はじめに
ずいぶん前にz/OSのSYSLOGをElasticsearchに取り込むというのをやってみましたが、それの別パターンを試してみました。
以前は REXX/ShellScript => Logstash => Elasticsearch => Kibana
という経路でデータ取得, 可視化しましたが、
今回は ファイル/FTP => fluentd => Elasticsearch => Grafana
という経路でデータ取得、可視化してみます。
関連記事
z/OSの新しい管理方法を探る - (1)DAパネル情報のElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (2)-1 SYSLOGのElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (2)-2 SYSLOGのElasticsearchへの取り込み part2
z/OSの新しい管理方法を探る - (2)-3 SYSLOGのElasticsearchへの取り込み part3
z/OSの新しい管理方法を探る - (3)CICSヒストリカルデータのElasticsearchへの取り込み
z/OSの新しい管理方法を探る - (4) RMF MonitorIIIレポートのElasticsearchへの取り込み
Elasticsearchに取り込んだログ情報をGrafanaのLogsで表示
全体像
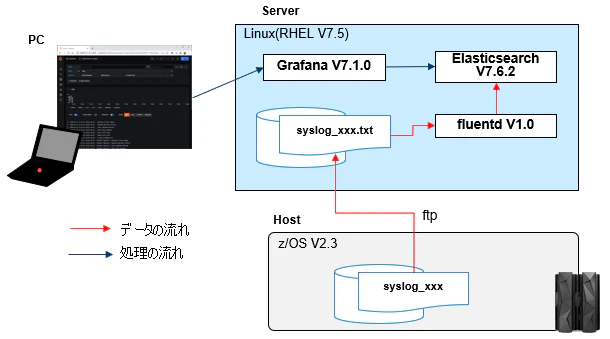
SYSLOGは定期的にファイルに落としてFTPでLinuxに転送し、fluentdでそのファイルを読み込んでElasticsearchに取り込む想定です。
SYSLOGを定期的に取得する部分はこの記事では触れていません(その辺の仕組みは環境によって個別に運用に組み込まれていたりするので)。適当な間隔で(数10分とか1時間とか)、細切れにファイルが転送されてくるという前提です。
※注意
SYSLOGは複数行で1つのレコードを意味するものがあります(マルチライン)。以下fluentdの定義ではマルチラインの1かたまりのメッセージを1レコードとして取り扱うようにしています。そのため、マルチラインの途中でファイルが途切れてしまうとその部分はメッセージのロストにつながる可能性が生じます。
Linux側環境
Linux(RHEL7.5)
Elasticsearch 7.6.2
Kibana 7.6.2
fluentd(td-agent) 1.0
Grafana 7.1.0
fluentd構成
特定のディレクトリに決まったネーミングでsyslogファイルが転送されてくる想定で、ファイルからデータを読み取ってデータをElasticsearchに投入します。
SYSLOGフォーマットの解釈
SYSLOGは複数行にまたがるのがちょっと厄介です。上のSYSLOGレコードフォーマット情報を参考に、multiline parser pluginで正規表現を使ってSYSLOG解釈していきます。
ちなみにこのmultiline parser pluginは、in_tail puluginでしか使えないようです(それがあってファイルを落として読み込む流れを前提としています。
参考:
tail
multiline
Unlike other parser plugins, this plugin needs special code in input plugin e.g. handle format_firstline. So, currently, in_tail plugin works with multiline but other input plugins do not work with it.
以下のように、in_tail pluginでmultiline parserを指定します。
<source>
@type tail
tag zos_syslog
path /etc/td-agent/Syslog/zos_syslog*.txt
pos_file /etc/td-agent/Syslog/zos_syslog.pos
refresh_interval 5s
read_from_head true
multiline_flush_interval 1m
<parse>
@type multiline
format_firstline /^ [NWMOX]/
format1 /^ (?<recordtype>[NWMOX][CRI ])(?<destcode>.{7}) (?<sysname>.{8}) (?<date_time>\d{2}\d{3} \d{2}:\d{2}:\d{2}\.\d{2}) (?<ident>.{8}) (?<msgflag>.{8}) (?<alertflag>.{1})[+]?((?<msgtext>(?<msgid>([A-Z]{3,7}[0-9]{3,5}[ADEISTW]?|\$HASP[0-9]{3,4})) (.*))|(?<msgtext>.*))/
</parse>
</source>
上の正規表現では、PCOMの画面でいうと以下のようにフィールド分割して解釈していることになります。
参考:
regexp
REGEXPER (正規表現を視覚的に表現してくれるサイト)
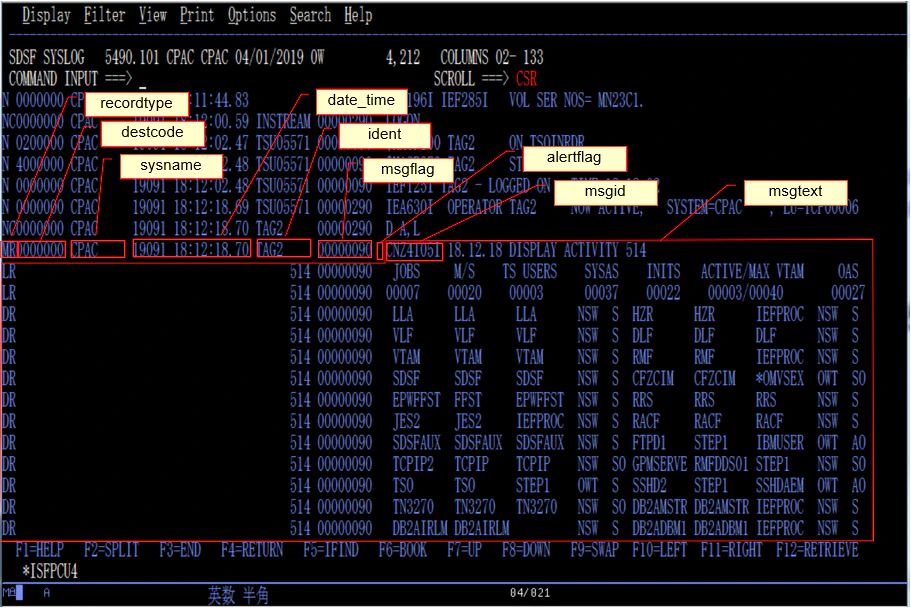
SYSLOGをファイルとして落とすと、1桁目にブランクが挿入されてしまうようです(やり方にもよるのかもしれませんが)。なので行の先頭にブランクがある前提で正規表現を記載しています。
メッセージ本体の先頭に"+"が入ることがあるのでこれは省くようにしています。
Grafanaで表示することを考慮して、msgtextにはmsgidを含ませるようにしています。
msgidは以下の辺りを参考に、割と汎用的にメッセージIDとして拾えるように正規表現を記載しています (この部分 => (?<msgid>([A-Z]{3,7}[0-9]{3,5}[ADEISTW]?|\$HASP[0-9]{3,4})))。
参考:
メッセージ本文のフォーマット
JES2 メッセージの形式
マルチラインのデータを扱う場合、一連のメッセージをバッファリングしていき、後続行が次のメッセージの先頭(format_firstline)に合致した場合、すなわち、マルチラインが終了したことが確定した段階でバッファリングしていたものを1レコードとして書き出します。つまりファイルの最後の部分のメッセージはその次のメッセージが来ないと書き出されないことになります。これに対しては、multiline_flush_intervalを指定することで一定期間後続メッセージがこなかったらバッファリングされていたものが書き出されるという動きになります。
フィールド変換
上のmultilineのパースでベースとなるフィールド毎の解釈ができました。いくつかフィールド毎の操作が必要な部分があるので個別に対応していきます。
sysname
ここではElasticsearchに取り込む際のindex名にsysnameを付けることを想定します。index名にブランクが含まれていると取り込み時にエラーになってしまうので、sysnameから余分なブランクを取り除きます。
record_transformer filterプラグインで新たなフィールドの作成や上書きができます。enable_rubyを指定するとrubyコードが指定できます。
参考: record_transformer
こんな感じになります。
<filter zos_syslog>
@type record_transformer
enable_ruby
<record>
sysname ${record["sysname"].strip}
</record>
</filter>
参考: instance method String#strip
タイムスタンプ
date_timeフィールドでレコード毎のタイムスタンプを解釈していますが、これはジュリアンデートで表現されているので、標準的なフォーマットに変換します。
これもrecord_transformerで変換できます。
<filter zos_syslog>
@type record_transformer
enable_ruby
<record>
sysname ${record["sysname"].strip}
date_time ${require "date"; DateTime.strptime(record["date_time"] + "+0900", "%y%j %H:%M:%S.%L%z").iso8601(2).to_s}
</record>
</filter>
上のsysnameの対応に追加でdate_timeの解釈をしています。扱う時刻はAsia/Tokyoのタイムゾーンを想定しているので"+0900"を指定しています。想定される元データのタイムゾーンに合わせて適宜変更してください。
参考:
DateTime - strptime
strptime
instance method Time#iso8601
マルチラインの2行目以降
2行目以降の左側部分(以下の赤枠部分)は邪魔なので削除します。
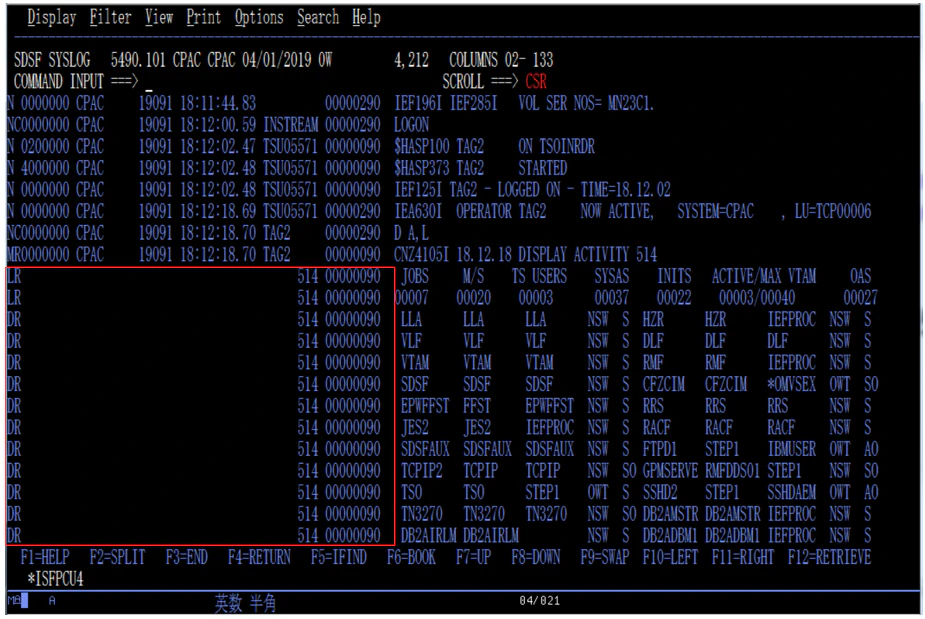
これもrecord_transformerで指定できるので、上の定義に追記します。
<filter zos_syslog>
@type record_transformer
enable_ruby
<record>
sysname ${record["sysname"].strip}
date_time ${require "date"; DateTime.strptime(record["date_time"] + "+0900", "%y%j %H:%M:%S.%L%z").iso8601(2).to_s}
msgtext ${record["msgtext"].gsub(/\n [DELS][CRI ][ ]{35}.{8} .{8} /, "\n")}
</record>
</filter>
gsubで2行目先頭部分にマッチする文字列を正規表現で判定し、削除しています。
参考: instance method String#gsub
ログレベルの設定
ログレベル用のフィールドを追加します。
これは、GrafanaのLogsというVisualizeに対応させるためです。ログの内容に応じて、"critical, debug, error, info trace, unknown, warning"のいずれかのレベルを設定しておくことで、色分けして表示してくれるようになります。
参考: Elasticsearchに取り込んだログ情報をGrafanaのLogsで表示
そのため、loglevelというフィールドを新たに追加してそこに"critical", "error"などの値を設定していきたいと思います。
ここでは、msgidとして認識した値の末尾の文字に応じてレベル分けします。
参考: メッセージ本文のフォーマット
上の記述を参考に、以下のようにマッピングします。
末尾が"S": critical
末尾が"E": error
末尾が"W": warning
末尾が"I": info
それ以外: unknown
fluentdでは各メッセージがタグ付けされているので、タグを利用してmsgidの末尾に応じてloglevelフィールドを追加します。
rewrite_tag_filterプラグインでmsgidに応じたタグ付けをし、record_transformerでタグ名からloglevelを設定します。
参考: rewrite_tag_filter
こんな感じ。
<match zos_syslog>
@type rewrite_tag_filter
<rule>
key msgid
pattern /S$/
tag ${tag}.critical
</rule>
<rule>
key msgid
pattern /E$/
tag ${tag}.error
</rule>
<rule>
key msgid
pattern /W$/
tag ${tag}.warning
</rule>
<rule>
key msgid
pattern /I$/
tag ${tag}.info
</rule>
<rule>
key recordtype
pattern /.+/
tag ${tag}.unknown
</rule>
</match>
<filter zos_syslog.**>
@type record_transformer
enable_ruby
<record>
loglevel ${tag_parts[1]}
</record>
</filter>
Elasticsearchへの出力部分
ここまでであらかた準備は整ったので、加工されたメッセージをElasticsearchに投入するための定義を作成します。
こんな感じ。
<match zos_syslog.**>
@type elasticsearch_dynamic
host "localhost"
port 9200
logstash_format true
logstash_prefix "syslog-${record[\'sysname\']}"
logstash_dateformat "%Y%m%d"
time_key "date_time"
utc_index false
<buffer>
flush_interval 1
</buffer>
</match>
index名としては、"syslog-sysname-yyyymmdd" というような形式になります。
date_timeフィールドをタイムスタンプ用のフィールドとして指定しています。
参考: GitHub - uken/fluent-plugin-elasticsearch - Dynamic Configuration
fluentd構成ファイルまとめ
最終的はfluentdの構成ファイルはこんな感じになります。
fluentd構成ファイル全体
<system>
log_level debug
</system>
<source>
@type tail
tag zos_syslog
path /etc/td-agent/Syslog/zos_syslog*.txt
pos_file /etc/td-agent/Syslog/zos_syslog.pos
refresh_interval 5s
read_from_head true
multiline_flush_interval 1m
<parse>
@type multiline
format_firstline /^ [NWMOX]/
format1 /^ (?<recordtype>[NWMOX][CRI ])(?<destcode>.{7}) (?<sysname>.{8}) (?<date_time>\d{2}\d{3} \d{2}:\d{2}:\d{2}\.\d{2}) (?<ident>.{8}) (?<msgflag>.{8}) (?<alertflag>.{1})[+]?((?<msgtext>(?<msgid>([A-Z]{3,7}[0-9]{3,5}[ADEISTW]?|\$HASP[0-9]{3,4})) (.*))|(?<msgtext>.*))/
</parse>
</source>
<filter zos_syslog>
@type record_transformer
enable_ruby
<record>
sysname ${record["sysname"].strip}
date_time ${require "date"; DateTime.strptime(record["date_time"] + "+0900", "%y%j %H:%M:%S.%L%z").iso8601(2).to_s}
msgtext ${record["msgtext"].gsub(/\n [DELS][CRI ][ ]{35}.{8} .{8} /, "\n")}
</record>
</filter>
<match zos_syslog>
@type rewrite_tag_filter
<rule>
key msgid
pattern /S$/
tag ${tag}.critical
</rule>
<rule>
key msgid
pattern /E$/
tag ${tag}.error
</rule>
<rule>
key msgid
pattern /W$/
tag ${tag}.warning
</rule>
<rule>
key msgid
pattern /I$/
tag ${tag}.info
</rule>
<rule>
key recordtype
pattern /.+/
tag ${tag}.unknown
</rule>
</match>
<filter zos_syslog.**>
@type record_transformer
enable_ruby
<record>
loglevel ${tag_parts[1]}
</record>
</filter>
# <match zos_syslog.**>
# @type stdout
# </match>
<match zos_syslog.**>
@type elasticsearch_dynamic
host "localhost"
port 9200
logstash_format true
logstash_prefix "syslog-${record[\'sysname\']}"
logstash_dateformat "%Y%m%d"
time_key "date_time"
utc_index false
<buffer>
flush_interval 1
</buffer>
</match>
Elasticsearch index template
以下のようにindex templateを作成しておきます。
PUT _template/syslog
{
"index_patterns": ["syslog-*"],
"order" : 0,
"settings": {
"number_of_shards": 1,
"number_of_replicas" : 0
},
"mappings": {
"numeric_detection": true,
"properties": {
"destcode": {
"type": "text"
},
"msgflag": {
"type": "text"
}
}
}
}
ここで使用している環境はテスト用なのでElasticsearchは1ノード構成にしています。従ってレプリカシャードは作れないのでレプリカ数は0にしています。
また、destcode, msgflagフィールドは、最初にアルファベットが含まれないデータが投入されてしまう可能性があるので、明示的に型指定をしています(他も指定しておいた方が安全ですが、最低限これらは指定しておいた方がよい)。
データ投入
あとはElasticsearch, fluentdを起動させて、fluentdのin_tailプラグインで指定したディレクトリ、名前に従ってsyslogファイルを転送してあげればOK。
適当なサンプルを取り込んで、KibanaのDiscoverで見るとこんな感じになります。
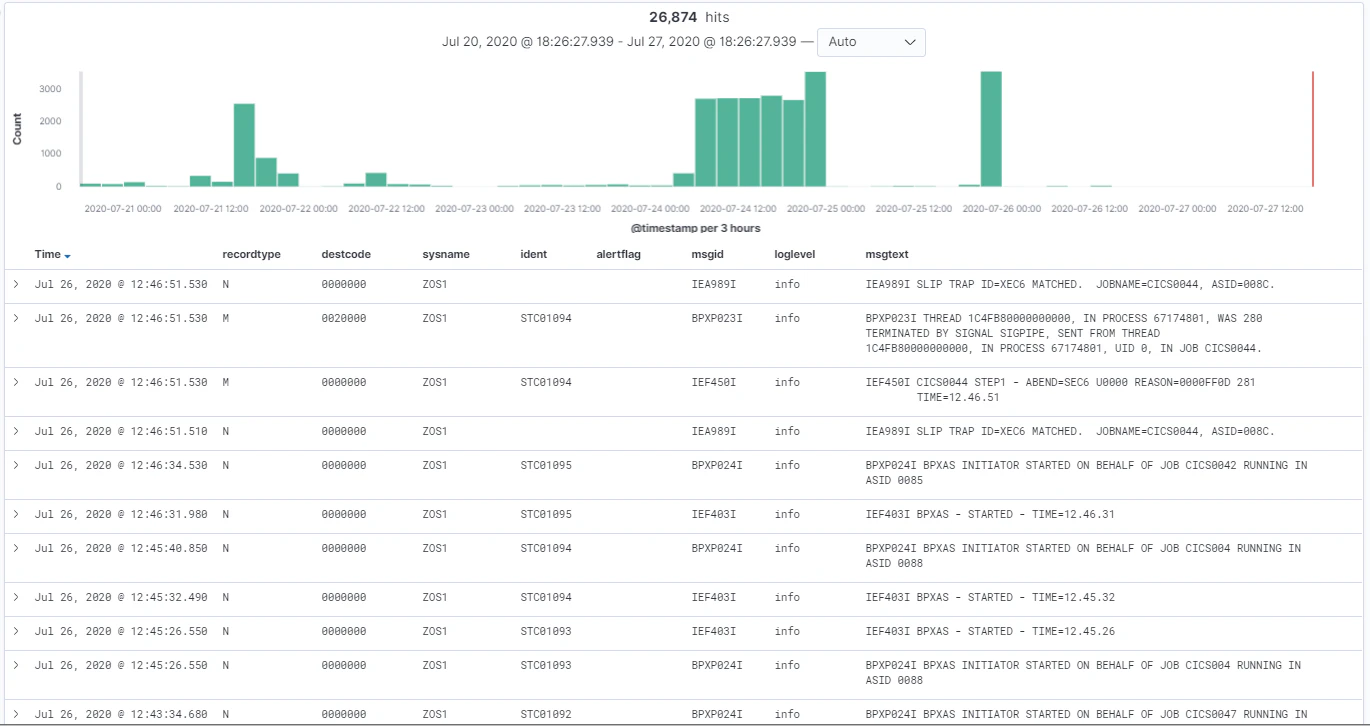
GrafanaのLogsで確認
DataSource定義
以下のようにDataSourceの定義を追加します。
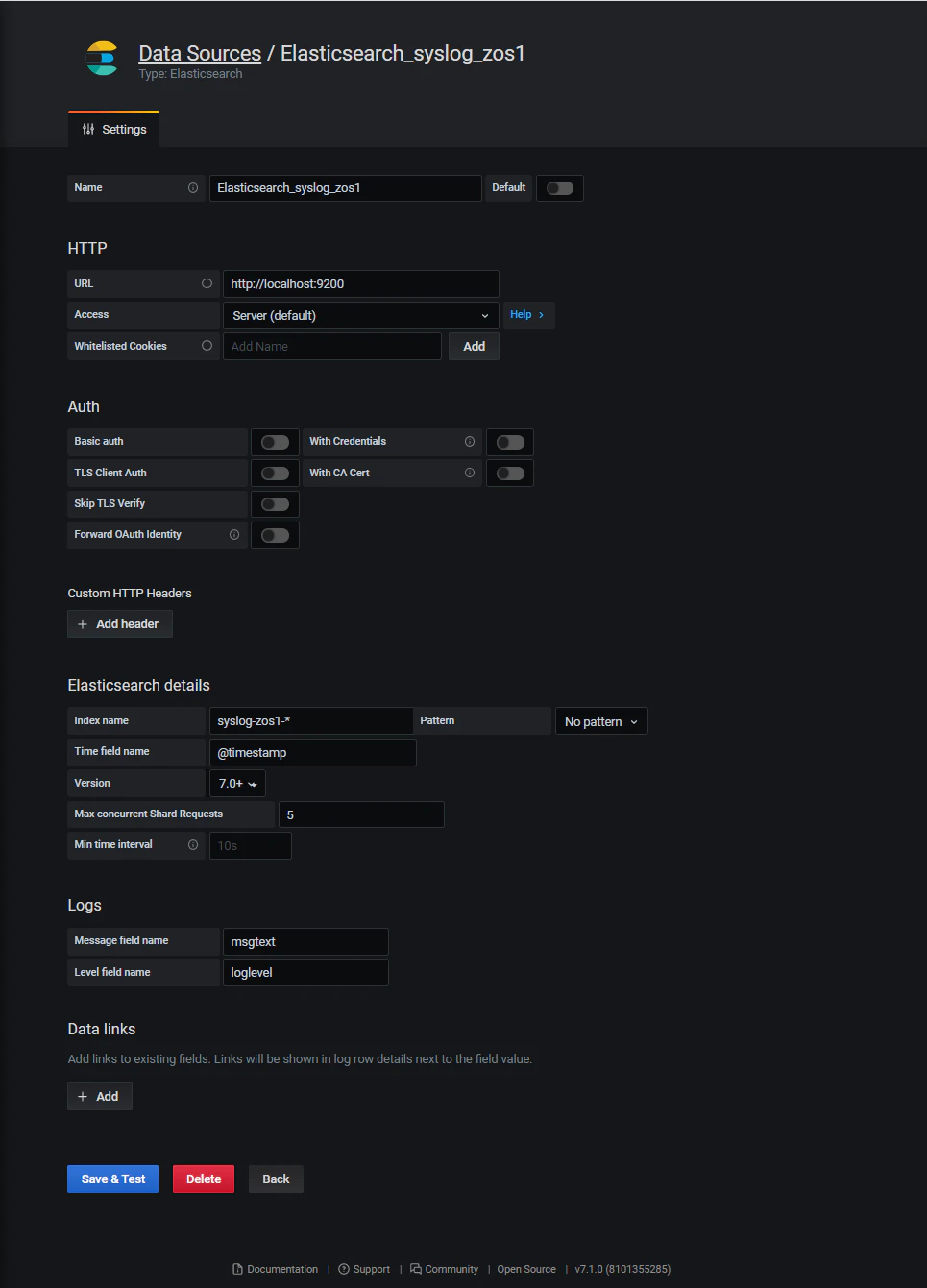
index名にはターゲットとなるIndexのパターンを指定します。
Logsの項目には、メッセージ用のフィールドとしてmsgtext、レベル用のフィールドとしてloglevelを指定します。
Explorer
Explorer画面で、上で定義したDataSourceを指定し、MetricにLogsを指定します。
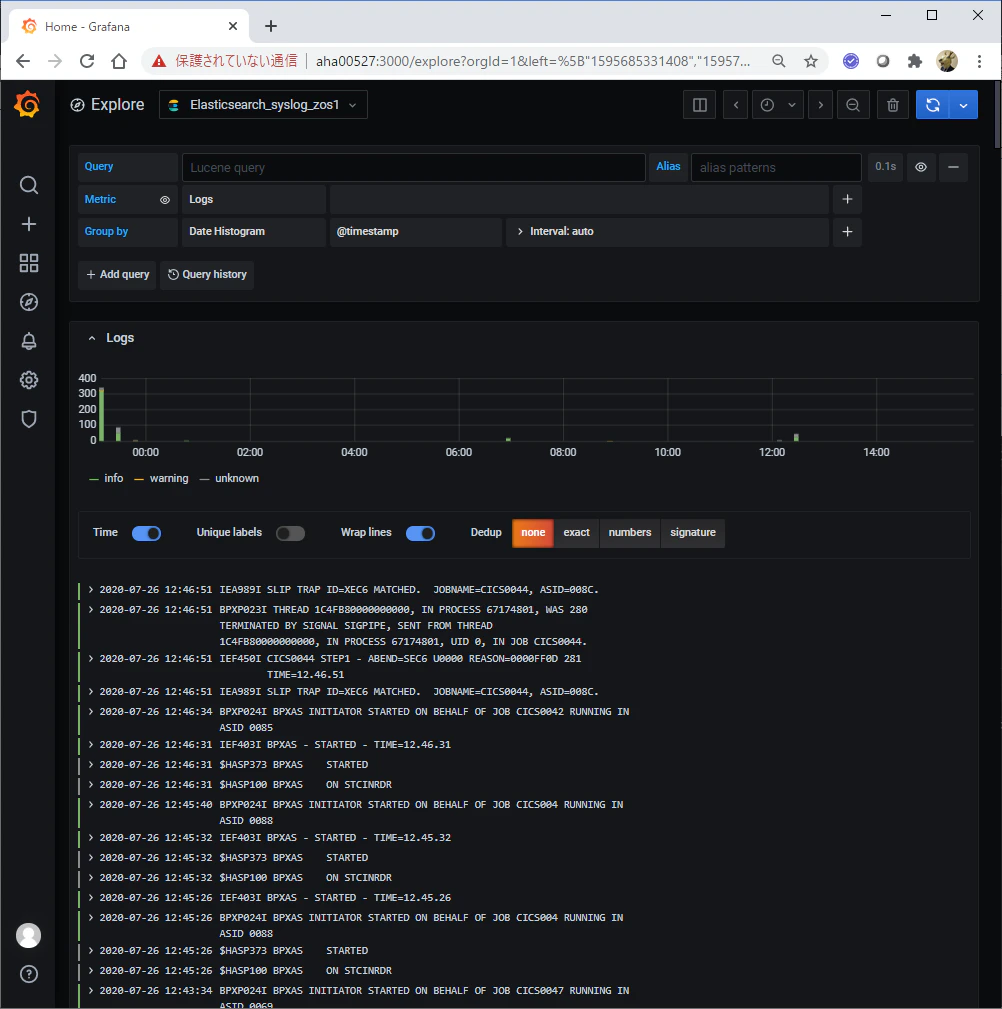
上のように、loglevelに応じて色分けされ、SYSLOGが表示されます。
loglevelごとの表示やQueryなども使用できます。