Christopher Olah氏のブログ記事
http://colah.github.io/posts/2015-08-Understanding-LSTMs/
の翻訳です。
翻訳の誤りなどあればご指摘お待ちしております。
リカレントニューラルネットワーク
人間は毎秒ゼロから思考を開始することはありません。このエッセイを読んでいる間、あなたは前の単語の理解に基づいて、各単語を理解します。すべてを捨てて、またゼロから思考を開始してはいません。あなたの思考は持続性を持っています。
従来のニューラルネットワークは、これを行うことができません、それは大きな欠点のように思えます。たとえば、映画の中の各時点でどのような種類の出来事が起こっているかを分類したいと想像してください。従来のニューラルネットワークが、映画の前の出来事についての推論を後のものに教えるためにどのように使用できるかは不明です。
リカレントニューラルネットワークは、この問題に対処します。それは内部にループを持ち、情報を持続させることができるネットワークです。

リカレントニューラルネットワークはループを持つ
上の図で、ニューラルネットワークのかけら、 $A$ は、入力 $x_t$ を見て、値 $h_t$ を出力します。ループは、情報をネットワークの1ステップから次のステップに渡すことを可能にします。
このようなループにより、リカレントニューラルネットワークは不可解なものに思われます。しかし、もう少し考えると、それが通常のニューラルネットワークとそれほど違いがないことが判ります。リカレントニューラルネットワークは、同じネットワークの複数のコピーであり、それぞれが後続のネットワークにメッセージを渡すと考えることができます。
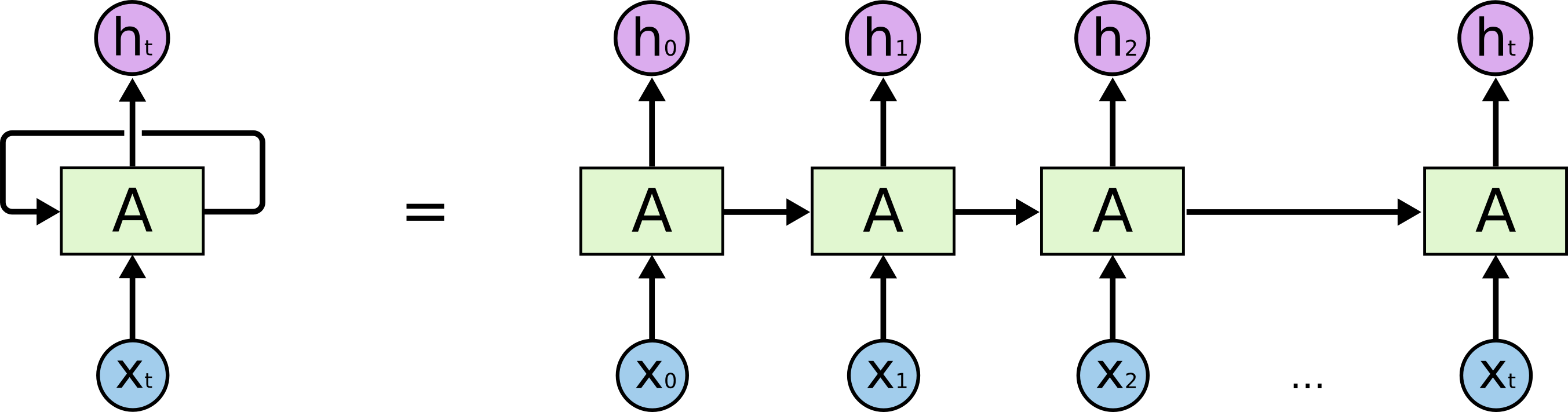
展開されたリカレントニューラルネットワーク
この鎖状の性質は、リカレントニューラルネットワークが配列やリストに密に関連していることを明らかにします。それは、このようなデータに使用するための自然なアーキテクチャです。
そして、それは確かに使用されています!ここ数年、さまざまな問題にRNNが適用され、信じられないほどの成功がありました:音声認識、言語モデリング、翻訳、画像キャプション…リストは続きます。RNNにより達成することができる、驚くべき偉業に関する議論は、 Andrej Karpathy の優れたブログ記事、リカレントニューラルネットワークの理不尽な効力に託します。でも、それらは本当にかなり素晴らしいです。
これらの成功に欠かせないことに、「LSTM」の使用があります。LSTMは非常に特別な種類のリカレントニューラルネットワークであり、多くのタスクにおいて、標準バージョンよりもはるかに優れた働きをします。リカレントニューラルネットワークに基づくほぼすべてのエキサイティングな結果は、これを用いて達成されています。このエッセイが探求するのは、これらLSTMです。
長期依存性の問題
RNNのアピールの1つは、前のビデオ・フレームの使用が現在のフレームの理解を助けるように、前の情報を現在のタスクに関係づけることができるというアイデアです。RNNにこれができれば、RNNはとても役に立つでしょう。しかし、できるでしょうか?それは場合によります。
時おり、私たちは現在のタスクを実行するのに、最新の情報を見てする必要があります。例えば、言語モデルが、以前の単語に基づいて、次の単語の予測を行うと考えてください。「the clouds are in the sky,」の最後の単語を予測する場合、これ以外のコンテキストを必要としません、次の単語が sky になることはかなり明白です。このように関連する情報とそれを必要とする場所のギャップが小さい場合、RNNは過去の情報を利用することを学習することができます。
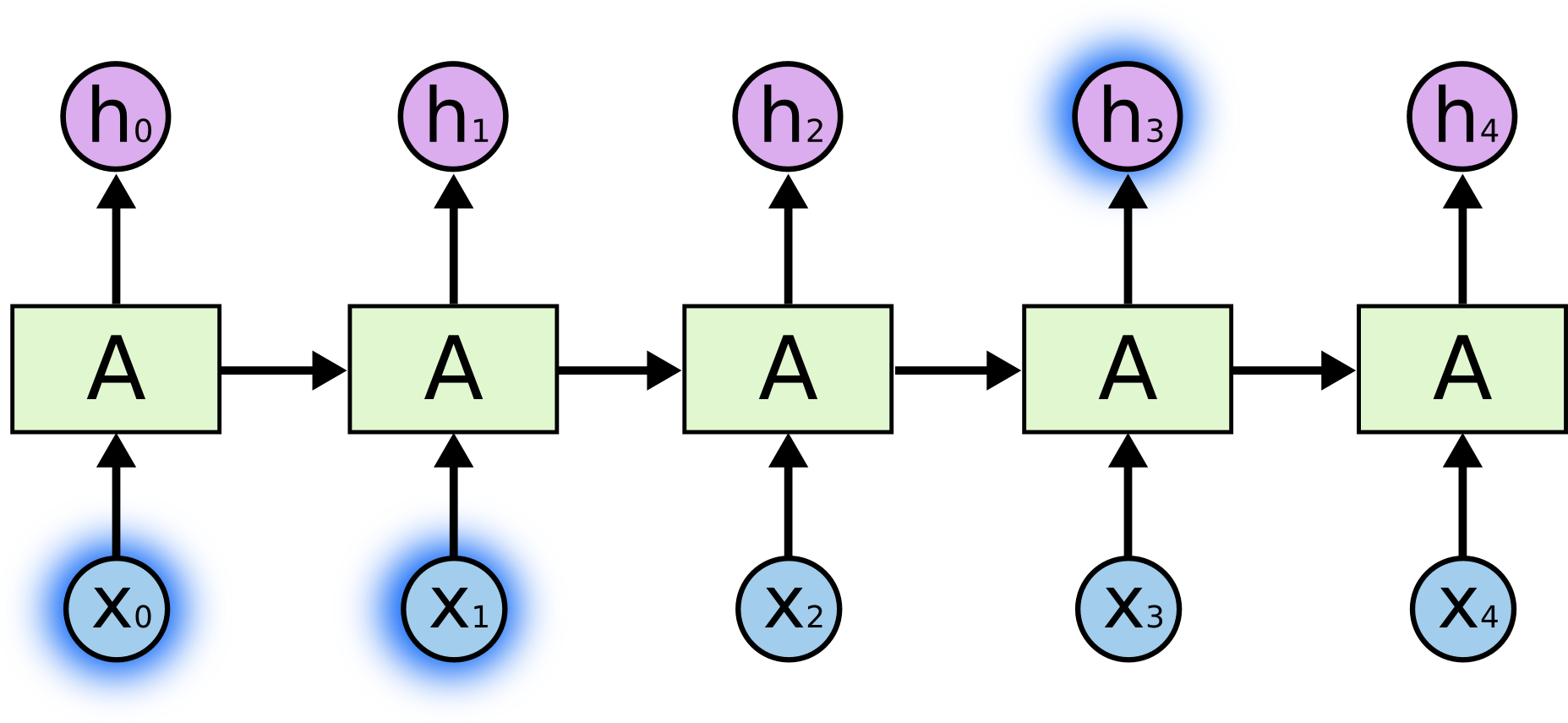
しかし、より多くのコンテキストを必要とする場合もあります。テキスト「 I grew up in France… I speak fluent French. 」の最後の単語の予測を試みると考えてみましょう。直近の情報は、次の単語がおそらく言語の名前であることを示唆していますが、どの言語か絞り込みたい場合、さらに後ろから、 France のコンテキストを必要とします。関連する情報とそれを必要とする場所のギャップが非常に大きくなることも十分あり得ます。
残念ながら、ギャップが大きくなるに従い、RNNは情報を関連づけて学習することができなくなります。
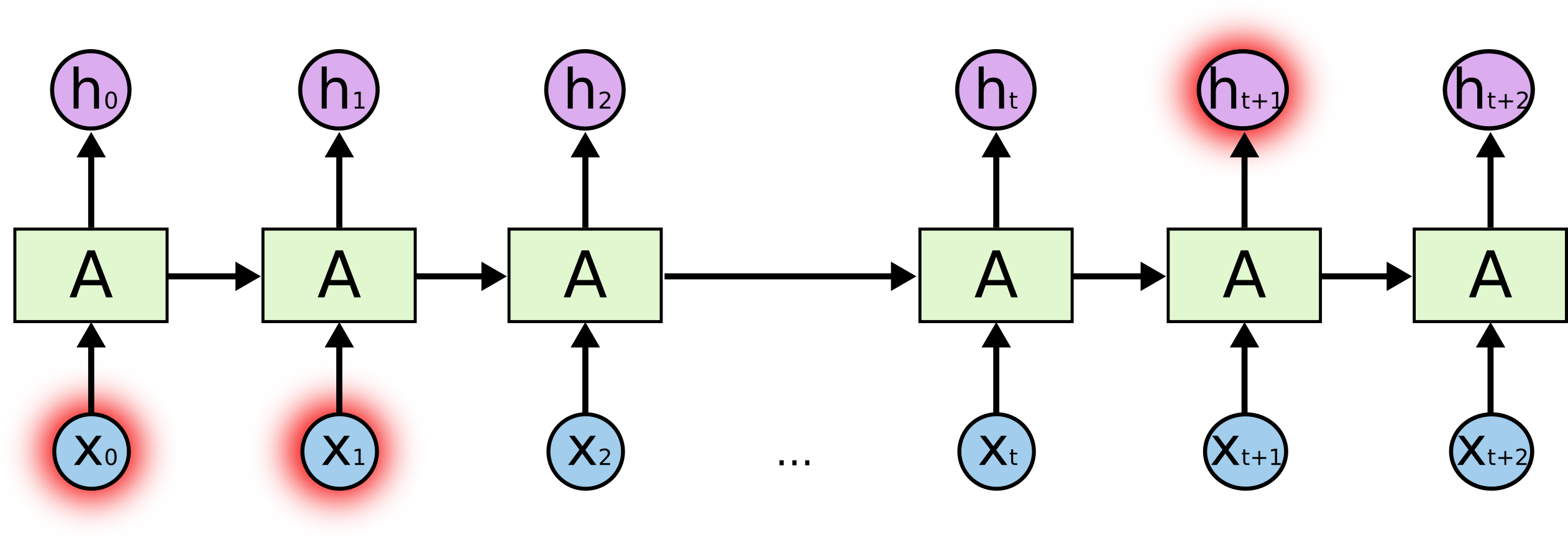
理論上、RNNはこのような「長期の依存性」を取り扱うことが十分できます。この形式の例題(toy problems)を解決するために、人が慎重にパラメータを選ぶことはできます。悲しいことに、実際には、RNNがそれを学習できるようにはならないようです。この問題は Hochreiter (1991) [ドイツ語] と Bengio, et al. (1994) により徹底的に調査され、それが難しいいくつかのかなり基本的な理由が見つかりました。
ありがたいことに、LSTMにはこの問題がありません。
LSTMネットワーク
Long Short Term Memory ネットワークは、通常は「LSTM」と呼ばれ、長期的な依存関係を学習することのできる、RNNの特別な一種です。これらは Hochreiter & Schmidhuber(1997) により導入され、後続の研究1で多くの人々によって洗練され、広められました。それは多種多様な問題にものすごくよく動作し、現在では広く使用されています。
LSTMは長期の依存性の問題を回避するように明示的に設計されています。長時間の情報を記憶することは実質的にそのデフォルトの動作であり、学習するのに苦労はありません!
すべてのリカレントニューラルネットワークは、ニューラルネットワークのモジュールを繰り返す、鎖状をしています。標準のRNNでは、この繰り返しモジュールは、単一の tanh 層という、非常に単純な構造を持ちます。

標準RNNの繰り返しモジュールは単一の層を含む
LSTMもまたこの鎖のような構造を持ちますが、繰り返しモジュールは異なる構造を持ちます。単一のニューラルネットワーク層ではなく、非常に特別な方法で相互作用する、4つの層を持ちます。

LSTMの繰り返しモジュールは4つの相互作用する層を含む
詳細については心配しないでください。後に一歩一歩LSTMの図を見ていきます。今のところは、後で使用する表記を覚えておきましょう。

上の図で、それぞれの線は、ベクトル全体を、一つのノードの出力から他のノードの入力に運びます。ピンクの円は、ベクトルの加算のような、一点の操作を表し、黄色のボックスは、学習されるニューラルネットワークの層です。合流している線は連結を意味し、分岐している線は内容がコピーされ、そのコピーが別の場所に行くことを意味します。
LSTMの中心的アイデア
LSTMの鍵は、セル状態、図の上部を通る水平線です。
セル状態は一種のコンベア・ベルトのようなものです。それはいくつかのマイナーな線形相互作用のみを伴い、鎖全体をまっすぐに走ります。情報は不変で、それに沿って流れることは非常に簡単です。
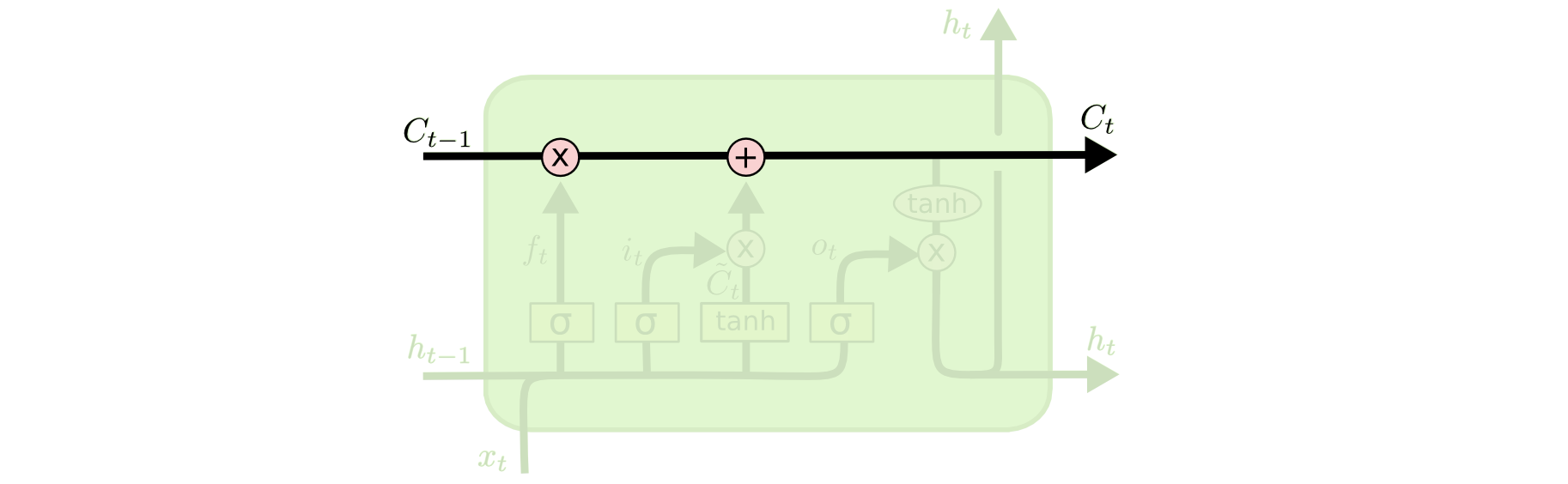
LSTMは、セル状態に対し情報を削除したり追加する機能を持っています。この操作はゲートと呼ばれる構造によりしっかり制御されます。
ゲートは選択的に情報を通す方法です。これはシグモイド・ニューラルネット層と一点の乗算により構成されます。
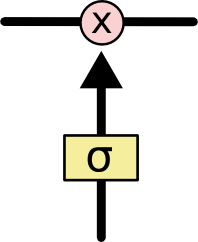
シグモイド層は0から1までの数値を出力します。この数値は各コンポーネントをどの程度通すべきかを表します。0は「何も通さない」を、1は「全てを通す」を意味します!
LSTMは、セル状態を保護し、制御するために、このようなゲートを3つ持ちます。
ステップ・バイ・ステップLSTMウォークスルー
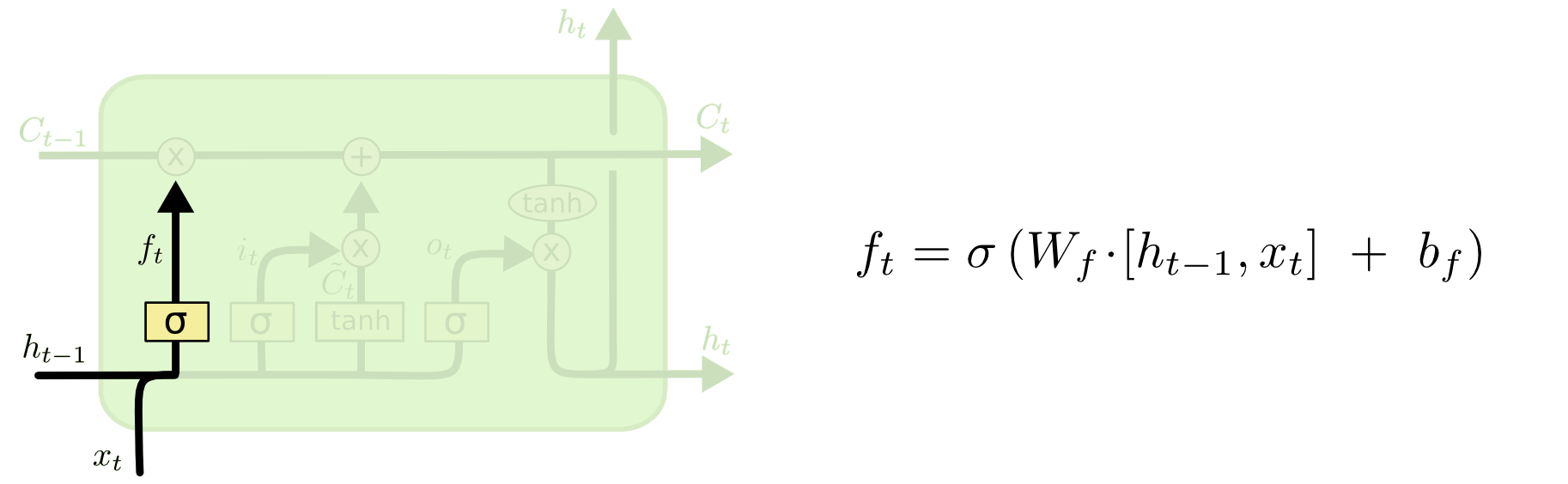
LSTMの最初のステップは、セル状態から捨てる情報を判定することです。この判定は「忘却ゲート層」と呼ばれるシグモイド層によって行われます。それは、 $h_{t-1}$ と $x_t$ を見て、セル状態 $C_{t-1}$ の中の各数値のために $0$ と $1$ の間の数値を出力します。 $1$ は「完全に維持する」を表し、 $0$ は「完全に取り除く」を表します。
では、前のすべての単語に基づいて次の単語を予測する、言語モデルの例に戻りましょう。このような問題では、正しい代名詞を使用するために、セル状態は現在の主語の性別を含むかもしれません。新しい主語を見るときには、古い主語の性別は忘れたいです。
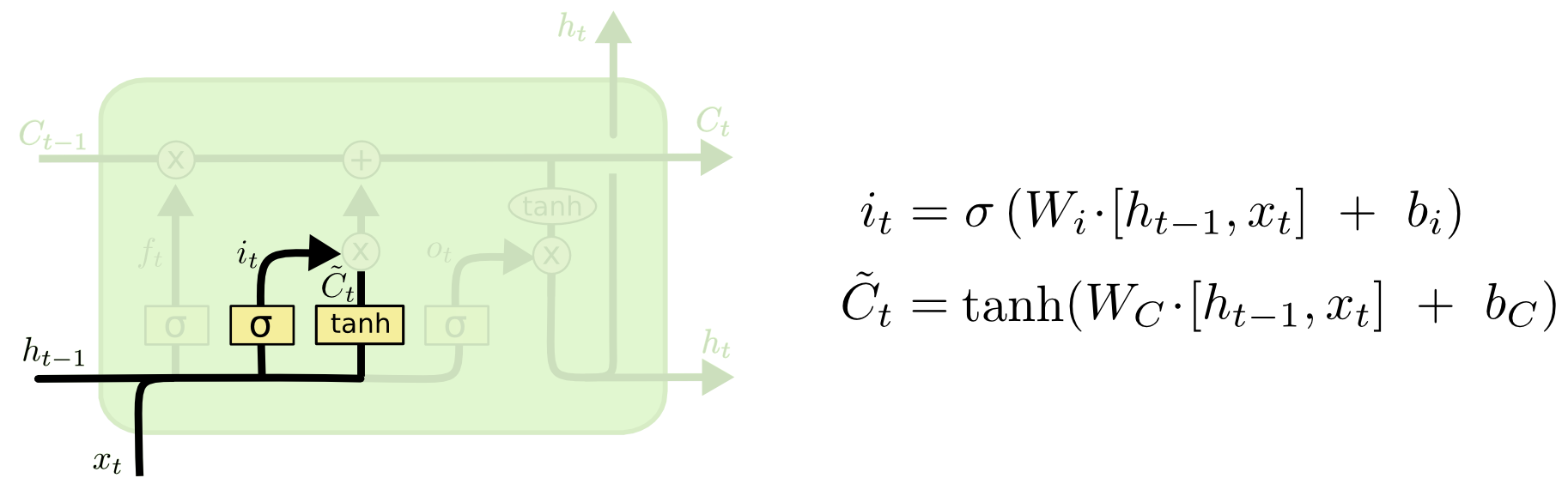
次のステップは、セル状態で保存する新たな情報を判定することです。これには2つの部分があります。まず、「入力ゲート層」と呼ばれるシグモイド層は、どの値を更新するかを判定します。次に、 tanh 層は、セル状態に加えられる新たな候補値のベクトル $\tilde{C}_t$ を作成します。次のステップでは、状態を更新するために、これら2つを組み合わせます。
言語モデルの例では、忘れようとしている古いものを置き換えるために、セル状態に新たな主語の性別を追加したいです。
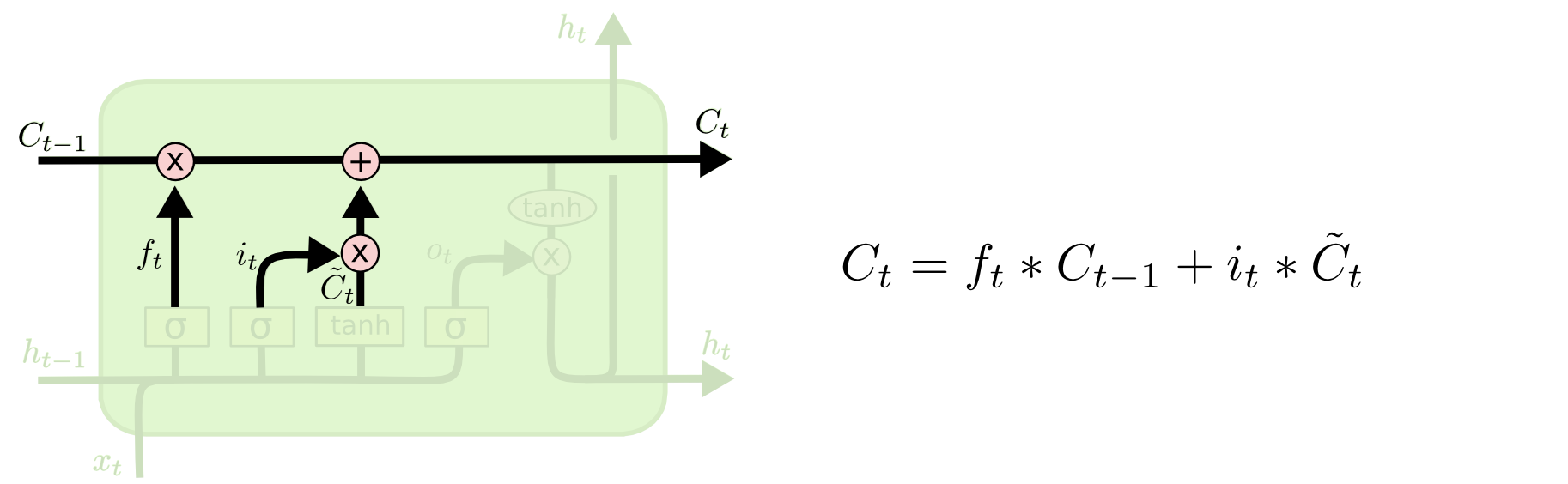
そして、古いセル状態 $C_{t-1}$ から新しいセル状態 $C_t$ に更新します。何をするべきかについては前のステップですでに判定しました。今、実際にそれをする必要があります。
古い状態に $f_t$ を掛け、さきほど忘れると判定されたものを忘れます。そして、 $i_t*\tilde{C}_t$ を加えます。これは、各状態値を更新すると決定した割合でスケーリングされた、新たな候補値です。
言語モデルの場合、前のステップで判定した通り、ここで実際に古い主語の性別に関する情報を落とし、新たな情報を加えます。
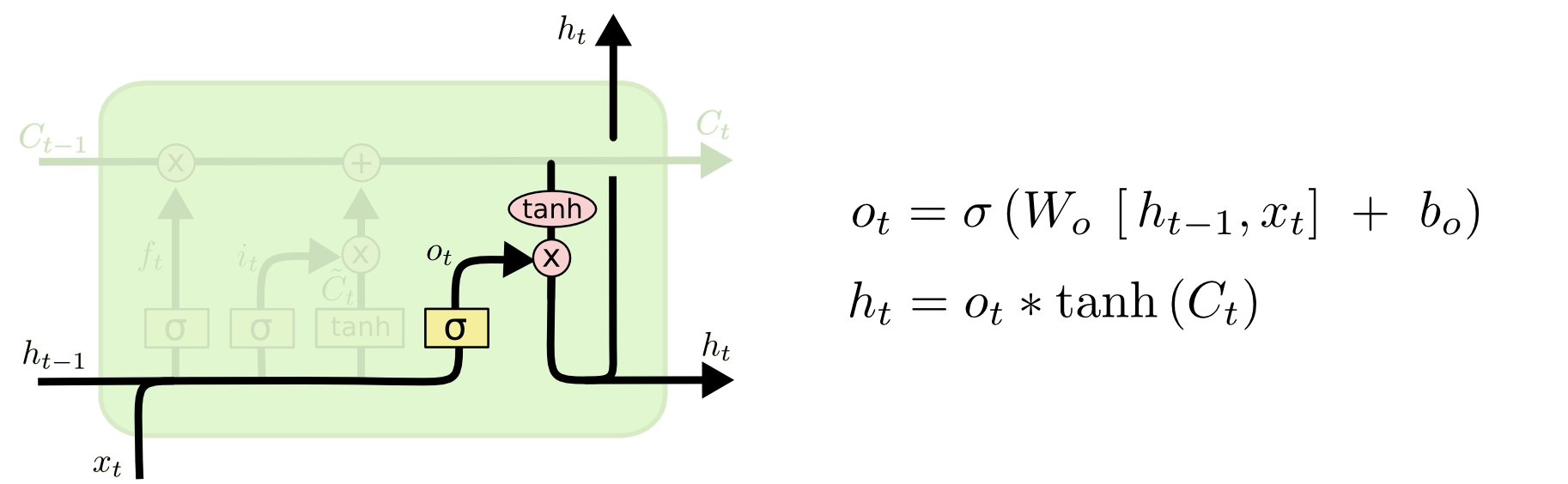
最後に、出力するものを判定する必要があります。この出力は、セル状態に基づいて行われますが、フィルタリングされたバージョンになります。まず、シグモイド層を実行します。この層は、セル状態のどの部分を出力するかを判定します。その後、判定された部分のみ出力するため、セル状態に(値を-1と1の間に圧縮するために) $tanh$ を適用し、それにシグモイド・ゲートの出力を掛けます。
言語モデルの例では、主語を見たとき、動詞が次に来る場合には、動詞に関連する情報を出力することを求められるかもしれません。例えば、主語が単数か複数かを出力するかもしれません。動詞が後につづく場合、どの活用形であるべきかわかるためです。
LSTMのバリエーション
これまで説明してきたのは、かなりノーマルなLSTMです。でも、すべてのLSTMが上記と同じではありません。実際には、LSTMを含むほぼすべての論文は、わずかに異なるバージョンを使用しているようです。違いは軽微なものですが、いくつかについて言及する価値があります。
Gers & Schmidhuber (2000) により導入された、一般的なLSTMのバリエーションの一つは、「のぞき穴の結合」を加えています。これは、ゲート層にセル状態を見させることを意味します。
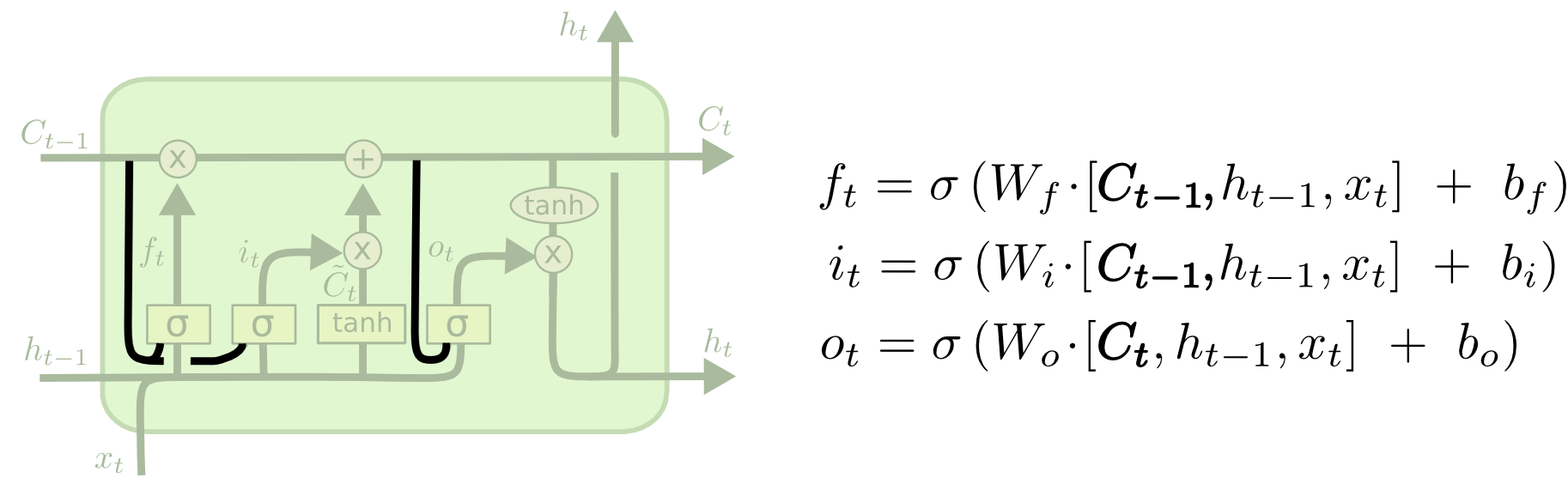
上の図ではすべてのゲートにのぞき穴が追加されていますが、多くの論文では、いくつかにはのぞき穴を与え、他のものには与えません。
別のバリエーションでは、忘却ゲートと入力ゲートを組み合わせて使用します。何を忘れ、新しい情報を何に加えるべきかを別々に判定する代わりに、これらの判定を同時に行います。その場所に何かを入力するときのみ、忘却します。古いものを忘れたときのみ、状態に新しい値を入力します。
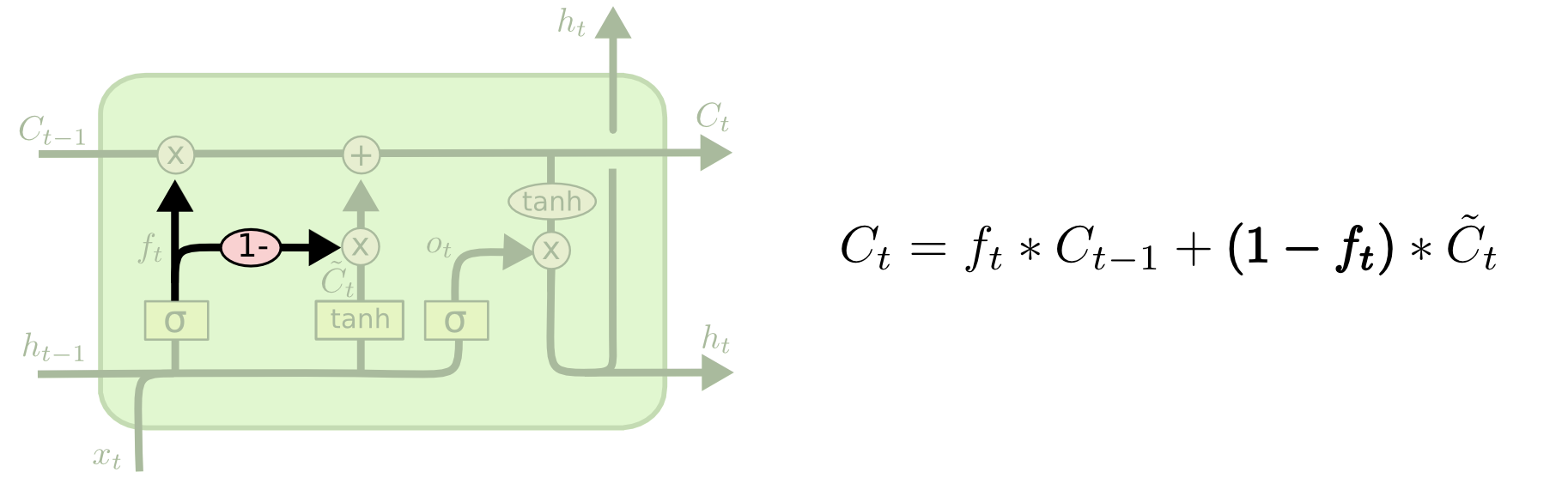
LSTMのもう少し劇的なバリエーションは、 Cho, et al. (2014) により導入された、 Gated Recurrent Unit 、あるいはGRUです。これは忘却ゲートと入力ゲートを単一の「更新ゲート」に組み合わせます。また、セル状態と隠れ状態をマージし、他のいくつかの変更を加えます。結果として得られるモデルは、標準的なLSTMモデルよりもシンプルであり、ますます一般的になってきています。

これらは、最も注目すべきLSTMのバリエーションのほんの一部です。他にも、 Yao, et al. (2015) による Depth Gated RNNs などがあります。また、長期の依存性に取り組むまったく異なるアプローチ、 Koutnik, et al. (2014) による Clockwork RNNs などもあります。
これらのバリエーションのうちどれがベストでしょうか?違いは重要でしょうか? Greff, et al. (2015) は、ポピュラーなバリエーションのすばらしい比較を行い、それらすべてがほぼ同じだと結論づけました。 Jozefowicz, et al. (2015) は、1万以上のRNNのアーキテクチャをテストし、その一部は特定のタスクにおいてはLSTMよりも良いと結論づけました。
結論
さきほど、人々がRNNで達成した顕著な成果を述べました。基本的にこれらのすべてがLSTMを使用して達成されます。それはほとんどのタスクにおいて本当に多くの良い働きをします!
一連の方程式として書かれると、LSTMはかなり威圧的に見えます。このエッセイで一歩一歩見ていくことで、それがもう少し親しみやすくなっていれば幸いです。
LSTMは、RNNで達成することができるものにおける大きな一歩でした。以下の疑問は自然です:ほかに大きな一歩はありますか?研究者の間で共通の意見は次のとおりです:「はい!次の一歩があり、それはアテンションです!」。そのアイデアは、RNNのすべてのステップが、情報のいくつかの大きなコレクションから、見るために情報を摘まめるようにするというものです。たとえば、画像を説明するキャプションを作成するためにRNNを使用する場合、出力する単語ごとに、見るために画像の一部を摘まむかもしれません。実際、 Xu, et al. (2015) は、まさにこれを行いました、アテンションを知りたい場合、それは楽しい出発点かもしれません!アテンションを使用した、いくつかの本当にエキサイティングな結果があり、角を曲がればさらにたくさんあるように思われます…
アテンションはRNN研究の唯一のエキサイティングな糸ではありません。たとえば、 Kalchbrenner, et al. (2015) によるGrid LSTMは、非常に有望に思えます。生成モデルにRNNを使用した研究( Gregor, et al. (2015) 、 Chung, et al. (2015) 、 Bayer & Osendorfer (2015) など)も、非常に興味深いと思われます。ここ数年は、リカレントニューラルネットワークにとってエキサイティングな時間でした。今後もさらにそうであることを約束します!
謝辞
LSTMをより良く理解する手助けをし、可視化についてコメントし、この記事にフィードバックしてくださった方々に感謝いたします。
有益なフィードバックをくださったGoogleの同僚、特に Oriol Vinyals 、 Greg Corrado 、 Jon Shlens 、 Luke Vilnis 、 Ilya Sutskever に非常に感謝しています。また、Dario Amodei 、 Jacob Steinhardt を含め、時間を割いて助けてくださった、多くの友人や同僚に感謝します。図について非常に考え深い対応のため、 Kyunghyun Cho には特に感謝しています。
この投稿以前、私は、ニューラルネットワークを教える2つのセミナー・シリーズの中で、LSTMを説明する練習をしました。忍耐づよく参加し、フィードバックしてくださったみなさまに感謝します。
-
原著者に加えて、多くの人がモダンLSTMに貢献しました。非包括的なリストは、次のとおりです:Felix Gers 、 Fred Cummins 、 Santiago Fernandez 、 Justin Bayer 、 Daan Wierstra 、 Julian Togelius 、 Faustian Gomez 、 Matteo Gagliolo 、 Alex Graves ↩