はじめに
この記事は全7章に分かれた「本当にわかりやすいAI入門」の第3章です。以前の記事を読まれていない方は、先にこちらをご参照ください。
| 章 | 内容 |
|---|---|
| 第1章 | AIはなぜ人間みたいなことができるのか? |
| 第2章 | 脳はすごい |
| 第3章 | 伝わりやすさと境界の決め方(この記事) |
| 第4章 | 細胞増やすだけではダメだった |
| 第5章 | 時間も手間もお金もかかる |
| 第6章 | 文章生成の大規模化による進化 |
| 第7章 | AIのこれから |
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
第3章 伝わりやすさと境界の決め方
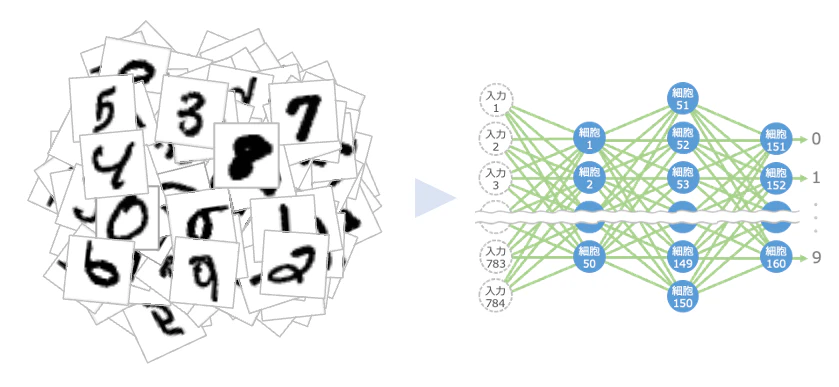
今回は、細胞間の伝わりやすさや境界の値の決め方についてのお話です。前回の最後にご紹介した手書き数字の認識を例にご説明します。
まず1箇所だけ調整
とりあえず、伝わりやすさと境界の値はすべて適当な値にしておきます。そして、手書き数字の「0」の画像を1枚入力して出力を計算してみます。

伝わりやすさや境界の値が適当なので、当然ながら「0」の場合に出力して欲しい細胞151はまず出力しません。細胞151〜160はいずれも適当な出力をする状態です。
ここで、入力1と細胞1の間の伝わりやすさの値だけを、試しに少しだけ大きくしてみます。

そして、これによって変化する後続の細胞の値を計算し直します。下の図の青い細胞と緑の線が影響を受けるので計算をやり直すことになります。

ここで、最後の細胞151の出力がどう変わるかに注目します。今は「0」の画像を入力しているので、細胞151の出力が強くなったかどうかをチェックするわけです。

もし、細胞151の出力が強くなった場合は今回の入力1と細胞1の間の伝わりやすさを大きくしたことが正解だったので、この値の変更を確定します。逆に出力が弱くなってしまった場合は失敗だったので、この値を少し小さくすることで確定します1。
すべての値を調整
これで、入力1と細胞1の間の伝わりやすさの値の調整が終わりましたので、同じ感じですべての伝わりやすさと境界の値を調整します。

伝わりやすさの値は上の図の緑の線の数だけあるので45,200個、境界の値は青い細胞の数だけあるので160個あります。これらを1つずつ調整していきます2。
他の数字の画像でも調整
これで「0」の画像の調整が終わりましたが、数字は「0」だけではありませんので、他の数字の画像でも同じように調整していきます。

いろいろな画像でさらに調整
これで「0」から「9」のすべての数字の調整が終わりましたが、実際の手書き数字には書き手ごとにバリエーションがあるので、いろいろな画像を集めて同じように調整していきます。
少しずつ何度も調整
集めた画像で一通りの調整が終わりましたが、いろいろな画像をバランスよく認識できるようにするためには、ここまでの一連の調整を何度も繰り返して実施する必要があります3。
いろいろな画像をバランスよく認識できるようになれば調整は完了です。これで、手書き数字を認識できるようになります。
この作業はコンピューターに任せられる
このような調整は人間がやるとかなり大変な作業になりますが、比較的単純な作業の繰り返しなので、実際にはプログラムを開発してコンピューターにお任せします4。
ただし、調整用の大量のデータは人間が用意しないといけません。今回の例では「手書き数字の画像」と「正解の数字」のペアを大量に用意するのは人間の仕事です。
ここで第1章のおさらい
第1章の「どうやって人間のマネをさせるのか?」の部分を少し振り返ります。第1章では、手書き数字を認識するような複雑なものはルールを考えるのが大変、とご説明しました。
この認識のルールを考えるのはすごく大変です。
- 縦方向の棒が1本しかなければ「1」
- 上の部分から少し左に伸びた横棒があっても「1」
- 縦棒の下の部分に短い横棒があっても「1」
- 棒が多少斜めになっていても「1」
- いずれかの棒が多少離れていても「1」
- 「7」との違いは… etc.

続けて、そのようなものはルール自体を考えることまでコンピューターにやらせるのが主流ともご説明しました。
そのため、ルールや公式を考えるのが大変なものは、「ルールを考える作業」までコンピューターにやらせるのが主流になっています。
そうなのです。この第3章でご説明している「伝わりやすさと境界の値をコンピューターに調整させること」は、まさに、手書き数字を認識するためのルールをコンピューターに考えさせていることなのです。
以下、第1章のまとめを振り返ります。
第1章のまとめ
- コンピューターで人間のマネをする仕組みが「AI」です。
- 人間のマネをさせるには次の2つの方法があります。
「人間が考えたルール」をコンピューターに実行させる
「ルール自体を考えること」までコンピューターに実行させる
この最後にある「『ルール自体を考えること』までコンピューターに実行させる」ことが、この第3章のご説明の内容でした。
第3章のまとめ
- (第2章より)細胞の数を増やせば複雑なこともできます。
- 各細胞間の伝わりやすさや各細胞の境界の値は、いろいろな入力データを使って少しずつ調整を繰り返して決めます。
- 調整は大量のデータを用意してコンピューターで実行します。これにより、ルール自体を考えることもコンピュータに任せられます。
細胞増やして調整をコンピューターに任せたら、なんでもできそうな感じがしてきましたよね?ところが、現実はそう甘くはありません。次回はこの辺りを考えていきます。
「第4章 細胞増やすだけではダメだった」へ続きます。
-
前章では、各細胞は入力の合計が境界値以上なら1を出力するとご説明しましたが、実際には0か1のどちらかではなく、「シグモイド関数」や「正規化線形関数」(ReLU)と呼ばれる仕組みで0から1の間のなだらかな出力にします。0か1のどちらかにしてしまうと、調整によって入力の合計が変化しても境界をまたがない限り出力が変化しないため調整の正否が判定できず、調整効率が悪くなってしまうのです。 ↩
-
値の調整は最終の出力がどう変化するのかを確認しながらおこなうため、最終出力までの計算を繰り返す必要があります。しかし、細胞が多いと計算量が膨大になってしまいます。そこで実際には「偏微分」を利用します。偏微分は式の中のある値が変わった時に式の最終結果がどう変化するのかを調べるためのもので、偏微分ができれば再計算をせずに最終出力がわかるので各値の調整が効率化できます。実用化されている仕組みは、最終結果が偏微分できるように設計することで調整作業を大きく効率化しています。 ↩
-
用意したデータを使ってなんども調整を繰り返す必要がありますが、その繰り返した回数のことを「エポック数」(epoch)と呼びます。用意したデータすべてを1回ずつ使って調整した状態が1エポックです。エポック数を増やせば精度は上がるのですが、用意したデータに特化しすぎてしまい、それ以外のデータの認識精度が下がってしまう「過学習」(overtraining)とよばれる事象が発生しがちです。そのため、用意したデータをすべて使って調整するのではなく、そのデータを調整用と精度確認用にわけて使う「交差検証」という方式で、精度を確認しながらエポック数を調整することが多いです。
また、エポック数以外にもうまく調整するためには試行錯誤が必要です。たとえば、伝わりやすさや境界の値を「少しずつ」変えるその程度のことを「学習率」(stepsize)と呼びますが、これも加減を間違えると調整がうまく終わりません。このようなエポック数や学習率などのさじ加減的なものを「ハイパーパラメーター」と呼びます。ハイパーパラメーターには他にも多くの種類があり、調整をうまくおこなうには、これらのハイパーパラメーターの調整が非常に重要です。 ↩ -
このように、用意した大量のデータを使って各値の調整作業をコンピューターで実行することを「機械学習」(machine learning)と呼びます。なお、機械学習という言葉は脳をマネしていない仕組みでも使われる用語です。また、脳をマネした仕組みの中で、特に大量の細胞を何層も重ねたような構造を機械学習することを「深層学習」(ディープラーニング:deep learning)と呼びます。今回ご説明したの手書き数字を認識する仕組みも深層学習の一例です。 ↩