1. 概要
前回、Coral EdgeTPU DevBoard 上で、TensorFlow Lite GPU Delegate (OpenGLESバックエンド) を試しました。が、その結果は「GPU Delegate を有効にすると逆に3倍遅くなる」という悲しいものでした。
「んなアホな」と軽くツッコミをいれながら GPU Delegate の内部実装を調べたところ、ちょろっと手を入れるだけで下表の数値まで性能改善できることが分かったので、記事としてまとめます。
| 比較項目 | GPU Delegateなし | GPU Delegateあり(改善前) | GPU Delegateあり(改善後) |
|---|---|---|---|
| 処理時間 | 280[ms] | 914[ms] | 655[ms] |
(速くできたとはいえ、まだまだ遅いです。継続調査して新情報出てくれば随時追記します)
2. 状況整理
・Coral EdgeTPU DevBoard (November 2019)
・TensorFlow r2.0 ブランチ
・ネットワークモデルは 公式ドキュメントからリンクされている、Posenetの tflite ファイル

Posenetのネットワークモデルは、下図の通り、Conv2D と DepthWiseConv2D が交互に並ぶ比較的シンプルな構造をしています。ノードの数は全部で31個です。

GPU Delegate (OpenGLES) 実行時は、このノード1つ1つに ComputeShader のカーネルプログラムが1つずつ割り当てられ、これらのカーネルプログラムは順にGPUで実行されます。ノード間のデータ授受は OpenGLES の SSBO (Shader Storage Buffer Object) で実装されています。
この ComputeShader は、GPU Delegate 内の下記コードでキックされます。この関数を1回呼び出すごとに、カーネルが1つ=ノード1つがGPU上で実行されます。
ですので、この関数の前後で時間を計測すれば、ネットワークモデルを構成するノード毎の処理時間(どのノードが遅いのか)を計測することができます。
(注)この関数は非同期関数なので、性能計測時は glFinish() 等でGPU実行完了を待つ必要があります。
Status GlProgram::Dispatch(const uint3& workgroups) const {
if (workgroups.x == 0 || workgroups.y == 0 || workgroups.z == 0) {
return InvalidArgumentError("Invalid workgroups");
}
RETURN_IF_ERROR(TFLITE_GPU_CALL_GL(glUseProgram, id_));
return TFLITE_GPU_CALL_GL(glDispatchCompute, workgroups.x, workgroups.y,
workgroups.z);
}
下表は、このようにしてノードごとの処理時間を計測した結果です。
ノードによって処理時間の大小がありますが、ネットワーク後半の Conv2D の処理時間が長い傾向にあることが見て取れます。
| Node番号 | Ope Type | 処理時間[ms] |
|---|---|---|
| 1 | Conv2D | 17.83 |
| 2 | DepthWiseConv2D | 44.10 |
| 3 | Conv2D | 20.00 |
| 4 | DepthWiseConv2D | 22.59 |
| 5 | Conv2D | 20.46 |
| 6 | DepthWiseConv2D | 43.04 |
| 7 | Conv2D | 39.43 |
| 8 | DepthWiseConv2D | 12.18 |
| 9 | Conv2D | 25.74 |
| 10 | DepthWiseConv2D | 23.05 |
| 11 | Conv2D | 53.44 |
| 12 | DepthWiseConv2D | 7.22 |
| 13 | Conv2D | 32.78 |
| 14 | DepthWiseConv2D | 13.13 |
| 15 | Conv2D | 64.51 |
| 16 | DepthWiseConv2D | 13.12 |
| 17 | Conv2D | 64.63 |
| 18 | DepthWiseConv2D | 13.11 |
| 19 | Conv2D | 64.55 |
| 20 | DepthWiseConv2D | 13.12 |
| 21 | Conv2D | 64.53 |
| 22 | DepthWiseConv2D | 13.15 |
| 23 | Conv2D | 64.48 |
| 24 | DepthWiseConv2D | 4.78 |
| 25 | Conv2D | 45.75 |
| 26 | DepthWiseConv2D | 8.23 |
| 27 | Conv2D | 90.25 |
| 28 | Conv2D | 3.05 |
| 29 | Conv2D | 4.47 |
| 30 | Conv2D | 3.63 |
| 31 | Conv2D | 3.61 |
| 合計 | 913.97 |
3. Conv2D カーネルの確認
上表において、最も処理時間の長いノードである、「27番の Conv2D ノード」について中身を詳しく見ていきます。
このノードは、下図の通り、(1x9x9x1024)の入力テンソルに対し、(1024x1x1x1024)のウェイトを重畳してバイアス加算した後、Relu6で[0, 6]クランプし、(1x9x9x1024)のテンソルを出力する処理を行います。
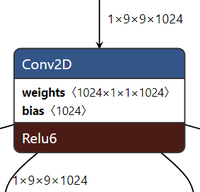
もう少し直感的に理解するために図を描くと、下記のようになります。
入力は 9x9サイズの画像1024枚で、下記1~4の処理を行い、9x9サイズの画像を1024枚出力します。
1)入力画像から1画素を取り出してきて重みと乗算。これを1024枚の画像に対して行い、積を合算
2)1)の結果にバイアス値を加算、[0, 6] クランプした結果を1つの画素値として出力
3)1)~2)の処理を 9x9 画素に対して行う
4)3)の処理を、1024個の異なる重みパラメータに対して行う
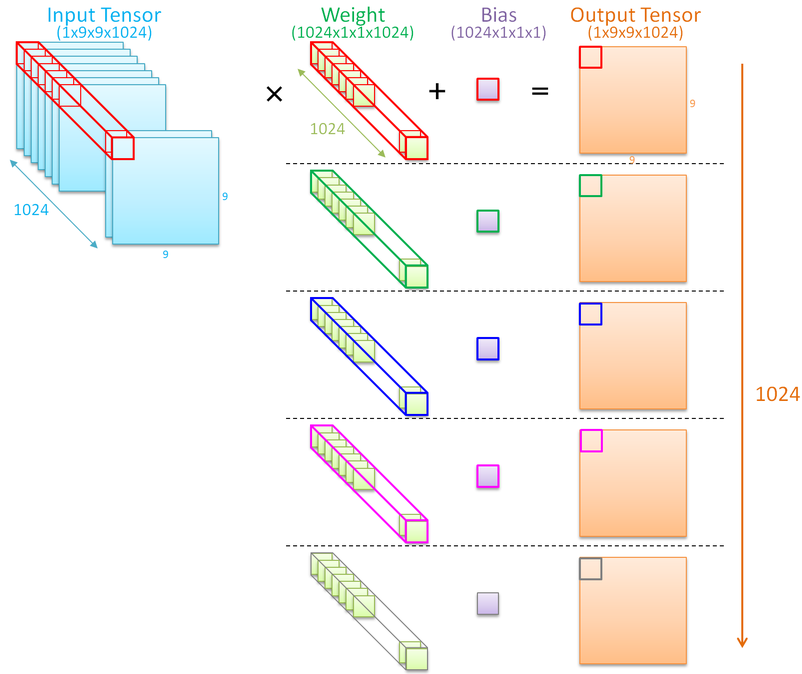
1画素の値を決めるのに、1024個の画素値と、1024個の重みを読み出す必要があるので、なんとなくメモリネックになりそうなことは直感的に感じとれると思います。
ただ、メモリアクセスはランダムアクセスではなくアドレス順にシーケンシャルアクセスすればよいので、うまくはまればそれほど心配する必要はないかもしれません。
3.1 Compute Shader での処理
このConv2D処理を、GPU Delegate は ComputeShader としてどのように実装しているのかをみてみます。
下記は、GPU Delegate が Conv2D用に動的生成するシェーダコード(を見やすいように少し改変したもの)です。
# version 310 es
layout(local_size_x = 8, local_size_y = 4, local_size_z = 8) in;
layout(std430) buffer;
precision highp float;
layout(binding = 1) writeonly buffer B1 { vec4 data[]; } output_data_0;
layout(binding = 0) readonly buffer B0 { vec4 data[]; } input_data_0;
layout(binding = 3) readonly buffer B3 { vec4 data[]; } bias;
layout(binding = 2) readonly buffer B2 { vec4 data[]; } weights;
uniform float clip; /* 6.0 */
uniform int input_data_0_h; /* 9 */
uniform int input_data_0_w; /* 9 */
uniform int output_data_0_h; /* 9 */
uniform int output_data_0_w; /* 9 */
uniform int src_depth; /* 256 */
uniform int weights_h; /* 256 */
uniform int weights_w; /* 4 */
uniform int workload_x; /* 9 */
uniform int workload_y; /* 9 */
uniform int workload_z; /* 256 */
void main() {
ivec3 gid = ivec3(gl_GlobalInvocationID.xyz);
if (gid.x >= workload_x || gid.y >= workload_y || gid.z >= workload_z) {
return;
}
/* convolution */
highp vec4 value_0 = vec4(0);
highp vec4 result0 = vec4(0);
vec4 f;
for (int l = 0; l < src_depth; ++l) {
vec4 input0 = input_data_0.data[gid.x + input_data_0_w * (gid.y + input_data_0_h * (l))];
f = weights.data[0 + weights_w * (l + weights_h * gid.z)];
result0[0] += dot(input0, f);
f = weights.data[1 + weights_w * (l + weights_h * gid.z)];
result0[1] += dot(input0, f);
f = weights.data[2 + weights_w * (l + weights_h * gid.z)];
result0[2] += dot(input0, f);
f = weights.data[3 + weights_w * (l + weights_h * gid.z)];
result0[3] += dot(input0, f);
}
/* add bias */
vec4 b = bias.data[gid.z];
result0 += b;
/* Relu6 */
value_0 = result0;
value_0 = clamp(value_0, vec4(0.0), vec4(clip));
output_data_0.data[gid.x + output_data_0_w * ( gid.y + output_data_0_h * ( gid.z))] = value_0;
}
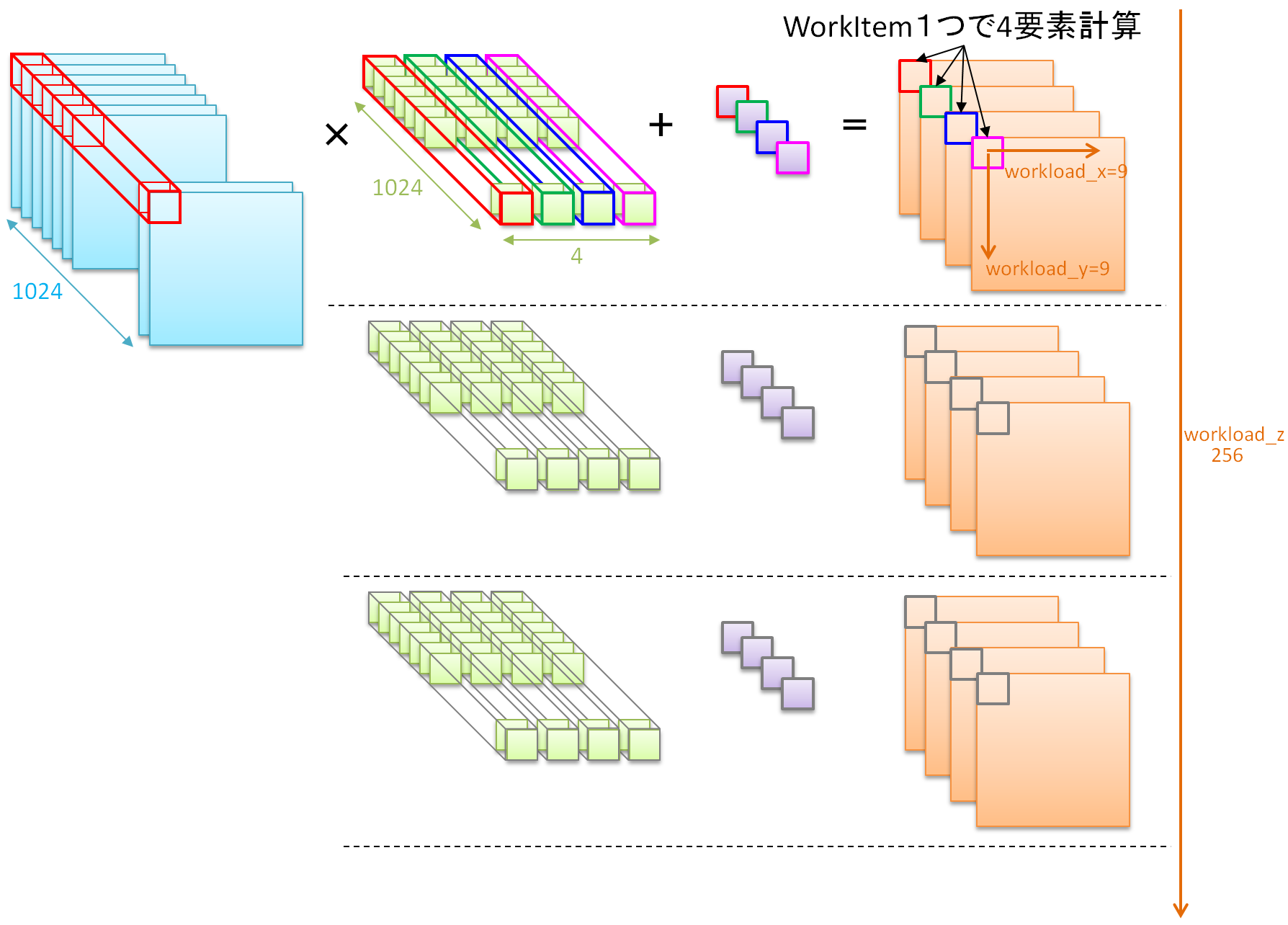
上記シェーダでやっている処理も絵で描いてみます。(下図)
ComputeShader では、GPUが得意な4次元ベクトル処理を利用し、カーネルプログラムを1回動かせば4画素分の値が同時に計算されるコードになっています。このカーネルを、画像サイズ(9x9)ぶんだけ実行し、さらに重みを変えながら256回実行すれば、すべての演算を行うことができます。
シェーダコード内に出てくる workload_x, workload_y, workload_z という変数は、この「カーネルを何回実行する必要があるか」の数値であり、今回の例では、(workload_x, workload_y, workload_z) = (9, 9, 256) となります。
一方、GPUは内部に複数の演算器を搭載しているので、カーネルを並列動作することで高速化を図ることができます。この時、一定数をグループとしてまとめて同時実行することで、グループ間でキャッシュを共有したりカーネル間で細かく同期をとったりするときに便利になるので、カーネル実行時にはワークグループサイズを指定することになります。
この「ワークグループサイズをいくらにするか」は、処理時間を決めるのにとても重要な要因となります。すごく荒っぽく言えば、ワークグループサイズが小さすぎるとGPUの演算器があまって速度向上しないし、逆に大きすぎると共有メモリが溢れてメモリアクセスが遅くなってしまいます。最適サイズは演算器量とメモリ量、メモリアクセスレイテンシに依存するため、アプリケーションは、GPUによって異なる値を設定しないといけません。
それでは、いろんなGPU上で動くことを想定しているTFLite GPU Delegateでは、どうやってこのワークサイズを決定しているかというと、「GPUごとに最適と思われる値をテーブルとして持っている」となります。
例えば、下記のようなコードがあります。
このコードの意味するところは、
「GPUがQualcommのAdrenoで、workload の大きさがいくらなら、workgroupサイズはこの値」
「それ以外のGPUは、どんなGPUかよくわからないけど、とりあえずこの値」
という、Adrenoだけを特別扱いしたパラメータが列挙されています。
ソースコードの他の場所には、「GPUがMALIの場合は、、、」というコードも見つかります。
Status GenerateCode(const GenerationContext& ctx,
GeneratedCode* generated_code) const final {
(略)
uint3 workgroup = uint3(16, 16, 1);
if (ctx.gpu_info->type == GpuType::ADRENO) {
if (dst_depth >= 2) {
workgroup = uint3(8, 8, 2);
}
if (dst_depth >= 4) {
workgroup = uint3(4, 8, 4);
}
if (dst_depth >= 8) {
workgroup = uint3(4, 4, 8);
}
if (dst_depth >= 32) {
workgroup = uint3(4, 4, 16);
}
if (dst_depth >= 64) {
workgroup = uint3(2, 8, 16);
}
} else {
if (dst_depth >= 2) {
workgroup = uint3(16, 8, 2);
}
if (dst_depth >= 4) {
workgroup = uint3(16, 4, 4);
}
if (dst_depth >= 8) {
workgroup = uint3(8, 4, 8);
}
if (dst_depth >= 32) {
workgroup = uint3(8, 4, 8);
}
if (dst_depth >= 64) {
workgroup = uint3(8, 4, 8);
}
}
このような実装方針のため、GPU Delegate の性能の良し悪しは、この最適値パラメータテーブルの網羅性に強く依存することになります。このテーブルに考慮されている環境だと性能がでるし、考慮されてない環境だと性能が出ません。
私がいま動かしている Coral DevBoard では、残念ながら考慮対象外で、このテーブルのデフォルト値である (8, 4, 8) というサイズで動いていました。ComputeShaderソースコード先頭に出てくる layout(local_size_x = 8, local_size_y = 4, local_size_z = 8) in; という記述がそれです。
このサイズは Coral DevBoard に最適化された値でもなんでもない値なので、性能改善するためには、Coral DevBoard 用に最適サイズを設定する必要があるのではないかと推測しました。
4. WorkSizeを変えたときの処理時間変化
4.1 Conv2D 単体での処理時間変化
Conv2D カーネル単体に対して、ワークグループサイズを変えた時に処理時間がどう変化するかを計測する簡単なベンチアプリを作って計測しました。
下記が結果のグラフです。
ワークグループサイズを (1, 1, 1) から (8, 4, 8) までいろいろ変化させながら、処理時間がどう変化するかを計測したものです。
横軸は Work Load Z 値で、入力画像枚数を変えた時の処理時間変化を見るために計測したものです。今回は 1024 の値を見ます。
なお、グラフ線のうち点線のものは、ComputeShader実行時の演算精度を mediump (fp16) に変えて実行したものです。実線は highp (fp32) 実行時の処理時間です。highp よりも mediump のほうが遅い理由は別途調べる必要がありますが、ここは highp だけをみることにします。
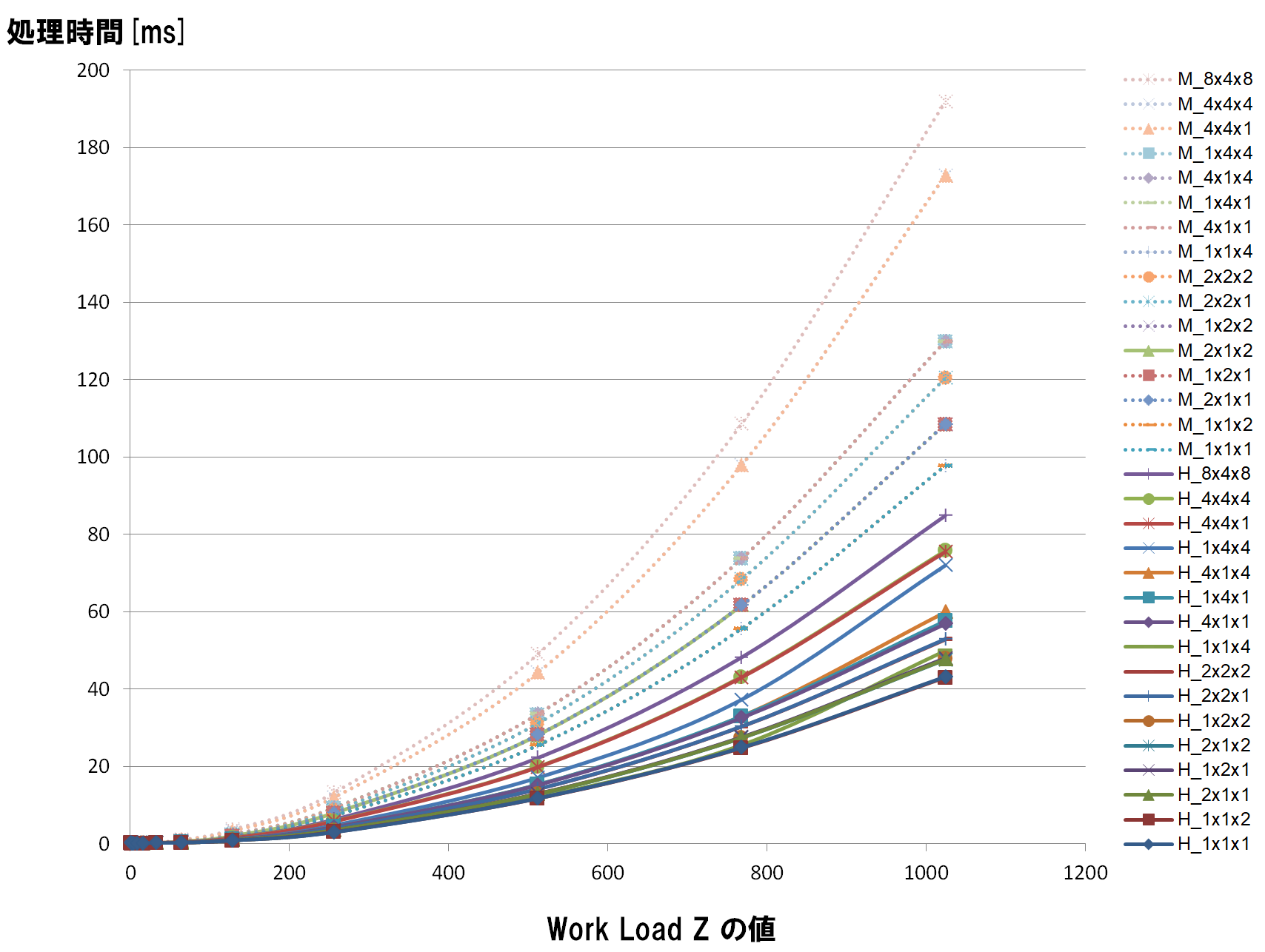
同じカーネルでも、ワークフローサイズの大きさで処理時間が大きく変化することが見て取れます。
このなかから最適値をみつけるべく、いろいろ条件を変えて計測してみましたが、結論からいうと、ワークサイズは (1, 1, 1) が最も早いという(若干拍子抜けな)結果になりました。
Coral DevBoard では、GPUの演算器を眠らせてでも、メモリアクセスの局所性を高めたほうが性能が向上する、ということが読み取れる結果になりました。
4.2 PoseNet 全体の処理時間変化
ワークサイズ (1, 1, 1) が最適値ということが分かったので、PoseNet全体をワークサイズ(1, 1, 1)で動かしたときの処理時間を計測しました。
※「ワークサイズ (1, 1, 1) が最適値」というのは、あくまでも 27番目のノードだけを見た時の最適値であって、本来ならPoseNetを構成する各ノードごとの最適値を求める必要があります。
下表がその結果です。
| Node番号 | Ope Type | 処理時間(改善前)[ms] | 処理時間(改善後)[ms] |
|---|---|---|---|
| 1 | Conv2D | 17.83 | 17.14 |
| 2 | DepthWiseConv2D | 44.10 | 42.35 |
| 3 | Conv2D | 20.00 | 19.14 |
| 4 | DepthWiseConv2D | 22.59 | 21.66 |
| 5 | Conv2D | 20.46 | 18.75 |
| 6 | DepthWiseConv2D | 43.04 | 42.29 |
| 7 | Conv2D | 39.43 | 35.69 |
| 8 | DepthWiseConv2D | 12.18 | 11.76 |
| 9 | Conv2D | 25.74 | 18.98 |
| 10 | DepthWiseConv2D | 23.05 | 22.34 |
| 11 | Conv2D | 53.44 | 36.46 |
| 12 | DepthWiseConv2D | 7.22 | 6.90 |
| 13 | Conv2D | 32.78 | 19.92 |
| 14 | DepthWiseConv2D | 13.13 | 12.51 |
| 15 | Conv2D | 64.51 | 38.55 |
| 16 | DepthWiseConv2D | 13.12 | 12.44 |
| 17 | Conv2D | 64.63 | 38.50 |
| 18 | DepthWiseConv2D | 13.11 | 12.53 |
| 19 | Conv2D | 64.55 | 38.46 |
| 20 | DepthWiseConv2D | 13.12 | 12.53 |
| 21 | Conv2D | 64.53 | 38.51 |
| 22 | DepthWiseConv2D | 13.15 | 12.51 |
| 23 | Conv2D | 64.48 | 38.55 |
| 24 | DepthWiseConv2D | 4.78 | 4.51 |
| 25 | Conv2D | 45.75 | 22.18 |
| 26 | DepthWiseConv2D | 8.23 | 7.63 |
| 27 | Conv2D | 90.25 | 43.07 |
| 28 | Conv2D | 3.05 | 2.12 |
| 29 | Conv2D | 4.47 | 2.80 |
| 30 | Conv2D | 3.63 | 2.63 |
| 31 | Conv2D | 3.61 | 2.58 |
| 合計 | 913.97 | 655.96 |
性能改善効果の高いノードや、ほとんど効果のないノードがありますが、 特に、ネットワーク後半の、Depthが深くなる Conv2D のノードで性能改善効果が高く、1.5倍~2.0倍の高速化効果を得ることができました。
5. 最後に
ComputeShaderのカーネルコードに一切手を入れることなく、カーネル実行時のワークサイズを変更するだけで、処理時間を1.5倍高速化することができました。
逆に言えば、与えるパラメータがちょっと異なるだけで処理性能が大きく変わるGPUプログラミングの繊細さを痛感しました。
「GPU使うと速くなるんでしょ」という単純な話ではなく、「TFLite GPU Delegate はそのまま使っても性能が出ない可能性があるので、環境にあわせて自分でネチネチとチューニングしないといけないよ」という態度で構える必要がありそうです。
1.5倍速くなったとはいえ、まだまだ遅いので、引き続き調査する予定です。
何かお気づきの点がありましたら、コメント等いただけましたら励みになりますので、よろしくお願いします。