1. はじめに
世の中にはDeepLearningの学習済みモデルを公開してくださっている方がたくさんいらっしゃいます。本記事は、そのうちのいくつかをラズパイ4で動かしてみて、いったいどれくらいの速度で動くのかを検証したものです。
計測対象モデルとして、Mediapipe および TensorFlow.js、TensorFlow Lite models で公開されている学習済みモデルを利用させて頂きました。またモデル実行フレームワークとしては、モバイル向けに整備が進む TensorFlow Lite (C++) を用いました。
計測にあたっては、公開されているモデルをそのまま動かすだけでなく、一般的な高速化手法である下記の2手法を両方試し、その効果も計測しました。
-
[1] モデルをint8量子化する方法
演算精度に多少目をつぶる代わりに、NEON等のSIMD演算器による並列処理の並列度をさらに高めることで高速化するものです1。量子化については @PINTO さんが公開されている この記事 がとても参考になります。今回の計測でも、@PINTO さんが GitHubで公開されている量子化モデルを使用させて頂いています。
-
[2] GPUを使う方法
DeepLearningといえばGPUです2。TensorFlow Liteには演算処理をGPUにオフロードすることができる GPU Delegate 機能があり、この機能を有効にした時と無効時との速度差を比較計測しました。ラズパイ4で TensorFlow Lite GPU Delegate を動かす方法については前回記事をご参考ください。
また、ちょうどこのタイミングで Raspberry Pi OS 64bit版 がリリースされ3、ラズパイ4が備える 64bit アーキCPU の本来の性能が出せる状態になりました。良い機会なので、OSがこれまでの Raspbian OS(32bit) から Raspberry Pi OS (64bit) へ変わったことによる速度性能差も比較計測しました。
加えて、主にGPU性能比較のために、ラズパイ4と同じシングルボードコンピュータである Jetson Nano でも同様に計測を行いました4。
今回の計測条件をまとめると下記のようになります。
| 条件 | 項目 |
|---|---|
| フレームワーク | TensorFlow Lite 2.2 C++ API |
| ターゲット環境 | (1) ラズパイ4(Raspbian 32bit) |
| (2) ラズパイ4(Raspberry Pi OS 64bit) | |
| (3) Jetson Nano (L4T 64bit) | |
| 推論精度 | (1) fp32 (GPU Delegate有効時は fp16) |
| (2) int8 (GPU Delegate無効時のみ) | |
| GPU使用有無 | (1) GPU Delegate 有効 |
| (2) GPU Delegate 無効 |
2. (本題の前に)基礎体力計測
TensorFlow Lite の計測を始める前に、ラズパイ4およびJetson Nanoが備える CPU とGPUの基本性能を簡単に見ておきます。
2.1. CPU性能
UnixBench で整数演算性能と浮動小数演算性能を計測します。
$ git clone https://github.com/kdlucas/byte-unixbench
$ cd byte-unixbench/UnixBench
$ ./Run
ラズパイ4(Raspbian 32bit) の性能を 1 としたときの、ラズパイ4(Raspberry Pi OS 64bit) および Jetson Nano の相対性能は下記のようになりました。

OSを32bitから64bitに変えるだけで、整数演算性能が 1.5 倍に向上するようです。64bitアーキCPUの本領発揮といったところでしょうか。浮動小数点演算については変化はありませんでした。
CPU演算性能だけをみると、ラズパイ4のほうがJetson Nanoより少し速いですね。
2.2. GPU性能
次にGPU性能を比較するために、glmark2 を用いて OpenGLESの描画性能を計測します。
$ git clone https://github.com/glmark2/glmark2.git
$ cd glmark2
$ ./waf configure --with-flavors=x11-glesv2
$ ./waf
$ sudo ./waf install
$ glmark2-es2

ラズパイOSを64bitに更新すると、描画性能も 1.25倍に向上するようです。OSが変わってもGPU性能は変わらないと予想していたので意外な結果でした。64bit 版の OpenGLES では、GPUを動かすためのコマンド列を (CPUが) より効率的に生成することができるようになったのでしょうか。
一方で、Jetson Nanoはさらに10倍速 です。さすがGPUベンダが作ったボードだけあって、圧倒的パワーを感じます。
以上の結果から、ラズパイ4は 64bit OSに更新することで、CPU/GPU とも性能向上することが確認できました。またGPU性能はJetson Nanoがラズパイの10倍速いこともわかりました。
3. TensorFlow Lite 速度計測
CPUとGPUの基礎体力測定が終わったところで、いよいよTensorFlow Liteの性能計測に移ります。世の中に公開されているモデルの中から私が個人的に気になった7種類のモデルをピックアップし、冒頭記載の条件で性能計測を行った結果についてまとめます。
なお計測結果は下記のような棒グラフで示していきますが、はじめにグラフの見方を説明しておきます。

横軸として、ラズパイ32bit, ラズパイ64bit, Jetson Nano それぞれに対して、青/赤/緑 の3本の棒グラフがあります。この3本はそれぞれ下記条件での計測結果であり、棒が長いほうが速度性能が高く(=短時間で処理が完了する)、フレームレートが高いことを示します。
| 色 | 説明 |
|---|---|
| 青 | オリジナルのfloatモデルで推論実行したときの速度[fps] |
| 赤 | int8量子化モデルで推論実行したときの速度[fps] |
| 緑 | GPU Delegate有効にしたときの速度[fps]。モデルはオリジナルのfloatモデルを使用 |
またここでいうfpsは、純粋に TensorFlow Lite の invoke() にかかった時間の逆数で求まるフレームレートです。実際の推論動作には、TensorFlow Lite 実行前に画像リサイズ等の前処理や、推論結果の描画処理が必要となりますが、このグラフには含まれていません。前処理や後処理は合計で 10ms 程度で完了することが多く、計測結果の大勢に影響はないと判断したためです。
3.1 BlazeFace
mediapipeで公開されている、高速動作を目的とした顔検出モデルです。
顔のバウンダリ領域だけでなく、目・鼻・口のキーポイント位置も検出できるので、およその顔の向きもあわせて推定することができます。後述の Facemesh のような他のモデルを実行するための前処理として顔領域を切り出す目的でも使用されます。

このモデルをラズパイおよびJetson Nanoで実行したときの処理速度は下記となりました。

-
計測結果から読み取れること
- ラズパイOSを32bitから64bitに変えるだけで、1.25倍速になる
- ラズパイではint8量子化すると、float モデル比で2倍速くなる
- ラズパイではint8量子化すると、125[fps]の速度で推論可能となる
- ラズパイのGPU Delegateは遅い
- Jetson Nano では、int8 量子化と GPU Delegateの速度が互角
もともとBlazefaceは軽量モデルである上に、さらに量子化することで、前処理や描画結果も含めて 一般的なDisplayの表示周波数である60fps に到達 させることができます。
ラズパイ4で実際に動いている様子:
@PINTO03091 さんの量子化済みblazefaceモデルをお借りして、ラズパイ4で顔検出 60fps 到達できた!
— terryky (@terryky1220) May 16, 2020
(カメラ処理・描画処理込み)
『スピードに生きる』 pic.twitter.com/e4uZwy6zIv
3.2 Facemesh
上記Blazefaceで切り出した顔画像を入力として、さらに表情を構成する468個のキーポイント位置を推定することができるモデルです。mediapipeで公開されています。
キーポイント位置にあわせて他の顔画像とさしかえて別人に変身したり、表情の動きに合わせてキャラクタを動かすようなエフェクトが実現できるようになります。
↓左側の顔画像上に表示されているメッシュが推論結果です。右側は別人の顔画像をこのメッシュに合わせて変形させたものになります。これを左側の顔画像の位置に重ねて描画すれば別人に変身できる、というわけです。

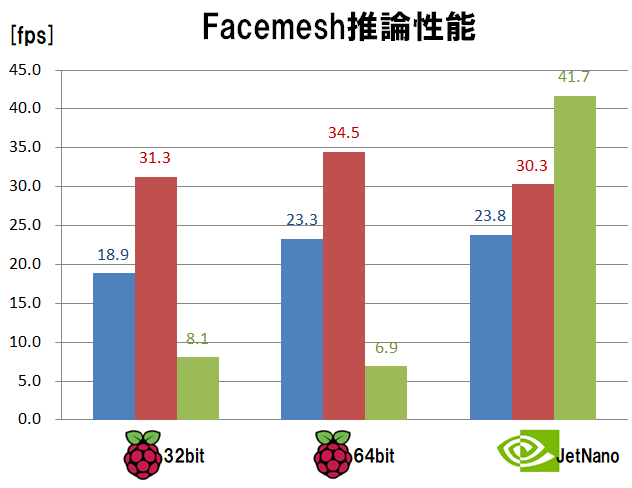
処理速度の計測結果は下記となりました。
Blazefaceによる顔領域検出とFacemeshによるメッシュ推定の2つモデルの実行時間合計の値です。
-
計測結果から読み取れること
- ラズパイOSを32bitから64bitに変えるだけで、1.1~1.2倍速になる
- ラズパイではint8量子化すると、float モデル比で1.5倍速くなる
- ラズパイではint8量子化すると、34.5[fps]の速度で推論可能となる
- ラズパイのGPU Delegateは遅い
- Jetson Nano では、GPU Delegateが最も速い
計測結果は Blazeface と同じ傾向となりました。
この派手な見た目で楽しいモデルを、前処理や描画結果も含めて 約30fps でサクサクと動かすことが出来ることがわかりました。
ラズパイ4で実際に動いている様子:
ラズパイ4単体で
— terryky (@terryky1220) May 27, 2020
1) H264 Videoデコード
2) TensorFlow Lite (facemesh) で表情姿勢推定
3) 画像メッシュ変形でフェイスマスク描画
を一気通貫処理してみるテスト。
思ってたよりサクサク動きました。 pic.twitter.com/4XTFzBggrk
3.3 3D Handpose
引き続きmediapipeで公開されているモデルです。手・指の姿勢形状を3次元的に推定することができます。比較的安定して手形状を推測できるので見た目にも楽しいです。
実際のユースケースでは、このモデルで手の姿勢形状推定する前に、Palm検出用の別モデルを使って手領域画像の切り出しを行うことが多いですが、ここでは手領域切り出しが終わった前提で(手がカメラに大写しになるように位置調整して)Handpose単体モデルの性能をみることにします。
ラズパイ4で実際に動いている様子:

処理速度の計測結果は下記となりました。
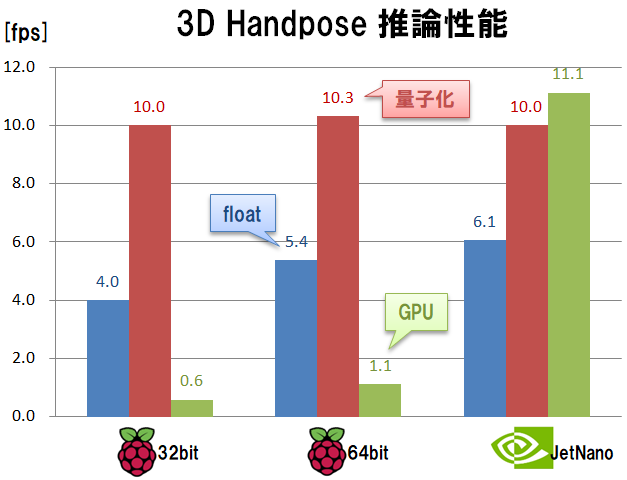
グラフから読み取れる性能傾向はこれまでと同じです。量子化モデルが速く、GPU Delegateは振るいません。このモデルもラズパイ4で、前処理や描画結果も含めて 約10fps で動かすことが出来ます。
3.4 Posenet
TensorFlow.jsで公開されているモデルです。人間の各関節位置を推定することができます。複数の人間の姿勢を同時に推定することもできます。
ラズパイ4で実際に動いている様子:

処理速度の計測結果は下記となりました。
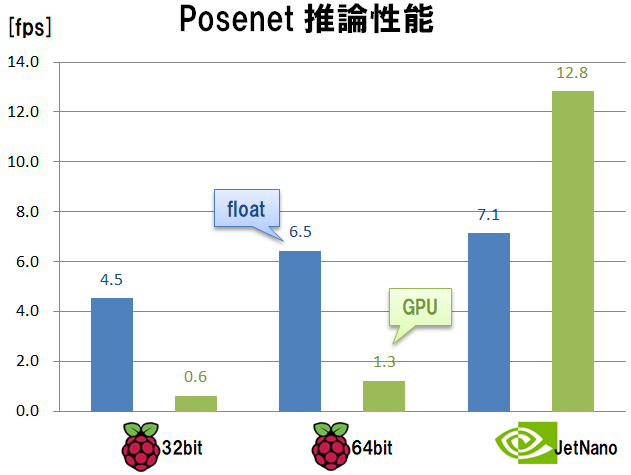
あいにくこのモデルは量子化モデルで動かせていません。オリジナルのfloatモデルではラズパイ4で 約6fps で動きました。量子化モデルで動かすともっと高速に動かせるようになるのではないかと思います。
3.5 Hair segmentation & recoloring
mediapipeで公開されている、髪の毛領域を画素単位で抽出することができるモデルです。抽出した領域に任意の色を乗算することで、仮想的に髪の毛をカラーリングして遊ぶことができます。

処理速度の計測結果は下記となりました。
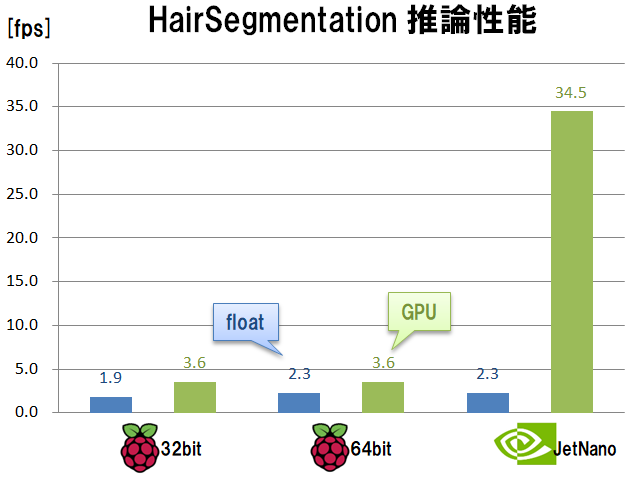
このモデルは他のモデルと速度傾向が大きく異なります。GPU Delegate有効時の処理速度が圧倒的に速いです。Jetson Nano での GPU Delegate 性能がとびぬけているだけでなく、ラズパイ4でも唯一GPU Delegate有効時の性能がCPU処理の性能を上回る珍しいモデルになっています。
これは、このモデルがGPUDelegateを使うことを前提にしたカスタムOperationを含んでいるためだと推測されます。
GPU Delegate が活用できるケースとはいえ、ラズパイ4だと 約3fps なので、リアルタイムにぬるぬる動かせるというわけにはいきません。ですが、静止画に対して髪の毛の色をいろいろ変えて遊んでみるといったユースケースには十分に使えると思います。
ラズパイ4で実際に動いている様子:
この hair segmentation をラズパイ4の TFLite GPUDelegate で試してみた。
— terryky (@terryky1220) June 2, 2020
秒3コマくらいの速度だけど、GPU性能が Jetson Nano の 1/10 しかないから妥当かな。
ちなみに、ラズパイ4で GPUDelegateのほうが CPU より速いモデルはこれが初体験。(約2倍速)
それだけカスタムOpのCPU実行は重いのね。 https://t.co/Ah0Jewc3Q3 pic.twitter.com/cyTy1GTbG8
3.6 3D Object detection
これもmediapipeで公開されているモデルです。物体の位置姿勢を3次元的に検出することができるという、にわかには信じがたいことが出来てしまいます。
今回使ったモデルでは「椅子」の3次元位置姿勢を検出することができるように学習されています。
ラズパイ4で実際に動いている様子:
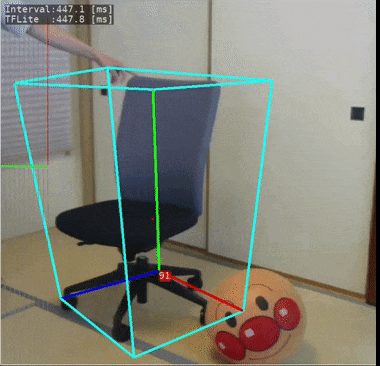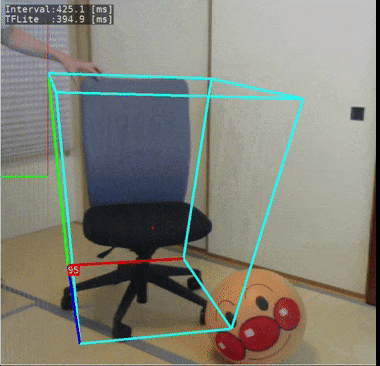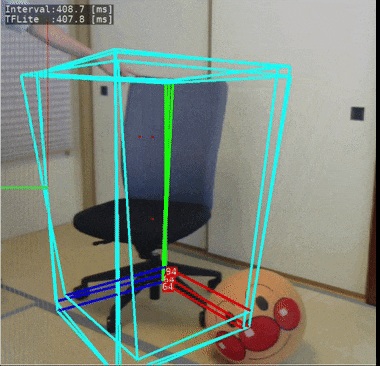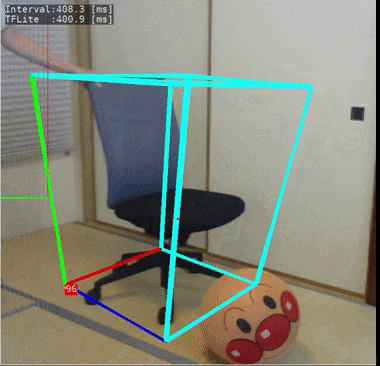
処理速度の計測結果は下記となりました。

速度傾向はいつものパターンに戻ります。量子化モデルが速く、GPU Delegateは振るいません。
ラズパイ4で約3fpsで動きます。動きの速い物体だと検出処理が追い付かないですが、比較的ゆっくり動かす場合には有用だと思います。ただし、椅子以外の物体にも反応することも多く、正しく認識させるにはコツがいるような印象です。
3.7 Artistic styletransfer
TensorFlow Lite models で公開されているモデルです。好きな写真を、ムンクなどの特徴的な画家の画風に変換することができるというモデルです。普通に撮影した写真が全く異なる印象に変化するので見ていて楽しいです。

処理速度の計測結果は下記となりました。
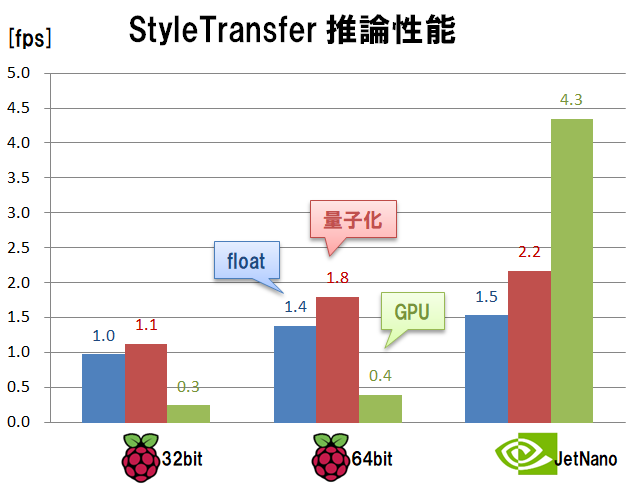
量子化モデルでも重いです。ラズパイ4だと 1fps です。さすがにリアルタイム処理は難しいですが、逆にたった1秒で画調変換できるので、たとえば静止画撮影するカメラのエフェクト機能といった用途には十分使えるのではないでしょうか。
4. まとめ
前節で示したグラフを、縦軸のスケールを揃えて一覧表示してみるとこのようになります。
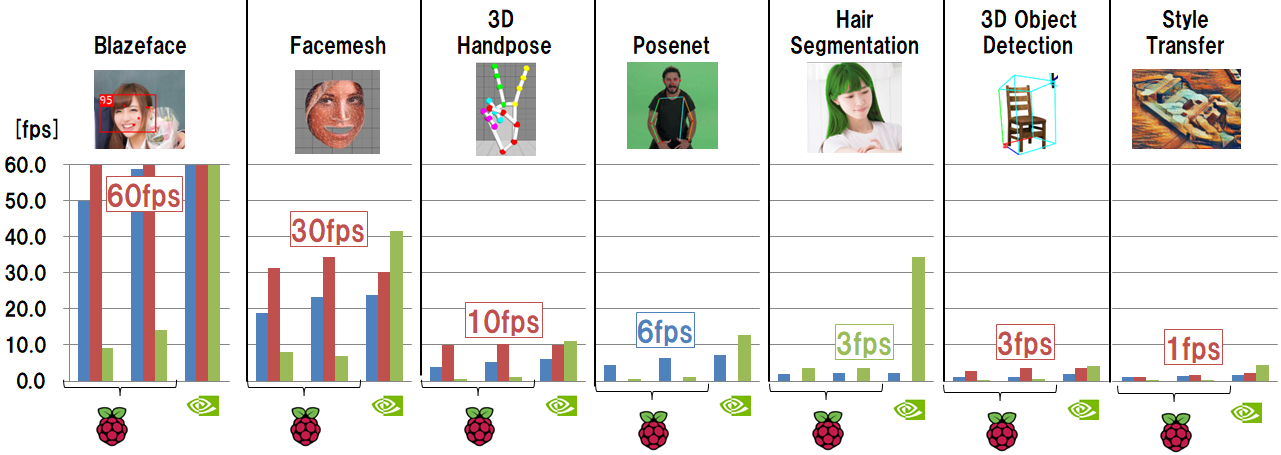
モデルによって処理速度はまちまちですが、ラズパイ4でTensorFlow Lite を動かす場合に最も処理速度が速くなるのは、下記の場合であることがいえると思います。
- 64bit OS 環境で、
- 量子化したモデル を用い
- GPUではなく CPUで推論 する5
速度向上という観点からだけみれば、ラズパイ4ではGPU Delegateは活用できない という結果となりました。
GPU Delegate の性能がふるわない原因として、そもそもラズパイ4のGPU性能があまり高くないことに加え、ラズパイ4、JetsonNanoとも、OpenCL をサポートしていない ことも要因として考えられます。GPU Delegate は OpenCL 経由でGPUを叩こうとしますが、OpenCL が使えない環境では代替策として OpenGLES の Compute Shaderを使う実装になっています。GPU Delegate は OpenCL バックエンドのほうが速度性能が高いことが分かっています。残念ながらラズパイ4でOpenCLが使えるようになるのは期待薄なので、これに関してはあきらめるしかないかなと思っています。
参考)Coral Edge TPU Dev Board で TensorFlow Lite GPU Delegate V2 (OpenCL) を試す
さらに、GPU Delegate は、(スマホ用にチューニングされている)内部パラメータをいじることで速度性能が大きく変化することもわかっていますが、今回は素直にオリジナルのパラメータのままで計測しています。
参考)TensorFlow Lite GPUDelegate(OpenGLES)を手軽に高速化
ちなみにラズパイ4とJetson Nano の GPU Delegate 同士で速度比較すると、JetsonNanoはラズパイのほぼ10倍速になっています。これは本記事冒頭で比較したOpenGLESの基礎体力性能比にそった値となっており、納得できる値だと思います。
なお、上の一覧グラフを見て、「ラズパイ4と比べてJetson Nanoの速度性能が意外にのびないな」、という印象を持たれる方がいらっしゃるかもしれません。冒頭でもふれましたが、今回の計測は Jetson Nano でもTensorFlow Lite GPU Delegate を用いており、Jetson専用フレームワークである TensorRT を使っていません。TensorRTを使えばさらに高速化できると思いますので、ご注意ください。
5. 最後に
世の中に公開されている学習済みモデルをラズパイ4で動かしてみました。ラズパイ4単体でも、思っていた以上にサクサク動くものもありとても驚きました。
ラズパイ4のGPUはあまり強力ではないので、動作速度を求めるならモデルを量子化してCPU実行するのが有効だということもわかりました。もちろん、量子化に伴う演算精度劣化やCPUを全力で動かすことによる消費電力・発熱の問題には注意が必要です。
DeepLearningは進化がきわめて速いので、今回計測した結果も、時間がたてば全く違う結果になるかもしれません。つまり本記事内容の賞味期限はそう長くないかもしれません。
ですが、それよりなにより、DeepLearningという花盛りな技術を使ったいろんな実験(遊び)が、ラズパイのような安価な機材と、広く公開されているオープンソースだけで手軽にできてしまうことがこよなく楽しいと思っています。
6. ソースコード、その他
6.1. 計測プログラムのありか
今回計測に用いたソースコードは下記にあります。
https://github.com/terryky/tflite_gles_app
6.2. 環境情報など
6.2.1 Raspberry Pi4 (Raspberry Pi OS 64bit)
pi@raspberrypi:~$ uname -a
Linux raspberrypi 5.4.42-v8+ #1319 SMP PREEMPT Wed May 20 14:18:56 BST 2020 aarch64 GNU/Linux
GL_VENDOR: Broadcom
GL_RENDERER: V3D 4.2
GL_VERSION: OpenGL ES 3.1 Mesa 19.3.2
6.2.2 Raspberry Pi4 (Raspbian 32bit)
pi@raspberrypi:~$ uname -a
Linux raspberrypi 4.19.118-v7l+ #1311 SMP Mon Apr 27 14:26:42 BST 2020 armv7l GNU/Linux
GL_VENDOR: Broadcom
GL_RENDERER: V3D 4.2
GL_VERSION: OpenGL ES 3.1 Mesa 19.3.2
6.2.3 Jetson Nano (Linux for Tegra 64bit)
jetson@jetsonnano:~$ uname -a
Linux jetsonnano 4.9.140-tegra #1 SMP PREEMPT Tue Nov 5 13:43:53 PST 2019 aarch64 aarch64 aarch64 GNU/Linux
GL_VENDOR: NVIDIA Corporation
GL_RENDERER: NVIDIA Tegra X1 (nvgpu)/integrated
GL_VERSION: OpenGL ES 3.2 NVIDIA 32.2.3
-
量子化モデルを使うことによる精度劣化については今回評価対象外としています。 ↩
-
ラズパイ4単体での性能検証なので、[Coral EdgeTPU] (https://coral.ai/products/accelerator)等の後付けアクセラレータは用いません。 ↩
-
2020/6/1現在、Raspberry Pi OS 64bit はβ版の位置づけです。正式リリースが待ち遠しいです。 ↩
-
今回の Jetson Nanoの計測結果はあくまでもラズパイ4との比較用であり、JetsonNano本来の性能を使い切ったものではありません。Jetson Nano の性能を引き出すには NVIDIA 純正フレームワークである[TensorRT] (https://developer.nvidia.com/embedded/jetpack) を使うべきですが、ここでは、ラズパイ4と同じようにTensorFlow Lite GPU Delegate を使っています。 ↩
-
例外的に HairSegmentation のように GPU Delegate を使ったほうが速いモデルも存在する。 ↩