はじめに
fluentdやlogstashは比較的リアルタイムにデータを転送する場合(Streaming)に有効なようですが、大量のデータをバッチ的に取り扱う場合はEmbulkというOSSが適しているようです。
参考: Fluentdのバッチ版Embulk(エンバルク)のまとめ
ここでは、CSVファイルをEmbulkを使ってElasticsearchに取り込む手順を試してみました。
末尾にEmbulkとfluentdの簡単なパフォーマンス比較結果も記載しています。
参考情報
Embulk Documentation
Scheduled bulk data loading to Elasticsearch + Kibana 5 from CSV files
環境準備
RHEL V7.5
Elasticsearch V7.6.2
Kibana V7.6.2
Embulk V0.9.23
Elasticsearch/Kibanaインストール
この辺を参考に
fluentd/Elasticsearch/kibanaを試す: (1)インストール
Java
EmbulkはJavaで実装されているよなので、Javaが前提で必要になります。
最新のEmbulkはJava8以降であればよいようなので、セットアップしておきます(詳細はここでは割愛)。
[root@test08 ~]# java -version
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
Embulkインストール
以下の記述を参考に。
参考: Quick Start - Linux & Mac & BSD
バイナリを適当な所にダウンロード。
[root@test08 ~]# curl --create-dirs -o /usr/local/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 628 100 628 0 0 1310 0 --:--:-- --:--:-- --:--:-- 1310
100 42.4M 100 42.4M 0 0 1535k 0 0:00:28 0:00:28 --:--:-- 2611k
実行権限設定
[root@test08 ~]# chmod +x /usr/local/bin/embulk
[root@test08 ~]# ls -la /usr/local/bin | grep embulk
-rwxr-xr-x. 1 root root 44506338 6月 21 13:40 embulk
上でダウンロードしたembulkのパスをPATHに設定
確認
[root@test08 ~]# embulk --help
Embulk v0.9.23
Usage: embulk [-vm-options] <command> [--options]
Commands:
mkbundle <directory> # create a new plugin bundle environment.
bundle [directory] # update a plugin bundle environment.
run <config.yml> # run a bulk load transaction.
cleanup <config.yml> # cleanup resume state.
preview <config.yml> # dry-run the bulk load without output and show preview.
guess <partial-config.yml> -o <output.yml> # guess missing parameters to create a complete configuration file.
gem <install | list | help> # install a plugin or show installed plugins.
new <category> <name> # generates new plugin template
migrate <path> # modify plugin code to use the latest Embulk plugin API
example [path] # creates an example config file and csv file to try embulk.
selfupdate [version] # upgrades embulk to the latest released version or to the specified version.
VM options:
-E... Run an external script to configure environment variables in JVM
(Operations not just setting envs are not recommended nor guaranteed.
Expect side effects by running your external script at your own risk.)
-J-O Disable JVM optimizations to speed up startup time (enabled by default if command is 'run')
-J+O Enable JVM optimizations to speed up throughput
-J... Set JVM options (use -J-help to see available options)
-R--dev Set JRuby to be in development mode
Use `<command> --help` to see description of the commands.
EmbulkのElasticsearch用プラグインのインストール
[root@test08 ~]# embulk gem install embulk-output-elasticsearch
2020-06-21 13:57:53.675 +0900: Embulk v0.9.23
Gem plugin path is: /root/.embulk/lib/gems
Fetching: embulk-output-elasticsearch-0.4.7.gem (100%)
Successfully installed embulk-output-elasticsearch-0.4.7
1 gem installed
サンプルデータの取り込み
Embulkが提供しているサンプルのCSVを、Embulk経由でElasticsearchに取り込んで見ます。
参考: Scheduled bulk data loading to Elasticsearch + Kibana 5 from CSV files
Embulkサンプルの準備
Embulk提供のサンプルのファイルがあるようなのでそれをセットアップします。
[root@test08 ~/embulk]# embulk example ./mydata
2020-06-21 14:04:20.556 +0900: Embulk v0.9.23
Creating ./mydata directory...
Creating ./mydata/
Creating ./mydata/csv/
Creating ./mydata/csv/sample_01.csv.gz
Creating ./mydata/seed.yml
Run following subcommands to try embulk:
1. embulk guess ./mydata/seed.yml -o config.yml
2. embulk preview config.yml
3. embulk run config.yml
これで以下のようなファイルが作成されます。
[root@test08 ~/embulk]# tree --charset=C
.
`-- mydata
|-- csv
| `-- sample_01.csv.gz
`-- seed.yml
内容確認
構成ファイルの雛形となるseed.ymlが提供されています。
in:
type: file
path_prefix: '/root/embulk/./mydata/csv/sample_'
out:
type: stdout
CSVファイルはgz形式で固められていますが、解凍して中身をみてみるとこんな感じのファイルが含まれています。
id,account,time,purchase,comment
1,32864,2015-01-27 19:23:49,20150127,embulk
2,14824,2015-01-27 19:01:23,20150127,embulk jruby
3,27559,2015-01-28 02:20:02,20150128,"Embulk ""csv"" parser plugin"
4,11270,2015-01-29 11:54:36,20150129,NULL
Embulk構成ファイル作成
雛形であるseed.ymlを指定してembulk guessコマンドを使用すると、必要なパラメーターを補って構成ファイルを生成してくれるようです。
[root@test08 ~/embulk]# embulk guess ./mydata/seed.yml -o config.yml
2020-06-21 14:09:12.870 +0900: Embulk v0.9.23
2020-06-21 14:09:13.689 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2020-06-21 14:09:15.928 +0900 [INFO] (main): Gem's home and path are set by default: "/root/.embulk/lib/gems"
2020-06-21 14:09:17.085 +0900 [INFO] (main): Started Embulk v0.9.23
2020-06-21 14:09:17.188 +0900 [INFO] (0001:guess): Listing local files at directory '/root/embulk/./mydata/csv' filtering filename by prefix 'sample_'
2020-06-21 14:09:17.189 +0900 [INFO] (0001:guess): "follow_symlinks" is set false. Note that symbolic links to directories are skipped.
2020-06-21 14:09:17.190 +0900 [INFO] (0001:guess): Loading files [/root/embulk/./mydata/csv/sample_01.csv.gz]
2020-06-21 14:09:17.200 +0900 [INFO] (0001:guess): Try to read 32,768 bytes from input source
2020-06-21 14:09:17.255 +0900 [INFO] (0001:guess): Loaded plugin embulk (0.9.23)
2020-06-21 14:09:17.270 +0900 [INFO] (0001:guess): Loaded plugin embulk (0.9.23)
2020-06-21 14:09:17.288 +0900 [INFO] (0001:guess): Loaded plugin embulk (0.9.23)
2020-06-21 14:09:17.298 +0900 [INFO] (0001:guess): Loaded plugin embulk (0.9.23)
in:
type: file
path_prefix: /root/embulk/./mydata/csv/sample_
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
null_string: 'NULL'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
- {name: purchase, type: timestamp, format: '%Y%m%d'}
- {name: comment, type: string}
out: {type: stdout}
Created 'config.yml' file.
以下の構成ファイルが作成されました。
in:
type: file
path_prefix: /root/embulk/./mydata/csv/sample_
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
null_string: 'NULL'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
- {name: purchase, type: timestamp, format: '%Y%m%d'}
- {name: comment, type: string}
out: {type: stdout}
parserのカスタマイズ
時刻情報のタイムゾーンを指定のため、parserに以下の設定を追加します。
default_timezone: 'Asia/Tokyo'
outputのカスタマイズ
参考: embulk/embulk-output-elasticsearch
出力先をElasticsearchにするため、out:部分を以下のように変更します。
out:
type: elasticsearch
index: embulk
index_type: embulk
nodes:
- {host: localhost, port: 9200}
最終系
最終的には以下のようになります。
in:
type: file
path_prefix: /root/embulk/./mydata/csv/sample_
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
null_string: 'NULL'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
- {name: purchase, type: timestamp, format: '%Y%m%d'}
- {name: comment, type: string}
default_timezone: 'Asia/Tokyo'
out:
type: elasticsearch
index: embulk
index_type: embulk
nodes:
- {host: localhost, port: 9200}
データ取り込み実施
Embulk経由でCSVファイルをElasticsearchに取り込んでみます。
と、その前に、プレビューをする機能があるようなので、構成ファイルに問題がないか確認してみます。
[root@test08 ~/embulk]# embulk preview config.yml
2020-06-21 16:47:07.804 +0900: Embulk v0.9.23
2020-06-21 16:47:08.652 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2020-06-21 16:47:11.299 +0900 [INFO] (main): Gem's home and path are set by default: "/root/.embulk/lib/gems"
2020-06-21 16:47:12.193 +0900 [INFO] (main): Started Embulk v0.9.23
2020-06-21 16:47:12.276 +0900 [INFO] (0001:preview): Listing local files at directory '/root/embulk/./mydata/csv' filtering filename by prefix 'sample_'
2020-06-21 16:47:12.277 +0900 [INFO] (0001:preview): "follow_symlinks" is set false. Note that symbolic links to directories are skipped.
2020-06-21 16:47:12.278 +0900 [INFO] (0001:preview): Loading files [/root/embulk/./mydata/csv/sample_01.csv.gz]
2020-06-21 16:47:12.285 +0900 [INFO] (0001:preview): Try to read 32,768 bytes from input source
+---------+--------------+-------------------------+-------------------------+----------------------------+
| id:long | account:long | time:timestamp | purchase:timestamp | comment:string |
+---------+--------------+-------------------------+-------------------------+----------------------------+
| 1 | 32,864 | 2015-01-27 10:23:49 UTC | 2015-01-26 15:00:00 UTC | embulk |
| 2 | 14,824 | 2015-01-27 10:01:23 UTC | 2015-01-26 15:00:00 UTC | embulk jruby |
| 3 | 27,559 | 2015-01-27 17:20:02 UTC | 2015-01-27 15:00:00 UTC | Embulk "csv" parser plugin |
| 4 | 11,270 | 2015-01-29 02:54:36 UTC | 2015-01-28 15:00:00 UTC | |
+---------+--------------+-------------------------+-------------------------+----------------------------+
OKそうなので、実際に取り込みを行ってみましょう。
[root@test08 ~/embulk]# embulk run config.yml -c diff.yml
2020-06-21 14:37:42.867 +0900: Embulk v0.9.23
2020-06-21 14:37:45.269 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2020-06-21 14:37:47.755 +0900 [INFO] (main): Gem's home and path are set by default: "/root/.embulk/lib/gems"
2020-06-21 14:37:48.819 +0900 [INFO] (main): Started Embulk v0.9.23
2020-06-21 14:37:48.965 +0900 [INFO] (0001:transaction): Loaded plugin embulk-output-elasticsearch (0.4.7)
2020-06-21 14:37:49.024 +0900 [INFO] (0001:transaction): Listing local files at directory '/root/embulk/./mydata/csv' filtering filename by prefix 'sample_'
2020-06-21 14:37:49.025 +0900 [INFO] (0001:transaction): "follow_symlinks" is set false. Note that symbolic links to directories are skipped.
2020-06-21 14:37:49.026 +0900 [INFO] (0001:transaction): Loading files [/root/embulk/./mydata/csv/sample_01.csv.gz]
2020-06-21 14:37:49.084 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=12 / output tasks 6 = input tasks 1 * 6
2020-06-21 14:37:49.112 +0900 [INFO] (0001:transaction): Logging initialized @6700ms
2020-06-21 14:37:49.402 +0900 [INFO] (0001:transaction): Connecting to Elasticsearch version:7.6.2
2020-06-21 14:37:49.403 +0900 [INFO] (0001:transaction): Executing plugin with 'insert' mode.
2020-06-21 14:37:49.403 +0900 [INFO] (0001:transaction): Inserting data into index[embulk]
2020-06-21 14:37:49.412 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0}
2020-06-21 14:37:49.735 +0900 [INFO] (0023:task-0000): Inserted 4 records
2020-06-21 14:37:49.736 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0}
2020-06-21 14:37:49.737 +0900 [INFO] (0001:transaction): Insert completed. 4 records
2020-06-21 14:37:49.742 +0900 [INFO] (main): Committed.
2020-06-21 14:37:49.742 +0900 [INFO] (main): Next config diff: {"in":{"last_path":"/root/embulk/./mydata/csv/sample_01.csv.gz"},"out":{}}
取り込み完了しました。
KibanaでElasticsearchのIndex見てみます。
embulkというIndexが作成されました!
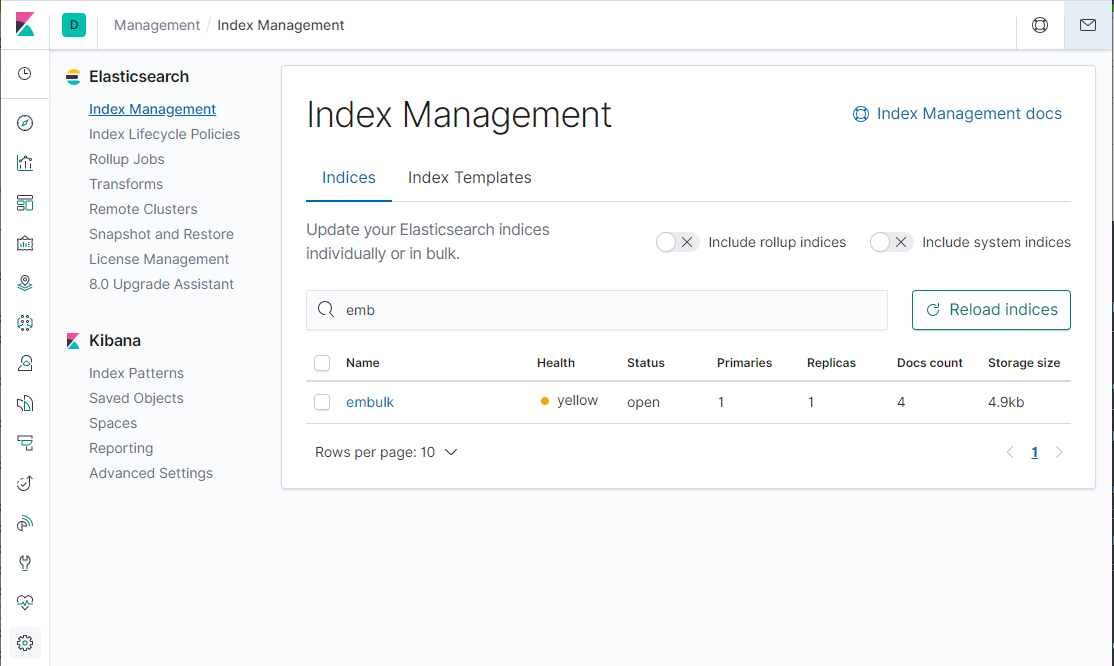
Index Patternを作成して中身をみてみます。("time"カラムをTime Filter fieldとして指定)
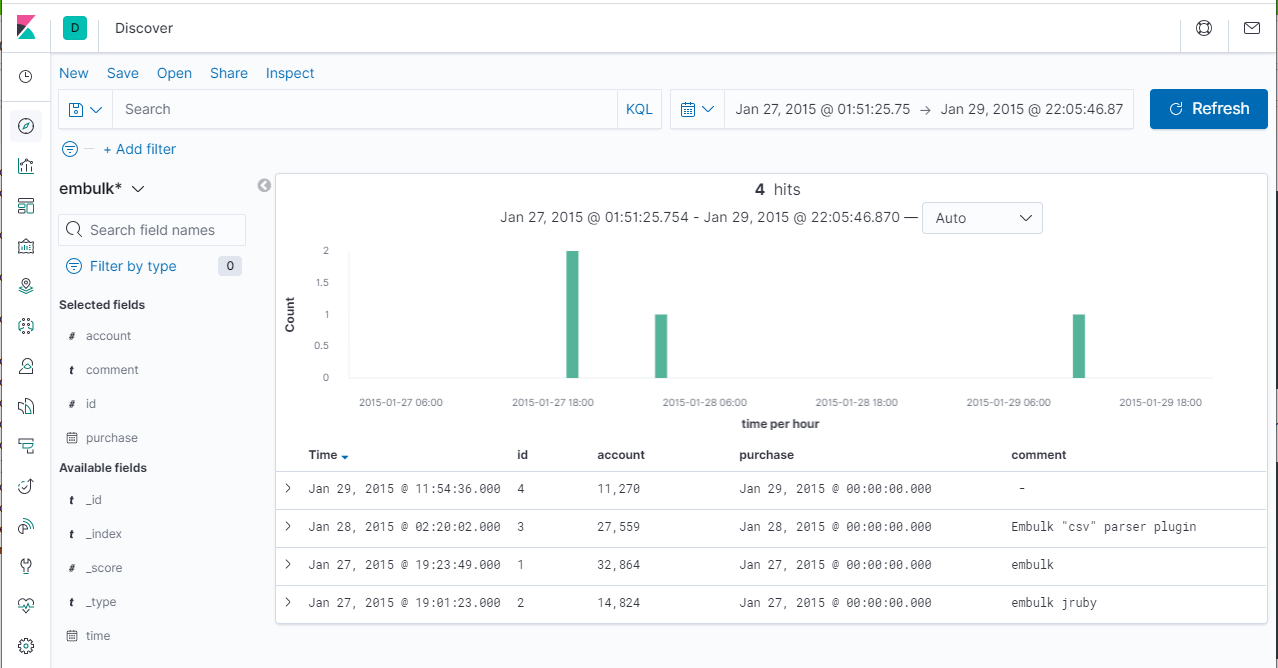
CSVで提供された4レコードが上のように取り込まれたことが確認できました。
補足
インデックス名について (環境変数の利用)
fluentdやlogstashは基本的には出力されるログなどの情報を逐一処理していくような形態で処理されますので(いわゆるストリーミング)、各レコードに含まれるフィールドを加工するということは普通に行われます。例えばElasticsearchにデータを取り込む際のIndex名の指定などもそうです。よく使われるのは特定のフィールドの情報を@timestampとして認識させその日付をIndex名に付与する、というようなことが行われます(Indexを日付単位に分ける)。2020/01/01のタイムスタンプのレコードはtest01_2020-01-01というインデックスに格納し、2020/01/02のタイムスタンプのレコードはtest01_2020-01-02というインデックスに格納する、といった具合です。
ただ、Embulkの場合そのようなレコードの内容に応じてインデックス名を変更するというような操作には対応していないようにみえます。
embulk/embulk-output-elasticsearch
index: index name (string, required)
index名として指定できる値については、上のような説明書きしかなく、レコードに含まれるタイムスタンプ情報からインデックス名を動的に判断させることは無理のようです。
Embulkはバッチで大量データを効率よく投入するのが目的なので、そもそもレコード毎の個別の処理を行うことはあまり想定していないのかもしれません。
ですので、レコード単位にインデックス名を可変にすることはできませんが、通常はある一定の単位で(1日分とか1時間分とか)バッチ的に投入することになると思うので、その都度投入するデータに応じてインデックス名を指定するということになります。
そのためには、上の例のようにyamlに固定でインデックス名を持たせてしまうと扱いにくいので、そのような可変にしたいものは環境変数で与えることができるようになっています。
上のサンプルの例のインデックス名を変数で与えるようにしてみます。
config.ymlをconfig.yml.liquidという名前にコピーして編集します。(拡張子をyml.liquidにする必要があります。)
in:
type: file
path_prefix: /root/embulk/./mydata/csv/sample_
decoders:
- {type: gzip}
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
null_string: 'NULL'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: id, type: long}
- {name: account, type: long}
- {name: time, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
- {name: purchase, type: timestamp, format: '%Y%m%d'}
- {name: comment, type: string}
default_timezone: 'Asia/Tokyo'
out:
type: elasticsearch
index: {{env.INDEX_NAME}}
index_type: embulk
nodes:
- {host: localhost, port: 9200}
outのindexの指定を index: {{env.INDEX_NAME}}に変更しました。
環境変数 INDEX_NAMEを指定して同じようにembulkを実行すればOKです。
[root@test08 ~/embulk]# export INDEX_NAME=embulk_201501
[root@test08 ~/embulk]# embulk run config.yml.liquid
2020-06-21 16:33:01.415 +0900: Embulk v0.9.23
2020-06-21 16:33:02.945 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2020-06-21 16:33:05.508 +0900 [INFO] (main): Gem's home and path are set by default: "/root/.embulk/lib/gems"
2020-06-21 16:33:08.014 +0900 [INFO] (main): Started Embulk v0.9.23
2020-06-21 16:33:08.129 +0900 [INFO] (0001:transaction): Loaded plugin embulk-output-elasticsearch (0.4.7)
2020-06-21 16:33:08.210 +0900 [INFO] (0001:transaction): Listing local files at directory '/root/embulk/./mydata/csv' filtering filename by prefix 'sample_'
2020-06-21 16:33:08.211 +0900 [INFO] (0001:transaction): "follow_symlinks" is set false. Note that symbolic links to directories are skipped.
2020-06-21 16:33:08.212 +0900 [INFO] (0001:transaction): Loading files [/root/embulk/./mydata/csv/sample_01.csv.gz]
2020-06-21 16:33:08.262 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=12 / output tasks 6 = input tasks 1 * 6
2020-06-21 16:33:08.288 +0900 [INFO] (0001:transaction): Logging initialized @7329ms
2020-06-21 16:33:08.609 +0900 [INFO] (0001:transaction): Connecting to Elasticsearch version:7.6.2
2020-06-21 16:33:08.609 +0900 [INFO] (0001:transaction): Executing plugin with 'insert' mode.
2020-06-21 16:33:08.610 +0900 [INFO] (0001:transaction): Inserting data into index[embulk_201501]
2020-06-21 16:33:08.619 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0}
2020-06-21 16:33:08.951 +0900 [INFO] (0025:task-0000): Inserted 4 records
2020-06-21 16:33:08.952 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0}
2020-06-21 16:33:08.953 +0900 [INFO] (0001:transaction): Insert completed. 4 records
2020-06-21 16:33:08.957 +0900 [INFO] (main): Committed.
2020-06-21 16:33:08.958 +0900 [INFO] (main): Next config diff: {"in":{"last_path":"/root/embulk/./mydata/csv/sample_01.csv.gz"},"out":{}}
上の例では、INDEX_NAMEにembulk_201501という名前を指定してみました(取り込む対象のデータが2015年1月のものであるため)。
KibanaでElasticsearchのIndex見てみると、embulk_2015というインデックスが作成されたことが確認できました。
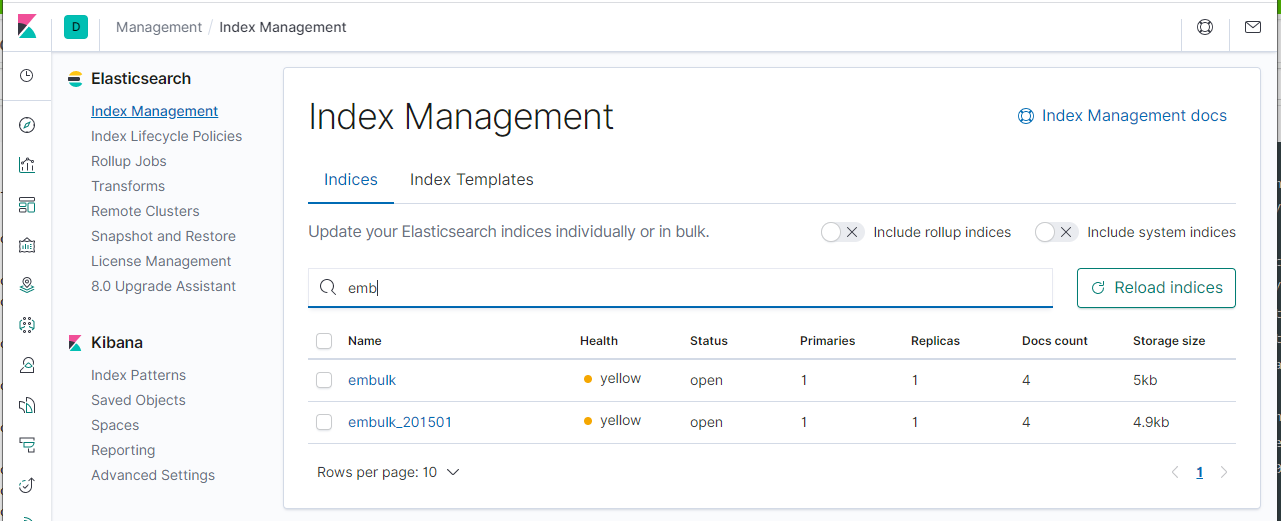
fluentdとのパフォーマンス比較
以下から入手できるCSVファイルのうち、一番サイズが大きいratings.csv(約230MB, 205,832レコード)を取り込んでみた時の所要時間を比較してみます。
https://github.com/livedoor/datasets
環境
Windows10上のVirtualBoxにLinuxを立てて、Elasticsearch, Kibana, Embulk, fluentdを全て同じOS上で稼働させています。
【H/W】
ThinkPad T480
Intel Core i5-8350U 1.70GHz
Memory: 32GB
【HostOS】
Windows10
【Guest】
リソース割り当て: vCPU:6, Memory:12GB
RHEL V7.5
【S/W】
Elasticsearch/Kibana V7.6.2
Embulk V0.9.23
td-agent v3 (fluentd v1)
Embulkでのテスト
構成ファイル
対象のratings.csvをそのまま指定して取り込んでいます。
in:
type: file
path_prefix: /root/embulk/./datasets/ratings.csv
parser:
charset: UTF-8
newline: LF
type: csv
delimiter: ','
quote: '"'
escape: '"'
trim_if_not_quoted: false
skip_header_lines: 1
allow_extra_columns: false
allow_optional_columns: false
columns:
- {name: id, type: long}
- {name: restaurant_id, type: long}
- {name: user_id, type: string}
- {name: total, type: long}
- {name: food, type: long}
- {name: service, type: long}
- {name: atmosphere, type: long}
- {name: cost_performance, type: long}
- {name: title, type: string}
- {name: body, type: string}
- {name: purpose, type: long}
- {name: created_on, type: timestamp, format: '%Y-%m-%d %H:%M:%S'}
out:
type: elasticsearch
index: embulk_test01
index_type: embulk
nodes:
- {host: localhost, port: 9200}
実行
[root@test08 ~/embulk]# date; embulk run test01.yml; date
2020年 6月 21日 日曜日 17:42:22 JST
2020-06-21 17:42:22.703 +0900: Embulk v0.9.23
2020-06-21 17:42:23.861 +0900 [WARN] (main): DEPRECATION: JRuby org.jruby.embed.ScriptingContainer is directly injected.
2020-06-21 17:42:26.637 +0900 [INFO] (main): Gem's home and path are set by default: "/root/.embulk/lib/gems"
2020-06-21 17:42:27.647 +0900 [INFO] (main): Started Embulk v0.9.23
2020-06-21 17:42:27.792 +0900 [INFO] (0001:transaction): Loaded plugin embulk-output-elasticsearch (0.4.7)
2020-06-21 17:42:27.849 +0900 [INFO] (0001:transaction): Listing local files at directory '/root/embulk/./datasets' filtering filename by prefix 'ratings.csv'
2020-06-21 17:42:27.851 +0900 [INFO] (0001:transaction): "follow_symlinks" is set false. Note that symbolic links to directories are skipped.
2020-06-21 17:42:27.853 +0900 [INFO] (0001:transaction): Loading files [/root/embulk/./datasets/ratings.csv]
2020-06-21 17:42:27.911 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=12 / output tasks 6 = input tasks 1 * 6
2020-06-21 17:42:27.939 +0900 [INFO] (0001:transaction): Logging initialized @5715ms
2020-06-21 17:42:28.202 +0900 [INFO] (0001:transaction): Connecting to Elasticsearch version:7.6.2
2020-06-21 17:42:28.202 +0900 [INFO] (0001:transaction): Executing plugin with 'insert' mode.
2020-06-21 17:42:28.202 +0900 [INFO] (0001:transaction): Inserting data into index[embulk_test01]
2020-06-21 17:42:28.212 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0}
2020-06-21 17:42:28.632 +0900 [ERROR] (0023:task-0000): LEAK: ByteBuf.release() was not called before it's garbage-collected. Enable advanced leak reporting to find out where the leak occurred. To enable advanced leak reporting, specify the JVM option '-Dio.netty.leakDetection.level=advanced' or call ResourceLeakDetector.setLevel() See http://netty.io/wiki/reference-counted-objects.html for more information.
2020-06-21 17:42:41.189 +0900 [INFO] (embulk-output-executor-5): Inserted 10000 records
2020-06-21 17:42:41.388 +0900 [INFO] (embulk-output-executor-3): Inserted 10000 records
2020-06-21 17:42:41.412 +0900 [INFO] (embulk-output-executor-0): Inserted 10000 records
2020-06-21 17:42:41.705 +0900 [INFO] (embulk-output-executor-4): Inserted 10000 records
2020-06-21 17:42:41.919 +0900 [INFO] (embulk-output-executor-2): Inserted 10000 records
2020-06-21 17:42:41.931 +0900 [INFO] (embulk-output-executor-1): Inserted 10000 records
2020-06-21 17:42:53.163 +0900 [INFO] (embulk-output-executor-5): Inserted 20000 records
2020-06-21 17:42:53.339 +0900 [INFO] (embulk-output-executor-3): Inserted 20000 records
2020-06-21 17:42:53.521 +0900 [INFO] (embulk-output-executor-4): Inserted 20000 records
2020-06-21 17:42:53.730 +0900 [INFO] (embulk-output-executor-2): Inserted 20000 records
2020-06-21 17:42:53.947 +0900 [INFO] (embulk-output-executor-0): Inserted 20000 records
2020-06-21 17:42:54.191 +0900 [INFO] (embulk-output-executor-1): Inserted 20000 records
2020-06-21 17:43:04.266 +0900 [INFO] (embulk-output-executor-5): Inserted 30000 records
2020-06-21 17:43:04.447 +0900 [INFO] (embulk-output-executor-3): Inserted 30000 records
2020-06-21 17:43:04.453 +0900 [INFO] (embulk-output-executor-4): Inserted 30000 records
2020-06-21 17:43:04.614 +0900 [INFO] (embulk-output-executor-0): Inserted 30000 records
2020-06-21 17:43:04.774 +0900 [INFO] (embulk-output-executor-2): Inserted 30000 records
2020-06-21 17:43:05.082 +0900 [INFO] (embulk-output-executor-1): Inserted 30000 records
2020-06-21 17:43:09.605 +0900 [INFO] (0023:task-0000): Inserted 390 records
2020-06-21 17:43:09.815 +0900 [INFO] (0023:task-0000): Inserted 803 records
2020-06-21 17:43:10.035 +0900 [INFO] (0023:task-0000): Inserted 887 records
2020-06-21 17:43:10.141 +0900 [INFO] (0023:task-0000): Inserted 321 records
2020-06-21 17:43:10.283 +0900 [INFO] (0023:task-0000): Inserted 407 records
2020-06-21 17:43:10.303 +0900 [INFO] (0023:task-0000): Inserted 24 records
2020-06-21 17:43:10.304 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0}
2020-06-21 17:43:10.304 +0900 [INFO] (0001:transaction): Insert completed. 205832 records
2020-06-21 17:43:10.310 +0900 [INFO] (main): Committed.
2020-06-21 17:43:10.311 +0900 [INFO] (main): Next config diff: {"in":{"last_path":"/root/embulk/./datasets/ratings.csv"},"out":{}}
2020年 6月 21日 日曜日 17:43:10 JST
結果: 約48sec
fluentdでのテスト
構成ファイル
<system>
log_level debug
</system>
<source>
@type tail
path /root/embulk/datasets/ratings_test.csv
pos_file /root/embulk/td-agent_pos.txt
tag test01
<parse>
@type csv
keys id, restaurant_id, user_id, total, food, service, atmosphere, cost_performance, title, body, purpose, created_on
types id:integer,restaurant_id:integer,user_id:string,total:integer,food:integer,service:integer,atmosphere:integer,cost_performance:integer,title:string,body:string,purpose:integer,created_on:string
</parse>
</source>
<filter test01>
@type record_transformer
enable_ruby true
auto_typecast true
<record>
@timestamp ${require "date"; DateTime.strptime(record["created_on"] + "+0900", "%Y-%m-%d %H:%M:%S%z").iso8601(3).to_s}
</record>
</filter>
<match test01>
@type elasticsearch
host localhost
port 9200
index_name fluentd_test01
time_key @timestamp
<buffer>
@type memory
flush_thread_count 6
flush_interval 1
</buffer>
</match>
tailでファイルを参照するようにしているので、td-agent起動させた後、cat ratings.csv >> ratings_test.csv というように取り込み対象ファイルにデータを流し込みました。
kibanaやtopで稼働状況を確認して全レコード取り込み完了時刻を目視で確認しました。
結果、約183secくらいかかりました。
結果まとめ
約230MB, 205,832レコードのCSVをElasticsearchに取り込んだ時の所要時間
Embulk: 約48sec
fluentd: 約183sec
あまりチューニングをきちんと行っていないため、両者ともにもう少しパフォーマンス改善の余地はありそうですが、Embulkの方が圧倒的に早いのは間違いなさそうです。