最近、DeepLearning業界で話題のmixupをkerasで動かしてみます。
mixupとは
一言でいうと、Data Augmentationの一種で精度アップの効果があるそうです。
論文はこちら↓
https://arxiv.org/abs/1710.09412
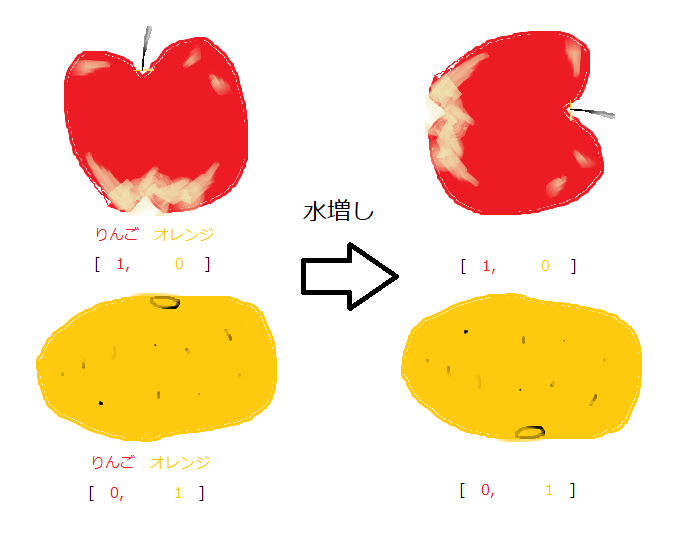
通常のData Augmentationは、下図のように元の画像を回転させたり
反転させたりして、データを水増しします。水増ししたデータで学習
させることにより、汎化能力を高めることができます。
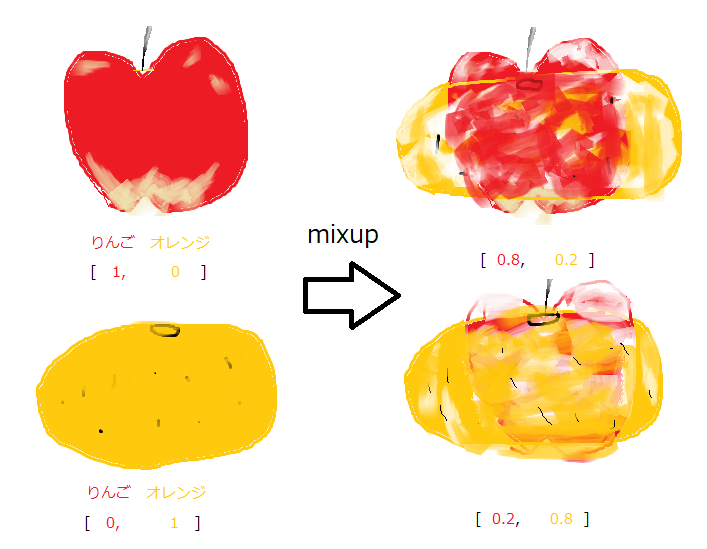
一方、mixupではラベル間のデータを混ぜてData Augmentationを行います。
そして、ラベルも混ぜて学習させます。
論文によると、次の利点もあるそうです。
・ラベル付けに間違いがあっても、柔軟力がある
・adversarial attackにも比較的頑強
・画像以外のデータでも効果がある
・GANの安定性も増す
kaggleで使われるmixup
kaggleのまとめサイトを見ても、mixupで精度がアップしたものが見受けられます。
・kaggle TensorFlow Speech Recognition Challengeの上位者のアプローチを紹介する(後編)
https://qiita.com/daimonji-bucket/items/c61c19f25deeceec47d8
(mixupを使うことにより2.9%の改善)
浅いNNでmixupを使ってみた
論文中で、使われているモデルはDNNですが、浅いNNでも効果があるのか試してみました。
今回用意したのは、隠れ層が1層でノード数80個のニューラルネットワークです。
使うデータセットは、scikit-learnで提供されている次のものを使います。
・Irisデータ(アヤメの”がく”と弁の寸法)
・Digitsデータ(数字の手書き文字画像)
20回試行を行い平均値をとると、テストデータの精度推移は以下のようになりました。
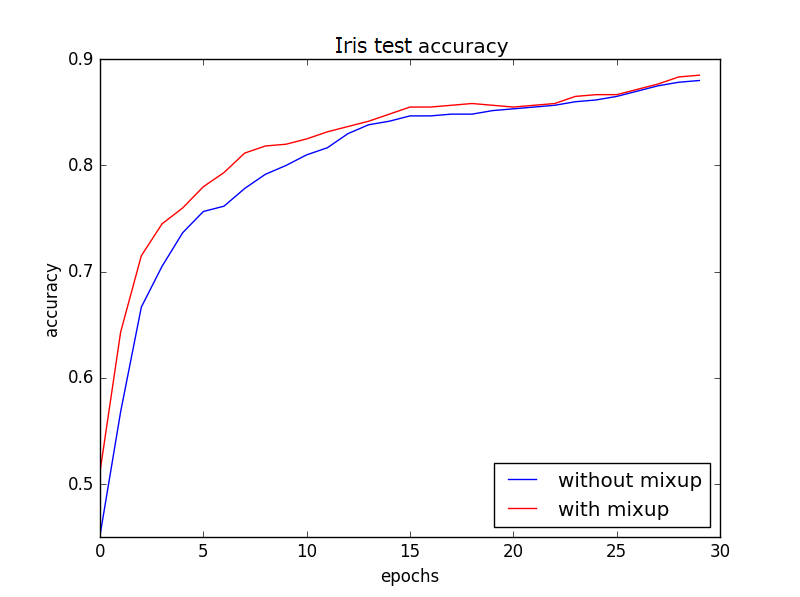
Irisデータでは、mixupを使うと最終精度が**1.5%**ほど上昇しました。
さらに、特筆すべきは学習の速度も上がっています!
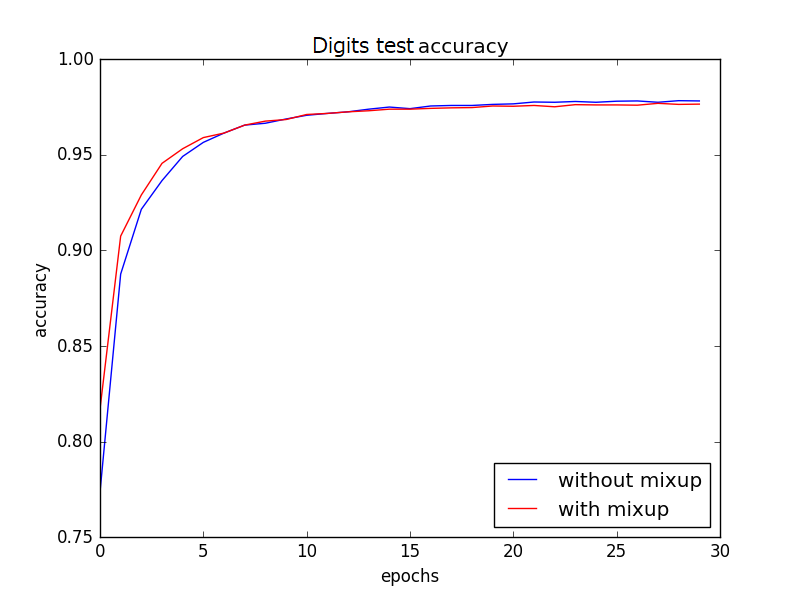
Digitsデータでは、最終精度はほぼ変わりませんが、やはり学習の速度が
上がっています。
浅いNNは、アンサンブル学習でもよく使われます。
そんなときは、mixupを入れてみると、精度アップするかもしれません。
コード
mixupのコードはyu4uさんのものを拝借しました。
ただし、今回はCNNを使っていないので、次元数を変更しています。
# mixup_generator.py
import numpy as np
class MixupGenerator():
def __init__(self, X_train, y_train, batch_size=30, alpha=0.2, shuffle=True):
self.X_train = X_train
self.y_train = y_train
self.batch_size = batch_size
self.alpha = alpha
self.shuffle = shuffle
self.sample_num = len(X_train)
def __call__(self):
while True:
indexes = self.__get_exploration_order()
itr_num = int(len(indexes) // (self.batch_size * 2))
for i in range(itr_num):
batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2]
X, y = self.__data_generation(batch_ids)
yield X, y
def __get_exploration_order(self):
indexes = np.arange(self.sample_num)
if self.shuffle:
np.random.shuffle(indexes)
return indexes
def __data_generation(self, batch_ids):
#_, h, w, c = self.X_train.shape
#_, class_num = self.y_train.shape
X1 = self.X_train[batch_ids[:self.batch_size]]
X2 = self.X_train[batch_ids[self.batch_size:]]
y1 = self.y_train[batch_ids[:self.batch_size]]
y2 = self.y_train[batch_ids[self.batch_size:]]
l = np.random.beta(self.alpha, self.alpha, self.batch_size)
X_l = l.reshape(self.batch_size, 1)
y_l = l.reshape(self.batch_size, 1)
X = X1 * X_l + X2 * (1 - X_l)
y = y1 * y_l + y2 * (1 - y_l)
return X, y
メインプログラムでは以下のように呼び出して、学習データに結合させます。
from mixup_generator import MixupGenerator
generator1 = MixupGenerator(x_train, y_train, batch_size=batch_size)()
x, y = next(generator1)
x_train = np.vstack((x_train,x))
y_train = np.vstack((y_train,y))
学習用のコードの全文も載せます。相変わらず、ぐちゃぐちゃです。。。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import confusion_matrix
from sklearn.datasets import load_iris, load_digits
from sklearn.preprocessing import StandardScaler
from sklearn.cross_validation import train_test_split
# 新バージョンはfrom sklearn.cross_model_selection
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Activation
from mixup_generator import MixupGenerator
# NNの学習
def train_NN(x_train, y_train, x_test, y_test, output_dim, batch_size=30, mixup_flag=False):
model = Sequential()
model.add(Dense(80, input_dim=x_train.shape[1]))
model.add(Activation('relu'))
model.add(Dense(output_dim))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
#mixup
if mixup_flag == True:
generator1 = MixupGenerator(x_train, y_train, batch_size=batch_size)()
x, y = next(generator1)
x_train = np.vstack((x_train,x))
y_train = np.vstack((y_train,y))
#モデルの学習
Y_test = to_categorical(y_test, output_dim)
hist = model.fit(x_train, y_train,
epochs=30, batch_size=30,
validation_data = (x_test,Y_test),
verbose=0)
y_predict = model.predict_classes(x_test, batch_size=1)
#分類精度の算出
conma = confusion_matrix(y_test,y_predict)
acc = np.trace(conma)/np.sum(conma)
#acurracyの推移
hist_acc = np.array(hist.history['val_acc'])
return acc,hist_acc
# データの分割、学習
def train(x_train, y_train, output_dim, batch_size):
#学習データの分割
(x_train,x_test,y_train,y_test) = train_test_split(x_train, y_train, test_size=0.2)
y_train = to_categorical(y_train, output_dim)
acc_n, hist_acc_n = train_NN(x_train, y_train, x_test, y_test, output_dim, batch_size)
acc_m, hist_acc_m = train_NN(x_train, y_train, x_test, y_test, output_dim, batch_size, mixup_flag=True)
return acc_n, acc_m, hist_acc_n, hist_acc_m
# ==========================================================
# iris データロード
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names)#150個
X = np.array(data)
true_label = np.array(iris.target)# (0: 'setosa', 1: 'versicolor', 2: 'virginica')
# 学習データ + 標準化
x_train = X
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
# 20回試行して平均精度を算出
y_n, y_m = [],[]
hist_acc_n = np.zeros(30)
hist_acc_m = np.zeros(30)
for i in range(20):
acc_n, acc_m, result_n, result_m = train(x_train, true_label, 3, 30)
y_n.append(result_n)
y_m.append(result_m)
hist_acc_n += result_n
hist_acc_m += result_m
print(i)
hist_acc_n = hist_acc_n/20
hist_acc_m = hist_acc_m/20
plt.figure()
plt.plot(hist_acc_n,label="without mixup")
plt.plot(hist_acc_m,label="with mixup",c="r")
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.title("Validation accuracy")
plt.legend(loc = "lower right")
plt.show()
# ==========================================================
# digits データロード
digits = load_digits(n_class=10)
data = pd.DataFrame(digits.data)
X = np.array(data)
true_label = np.array(digits.target)#array([0, 1, 2, ..., 8, 9, 8])
# 学習データ + 標準化
x_train = X
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
# 20回試行して平均精度を算出
y_n, y_m = [],[]
hist_acc_n = np.zeros(30)
hist_acc_m = np.zeros(30)
for i in range(20):
acc_n, acc_m, result_n, result_m = train(x_train, true_label, 10, 300)
y_n.append(result_n)
y_m.append(result_m)
hist_acc_n += result_n
hist_acc_m += result_m
print(i)
hist_acc_n = hist_acc_n/20
hist_acc_m = hist_acc_m/20
plt.figure()
plt.plot(hist_acc_n,label="without mixup")
plt.plot(hist_acc_m,label="with mixup",c="r")
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.title("Validation accuracy")
plt.legend(loc = "lower right")
plt.show()