はじめに
本連載の主題である機械学習モデルを構築します。
連絡目次
- 導入/環境設定
- Collaborative Notebook でデータ可視化
- Anomaly Detector をデータ探索ツールとして使ってみる
- 1つ目のモデル構築 (データの偏り 未考慮) → 本稿
- 2つ目のモデル構築 (データの偏り 考慮)
要件
実務チームからは、
- 予測結果をドメイン知識のあるメンバーに渡すことで、モバイル決済のサービス展開やユーザー登録規制方針を練る材料としたい
という要請があるものとします。この要件には、できるだけ判定ミスが起こりにくいように注意しつつ不正検知の取りこぼしが極力ないようなロジック、つまり、
- Presision (正しく不正取引と判定された件数 / 実不正取引件数合計) をできるだけ高くしつつも、
- Recall (正しく不正取引と判定された件数 / 不正取引と判定された件数合計) を優先しする、
を満たすモデルが運用しやすそうです。
アルゴリズム概要
今回利用するのはディシジョンツリー (分類木) です。他の機械学習アルゴリズムに比べて元々利用されているルールベースのロジックとの比較が容易なので、機械学習プロジェクトの出発点として利用される事が多いです。条件分岐見ればモデルが何をやっているか分かりやすいので納得ですね。
- 分類および回帰の機械学習タスクで一般的な方法
- 分類木を複数組み合わせたアルゴリズムがよく使われる
- モデル自体の説明性が高い (分類ロジックの可視化が容易)
評価指標導出関数の定義
混合行列の表示と特徴量の重みを算出する関数を作成します。このあたりの処理は機械学習の運用・改善プロセスを回す上で頻繁に使用・トラッキングするのでまとめておくと便利です。
一つの Notebook に収まりきらない、見通しが悪くなりそう、ということであれば別の Notebook にまとめておいて呼び出すということも可能です。
Azure Databricks で、他の Notebook を呼び出す、基礎: Hello World レベル
# 混合行列プロット
import matplotlib.pyplot as plt
import numpy as np
import itertools
from pyspark.sql.functions import lit, expr, col, column
# 混合行列用の空DFと一時ビューの作成
cmt = spark.createDataFrame([(1, 0), (0, 0), (1, 1), (0, 1)], ["label", "prediction"])
cmt.createOrReplaceTempView("cmt")
# 混合行列表示関数
# ---------------------------------------
def plot_confusion_matrix(cm, title):
# matplotlib 初期化
plt.gcf().clear()
# 図の要素数設定
fig = plt.figure(1)
# matplotlib 定義
classes = ['Fraud', 'No Fraud']
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
# しきい値設定
normalize=False
fmt = 'd'
thresh = cm.max() / 2.
# 混合行列のセルを反復処理
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
# レイアウトとラベル定義
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
image = fig
#fig = plt.show()
# 図として保存
fig.savefig("confusion-matrix.png")
# 描画
display(image)
# matplotlib 終了
plt.close(fig)
# 特徴量重要度算出関数
# ---------------------------------------
import pandas as pd
def ExtractFeatureImp(featureImp, dataset, featuresCol):
list_extract = []
for i in dataset.schema[featuresCol].metadata["ml_attr"]["attrs"]:
list_extract = list_extract + dataset.schema[featuresCol].metadata["ml_attr"]["attrs"][i]
varlist = pd.DataFrame(list_extract)
varlist['score'] = varlist['idx'].apply(lambda x: featureImp[x])
return(varlist.sort_values('score', ascending = False))
データセットの分割
連載#2 では通常取引/不正取引でデータセットに偏りがあることを確認しました。初回モデルはこれを考慮しないデータセットを用いて構築します。
# データセットを分割。80%をトレーニング用データに、20%をテスト用データとします
(train, test) = df.randomSplit([0.8, 0.2], seed=12345)
# それぞれをメモリのキャッシュ上に載せます
train.cache()
test.cache()
# それぞれのデータセット数
print("Total rows: %s, Training rows: %s, Test rows: %s" % (df.count(), train.count(), test.count()))
Total rows: 6362620, Training rows: 5090311, Test rows: 1272309
パイプライン構築
先ほど作成した関数もその一例ですが、機械学習モデルを改善していく際、複数のステップを繰り返し行うことになります。都度コードを書くのは面倒なので、処理フローのテンプレート(=パイプライン)を作成します。
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer
from pyspark.ml.feature import OneHotEncoderEstimator
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import DecisionTreeClassifier
# StringIndexer: 文字列型のカラムをラベルインデックスの列にエンコード
indexer = StringIndexer(inputCol = "type", outputCol = "typeIndexed")
# VectorAssembler: 指定された列のリストを一つのベクトル型に結合、変換。今回はIndexを除いて7つの特徴量を用います。
va = VectorAssembler(inputCols = ["typeIndexed", "amount", "oldbalanceOrg", "newbalanceOrig", "oldbalanceDest", "newbalanceDest", "orgDiff", "destDiff"], outputCol = "features")
# 分類木を使用
dt = DecisionTreeClassifier(labelCol = "label", featuresCol = "features", seed = 54321, maxDepth = 5)
# 機械学習パイプラインを作成
pipeline = Pipeline(stages=[indexer, va, dt])
モデルの作成と分類木の可視化
過学習を防ぐための代表的な手法に交差検証 (CrossValudation) がありますが、これを行わない場合でモデルを作成、樹形図を出力します。
dt_model = pipeline.fit(train)
display(dt_model.stages[-1])

樹形図はやはり分かりやすいですね。次に各特徴量がそれぞれどのくらい分類ロジックに寄与しているかを算出します。口座残高差分と支払いタイプが効いていることが分かります。
# 特徴量重要度
ExtractFeatureImp(dt_model.stages[-1].featureImportances, train_pred, "features").head(10)

モデリング時の評価指標
機械学習モデルの評価指標には要件の章で触れた Recall や Precision など基本的なもののほかに、様々なものがあります。今回は areaUnderPR と areaUnderROC をモデリング時の評価指標として用います。
偏ったデータセットで学習する場合には evaluatorPR を指標としてモデル構築すると良いので、初回モデルではこれを利用します。また、様々なパラメータを変えてチューニングするのは手間がかかるので自動的にいろいろな組み合わせを試してくれる PramGridBuilder というライブラリを用います。
# 評価指標の定義
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluatorAUC = BinaryClassificationEvaluator(labelCol = "label", rawPredictionCol = "prediction", metricName = "areaUnderROC")
evaluatorPR = BinaryClassificationEvaluator(labelCol = "label", rawPredictionCol = "prediction", metricName = "areaUnderPR")
# 特徴量のグリッドを作成
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
paramGrid = ParamGridBuilder() \
.addGrid(dt.maxDepth, [5, 10, 15]) \
.addGrid(dt.maxBins, [10, 20, 30]) \
.build()
# 交差検証器を作成
crossval = CrossValidator(estimator = dt,
estimatorParamMaps = paramGrid,
evaluator = evaluatorPR,
numFolds = 3)
pipelineCV = Pipeline(stages=[indexer, va, crossval])
# パイプライン、特徴量グリッド、二項分類器を用いて、トレーニングデータセットを学習
cvModel_u = pipelineCV.fit(train)
精度指標算出
作成したモデルの評価指標を確認します。
# パイプラインの中で一番いいモデルを構築
train_pred = cvModel_u.transform(train)
test_pred = cvModel_u.transform(test)
# Training データで評価指標を算出
pr_train = evaluatorPR.evaluate(train_pred)
auc_train = evaluatorAUC.evaluate(train_pred)
# Test データで評価指標算出
pr_test = evaluatorPR.evaluate(test_pred)
auc_test = evaluatorAUC.evaluate(test_pred)
# 評価指標の出力
print("PR train:", pr_train)
print("AUC train:", auc_train)
print("PR test:", pr_test)
print("AUC test:", auc_test)
PR train: 0.847168047612724
AUC train: 0.8648916320839469
PR test: 0.8432895226140703
AUC test: 0.8633701428270321
Train および Test データ、それぞれの指標値を見る限り過学習は発生してなさそうですね。
混合行列可視化
定義しておいた関数にモデリングの結果を渡して、混合行列を可視化します。
# 予測結果の一時ビュー作成
test_pred.createOrReplaceTempView("test_pred")
# テスト結果の混合行列 spark df の作成
test_pred_cmdf = spark.sql("select a.label, a.prediction, coalesce(b.count, 0) as count from cmt a left outer join (select label, prediction, count(1) as count from test_pred group by label, prediction) b on b.label = a.label and b.prediction = a.prediction order by a.label desc, a.prediction desc")
# Pandas df に変換
cm_pdf = test_pred_cmdf.toPandas()
# 混合行列の配列生成
cm_1d = cm_pdf.iloc[:, 2]
TP, FN, FP, TN = cm_1d
# 2次元にする
cm = np.array([[TP, FN], [FP, TN]])
# 混合行列描画
plot_confusion_matrix(cm, "Confusion Matrix (Unbalanced Test)")
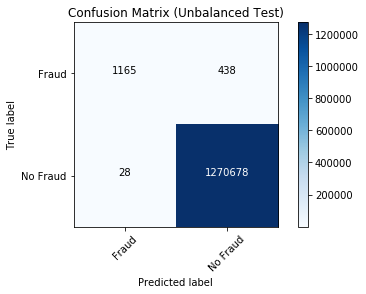
TN (本当は不正取引なのに通常取引と判断されてしまったもの。図右上) が 438件。TP (不正取引だと正しく予測されたもの。図左上) の件数と並べてみると、不正取引の対策のための参考情報としては少々心もとないような気がします。
メトリクスの保存
mlflow にメトリクスとして保存しておきます。作図した混合行列もそのまま保存できます。
with mlflow.start_run(experiment_id = mlflow_experiment_id) as run:
mlflow.log_param("balanced", "no")
mlflow.log_metric("AUC train", auc_train)
mlflow.log_metric("AUC test", auc_test)
mlflow.log_metric("PR train", pr_train)
mlflow.log_metric("PR test", pr_test)
# モデルのロギング
mlflow.spark.log_model(dt_model, "model")
# 混合行列もログとして残す
mlflow.log_artifact("confusion-matrix.png")
まとめ
今回は初回モデルを構築、評価指標の算出まで行いました。次回は学習させるデータセットのばらつきを考慮したモデルを作成、mlflow で初回モデルとの比較を行います。お楽しみに!
参考リンク
datarbicks Resources (公式参考記事集)
Detecting Financial Fraud at Scale with Decision Trees and MLflow on Databricks
mlflow - track machine learning training runs
Synthetic Financial Datasets For Fraud Detection
Binary Classifier Evaluation made easy with HandySpark
notebook