はじめに
「ゼロから作るDeep LearningーーPythonで学ぶディープラーニングの理論と実装」が読み終わったので続編の「ゼロから作るDeep Learning❷ーー自然言語処理編」 に進むつもりだったのですが、新型コロナの影響で生活ペースが変わってしまい、うまく勉強時間が作れなくなってしまいました。これまでは仕事帰りにコーヒー屋に立ち寄って勉強するのが日課だったのですが、テレワークになったら仕事終わって5分でビールの生活になってしまいまして![]()
これじゃマズいので、アラフィフの体に鞭打ってお勉強の再開です。前巻の投稿と同じように、この本で私がつまずいたことなどを1章ごとにメモしていこうと思いますので、誤りなどありましたらご指摘いただけるとうれしいです。
(このメモの他の章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / まとめ)
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
私の環境
前回同様、Macの仮想マシンで進めます。仮想マシンのOSはMojaveからCatalinaに上げました。
| ホスト | 環境 |
|---|---|
| ハード | Mac mini(Late 2012) |
| OS | macOS Mojave バージョン 10.14.6 |
| 仮想化基盤 | Parallels Desktop 15 for Mac Pro Edition バージョン 15.1.4 (47270) |
| ゲスト | 環境 |
|---|---|
| OS | macOS Catalina バージョン 10.15.4 |
| 開発環境 | Anaconda 2019.10 (Python 3.7) |
| エディタ | Visual Studio Code Version 1.44.2 |
8年前のマシンで仮想マシン動かしてDeep Learningとかちょっとあり得ないかも知れませんが、前巻はこれでなんとかなったので継続します。私の環境の詳細については、前回のゼロから作るDeep Learningで素人がつまずいたことメモ:1章をご参照ください。
1章 ニューラルネットワークの復習
この本の「まえがき」の「誰のための本か」の部分で、「ニューラルネットワークやPythonの知識のある方は、前作の知識がなくても本書を読み進められるように配慮してあります。」とありますが、どれくらいの前提知識があれば良いのか悩ましいところかと思います。
この1章には前巻の半分以上の内容が凝縮されて詰まっていますので、1章で挫折しそうになった方は、まず先に前巻を読まれることをお薦めします。
以下、前巻との違いで気づいた点なども含め、つまずいた点を列挙します。
1.1 数学とPythonの復習
-
「1.1.3 ブロードキャスト」で紹介されている参考文献[1]のBroadcastingは英語なのですが、日本語ではnkmkさんのNumPyのブロードキャスト(形状の自動変換)が分かりやすいです。
-
「1.1.4 ベクトルの内積と行列の積」で出てくる
np.dot(x, y)は@演算子を使ってx @ yとも書けることを最近知りました。私は@の方がスッキリして良いかと思うのですが、この@が使えるようになったのはPython 3.5以降とのことなので、まだ@を使うのは少数派なのかも知れません。
1.2 ニューラルネットワークの推論
- 「1.2.2 レイヤとしてのクラス化と順伝播の実装」の実装では、すべての重みをリストにまとめるようになりました。前巻では辞書にレイヤーやバイアスごとのキー(
"W1"とか"b1"とか)を付けて格納していたので、実装方針が変更されています。
1.3 ニューラルネットワークの学習
- 「1.3.4 計算グラフ」の説明は、最初に説明する基本ノードの種類が前巻よりも増えました(前巻を会社に置いたままテレワークに突入してしまい記憶頼りなのですが、Repeatノード、Sumノード、MatMulノードの説明は基本ノードとしては出てこなかったかと)。これにより「1.3.5.2 Affineレイヤ」の説明も分かりやすくなっています。
- 「1.3.4.5 MatMulノード」で、NumPy配列への代入に3点リーダー(
...)を使うと深いコピー(deep copy)になるとの説明があります。前巻よりもメモリの利用効率や速度を重視する方針になっているようです。
ただ、代入先に3点リーダーを使うと深いコピーになるという説明が、なぜそうなるのかピンとこなかったので少し調べてみました。どうやら正確には、ndarrayでスライスを使うとビュー(view)オブジェクトが作られて、そこへ代入すれば元データの上書きになる、そしてスライスの便利な省略表記として3点リーダーがある、ということみたいです。
ビューオブジェクトについてはDeepAgeのNumPyのコピー(copy)とビュー(view)を分かりやすく解説の解説が、3点リーダーについてはnkmkさんのNumPy配列ndarrayの次元をEllipsis(...)で省略して指定が分かりやすかったです。 - 「1.3.5 勾配の導出と逆伝播の実装」の勾配の実装が前巻とは変わっていて、最初に確保した
gradsのメモリを使い回す形になっています。
1.4 ニューラルネットワークで問題を解く
-
「1.4.3 学習用のソースコード」のミニバッチでランダムにデータを選ぶ実装が、エポック単位で
numpy.random.permutation()を使う形に変わりました。前巻では1バッチごとにnumpy.random.choice()していたのでバッチ間で使うデータが重複してしまう可能性があったのですが、この実装なら重複がなくなります。 -
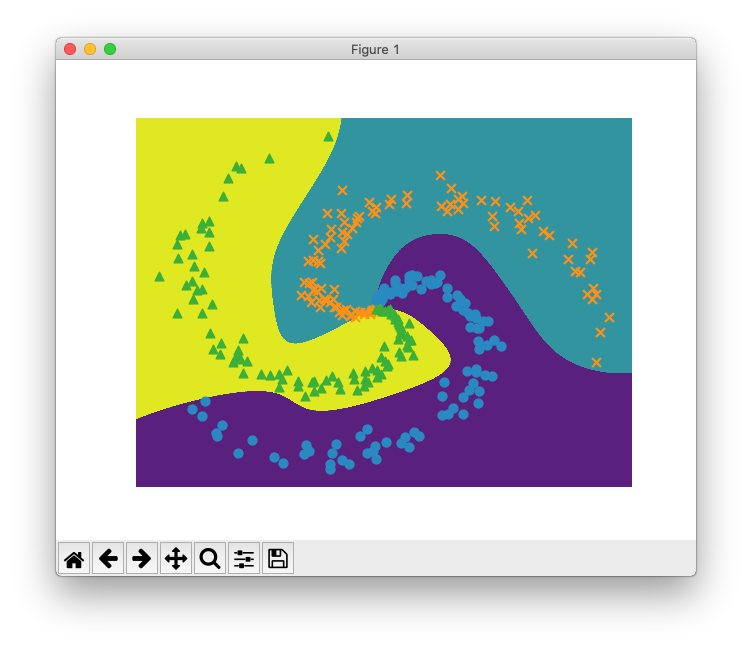
同じく「1.4.3 学習用のソースコード」で、本のソースコードを実行すると決定境界が可視化されるのですが、てっきり何か特殊な方法で境界を検出して範囲を塗りつぶすようなことをしているのかと思いソースコードを追ってみたところ、単純に座標を総当たりで推論して結果をプロットしているだけでした。当たり前といえば当たり前なのですが、何か泥臭くて面白いです。また、
numpy.meshgrid()などの便利な関数が用意されていて、このような可視化が数行でできてしまうのがPythonの(NumPyの?Matplotlibの?)すごいところです。
- 「1.4.4 Trainerクラス」の解説は確か前巻にはなかったと思いますが(前巻が会社のままテレワーク突入中)、前巻のソースコードではすでに取り入れられていた内容です。
1.5 計算の高速化
- 「1.5.1 ビット精度」は前巻の最終章で軽く解説されていましたが、具体的に16ビット浮動小数点の利用が始まっています。ただし過渡期なので、重みの保存時にだけ適用して容量を削減する方針になっています。
- 「1.5.2 GPU(CuPy)」も同様で、前巻では軽い解説のみでしたがCuPyの利用が始まりました。ただし基本はCPUによる実装になっているので、GPUがなくても大丈夫です。
1.6 まとめ
前巻のおさらいが中心なので、大きくつまずくところはありませんでした。ソースコードもいろいろと改良されていて良いですね。
この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。