これから異常検知を勉強される初心者、中級者の方のために一問一答集を作ってみました。
実際にあった質問も含まれますが、ほとんどの質問は、私が勉強しながら疑問に思ったことです。
なお、各質問には私の失敗談を添えております。皆さんは私のような失敗をしないよう
祈っております(^^)。異常検知に特化した内容となっておりますので、ご了承ください。
初心者の方向け
勉強の仕方編
Q:異常検知を勉強したいのですが、何から手をつけて良いのか分かりません。
A:書籍を買って読むのがおススメです。
最初、私はネット情報で勉強していました。しかし、それにも限界があります。
ところが、書籍(入門 機械学習による異常検知)を買って読んだところ、かなり知識を
得ることができました。最初から、書籍を買っていれば、一年くらい得することができたのに...
と思うこともあります(^^;
ただ、こちらの本はディープラーニング系は載っていません。しかし、ディープラーニングに通じる
技術がたくさん載っていますので、ディープラーニング系の異常検知をやる方であっても一読する
ことをおススメします。
「ディープラーニング系の異常検知」の書籍は、今のところ見かけたことはありませんが、こちらで
コードを動かしながら学ぶことができるかもしれません。
前処理編
Q:スコアが全然出ません。
A:まずは、可視化してみてください。
異常検知に限らず、データ分析全般にいえることですが、データが与えられたとして分析を
いきなり始めるのではなく、可視化するプロセスは必ずやった方が良いです。
これにより、データ分析の難しさをある程度推測することもできますし、思わぬ気付きも
あるかもしれません。あるいは、データ収集の問題点が浮き彫りになることもあります。
多次元で可視化するのが難しければ、t-sneを使えば可視化できます。最近ではUMAPという
速い手法も出てきています。
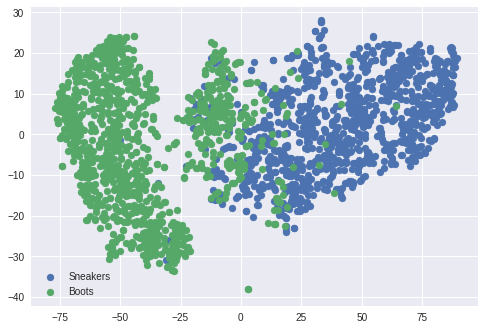
上の例は、Fashin-MNISTのデータを使ってt-sneで可視化した一例です。
上の例のように、いくらか分布が異なれば「異常検知ができそう!」とか見積ることが
できます。あるいは、完全に分布が分かれれば、あえて機械学習を使う必要がなく、
ルールベースの判定法でも良いかもしれません。「機械学習をしなくて良い方法を考える」
という考え方も大切です。
「可視化の次は分析!」といきたいところですが、前処理も十二分に検討しましょう。
0-1変換が良いのか、標準化が良いのか、あるいは対数変換を使うのか...
音の分析では、0-1変換→標準化に変更するだけで、AUC(通常0.5~1.0となる、高ければ
高いほど良い)が0.05上がったこともあります(^^;
あるいは、K近傍法など距離ベースの異常検知手法は、スケール(0~1変換)を揃える
必要があります。これを忘れるだけで、精度が数十%降下することもあります。
手法編
Q:ディープラーニングがカッコイイから、とりあえずディープラーニングにデータを突っ込めばいいんでしょう?
A:初手、ディープラーニングはやめた方が良いです。時間が溶けます。
初手オートエンコーダは非常に有効だと思います。オートエンコーダは学習も安定していて
ある程度のスコアも保証してくれます。
それ以外のディープラーニング系は調整に時間がかかるため、最後の手段として試した方が良いです。
結論として初手は、Isolation Forest(IF)やLOF(もしくはオートエンコーダ)がおススメです。
実は、ディープラーニングが得意とする画像系のデータであっても、従来からある手法(IFやLOF)を
使うことで、ある程度のスコアを出すこともできます。もちろん、こららの手法はテーブルデータ
(表形式のデータ)でもかなりのスコアを出してくれます。これらの手法の良いところは、パラメータ
調整が少ないところです。また、計算時間の短さもメリットが大きいです。
失敗談として、ディープラーニング系の手法をテーブルデータに適用したお話しです。
今やディープラーニングは、画像系をはじめテーブルデータでもSOTA(スコアが最も高い)を
達成するようになってきました。下の表はテーブルデータにディープラーニング系の異常検知
手法(GOAD)を適用したものです。
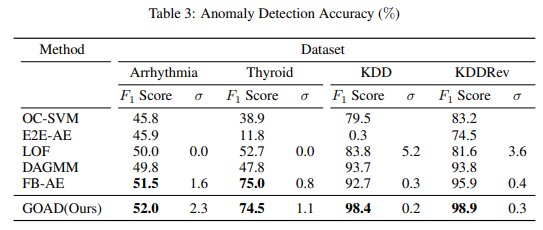
(表はClassification-Based Anomaly Detection for General Dataより引用)
しかし、この手法は使ってみると分かるのですが、パラメータ依存性が非常に高く、再現性を
担保することも難しいです。(アフィン変換をランダムに行うのですが、このランダム性が
非常にやっかい)
従って、論文に書いてあるようなスコアを出すためには安定する乱数や、パラメータを見つける
必要があります。さらに、論文では出てこないような調整ノウハウも存在することがあり、
多くの時間が溶ける可能性があります。
使えるコスト・時間・人員を考えて手法を選んだ方が良いです。これらが潤沢にあれば
ディープラーニング系でも良いですし、厳しければIFやLOFを検討しましょう。
ハードウェア編
Q:エッジ処理で異常検知をしたいです。おススメのハードウェアはありますか?
A:価格ならラズパイ4、使いやすさならJetsonNano、安定性ならPCです。
価格でいうとラズパイ4が圧倒的です。5千円強のお値段でディープラーニングが
ある程度の速度で動きます。下の例は異常検知しながら、異常部分を可視化した
例です。
本当にやりたかったのはコレ!Faster-Grad-CAMで異常部分の可視化。
— shinmura0 @ 4/11参加者募集中 (@shinmura0) March 9, 2020
〇を正常として学習させました。(余分な線、欠けた線、異物は「異常」です。)リアルタイムで「可視化」と「異常検知」が同時にできるなんて夢のよう...(^^)。 pic.twitter.com/66BFAc8Efz
なお、このデモはラズパイ3を使ってMobileNetV2を動かしています。
ラズパイ4で動かすと9FPSくらい出ます。
ただ、ラズパイのセットアップは非常に面倒くさいです。最近は@karaage0703 さんが
こちらでshellコードを公開してくれているため、非常に楽になっています。
JetsonNanoは使いやすいです。価格は1万円強とすこし高いですが、JetCardという
非常に使いやすいパッケージを用意してくれているため、すぐに使えるようになります。
速度はラズパイ4より少し速いです。
これらのハードウェアは価格面、サイズの面で非常に優秀です。しかし、電源の安定性や
熱の問題に細心の注意を払わないと、シャットダウンしてしまうことがあります。
従って、どうしてもダウンしてマズイところはPCを使うのが妥当です。
と書いてきましたが、**一番のおススメはやはりラズパイ4です。**価格も優れていますが、
実績もあるハードウェアなので、信頼性もある程度高いです。私の経験では、2か月
工場で作動させっぱなし(中では機械学習が動いていた)にしても、問題なく動き
ました。
中級者の方向け
勉強の仕方編
Q:書籍を読んだり、コードを動かしたりしたのですが、飽きました。面白い勉強方法はありませんか?
A:Kaggleなどのコンペに出てみましょう。あるいは、論文を読んでも面白いかもしれません。
コンペに出るのは学びが多いです。メリットは以下のとおりです。
- 前処理から始まり、コードの管理、手法の検証など一連の作業を学ぶことができる
- 論文を読む習慣が付く、そして読む速度が速くなる
- 仮説を考える習慣が身に付く
- 素晴らしい方とお知り合いになれる
実は最後が非常に重要で、コンペに出るとライバルと呼べる方と知り合えるかもしれません。
ときには、その方とチームを組みディスカッションや論文の紹介など、非常に貴重な情報交換が
できることもあります。また海外の強い人の動向も知ることができ、英語でディスカッション
することもできます。
一人で勉強していては、ゆっくりとした速度でしか成長できません。やはり、仲間やライバルが
いると成長する速度は速く(体感10倍くらい(^^))、お互いに良い刺激を与えることが
できます。
論文読み単独でも面白いときはありますが、やはり論文を読むのは非常に体力が必要です。
従って、これだけやっていても長続きせず、断続的に読むことになる可能性もあります。
しかし、コンペに出れば締め切りが決まっている分、読む速度も速くなりますし、
モチベーションが上がります。コンペ×論文読みセットがおススメです。
前処理編
Q:精度が100%になりました。これ以上やることはないですか?
A:念のため、コードに間違いがないか検証しましょう。
仕事やコンペでデータをいじっていて、精度100%が出たら、その結果は疑ってかかるべきです。
前処理や後処理でミスしている可能性が高いです。
一番手っ取り早い検証方法は、異常スコアをグラフにするべきです。
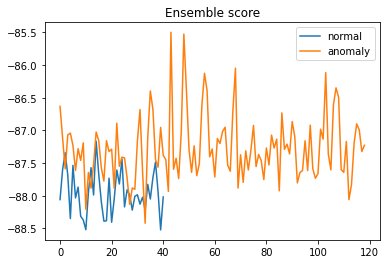
上記は異常スコアの一例です。
スコアがこのように入り乱れていると、ある程度信頼できます。
ところが、スコアが完全に二分されていると、前処理や後処理でミスしている可能性が高いです。
ディープラーニングを使っている場合は、下記のように可視化してみて、ちゃんと異常部分を
見ているのか検証してみても良いでしょう。
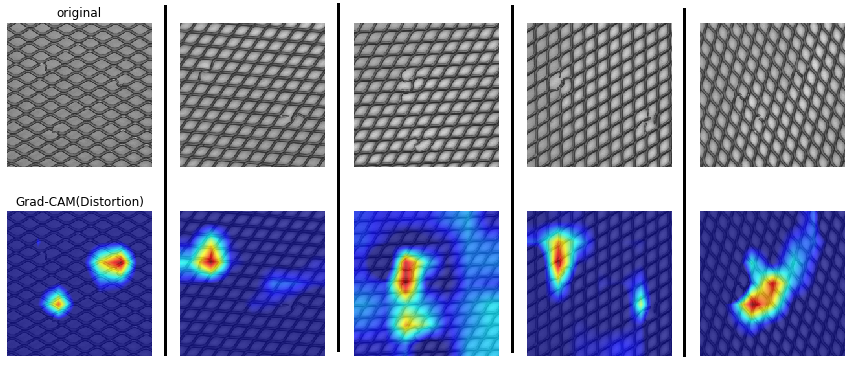
私がミスったのは、画像を回転させる前処理を入れたときに、画面の明るさが変わってしまい、
画像の異常部分ではなく、画像の明るさで異常を判定していたときがありました。
一瞬「AUC1.0、ヨッシャー!」となりましたが、幻の結果となりました(^^;
「精度100%は都市伝説」くらいに考えた方が良いです。
手法編
Q:どうしても精度が伸びません。貪欲に最新手法を試すべきでしょうか?
A:今使っている手法でもう少し粘ってみましょう。
異常検知の分野でも、日々最新手法が登場しています。しかし、それらの手法は精度が少し
改善した報告がほとんどです。これらの論文は再現性が担保されていないものも多く、皆さんが
お持ちのデータに適合するかも不明瞭です。データ数が少ないと性能を発揮しないかもしれません。
つまり、最新手法に変えたからといって、うまくいく可能性は非常に低いです。
2~3年に一度、ブレイクスルーとなるような論文も登場しますが、それはいずれ噂となり、皆さん
の耳にも届いてくると思いますので、最新論文に手を出すのはしばらく待ちましょう。
よって、今の手法でもう少し粘るのが時間的に一番有効です。
具体的には、
- 今の手法でアンサンブル学習してみる
- 違う手法を混ぜてアンサンブル学習してみる(私の経験では、AUC0.05上がったこともあります。)
- 学習の仕方を変えてみる。(例えば、自己教師あり学習の異常データ生成方法を変えてみるなど)
あとは以下のような前処理が効くときがあります。
- ぼけた画像を破棄する
- 正常画像を刻んで細かく検査させる
- 正常データをいくつかのグループに分けて異常検知する
私の経験談として、一年前に深層距離学習(ArcFace)を使った異常検知を試しました。
その後、深層距離学習の最新手法をいくつか試しましたが、精度は上がりませんでした。
さらに、深層距離学習以外の手法にも手を出しましたが、精度が上がっても少し、中には
再現しなくて精度が下がったものもありました。
深層距離学習の最新手法「CircleLoss」を異常検知で使ってみた。
— shinmura0 @ 7/11参加者募集中 (@shinmura0) May 5, 2020
特長にあった、パラメータのロバスト性・高精度は出なかった(T T)。ただ、前述したように学習速度は異常に速く、エッジ学習で活躍しそう(^^)。
※データは #DCASE 2020 Task2 Fan id=0https://t.co/e8AB5WDTfx pic.twitter.com/4fG0O2hvNf
つまり、最新手法を試したからといって、精度が劇的に上がることは稀です。
最新手法が出るたびに、それらに手を出していたら、時間が溶けます。
ハードウェア編
Q:ラズパイで異常検知をして、かつ**極限まで速度を上げたいです。**おススメの手法はありますか?
A:ハードウェアの進化を待つか、職人技(TensorFlow lite)を使いましょう。
ラズパイ4を使えば、モデルのサイズによりますが、10FPSくらいの速度は出ます。
これだけでも非常に使えるシーンはあるかと思います。ただ、それ以上の速度となると
結構険しい道が待っているかもしれません。
TensorFlow liteはモデルを量子化することで、速度が大体2倍になるらしいです。
「らしい」というのは私が使ったことないためです(^^;。この手のモデル変換は結構
ハマることが多く、時間が溶けることが多いです。私は、OpenVINOというIntel製のモデル変換
技術を使ったことがありますが、かなり難儀しました。結局、@PINTO さんのお力を借りて
モデルを若干変更することで何とか変換できました。私一人では無理でした。
つまり、量子化などのモデル変換は、使える人が限られています。かなりの職人技です。
高度な知識・経験が要求されます。これらを使いたい人は、上記の記事や@PINTO さんの
レポジトリなどを参考にしながらチャレンジしてみてください。
最近、JETSON XAVIER NXが発売されました。ラズパイ4が登場して1年も経たないうちに
新たなハードウェアが登場したことになります。速度はJetson Nanoの2倍速いという噂も
聞こえてきます。このようにハードウェアの進化は早く、少し待てば高速なハードウェアが
出てくるかもしれません。高速化したいけど、急がない人はハードウェアの進化を待っても
良いかもしれません。
おわりに
ディープラーニングに対し、かなり懐疑的な内容になってしまいましたが、ディープラーニングは
調整を頑張れば、かなりのスコアを出すことが期待できます。そして、使いこなせるようになると
もはや調整が必要なくなる(勘所が分かる)瞬間が来ます。ここまでくると、こっちのものです。
私の場合、ArcFace+自己教師あり学習が使い慣れていますが、ArcFace側のパラメータをいじる
ことはありません。いじるところはエポック数くらいです。また、ISやLOFのパラメータ調整
もほとんど行いません。従って、一度お馴染みの手法を確立してしまえば、どんな手法を使うのか
頭を悩ませる時間は無くなります。
一番言いたかったのは、新たな案件が来たとして、未知の手法を使うのではなく、まずは
使い慣れた手法でとことん粘ってみましょうということです。結局、新たな手法を使っても、
使い慣れた手法で粘った方が良いスコアが出ます。手法をころころ変えていると、「データでは
なく、手法を見てる」に過ぎないです。
分析で一番時間をかけているのは、学習のさせ方・前処理の工夫・データのクレンジング・
ドメイン知識の勉強など、データの裏側を探索する作業がほとんどです。そこを頑張れば、
時にはAUCで0.2~0.3くらい底上げすることもできますので、辛抱強くデータを見てください。