はじめに
強化学習勉強会なるものがスタートしました!
なので,それらを勉強もかねてまとめていこうと思います.二番煎じ感がものすごいですが,自分の理解度向上のためにも!
予定ではQiitaで第7回分(Q学習ぐらいまで)ぐらいやろうかなと考えています.今回は第六回(1)です!
過去のもの
- 第一回:概要
- 第二回:n本腕バンディット
- 第三回:用語まとめ編
- 第四回:動的計画法
- 第五回(1):モンテカルロ法(ES法)
- 第五回(2):モンテカルロ法(方策ON型,方策OFF型)
- 第六回(1):TD学習の基本(ランダムウォーク)
- 第六回(2):TD学習(Q学習・Sarsa学習)
その他リンク
- github
https://github.com/Shunichi09/ - twitter
https://twitter.com/ShunichiSekigu1?lang=ja - 参考書
http://www.morikita.co.jp/books/book/1990 - 参考書(原本)
http://incompleteideas.net/book/bookdraft2018jan1.pdf - 原著プログラム
https://github.com/ShangtongZhang
原著プログラムについてですが,基本的には見ずに書いてます.
原著のプログラムが分かりにくければ,僕のgithubで見ていただけると嬉しいです.
目的
強化学習勉強会の内容のまとめ
自分の理解度向上もかねて
プログラムの書き方の練習もかねて
おしながき
- 強化学習とは
2. 概要
3. 用語
4. 考え方
強化学習とは
強化学習とはなんでしょうか?
「試行錯誤を通じて「価値を最大化するような行動」を学習するものです」
とされています.
平行して,nnを用いた時系列データの処理なんかもやっている僕としては,強化学習は,教師がない学習のイメージをもっています.
普通,NNを用いた機械学習といえば,CNNに代表されるこの写真は猫ですか?犬ですか?みたいな話ですよね?
正解があります
でも強化学習は正解がありません
その代わりに価値があります,報酬があります
分かりやすいように今は厳密には説明しませんが,(できませんが)これらを最大化する行動をとるようにします.
例えば車にのって競争してゴールにたどり着くゲームがありますね
こういうゲームって
大体
- 道中にあるコイン拾うと点数がもらえます
- 速くゴールすると点数が高いです
こんな風に設定されます
ここで,ロボットが点数高くゴールするようにCPUに学習させたいなって思うと,速くゴールすることと,コインを拾うことが報酬になります.でもここで,報酬の設定が悪いと道中にとどまって定期的に出現するコインばっかり集めるヘンテコプレーヤーを生み出します
イメージ図ですが,,,

ということです.
まとめると強化学習とは
繰り返しいろいろ試してみて,報酬や価値を最大化する行動を習得することと言えそうです.人間に近いような手法ですね
補足
結構いろいろ研究されてるので,調べてみてください
-
これは一番有名ですが,ブロック崩しです!!
上手く学習させて,ゲームをクリアできるようにしています 最後は上の方に追いやれるようにしてますね
https://www.youtube.com/watch?v=V1eYniJ0Rnk&list=PLmUKhqMdez2p3a5stFofgcWu1Whrqn6D0 -
PFN(ロボットがうまく動くように)
https://www.youtube.com/watch?v=a3AWpeOjkzw -
これ某社のゲームですね ゴールまでたどり着くようにしています
https://www.youtube.com/watch?time_continue=2&v=vrccd3yeXnc
用語
強化学習によく出てくる言葉をよく出てくる図と一緒にまとめておきます
用語については,今まだ勉強途中の僕がいうのもなんですが,たぶんこれらの意味をこの時点で深く追うのはよくないです.よくこれ最初に言われてなんだこれってなって,強化学習??ってなる人多いかと
第二回,第三回で,どんどん実感が湧くはず?ですので,今はフーン程度で!
ここで苦しむ必要はないと思います
ではさっそくいきます
強化学習ではよくこの図がでてきます
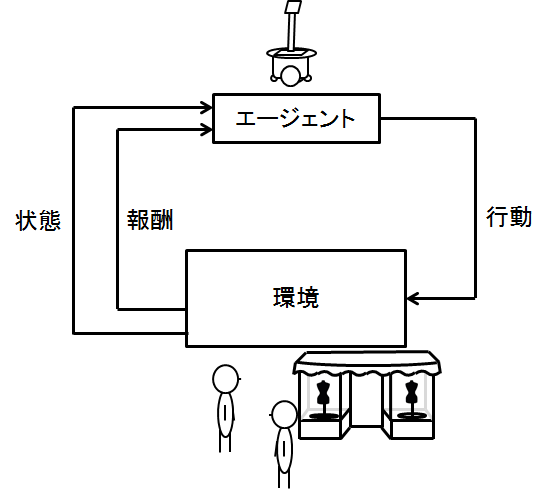
これは,強化学習の仕組みというかイメージを表しています.
ロボット(エージェント)が,行動して,状態が変化し,報酬を受け取るみたいな感じです
さっきのゲームの例だと
ロボットが道中コインを拾って,(自分の位置が変化して,時間がたって),ポイントをもらうって感じです
この絵はロボットがいて,そのロボットがエージェントとなって,人を案内したりする行動をとるイメージです
さてそれぞれの言語の意味の詳細です
エージェント
学習するもの
ロボットとか,ゲームの中のプレーヤーとか
状態
そのまま
エージェントや環境の状態
位置とか速度とか,位置の例が多いかも
周囲の環境の状態も入ります
環境
そのまま
状態と行動によって変化するもの(コインとったらコインがなくなるみたいな話,周囲の環境)
(制御系の人間は状態方程式的な話がと思ってもいいかも)
方策,政策
ロボット(エージェント)がとる行動
(迷路であっちいってみようとか)
価値
エージェントが将来受け取る報酬の期待値
(これが一番よくわかんないと思いますが今は報酬と似たようなものと考えてよいです)
報酬
環境からもらえる評価の値
(コインとったら点数もらえる)
(ゴールに近づいたら点数もらえるとか)
考え方
では,実際にどうやってロボット(エージェント)に学習を行えばよいのでしょうか?
たくさん試行してみる,とりあえずやりまくるのはなんとなくわかりますが,そのあとです
何を基準にして,今のがよかったとか悪かったとかいうかがポイントです
今までも話していたように基準は報酬と価値です
つまり,ある行動をとってみたら,それがすごくいいことがわかったら,この状態なら,この行動をする!ってわけですね
それをたくさん増やせば,いろんな状態において取るべき選択肢が分かります
図はこんな感じ

これは三目並べの例です
イメージ湧きましたでしょうか?
次回は
n本腕バンディット問題をときます
キーワードは知識利用と探査,貪欲法です!!
githubにもあがってます
https://github.com/Shunichi09/Reinforcement_Learning