【C++】円周率の近似値が途中で発散してしまう
Q&A
Closed
次のサイト
で紹介されている円周率計算のプログラムについて質問です。
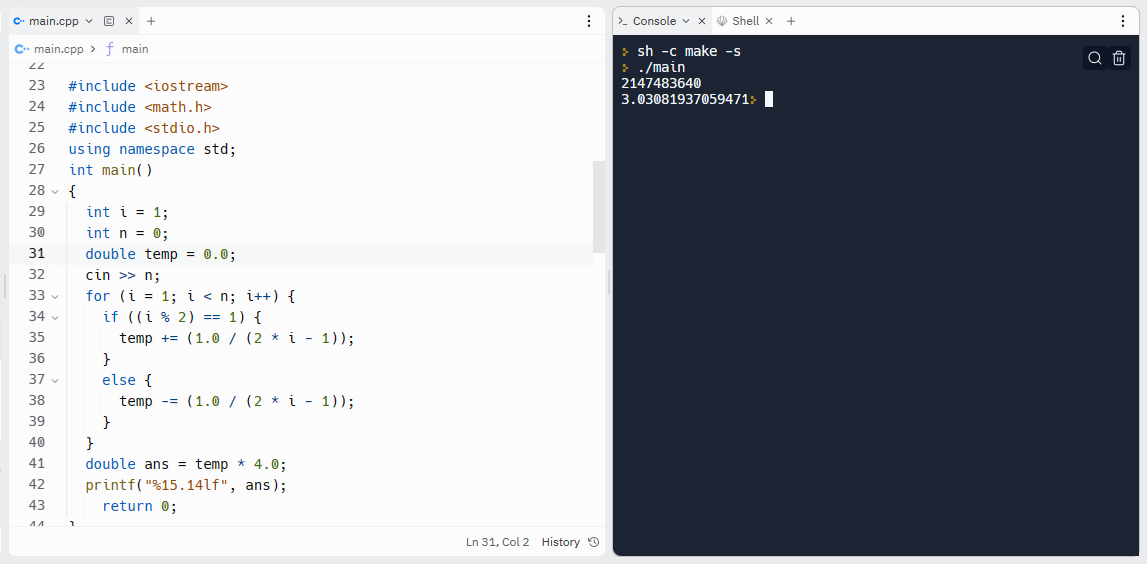
#include <iostream>
#include <math.h>
#include <stdio.h>
using namespace std;
int main()
{
int n = 0;
double temp = 0.0;
cin >> n;
for (int i = 1; i < n; i++) {
if ((i % 2) == 1) {
temp += (1.0 / (2 * i - 1));
}
else {
temp -= (1.0 / (2 * i - 1));
}
}
double ans = temp * 4.0;
printf("%15.14lf", ans);
return 0;
}
n:加算する分数の個数 (キーボード入力)
temp:分数を個数分加算して最終的な値を4倍にして (ans) 出力
i:ループのカウント
このプログラムを「Replit」にて実行した時、nを大きくしていく事で出力値ansはπに収束するかと思いきや、nをint型の上限値 (2147483647) まで近づけると、今度はansの振れ幅が大きくなり、πの理論値から遠のき始めました。
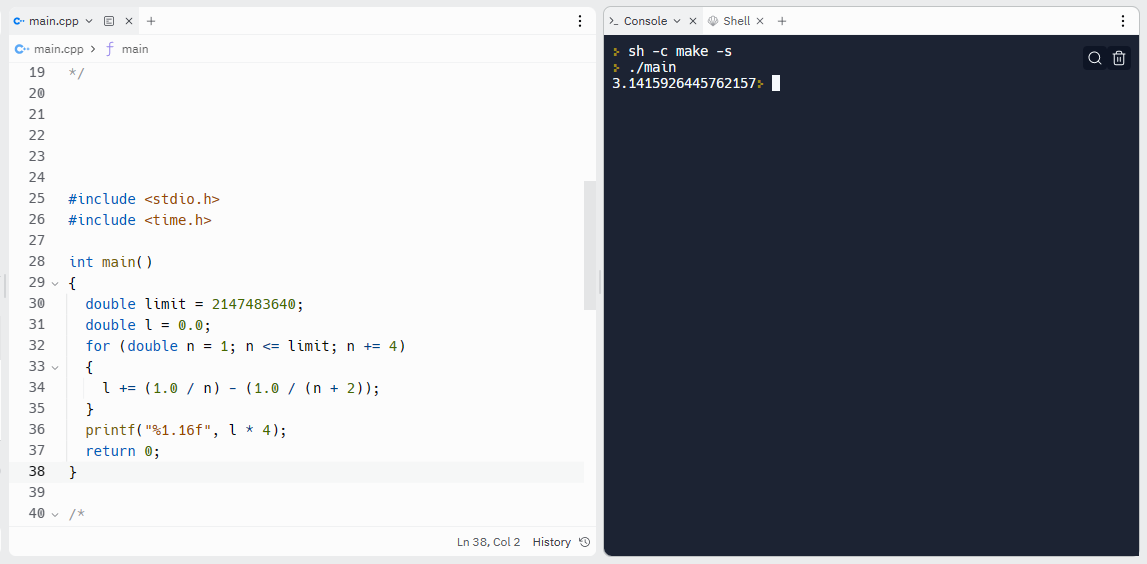
次のサイトのプログラムだと、入力値を十分に大きくしても出力値は期待通りπに収束します。
#include <stdio.h>
#include <time.h>
int main()
{
double limit = 2147483640;
double l = 0.0;
for (double n = 1; n <= limit; n += 4)
{
l += (1.0 / n) - (1.0 / (n + 2));
}
printf("%1.16f", l * 4);
return 0;
}
int型であるnumのとりうる値の範囲も考慮してキーボード入力したつもりなので、一番上のプログラムの加算方法でなぜ出力値が途中から発散し出すのか疑問でなりません。ささいな事でも良いので、アドバイス頂けないでしょうか?
0 likes