本記事はPostgreSQL on Kubernetes Advent Calendar 2018の7日目です。
昨日は「pgbenchでお手軽ベンチマーク」ということで、PostgreSQL on Kubernetesと同じクラスタ内にpgbenchを動かし、初期データのセットアップとベンチマークを動かしてみました。
今日は今回の構成で障害が発生したときにどのような動作となるのかをテストして、整理してみたいと思います。
TL;DR
- PostgreSQL on KubernetesでDBノードが障害となったケースを試してみた。
- StatefulSetではノード障害時にポッドをFailoverしない。
- 自動復旧させることもできるけど、Failoverに5分かかったよ。
今回の構成と障害ポイント
これまで何度かお見せしていますが、あらためてPostgreSQL on Kubernetesの構成を確認しておきましょう。
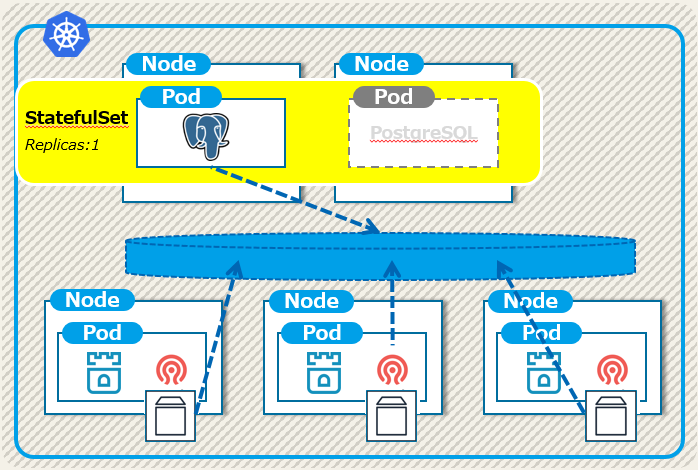
障害パターンとしては以下が想定されます。
| 障害分類 | 障害部位 | 想定する動き |
|---|---|---|
| ノード | DBノード | サービス継続、PostgreSQLフェイルオーバ |
| ストレージノード | サービス継続、Ceph縮退 | |
| ポッド | PostgreSQL | サービス停止、PostgreSQLポッド再起動 |
| Rook.operator | サービス継続、Rookポッド再起動 | |
| Rook.Agent | サービス継続、Rookポッド再起動 | |
| Ceph.MON | サービス継続、Cephポッド再起動 | |
| Ceph.OSD | サービス継続、Cephポッド再起動 |
テスト(1) DBノード障害
今回構成ではPostgreSQLインスタンスが常に1つだけ(Replicas=1)です。
そのため、インスタンス稼働中のDBノードが停止した際に、待機系ノードでPostgreSQLがリカバリ起動されないことにはサービスが再開できません。
まずはこの障害ケースをテストしていきます。
手順は以下の通りです。
- pgbenchで3分程度のベンチマークを流す。※但し2.の時点で止まる。そこでサービス停止時間を計測。
- pg-rook-sf-0のポッドが稼動しているノードを停止。
- pg-rook-sf-0のポッドが別ノードでRunningとなることを確認。
- PostgreSQLのログから起動時間を確認。1.との差分でサービス停止時間を計測。
ただ、結論からいうと上記のような動きは実現できませんでした。
何が問題か?
私が仕様を理解できていない部分があったのですが、KubernetesのStatefulSetではノード障害時にポッドを再起動してくれません。
そのため、下図のようにPostgreSQLインスタンスがどのノードでも起動せず、サービス完全停止に陥ります。
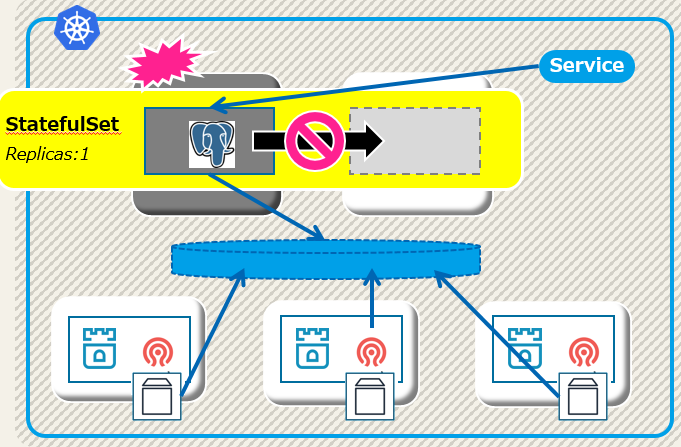
この動き(=仕様)については、「StatefulSetでActive-Standbyなデータベースを動かしてみた話」としてまとめていますので、背景を知りたい方はこちらもお読み下さい。
なお、HA構成を取っているのにノード障害から自動復旧しないというのは方式として成立していません。
ということで、先ほどの記事には「この方法は公式ドキュメントでも非推奨」と書いた、pod.Spec.TerminationGracePeriodSecondsを0にして障害テストをやってみました。
pod.Spec.TerminationGracePeriodSeconds=0の場合
この場合、別ノードでStatefulSetに属するPostgreSQLポッドが起動されました。
動きとしては以下となります。
- pgbenchを実行。
- ノードを停止。14:18:52に最後のトランザクションが実行され、pgbenchはABENDする。
- 14:23:52に別ノードでPostgreSQLが起動される。この間、5分(300秒)かかっている。
- PostgreSQLがリカバリを実行。下記のログからは約10秒でリカバリ完了。
実際のpostgresql.logは以下になります。
14:23:52.574 JST [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
14:23:52.574 JST [1] LOG: listening on IPv6 address "::", port 5432
14:23:52.583 JST [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
14:23:52.620 JST [25] LOG: database system was interrupted; last known up at 2018-12-05 14:06:45 JST
14:23:52.659 JST [25] LOG: database system was not properly shut down; automatic recovery in progress
14:23:52.667 JST [25] LOG: redo starts at 0/900000D0
14:24:02.188 JST [25] LOG: invalid record length at 0/A5828160: wanted 24, got 0
14:24:02.188 JST [25] LOG: redo done at 0/A5828138
14:24:02.188 JST [25] LOG: last completed transaction was at log time 2018-12-05 14:18:52.557874+09
14:24:02.206 JST [25] LOG: checkpoint starting: end-of-recovery immediate
この5分で別ノードでポッドを起動、というのはこちらで書かれている内容とも整合します。
- フェイルオーバに6分ほどかかるので注意
- ノードから40秒status updateがないとNotReady
- ノードが5分間NotReadyなら障害とみなしPodをEvict
- --node-monitor-grace-period=40s
- --pod-eviction-timeout=5m0s
下の2行はkube-contorller-managerのパラメータになります。
こちらを変更すれば、このフェイルオーバに時間は調節できそうですが試せていません。
まとめ
今回のPostgreSQL on Kubernetesですが、Active-StandbyのHA-DBクラスタをKubernetes上に構築することを目標としています。
にも関わらず、Kubernetesにbuilt-inされているStatefulSetではそれが実現できないという課題が発生しました。
明日以降、引き続き他の検証を進めて、想定している構成に必要となる機能が洗い出せればと思います。
よろしくお願いします。