はじめに
ふと思い立って勉強を始めた「ゼロから作るDeep Learning❷ーー自然言語処理編」の3章で私がつまずいたことのメモです。
実行環境はmacOS Catalina + Anaconda 2019.10、Pythonのバージョンは3.7.4です。詳細はこのメモの1章をご参照ください。
(このメモの他の章へ:1章 / 2章 / 3章 / 4章 / 5章 / 6章 / 7章 / 8章 / まとめ)
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
3章 word2vec
この章では、シンプルなword2vecを実装します。
3.1 推論ベースの手法とニューラルネットワーク
単語の意味を理解させる手法として、2章でシソーラスを使うものとカウントベースの2つを学びましたが、3番目としてニューラルネットワークを使った推論ベースの手法を学びます。
3.2 シンプルなword2vec
シンプルなword2vecとして、2つのモデルのうちのCBOWモデルを実装します。
3.3 学習データの準備
学習データの準備については、特につまずく点はありませんでした。
3.4 CBOWモデルの実装
CBOWモデル自体はシンプルなので大きくつまずく点はなかったのですが、コードの理解は少し大変でした。今回作る3つのMatMulレイヤーのうちの2つは同じ重み$ W_{in} $を共有しており、重みを束ねているリストの中でも共有された要素がでてきます。そのため、各オブジェクトがどのように共有されているのかの理解が必要です。
整理のために、登場する2つの重み( $W_{in}$、$W_{out}$ )と3つの勾配(ここでは $ grad_{in1}$、$grad_{in2}$、$grad_{out}$ とします)に注目して、本のコードを追ってみます。
まず、SimpleCBOW.__init__() で $W_{in}$ と $W_{out}$ を生成します。
class SimpleCBOW:
def __init__(self, vocab_size, hidden_size):
# (中略)
# 重みの初期化
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
そして、MatMulオブジェクトを3つ生成し、それぞれ SimpleCBOW.in_layer0 、 SimpleCBOW.in_layer1 、 SimpleCBOW.out_layer に代入します。
# レイヤの生成
self.in_layer0 = MatMul(W_in)
self.in_layer1 = MatMul(W_in)
self.out_layer = MatMul(W_out)
重みを受け取った MatMul.__init__() 側では、それをMatMul.paramsに代入します。また、3つのMatMulオブジェクトの中でそれぞれの勾配( $ grad_{in1}$、$grad_{in2}$、$grad_{out}$ )を生成し MatMul.gradsに代入します。
class MatMul:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
この時、2つの重み( $W_{in}$、$W_{out}$ )と3つの勾配( $ grad_{in1}$、$grad_{in2}$、$grad_{out}$ )と各オブジェクトの関係は、こんな感じになっています。
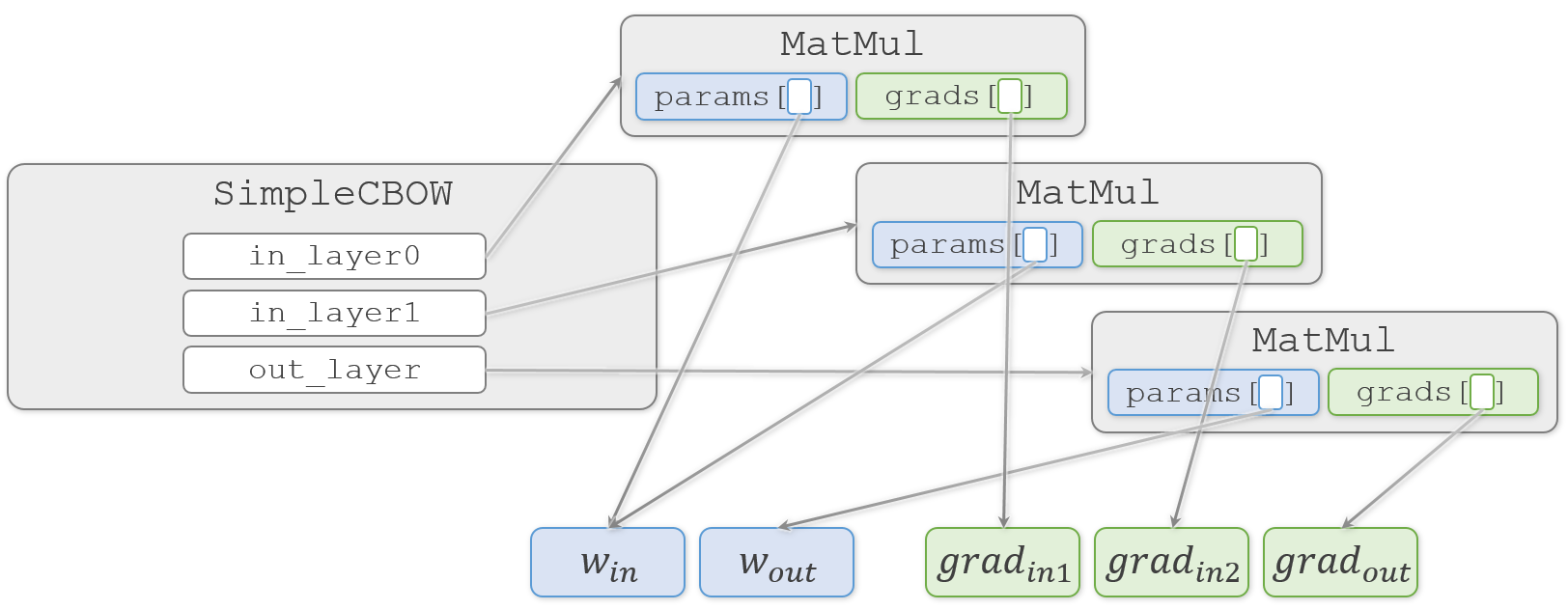
塗りつぶしていない四角はそこに実体がなく、矢印の先の実体を指しています(実際には MatMul.params や MatMul.grads などのリストも MatMul オブジェクトの中に実体がある訳ではないのですが、今注目したいのは重みと勾配なので、それ以外については簡略化してオブジェクトの中に書いています)。
SimpleCBOW.__init__() に戻ります。
生成した3つのMatMulオブジェクトから重みを取り出して SimpleCBOW.params リストへ代入し、同様に勾配を取り出して SimpleCBOW.grads リストへ代入します。
class SimpleCBOW:
def __init__(self, vocab_size, hidden_size):
# (中略)
# すべての重みと勾配をリストにまとめる
layers = [self.in_layer0, self.in_layer1, self.out_layer]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
ここまでの重みや勾配の代入はすべて浅いコピー(shallow copy)です。そのため、重みや勾配の複製は行われず、実体(塗りつぶした四角)は1つのままです。
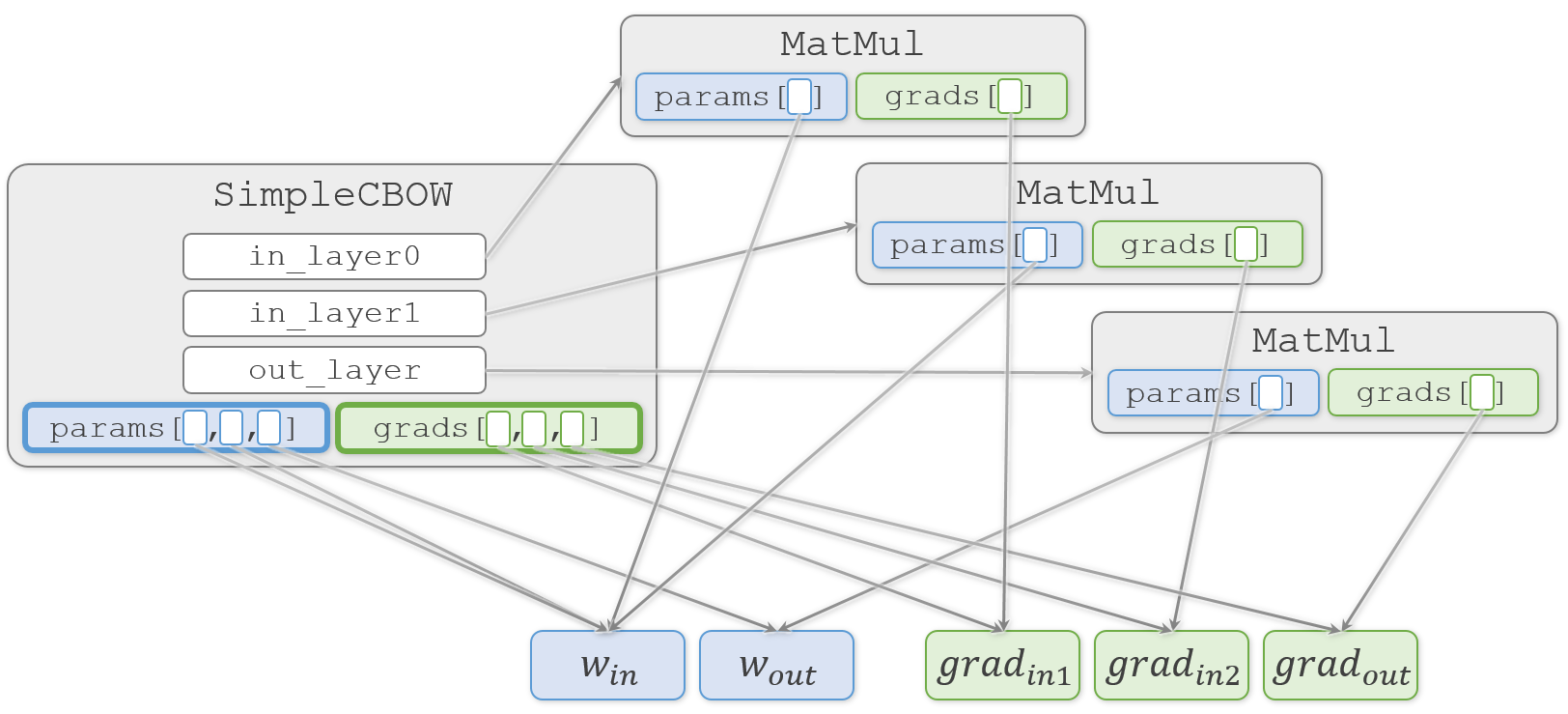
そして、結果になる SimpleCBOW.word_vecs へ重みを代入します。
# メンバ変数に単語の分散表現を設定
self.word_vecs = W_in
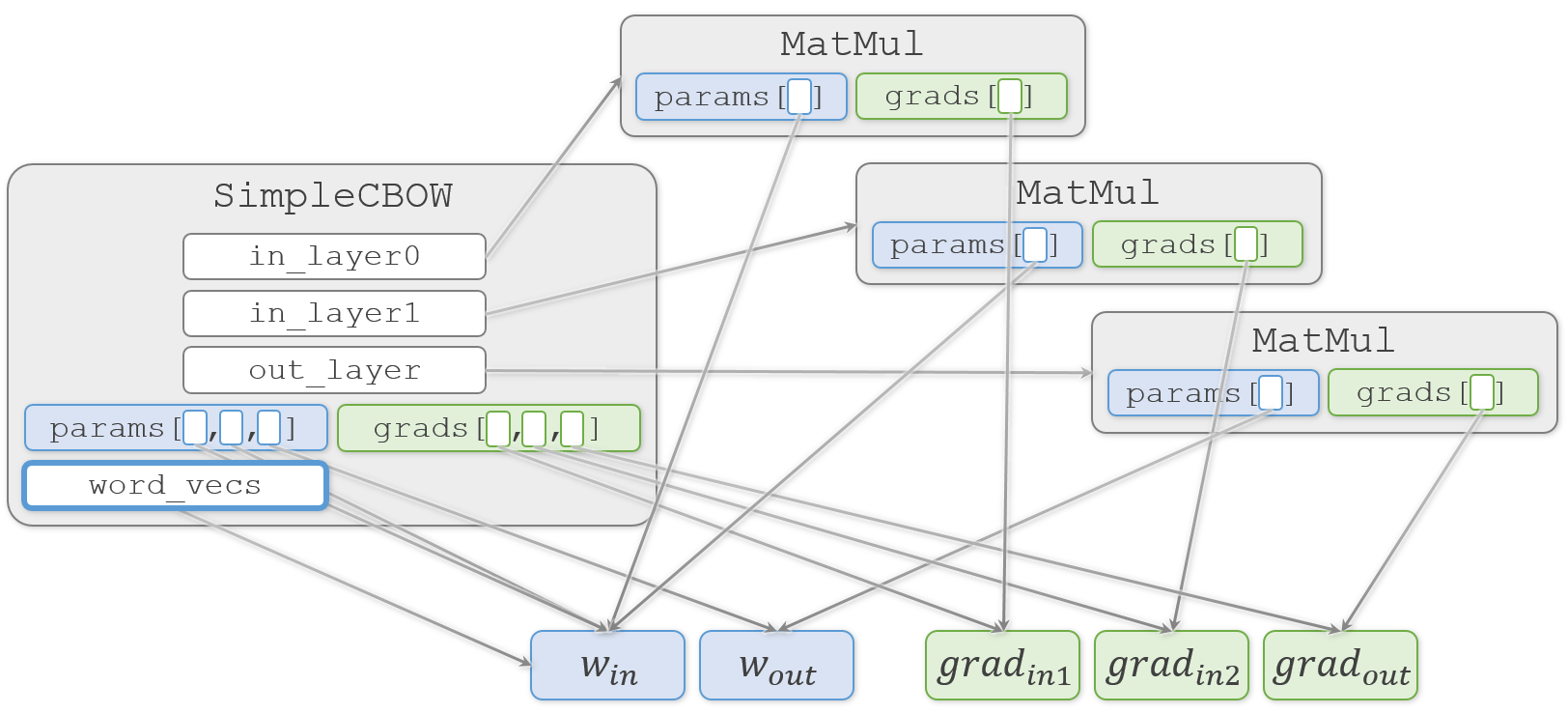
わかりやすく説明しようとして描き始めた図が、矢印だらけでわかりにくくなってきました![]()
おさらいですが、この図では矢印の先のオブジェクトを矢印の元で共有していることを示しています。そのため、矢印の先のオブジェクトをどこかで更新すると、それを見ている矢印の元でも更新されていることになります。
続いて、メインのコードである train.py に移ります。
まず SimpleCBOW オブジェクトと Adam オブジェクトを生成し、作ったオブジェクトを Trainer オブジェクトの生成時に渡します。
model = SimpleCBOW(vocab_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
受け取った Trainer.__init__() 側では、それをTrainer.model と Trainer.optimizer に代入します。
class Trainer:
def __init__(self, model, optimizer):
self.model = model
self.optimizer = optimizer
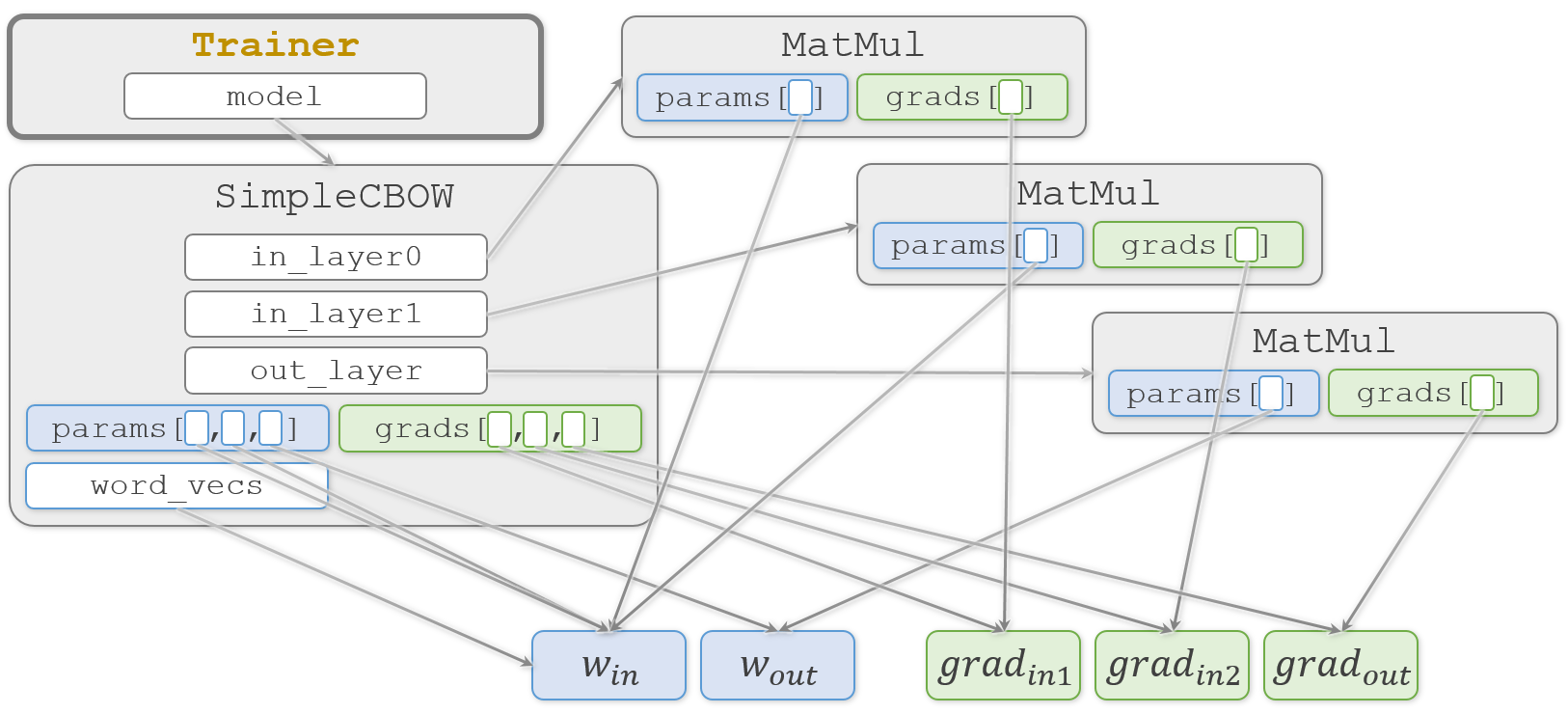
図をシンプルにするため、今回あまり関係しない Adam オブジェクトは図から省いています。
ここまでで学習に必要なオブジェクトが完成しました。続いて学習です。学習の実装は Trainer.fit() です。
trainer.fit(contexts, target, max_epoch, batch_size)
Trainer.fit() の中では Trainer.model.forward() で順伝播し、Trainer.model.backward() で逆伝播します。
class Trainer:
def fit(self, x, t, max_epoch=10, batch_size=32, max_grad=None, eval_interval=20):
#(中略)
model, optimizer = self.model, self.optimizer
#(中略)
for epoch in range(max_epoch):
#(中略)
for iters in range(max_iters):
#(中略)
# 勾配を求め、パラメータを更新
loss = model.forward(batch_x, batch_t)
model.backward()
逆伝播の Trainer.model.backward() の実装は SimpleCBOW.backward() です。この中では各レイヤーの逆伝播である SimpleCBOW.out_layer.backward()、SimpleCBOW.in_layer1.backward()、SimpleCBOW.in_layer0.backward() を呼び出します。
class SimpleCBOW:
def backward(self, dout=1):
ds = self.loss_layer.backward(dout)
da = self.out_layer.backward(ds)
da *= 0.5
self.in_layer1.backward(da)
self.in_layer0.backward(da)
return None
いずれのレイヤーも実行される関数は MatMul.backward() です。
class MatMul:
def backward(self, dout):
W, = self.params
dx = np.dot(dout, W.T)
dW = np.dot(self.x.T, dout)
self.grads[0][...] = dW
return dx
ここで MatMul.grads[0] を更新するので、結果として各レイヤーに対応する3つの勾配( $ grad_{in1}$、$grad_{in2}$、$grad_{out}$ )を更新することになります。
ここまでの学習の流れを図の中で黄色にしてみました。

Trainer.fit() の続きに戻ります。
ここまでの処理で勾配情報の Trainer.model.grads リストが更新されたので、これを使って重み情報の Trainer.model.params リストを更新します。ただし、このリストには中身の重複があるので、特殊な処理が入っています。
params, grads = remove_duplicate(model.params, model.grads) # 共有された重みを1つに集約
本では remove_duplicate() の解説が省略されていますが、中を覗いてみます。
def remove_duplicate(params, grads):
'''
パラメータ配列中の重複する重みをひとつに集約し、
その重みに対応する勾配を加算する
'''
params, grads = params[:], grads[:] # copy list
まず渡された重みと勾配のリストを複製します。この複製により SimpleCBOW.params と SimpleCBOW.grads とは別のリストオブジェクト params と grads が生成されます。ただし、その中身は複製されません。図の下の部分になります。
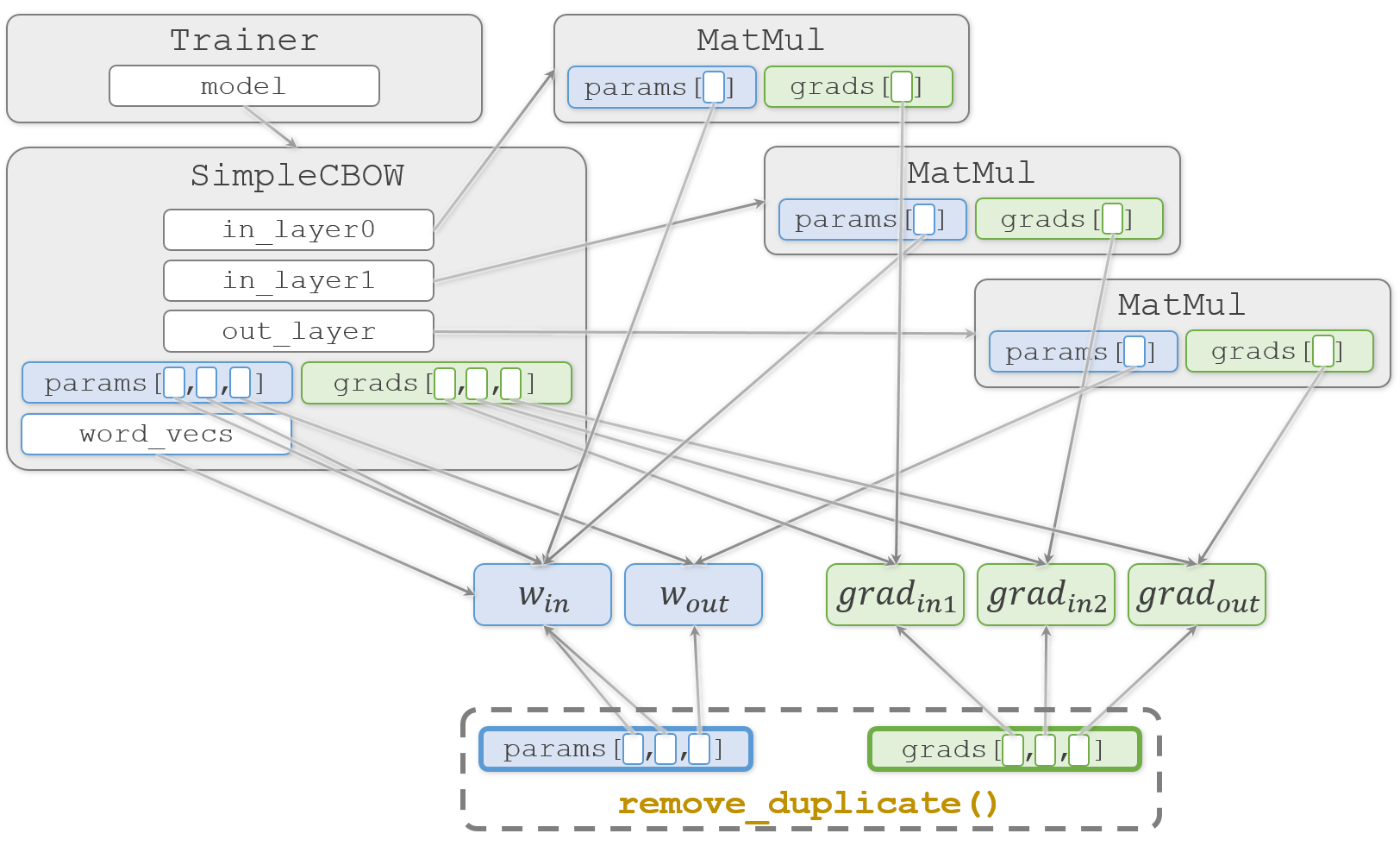
続いて、重複している重みを総当たりで探します。
while True:
find_flg = False
L = len(params)
for i in range(0, L - 1):
for j in range(i + 1, L):
# 重みを共有する場合
if params[i] is params[j]:
grads[i] += grads[j] # 勾配の加算
find_flg = True
params.pop(j)
grads.pop(j)
# (中略)
if find_flg: break
if find_flg: break
if not find_flg: break
return params, grads
if params[i] is params[j]: で、オブジェクトが同じものかどうかをチェックします。ここで、i が 0、j が 1 の時に、どちらも同じ $W_{in}$ を指していることがわかり、中の処理に進みます。
# 重みを共有する場合
if params[i] is params[j]:
grads[i] += grads[j] # 勾配の加算
find_flg = True
params.pop(j)
grads.pop(j)
ここで $W_{in}$ に対応する2つの勾配 $ grad_{in1}$ と $grad_{in2}$ を加算して $ grad_{in1}$ を更新します。そして、params と grads の両方のリストから2番目の要素を削除することで、更新対象の重みを2つにします。
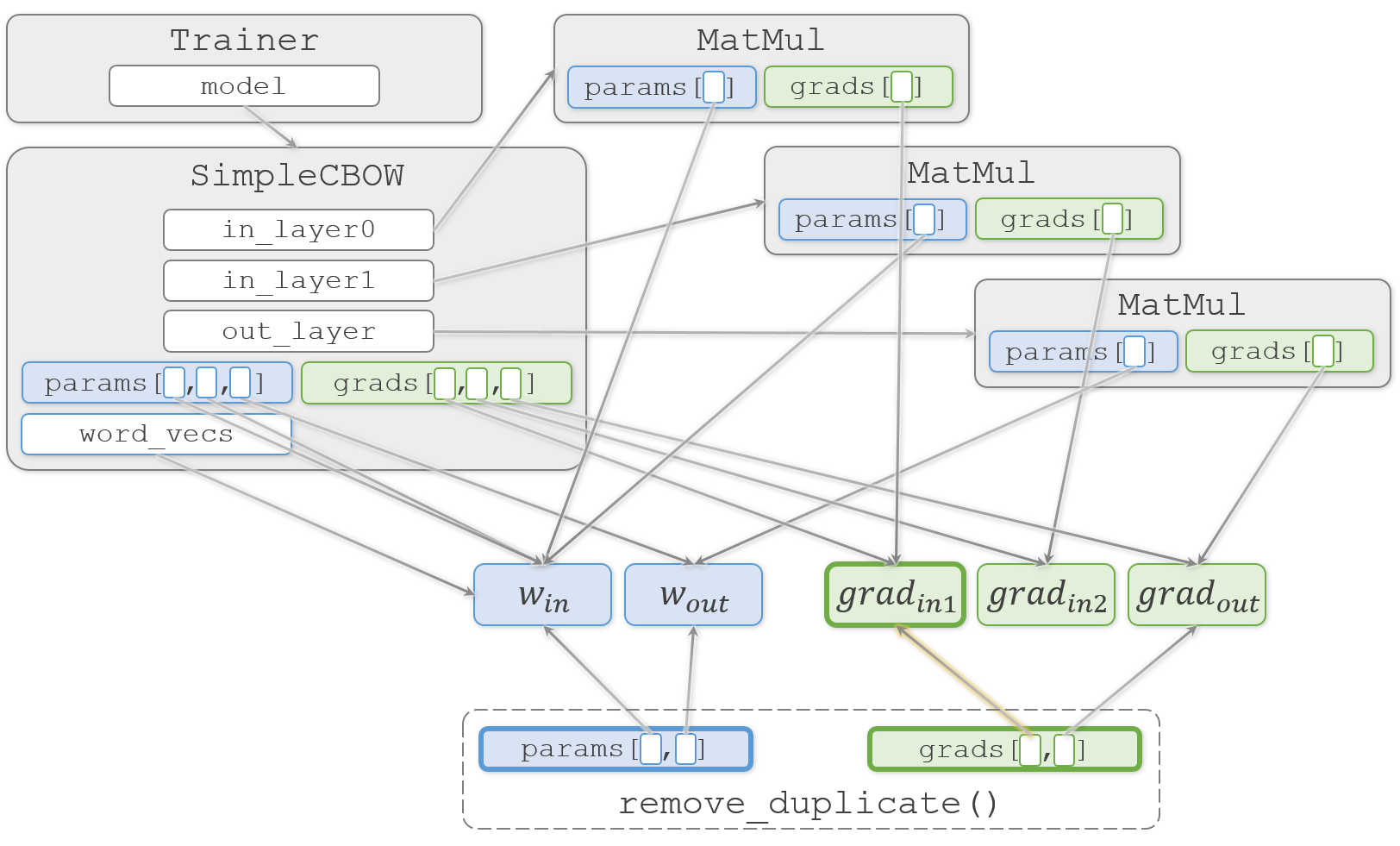
重みの重複を除く理由は、除かないと1回のイテレーションで $W_{in}$ を2回更新してしまうからです。2回更新してしまうと困るのは、更新時のAdamの挙動が変わってしまうためです。
AdamはMomentumとRMSPropを掛け合わせたようなアルゴリズムで、Momentumは勾配の移動平均を使うことで振動を抑え、RMSPropは振動時の学習率を抑えることで振動を抑えます。どちらも以前の勾配情報を蓄積しながら調整するのですが、 $W_{in}$ を入力レイヤー#0用と#1用とで2回に分けて更新してしまうと、それぞれ独立して以前の勾配情報を蓄え振動を抑えようとするために、入力レイヤー#0用と#1用を交互で更新することによる振動が考慮できません。そのため、両方の勾配を足し合わせて1度で更新する必要があります。
なお、Adamについては @omiita さんの 【2020決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法- がスーパーわかりやすいです。
1つ気になるのは、2レイヤー分を1回で更新するために $ grad_{in1}$ へ $ grad_{in2}$ の勾配を足しこんでしまうので、SimpleCBOW.in_layer0のMauMulオブジェクトから見ると、勾配情報が勝手に破壊されてしまう点です。ただ、破壊前の勾配は次回のイテレーションまでもう使われることはなく、次回の逆伝播で正しい値で上書きされるので気にしないで大丈夫です。この辺りの実装方法が少し気持ち悪く感じる方もいるかとは思いますが、無駄な複製を防ぐ措置だと思います。
remove_duplicate() の続きに戻ります。
重複を除いた際に find_flg を立てているので、後続の2つの break が実行されて、再び総当たりのチェックをやり直します。今回は他に重みの重複はないので、結果として要素数が2のparams と grads が返ります。
そして、Trainer.fit() の続きに戻ります。
optimizer.update(params, grads)
optimizer は Adam オブジェクトです。要素数が2つになった params と grads を Adam.update() に渡して実行し、$W_{in}$ と $W_{out}$ を更新する形になります。
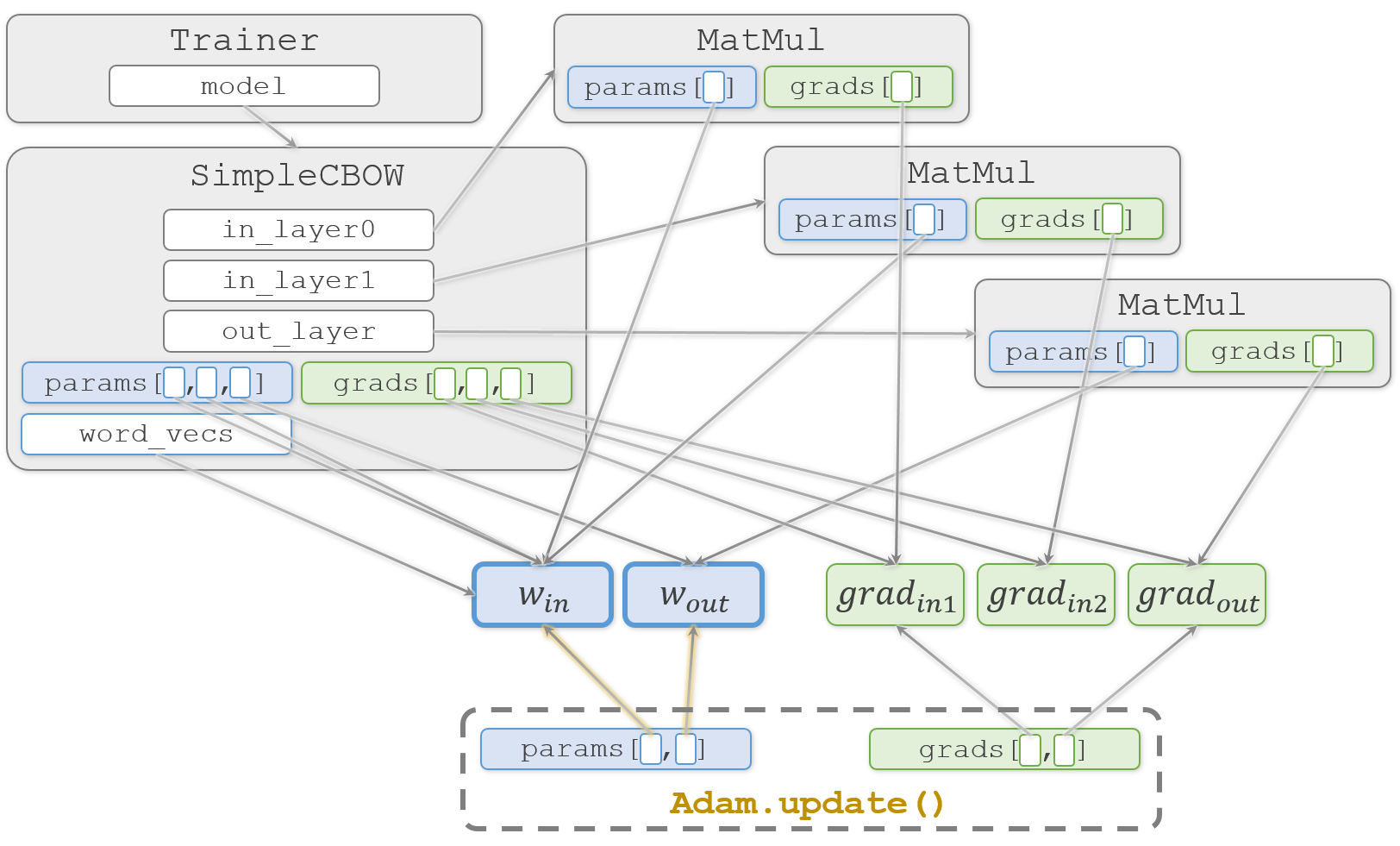
これを繰り返して学習を進めます。これで Trainer.fit()の処理が終わります。
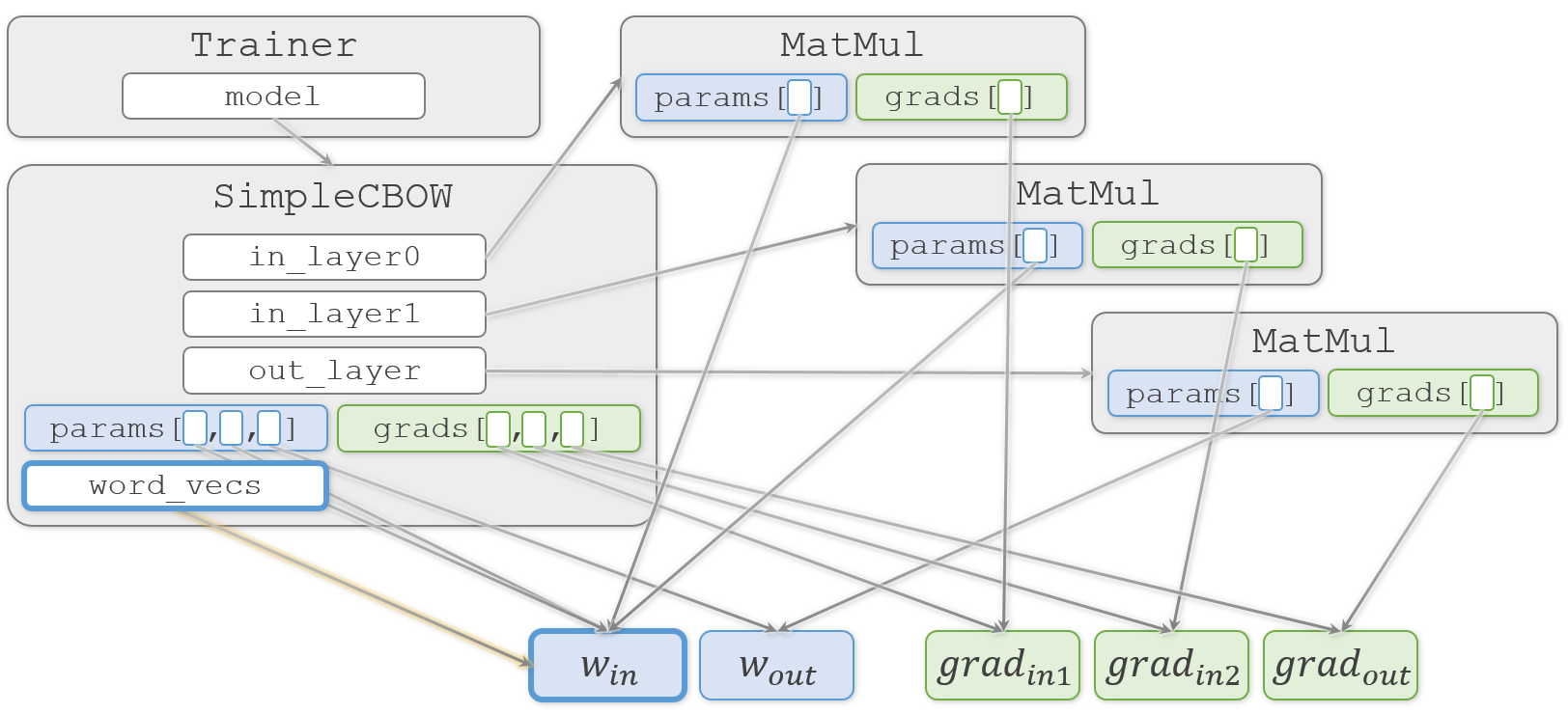
最後に完成した単語の分散表現をSimpleCBOW.word_vecs から取り出して完了です。
word_vecs = model.word_vecs
for word_id, word in id_to_word.items():
print(word, word_vecs[word_id])
you [ 0.93458694 1.6282444 0.94795746 -0.92400223 0.8647629 ]
say [-1.2477087 0.24887817 -1.199617 0.8608295 -1.2035855 ]
goodbye [ 0.92808425 0.01414002 0.9206358 -1.155395 1.0054088 ]
and [-0.72053814 1.7237687 -0.74599844 1.3244902 -0.7532529 ]
i [ 0.91120744 0.01902297 0.92178065 -1.1321857 1.0154353 ]
hello [ 0.9499151 1.6287371 0.96806735 -0.9076484 0.87147075]
. [-1.3032959 -1.5691308 -1.2686406 -1.2225806 -1.2338196]
おつかれさまでした。
Pythonは普通にコードを書くとオブジェクトが共有されまくるので、いつの間にか値が書き変えられていた!という事故が起きてしまいがちです。共有して良いのか複製が必要なのかは、常に気にしておかないといけません。なお共有と複製については、Pythonのcopy関数とdeepcopy関数の違いと使い方の解説がわかりやすかったです。
3.5 word2vecに関する補足
word2vecのもう1つのモデルであるskip-gramが紹介されています。また、カウントベースと推論ベースの論争(?)についても紹介されています。
3.6 まとめ
この章でCBOWの実装は終わりましたが、まだまだシンプルな形で大きなコーパスには耐えられず、前章のように青空文庫で遊ぶことができません。次の章で高速化が終わったら試してみたいですね。
この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。