はじめに
この記事は全7章に分かれた「本当にわかりやすいAI入門」の第4章です。以前の記事を読まれていない方は、先にこちらをご参照ください。
| 章 | 内容 |
|---|---|
| 第1章 | AIはなぜ人間みたいなことができるのか? |
| 第2章 | 脳はすごい |
| 第3章 | 伝わりやすさと境界の決め方 |
| 第4章 | 細胞増やすだけではダメだった(この記事) |
| 第5章 | 時間も手間もお金もかかる |
| 第6章 | 文章生成の大規模化による進化 |
| 第7章 | AIのこれから |
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
第4章 細胞増やすだけではダメだった
前回のまとめで、細胞を増やして調整をコンピューターに任せたらなんでもできそうなお話をしましたが、現実は甘くはありません。
細胞を増やすだけではダメだった
細胞間の伝わりやすさと境界の値の調整はさじ加減が非常に難しく、コンピューターに調整させ続けても精度の上がらないことがよくあります。また、細胞の数を増やせば複雑なことはできるのですが、単純に増やすだけでは解決できない課題もたくさんあります。
そのため、細胞そのものの仕組みを改良する研究や、細胞間のつなげ方の研究が盛んに行われてきました。
さまざまな細胞の機能とつなぎ方
以下のサイトで、FJODOR VAN VEENさんが主要な仕組みをイラストで紹介しています。ページの先頭にある「Neural Networks」というイラストを軽く眺めてみてください。
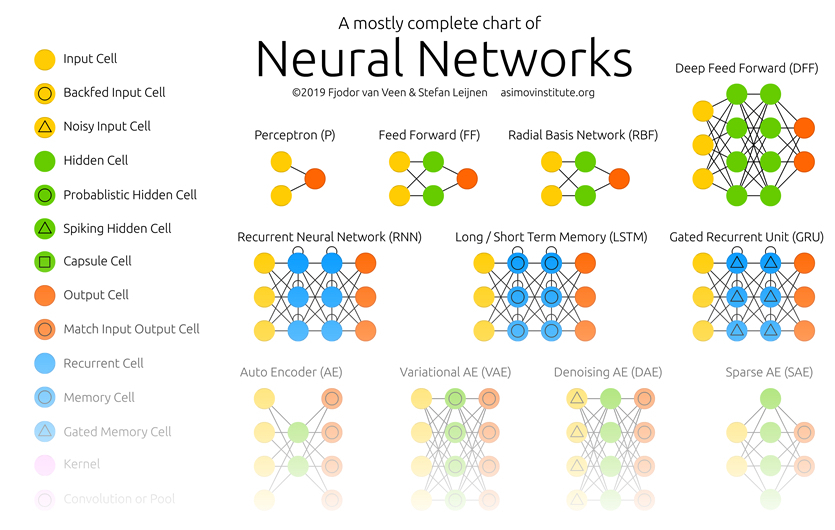
(出典)THE ASIMOV INSTITUTE.「THE NEURAL NETWORK ZOO」.
これは、主要な細胞の種類とつなぎ方をイラストにしたものです。カラフルな丸が細胞なのですが、いろいろな種類のあることがわかります。また、細胞のつなぎ方も、総当たりだったり間を飛び越していたり循環していたり、いろいろなつなげ方のあることがわかります。
つなぎ方の工夫の例
細胞のつなぎ方の例として、細胞の入力を計算する時に、前回計算した自身の出力も混ぜて使う仕組みをご紹介します。
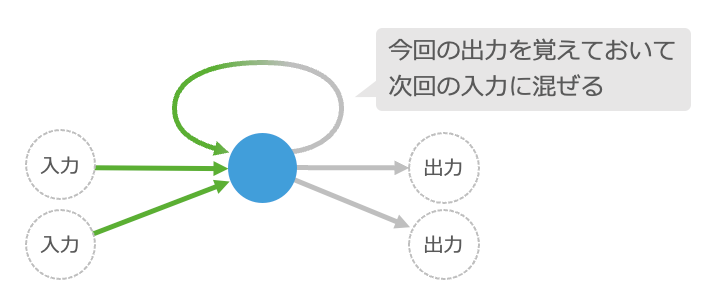
これまでご説明してきた細胞は、入力の合計が境界の値を超えたら次の細胞へ出力していましたが、それを自分自身の次の入力にも使います1。これだけでは何を言っているのかわからないと思いますが、この仕組みでおもしろいことができるようになります。
細胞の出力を自分の入力にまぜると……
まず、夏目漱石の小説を用意します2。そして、先頭の単語を入力して、出力が次の単語になるように調整します3。夏目漱石の「吾輩は猫である」の場合なら、まず「吾輩」を入力して出力が「は」になるように調整し、次に「は」を入力して出力が「猫」になるように調整していきます。
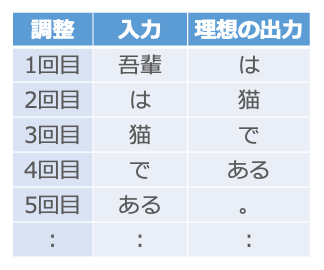
ここでのポイントは、小説の通りの順番で単語を入力して調整することです。出力を自分自身に戻す仕組みがあるため、たとえば2回目の「は」→「猫」の調整では、いつでも「は」がきたら「猫」が正しい、と調整されるわけではなく、1回目の「吾輩」の調整で使った細胞の出力が2回目の「は」の入力と混ざることで、「吾輩」と「は」が続く時は「猫」が正しい、という形で調整が進みます。
夏目漱石のさまざまな小説を使って、次の単語が出力できるように調整を繰り返します。
なんと小説が執筆できる!
これで、書き出しの文章を適当に与えるだけで続きを執筆してくれる仕組みができあがります。
まず入力に「吾輩」を与えます。何か単語が出力されますが、それは無視して次に「は」を入力します。同じように出力の単語は無視して「犬」を入力します。ここから先は出力で得られた単語をそのまま次の入力として与えていきます。
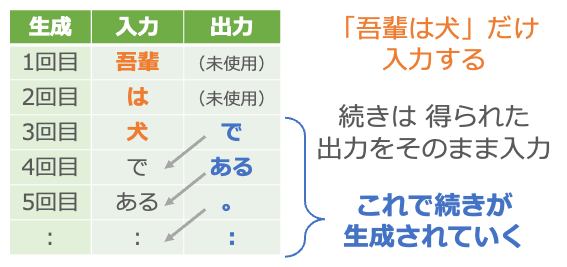
つまり「吾輩は犬」という書き出しを与えたら、あとは得られた出力をそのまま入力に回すことで、次々に文章を生成させていくわけです。夏目漱石の小説には「吾輩は犬」で始まる文はないかと思いますが、なんとなく夏目漱石風の新しい小説を執筆してくれます4。

第4章のまとめ
- 細胞の数を増やすだけでは限界があります。
- 細胞自身の機能やつなぎ方にはさまざまな工夫ができます。
- たとえば 出力を次回の入力にまぜると文章の生成ができます5。
細胞自身やつなぎ方を工夫することで、できることが増やせます。しかし、もう1つ大きな課題があります。次回はそれについて考えていきます。
(おまけ)AIでなぜグラボが人気になる?
グラボ(グラフィックボード)は画像処理の計算に特化した、GPU(graphics processing unit)という演算装置を搭載したものです。画像処理では大量の点の情報を一気に計算するために行列(数字の羅列)の計算を多用するのですが、GPUはその行列の計算専用に設計されているため高速に画像を処理できます。

ここまでにご紹介してきた手書き数字の認識や文章の生成では、その調整や認識の作業で各細胞の出力と伝わりやすさの掛け算、そしてその結果の足し算を大量に繰り返します。この計算は、少し工夫するとグラボが得意な行列の計算に置き換えられます。そのため、グラボを流用するとAIの調整や認識が高速化できるのです。なお、最近ではAI専用の演算装置もどんどん開発されています。
ちなみに、行列は一時期高校の数学から外れていたのですが、AIの普及に伴い重要度が増しており、文科省は2022年に数学Cで復活させています。
「第5章 時間も手間もお金もかかる」へ続きます。
-
細胞の出力を次の自身の入力に使うつなぎ方を「回帰型ニューラルネットワーク」(リカレントニューラルネットワーク:recurrent neural network)と呼びます。順番に意味のあるデータで使われる仕組みの1つです。 ↩
-
もちろん夏目漱石の小説ではなくてもOKです。この例は書籍「ゼロから作るDeep Learning ❷ ―自然言語処理編」で紹介されているものをベースにしていますが、書籍では「コーパス」が英文だったので、英語が苦手な私は「青空文庫」の日本語の小説で試しました。当時のメモを「ゼロから作るDeep Learning❷で素人がつまずいたことメモ: まとめ」にまとめているので、よろしければご参照ください。 ↩
-
単語は第2章でご紹介した手書き数字画像のような固定数の数値の羅列ではないので、実際には単語を入力する前に「単語の埋め込み」(word embedding)という仕組みで固定数の数値の羅列に変換します。 ↩
-
このように大量のテキストデータを使って文章を生成できるようにした仕組みを「言語モデル」(language model)と呼びます。 ↩
-
ここでは回帰型ニューラルネットワークのわかりやすい例として文章生成を取り上げましたが、文章生成や音声認識などの時系列データを取り扱う場合は、改良型である「LSTM」(長・短期記憶:Long Short-Term Memory)や「GRU」(ゲート付き回帰型ユニット:Gated Recurrent Unit)などの方が精度が上がります。また、これらの仕組みは時系列順にデータを処理する必要がある関係で並列に処理しにくいため、大規模なデータセットを処理する場合は「Transformer」(トランスフォーマー)がよく使われています。 ↩