本記事はKubernetes Advent Calendar 2018の6日目です。
昨日は@nnao45さんの「kubectl-completion-zshを車輪の再発明した」でした。
コマンド補完、いいですよね。あれやこれや一々打つの面倒くさいし!
さて私は「PostgreSQL on Kubernetes 2018(全部俺)」のAdvent Calenderを執筆中ですが、そこでデータベースをStatefulSetで動かしています。
その際に起きた問題や調べたことを書いていきたいと思います。
TL;DR
- PostgreSQLをStatefulSetで動かしたら、Failoverしなかったよ。
- 良く調べたらそれが仕様。
- operatorを使えるようになるとつよい。
PostgreSQL on Kubernetes
こちらで述べたように、PostgreSQLをContainer-Nativeな分散ストレージ:Rookの上で動かすという構成を作ってみました。
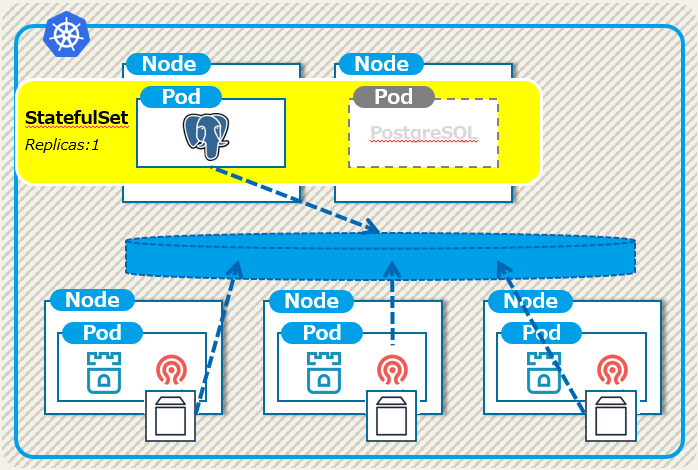
このとき、PostgreSQLのワークロードにはStatefulSetを使っていますが、Active-Standbyの構成を意識し、Replicasは1、つまり起動しているデータベースは常に1台という形にしています。
この構成の特徴は以下となります。
- PostgreSQLインスタンスは常に1つ、ノード障害時は副系でインスタンスを起動する。
- データはRookが展開するCephのブロックデバイスに格納。ノードを跨ぐFOにも対応。
- PostgreSQLのポッドがrecreateされても、Serviceを介することで一意な名称でアクセス
問題点:StatefulSetはFailoverしない
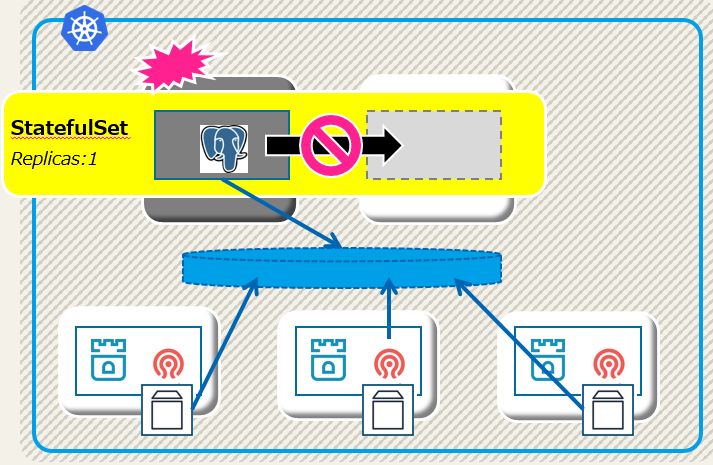
既に使っている人はご存知のことかと思うのですが、StatefulSetの基本的な考え方として、ポッドが稼動しているノードがダウンした際に別ノードでポッドを再起動する、ということをしません。
つまり、Active-Standbyな構成では必須のクラスタリソースのFailoverがされず、下図のようにPostgreSQLインスタンスが1つも起動されない状態になります。
仕様(のよう)です
同じようなことに悩む人は多いようで、本家Kubernetesのgithubにも当問題に関するissueがありました。
StatefulSet pod is never evicted from shutdown nodeがそれで、問題に対応したプルリクまで作成されたようですが、それに対してこのようなコメントがされています。
This is by design. When a node goes "down", the master does not know whether it was a safe down (deliberate shutdown) or a network partition.
If the master said "ok, the pod is deleted" then the pod could actually be running somewhere on the cluster, thus violating the guarantees of stateful sets only having one pod.
(Google翻訳)
これは設計によるものです。ノードが「ダウン」状態になると、マスタは安全ダウン(意図的なシャットダウン)かネットワークパーティションかを認識しません。
マスターが「OK、ポッドが削除されました」と言った場合、ポッドは実際にクラスタ上のどこかで動作している可能性があり、ポッドが1つしかないステートフルなセットの保証に違反します。
こちらのブログでも同じことを言っています。
Kubernetes doesn’t want a Pod to be immediately restarted on another node to reduce a possible split-brain scenario.
However, if the storage provider is capable, pod.Spec.TerminationGracePeriodSeconds can be added to the StatefulSet and the Controller will automatically restart the Pod on a new host after it’s gone into an “Unknown” state.
(Google翻訳)
Kubernetesは、スプリットブレインシナリオの可能性を減らすために、別のノードでポッドをすぐに再起動することは望ましくありません。
ただし、ストレージプロバイダが対応可能であれば、pod.Spec.TerminationGracePeriodSecondsをStatefulSetに追加することができます。コントローラは、「Unknown」状態になった後、自動的に新しいホスト上でPodを再起動します。
Failoverさせるには
では、このような状態に陥ったらどうすべきかを考えてみましょう。
ポッドが稼動していたノードが停止してしまった場合、以下のような状況になります。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
node001 NotReady worker 15d v1.10.5
node002 Ready worker 15d v1.10.5
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
pg-rook-sf-0 1/1 Unknown 0 15m
ノード:node001がNotReadyになっており、その上で動いていたポッド:pg-rook-sf-0のSTATUSがUnknownになってしまいます。
これを放っておいても、node002でpg-rook-sf-0のポッドが起動することはありません。
node002でpg-rook-sf-0を起動させる方法の一つとして、強制削除する方法があります。
$ kubectl delete pod pg-rook-sf-0 --force --grace-period=0
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
pod "pg-rook-sf-0" force deleted
$ kubectl get node
NAME STATUS ROLES AGE VERSION
node001 NotReady worker 15d v1.10.5
node002 Ready worker 15d v1.10.5
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pg-rook-sf-0 1/1 Running 0 5s 10.42.6.21 node002
ポイントはdeleteコマンドに付けられた --force --grace-period=0 の2つのオプションです。
このオプションを付けることでKubernetesはポッドにいきなりSIGKILLを送信します。
これにより下記のように動作しているように見えます(詳細はちょっと違うかも)。
- 応答できないノード上のポッドが強制削除され、管理情報(etcd?)も更新される。
- ポッド数が0となったことで、ReadyなノードでPostgreSQLインスタンスが起動される。
- 結果として、Failoverが完了する。
もう一つは上述のブログでも紹介されているしたやり方で、YAMLの中でpod.Spec.TerminationGracePeriodSecondsに0をセットしておくことです。
そうすることでノード障害時に自動でFalioverするようになりますが、こちらはこちらで困ったことになります。
つまり、今回のPostgreSQL on Kubernetesでは常にデータベースがSIGKILLで即時に落とされてしまうことになります(kubectl deleteやapplyでも)。
この方法は公式ドキュメントでも非推奨となっています。
と言いながら、一応こちらのパラメータも検証してみました。
興味のある方はこちらをお読み下さい。
実際のところはこうすべき
- データベースなどのステートフルなアプリではStatefulSetを使いましょう。
とは良く言われることですが、これまで書いてきたように課題もあります。(他の課題は別途Advent Calender内で紹介できればと思っています。)
では、LinuxのHA構成でこれまでCluterProやPacemakerがやってくれていた複雑な処理はどこで扱えばよいのでしょうか。
一つの回答は「operatorで実装しましょう」になります。
StatefulSetで(DeploymentやDaemonsetでも)足りない部分はCustom Controlerで補いましょう、という考え方です。
例えば、Kubecon ChinaでもTiDBという分散データベースの紹介で同じ悩みが述べられています。(資料のPDFはこちら)
また、mysqlですとOracle謹製のmysql-operatorというものがあります。
とあるコミュニュティで教えて頂いて未利用ですが、backup/restoreなども実装されているようです。
PostgreSQLでもHA構成ではなくレプリケーション構成ですが、Crunchy Dataという会社がoperatorを作っているようです。(紹介資料のPDFはこちら)
まとめ
Kubernetesの初心者としては、StatefulSetでFailoverしないという事象は正直バグだと思いました。
しかし、確かに分散システムでsplit brainを恐れる気持ちはDBエンジニアとして良く理解できます。
operatorやCRDによるKubernetesの拡張の必要性も今回の事象を通して強く認識できたので、次はoperator開発にチャレンジしてみようかと思います。
ありがとうございました。