はじめに
ふと思い立って勉強を始めた「ゼロから作るDeep Learning❷ーー自然言語処理編」の7章で私がつまずいたことのメモです。
実行環境はmacOS Catalina + Anaconda 2019.10、Pythonのバージョンは3.7.4です。詳細はこのメモの1章をご参照ください。
(このメモの他の章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / まとめ)
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
7章 RNNによる文章生成
この章は、前章でつくった言語モデルによる文章生成と、seq2seqという新しいモデルの解説です。なお、今回も自分で実装する時間が取れなかったので、本の実装を試すレベルに留まっています。ご了承ください。
7.1 言語モデルを使った文章生成
PTBコーパスから作った言語モデルでは、英語が苦手な私は結果の良し悪しがよくわからないので、前章で作った青空文庫の言語モデルで試してみました。
まず、前章でパープレキシティが105.19だったRNNLMを試すため、ch07/generate_text.pyを少し変更します。★の部分が変更点です。
# coding: utf-8
import sys
sys.path.append('..')
from rnnlm_gen import RnnlmGen
from dataset import aozorabunko # ★青空文庫のコーパスを利用するように変更
corpus, word_to_id, id_to_word = aozorabunko.load_data('train') # ★コーパス変更
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen(vocab_size=vocab_size) # ★語彙数指定(省略時はRnnlmの既定値=PTBの値になる)
model.load_params('../ch06/Rnnlm.pkl')
# start文字とskip文字の設定
start_word = 'あなた' # ★you
start_id = word_to_id[start_word]
skip_words = [] # ★前処理していないのでskip文字はなし
skip_ids = [word_to_id[w] for w in skip_words]
# 文章生成
word_ids = model.generate(start_id, skip_ids)
# ★日本語なので空白なしで連結、<eos>は句点+改行に置換
eos_id = word_to_id['<eos>']
txt = ''.join([id_to_word[i] if i != eos_id else '。\n' for i in word_ids])
txt = txt.replace('\n。\n', '\n') # 空行の除去
txt = txt.replace('」。\n', '」\n') # 会話の最後に句点をつけてしまったものを除去
print(txt)
そして「あなた」から生成した文章の結果です。何回か実行してみました。
あなたたちがかえって進んで来るんだから、しばらくすると、あの女の汽車のなかの紳士の方ですから、それでも江戸られまいといって、もう少し聞いたときは、まだ紀元前したかはぎとらと見えないのです。
かれはこのままで静かに渡ったらいないので、ごちゃごちゃのなけりゃとわらって、私はどうしてもぱみじんにくだけ文学調子で入り口のうちころす話しを与えたのです。
お嬢さんたちは失望尽そうとし
あなたに割り込んでそこにハトのお口へ送ったんですが、。
「それがその帰り、この家はぽんぽんするに』」
「くらいじゃありませんか」
「そうです」
「それから助からない。
」
「どうだ、手荒なんだか?」ジョバンニは楽器の頭の毛状の藁を通って思わず、飛んでしまいました。
それから海苔とというのはいいもといって金色のよう
あなたの楯に追いついた。
二人は返さずにいった。
ところがむずかしい否ふさいを、いつでも寝ていた。
ところが鏡の外で躁狂の頸はなんともいえぬまるで意味かも知れませんから、無声という音は次第で、どんな風には白難症の超然たる元々でいた何だか酒のこの藪のたった右の木には細長いこちらが正門の寸方がすぎて飯前たこチラッとたまりません。
そこで
なんとなく文章にはなりかけていますね。使っているコーパスが小説なので、何か小説っぽい文章ができています。
2番目の結果はカッコのつじつまがざっくり合っていて、カッコの開始と終了の関係をきちんと記憶できていることがわかります。
それにしても2番目の結果の「ハトのお口へ送ったんですが」から「ジョバンニは楽器の頭の毛状の藁を通って思わず、飛んでしまいました。」への展開、意味はさっぱりわかりませんがジワります![]()
つづいて、前章でパープレキシティ73.66まで下がった改良版を試してみます。以下、ch07/generate_better_text.py の変更版です。★の部分が変更点です。
# coding: utf-8
import sys
sys.path.append('..')
from common.np import *
from rnnlm_gen import BetterRnnlmGen
from dataset import aozorabunko # ★青空文庫のコーパスを利用するように変更
corpus, word_to_id, id_to_word = aozorabunko.load_data('train') # ★コーパス変更
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = BetterRnnlmGen(vocab_size=vocab_size) # ★語彙数指定(省略時はBetterRnnlmの既定値になる)
model.load_params('../ch06/BetterRnnlm.pkl')
# start文字とskip文字の設定
start_word = 'あなた' # ★you
start_id = word_to_id[start_word]
skip_words = [] # ★前処理していないのでskip文字はなし
skip_ids = [word_to_id[w] for w in skip_words]
# 文章生成
word_ids = model.generate(start_id, skip_ids)
# ★日本語なので空白なしで連結、<eos>は句点+改行に置換
eos_id = word_to_id['<eos>']
txt = ''.join([id_to_word[i] if i != eos_id else '。\n' for i in word_ids])
txt = txt.replace('\n。\n', '\n') # 空行の除去
txt = txt.replace('」。\n', '」\n') # 会話の最後に句点をつけてしまったものを除去
print(txt)
model.reset_state()
start_words = '人生 の 意味 は' # ★the meaning of life is
start_ids = [word_to_id[w] for w in start_words.split(' ')]
for x in start_ids[:-1]:
x = np.array(x).reshape(1, 1)
model.predict(x)
word_ids = model.generate(start_ids[-1], skip_ids)
word_ids = start_ids[:-1] + word_ids
# ★日本語なので空白なしで連結、<eos>は句点+改行に置換
txt = ''.join([id_to_word[i] if i != eos_id else '。\n' for i in word_ids])
txt = txt.replace('\n。\n', '\n') # 空行の除去
txt = txt.replace('」。\n', '」\n') # 会話の最後に句点をつけてしまったものを除去
print('-' * 50)
print(txt)
以下、「あなた」から始まる文章の生成結果です。
あなたにも知らずに、もぎ取ってしまった。
もっともこれからがぼくの気になれるのか、その人なら仕事にだきしめた時眼がかんかんつく。
slip'麭の御代と云う家族死の事、しらになる。
人が金を快楽を棄てる道具のつくのを天下と肩身のように水に残さん上なら、自ら世帯人種の歴史を読んで、四の二文字を見ても愉快だ。
お腹の代表
あなたが、私に話し給えと云った。
(僕はそんな碁だ。
あるところで、上野と来たのは門口行灯袴を持って続いている。
今年の夜中ぼろしで出るので勝手には行かない。
減る、手が高射泣きついて、まあ今ではとても楽がないくらいだ。
今は呑気だから、教師が上等な手段より持ち方を折ったじゃありませんか」
「なぜ」
「いいえまだ
あなたには行った事実があるので、目まいがしてそんなに来られたかな。
まだ病人なのか知らない。
いくら泳げてもどうしてもびかかってきたではありませんか。
この二十四。
私は床の上をぐるぐる回って、不安の顔を見合わせて客を捜している。
先生は二人とも午近く性、座敷へ帰ったまま歩き出した。
奥に東京へ二人で参れた頃の、次は少し賑やか
なんとなく、前の結果よりも日本語になっている感じはします。
なお、1つ目の結果で突然「slip'」という言葉が出てきたのでコーパスを調べてみたら、「吾輩は猫である」の中にmany a slip ' twixt the cup and the lip と 云う 西洋 の 諺 くらい は 心得 て いる だろ うという文章がありました。ここでしか使われていないので、やはりPTBコーパスのようにレアな単語の前処理をしないとダメですね![]()
続いて本と同じように「人生の意味は」の続きを語らせてみた結果です。
人生の意味は心の歴史と同じように思われたからだから、庭は終わるには落ちつかなかったのである。
あることは名文家に関係通りあるものだ。
砂の焼けたレンズが、圧力に打たれてもよいのだろうか。
あれほどが月々問題を見て、偽りをにやにや茶托に結んでいたから、これは精神的世界に大した刺激ではない。
ただ腹に目の結んだものである
人生の意味は作家の広告違だからきたなくなった。
それで未来を茶器をかためて、かえって死なないような気がした。
三四郎はこうざあい。
東京でも早く円を入れて一、五長を根堀りした人がぬすまれたと思って、いよいよこうなるというだけであった。
三四郎はその婦人の神様から主人と丸鞄の下にすわって、授業をするのもじっとしていた。
人生の意味はちょうどと、第二の遠いところを択んだのである。
しかしこういう顔が済んだ時、その言葉に。
私は今日午町へ行ったに始まった。
友達の生活な男は宿へ出ない歌い籠は、歴々と縞物のお光だから、今催促したと生きていたので、取り巻かれた十三飯をくれた母の顔であった。
先生はまたちょいと蔵の方
あまり深い言葉は出てきませんでしたが、確率的なロジックなので繰り返していると名言が生まれるかもしれません。
最後に「吾輩 は 犬 で ある」の続きを書かせてみます。
吾輩は犬である。
茶托に登りながら、前足で手を隔てたまま振りを落して見る。
はたきのいい部屋が手を入れている。
吾輩はあっけに取られた調子であった。
そこで異な眼でおわる。
水の先を見ると、ぱっと並んでいる。
余は表の畳から、潰す中に昼の親類がある。
しかし見てもよろしい男すら、この問いをうぶきーと、今日十万でもって来た
内容はよくわかりませんが、なんとなく小説らしきものを作ってくれました。
7.2 seq2seq
時系列データから時系列データに変換するseq2seqの説明です。本ではトイ・プロブレムとして足し算を扱っていますが、同じものを試しても面白くないので平方根を解かせてみることにしました。例えば入力に「2」を与えて「1.414」を出力させる形です。
作ったデータセットは単純で、0から49,999までの50,000個の数値とその平方根(有効桁数は4桁)のペアです。本のコードでそのまま学習できるように、桁を揃えて入出力を_で区切りました。以下、データセットの生成コードdataset/create_sqroot_dataset.pyです。これをdatasetディレクトリで動かせばsqroot.txtができます。
# coding: utf-8
import math
file_name = 'sqroot.txt'
with open(file_name, mode='w') as f:
for i in range(50000):
res = f'{math.sqrt(i):.4g}'
f.write(f'{i: <5}_{res: <5}\n')
生成したデータセットsqroot.txtの中身は次のような感じです。
0 _0
1 _1
2 _1.414
3 _1.732
4 _2
5 _2.236
6 _2.449
7 _2.646
8 _2.828
9 _3
10 _3.162
11 _3.317
12 _3.464
13 _3.606
14 _3.742
15 _3.873
16 _4
17 _4.123
18 _4.243
19 _4.359
(中略)
49980_223.6
49981_223.6
49982_223.6
49983_223.6
49984_223.6
49985_223.6
49986_223.6
49987_223.6
49988_223.6
49989_223.6
49990_223.6
49991_223.6
49992_223.6
49993_223.6
49994_223.6
49995_223.6
49996_223.6
49997_223.6
49998_223.6
49999_223.6
入力は5文字、出力は_を含めて6文字で、語彙数は足し算のデータセットと同じ13(足し算の+が減り、小数点の.が増えている)です。
7.3 seq2seqの実装
改良前の状態では、足し算同様になかなか正答率が上がりませんでした。
7.4 seq2seqの改良
データの反転と覗き見の改良を加えたものでは、なんとか平方根を求めてくれるようになりました。
以下、ch07/train_seq2seq.pyのソースです。★の部分が本のコードからの変更点です。ハイパーパラメーターは何回か試行し、隠れ層のサイズを少し大きくしました。
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from dataset import sequence
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from seq2seq import Seq2seq
from peeky_seq2seq import PeekySeq2seq
# データセットの読み込み
(x_train, t_train), (x_test, t_test) = sequence.load_data('sqroot.txt') # ★ データセット変更
char_to_id, id_to_char = sequence.get_vocab()
# Reverse input? =================================================
is_reverse = True # ★ 改良版
if is_reverse:
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
# ================================================================
# ハイパーパラメータの設定
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 192 # ★ 調整
batch_size = 128
max_epoch = 25
max_grad = 5.0
# Normal or Peeky? ==============================================
# model = Seq2seq(vocab_size, wordvec_size, hidden_size)
model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size) # ★ 改良版
# ================================================================
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose, is_reverse)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc * 100))
# グラフの描画
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(0, 1.0)
plt.show()
以下、実行結果の最後の部分です。
| epoch 25 | iter 1 / 351 | time 0[s] | loss 0.08
| epoch 25 | iter 21 / 351 | time 6[s] | loss 0.08
| epoch 25 | iter 41 / 351 | time 13[s] | loss 0.09
| epoch 25 | iter 61 / 351 | time 18[s] | loss 0.08
| epoch 25 | iter 81 / 351 | time 22[s] | loss 0.09
| epoch 25 | iter 101 / 351 | time 27[s] | loss 0.09
| epoch 25 | iter 121 / 351 | time 32[s] | loss 0.08
| epoch 25 | iter 141 / 351 | time 38[s] | loss 0.08
| epoch 25 | iter 161 / 351 | time 43[s] | loss 0.09
| epoch 25 | iter 181 / 351 | time 48[s] | loss 0.08
| epoch 25 | iter 201 / 351 | time 52[s] | loss 0.08
| epoch 25 | iter 221 / 351 | time 56[s] | loss 0.09
| epoch 25 | iter 241 / 351 | time 61[s] | loss 0.08
| epoch 25 | iter 261 / 351 | time 66[s] | loss 0.09
| epoch 25 | iter 281 / 351 | time 72[s] | loss 0.09
| epoch 25 | iter 301 / 351 | time 77[s] | loss 0.08
| epoch 25 | iter 321 / 351 | time 81[s] | loss 0.09
| epoch 25 | iter 341 / 351 | time 85[s] | loss 0.09
Q 27156
T 164.8
☑ 164.8
---
Q 41538
T 203.8
☑ 203.8
---
Q 82
T 9.055
☒ 9.124
---
Q 40944
T 202.3
☑ 202.3
---
Q 36174
T 190.2
☑ 190.2
---
Q 13831
T 117.6
☑ 117.6
---
Q 16916
T 130.1
☑ 130.1
---
Q 1133
T 33.66
☒ 33.63
---
Q 31131
T 176.4
☑ 176.4
---
Q 21956
T 148.2
☑ 148.2
---
val acc 79.000%
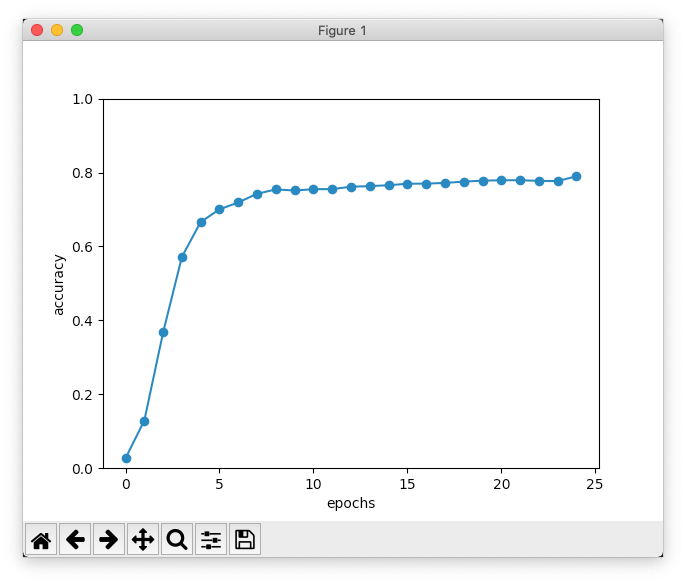
なんとか80%弱の正解率になりました。ハイパーパラメーターをもう少し調整すると改善できるかも知れませんが、やはり足し算でうまくいくモデルを単純に使っても、簡単には高い精度を出せないことがわかりました。扱う問題に合わせたモデルの選択や調整はなかなか難しそうです。
7.5 seq2seqを用いたアプリケーション
チャットボットやイメージキャプションのような実例を見ると、いろいろと夢が広がります。裏では先人の方々の多くの試行錯誤があったのかと思うと、なんというか感慨深いです。
7.6 まとめ
この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。