はじめに
ふと思い立って勉強を始めた「ゼロから作るDeep Learning❷ーー自然言語処理編」の6章で私がつまずいたことのメモです。
実行環境はmacOS Catalina + Anaconda 2019.10、Pythonのバージョンは3.7.4です。詳細はこのメモの1章をご参照ください。なお、この章では途中からGoogle Colaboratoryも使っています。
(このメモの他の章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / まとめ)
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
6章 ゲート付きRNN
この章は、ゲート付きRNNの説明です。
6.1 RNNの問題点
RNNは勾配爆発と勾配消失の課題があって長期記憶が苦手というお話です。
まずは勾配爆発の対策ですが、ここで使う勾配クリッピングはすごくローテクです。これに限らずDeep Learning関連は「やってみたらうまく行った」的な話が多いですよね。私は研究職だったことはなく、これまで確立した技術しか学ぶことがなかったので、最先端の技術開発はこういった感じなのかと、いろいろ新鮮に感じています。
6.2 勾配消失とLSTM
勾配消失の対策としてゲート付きRNNを使います。この本ではLSTMがメインで解説されていて、付録でGRUの解説があります。本の解説はわかりやすく特につまずく部分はなかったです。
なお、この本の解説は参考文献[31]のcolah's blog: "Understanding LSTM Networks" がベースになっていますが、これを@KojiOhkiさんが「LSTMネットワークの概要」として翻訳されています。LSTMのバリエーションとしてGRUも解説されています。
6.3 LSTMの実装
本来はここから自分で実装するところなのですが、多忙で時間が取れず、まだ本のコードを眺める程度になっています。実際に時間が取れた時に実装してみて、何かつまずいたところがあれば追記しようと思います。
6.4 LSTMを使った言語モデル
実装しないと言っても読んでいるだけではつまらないので、2章や4章同様に青空文庫の分かち書き済みテキストを使って実行してみました。
2章でdataset/ptb.pyを流用して作ったdataset/aozorabunko.pyはtrain用のデータしか取得できなかったので、青空文庫の分かち書き済みテキストに作品をいくつか追加して、test用とvalid用のデータも取得できるようにしています。
なお、PTBデータセットはtrain、test、validの3つのセットで語彙が共通なのですが、私のコードは青空文庫から適当に選んだいくつかの作品を分かち書きしているだけなので語彙が共通にはなりません。そこで、一番データ量の多いtrain用のセットで語彙を作り、testやvalidでそこにない単語が出てきてしまった場合は、単純にその単語を無視する形でコーパスを作っています。
以下、dataset/aozorabunko.pyのコードです。★の部分がdataset/ptb.pyからの変更点です。
# coding: utf-8
import sys
import os
sys.path.append('..')
try:
import urllib.request
except ImportError:
raise ImportError('Use Python3!')
import pickle
import numpy as np
# ★このURLはGitHubにアップしてある分かち書き済みの青空文庫作品詰め合わせのダウンロードURL
# 詳細は https://github.com/segavvy/wakatigaki-aozorabunko を参照してください。
url_base = 'https://github.com/segavvy/wakatigaki-aozorabunko/raw/master/'
key_file = {
'train': '20200516merge.txt',
'test': '20201207merge.txt',
'valid': '20201231merge.txt'
}
save_file = {
'train': 'aozorabunko.train.npy',
'test': 'aozorabunko.test.npy',
'valid': 'aozorabunko.valid.npy'
}
vocab_file = 'aozorabunko.vocab.pkl'
dataset_dir = os.path.dirname(os.path.abspath(__file__))
def _download(file_name):
file_path = dataset_dir + '/' + file_name
if os.path.exists(file_path):
return
print('Downloading ' + file_name + ' ... ')
try:
urllib.request.urlretrieve(url_base + file_name, file_path)
except urllib.error.URLError:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
urllib.request.urlretrieve(url_base + file_name, file_path)
print('Done')
# ★テキストの分割が2箇所で使われるため関数化。実装は超その場しのぎ……
def _split_data(text):
return text.replace('\n', '<eos> ').replace('。', '<eos> ').strip().split()
def load_vocab():
vocab_path = dataset_dir + '/' + vocab_file
if os.path.exists(vocab_path):
with open(vocab_path, 'rb') as f:
word_to_id, id_to_word = pickle.load(f)
return word_to_id, id_to_word
word_to_id = {}
id_to_word = {}
data_type = 'train'
file_name = key_file[data_type]
file_path = dataset_dir + '/' + file_name
_download(file_name)
words = _split_data(open(file_path).read())
for i, word in enumerate(words):
if word not in word_to_id:
tmp_id = len(word_to_id)
word_to_id[word] = tmp_id
id_to_word[tmp_id] = word
with open(vocab_path, 'wb') as f:
pickle.dump((word_to_id, id_to_word), f)
return word_to_id, id_to_word
def load_data(data_type='train'):
'''
:param data_type: データの種類:'train' or 'test' or 'valid (val)'
:return:
'''
if data_type == 'val': data_type = 'valid'
save_path = dataset_dir + '/' + save_file[data_type]
word_to_id, id_to_word = load_vocab()
if os.path.exists(save_path):
corpus = np.load(save_path)
return corpus, word_to_id, id_to_word
file_name = key_file[data_type]
file_path = dataset_dir + '/' + file_name
_download(file_name)
words = _split_data(open(file_path).read())
# ★今回使っている青空文庫のデータはPTBのような前処理をしていないため、
# testのデータにはtrainになかった単語も出現する。かなり乱暴だが、そういった単語はスキップ。
if data_type == 'train':
corpus = np.array([word_to_id[w] for w in words])
else:
corpus = np.array([word_to_id[w] for w in words if w in word_to_id])
np.save(save_path, corpus)
return corpus, word_to_id, id_to_word
if __name__ == '__main__':
for data_type in ('train', 'val', 'test'):
load_data(data_type)
学習用のコードch06/train_rnnlm.pyは、PTBコーパスを使う部分を青空文庫に変えるだけです。★の部分が変更点です。
# coding: utf-8
import sys
sys.path.append('..')
from common.optimizer import SGD
from common.trainer import RnnlmTrainer
from common.util import eval_perplexity
from dataset import aozorabunko # ★青空文庫のコーパスを利用するように変更
from rnnlm import Rnnlm
# ハイパーパラメータの設定
batch_size = 20
wordvec_size = 100
hidden_size = 100 # RNNの隠れ状態ベクトルの要素数
time_size = 35 # RNNを展開するサイズ
lr = 20.0
max_epoch = 4
max_grad = 0.25
# 学習データの読み込み
corpus, word_to_id, id_to_word = aozorabunko.load_data('train') # ★コーパス変更
corpus_test, _, _ = aozorabunko.load_data('test') # ★コーパス変更
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
# モデルの生成
model = Rnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
# 勾配クリッピングを適用して学習
trainer.fit(xs, ts, max_epoch, batch_size, time_size, max_grad,
eval_interval=20)
trainer.plot(ylim=(0, 500))
# テストデータで評価
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('test perplexity: ', ppl_test)
# パラメータの保存
model.save_params()
そして実行結果です。
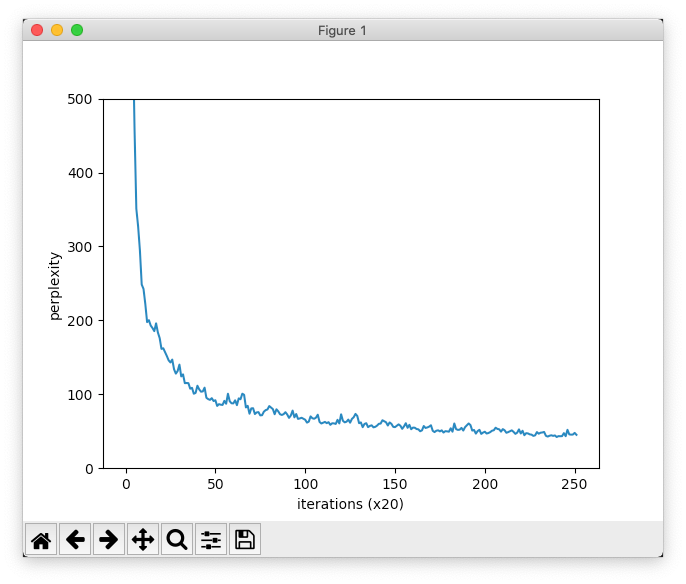
| epoch 1 | iter 1 / 1247 | time 1[s] | perplexity 27249.26
| epoch 1 | iter 21 / 1247 | time 36[s] | perplexity 4283.50
| epoch 1 | iter 41 / 1247 | time 71[s] | perplexity 1291.40
| epoch 1 | iter 61 / 1247 | time 110[s] | perplexity 846.53
| epoch 1 | iter 81 / 1247 | time 148[s] | perplexity 597.52
| epoch 1 | iter 101 / 1247 | time 185[s] | perplexity 459.56
| epoch 1 | iter 121 / 1247 | time 221[s] | perplexity 351.08
| epoch 1 | iter 141 / 1247 | time 258[s] | perplexity 327.10
| epoch 1 | iter 161 / 1247 | time 294[s] | perplexity 294.42
| epoch 1 | iter 181 / 1247 | time 331[s] | perplexity 248.45
| epoch 1 | iter 201 / 1247 | time 367[s] | perplexity 242.54
| epoch 1 | iter 221 / 1247 | time 404[s] | perplexity 222.16
| epoch 1 | iter 241 / 1247 | time 439[s] | perplexity 197.64
| epoch 1 | iter 261 / 1247 | time 478[s] | perplexity 200.25
| epoch 1 | iter 281 / 1247 | time 527[s] | perplexity 193.02
| epoch 1 | iter 301 / 1247 | time 568[s] | perplexity 189.60
| epoch 1 | iter 321 / 1247 | time 612[s] | perplexity 185.42
| epoch 1 | iter 341 / 1247 | time 645[s] | perplexity 196.01
| epoch 1 | iter 361 / 1247 | time 675[s] | perplexity 183.63
| epoch 1 | iter 381 / 1247 | time 707[s] | perplexity 175.95
(中略)
| epoch 4 | iter 861 / 1247 | time 7444[s] | perplexity 48.34
| epoch 4 | iter 881 / 1247 | time 7474[s] | perplexity 49.01
| epoch 4 | iter 901 / 1247 | time 7502[s] | perplexity 43.83
| epoch 4 | iter 921 / 1247 | time 7533[s] | perplexity 42.77
| epoch 4 | iter 941 / 1247 | time 7564[s] | perplexity 43.90
| epoch 4 | iter 961 / 1247 | time 7595[s] | perplexity 44.55
| epoch 4 | iter 981 / 1247 | time 7626[s] | perplexity 43.74
| epoch 4 | iter 1001 / 1247 | time 7657[s] | perplexity 44.34
| epoch 4 | iter 1021 / 1247 | time 7687[s] | perplexity 42.23
| epoch 4 | iter 1041 / 1247 | time 7714[s] | perplexity 43.39
| epoch 4 | iter 1061 / 1247 | time 7742[s] | perplexity 43.26
| epoch 4 | iter 1081 / 1247 | time 7769[s] | perplexity 43.42
| epoch 4 | iter 1101 / 1247 | time 7795[s] | perplexity 47.44
| epoch 4 | iter 1121 / 1247 | time 7822[s] | perplexity 43.31
| epoch 4 | iter 1141 / 1247 | time 7849[s] | perplexity 51.94
| epoch 4 | iter 1161 / 1247 | time 7875[s] | perplexity 45.76
| epoch 4 | iter 1181 / 1247 | time 7900[s] | perplexity 45.39
| epoch 4 | iter 1201 / 1247 | time 7925[s] | perplexity 45.50
| epoch 4 | iter 1221 / 1247 | time 7950[s] | perplexity 47.77
| epoch 4 | iter 1241 / 1247 | time 7975[s] | perplexity 45.17
Unable to create basic Accelerated OpenGL renderer.
Unable to create basic Accelerated OpenGL renderer.
Core Image is now using the software OpenGL renderer. This will be slow.
evaluating perplexity ...
670 / 671
test perplexity: 105.19809806111377
「Unable to create basic Accelerated OpenGL renderer.」のエラーが出ているのは、おそらく私の環境が特殊で、Visual Studio Codeの起動時にGPUを無効にしているためだと思います1。
最終的に4エポックでパープレキシティは45.17まで下がり、テストデータでの評価結果は105.19...でした。本と比べて良い値になっていますが、使っているデータが違いすぎるので、単純比較はできません。初回のパープレキシティが本より異常に大きい原因も語彙数の違いがあるためです。
以下、本が使っているPTBデータセットと、今回使っている青空文庫のデータの違いをまとめます。
| 項目 | PTBデータセット | 今回の青空文庫のデータ |
|---|---|---|
| 語彙数 | 10,000 | 27,255 |
| 学習データ(train)の語数 | 929,589 | 873,028 |
| 検証データ(valid)の語数 | 73,760 | 154,598 |
| テストデータ(test)の語数 | 82,430 | 234,943 |
| 主な前処理 | レアな単語を<unk>に置換、具体的な数字をNに置換など。 |
レアな単語や数字の前処理はなし。語彙は学習データからのみ作成し、検証データとテストデータに出現した未知語は無視。 |
PTBデータセットと比べると前処理がいい加減すぎますが、勉強目的ということで前に進みます![]()
6.5 RNNLMのさらなる改善
こちらも青空文庫のデータで学習させてみました。学習用のコードch06/train_better_rnnlm.pyで、PTBコーパスを使う部分を青空文庫に変えるだけです。★の部分が変更点です。
# coding: utf-8
import sys
sys.path.append('..')
from common import config
# GPUで実行する場合は下記のコメントアウトを消去(要cupy)
# ==============================================
# config.GPU = True
# ==============================================
from common.optimizer import SGD
from common.trainer import RnnlmTrainer
from common.util import eval_perplexity, to_gpu
from dataset import aozorabunko # ★青空文庫のコーパスを利用するように変更
from better_rnnlm import BetterRnnlm
# ハイパーパラメータの設定
batch_size = 20
wordvec_size = 650
hidden_size = 650
time_size = 35
lr = 20.0
max_epoch = 40
max_grad = 0.25
dropout = 0.5
# 学習データの読み込み
corpus, word_to_id, id_to_word = aozorabunko.load_data('train') # ★コーパス変更
corpus_val, _, _ = aozorabunko.load_data('val') # ★コーパス変更
corpus_test, _, _ = aozorabunko.load_data('test') # ★コーパス変更
print(len(corpus))
print(len(corpus_val))
print(len(corpus_test))
if config.GPU:
corpus = to_gpu(corpus)
corpus_val = to_gpu(corpus_val)
corpus_test = to_gpu(corpus_test)
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
best_ppl = float('inf')
for epoch in range(max_epoch):
trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size,
time_size=time_size, max_grad=max_grad)
model.reset_state()
ppl = eval_perplexity(model, corpus_val)
print('valid perplexity: ', ppl)
if best_ppl > ppl:
best_ppl = ppl
model.save_params()
else:
lr /= 4.0
optimizer.lr = lr
model.reset_state()
print('-' * 50)
# テストデータでの評価
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('test perplexity: ', ppl_test)
これで実行してみたのですが……
| epoch 1 | iter 1 / 1247 | time 29[s] | perplexity 27253.64
| epoch 1 | iter 21 / 1247 | time 464[s] | perplexity 5073.64
| epoch 1 | iter 41 / 1247 | time 876[s] | perplexity 1873.61
| epoch 1 | iter 61 / 1247 | time 1246[s] | perplexity 1320.39
| epoch 1 | iter 81 / 1247 | time 1611[s] | perplexity 996.53
| epoch 1 | iter 101 / 1247 | time 1978[s] | perplexity 775.86
| epoch 1 | iter 121 / 1247 | time 2374[s] | perplexity 564.95
| epoch 1 | iter 141 / 1247 | time 2789[s] | perplexity 504.54
| epoch 1 | iter 161 / 1247 | time 3201[s] | perplexity 424.97
| epoch 1 | iter 181 / 1247 | time 3605[s] | perplexity 374.88
| epoch 1 | iter 201 / 1247 | time 4007[s] | perplexity 339.03
| epoch 1 | iter 221 / 1247 | time 4409[s] | perplexity 302.10
| epoch 1 | iter 241 / 1247 | time 4810[s] | perplexity 272.72
| epoch 1 | iter 261 / 1247 | time 5208[s] | perplexity 260.39
| epoch 1 | iter 281 / 1247 | time 5608[s] | perplexity 247.86
| epoch 1 | iter 301 / 1247 | time 6009[s] | perplexity 235.96
| epoch 1 | iter 321 / 1247 | time 6530[s] | perplexity 237.14
| epoch 1 | iter 341 / 1247 | time 7067[s] | perplexity 241.14
| epoch 1 | iter 361 / 1247 | time 7597[s] | perplexity 214.95
| epoch 1 | iter 381 / 1247 | time 8124[s] | perplexity 212.66
| epoch 1 | iter 401 / 1247 | time 8653[s] | perplexity 194.03
| epoch 1 | iter 421 / 1247 | time 9171[s] | perplexity 191.89
| epoch 1 | iter 441 / 1247 | time 9685[s] | perplexity 189.85
| epoch 1 | iter 461 / 1247 | time 10187[s] | perplexity 176.23
| epoch 1 | iter 481 / 1247 | time 10692[s] | perplexity 172.90
| epoch 1 | iter 501 / 1247 | time 11206[s] | perplexity 169.14
| epoch 1 | iter 521 / 1247 | time 11713[s] | perplexity 169.99
| epoch 1 | iter 541 / 1247 | time 12221[s] | perplexity 160.42
| epoch 1 | iter 561 / 1247 | time 12731[s] | perplexity 150.20
| epoch 1 | iter 581 / 1247 | time 13189[s] | perplexity 154.43
| epoch 1 | iter 601 / 1247 | time 13561[s] | perplexity 169.05
| epoch 1 | iter 621 / 1247 | time 13926[s] | perplexity 145.88
| epoch 1 | iter 641 / 1247 | time 14305[s] | perplexity 149.73
| epoch 1 | iter 661 / 1247 | time 14671[s] | perplexity 140.01
| epoch 1 | iter 681 / 1247 | time 15041[s] | perplexity 136.77
| epoch 1 | iter 701 / 1247 | time 15414[s] | perplexity 138.95
| epoch 1 | iter 721 / 1247 | time 15778[s] | perplexity 128.21
| epoch 1 | iter 741 / 1247 | time 16143[s] | perplexity 129.12
| epoch 1 | iter 761 / 1247 | time 16509[s] | perplexity 117.92
| epoch 1 | iter 781 / 1247 | time 16877[s] | perplexity 118.82
| epoch 1 | iter 801 / 1247 | time 17252[s] | perplexity 131.58
| epoch 1 | iter 821 / 1247 | time 17659[s] | perplexity 125.46
| epoch 1 | iter 841 / 1247 | time 18055[s] | perplexity 121.22
| epoch 1 | iter 861 / 1247 | time 18490[s] | perplexity 124.50
| epoch 1 | iter 881 / 1247 | time 18909[s] | perplexity 128.52
| epoch 1 | iter 901 / 1247 | time 19254[s] | perplexity 110.78
| epoch 1 | iter 921 / 1247 | time 19613[s] | perplexity 109.87
| epoch 1 | iter 941 / 1247 | time 19974[s] | perplexity 104.43
| epoch 1 | iter 961 / 1247 | time 20334[s] | perplexity 109.85
| epoch 1 | iter 981 / 1247 | time 20713[s] | perplexity 105.33
| epoch 1 | iter 1001 / 1247 | time 21214[s] | perplexity 107.46
| epoch 1 | iter 1021 / 1247 | time 21727[s] | perplexity 98.93
| epoch 1 | iter 1041 / 1247 | time 22195[s] | perplexity 101.21
| epoch 1 | iter 1061 / 1247 | time 22608[s] | perplexity 99.85
| epoch 1 | iter 1081 / 1247 | time 23070[s] | perplexity 100.58
| epoch 1 | iter 1101 / 1247 | time 23493[s] | perplexity 106.59
| epoch 1 | iter 1121 / 1247 | time 23930[s] | perplexity 101.43
| epoch 1 | iter 1141 / 1247 | time 24364[s] | perplexity 118.50
| epoch 1 | iter 1161 / 1247 | time 24754[s] | perplexity 103.30
| epoch 1 | iter 1181 / 1247 | time 25166[s] | perplexity 101.68
| epoch 1 | iter 1201 / 1247 | time 25574[s] | perplexity 101.07
| epoch 1 | iter 1221 / 1247 | time 26001[s] | perplexity 105.31
| epoch 1 | iter 1241 / 1247 | time 26425[s] | perplexity 97.66
evaluating perplexity ...
440 / 441
valid perplexity: 131.10745282836612
なんと私の環境では、1エポックで8時間もかかってしまいました。これを本の通りに40エポック回したら2週間くらいかかります。8年前のMac miniでmacOSを仮想化しているような手元の環境では、さすがに実行は無理そうです。そこでここからは「Google Colaboratory」を使ってみました。
(脱線)Google Colaboratoryでの実行の流れ
Google Colaboratory(以降、Google Colab)は、Googleが無償提供しているJupyterノートブックの環境です。この本で必要なモジュールは事前にすべてインストールされており、さらにGPUまで使えます。
以下、この本のプログラムを実行するまでの流れをざっとまとめます。
なお、JupyterノートブックやGoogle Colabを使ったことがない方は、日本のPython情報サイトpython.jpにあるゼロからのPython入門講座 > Python初体験が分かりやすくてオススメです。
また、Google Driveとの連携などについては、@tomo_makesさんの【秒速で無料GPUを使う】深層学習実践Tips on Colaboratoryが分かりやすくてオススメです。
- Google ColabではGPUが利用できるので、
ch06/train_better_rnnlm.pyの先頭部分にあるGPU利用のコメントアウトを削除します。
# coding: utf-8
import sys
sys.path.append('..')
from common import config
# GPUで実行する場合は下記のコメントアウトを消去(要cupy)
# ==============================================
config.GPU = True # ★GPUで実行
# ==============================================
- Googleドライブに適当なフォルダーを作って、実行に必要なファイルをアップロードします。今回の6章に必要なのは
ch06フォルダーとcommonフォルダーとdatasetフォルダーなので、私は以下のような感じにしました。なお__pycache__フォルダーはコンパイル済みのモジュールがキャッシュされる場所2なのでアップロードはしないでください。Google Colabで実行すると自動的に生成されます。

-
ch06フォルダーを表示してすきまを右クリックし、プログラムの実行用に使うGoogle Colabのファイルを作ります。

- 空のノートブックが開くので名前を設定しましょう。私は「train_better_rnnlm実行.ipynb」としました。
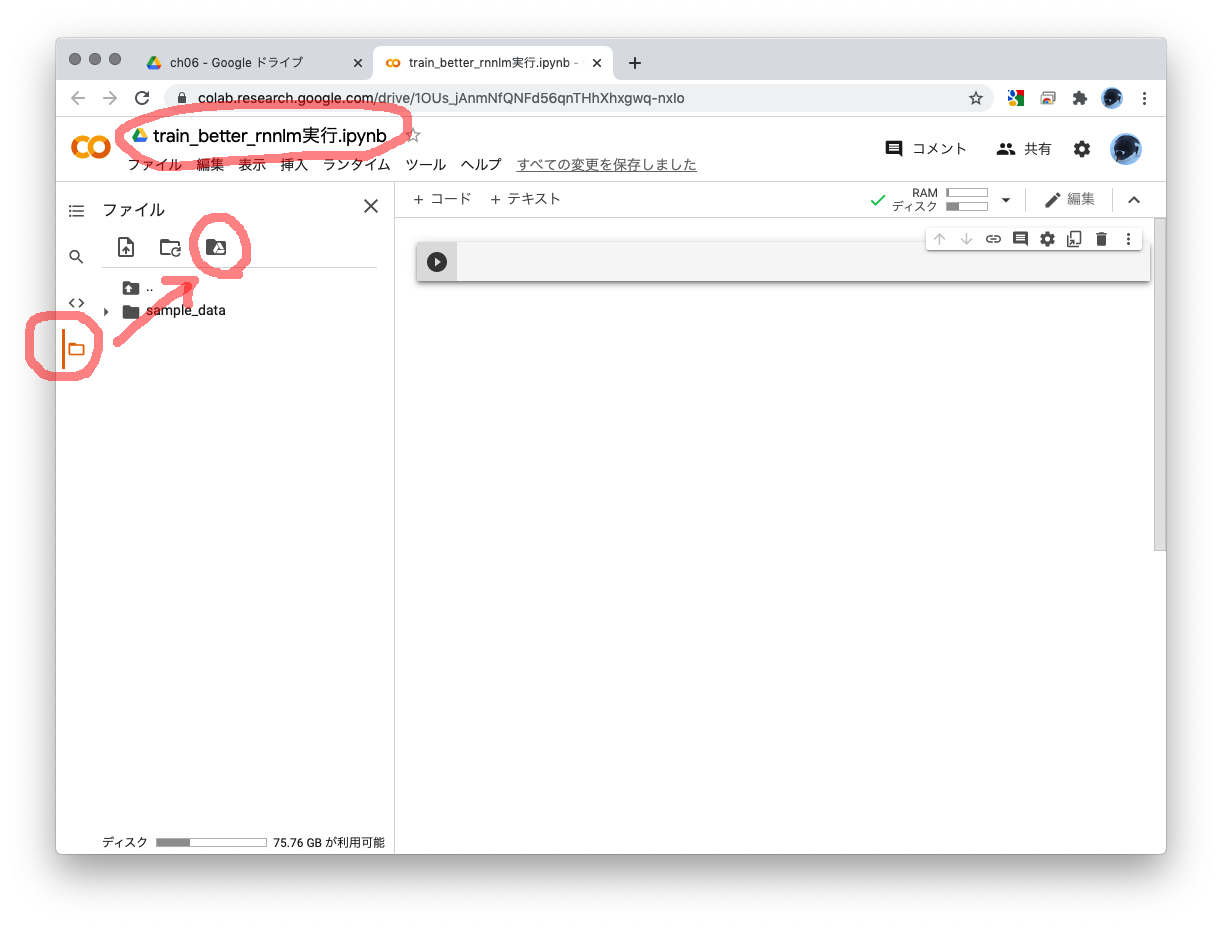
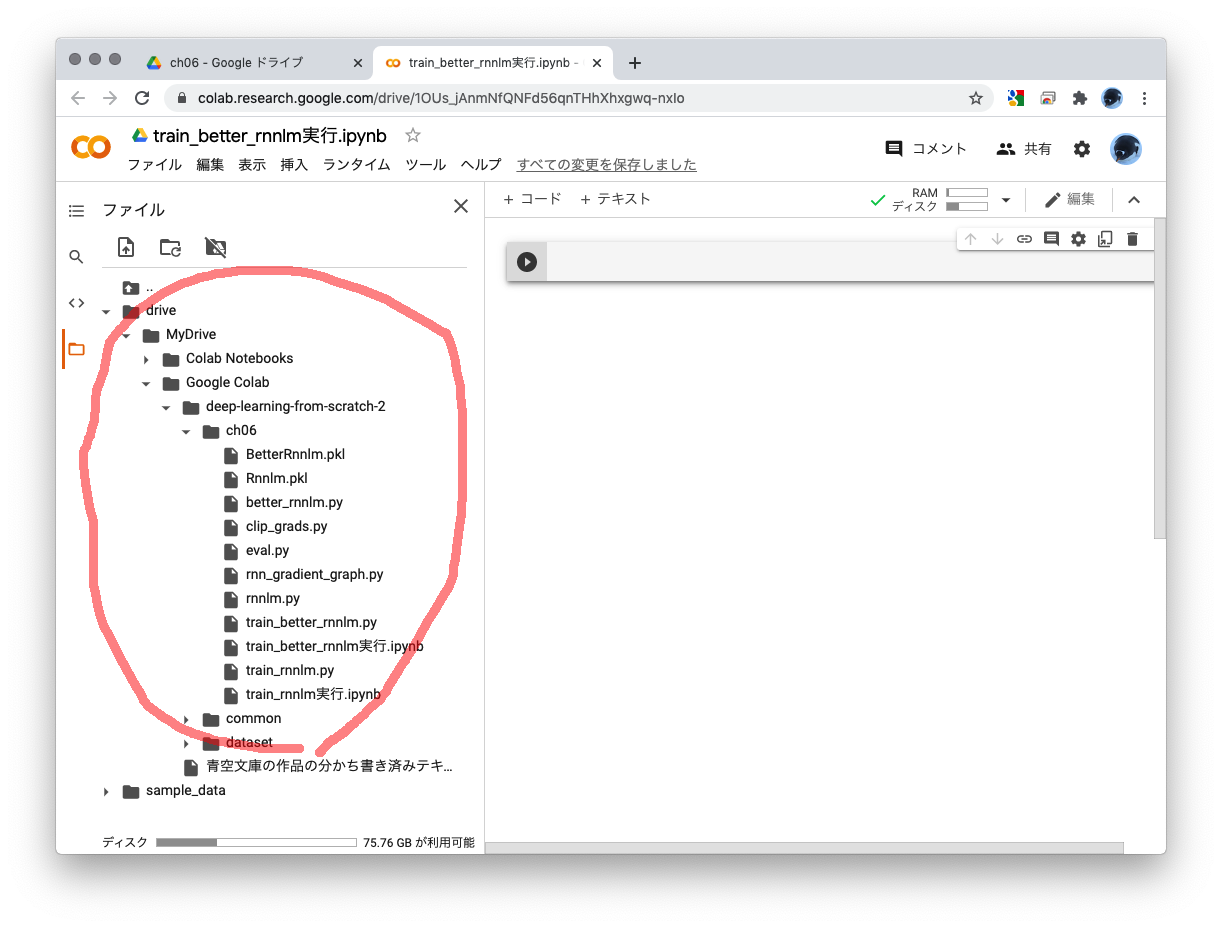
- 上図の左側の赤丸部分にあるフォルダーアイコンから、Googleドライブをマウントするアイアコンを選びます。「このノートブックにGoogleドライブのファイルへのアクセスを許可しますか?」と聞いてくるので「GOOGLEドライブに接続」してください。
これで「MyDrive」以下にGoogleドライブがマウントされて、ノートブックから先ほどアップしたファイルへアクセスできるようになります。
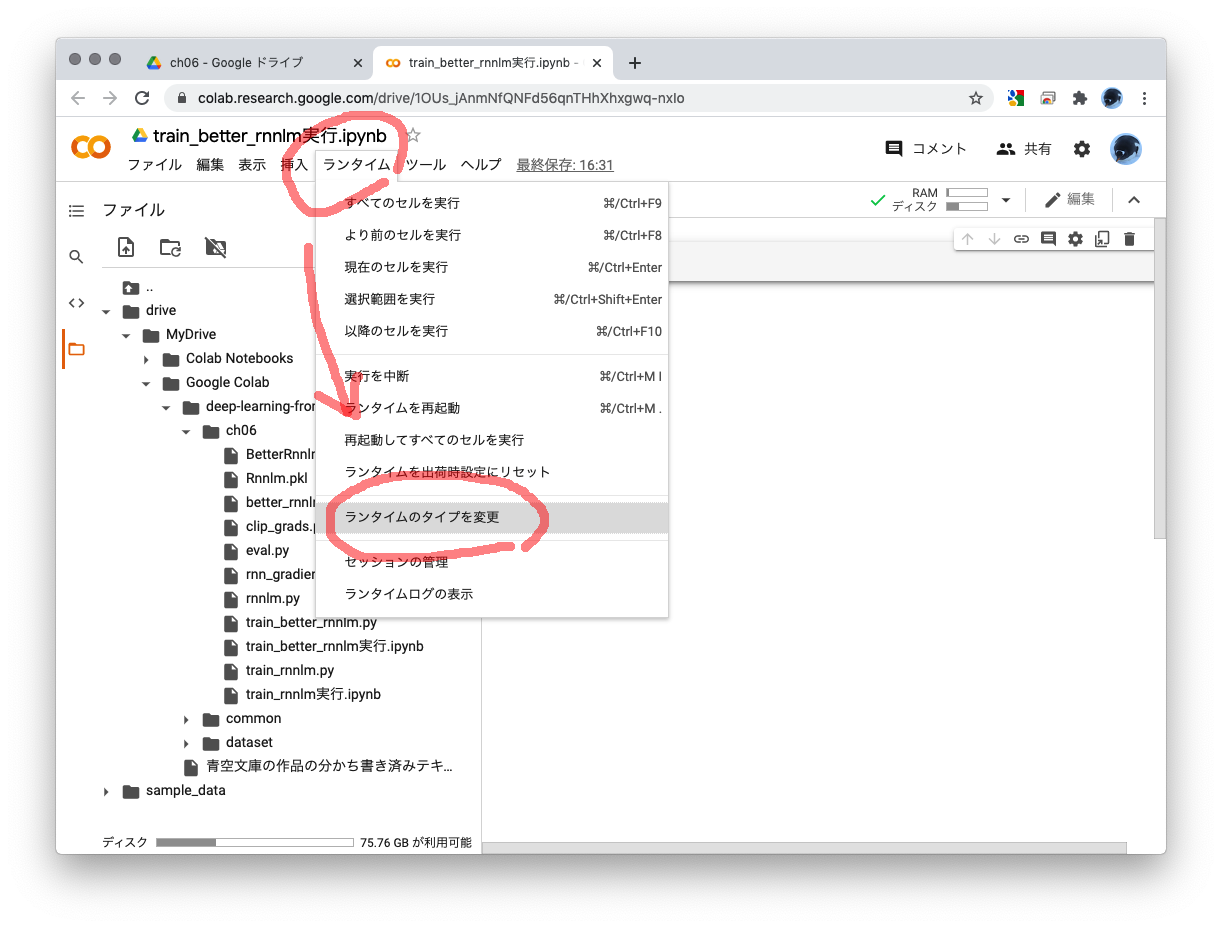
- Google ColabのデフォルトではGPUが使えないので、使えるように設定を切り替えます。「ランタイム」から「ランタイムのタイプを変更」を選び、ハードウェア アクセラレータで「GPU」を選んで「保存」してください。
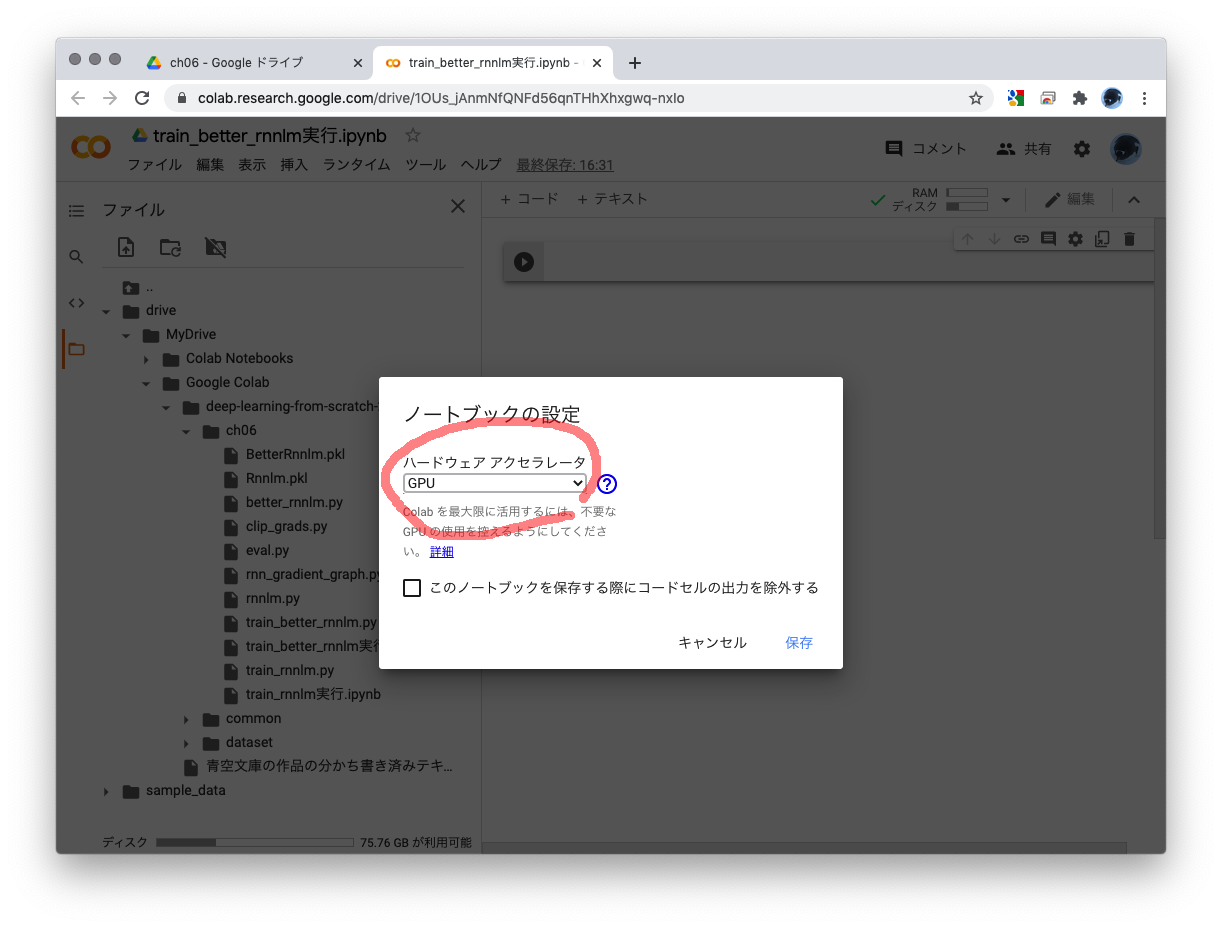
- あとは、ノートブックでカレントを
ch06に切り替えて、import train_better_rnnlmで実行できます。

Google Colabだと、なんと3時間で終了しました。
------------------------------------------------------------
GPU Mode (cupy)
------------------------------------------------------------
| epoch 1 | iter 1 / 1247 | time 0[s] | perplexity 27254.36
| epoch 1 | iter 21 / 1247 | time 4[s] | perplexity 5519.64
| epoch 1 | iter 41 / 1247 | time 9[s] | perplexity 1787.35
| epoch 1 | iter 61 / 1247 | time 13[s] | perplexity 1414.92
| epoch 1 | iter 81 / 1247 | time 17[s] | perplexity 1023.22
| epoch 1 | iter 101 / 1247 | time 21[s] | perplexity 841.00
| epoch 1 | iter 121 / 1247 | time 26[s] | perplexity 645.57
| epoch 1 | iter 141 / 1247 | time 30[s] | perplexity 554.69
| epoch 1 | iter 161 / 1247 | time 34[s] | perplexity 466.50
| epoch 1 | iter 181 / 1247 | time 38[s] | perplexity 378.45
| epoch 1 | iter 201 / 1247 | time 43[s] | perplexity 355.62
| epoch 1 | iter 221 / 1247 | time 47[s] | perplexity 312.13
| epoch 1 | iter 241 / 1247 | time 51[s] | perplexity 284.31
| epoch 1 | iter 261 / 1247 | time 55[s] | perplexity 263.32
| epoch 1 | iter 281 / 1247 | time 60[s] | perplexity 249.79
| epoch 1 | iter 301 / 1247 | time 64[s] | perplexity 241.19
| epoch 1 | iter 321 / 1247 | time 68[s] | perplexity 240.92
| epoch 1 | iter 341 / 1247 | time 72[s] | perplexity 245.29
| epoch 1 | iter 361 / 1247 | time 77[s] | perplexity 223.77
| epoch 1 | iter 381 / 1247 | time 81[s] | perplexity 212.58
| epoch 1 | iter 401 / 1247 | time 85[s] | perplexity 196.46
| epoch 1 | iter 421 / 1247 | time 90[s] | perplexity 193.10
| epoch 1 | iter 441 / 1247 | time 94[s] | perplexity 190.85
| epoch 1 | iter 461 / 1247 | time 98[s] | perplexity 178.43
| epoch 1 | iter 481 / 1247 | time 102[s] | perplexity 175.06
| epoch 1 | iter 501 / 1247 | time 107[s] | perplexity 172.07
| epoch 1 | iter 521 / 1247 | time 111[s] | perplexity 174.37
| epoch 1 | iter 541 / 1247 | time 115[s] | perplexity 162.38
| epoch 1 | iter 561 / 1247 | time 120[s] | perplexity 153.01
| epoch 1 | iter 581 / 1247 | time 124[s] | perplexity 153.36
| epoch 1 | iter 601 / 1247 | time 128[s] | perplexity 167.39
| epoch 1 | iter 621 / 1247 | time 132[s] | perplexity 147.94
| epoch 1 | iter 641 / 1247 | time 137[s] | perplexity 151.36
| epoch 1 | iter 661 / 1247 | time 141[s] | perplexity 140.71
| epoch 1 | iter 681 / 1247 | time 145[s] | perplexity 137.02
| epoch 1 | iter 701 / 1247 | time 150[s] | perplexity 140.36
| epoch 1 | iter 721 / 1247 | time 154[s] | perplexity 129.04
| epoch 1 | iter 741 / 1247 | time 158[s] | perplexity 132.23
| epoch 1 | iter 761 / 1247 | time 163[s] | perplexity 121.74
| epoch 1 | iter 781 / 1247 | time 167[s] | perplexity 123.19
| epoch 1 | iter 801 / 1247 | time 171[s] | perplexity 132.10
| epoch 1 | iter 821 / 1247 | time 175[s] | perplexity 126.86
| epoch 1 | iter 841 / 1247 | time 180[s] | perplexity 121.01
| epoch 1 | iter 861 / 1247 | time 184[s] | perplexity 124.81
| epoch 1 | iter 881 / 1247 | time 188[s] | perplexity 127.83
| epoch 1 | iter 901 / 1247 | time 193[s] | perplexity 111.56
| epoch 1 | iter 921 / 1247 | time 197[s] | perplexity 110.17
| epoch 1 | iter 941 / 1247 | time 201[s] | perplexity 106.49
| epoch 1 | iter 961 / 1247 | time 206[s] | perplexity 109.84
| epoch 1 | iter 981 / 1247 | time 210[s] | perplexity 105.97
| epoch 1 | iter 1001 / 1247 | time 214[s] | perplexity 106.18
| epoch 1 | iter 1021 / 1247 | time 219[s] | perplexity 98.83
| epoch 1 | iter 1041 / 1247 | time 223[s] | perplexity 100.83
| epoch 1 | iter 1061 / 1247 | time 227[s] | perplexity 100.39
| epoch 1 | iter 1081 / 1247 | time 232[s] | perplexity 98.95
| epoch 1 | iter 1101 / 1247 | time 236[s] | perplexity 107.26
| epoch 1 | iter 1121 / 1247 | time 240[s] | perplexity 100.78
| epoch 1 | iter 1141 / 1247 | time 245[s] | perplexity 115.91
| epoch 1 | iter 1161 / 1247 | time 249[s] | perplexity 103.40
| epoch 1 | iter 1181 / 1247 | time 253[s] | perplexity 102.27
| epoch 1 | iter 1201 / 1247 | time 258[s] | perplexity 102.13
| epoch 1 | iter 1221 / 1247 | time 262[s] | perplexity 103.44
| epoch 1 | iter 1241 / 1247 | time 266[s] | perplexity 97.24
evaluating perplexity ...
440 / 441
valid perplexity: 131.96678
--------------------------------------------------
| epoch 2 | iter 1 / 1247 | time 0[s] | perplexity 152.90
(中略)
| epoch 39 | iter 1241 / 1247 | time 268[s] | perplexity 26.58
evaluating perplexity ...
440 / 441
valid perplexity: 87.54218
--------------------------------------------------
| epoch 40 | iter 1 / 1247 | time 0[s] | perplexity 44.52
| epoch 40 | iter 21 / 1247 | time 4[s] | perplexity 35.15
| epoch 40 | iter 41 / 1247 | time 8[s] | perplexity 34.62
| epoch 40 | iter 61 / 1247 | time 13[s] | perplexity 34.63
| epoch 40 | iter 81 / 1247 | time 17[s] | perplexity 30.87
| epoch 40 | iter 101 / 1247 | time 21[s] | perplexity 31.86
| epoch 40 | iter 121 / 1247 | time 26[s] | perplexity 29.81
| epoch 40 | iter 141 / 1247 | time 30[s] | perplexity 31.46
| epoch 40 | iter 161 / 1247 | time 34[s] | perplexity 31.74
| epoch 40 | iter 181 / 1247 | time 39[s] | perplexity 29.82
| epoch 40 | iter 201 / 1247 | time 43[s] | perplexity 30.46
| epoch 40 | iter 221 / 1247 | time 47[s] | perplexity 30.38
| epoch 40 | iter 241 / 1247 | time 52[s] | perplexity 29.90
| epoch 40 | iter 261 / 1247 | time 56[s] | perplexity 30.13
| epoch 40 | iter 281 / 1247 | time 60[s] | perplexity 31.11
| epoch 40 | iter 301 / 1247 | time 65[s] | perplexity 30.98
| epoch 40 | iter 321 / 1247 | time 69[s] | perplexity 30.86
| epoch 40 | iter 341 / 1247 | time 73[s] | perplexity 33.41
| epoch 40 | iter 361 / 1247 | time 78[s] | perplexity 31.96
| epoch 40 | iter 381 / 1247 | time 82[s] | perplexity 31.97
| epoch 40 | iter 401 / 1247 | time 86[s] | perplexity 30.91
| epoch 40 | iter 421 / 1247 | time 91[s] | perplexity 32.48
| epoch 40 | iter 441 / 1247 | time 95[s] | perplexity 30.68
| epoch 40 | iter 461 / 1247 | time 99[s] | perplexity 29.06
| epoch 40 | iter 481 / 1247 | time 104[s] | perplexity 29.30
| epoch 40 | iter 501 / 1247 | time 108[s] | perplexity 30.14
| epoch 40 | iter 521 / 1247 | time 112[s] | perplexity 30.65
| epoch 40 | iter 541 / 1247 | time 117[s] | perplexity 30.09
| epoch 40 | iter 561 / 1247 | time 121[s] | perplexity 28.05
| epoch 40 | iter 581 / 1247 | time 125[s] | perplexity 30.44
| epoch 40 | iter 601 / 1247 | time 130[s] | perplexity 31.19
| epoch 40 | iter 621 / 1247 | time 134[s] | perplexity 28.56
| epoch 40 | iter 641 / 1247 | time 138[s] | perplexity 31.40
| epoch 40 | iter 661 / 1247 | time 143[s] | perplexity 28.68
| epoch 40 | iter 681 / 1247 | time 147[s] | perplexity 28.82
| epoch 40 | iter 701 / 1247 | time 151[s] | perplexity 29.54
| epoch 40 | iter 721 / 1247 | time 156[s] | perplexity 26.66
| epoch 40 | iter 741 / 1247 | time 160[s] | perplexity 27.79
| epoch 40 | iter 761 / 1247 | time 164[s] | perplexity 26.76
| epoch 40 | iter 781 / 1247 | time 169[s] | perplexity 26.98
| epoch 40 | iter 801 / 1247 | time 173[s] | perplexity 29.41
| epoch 40 | iter 821 / 1247 | time 177[s] | perplexity 27.64
| epoch 40 | iter 841 / 1247 | time 182[s] | perplexity 28.54
| epoch 40 | iter 861 / 1247 | time 186[s] | perplexity 29.63
| epoch 40 | iter 881 / 1247 | time 190[s] | perplexity 28.86
| epoch 40 | iter 901 / 1247 | time 195[s] | perplexity 26.40
| epoch 40 | iter 921 / 1247 | time 199[s] | perplexity 25.49
| epoch 40 | iter 941 / 1247 | time 203[s] | perplexity 26.11
| epoch 40 | iter 961 / 1247 | time 208[s] | perplexity 27.68
| epoch 40 | iter 981 / 1247 | time 212[s] | perplexity 26.79
| epoch 40 | iter 1001 / 1247 | time 216[s] | perplexity 27.18
| epoch 40 | iter 1021 / 1247 | time 221[s] | perplexity 25.34
| epoch 40 | iter 1041 / 1247 | time 225[s] | perplexity 26.43
| epoch 40 | iter 1061 / 1247 | time 229[s] | perplexity 26.31
| epoch 40 | iter 1081 / 1247 | time 234[s] | perplexity 26.05
| epoch 40 | iter 1101 / 1247 | time 238[s] | perplexity 27.87
| epoch 40 | iter 1121 / 1247 | time 242[s] | perplexity 26.48
| epoch 40 | iter 1141 / 1247 | time 247[s] | perplexity 30.43
| epoch 40 | iter 1161 / 1247 | time 251[s] | perplexity 28.00
| epoch 40 | iter 1181 / 1247 | time 255[s] | perplexity 26.65
| epoch 40 | iter 1201 / 1247 | time 260[s] | perplexity 27.46
| epoch 40 | iter 1221 / 1247 | time 264[s] | perplexity 27.82
| epoch 40 | iter 1241 / 1247 | time 269[s] | perplexity 26.43
evaluating perplexity ...
440 / 441
valid perplexity: 87.54218
--------------------------------------------------
evaluating perplexity ...
670 / 671
test perplexity: 73.6651
Google Colabのおかげで、貧弱なPCしかない私でもGPUを使った本格的な学習が試せました。ありがたい限りです。
パープレキシティも73.66...まで下がりました。なかなか良さそうです。
6.6 まとめ
せっかく青空文庫で学習させたので文章の生成を試してみたいところなのですが、それは次の章の頭で取り組みます。
この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。
(このメモの他の章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / まとめ)
-
Mac on Macの環境なのですが、Visual Studio Codeの表示周りが乱れるのでGPUを切って使っています。興味のある方は Parallels DesktopのmacOS仮想マシンでVisual Studio Codeをとりあえず使うをご参照ください。 ↩
-
詳細はPython公式のヘルプをご参照ください。例えばVer3.9なら6.1.3. "コンパイル" された Python ファイルです。 ↩