今更ながら、畳込みニューラルネット(CNN)の基本技術を比較します。
やりたいことは、どの技術が一番効果があるのか数値化します。
以下の流れでやっていきます。
(基本のCNN) → (Resnetの各技術を追加していく) → (+最先端技術)
基本のCNNに、Resnetに出てくる技術を追加しながら、分類精度の上昇幅を比較します。
コードはkerasで書いています。
Resnetとは
2015年に登場したモデルで、層を飛ばす仕組みを作ることで、深い層を作っても
学習可能なモデルとなりました。ディープラーニング業界では、斬新なアイデアで
革命を起こしました。
詳しくは以下の記事をご覧下さい。
https://qiita.com/koshian2/items/343a55d59d8fdc112661
データのダウンロード
使うデータはCIFAR-10です。これは、32×32サイズの画像が入ったデータセットで、
10クラスに分類されています。kerasでは簡単にダウンロードできます。
from keras.datasets import cifar10
from keras.utils import to_categorical
# データの読み込み
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
基本のCNN
ベースとなるCNNを構築します。
kerasだと簡素で良いですね。
# cnnの学習
input_ = Input(shape=(32, 32, 3))
c = Conv2D(64, (1, 1), padding="same")(input_)
c = Activation("relu")(c)
c = Conv2D(64, (3, 3), padding="same")(c)
c = Activation("relu")(c)
c = Conv2D(64, (3, 3), padding="same")(c)
c = Activation("relu")(c)
c = Conv2D(64, (3, 3), strides=2)(c)
c = Activation("relu")(c)
c = Conv2D(128, (3, 3), padding="same")(c)
c = Activation("relu")(c)
c = Conv2D(128, (3, 3), padding="same")(c)
c = Activation("relu")(c)
c = Conv2D(128, (3, 3), strides=2)(c)
c = Activation("relu")(c)
c = Conv2D(256, (3, 3), padding="same")(c)
c = Activation("relu")(c)
c = Conv2D(256, (3, 3), padding="same")(c)
c = Activation("relu")(c)
c = Conv2D(256, (3, 3), strides=2)(c)
c = Activation("relu")(c)
c = Flatten()(c)
c = Dense(10, activation='softmax')(c)
MaxPoolingは使わずに、畳込み層でstride=2として、画像をどんどん小さくしていきます。
最適化手法は、Adamを使っています。
学習結果↓
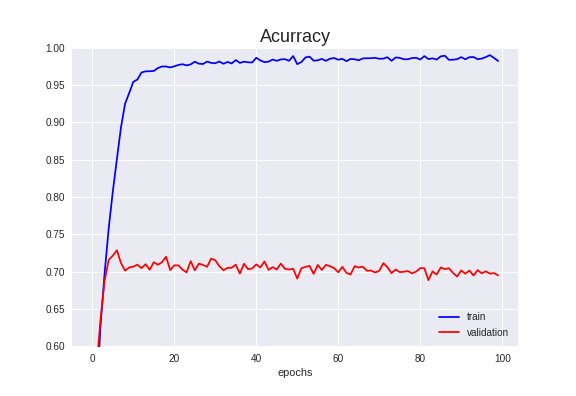
trainの精度はほぼ100%ですが、validationの精度から大きく乖離し、過学習しています。
Validation Accuracyは72.88%でした。
各技術の追加
これより、各技術を追加します。
基本のCNNと同じ条件にするために、畳込み層は10層で固定し、epochも100で固定します。
その他、全結合層や正則化層などは無制限です。
Data Augmentationの効果
まずは、基本のCNNにデータの水増しを追加します。
kerasではImageDataGeneratorが標準装備されています。
datagen = ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
水増しの際に、画像の回転、上下左右の平行移動、水平方向の反転を加えています。
学習結果↓
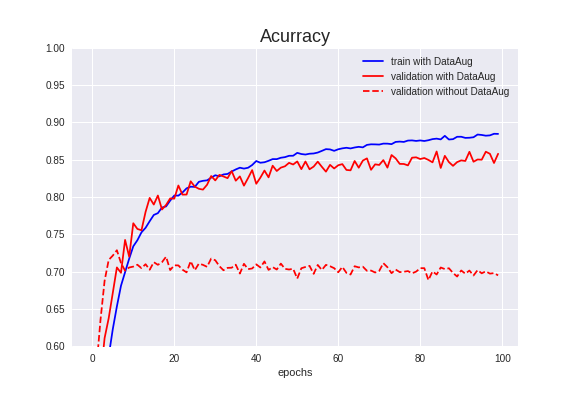
Validation Accuracyは86.09%で、基本のCNNより**13.21%**アップしました。
trainデータとvalidationデータの精度が近づき、過学習が抑えられているのも分かります。
Batch Normalizationの効果
前項(Data Augmentation)のモデルにBatch Normalization(BN)を追加します。
BNは、今や無くてはならない技術で、バッチ内で標準化する層です。CNN以外でも多く使われています。
c = Conv2D(16, (3, 3), strides=2)(c)
c = BatchNormalization()(c)
c = Activation("relu")(c)
ポイントは、活性化関数の前にBNを置くということです。
学習結果↓
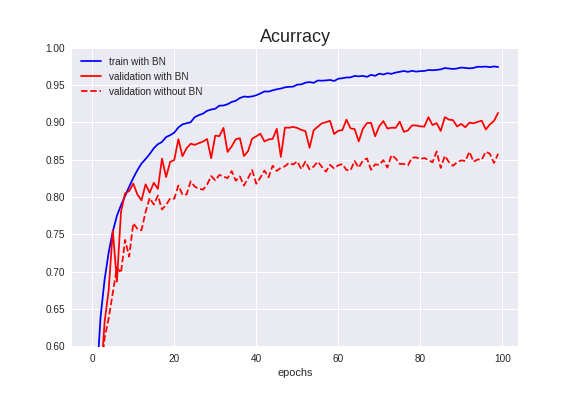
Validation Accuracyは91.24%で、前項より**5.15%**アップしました。
学習も早くなり、精度もアップし、良いことずくめです。
実は、今回の試みでこれが一番良い精度となりました。Data AugmentationとBNで十分な精度が出ます。
Res blockの効果
前項(Batch Normalization)のモデルにRes blockを追加します。
Res blockは冒頭でご紹介したように、層を飛ばす仕組みを持っており、Resnetの目玉になっています。
def resblock(x, filters, kernel_size):
x_ = Conv2D(filters, kernel_size, padding='same')(x)
x_ = BatchNormalization()(x_)
x_ = Activation("relu")(x_)
x_ = Conv2D(filters, kernel_size, padding='same')(x_)
x = Add()([x_, x])
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
学習結果↓
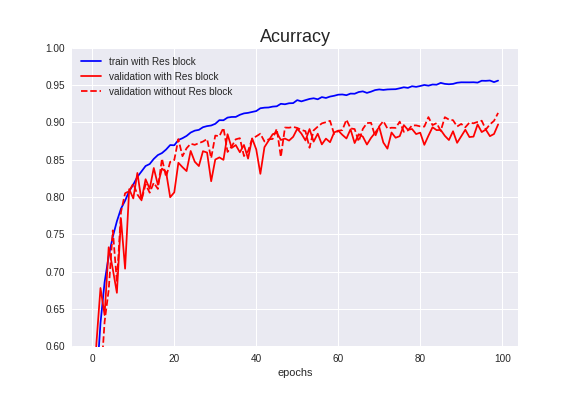
Validation Accuracyは89.71%で、前項より1.53%ダウンしました。
ダウンした理由を考察してみると、Res blockは、勾配消失問題を解消するために考案された仕組みです。
そのため、層が深いモデル(例えば20層くらい)でないと良い作用が出ず、逆に層が浅いモデルでは悪い作用が出るのかもしれません。
Global Average Poolingの効果
Global Average Pooling(GAP)は全結合層で使われる技術で、CNNの出力を横並びにするのではなく、
加算してしまう方法です。これによりパラメータ数を一気に減らすことができます。
精度アップというよりは、計算時間の短縮化を狙った技術です。
詳細は以下の記事をご覧ください。
https://qiita.com/mine820/items/1e49bca6d215ce88594a
# c = Flatten()(c)
c = GlobalAveragePooling2D()(c)
Flattenの代わりに使います。
※ 12/14コード修正
学習結果↓
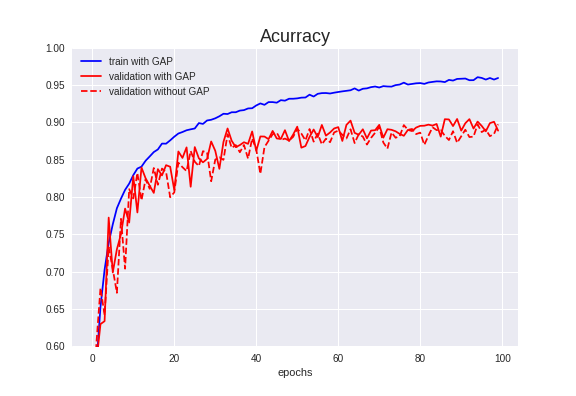
Validation Accuracyは90.44%でした。
前項より**0.73%**アップしました。
念のため、学習時間も記載します。
Flatten↓
Epoch 100/100
391/390 [==============================] - 52s 133ms/step
GAP↓
Epoch 100/100
391/390 [==============================] - 51s 131ms/step
GAPにすると、1エポック当たり1秒早くなりました。
dropoutの効果
ここからは、Resnetの論文にない技術を追加します。
dropoutは過学習を防ぐ目的で使われます。見方を変えると、アンサンブル学習の側面があります。
dropoutを追加すると、Validation Accuracyの上昇が期待されます。
c = Conv2D(64, (3, 3), strides=2)(c)
c = BatchNormalization()(c)
c = Activation("relu")(c)
c = Dropout(0.2)(c)
学習結果↓
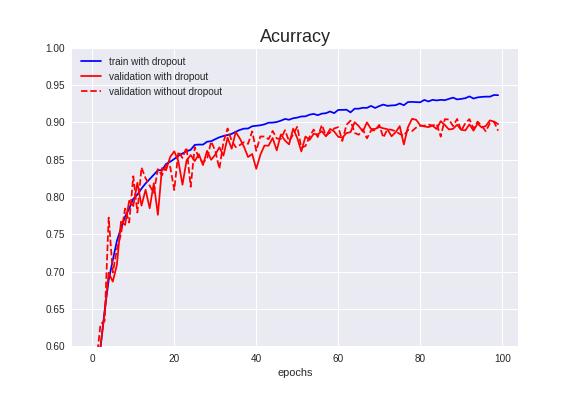
Validation Accuracyは90.46%で、前項より0.02%アップしました。これは、もはや「上昇しなかった」と言ってよいでしょう。
BNを使うとdropoutは不要との報告もあり、今回はBNを既に追加しているため、あまり効果がなかったかもしれません。
mixupの効果
mixupは、最近使われ始めているDataAugmentationの一手法です。
以前、記事にも書いたことがあります↓。
・浅いNNでmixupを使ってみた(塩尻MLもくもく会#6)
https://qiita.com/shinmura0/items/e51565960648dccf8486
今回も、mixupのコードは@yu4uさんのものを借用しました。
従来のData Augmentationにmixupを追加します。
学習結果↓
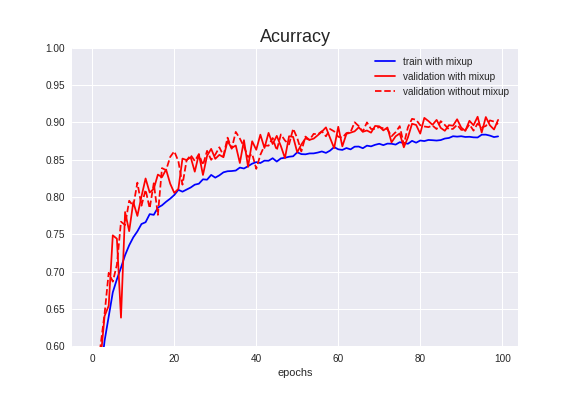
Validation Accuracyは90.70%でした。
前項より**0.24%**アップしました。
Amsgradの効果
論文をまともに読んでいませんが、Adamの改良版「Amsgrad」を使ってみます。
Amsgradを詳しく知りたい方は、こちらをご覧ください。
kerasだと標準装備されています。
optimizer=Adam(amsgrad=True)
「amsgrad=True」とするだけです。これは便利!
学習結果↓
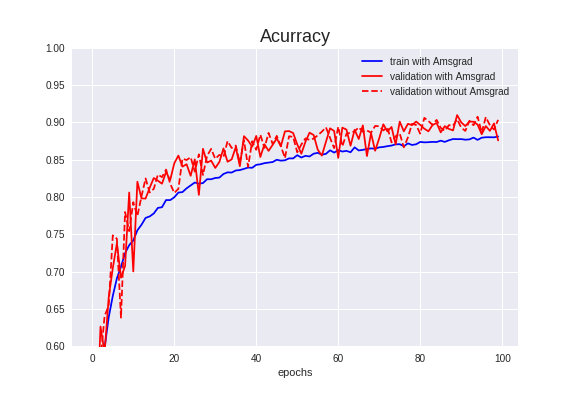
Validation Accuracyは90.96%でした。
前項より**0.26%**アップしました。
まとめ
以上の効果をまとめると、以下のようになります。
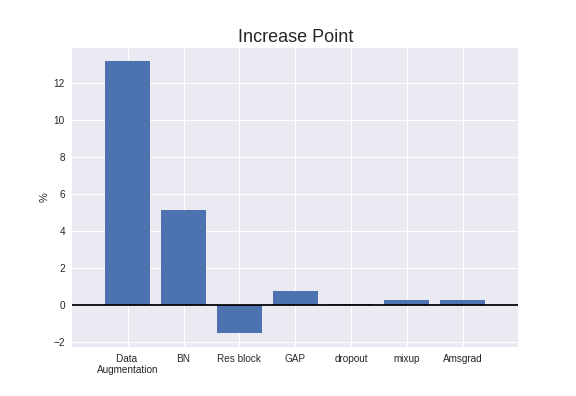
厳密にいうと、各技術を加える順番によって上昇幅も変わりますし、相乗効果もありますし、
1回しか試行していないので、ここだけで判断するのはちょっと乱暴ですが、今回の調査では
「Data Augmentation」が一番効果的であることが確認されました。
畳込みニューラルネットワークでどうしても精度が上がらないときは、データをもっと集めるか
Data Augmentationを使うと良いかもしれません。
音ファイルでもやってみました。(9/10追記)
最終形態のコード
全ての技術を取り入れたコードを以下に示します。
Colaboratoryを使えば2時間くらいで、学習が完了します。
※12/14 コード修正(GlobalAveragePooling2Dの部分を修正させていただきました。)
from keras.layers import Input, Conv2D, GlobalAveragePooling2D, BatchNormalization
from keras.layers import Add, Activation, Flatten, Dense, Dropout
from keras.models import Model
from keras.optimizers import Adam
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import matplotlib.pyplot as plt
# mixup
class MixupGenerator():
def __init__(self, X_train, y_train, batch_size=128, alpha=0.2, shuffle=True, datagen=None):
self.X_train = X_train
self.y_train = y_train
self.batch_size = batch_size
self.alpha = alpha
self.shuffle = shuffle
self.sample_num = len(X_train)
self.datagen = datagen
def __call__(self):
while True:
indexes = self.__get_exploration_order()
itr_num = int(len(indexes) // (self.batch_size * 2))
for i in range(itr_num):
batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2]
X, y = self.__data_generation(batch_ids)
yield X, y
def __get_exploration_order(self):
indexes = np.arange(self.sample_num)
if self.shuffle:
np.random.shuffle(indexes)
return indexes
def __data_generation(self, batch_ids):
_, h, w, c = self.X_train.shape
_, class_num = self.y_train.shape
X1 = self.X_train[batch_ids[:self.batch_size]]
X2 = self.X_train[batch_ids[self.batch_size:]]
y1 = self.y_train[batch_ids[:self.batch_size]]
y2 = self.y_train[batch_ids[self.batch_size:]]
l = np.random.beta(self.alpha, self.alpha, self.batch_size)
X_l = l.reshape(self.batch_size, 1, 1, 1)
y_l = l.reshape(self.batch_size, 1)
X = X1 * X_l + X2 * (1 - X_l)
y = y1 * y_l + y2 * (1 - y_l)
if self.datagen:
for i in range(self.batch_size):
X[i] = self.datagen.random_transform(X[i])
return X, y
# res block
def resblock(x, filters, kernel_size):
x_ = Conv2D(filters, kernel_size, padding='same')(x)
x_ = BatchNormalization()(x_)
x_ = Activation("relu")(x_)
x_ = Conv2D(filters, kernel_size, padding='same')(x_)
x = Add()([x_, x])
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
# cnnの構築
input_ = Input(shape=(32, 32, 3))#横の数、縦の数、RGB
c = Conv2D(64, (1, 1), padding="same")(input_)
c = BatchNormalization()(c)
c = Activation("relu")(c)
c = resblock(c,filters=64, kernel_size=(3, 3))
c = Conv2D(64, (3, 3), strides=2)(c)
c = BatchNormalization()(c)
c = Activation("relu")(c)
c = Dropout(0.2)(c)
c = resblock(c,filters=64, kernel_size=(3, 3))
c = Conv2D(128, (3, 3), strides=2)(c)
c = BatchNormalization()(c)
c = Activation("relu")(c)
c = Dropout(0.2)(c)
c = resblock(c,filters=128, kernel_size=(3, 3))
c = Conv2D(256, (3, 3), strides=2)(c)
c = BatchNormalization()(c)
c = Activation("relu")(c)
c = Dropout(0.2)(c)
c = GlobalAveragePooling2D()(c)
c = Dense(10, activation='softmax')(c)
model = Model(input_, c)
model.compile(loss='categorical_crossentropy',
optimizer=Adam(amsgrad=True),
metrics=['accuracy'])
# Data Augmentation
datagen = ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
# mixup
training_generator = MixupGenerator(X_train, Y_train, datagen=datagen)()
# cnnの学習
hist = model.fit_generator(generator=training_generator,
steps_per_epoch=X_train.shape[0] /128,
validation_data=(X_test, Y_test),
epochs=100,
verbose=1)
# 結果描画
plt.figure()
plt.plot(hist.history['loss'],label="train_loss")
plt.plot(hist.history['val_loss'],label="val_loss")
plt.legend()
plt.show()
plt.figure()
plt.plot(hist.history['acc'],label="train_acc")
plt.plot(hist.history['val_acc'],label="val_acc")
plt.legend(loc="lower right")
plt.show()