畳み込みニューラルネットワーク(CNN)で成功を収めたネットワークの1つにRes-Nets(Residual Networks、残差ネットワーク)があります。一般にRes-Netsを使うと勾配消失問題に強いとされます。CIFAR-10データセットを使ってRes-Netsの有効性を軽く確認してみました。
元の論文
K.He, X.Zhang, S.Ren, J.Sun, "Deep Residual Learning for Image Recognition", 2015
https://arxiv.org/pdf/1512.03385.pdf
残差ブロック(Residual Block)とは
このようにショートカット構造のあるレイヤーの組み合わせ(ブロック)のこと。K.He et al.(2015)より
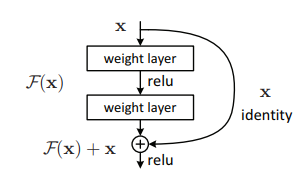
分岐前の活性化関数適用後の値を$a^{[l]}$とすると、合流後の活性化関数適用前の値は$z^{[l+2]}$となるので、
$$z^{[l+2]} = (w^{[l+2]}a^{[l+1]}+b^{[l+2]}) + a^{[l]}$$
で表されます。カッコ内はメインルートの値、右側はショートカットの値です。仮にメインルートの値が0になったとしても、ショートカット側の値が代入されるので、勾配消失問題に強いという理屈です。
そもそも勾配消失(爆発)問題とは
ネットワークが深くなると発生しやすくなる問題です。一般的な全結合ニューラルネットワークでの計算は、
$$a^{[l+1]}=g(w^{[l+1]}a^{[l]}+b^{[l+1]}) $$
で表されます。今わかりやすいように、活性化関数を線形活性化関数、b=0、wの係数を全て同一とすると、
$$a^{[l]} = w^lx$$
という指数関数になります。つまりネットワークが深くなればなるほど(lの値が大きくなるほど)、wが0.99という1に近い数字でも出力はほぼ0に近くなり、wが1.01なら出力は無限大になり……と出力をコントロールするのがとても難しくなります。
勾配の消失(爆発)はCNNだけではなく、全結合のNNやRNNでも発生する共通の問題です。一般に、勾配の爆発より消失のほうが深刻な問題であると言われています。無限大に爆発したものはクリッピング(max, min関数)で一定範囲内に収められますが、0になってしまったものは復活させようがなく、そこで学習が終わってしまうためです。
要はRes-Netsのメリットって何?
勾配消失問題を気にすることなく、モデルをどんどん深くできること。モデルを深く大きくすると、巨大な訓練データを精度に反映できるためです。
KerasでのResNet-50の実装を見る
Kerasには既に訓練済みのResNet-50のモデルがあり、簡単に読み込むことができます。summaryで表示し、ResBlockの実装を確認します。
from keras.applications.resnet50 import ResNet50
resnet = ResNet50()
with open("resnet50.txt", "w") as fp:
resnet.summary(print_fn=lambda x: fp.write(x + "\r\n"))
ResBlock1つを取り出すとこうなります。最初のMaxPoolingはResBlockに関係ありません。
max_pooling2d_1 (MaxPooling2D) (None, 55, 55, 64) 0 activation_1[0][0]
__________________________________________________________________________________________________
res2a_branch2a (Conv2D) (None, 55, 55, 64) 4160 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
bn2a_branch2a (BatchNormalizati (None, 55, 55, 64) 256 res2a_branch2a[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 55, 55, 64) 0 bn2a_branch2a[0][0]
__________________________________________________________________________________________________
res2a_branch2b (Conv2D) (None, 55, 55, 64) 36928 activation_2[0][0]
__________________________________________________________________________________________________
bn2a_branch2b (BatchNormalizati (None, 55, 55, 64) 256 res2a_branch2b[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 55, 55, 64) 0 bn2a_branch2b[0][0]
__________________________________________________________________________________________________
res2a_branch2c (Conv2D) (None, 55, 55, 256) 16640 activation_3[0][0]
__________________________________________________________________________________________________
res2a_branch1 (Conv2D) (None, 55, 55, 256) 16640 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
bn2a_branch2c (BatchNormalizati (None, 55, 55, 256) 1024 res2a_branch2c[0][0]
__________________________________________________________________________________________________
bn2a_branch1 (BatchNormalizatio (None, 55, 55, 256) 1024 res2a_branch1[0][0]
__________________________________________________________________________________________________
add_1 (Add) (None, 55, 55, 256) 0 bn2a_branch2c[0][0]
bn2a_branch1[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 55, 55, 256) 0 add_1[0][0]
__________________________________________________________________________________________________
まとめると次のとおりです。分岐以降、
- メインルート:Conv2d→BN→Activation → Conv2d→BN→Activation → Conv2d→BN
- ショートカット:Conv2d→BN
このあとAddで合流させます。これが1つのRes-Blockです。3レイヤーで1ResBlockを構成していますが、2レイヤー(メインルートの2回目のCov2d→BN→Activationを外す)にしても特に問題はなさそうです。今回の実験では簡単にするために1Res-Blockは2レイヤーとします。
派生研究として、合流後にReLUをするのではなく、ReLUをかけてから分岐させ合流後にはReLUをかけないというのもあります。下記資料によると、現在ではこっちがRes-Netsと呼ばれるそうです。
実験設定
CIFAR-10データを使い、深いモデルを定義し、Res Blockの有無で学習の過程を比較します。CIFAR-10程度のデータ数(5万)だと通常はここまで深いモデルは必要ありません。
元の論文がVGGを意識したモデルなので、これを踏襲し、簡素化したモデルにします。K.He et al.(2015)より
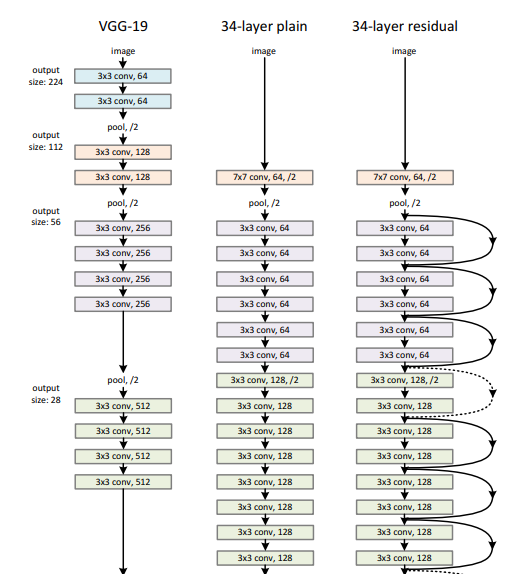
全てカーネルサイズ3x3の畳み込み(Conv2d)をやっているものの、フィルター数がだんだん増えていくモデルですね。元のVGGはフィルター数が変わるタイミングでPoolingを挟んでいます。
元の論文で示されていた用語ではありませんが、わかりやすいように同一のフィルター数の**レイヤー/ブロックの集まりを「1フェーズ」**と呼ぶことにします。上の図では緑色のレイヤーの集まりで1フェーズ、紫色のレイヤーの集まりで別の1フェーズ……となります。また、**ResBlockの1つを「1ブロック」**と呼びます。1ブロックは2つの畳み込みレイヤーで構成されるため、1ブロックのレイヤー数は2となります。
細かな設定は以下の通りです。フィルター数の変化はResNetよりもVGGを参考にしました。
- 1フェーズは3ブロックで構成される。フェーズの最初に2×2のAveragePoolingを入れる。またショートカットとメインルートのフィルター数を統一するため、AveragePoolingの後に1回だけ3×3の活性化関数なしのConv2dを入れる。したがって1フェーズは7層。
- 1ブロックは2レイヤーから構成され、メインルートはConv2d→BN→Activation→Conv2d→BN、ショートカットはBNだけ入れてAddで合流させる。合流後にActivationをかける。
- フィルター数は初期値16として、フェーズが変わるたびに倍々になっていく
- 畳み込みは全て3x3、same paddingとする。つまり、フェーズ間ではテンソルのサイズは同一
- 入力の次元は(32,32,3)なので、フェーズごとに(32,32,16)→(16,16,32)→(8,8,64)→(4,4,128)となる
- ResBlockの有無、フェーズ数が1~4の合計8パターンを試して比較する。ResBlockを使わない場合は、単に畳み込みフィルターを7個並べたものが1フェーズとなる。
字面にするとわかりづらいですが、コードを見たほうがわかりやすいと思います。
コード
import numpy as np
import pickle
import os
from keras.layers import Input, Conv2D, AveragePooling2D, BatchNormalization, Add, Activation, Flatten, Dense
from keras.models import Model
from keras.optimizers import Adam
from keras.datasets import cifar10
from keras.utils import to_categorical
class TestModel:
def __init__(self, use_resblock, nb_blocks):
self.use_resblock = use_resblock
self.nb_blocks = nb_blocks
# モデルの作成
self.model = self._create_model()
# モデル名
self.name = ""
if use_resblock: self.name += "use_res_"
else: self.name += "no_res_"
self.name = f"{self.name}{self.nb_blocks:02d}"
def _create_model(self):
input = Input(shape=(32, 32, 3))
X = input
n_filter = 16
for i in range(self.nb_blocks):
# 3ブロック単位でAveragePoolingを入れる、フィルター数を倍にする
if i % 3 == 0 and i != 0:
X = AveragePooling2D((2,2))(X)
n_filter *= 2
# ショートカットとメインのフィルター数を揃えるために活性化関数なしの畳込みレイヤーを作る
if i % 3 == 0:
X = Conv2D(n_filter, (3,3), padding="same")(X)
# 1ブロック単位の処理
if self.use_resblock:
# ショートカット:ショートカット→BatchNorm(ResBlockを使う場合のみ)
shortcut = X
shortcut = BatchNormalization()(shortcut)
# メイン
# 畳み込み→BatchNorm→活性化関数
X = Conv2D(n_filter, (3,3), padding="same")(X)
X = BatchNormalization()(X)
X = Activation("relu")(X)
# 畳み込み→BatchNorm
X = Conv2D(n_filter, (3,3), padding="same")(X)
X = BatchNormalization()(X)
if self.use_resblock:
# ショートカットとマージ(ResBlockを使う場合のみ)
X = Add()([X, shortcut])
# 活性化関数
X = Activation("relu")(X)
# 全結合
X = Flatten()(X)
y = Dense(10, activation="softmax")(X)
# モデル
model = Model(inputs=input, outputs=y)
return model
def train(self, Xtrain, ytrain, Xval, yval, nb_epoch=100, learning_rate=0.01):
self.model.compile(optimizer=Adam(lr=learning_rate), loss="categorical_crossentropy", metrics=["accuracy"])
history = self.model.fit(Xtrain, ytrain, batch_size=128, epochs=nb_epoch, validation_data=(Xval, yval)).history
# historyの保存
if not os.path.exists("history"): os.mkdir("history")
with open(f"history/{self.name}.dat", "wb") as fp:
pickle.dump(history, fp)
if __name__ == "__main__":
# データの読み込み
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
# テストパターン
resflag = [False, True]
nb_blocks = [3, 6, 9, 12]
# モデルの作成
for res in resflag:
for nb in nb_blocks:
print("Testing model... / ", res, nb)
model = TestModel(res, nb)
model.train(X_train, y_train, X_test, y_test, nb_epoch=100)
ちなみにモデルが一番大きくなる「Res-Blockあり、4フェーズ(12ブロック)」の場合のsummaryは次のようになりました(パラメーター数部分だけ抜粋)。
Total params: 1,303,050
Trainable params: 1,298,730
Non-trainable params: 4,320
130万個のパラメーターです。自分のCPUだと1epoch40分近くかかりますが、Google ColabのGPUを使ったら1epoch1分強でできました。100epochなので最悪1時間半ぐらいですね。ちなみに4フェーズの場合は28層のモデルです。1フェーズだけだと7層なのでもっと早く終わります。
ちなみに本家のResNet-50の場合はパラメーターが2563万もあります。これはちょっと自分では訓練したくないです。
結果
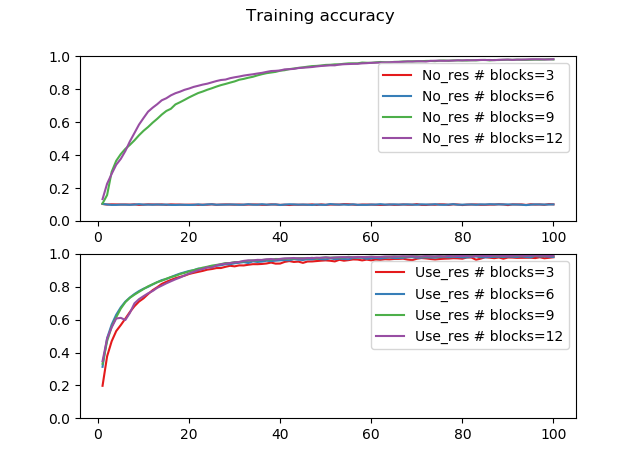
縦軸を訓練精度、横軸をepoch数としてプロットしました。
訓練精度0.9~1で拡大すると次のとおりです。
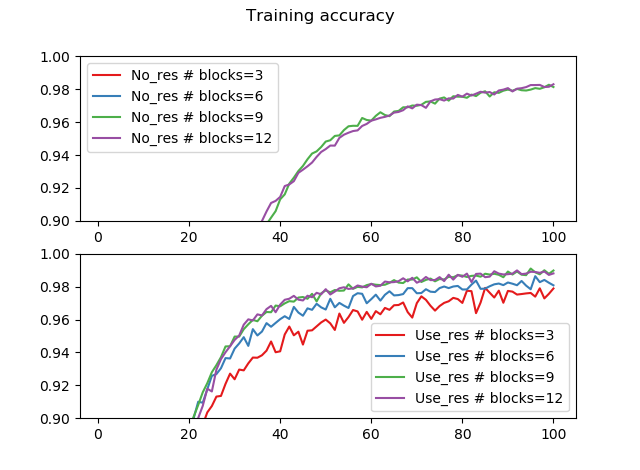
ResBlockなし、フェーズ=1、2(ブロック数3、6)の場合は勾配が消失して学習が進みませんでした。ResBlockありの場合は、どのフェーズ数でもきちんと学習が進んでいることが確認できます。また、ResBlockを使った場合はブロック数(モデルの深さ)が大きくなるほど、訓練精度が上がっていることが確認できます。
なお勾配消失はモデルが深くなるほど起こりやすいと言われていますが、なぜResBlockなしの場合浅いモデルのほうで勾配が消失して、深いモデルでは消失しなかったかはよくわかりません。しかし、ResBlockを使えばどの場合も勾配が消失していないというのは確かです。
同様に、交差検証データに対する精度を縦軸にしてプロットしてみます。ここではcifar10を読み込んだ際のテストデータを交差検証データとして用いています。
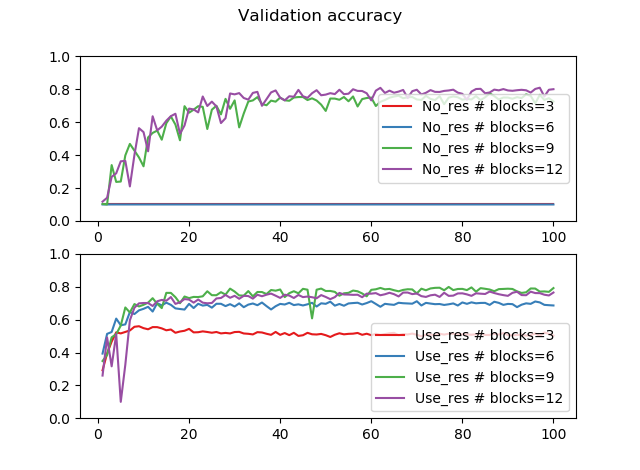
交差検証の精度を0.6~0.9で拡大すると次の通りです。
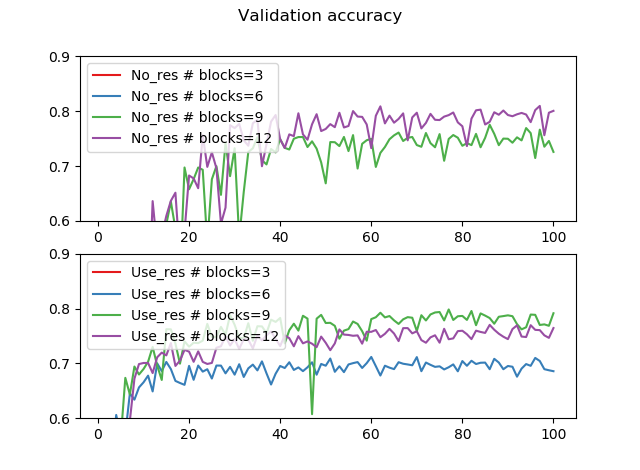
概ね交差検証の精度は0.8弱というところでしょうか。訓練精度が98%近いので、かなりオーバーフィッティングしています。それは半ば当たり前で、CIFAR-10程度でここまで深いモデルは必要なく、モデルが訓練データの数に対して大きすぎるのでオーバーフィッティングしがちということです。データの増強やドロップアウト使うとかなりいい結果になると思います。
まとめ
実験の結果をまとめます。
- Res-Netは勾配消失問題に対して有効と言われているが、この実験を通じてそれを確認できた。ResBlockを使わない場合は勾配消失が起こったが、ResBlockを使った場合はどれも勾配消失は起こらなかった。
- ResBlockを使うと、モデルを大きくするほど訓練誤差が下がり、より理想的な結果になりやすい。
データはgithubから見れます
https://github.com/koshian2/ResNet-CIFAR10