみましたが、動画は英語のものがそのまま使われていて動画内のテキストがすべて英語でした…
日本語字幕は有効にできますが、それだけだと辛いので今回は利用を見送りました。
3. AWSアカウント
学習の中で気になったところは実際にマネコンやCLIで触って確認します。
勉強(試験準備)の流れ
だいたいいつもの流れですが今回はAssociateレベルということで、ある程度の知識はすでにあるはずなので問題集を中心に進めていきます。
1. 試験ガイドを読む
今回もはじめに、公式サイトの「試験ガイド」を読みます。
各分野の対象知識に「AWSの〜」の文字は少なく、MLSと同様AWSよりもAI関連の一般知識の学習が必要そうです。
また、AIFとMLAの2試験は出題方式として、いままでの選択問題以外に
- 順序付け
- 内容一致(ペアの選択)
- 導入事例(1シナリオに複数問題)
が増えたようです。

2. 関連知識の復習
AIF、MLSと試験範囲が近いので過去の学習時の記録を読み返しt思い出しました。
MLSは2年前なので、忘れている部分が多かったです。
3. 練習問題を解く
おおよその難易度や現在の理解度合いを測るのにちょうどいいので、早めに練習問題をやっておきます。
無料なので気軽に実施できます。
4. 問題集を解く
あとは問題をどんどん解いて
- 解答/解説でわからなかった部分を調べる。
- 覚えたほうが良さそうな部分はノート(デジタルのほうが速いのでデジタルで)に書き出す。
を繰り返します。
今回は問題集165問を1周実施しました。
5. 復習
試験直前にノートの再確認をしました。
勉強時間
およそ20時間程度
受験後
結果はスコア945

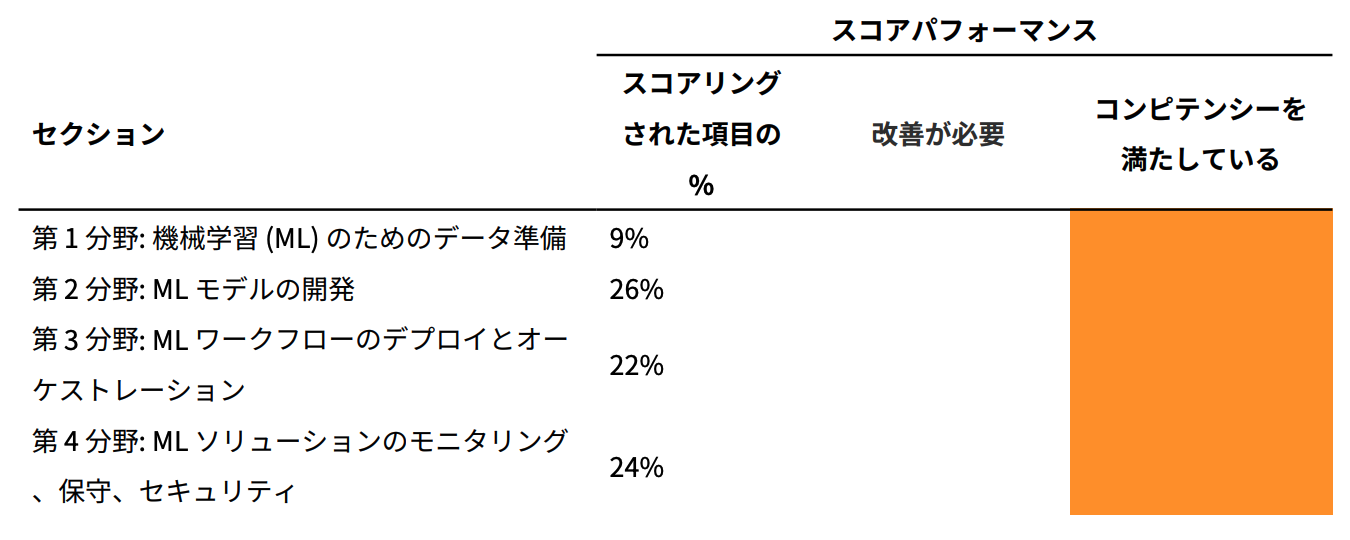
過去にMLS受験時に学習した範囲と近かったこともあり、比較的難易度は低く感じました。
今回、同一カテゴリのSPECIALTYとASSOCIATEが初めてできましたが、やはりASSOCIATEのほうが問題文の複雑さ的にも正解を選びやすい易しい形のものが多く、AWS以外の専門知識を問われる深さも浅くなっていましたね。
Ealy Adopterのバッジも滑り込みで獲得できました。
なんとか今年もAll Certificate継続できました ![]()
AWS認定は毎年新しく追加される資格の受験と期限が来た資格の更新をしているとそれなりに勉強になるので、来年も続けていこうと思います。
勉強になったことメモ
試験のために勉強しながらまとめたノート
※ここに書いてあることは、あくまで私が理解が足りないと感じ、覚えたかったことだけです。試験範囲を網羅はしていません。
AWSのAI/MLサービス
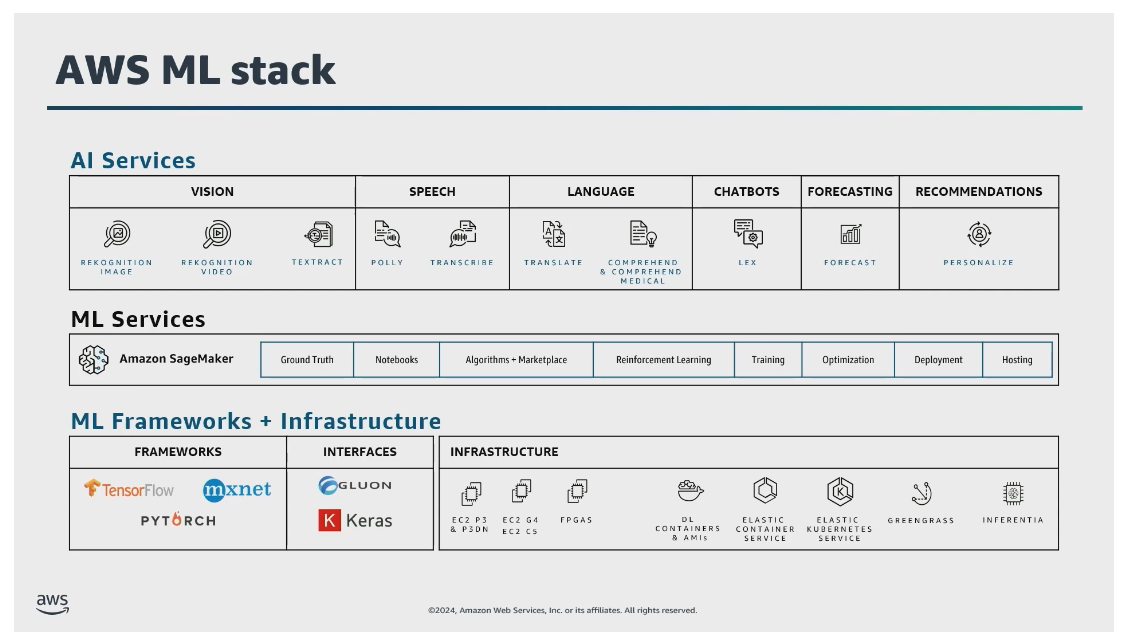
AWSのホワイトペーパーには一覧が掲載されている。
機械学習基礎
機械学習は大きく
- 前処理
- 学習
- 推論
のプロセスに分けられる。
前処理したデータから学習し、学習した結果を下にすい
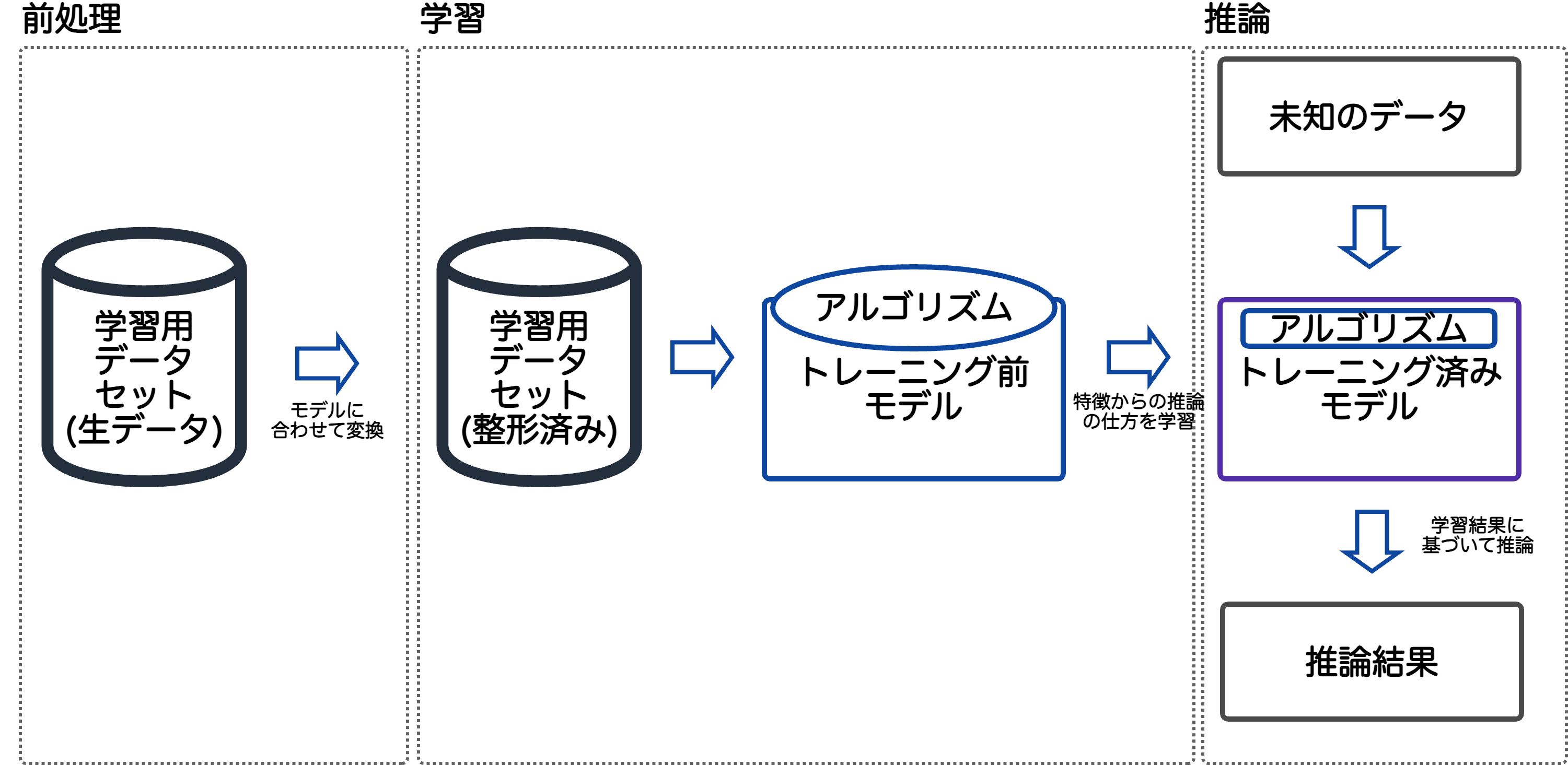
ハイパーパラメータ
バッチサイズ
機械学習ではデータセットを複数のグループに分割して学習する。
その際の1グループのデータの量をバッチサイズと呼ぶ。
バッチサイズが小さすぎると学習に時間がかかる。
バッチサイズが大きいほど、勾配が安定し、ノイズが少なくなるが、大きすぎるとメモリ不足や過学習がおきる可能性があるため、バランスを取る必要がある。
エポック
訓練データを何回使ったかを表す値。エポックが多すぎると過学習につながる。
max_depth
ツリーモデルの学習時のツリーの深さ
この値の大きさによりデータセットに対する学習率が変化するため、大きくしすぎると過学習の原因となる。
正則化
- L1正則化:一部の特徴を削除(0に)する。重要でない特徴を削除することで過剰適合対策になる。
- L2正則化:すべての特徴の全体的な重み値を小さくする。
オーバーサンプリングとアンダーサンプリング
予測モデルのもとになるデータが不均衡データ(負または正が極端に少ない偏ったデータ)の場合、データ数をいずれかに合わせる(均衡化する)ことで予測精度を上げる。
SageMaker Data Wranglerではランダムなオーバーサンプリング、アンダーサンプリングとSMOTEによるオーバーサンプリングができる。
ドリフト
環境の変化などにより、モデルの精度が低下すること。
- コンセプトドリフト
- データドリフト
の2つに分けられる。
プロンプトエンジニアリング手法
スカラー/ベクトル/テンソル
- スカラー: 大きさのみを表す単一の値
- ベクトル: 複数のスカラーを表す1次元配列
- テンソル: スカラー、ベクトルなどを複数ひとまとめにした多次元配列
データ変換
ハイパーパラメータ調整戦略
ハイパーパラメータチューニングではすべての組み合わせを検証することは現実的でないため、特定の戦略で特定の範囲内から組み合わせを検証し選択することになる。
その調整戦略として、主に3つの手法がある。
| 手法 | 概要 |
|---|---|
| グリッド検索 | カテゴリごとに値の範囲を指定し、それらすべて値の組み合わせを検証する。 |
| ランダム検索 | 訓練回数を指定し、その回数内でランダムに選択された組み合わせを検証する。 |
| ベイズ最適化 | 前回の結果を下に次の値を決めていくアルゴリズム |
| Hyperband | 中間結果と最終結果の両方を使用して、使用率の高いハイパーパラメータ構成にエポックを再割り当てし、パフォーマンスの低いものは自動的に停止する。 |
モデル圧縮
モデルのサイズを小さくするための手法がいくつかある
モデル最適化(model optimization)とも呼ぶ。
| 手法 | 概要 |
|---|---|
| Pruning(枝刈り) | モデルのサイズと複雑さを軽減、推論速度を向上しエネルギー消費を削減する。 |
| Quantize(量子化) | モデルの複雑さを完全に維持しながら、メモリ使用量を大幅に削減し、計算を高速化し、展開の柔軟性を高める。 |
| Knouledge Distillation(蒸留) | モデルを圧縮しながら精度を維持し、より大きな教師モデルからより小さなモデルの一般化を促進し、多用途で効率的なモデル設計をサポートする。 |
事前トレーニングバイアスメトリクス
モデルのトレーニング前にデータ内の偏りを測定するためにいくつかのデータバイアスメトリクスがある。
また、トレーニング後のデータとモデルのバイアスメトリクスも用意されている。
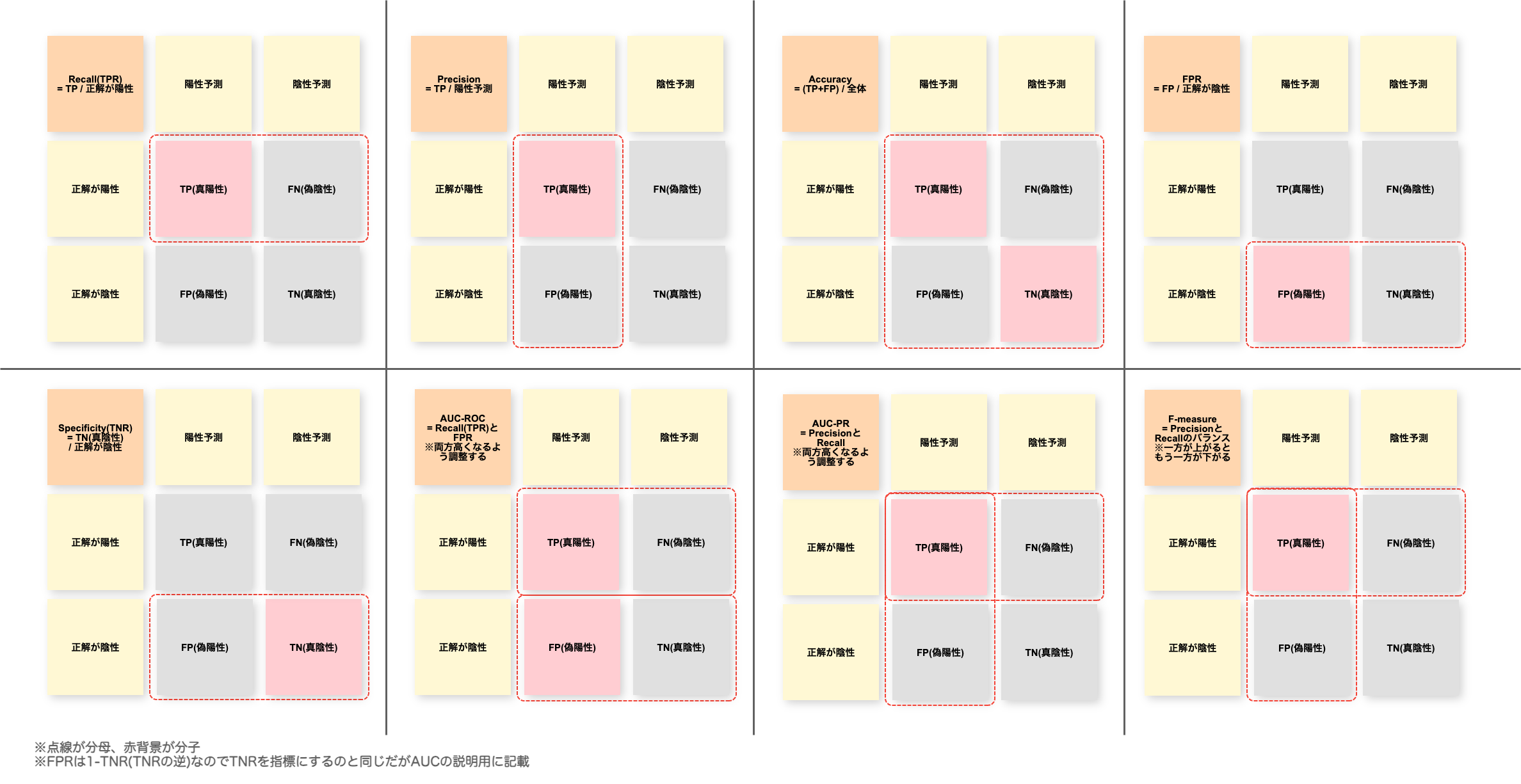
モデルの評価指標
モデルの種類ごとの評価指標一覧
| モデル | 評価指標 |
|---|---|
| 分類モデル | ・Recall ・Specificity ・Accuracy ・Precision ・FPR ・AUC ・F-measure |
| 回帰モデル | ・RMSE ・MSE ・MAE |
この試験の対策としては、それぞれの詳細まですべて覚える必要はなく
- 正誤判定などの分類問題は分類モデルの評価指標
- 将来の価格変動などの未来予測の場合は回帰モデル用の評価指標
といった、ユースケースにあった指標を選択できるよう分類 or 回帰どちらに属するかを覚える。
ただ、Recall、Precision、Accuracy、F-measureあたりは違いを覚え直しておく。
Amazon SageMaker
Amazon SageMaker AI推論オプション
| 推論オプション | 推奨ケース |
|---|---|
| リアルタイム推論 | 低レイテンシや高スループットが要求されるオンライン推論、最大60秒 |
| サーバーレス推論 | 断続的またはまれなトラフィックパターンを伴う処理、最大60秒 |
| バッチ変換 | 大量のデータが事前に利用可能で、永続的なエンドポイントが必要ない場合のオフライン処理、最小100MB以上の入力データが必要 |
| 非同期推論 | リクエストをキューに入れる必要がある推論、および大きなペイロードサイズや長時間の処理を要する推論、最大60分 |
サーバーレス推論のProvisioned Concurrency
サーバレス推論ではコールドスタートを減らすために同時実行数を事前に予約することができる。
スクリプトモード
SageMakerによる学習(トレーニング)は
- 組み込みアルゴリズム
- 独自スクリプト
- 独自コンテナ
の3つのやりかたがある。
スクリプトモードでは事前に用意されたコンテナ上で独自スクリプトによる学習(トレーニング)を行わせる事ができる。
これから新しくモデル作成する場合は「組み込みアルゴリズム」
オンプレなど既存環境からの以降の場合、スクリプトのみであれば「独自スクリプト」、実行環境も独自のものを利用している場合「独自コンテナ」と、使い分ける。
SageMaker Inference Recommender
SageMakerのモデルに対し、負荷テストを行い、最適なインスタンスタイプと設定の推奨を提供する。
SageMakerの早期停止
入力モードとストレージオプション
データセットの格納先としては
- S3
- EFS
- FSx
がある。
また、S3をストレージとする場合
- ファイルモード
- 高速ファイルモード
- パイプモード
の3つの入力モードがある。
パイプモードではファイルのDLを行わずに、データを直接ストリーミング処理するため、スループット向上や使用ディスク領域の削減ができる。
S3 Express One Zone
SageMakerモデルトレーニングなど、レイテンシーの影響を受けやすいアプリケーション用に設計されたS3のストレージクラス。
コンピューティングリソースと同一AZにファイルを格納できるため、可用性は99.5%に落ちるがデータアクセス速度は10倍になる。
Amazon SageMaker Model Registry
モデルを保存し、管理する機能。
モデルの
- バージョン管理
- カタログ化
- CI/CD
などに活用できる。
- モデルグループ: モデルの登録先となるグループ
- モデルコレクション: モデルの分類や階層化、整理に利用できる。1つのグループを複数のコレクションに追加可能。
Amazon SageMaker Pipelines
SageMakerによるデータ準備、トレーニング、デプロイ、監視の一連の機械学習パイプラインを構築できる。
GUIまたはJSONでパイプラインを定義する。
Amazon SageMaker Debugger
SageMaker AIでモデルの問題を検出、修正するための機能。
- モデル出力テンソルを抽出しS3に保存
- オーバーフィット、活性化関数の飽和、勾配の消失など、モデル収束の問題を検出
- CloudWatch Eventsを使用し、検出された問題を自動修正するLambdaの実行
- Amazon SNSによるEメールまたはテキスト通知
などができる。
Amazon SageMaker Feature Store
特徴量の作成、保存、共有を行うことができる機能。
Amazon SageMaker Clarify
モデルのパフォーマンスに影響を与える可能性のあるデータ分布の変化(データドリフト)を分析および識別できる。
新しい状況に対し、更新や再トレーニングするかを決定するための判断に利用できる。
また、モデルの説明可能性レポートを出力することもできる。
Amazon SageMaker Canvas
ノーコードで機械学習による推論を行える機能。
Amazon SageMaker Experiments
機械学習の実験を作成、管理、分析、比較できる機能。
マネージドウォームプール
機械学習 (ML) モデルトレーニングのハードウェアインスタンスを、ジョブ完了後の指定された期間、ウォーム状態に保つことができる。
この機能を利用すると、同じウォーム状態のインスタンスでモデルトレーニングの反復実験や連続したジョブを大規模に実行して、ジョブの起動レイテンシを最大8分の1に短縮できる。
ネットワーク分離モード
トレーニングジョブ/モデルの作成時や呼び出し時にEnableNetworkIsolationパラメータを有効にすることで、ネットワーク分離を有効にできる。
これによりコンテナ内の実行環境でインターネットやS3などへのアウトバウンド通信ができなくなる。また、AWS認証情報も利用できなくなる。
アウトバウンド通信の必要ないケースの場合、この機能でセキュリティの向上が期待できる。
MLflow
MLflowはオープンソースの機械学習のライフサイクル管理ツールで、トレーニングや評価などの反復的な実験を効率化できる。
SageMaker AIにはMLflow統合機能がある。
TensorBoad
TensorBoadはGoogleの機械学習OSSライブラリであるTensorFlowに付属する視覚化ツール
トレーニング中の中間テンソルの視覚化や分析によるデバッグやモデル最適化に利用できる。
SageMaker AIには「Amazon SageMaker with TensorBoard」というTensorBoad統合機能がある。
Amazon Redshift
マテリアライズド・ビュー
マテリアライズド・ビューを利用するとクエリ結果を事前に保存することで繰り返されるクエリを高速化できる。
マテリアライズド・ビューはREFRESHコマンドで更新することができる。
CREATEまたはALTER文でAUTO REFRESH YESを指定することで自動更新も可能。
権限の管理
GRANTコマンドで特定操作の許可やロールの付与を行う。
GRANT SELECT FOR TABLES IN DATABASE Sales_db TO alice WITH GRANT OPTION;
CREATE ROLE sample_role1;
GRANT ROLE sample_role1 TO user1;
ロールを別のロールに継承させることもできる。
CREATE ROLE sample_role2;
GRANT ROLE sample_role1 TO ROLE sample_role2;
他のロールを継承しているロールの削除時はFORCEの指定が必要
DROP ROLE sample_role2 FORCE;
動的データマスキング(DDM:Dynamic Data Masking)
データウェアハウス内の機密データを保護できる機能。
特定のユーザーまたはロールにカスタムの難読化ルールを適用するマスキングポリシーを適用できる。
Amazon Q in QuickSight
QuickSightにはAmazon Q統合機能がある。
Amazon QによるGenerative BI(生成系BI)機能が提供される。
対話形式での視覚化の構築や、データに対する質問を行うことができる。
Amazon Bedrock
モデル評価メトリクス
| メトリクス | 用途 |
|---|---|
| RWK (Real World Knowledge) |
テキスト生成タスクの精度評価 |
| BERT (Bidirectional Encoder Representations from Transformers) |
テキスト要約タスクの精度評価 |
| F1 | 質問と回答タスクの精度評価 |
| BLEU (BiLingual Evaluation Understudy) |
機械翻訳モデルの精度評価 |
推論パラメータ
推論を実行する際にパラメータを指定することで回答を調整することができる。
| パラメータ | 概要 |
|---|---|
| Top-K | 次のトークンとして考慮する最も可能性の高い候補の数 |
| Top-P | 次のトークンとして考慮する最も可能性の高い候補の割合 |
| 温度 (Temperature) |
確率の低い回答候補の選択されやすさ |
モデルカスタマイズ
基盤モデル(FM)のカスタマイズ方法として
- ファインチューニング
- 事前トレーニングの継続
がある。事前トレーニングの継続では、類似した追加データでさらに学習させることができる。このアプローチはファインチューニングよりライトなカスタマイズとして活用できる。
フェデレーテッドラーニング
地理的に分散した場所で独自のデータセットから並行してローカルモデルを開発し、それらを集約したグローバルモデルを作成する
AWS Compute Optimizer
EC2、ECS、ASG、Lambda、RDSなどの利用状況を分析し、適正サイズの推奨事項を提供するサービス。
CPU使用率のヘッドルームと閾値、メモリ使用率の余裕、ルックバック期間などのオプションを指定できる。
※ヘッドルーム=将来的な増加を考慮した余白
※ルックバック期間=分析のために遡る期間
構造化データと非構造化データ
CSV、Parquetなどの行列のテーブル(表)形式にすることができるデータを「構造化データ」、音声や動画、JSONで表現するような属性がバラバラの形式のデータを非構造化データと呼ぶ。
JSON Lines
JSONを複数行出力するフォーマット
ファイル出力する場合、拡張子は.jsonl
列単位ではなく、行単位で分析するデータに適している。
Parquet
Parquetは列志向のファイルフォーマット
.parquetのバイナリファイルなのでテキストエディタでは開けない。読み込みには専用のツールやPythonなどのアプリケーション内で分析用ライブラリなどを使う。
表形式にできるような矩形データだが、列単位で効率よく取り出す事ができるようになっている。
列単位の分析はParquet、単純な非構造データをリアルタイム分析する場合などはJSON Linesが適している。