はじめに
機械学習モデルを作る際、まずは様々な切り口でデータを眺め、仮説を立てるプロセスが必要不可欠です。
本稿では Collaboravive Notebook の可視化機能を用いて、データの全体像を把握します。
連絡目次
- 導入/環境設定
- Collaborative Notebook でデータ可視化 → 本稿
- Anomaly Detector をデータ探索ツールとして使ってみる
- 1つ目のモデル構築 (データの偏り 未考慮)
- [2つ目のモデル構築 (データの偏り 考慮)] (https://qiita.com/Catetin0310/items/0780b4e0f1ba07509930)
データ概要
PaySim というアフリカ諸国で実行されたモバイル決済サービスのトランザクションログデータです。
カードや銀行口座を持っていない人たちがどんどん経済圏に流入しているような地域では、日常の決済手段に加えて、出稼ぎ労働者の送金手段として、生活インフラの一部として普及しているそうです。
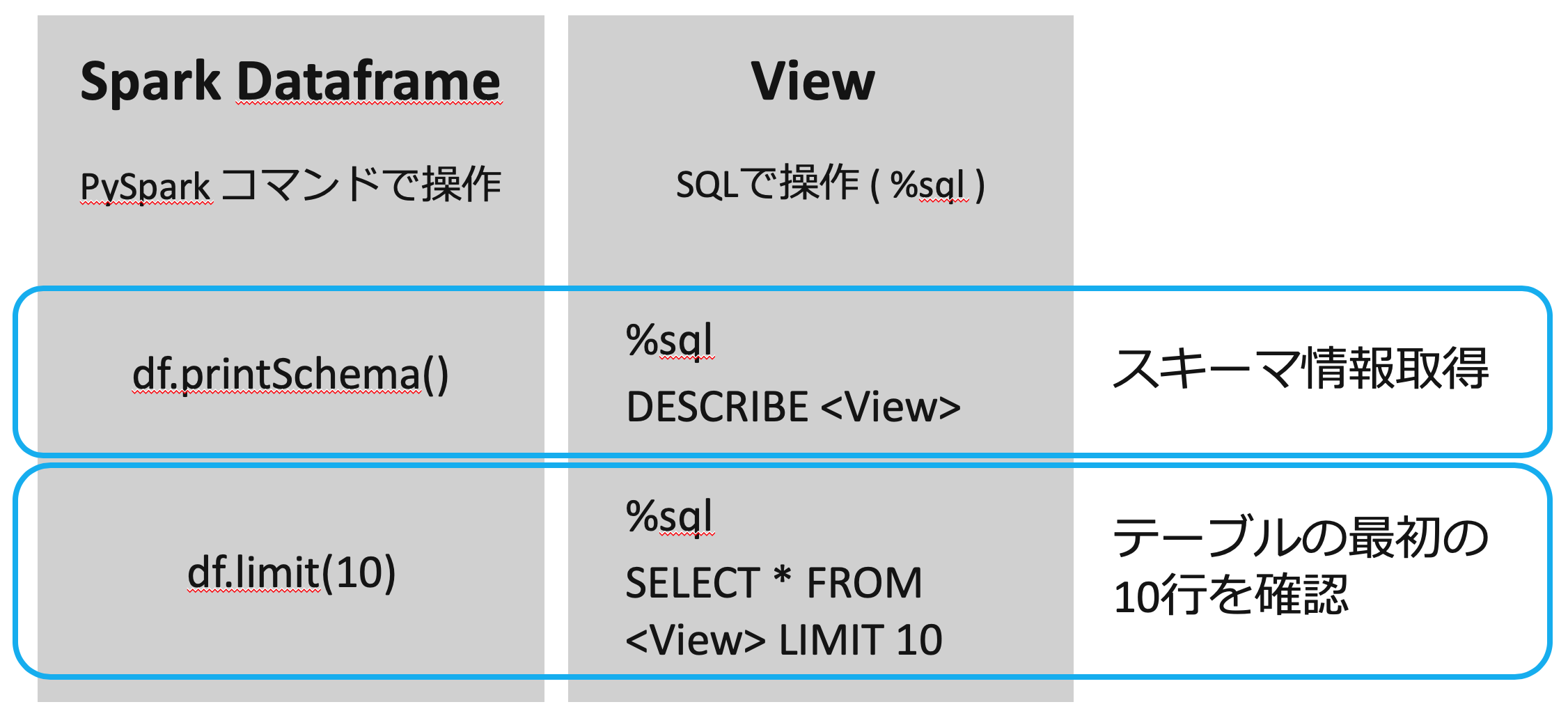
Spark Dataframe と View について
Spark Dataframe と View (もしくはTable)で、利用できるコマンドが異なっています。
私の場合は PySpark を使い慣れていないので、モデリングを行う際に前者を、データ探索やアドホックな可視化をしたい場合に後者、といった使い分けをすることが多いです。
前準備
ここからは実際に Notebook 上でコードを実行しつつ、データの中身を見て行きます。まず直接SQLを書けるようにするために以下のコードを実行します。不正取引の実行者はもともと大量の預金がある口座を使っているとは考えにくい(足が着いたら口座凍結される)ので、口座残高の変化を算出するカラムを追加しています。
# 前の記事で作成したテーブルに対してクエリを発行して spark dataframe を生成
df = spark.sql("select * from sim_fin_fraud_detection")
# withColumnRenamed : 通常/不正の判定が入っているカラムの名称を isFraud から label に変更
# withColumn: 取引実行者の口座残高の変化、取引先の口座残高の変化、の2カラムを追加
df = df\
.withColumnRenamed("isFraud", "label")\
.withColumn("orgDiff", df.newbalanceOrig - df.oldbalanceOrg)\
.withColumn("destDiff", df.newbalanceDest - df.oldbalanceDest)
# 同じ内容のテーブルを Delta Lake 形式で保存、テーブルとして永続化
df.write.format("delta").partitionBy("type").saveAsTable("financials")
# 作成した Dataframe を見てみる
display(df)
result

それぞれのカラムの詳細は以下の通り。
今回の場合、isFraud が目的変数(最終的に予測したい値) になります。
| カラム名 | 明細 |
|---|---|
| step | 現実世界でのタイムスパンの通し番号。1ステップ1時間で30日間分のデータ。計 744 ステップ。 |
| type | 取引タイプ。CASH-IN (入金), CASH-OUT(出金), DEBIT(デビット), PAYMENT(通常支払い), TRANSFER(送金)の5種類 |
| amount | 現地通貨での取引額 |
| nameOrig | 取引実行者の顧客ID |
| oldbalanceOrg | 取引実行者の初期残高 |
| newbalanceOrig | 取引実行者の取引後残高 |
| nameDest | 取引先の顧客ID |
| oldbalanceDest | 取引先の初期残高 (nameDest が M で始まる場合情報なし) |
| newbalanceDest | 取引先の取引後残高 (nameDest が M で始まる場合情報なし) |
| orgDiff | 取引実行者の口座残高の変化 |
| destDiff | 取引先の口座残高の変化 |
| isFraud | 正解ラベル。1が実際に不正取引であった取引、0が通常取引 |
| isFlaggedFraud | 予測結果。1が不正取引と予測された取引、0が通常取引と予測された取引 |
データ可視化
Notebook 上でクエリを実行した場合、デフォルトでは表形式で出力されます。
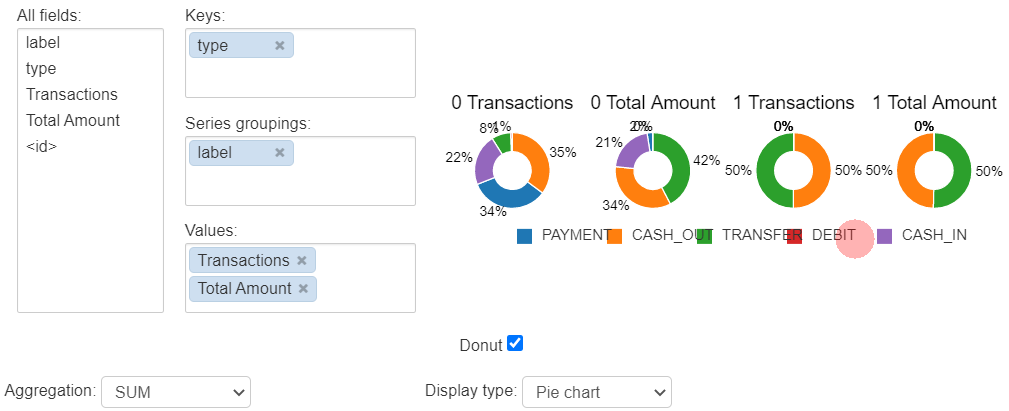
以下のようにドラッグアンドドロップで、クエリの実行結果をそのまま可視化できます。Excel のピボットグラフのような使用感です。わざわざ matplotlib 使わなくてもいいのでとても便利。

1. 不正取引の全体に占める割合
件数ベースで 約 0.13%、金額ベースで 約 1.1%。
かなり偏りがあるので、Train モデリングに使用するデータは注意する必要があります。
SELECT
label
, count(1) as cnt
, round(sum(amount)/1000000, 0) as mount_div_mil
FROM financial
GROUP BY label
result0

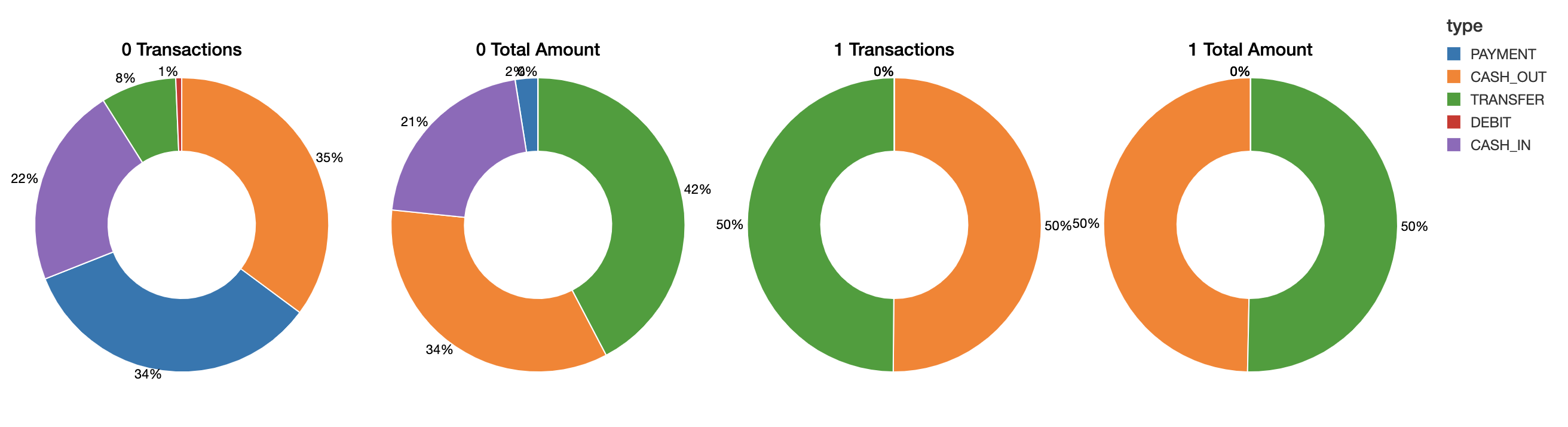
2. 取引タイプ毎 トランザクション数 及び 金額総計
左2つの円グラフが通常取引の集計です。TRANSFER と CASH_OUT で取引金額の 3/4 位を占めています。PAYMENT は小口取引が多く、TRANSFER は大口取引が多いようです。この辺りは利用用途をイメージすると肌感とも合致します。
右2つが不正取引の集計結果です。トランザクション数と取引金額ともに CASH_OUT と TRANSFER が半々。
SELECT
label
, type
, count(1) as `Transactions`
, sum(amount) as `Total Amount`
FROM financials
GROUP BY type, label
result1
plot option 1
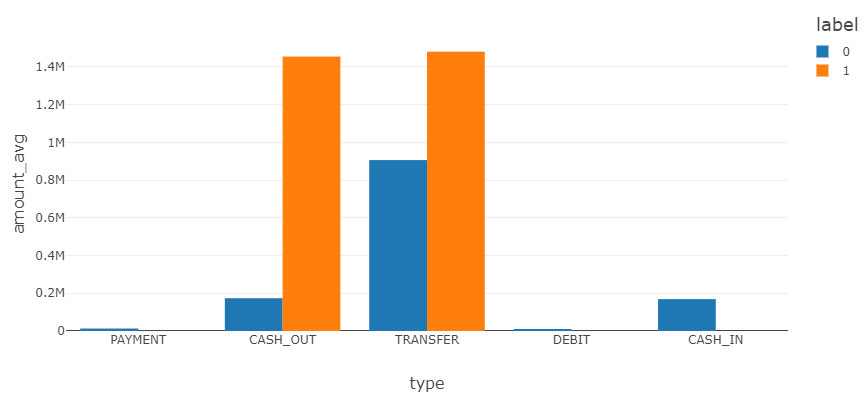
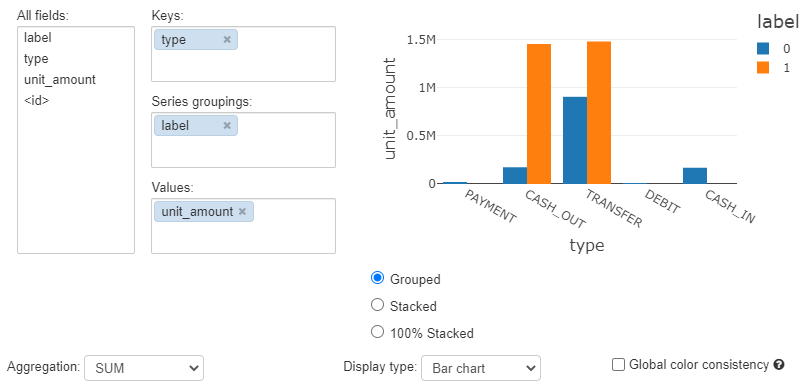
取引タイプ毎 平均単価
0 が通常取引、1 が不正取引の平均単価です。CASH_OUT の相違が顕著です。
※ 統計量については Spark Dataframe での算出がスムーズです → こちら
SELECT
label
, type
, AVG(amount) as amount_avg
FROM financial
GROUP BY type, label
result2
plot option 2
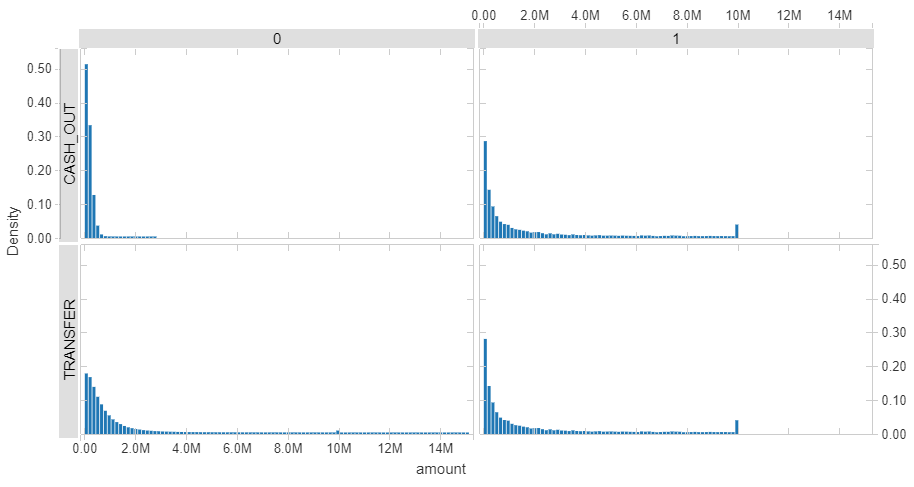
3. TRANSFER 及び CASH_OUT ヒストグラム
不正取引には 10 mil の付近にスパイクが見られます。取引金額の初期上限値と思われます。今回のデータには含まれませんが、モバイル決済の登録時情報やアクセスログなども踏まえて分析するとおもしろそうです。
SELECT
label
, type
, amount
FROM financial
WHERE (type='CASH_OUT' or type='TRANSFER') and amount < 15000000
result3
plot option 3
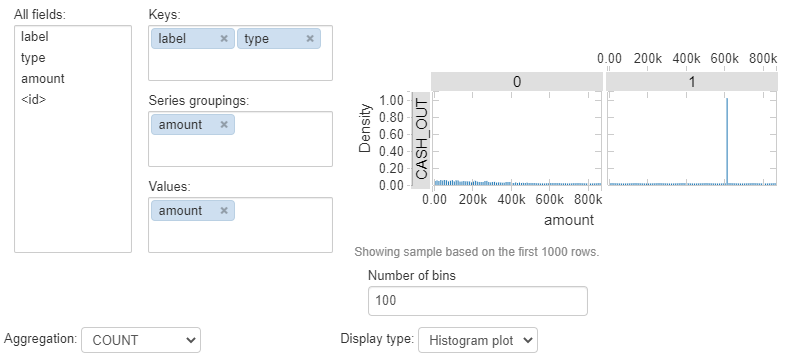
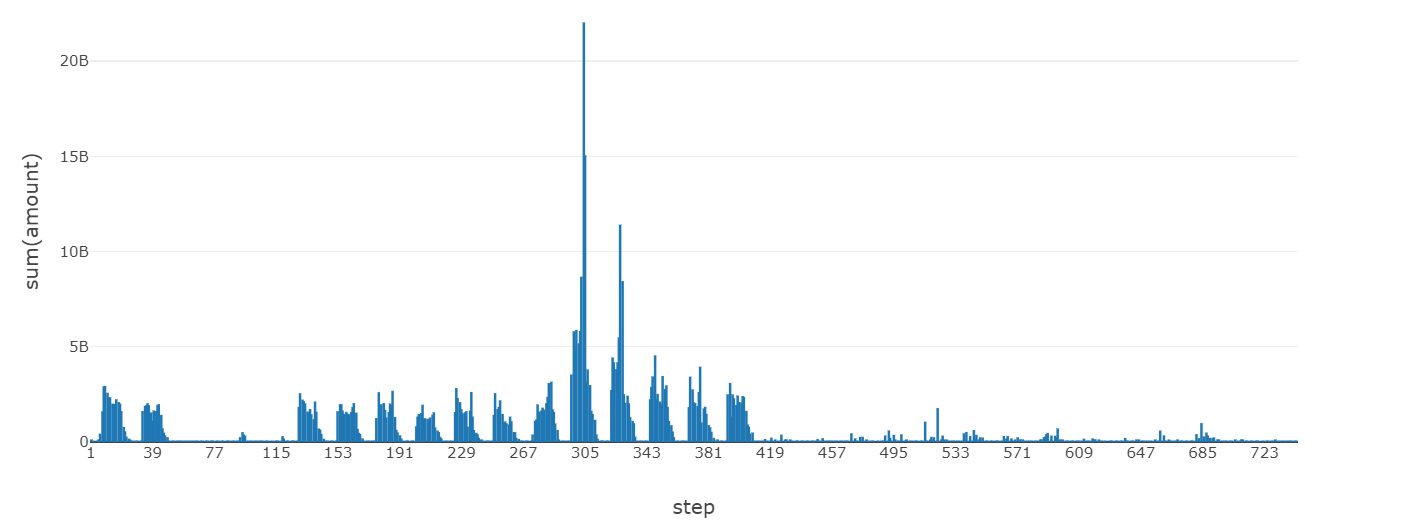
4. TRANSFER 取引金額 時系列推移
ここからは取引タイプ TRANSFER のみを抜粋してみてみます。日ごとの周期が見られ、120-420 のステップではこれがはっきりしています。STEP 345 付近でスパイクが見られます。例えば日本で言う5-10日のようなイベントによるものかもしれません。
SELECT step, sum(amount)
FROM financials
WHERE type='TRANSFER'
GROUP BY step
ORDER BY step
result4
plot option 4
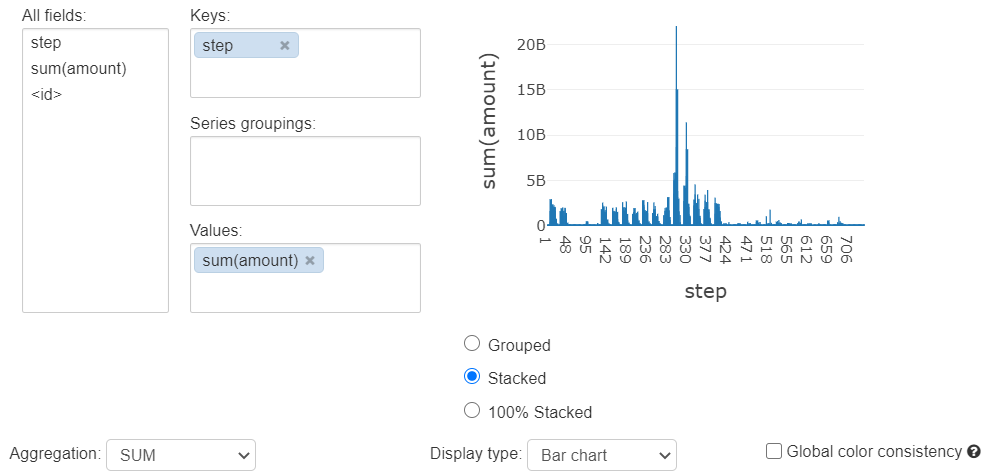
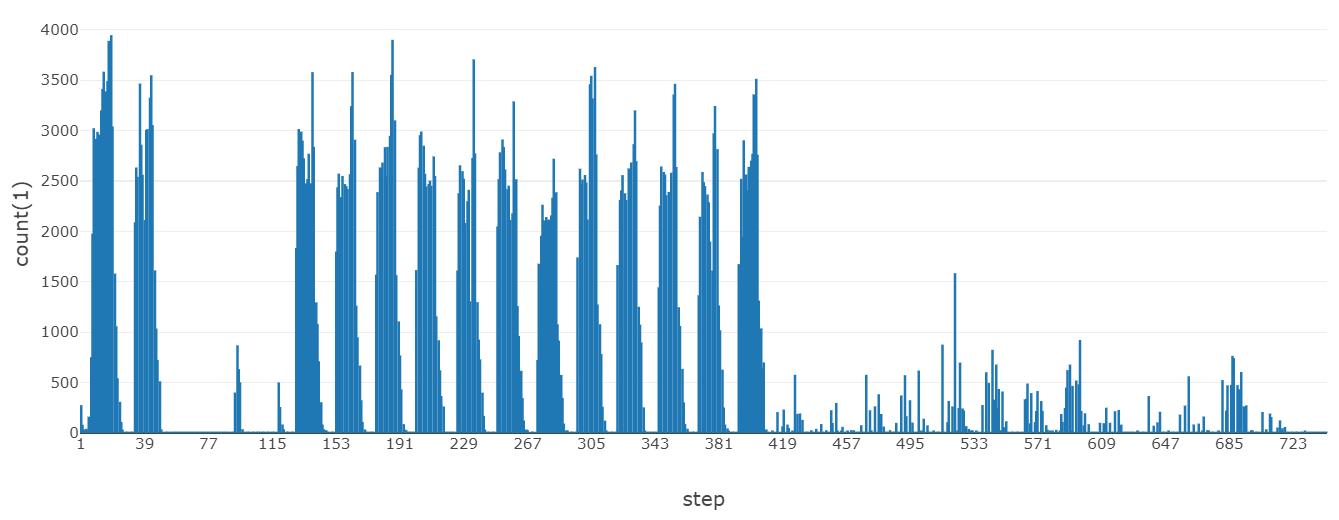
5. TRANSFER トランザクション 時系列推移
トランザクション数のほうがはっきりと周期性を確認できます。月単位/年単位のログがあれば、システム負荷の予測を通して運用コストの最適化を検討できそうです。
SELECT step, count(1)
FROM financials
WHERE type='TRANSFER'
GROUP BY step
ORDER BY step
result5
plot option 5
6. TRANSFER 口座残高の変化
取引実行者の口座残高変化額、取引相手の口座残高の変化額を、取引実行者と取引相手のペアごとに見てみます。まずは通常取引。
SELECT
nameOrig
, nameDest
, sum(OrgDiff) as TotalOrgDiff
, sum(destDiff) as TotalDestDiff
FROM
financial
WHERE
type='TRANSFER' AND label=0
GROUP BY
nameOrig
, nameDest
ORDER BY
TotalOrgDiff
LIMIT 1000
result6
plot option 6
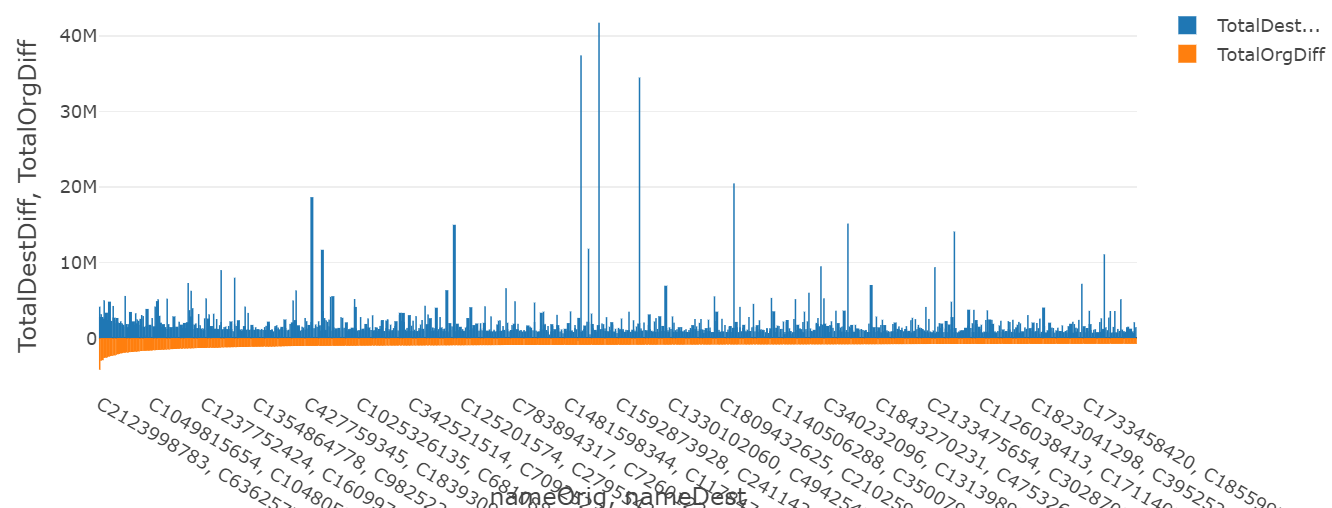
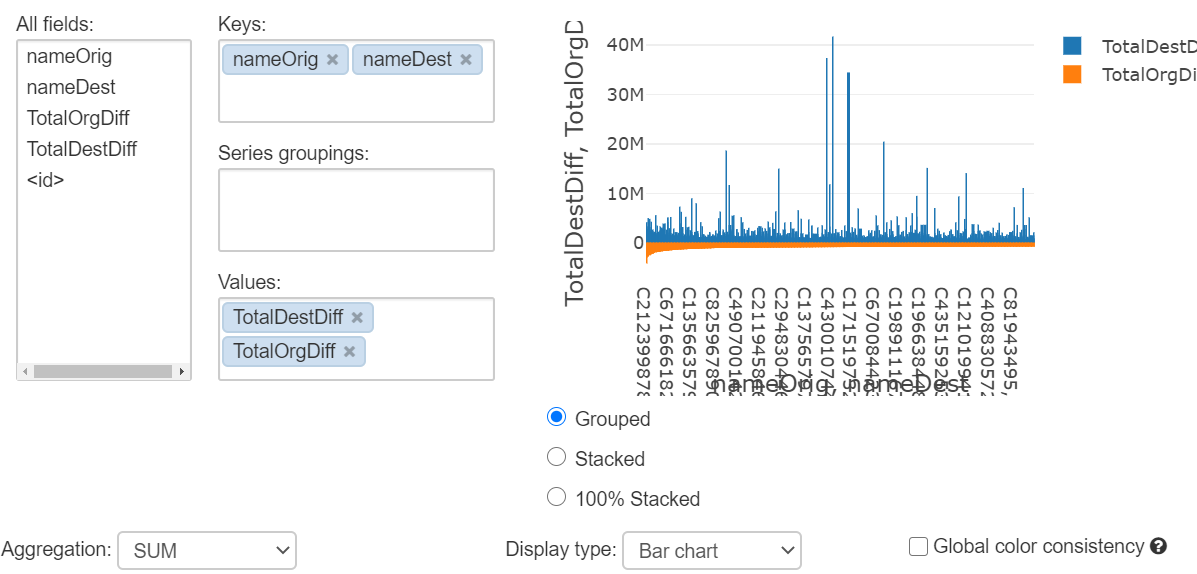
次に不正取引です。destDiff もしくはnewbalanceDest や oldbalanceDest が特徴量として効いてくるモデルが生成されそうです。(本番でのモデル運用考えるとこれら数値の算出タイミングが気になるところです)
SELECT
nameOrig
, nameDest
, sum(OrgDiff) as TotalOrgDiff
, sum(destDiff) as TotalDestDiff
FROM
financial
WHERE
type='TRANSFER' AND label=1
GROUP BY
nameOrig
, nameDest
ORDER BY
TotalOrgDiff
LIMIT 1000
result7
plot option 7
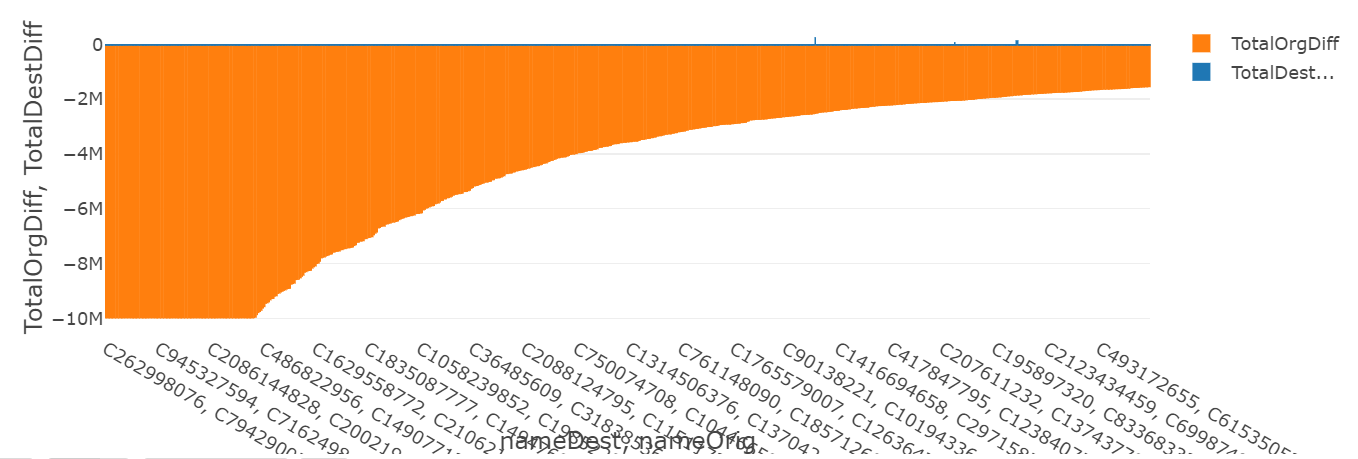
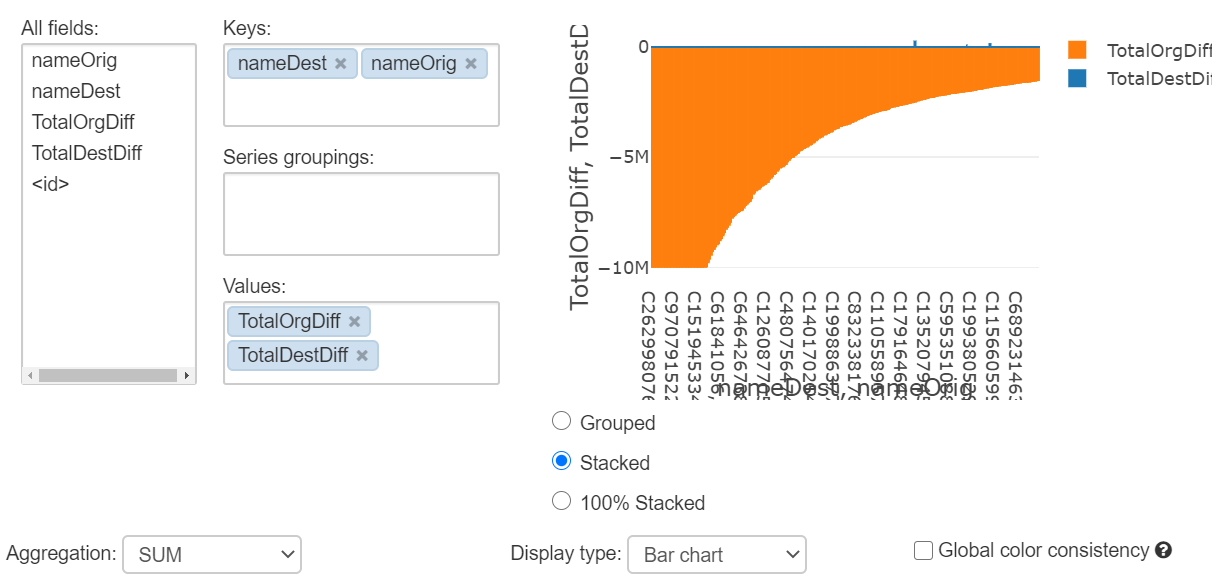
まとめ
データ全体の傾向や特徴を簡単に見てきました。次回は時系列データからの異常検知に Azure Anomaly Detector を利用してみます。お楽しみに!
備考:連番テーブル作成
今回のデータでは必要ありませんが、SparkSQLでは以下のように連番テーブル(いわゆるダミーテーブル)を作成できます。
from pyspark.sql.functions import col
from pyspark.sql import SparkSession
start = 1
end = 744
spark = SparkSession.builder.getOrCreate()
step_table = spark.range(start, end).select(col("id").cast("bigint"))
step_table.createOrReplaceTempView("step_table")
参考リンク
Detecting Financial Fraud at Scale with Decision Trees and MLflow on Databricks
Detecting Financial Fraud at Scale with Decision Trees and MLflow on Databricks 翻訳まとめ
Databricks Visualization