背景
非常に 小さな処理 などを複数の Notebook から使いまわしたい場合があります。
ずばっとした Hello-World のサンプルがあまり無いので、基礎 事項をまとめておきます。
注意点:
- 例外処理を書いていません
Sample Code
フォルダー構造
以下の様になっています。
├─ run.ipynb --- 呼び出し側
└─ tools.ipynb --- 呼び出される側
呼び出し側 (run.ipynb)
result = dbutils.notebook.run("./tools", 60, {"x" : 1})
print(result)
引数 x に 1 を指定しています。
呼び出される側 (tools.ipynb)
dbutils.widgets.text("x", "0", "0")
x = getArgument("x")
dbutils.notebook.exit(int(x) + 1)
1つの Notebookが、1つの関数程度と捉えてもらった方がいいかもしれません。
dbutils.wideget.text を使って、引数 x を定義しています。そして、getArgument 関数で、その値を取り出しています。
開発上のTips
Azure Databricks ポータル上での実行に便利なネタです。
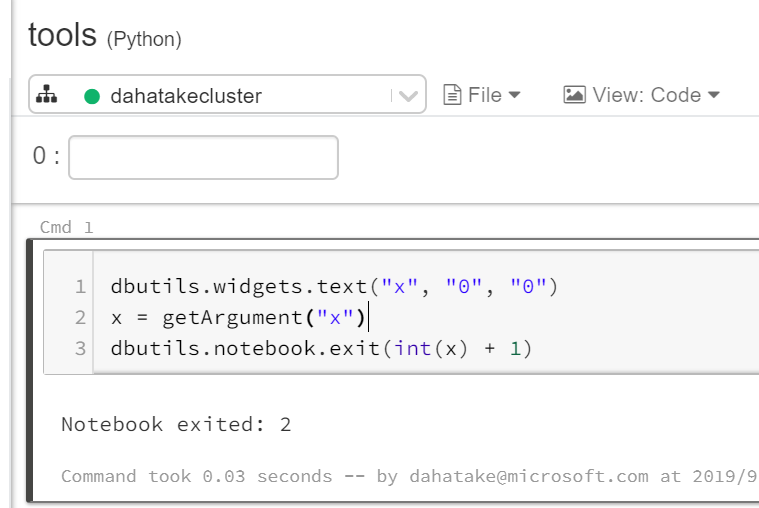
呼び出される側 単体で引数をセットする
見落としがちなのですが、ポータル上の画面上部に引数を設定できるテキストボックスがあります。そちらに設定したい引数を入れます。
呼び出し側から、呼び出した先でのエラーを確認する
単純なバグなどの発見に役に立ちます。これ初期には意外と気づかなかったりします...😅
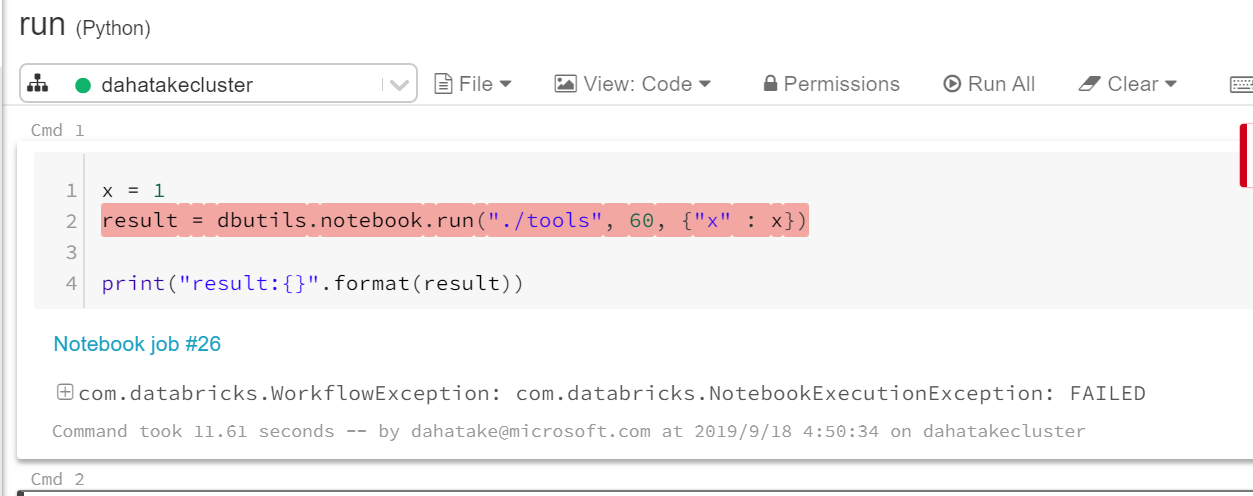
一見すると、トラブルシュートに役に立つエラーを出力してくれていません。
ここでは、リンクが設定されている [Notebook job #26] といった、ジョブの実行履歴を見ます。
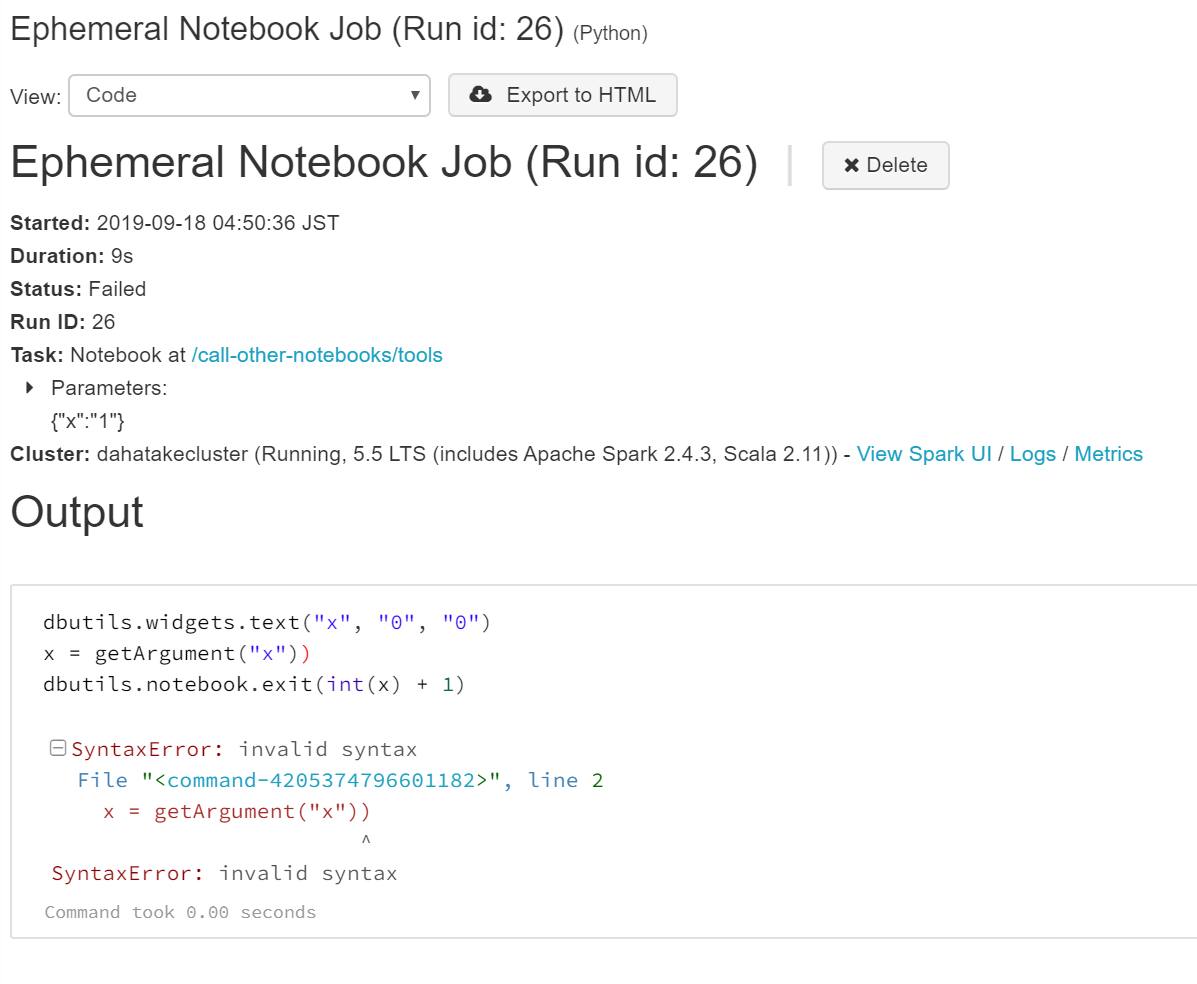
ここでは、SyntaxError だった、という事がわかるかと思います。
Global 変数が使えない
これも注意が必要です。
dbcファイル
Source:
https://dahatakestorage.blob.core.windows.net/code/call-other-notebooks.dbc
自分のPC/Macにダウンロードします。それを Azure Databricks のコンソールから、Import してください😊
Azure Data Factory から Databricks の Notebook を呼び出す
上記も良いのですが😁
結局呼び出し元は、それぞれのNotebookの呼び出し、結果のハンドル、データはファイルとして共有、といった事が増えてくると思います。
Azure には、Azure Data Factory というサービスがあり、上記を比較的簡単に実現できます😊

結局ジョブの実行履歴は管理したいし、PaaSのRDBMSからのデータダンプが意外とサクッとできないし、という事で。
Azure Data Factory で Databricks Notebook アクティビティを使用して Databricks ノートブックを実行する:
https://docs.microsoft.com/ja-jp/azure/data-factory/transform-data-using-databricks-notebook
Databricks Notebook を実行してデータを変換する:
https://docs.microsoft.com/ja-jp/azure/data-factory/transform-data-databricks-notebook
まとめ
Azure Databricks だけでも、ある程度の事は出来ます。
ただ、ジョブフロー制御という観点では、C# / Java / Python / JavaScript 等の様な柔軟なフロー制御はそもそも得意ではないので、どこかで限界があります。
うあく使い分けでください。
参考
-
Notebook Workflows: The Easiest Way to Implement Apache Spark Pipelines:
-
Notebook Workflows (公式ドキュメント)
https://docs.databricks.com/user-guide/notebooks/notebook-workflows.html