はじめに
z/OSのSYSLOGをElasticsearchに取り込む方法のpart3です。やることはpart2で実施したこととほぼ同じで、データの取り込み部分にfluentdの代わりにEmbulkを使ってみました。
ファイル/FTP => Embulk => Elasticsearch => Grafana
という経路でデータ取得、可視化してみます。
最後に、データをElasticsearchに取り込むところについて、fluentdとEmbulkの簡単なパフォーマンス比較もしています。
関連記事
z/OSの新しい管理方法を探る - (1)DAパネル情報のElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (2)-1 SYSLOGのElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (2)-2 SYSLOGのElasticsearchへの取り込み part2
z/OSの新しい管理方法を探る - (2)-3 SYSLOGのElasticsearchへの取り込み part3
z/OSの新しい管理方法を探る - (3)CICSヒストリカルデータのElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (4) RMF MonitorIIIレポートのElasticsearchへの取り込み
Elasticsearchに取り込んだログ情報をGrafanaのLogsで表示
全体像
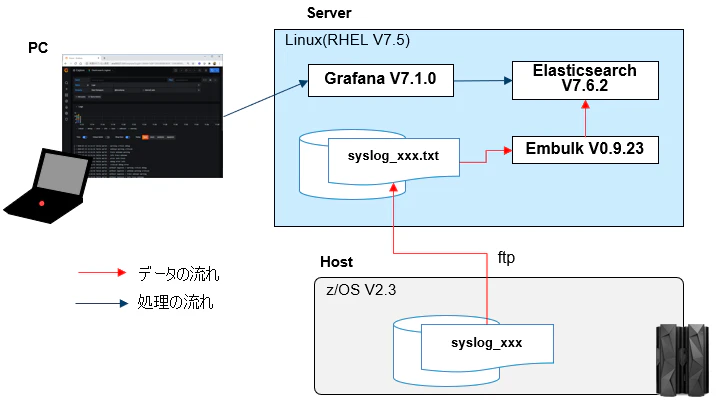
Embulkというのはfluentdのバッチ版みたいな位置づけのOSSです。
今回は数10分とか1時間とかこまめにSYSLOGファイルを落としてきて取り込むという感じではなく、1日~数日のSYSLOGファイルをまとめてどかっとバッチ的にElasticsearchに取り込むイメージです。
Linux側環境
Linux(RHEL7.5)
Elasticsearch 7.6.2
Kibana 7.6.2
fluentd(td-agent) 1.0
Embulk 0.9.23
Grafana 7.1.0
Embulk構成
プラグインのインストール
いくつかembulkのプラグインを使用することになるのでプラグインをインストールします。
以下はインストール済の想定。
EmbulkのElasticsearch用プラグインのインストール
embulk-parser-grokのインストール
[root@test08 ~]# embulk gem install embulk-parser-grok
2020-08-24 16:42:52.549 +0900: Embulk v0.9.23
Gem plugin path is: /root/.embulk/lib/gems
Fetching: embulk-parser-grok-0.1.7.gem (100%)
Successfully installed embulk-parser-grok-0.1.7
1 gem installed
embulk-filter-columnのインストール
[root@test08 ~]# embulk gem install embulk-filter-column
2020-08-25 10:08:03.063 +0900: Embulk v0.9.23
Gem plugin path is: /root/.embulk/lib/gems
Fetching: embulk-filter-column-0.7.1.gem (100%)
Successfully installed embulk-filter-column-0.7.1
1 gem installed
embulk-filter-evalのインストール
[root@test08 ~]# embulk gem install embulk-filter-eval
2020-08-25 09:55:42.186 +0900: Embulk v0.9.23
Gem plugin path is: /root/.embulk/lib/gems
Fetching: embulk-filter-eval-0.1.0.gem (100%)
Successfully installed embulk-filter-eval-0.1.0
1 gem installed
Embulk構成ファイル作成
SYSLOGを取り込むためのEmbulkの構成ファイルを作成していきます。
SYSLOGフォーマットの解釈
複数行にまたがるSYSLOGを解釈するのに、embulk-parser-grokプラグインを使います。
まず、SYSLOG解釈してフィールド単位に分割するためにSYSLOGフォーマットを正規表現で表します。
RECTYPE [NWMOX][CRI ]
DESTCODE .{7}
SYSNAME .{8}
DATETIME [0-9]{5} [0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{2}
IDENT .{8}
MSGFLAG .{8}
ALERTFLAG .{1}
MSGID_SUFFIX [ADEISTW]?
MSGID_MVS [A-Z]{3,7}[0-9]{3,5}%{MSGID_SUFFIX:msgsuffix}
MSGID_JES2 \$HASP[0-9]{3,4}
MSGID (%{MSGID_MVS}|%{MSGID_JES2})
MULTILINE (.*\n)*
MSGTEXT ([+]?%{MSGID:msgid} %{MULTILINE}|%{MULTILINE})
PATTERN01 [ ]?%{RECTYPE:recordtype}%{DESTCODE:destcode} %{SYSNAME:sysname} %{DATETIME:datetime} %{IDENT:ident} %{MSGFLAG:msgflag} %{ALERTFLAG:alertflag}%{MSGTEXT:msgtext}
最終的にPATTERN01というのがSYSLOGの1メッセージ全体を表しています。
これを使って、Embulkの構成ファイルのinput部分の構成を行います。
in:
type: file
path_prefix: syslog_test01.txt
parser:
charset: UTF-8
newline: LF
type: grok
grok_pattern_files:
- pattern/my-patterns
first_line_pattern: '^ [NWMOX]'
grok_pattern: '%{PATTERN01}'
timestamp_parser: SimpleDateFormat
columns:
- {name: recordtype, type: string}
- {name: destcode, type: string}
- {name: sysname, type: string}
- {name: datetime, format: 'yyD HH:mm:ss.SS', type: timestamp, timezone: 'Asia/Tokyo'}
- {name: ident, type: string}
- {name: msgflag, type: string}
- {name: alertflag, type: string}
- {name: msgid, type: string}
- {name: msgsuffix, type: string}
- {name: msgtext, type: string}
...
first_line_patternで、1行目を識別するためのパターンを指定します。
パターンファイルの正規表現でフィールドごとに分割されるので、各フィールドの型を定義します。datetimeはジュリアンデートなのでそのためのフォーマットをSimpleDatFormatで指定しています。
※SYSLOGで出力される時刻情報は10ミリ秒単位になっています。上のようにHH:mm:ss.SSと指定すると、SS部分はミリ秒単位の値と解釈されてしまいます。例えば、上の定義だと"11:22:33.44"という時刻のレコードがあった場合、"11:22:33.044"と解釈されてしまいます。実際のタイムスタンプとはずれてしまいますが、ここの厳密性を求める要件はあまりないと思いますので、これは目をつぶることにします。(厳密に変換させることも可能ですが、複雑な処理を行う分のメリットがないためやめておきます。)
ログレベルの設定
これもPart2と同様にGrafanaのLogs出力用にloglevelというフィールドを追加してみます。
loglevelのフィールド追加用に、msigdの末尾一文字([SEWI])をmsgsuffixというフィールドとして正規表現で抽出しています。
...
filters:
- type: column
add_columns:
- {name: loglevel, src: msgsuffix, default: "unknown", type: string}
- type: eval
eval_columns:
- loglevel: value.gsub(/[SEWI]/, "S"=>"critical", "E"=>"error", "W"=>"warning", "I"=>"info")
...
まず、embulk-filter-columnフィルタープラグインを使って、msgsuffixをコピーしてloglevelというフィールドを新たに作成します。このプラグインのadd_columnsでは、デフォルト値を指定できるので、"unknown"をデフォルト値として設定しておきます。
次に、embulk-filter-evalフィルタープラグインで、loglevelの値を"S"=>"critical", "E"=>"error", "W"=>"warning", "I"=>"info"というように変換してあげます。
※eval_columnsだけだと操作対象のフィールドが存在しない場合そのレコード自体がロストしてしまったので、一旦add_columnsをかませることでmsgsuffix無しのレコードのロストを回避しています。
マルチラインの2行目以降
2行目以降の左側部分を削除します。これもembulk-filter-evalフィルタープラグインでgsub使って余計な部分を削除します。
...
filters:
...
- type: eval
eval_columns:
- loglevel: value.gsub(/[SEWI]/, "S"=>"critical", "E"=>"error", "W"=>"warning", "I"=>"info")
- msgtext: value.gsub(/\n [DELS][CRI ][ ]{35}.{8} .{8} /, "\n")
...
上のようにeval_columsにmsgtextの処理を追加します。
Elasticsearchへの出力部分
こんな感じ。
...
out:
type: elasticsearch
index: syslog-embulk
index_type: embulk
nodes:
- {host: localhost, port: 9200}
ここではindex名は固定にしていますが、適宜変数化するなりして下さい。
Embulk構成ファイルまとめ
最終的はfluentdの構成ファイルはこんな感じになります。
in:
type: file
path_prefix: syslog_test01.txt
parser:
charset: UTF-8
newline: LF
type: grok
grok_pattern_files:
- pattern/my-patterns
first_line_pattern: '^ [NWMOX]'
grok_pattern: '%{PATTERN01}'
timestamp_parser: SimpleDateFormat
columns:
- {name: recordtype, type: string}
- {name: destcode, type: string}
- {name: sysname, type: string}
- {name: datetime, format: 'yyD HH:mm:ss.SS', type: timestamp, timezone: 'Asia/Tokyo'}
- {name: ident, type: string}
- {name: msgflag, type: string}
- {name: alertflag, type: string}
- {name: msgid, type: string}
- {name: msgsuffix, type: string}
- {name: msgtext, type: string}
filters:
- type: column
add_columns:
- {name: loglevel, src: msgsuffix, default: "unknown", type: string}
- type: eval
eval_columns:
- loglevel: value.gsub(/[SEWI]/, "S"=>"critical", "E"=>"error", "W"=>"warning", "I"=>"info")
- msgtext: value.gsub(/\n [DELS][CRI ][ ]{35}.{8} .{8} /, "\n")
out:
type: elasticsearch
index: syslog-embulk
index_type: embulk
nodes:
- {host: localhost, port: 9200}
Elasticsearch index template
以下のようにindex templateを作成しておきます。
PUT _template/syslog-embulk
{
"index_patterns": ["syslog-embulk*"],
"order" : 0,
"settings": {
"number_of_shards": 1,
"number_of_replicas" : 0
}
}
ここで使用している環境はテスト用なのでElasticsearchは1ノード構成にしています。従ってレプリカシャードは作れないのでレプリカ数は0にしています。
データ投入
以下のようにEmbulkを実行してデータを取り込みます。
[root@test08 ~/embulk/Syslog]# date; embulk run config.yml; date
2020年 8月 25日 火曜日 16:01:39 JST
2020-08-25 16:01:39.962 +0900: Embulk v0.9.23
2020-08-25 16:01:41.043 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2020-08-25 16:01:43.605 +0900 [INFO] (main): Gem's home and path are set by default: "/root/.embulk/lib/gems"
2020-08-25 16:01:44.589 +0900 [INFO] (main): Started Embulk v0.9.23
2020-08-25 16:01:44.722 +0900 [INFO] (0001:transaction): Loaded plugin embulk-output-elasticsearch (0.4.7)
2020-08-25 16:01:44.758 +0900 [INFO] (0001:transaction): Loaded plugin embulk-filter-column (0.7.1)
2020-08-25 16:01:44.784 +0900 [INFO] (0001:transaction): Loaded plugin embulk-filter-eval (0.1.0)
2020-08-25 16:01:44.865 +0900 [INFO] (0001:transaction): Loaded plugin embulk-parser-grok (0.1.7)
2020-08-25 16:01:44.889 +0900 [INFO] (0001:transaction): Listing local files at directory '.' filtering filename by prefix 'syslog_test01.txt'
2020-08-25 16:01:44.891 +0900 [INFO] (0001:transaction): "follow_symlinks" is set false. Note that symbolic links to directories are skipped.
2020-08-25 16:01:44.896 +0900 [INFO] (0001:transaction): Loading files [syslog_test01.txt]
2020-08-25 16:01:45.000 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=12 / output tasks 6 = input tasks 1 * 6
2020-08-25 16:01:45.023 +0900 [INFO] (0001:transaction): Logging initialized @5584ms
2020-08-25 16:01:45.304 +0900 [INFO] (0001:transaction): Connecting to Elasticsearch version:7.6.2
2020-08-25 16:01:45.304 +0900 [INFO] (0001:transaction): Executing plugin with 'insert' mode.
2020-08-25 16:01:45.305 +0900 [INFO] (0001:transaction): Inserting data into index[syslog-embulk]
2020-08-25 16:01:45.315 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0}
2020-08-25 16:01:55.973 +0900 [INFO] (0023:task-0000): Inserted 784 records
2020-08-25 16:01:56.218 +0900 [INFO] (0023:task-0000): Inserted 716 records
2020-08-25 16:01:56.340 +0900 [INFO] (0023:task-0000): Inserted 566 records
2020-08-25 16:01:56.438 +0900 [INFO] (0023:task-0000): Inserted 600 records
2020-08-25 16:01:56.535 +0900 [INFO] (0023:task-0000): Inserted 813 records
2020-08-25 16:01:56.637 +0900 [INFO] (0023:task-0000): Inserted 675 records
2020-08-25 16:01:56.658 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0}
2020-08-25 16:01:56.658 +0900 [INFO] (0001:transaction): Insert completed. 40154 records
2020-08-25 16:01:56.666 +0900 [INFO] (main): Committed.
2020-08-25 16:01:56.667 +0900 [INFO] (main): Next config diff: {"in":{"last_path":"syslog_test01.txt"},"out":{}}
2020年 8月 25日 火曜日 16:01:56 JS
あとはPart1, Part2の記事と同様にKibana, Grafanaで表示可能です。
追加テスト
コメントでembulk-filter-ruby_procを使う方が早いという情報を頂いたので試してみます。
embulk-filter-ruby_procのインストール
[root@test08 ~]# embulk gem install embulk-filter-ruby_proc
2020-08-31 09:08:58.309 +0900: Embulk v0.9.23
Gem plugin path is: /root/.embulk/lib/gems
Fetching: embulk-filter-ruby_proc-0.8.1.gem (100%)
Successfully installed embulk-filter-ruby_proc-0.8.1
1 gem installed
Embulk構成ファイル
上で作成したconfig.ymlのembulk-filter-evalを使用している部分を、embulk-filter-ruby_procに書き換えます。
in:
type: file
path_prefix: syslog_test01.txt
parser:
charset: UTF-8
newline: LF
type: grok
grok_pattern_files:
- pattern/my-patterns
first_line_pattern: '^ [NWMOX]'
grok_pattern: '%{PATTERN01}'
timestamp_parser: SimpleDateFormat
columns:
- {name: recordtype, type: string}
- {name: destcode, type: string}
- {name: sysname, type: string}
- {name: datetime, format: 'yyD HH:mm:ss.SS', type: timestamp, timezone: 'Asia/Tokyo'}
- {name: ident, type: string}
- {name: msgflag, type: string}
- {name: alertflag, type: string}
- {name: msgid, type: string}
- {name: msgsuffix, type: string}
- {name: msgtext, type: string}
filters:
- type: column
add_columns:
- {name: loglevel, src: msgsuffix, default: "unknown", type: string}
- type: ruby_proc
columns:
- name: loglevel
proc: |
->(loglevel) do
loglevel.gsub(/[SEWI]/, "S"=>"critical", "E"=>"error", "W"=>"warning", "I"=>"info")
end
- name: msgtext
proc: |
->(msgtext) do
msgtext.gsub(/\n [DELS][CRI ][ ]{35}.{8} .{8} /, "\n")
end
out:
type: elasticsearch
index: syslog-embulk
index_type: embulk
nodes:
- {host: localhost, port: 9200}
データ投入
以下のようにEmbulkを実行してデータを取り込みます。
[root@test08 ~/embulk/Syslog]# date; embulk run config2.yml; date
2020年 8月 31日 月曜日 18:48:11 JST
2020-08-31 18:48:11.710 +0900: Embulk v0.9.23
2020-08-31 18:48:12.930 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2020-08-31 18:48:15.841 +0900 [INFO] (main): Gem's home and path are set by default: "/root/.embulk/lib/gems"
2020-08-31 18:48:17.351 +0900 [INFO] (main): Started Embulk v0.9.23
2020-08-31 18:48:17.498 +0900 [INFO] (0001:transaction): Loaded plugin embulk-output-elasticsearch (0.4.7)
2020-08-31 18:48:17.548 +0900 [INFO] (0001:transaction): Loaded plugin embulk-filter-column (0.7.1)
2020-08-31 18:48:17.585 +0900 [INFO] (0001:transaction): Loaded plugin embulk-filter-ruby_proc (0.8.1)
2020-08-31 18:48:17.634 +0900 [INFO] (0001:transaction): Loaded plugin embulk-parser-grok (0.1.7)
2020-08-31 18:48:17.713 +0900 [INFO] (0001:transaction): Listing local files at directory '.' filtering filename by prefix 'syslog_test01.txt'
2020-08-31 18:48:17.715 +0900 [INFO] (0001:transaction): "follow_symlinks" is set false. Note that symbolic links to directories are skipped.
2020-08-31 18:48:17.722 +0900 [INFO] (0001:transaction): Loading files [syslog_test01.txt]
2020-08-31 18:48:17.862 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=12 / output tasks 6 = input tasks 1 * 6
2020-08-31 18:48:17.893 +0900 [INFO] (0001:transaction): Logging initialized @6706ms
2020-08-31 18:48:18.179 +0900 [INFO] (0001:transaction): Connecting to Elasticsearch version:7.6.2
2020-08-31 18:48:18.179 +0900 [INFO] (0001:transaction): Executing plugin with 'insert' mode.
2020-08-31 18:48:18.180 +0900 [INFO] (0001:transaction): Inserting data into index[syslog-embulk]
2020-08-31 18:48:18.193 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0}
2020-08-31 18:48:22.373 +0900 [ERROR] (0023:task-0000): LEAK: ByteBuf.release() was not called before it's garbage-collected. Enable advanced leak reporting to find out where the leak occurred. To enable advanced leak reporting, specify the JVM option '-Dio.netty.leakDetection.level=advanced' or call ResourceLeakDetector.setLevel() See http://netty.io/wiki/reference-counted-objects.html for more information.
2020-08-31 18:48:27.519 +0900 [INFO] (0023:task-0000): Inserted 784 records
2020-08-31 18:48:27.584 +0900 [INFO] (0023:task-0000): Inserted 716 records
2020-08-31 18:48:27.651 +0900 [INFO] (0023:task-0000): Inserted 566 records
2020-08-31 18:48:27.708 +0900 [INFO] (0023:task-0000): Inserted 600 records
2020-08-31 18:48:27.779 +0900 [INFO] (0023:task-0000): Inserted 813 records
2020-08-31 18:48:27.843 +0900 [INFO] (0023:task-0000): Inserted 675 records
2020-08-31 18:48:27.844 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0}
2020-08-31 18:48:27.845 +0900 [INFO] (0001:transaction): Insert completed. 40154 records
2020-08-31 18:48:27.854 +0900 [INFO] (main): Committed.
2020-08-31 18:48:27.854 +0900 [INFO] (main): Next config diff: {"in":{"last_path":"syslog_test01.txt"},"out":{}}
2020年 8月 31日 月曜日 18:48:27 JST
途中なんだかメモリーリークっぽいエラー出ましたが、メッセージは想定件数入ったのでロストはしていないようです。まぁバッチ実行なのでメモリーリークのメッセージは無視します。
fluentd, Embulk パフォーマンス比較
Part2で実施したfluentdによる取り込みと、今回のEmbulkによる取り込みを比較してみました。
環境
Windows10上のVirtualBox仮想マシンとしてLinux立てています。
Host:
- ThinkPad T480
- Intel Core i5-8350U 1.70GHz / 32GB RAM
- Windows10
Guest: - VirtualBox仮想マシン vCPU:6, 16GB RAM
- RHEL 7.5
取り込み対象のSYSLOG
ファイルサイズ: 8,235,191bytes (≒7.9MB)
レコード数: 40,156レコード
Embulk構成
上の通り
fluentd構成
fluentd構成ファイル
<system>
log_level debug
</system>
<source>
@type tail
tag zos_syslog
path /etc/td-agent/Syslog/zos_syslog*.txt
pos_file /etc/td-agent/Syslog/zos_syslog.pos
refresh_interval 5s
read_from_head true
multiline_flush_interval 1m
<parse>
@type multiline
format_firstline /^ [NWMOX]/
format1 /^ (?<recordtype>[NWMOX][CRI ])(?<destcode>.{7}) (?<sysname>.{8}) (?<date_time>\d{2}\d{3} \d{2}:\d{2}:\d{2}\.\d{2}) (?<ident>.{8}) (?<msgflag>.{8}) (?<alertflag>.{1})[+]?((?<msgtext>(?<msgid>([A-Z]{3,7}[0-9]{3,5}[ADEISTW]?|\$HASP[0-9]{3,4})) (.*))|(?<msgtext>.*))/
</parse>
</source>
<filter zos_syslog>
@type record_transformer
enable_ruby
<record>
sysname ${record["sysname"].strip}
date_time ${require "date"; DateTime.strptime(record["date_time"] + "+0900", "%y%j %H:%M:%S.%L%z").iso8601(2).to_s}
msgtext ${record["msgtext"].gsub(/\n [DELS][CRI ][ ]{35}.{8} .{8} /, "\n")}
</record>
</filter>
<match zos_syslog>
@type rewrite_tag_filter
<rule>
key msgid
pattern /S$/
tag ${tag}.critical
</rule>
<rule>
key msgid
pattern /E$/
tag ${tag}.error
</rule>
<rule>
key msgid
pattern /W$/
tag ${tag}.warning
</rule>
<rule>
key msgid
pattern /I$/
tag ${tag}.info
</rule>
<rule>
key recordtype
pattern /.+/
tag ${tag}.unknown
</rule>
</match>
<filter zos_syslog.**>
@type record_transformer
enable_ruby
<record>
loglevel ${tag_parts[1]}
</record>
</filter>
<match zos_syslog.**>
@type elasticsearch_dynamic
host "localhost"
port 9200
logstash_format true
logstash_prefix "syslog-${record[\'sysname\']}"
logstash_dateformat "%Y%m%d"
time_key "date_time"
utc_index false
<buffer>
flush_interval 1
</buffer>
</match>
結果
ファイルをElasticsearchに取り込むのにかかった時間
Embulk(embulk-filter-eval): 約17sec
Embulk(embulk-filter-ruby_proc): 約16sec
fluentd: 約26sec
Embulkのrubyを組み込んでいる部分について、使用するfilterプラグインの比較としては今回くらいのデータ量だとあまり差は出ませんでした。コメントで紹介いただいた以下記事によると、もっと大量のデータだと顕著にパフォーマンスの差が出てくるようです。
参考: 【Embulk】embulk-filter-evalとembulk-filter-ruby_proc速度比較
データの加工の仕方とか若干差異があったりするので厳密な比較ではないですが、Embulkとfluentdではfluentdの方が1.5倍くらい時間がかかってる感じです。