はじめに
z/OSの情報をOSSに取り込んでみるという話の第2弾です。
今回はSYSLOGをElasticsearchに取り込んでみます。
前置きとしては、以下の関連記事の(1)もご参照下さい。
(構成もほぼ重複していますので、細かい所は適宜(1)の記事を参考にして下さい。)
関連記事
z/OSの新しい管理方法を探る - (1)DAパネル情報のElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (2)-1 SYSLOGのElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (2)-2 SYSLOGのElasticsearchへの取り込み part2
z/OSの新しい管理方法を探る - (2)-3 SYSLOGのElasticsearchへの取り込み part3
z/OSの新しい管理方法を探る - (3)CICSヒストリカルデータのElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (4) RMF MonitorIIIレポートのElasticsearchへの取り込み
やりたいこと
普通PCOMとかでSYSLOG見るとこんな感じです。
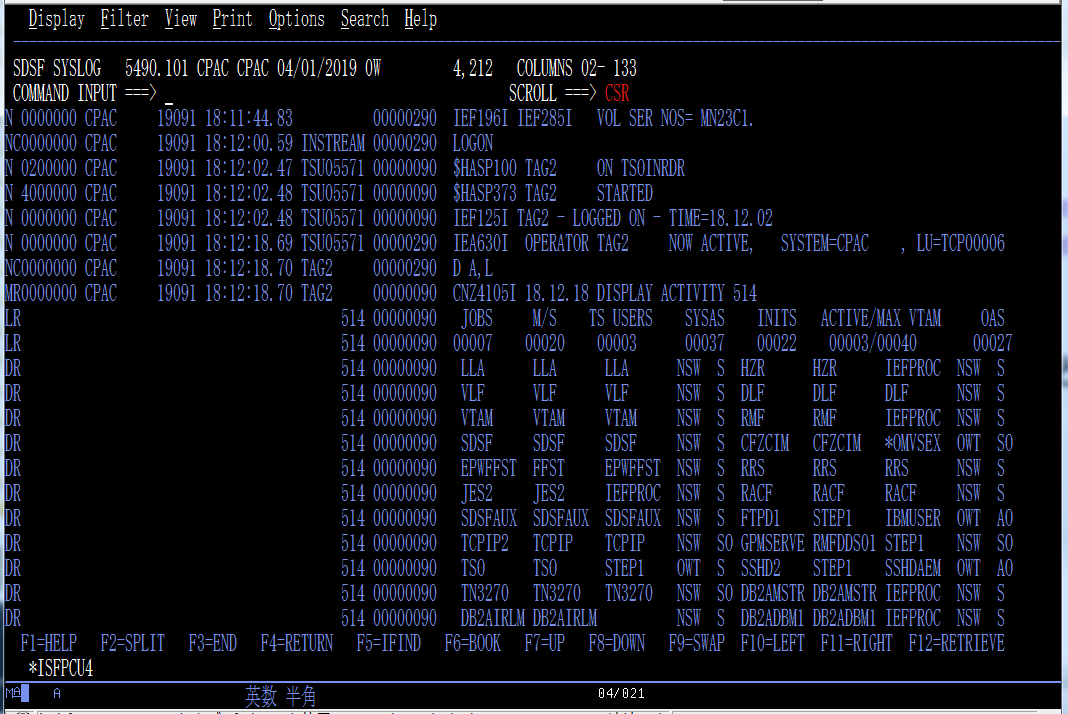
このSYSLOG情報をElasticsearchに取り込んで、フィルターかけて必要なメッセージだけ抽出するとか、どういうメッセージがどのくらい出ているかを見たりするのを、簡単に/スマートにやりたい!
実装
全体像
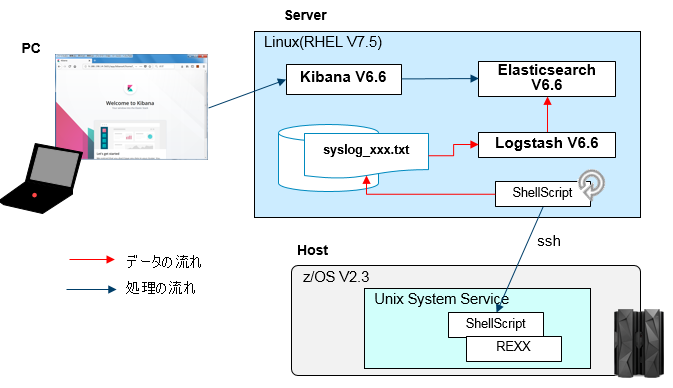
全体の構造は(1)のDAの取り込みのケースと同様です。
前提
前提も(1)と同様です。ELKのサーバー、SSH接続、REXXからSDSFアクセスについてそれぞれ準備しておきます。
USS / 情報取得部分
例によってSYSLOGを取得するREXXスクリプトをUSS上に作成します。REXXのSDSFインターフェースのステキな所は、日付/時刻で範囲を指定して、その範囲のSYSLOGを持ってこられることです!
参考: ISFLOG を使用したシステム・ログのブラウズ
(z/OSMFのREST APIでもSYSLOG取れるようですが、残念ながら日付/時刻での範囲指定ができなさそう...)
取得するSYSLOGの開始/終了の日時、および、取得した情報を書き出す一時ファイル名を引数に取るようにしています。
isflinelim=100000で、取得する行数の上限を指定しています。定期的に差分を抽出していくことを想定しているので、その特定の間隔で出力される想定の行数を見込んでおく必要があります。
(※大量のSYSLOGを一度に取得するようなことはここでは想定していません)
/* REXX */
/*--------------------------------------------------------*/
/* Arg1: start date (yyyy/mm/dd) */
/* Arg2: start time (hh:mm:ss.nn) */
/* Arg3: stop date (yyyy/mm/dd) */
/* Arg4: stop time (hh:mm:ss.nn) */
/* Arg5: output file (xxx.txt) */
/*--------------------------------------------------------*/
parse arg start_date start_time stop_date stop_time output_file
say start_date
say start_time
say stop_date
say stop_time
/* getSyslog.rex mm/dd/yy hh:mm:ss */
rc=isfcalls('ON')
if rc <> 0 then do
err_msg = " ** ISFCALLS ERROR : " rc
say err_msg
exit 4
end
isfdate="yyyymmdd /" /* Date format for special variables */
isflogstartdate=start_date
isflogstarttime=start_time
isflogstopdate=stop_date
isflogstoptime=stop_time
isflinelim=100000
Address SDSF "ISFLOG READ TYPE(SYSLOG)"
do ix=1 to isfmsg2.0
say isfmsg2.ix
end
/*
do ix=1 to isfline.0
say isfline.ix
end
*/
rc = charout(output_file,,)
do ix=1 to isfline.0 /* Process the returned variables */
/* record = isfline.ix || ESC_R || ESC_N */
record = isfline.ix || ESC_N
rc = charout(output_file, record,)
end
call stream output_file, 'C', 'CLOSE'
rc=isfcalls('OFF')
exit 0
これを呼び出すシェル・スクリプトを用意します。
仕様としては、前回取得したSYSLOGの終わりの時刻を別ファイル(previousDateTime.txt)に記録しておいて、それ以降から現在時刻までのSYSLOGを取得する、ということを実行するようにします。こうすることで、任意の時間間隔でこのスクリプトを動かせば、まだ取得していない最新のものを随時取得できるようになります。
previousDateTime.txtが存在しない場合は当日の00:00:00から取得するようにしています。
rexxのパスは適宜実環境に応じて修正して下さい。
#!/bin/sh
export TZ=JST-9
### REXX program to get SYSLOG
rexxFile=/u/tag/REXX/syslog.rex
#outputFile=$1
outputFile=syslog.txt
tempFile=previousDateTime.txt
toDate=$(date '+%Y/%m/%d')
toTime=$(date '+%T')
if [[ -e ${outputFile} ]]
then
rm ${outputFile}
fi
if [[ -e ${tempFile} ]]
then
read fromDate fromTime < ${tempFile}
else
fromDate=${toDate}
fromTime=00:00:00
fi
#echo From: ${fromDate} ${fromTime}.01
#echo To: ${toDate} ${toTime}.00
### Get Syslog
${rexxFile} ${fromDate} ${fromTime}.01 ${toDate} ${toTime}.00 ${outputFile} > /dev/null 2>&1
rc=$?
### Error Handling
if [ ${rc} -gt 0 ]; then
# do nothing
# echo Error!: ${rc}
rm ${outputFile}
exit 1
fi
### Output
echo ${toDate} ${toTime} > ${tempFile}
cat ${outputFile}
rm ${outputFile}
exit 0
このSYSLOG取得のスクリプトも、一旦USS上に一時ファイルを作成してそれを標準出力に吐き出し、最後に一時ファイルを削除するようにしています。
そのため、スクリプト実行のカレントディレクトリに、一時ファイルを保持するだけのサイズの余裕が必要になります。
これをUSS上で単発で実行すると、こんな感じになります。
$ ./getSyslog.sh
N 0000000 CPAC 19091 19:01:30.08 00000290 IEF196I IEF237I DA31 ALLOCATED TO SYS00095
N 0000000 CPAC 19091 19:01:30.08 00000290 IEF196I IEF285I ISF.SISFLOAD KEPT
N 0000000 CPAC 19091 19:01:30.08 00000290 IEF196I IEF285I VOL SER NOS= MN23T2.
N 0200000 CPAC 19091 19:06:08.02 JOB05594 00000090 $HASP100 OCOPY ON INTRDR FROM STC05541
S TADA3
N 0000000 CPAC 19091 19:06:08.03 JOB05594 00000290 IRR010I USERID TADA IS ASSIGNED TO THIS JOB.
N 0020000 CPAC 19091 19:06:08.05 JOB05594 00000090 ICH70001I TADA LAST ACCESS AT 19:06:01 ON MONDAY, APRIL 1, 2019
N 4000000 CPAC 19091 19:06:08.05 JOB05594 00000090 $HASP373 OCOPY STARTED - INIT 1 - CLASS A - SYS CPAC
N 0000000 CPAC 19091 19:06:08.05 JOB05594 00000090 IEF403I OCOPY - STARTED - TIME=19.06.08
N 0004000 CPAC 19091 19:06:08.07 JOB05594 00000290 - -----TIMINGS (MINS.)------
S -----PAGING COUNTS----
N 0004000 CPAC 19091 19:06:08.07 JOB05594 00000290 -STEPNAME PROCSTEP RC EXCP CONN TCB SRB CLOCK
S SERV WORKLOAD PAGE SWAP VIO SWAPS
N 0004000 CPAC 19091 19:06:08.07 JOB05594 00000290 -COPY 00 82 6 .00 .00 .0
S 3328 BATCH 0 0 0 0
N 0000000 CPAC 19091 19:06:08.07 JOB05594 00000090 IEF404I OCOPY - ENDED - TIME=19.06.08
N 0004000 CPAC 19091 19:06:08.07 JOB05594 00000290 -OCOPY ENDED. NAME- TOTAL TCB CPU TIME= .00
S TOTAL ELAPSED TIME= .0 SUBSYS=JES2
N 4000000 CPAC 19091 19:06:08.07 JOB05594 00000090 $HASP395 OCOPY ENDED - RC=0000
N C000000 CPAC 19091 19:06:08.08 00000090 $HASP309 INIT 1 INACTIVE ******** C=A
NC0000000 CPAC 19091 19:06:08.08 INTERNAL 00000290 SE '19.06.08 JOB05594 $HASP165 OCOPY ENDED AT N1 MAXCC=0000',LOGON,
SC USER=(TADA)
N 0200000 CPAC 19091 19:06:10.12 JOB05595 00000090 $HASP100 SYSREXX ON INTRDR FROM STC05541
S TADA4
N 0000000 CPAC 19091 19:06:10.12 JOB05595 00000290 IRR010I USERID TADA IS ASSIGNED TO THIS JOB.
N 0020000 CPAC 19091 19:06:10.14 JOB05595 00000090 ICH70001I TADA LAST ACCESS AT 19:06:08 ON MONDAY, APRIL 1, 2019
N 4000000 CPAC 19091 19:06:10.14 JOB05595 00000090 $HASP373 SYSREXX STARTED - INIT 1 - CLASS A - SYS CPAC
N 0000000 CPAC 19091 19:06:10.14 JOB05595 00000090 IEF403I SYSREXX - STARTED - TIME=19.06.10
previousDateTime.txtに指定された日時からスクリプト実行時刻までのSYSLOGが返されます。
(previousDateTime.txtが無ければ当日の00:00:00からのSYSLOGが返される)
注意!
SYSLOGを取得するのに、REXXからAddress SDSF "ISFLOG READ TYPE(SYSLOG)"というコマンドを使っており、この時、ISFLOGSTARTTIME, ISFLOGSTARTDATE, ISFLOGSTOPTIME, ISFLOGSTOPDAT という変数で取得する時刻を指定しています。ところが、マニュアルをよくよく見てみると、以下のような記述がありました。
Browsing the system log with ISFLOG
ISFLOGSTARTTIME, ISFLOGSTARTDATE, ISFLOGSTOPTIME and ISFLOGSTOPDATE define the date and time range for the records. Use them to ensure that your date and time range is reasonable, so that an excessive number of variables is not created.
When these special variables are used, SDSF positions the SYSLOG as near as possible to the requested record. However, due to the precision used for time stamps and the time the record is actually written to SYSLOG, it is possible that this may be several lines away from the desired record.
記録されているタイムスタンプと実際に書かれるタイミングが若干ずれる可能性があるらしい。まぁそれはよいとしても、上の変数で指定した時刻と、実際返されるSYSLOGデータにズレがあるっぽい!実際、時刻を一定時間ずらして取得する今回のスクリプトでは、一部メッセージがロストしてしまうケースがありました。うむむ、イケてない。厳密にSYSLOG取得しなければいけないケースだとちょっと向かないです...。うぐぐ。
SYSLOGは一定間隔で別データセットに退避させる運用をとる場合も多いので、リアルタイム性は損なわれますが別データセットに取得されたSYSLOGをFTPやNFSでファイル転送を行い、Logstashではそのテキストファイルを読み取るような仕組みにするのもよいでしょう。
Linux-USS間のssh接続
これも(1)のDAケースと一緒。
公開鍵認証の設定をして、パスワード無しでスクリプト実行できるようにしておく!
Linux / ssh経由で情報を取得するシェル・スクリプト
USS上に用意したスクリプトをssh経由で呼び出すためのシェル・スクリプトをLinux上に用意します。
これも(1)DA取得と同様、cronなどで定期的に実行することを想定しています。
今回は単純に、取得した情報をファイルにappendしていくだけです。
#!/bin/sh
outputDir=/var/log/zos_syslog/
yyyymmdd=$(date '+%Y%m%d')
outputFile=${outputDir}syslog_zosmf_${yyyymmdd}.txt
ssh TAG@hosname "REXX/getSyslog.sh" >> ${outputFile}
LogstashによるElasticsearchへのデータ取り込み
SYSLOGフォーマットの解釈
さて、いよいよLinux上に取得されたSYSLOG情報を取り込んでいきますが、まだ以下のような"メインフレームの特異性"が残されています。
まず、SYSLOGは1行が1メッセージではなく、複数行で1メッセージを表すものもあります。しかもレコードベースのフォーマットなので、カンマ区切りとかになっていません。イケてないですねぇ。
これらの対応のため、Logstashにて、行頭のレコードタイプを元に複数行にまたがる場合はそれらを1レコードとしてマージし、さらに、正規表現を使って各フィールドを認識させる、ということを行います。前者はMultiline codec pluginを、後者は Grok filter pluginを利用することにします。
参考:Multiline codec plugin, Grok filter plugin
複数行対応
まず、Mulitline対応の部分。
input{
file{
path => ["/var/log/zos_syslog/syslog_zosmf*.txt"]
start_position => "beginning"
sincedb_path => "/var/log/zos_syslog/temp_zosmf.sincedb"
codec => multiline {
pattern => "^[NWMOX]"
auto_flush_interval => 3
negate => "true"
what => "previous"
}
}
}
codec => multiline{...} という所で複数行を1レコードにまとめる処理を行っています。
行頭の文字がN,W,M,O,X(pattern=>"^[NWMOX]")のいずれでもなかった場合(negate=>"true")、前の行の継続とみなす(what=>"previous")、という設定を行っています。これで、複数行あるレコードを1レコードと判断していることになります。
正規表現によるフィールド分割
次に、レコードベースのフォーマット(区切り文字ではなく桁位置によるフィールド定義)になっている所を、正規表現を用いて各フィールドを認識させるようにします。
Logstash自体が正規表現のパターンを各種提供してくれていますが、独自にパターンを定義することもできます。
参考: logstash-plugins/logstash-patterns-core
(既存のパターン)
これを参考に、SYSLOGを解釈するパターンを正規表現で記述します。
RECTYPE [NWMOX][CRI ]
DESTCODE [0-9a-fA-F]{7,7}
SYSNAME .{8,8}
DATETIME [0-9]{5,5} [0-9]{2,2}:[0-9]{2,2}:[0-9]{2,2}.[0-9]{2,2}
IDENT .{8,8}
MSGFLAG .{8,8}
ALERTFLAG .{1,1}
MSGID_MVS [A-Z]{3,7}[0-9]{3,5}[ADEISTW]?
MSGID_JES2 \$HASP[0-9]{3,4}
MSGID (%{MSGID_MVS}|%{MSGID_JES2})
PATTERN01 %{RECTYPE:rectype}%{DESTCODE:destcode} %{SYSNAME:sysname} %{DATETIME:date_time} %{IDENT:ident} %{MSGFLAG:msgflag} %{ALERTFLAG:alertflag}%{GREEDYDATA:message}
PATTERN02 [+]?(%{MSGID:msg_id} %{GREEDYDATA:msg_text}|%{GREEDYDATA:msg_text})
参考: REGEXPER (正規表現を視覚的に表現してくれるサイト)
まず、PATTERN01で解釈している部分は、SYSLOGで見ると、以下の赤枠のイメージです。
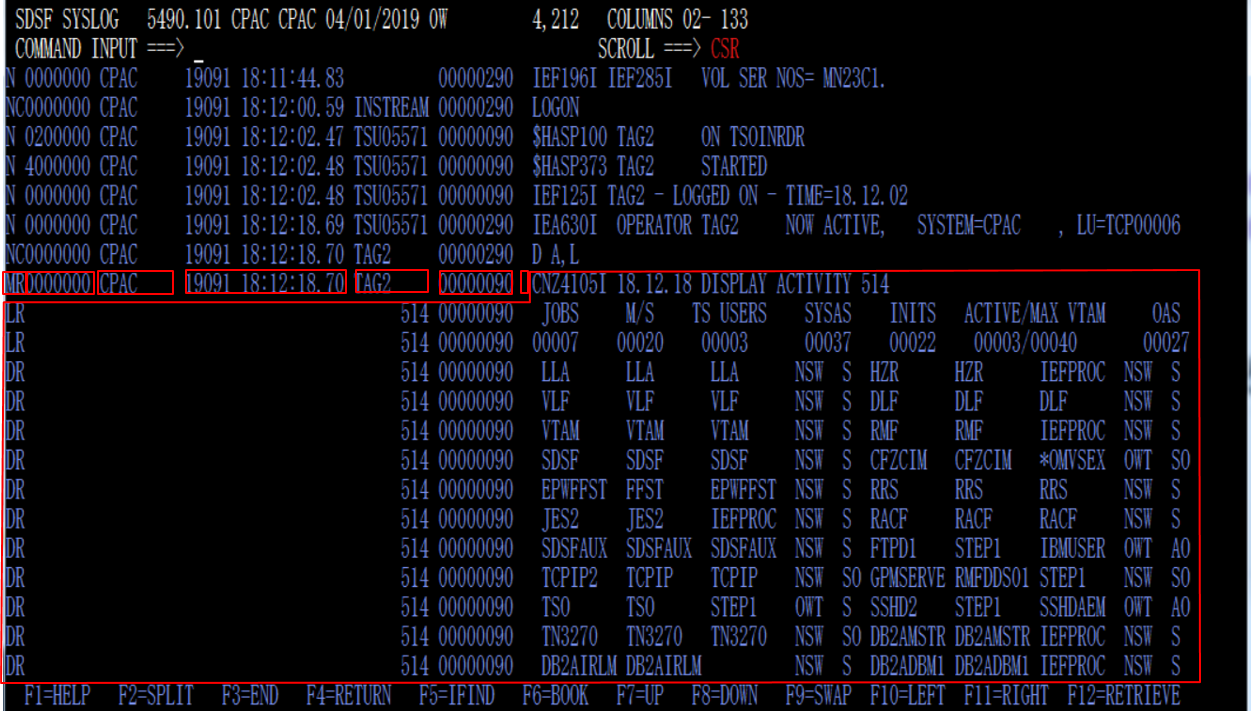
PATTERN01の最後のフィールドをPATTERN02で、メッセージIDとそれ以外というようにフィールド分割しています(msg_idは、マッチするものが無い場合はフィールド自体無しと判断)。
PATTERN02で解釈している部分はこちらのイメージです。
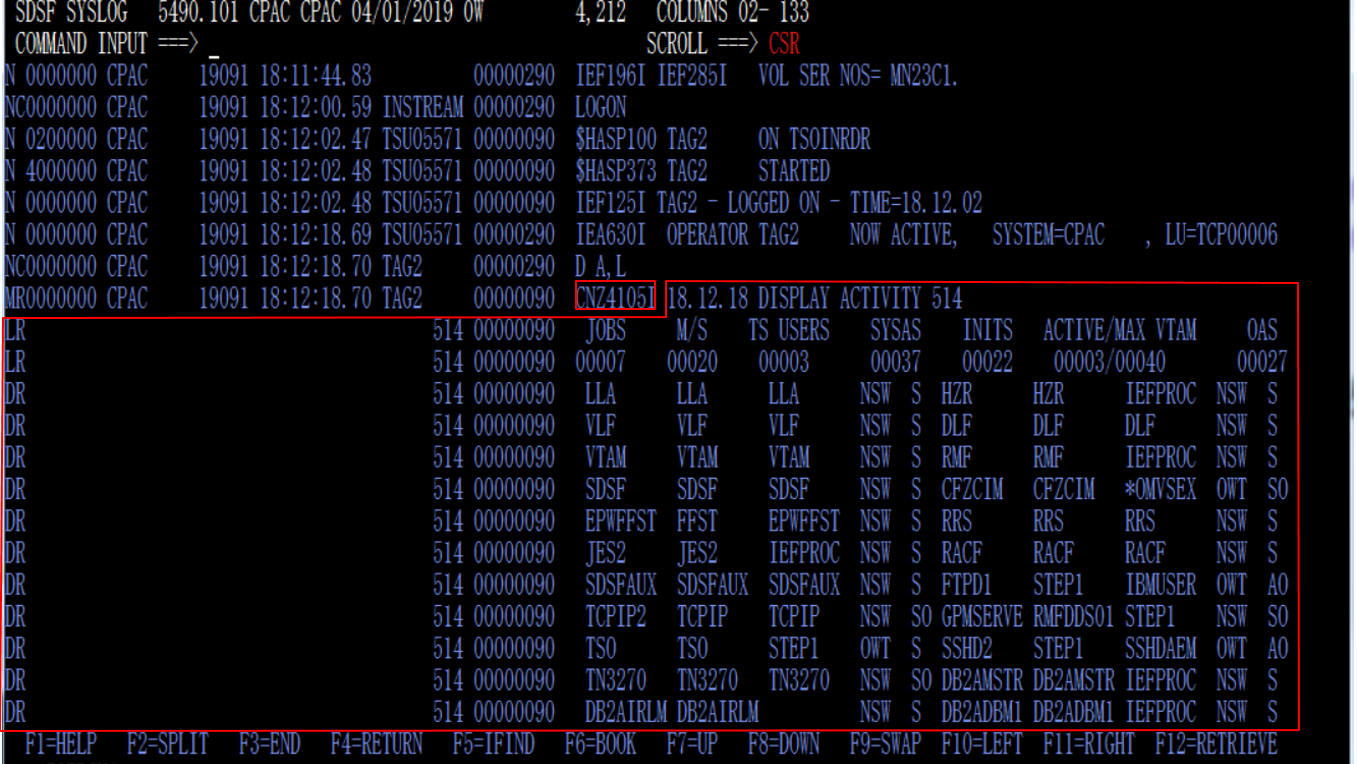
参考: メッセージフォーマット関連
メッセージ本文のフォーマット
JES2 メッセージの形式
PATTERN02ではMVS関連、JES2関連のメッセージIDフォーマットを正規表現で判別していますが、割と汎用的に記述しているので、類似のフォーマットであればミドルウェアのメッセージIDなどもこれで拾えます。より厳密に判別したり、メッセージごとに認識するフィールド名を分けたいなどの要件があれば、この辺色々とカスタマイズする必要があるでしょう。
このようなパターン定義ファイルを作成しておき、それを使ってgrokフィルターでフィールドを解釈させます。
filter{
grok{
patterns_dir => ["/etc/logstash/patterns.d"]
match => ["message", "%{PATTERN01}"]
overwrite => "message"
}
grok{
patterns_dir => ["/etc/logstash/patterns.d"]
match => ["message", "%{PATTERN02}"]
}
...
}
patterns_dirでは、先に定義したパターンファイルを配置しているディレクトリを指定します。
2段階でパターン判別しているので、最後のmessage部分はoverwite指定をしています。
2行目以降の左側部分の削除
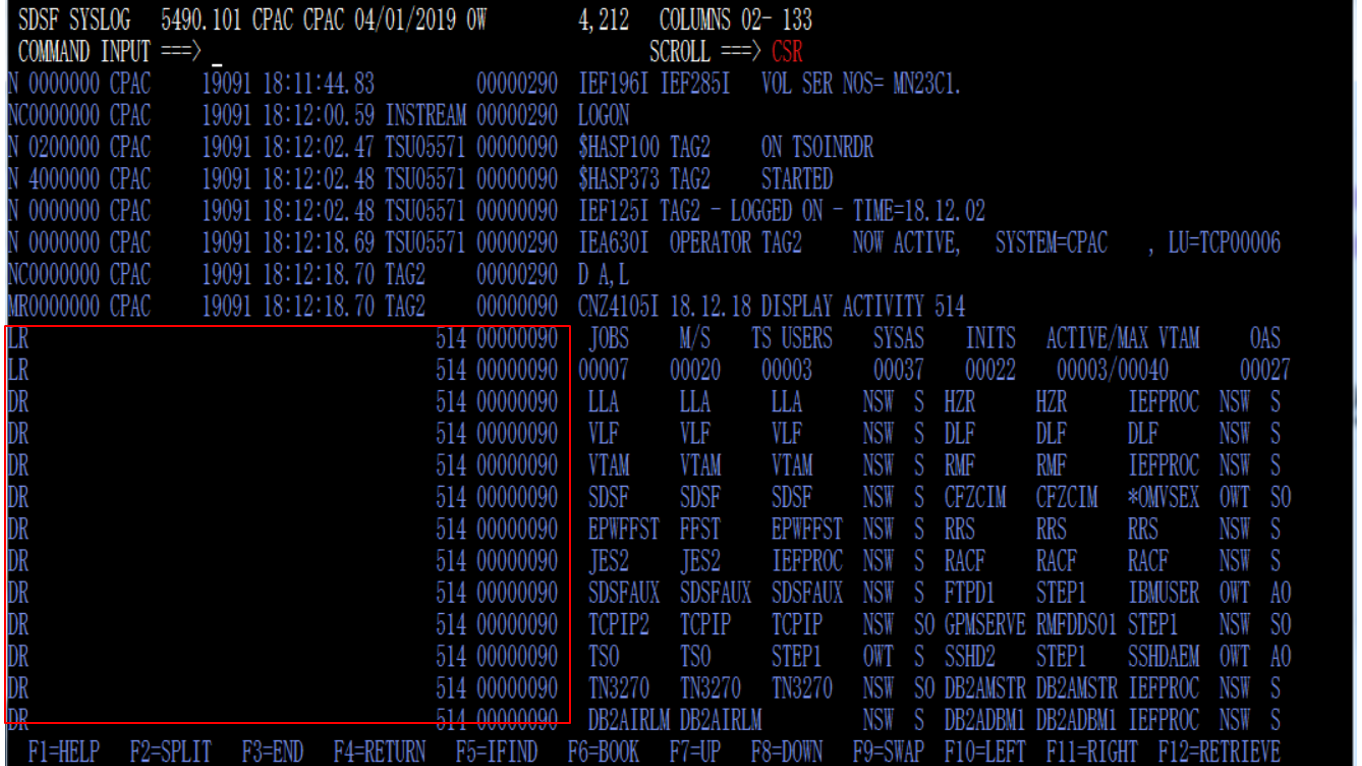
複数行ある場合、上の図に示す左側部分が邪魔なので、削除しちゃいます。
filter{
...
mutate {
gsub => [
"msg_text", "\n[DELS][CRI ][ ]{40,40}([0-9]{3,3} .{8,8}|[ ]{12,12}) ", "
"
]
}
...
}
改行に続いてLRとかDRのような行が来たときに、一定の長さの部分は排除して改行だけに置き換える、というのをやっています。
ここで注意は、置き換え元の文字の判定として改行コードは「\n」で表現できるのですが、何故か置き換え後の文字列として改行コードを「\n」で指定しても勝手にエスケープされてしまいます。仕方が無いので実際に改行入れたらうまくいきました。なので、gsub内の最後にダブルクォーテーションが行頭に来ていますが、その直前の改行は意味のある改行なので削除したらダメです!
まぁ置き換え元も置き換え先も両方改行コードはずしちゃってもうまくいくと思いますが、Tipsの意味も込めてそのまま残しておきます。
参考:
Define quote escaping semantics. #1645
Add newline with gsub
How to add newline with gsub in logstash
ジュリアンデート対応
はい、来ました、"メインフレームの特異性"。SYSLOGの日付表示はいまだにジュリアンデートをひきずっています。上の画面イメージの例だと"19091"と表示されている5桁の数字です。頭2桁が西暦の下2桁(2019年)を表し、後続の3桁が1月1日からカウントされていく日数を表します。すなわち、"19091"=2019年の91日目= 2019/04/01 となります。
こういう表示形式になっているので、メインフレームを扱う人にとってはジュリアンデート入りカレンダーが手放せず、"人手で" 日付変換を行わなければなりません。
参考: ジュリアンデートカレンダー壁紙 2019年版 ダウンロード
当初ジュリアンデートの判定のためにはrubyコードとかで対応しないといけないかなーと思ったのですが、特にそこまでする必要はなく、date filter pluginでさくっと判定できました。すばらしい。
参考: Date filter plugin - match
filter{
...
date{
match => ["date_time", "yyD HH:mm:ss.SS"]
target => "@timestamp"
remove_field => ["date_time", "message", "path", "@version", "host"]
}
...
}
matchの"yyD"という部分が、ジュリアンデートのフォーマット判定部分です。
logstash構成まとめ
まとめると、構成ファイルはこんな感じになります。
input{
file{
path => ["/var/log/zos_syslog/syslog_zosmf*.txt"]
start_position => "beginning"
sincedb_path => "/var/log/zos_syslog/temp_zosmf.sincedb"
codec => multiline {
pattern => "^[NWMOX]"
auto_flush_interval => 3
negate => "true"
what => "previous"
}
}
}
filter{
grok{
patterns_dir => ["/etc/logstash/patterns.d"]
match => ["message", "%{PATTERN01}"]
overwrite => "message"
}
grok{
patterns_dir => ["/etc/logstash/patterns.d"]
match => ["message", "%{PATTERN02}"]
}
date{
match => ["date_time", "yyD HH:mm:ss.SS"]
target => "@timestamp"
remove_field => ["date_time", "message", "path", "@version", "host"]
}
mutate {
gsub => [
"msg_text", "\n[DELS][CRI ][ ]{40,40}([0-9]{3,3} .{8,8}|[ ]{12,12}) ", "
"
]
}
}
output{
elasticsearch{
hosts => ["http://localhost:9200"]
index => "syslog-zosmf-%{+YYYY.MM.dd}"
}
}
これで、syslog-zosmf-yyyy.MM.dd というindexでElasticsearchに取り込まれます。
Kibanaで可視化
インデックス・パターン作成
Kibanaの Management - Intex Patterns から、syslog-zosmf-*という名前でインデックス・パターンを作成します。Time Filter field nameとしてtimestampを指定します。
Discoverメニューでの確認
Kibanaの基本的なメニューであるDiscoverのメニューでインデックス・パターン毎の情報が参照できるので、ここからSYSLOGデータが参照できるようになります。
こんな感じ。
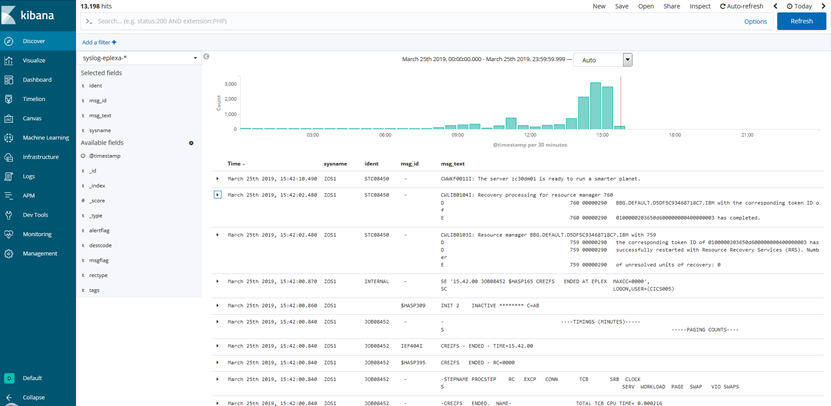
こんな感じでSYSLOG見られるようになりますよ、というのを少し細かく見ていきます。
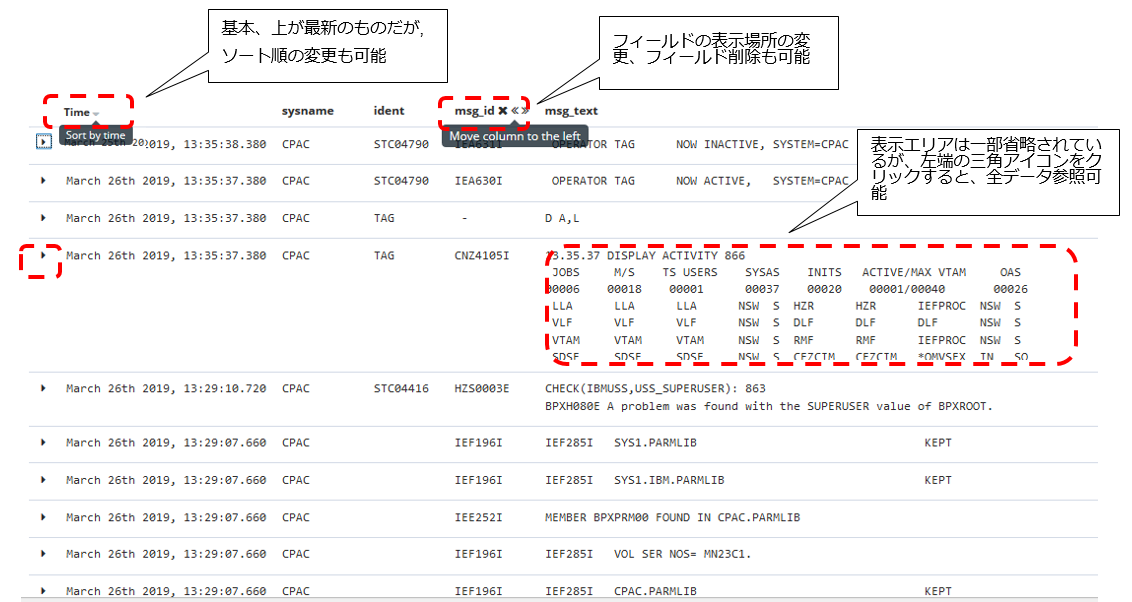
Discover画面のレイアウト
全体のレイアウトは以下のようになっています。
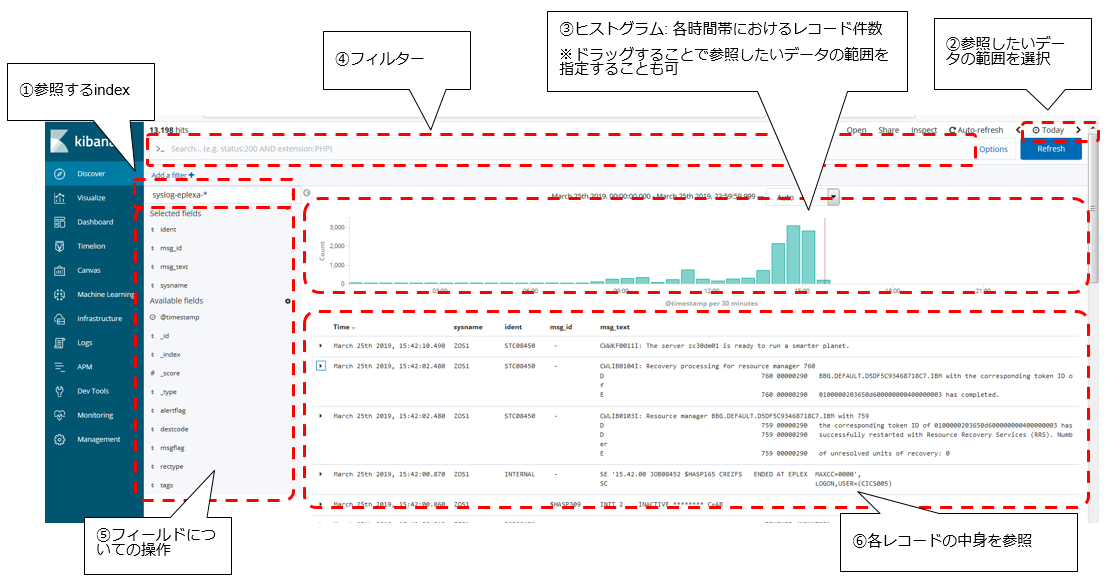
それぞれ補足します。
① Index指定
参照したいインデックス・パターンを選択します。インデックスはデータを取り込んでいる単位なのでRDBのテーブルに似ている所がありますが、もう少し柔軟に操作できます。例えば、今回syslog-zosmf-yyyy.mm.ddという名前のインデックスでデータを取り込んでいますが、zosmfというのは対象のz/OS環境名を意味しています。別の環境の情報も同様にsyslog-xxx-yyyy.mm.ddのように取り込んでいる場合、syslog-*というインデックスパターンを作れば、全環境のsyslogをまとめて見られたりします。
② 日時範囲指定
右上のボタンでは、参照したいデータ範囲を色んなやり方で指定できます。
Quick: 良く使われるパターンを簡易的に指定
当日とか当月とか直近15分など。
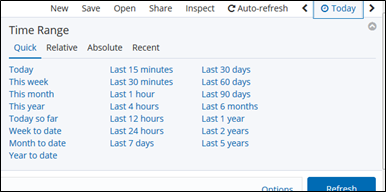
Relative: 現時点を基点にした指定
1時間前~30分前までなど。
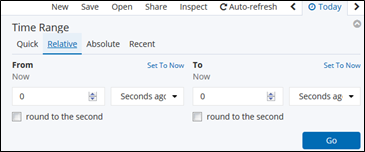
Absolute: 絶対的な日時指定
2019/3/25 10:00:00 ~ 2019/3/26 08:00:00 など。
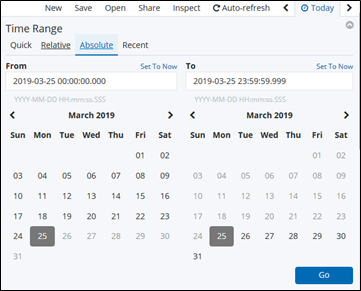
Recent: 最近使った範囲指定
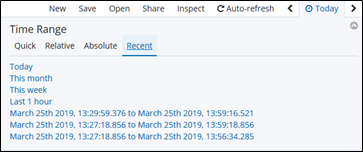
直近の情報を出力させている場合、Auto-Refresh機能をONにしておくと、定期的に情報の更新をしてくれるので、常に最新情報を表示させておくことができます。
参照範囲は③のヒストグラム上をドラッグすることで指定することもできます。
③ ヒストグラム
参照している範囲における、時間帯毎のレコード件数が棒グラフで表示されます。範囲をドラッグすることで参照範囲を変更することも可能です。
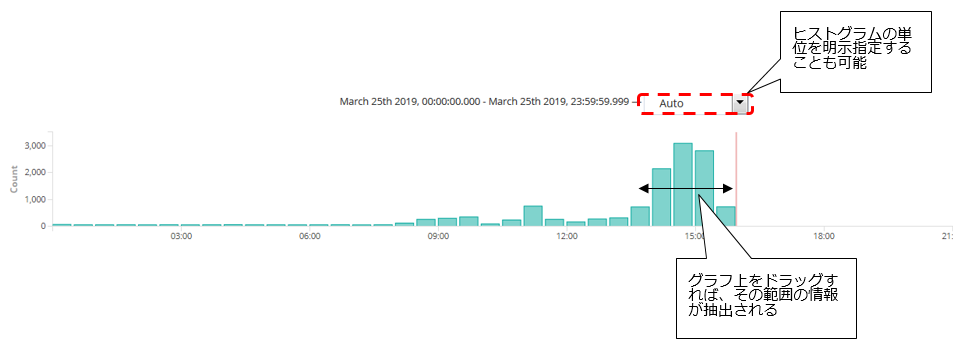
棒グラフの高さが高くなっている時間帯があれば、それはその時間帯に大量にメッセージが出力されたことを意味します。ですので、例えば他の時間帯より棒グラフがぴょこっと出てるところがあったとしたら、その部分をドラッグしてその範囲を絞り込んで、そこでどういうメッセージが沢山でていたのかな?というのを見ることができます。
④ フィルター
フィルターを指定することで、特定条件に合致するレコードのみを抽出することができます。
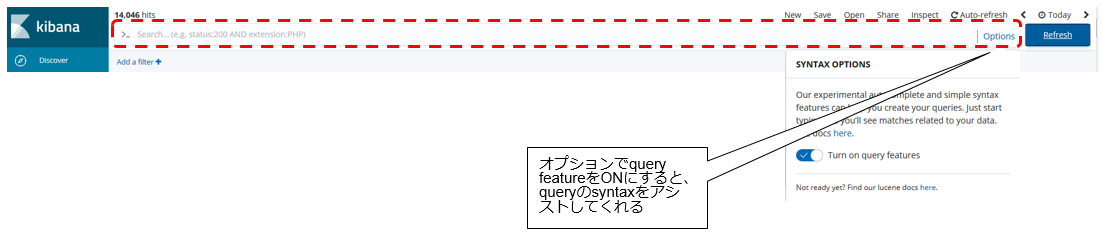
このフィルター欄では、例えばこんな感じの指定ができます。
- 「CICS」 : 任意のフィールドに”CICS”という文字列が含まれているレコードを抽出
- 「ident:CICS*」 : identフィールドにCICSで始まる文字列が含まれているレコードを抽出
- 「ident:CICS* AND msg_txt:ZC30*」 identフィールドにCICSで始まる文字列が含まれており、かつ、msg_txtにZC30で始まる文字列が含まれるレコードを抽出
特定のユーザーの操作だけ抽出してみたり、DFH*ではじまるCICS関連のメッセージだけ抽出して表示させる、みたいなことが比較的簡単にできますね。
さらにElasticsearchはもともとドキュメントの検索エンジン(Apache Luceneがベース)ですので、こういう条件指定での検索みたいなものは得意です。この欄の指定以外でも様々な方法での検索ができます。Query DSLというJSONベースの方式を使うと、より複雑なQueryを実施することも可能です。
参考: Query DSL(https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html)
⑤ フィールド操作
⑥のエリアに表示したいフィールドを選択したり、そのフィールドに現れる件数上位の値を表示してくれたりします。
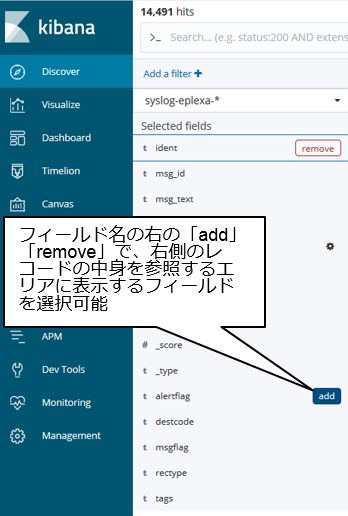
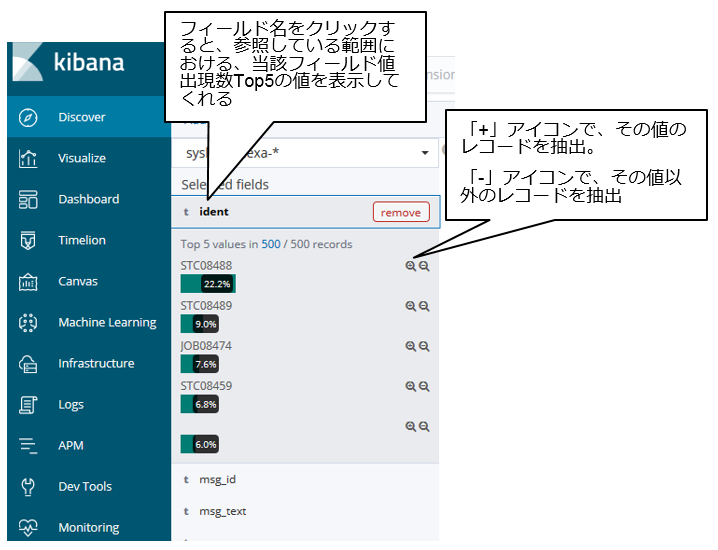
⑥ レコードの中身参照
SYSLOGの中身そのものを確認できるエリアです。基本、最新のものが上にくるので時刻で降順ソートされていますが、もちろん昇順ソートで表示することもできます。
応用編
Kibanaでは、Elasticsearchに保持されているフィールドを可視化の段階で加工して表示させるような仕組みも提供されているのでやってみます。
例えば、Scripted fieldというものを使うと、既存のフィールドをベースにロジックを組込んで加工し別フィールドを定義できます。
参考:
KibanaのScript FieldでPainlessを使う
Painless Scripting Language
ここでは、msg_idのフィールドの先頭3桁を取って、msg_categoryというフィールドを作ってみます(先頭3桁みればだいたい何のメッセージか区別がつくので)。
Managementメニューから、Index Patterns - 対象のIndex Patternを選択し(ここではsyslog-zosmf-*)、Scripted fieldsというタブの中から、Add scripted fieldボタンを押します。
以下のような感じで、msg_categoryフィールドを追加します。
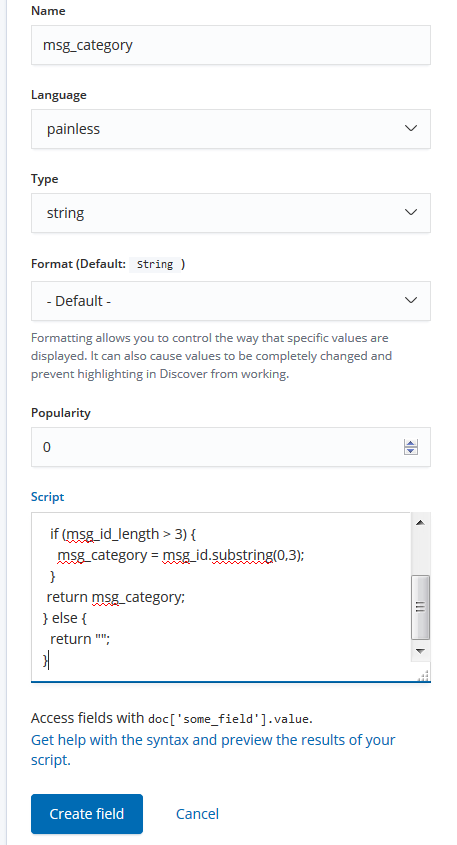
Script部分のコードは以下の通りです。
def msg_id = doc['msg_id.keyword'].value;
if (msg_id != null) {
int msg_id_length = msg_id.length();
def msg_category = msg_id;
if (msg_id_length > 3) {
msg_category = msg_id.substring(0,3);
}
return msg_category;
} else {
return "";
}
これで保存し、Discoverで見てみると、
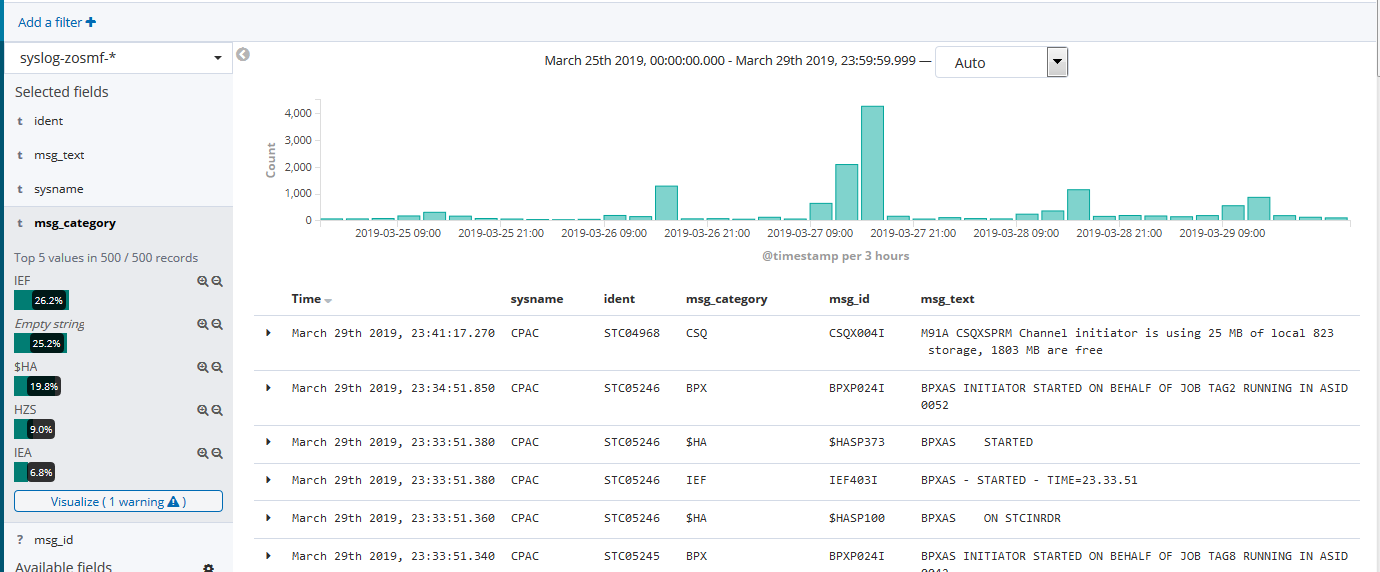
こんな感じにmsg_idの頭3桁を抽出したmsg_categoryフィールドが他のフィールドと同じように扱えます。
これで、当該時間帯でどういうカテゴリのメッセージが出ているか、というのも分かりやすいですね!
Scripted fieldは、実際にそういうフィールドがElasticsearch上に定義されていなくても、Kibana上で定義して扱うことができるのが便利です。
ただし、可視化の時点でスクリプト処理が行われることになるのでパフォーマンスの悪化に繋がります。これがヘビーに使われるのであれば、Elasticsearchに取り込むタイミングで、そういうフィールドを追加してしまう方がよいでしょう(Elasticsearchに取り込むデータ量と可視化時のパフォーマンスのトレードオフになるかと思います)。
補足
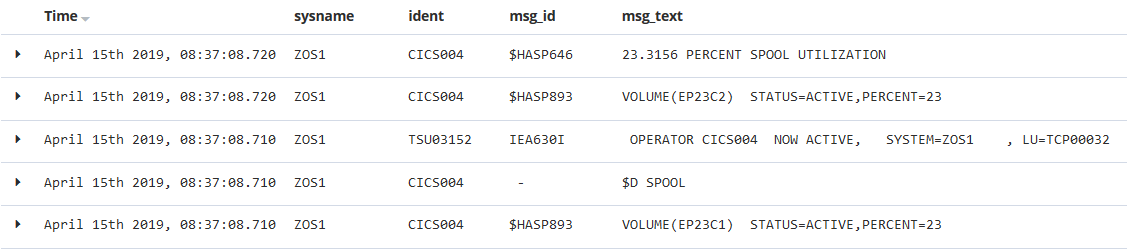
SYSLOGは10msec単位でメッセージが表示されていますが、タイムスタンプが同じメッセージがあった場合、Kibana上の表示は実際のSYSLOGの表示と順番が異なる場合があります。
PCOMによるSYSLOG表示(時系列としては昇順表示)

KibanaによるSYSLOG表示(時系列としては降順表示)
おわりに
PCOMのSDSFでSYSLOGの画面を使うのは、単にSYSLOG確認だけでなくMVSのシステムコマンドを投入したりすると思うので、今回の仕組みだけでPCOMの置き換えにはなりえないですが、手っ取り早くSYSLOGを確認したり、SYSLOGを分析したりするなど、補足的に使うと便利ですよね。(Elasticsearchに取り込まれるまでタイムラグが発生するので、リアルタイム性を求める場合は若干難ありです。)
Elasticsearchにデータが取り込まれていれば、データを加工するロジックも自由に作りやすいので、色々使い道が広がると思います。
※ 一応各ファイルは以下のGitHub上にも公開しています。作り物はこのページ上で紹介したものがほぼ全てですけど。
https://github.com/tomotagwork/zOS_with_ELK