はじめに
この記事は全7章に分かれた「本当にわかりやすいAI入門」の第5章です。以前の記事を読まれていない方は、先にこちらをご参照ください。
| 章 | 内容 |
|---|---|
| 第1章 | AIはなぜ人間みたいなことができるのか? |
| 第2章 | 脳はすごい |
| 第3章 | 伝わりやすさと境界の決め方 |
| 第4章 | 細胞増やすだけではダメだった |
| 第5章 | 時間も手間もお金もかかる(この記事) |
| 第6章 | 文章生成の大規模化による進化 |
| 第7章 | AIのこれから |
この記事は個人で作成したものであり、内容や意見は所属企業・部門見解を代表するものではありません。
第5章 時間も手間もお金もかかる
細胞自身の工夫やつなぎ方の工夫だけでは乗り越えられない課題、それは時間や手間やお金です。
時間と手間とお金がかかる問題
調整に使うデータの準備は大変です。目的にあった質の良いデータを集めるのも大変ですし、正解のデータを人手で作る必要がある場合は膨大な時間や手間もかかります。
また、細胞を増やせばできることが増えますが、増やせば増やすほど調整対象も増えて、必要なマシンパワーも増えていきます。このマシンパワーを確保するためにはお金が必要です。
そうなのです。調整作業は時間や手間やお金がかかる、とにかく大変でやりたくない作業なのです。
すでにある仕組みの流用や組み合わせ
そのため、すでにある仕組みを流用したり組み合わせたりすることで、効率的にできることを増やす取り組みも進んでいます。ここではその3つの例をご紹介します。
【例1】 画像分類+文章生成
画像分類の仕組みと……
最初の例で流用するのは画像分類の仕組みです。この仕組みは、カラーの画像を入力すると、その画像の内容が1,000種類の分類のどれなのかを判定してくれます。1,000種類の分類は、例えば「自転車」だったり「ペンギン」だったり「テーブル」だったり「サンドイッチ」だったりと様々です。
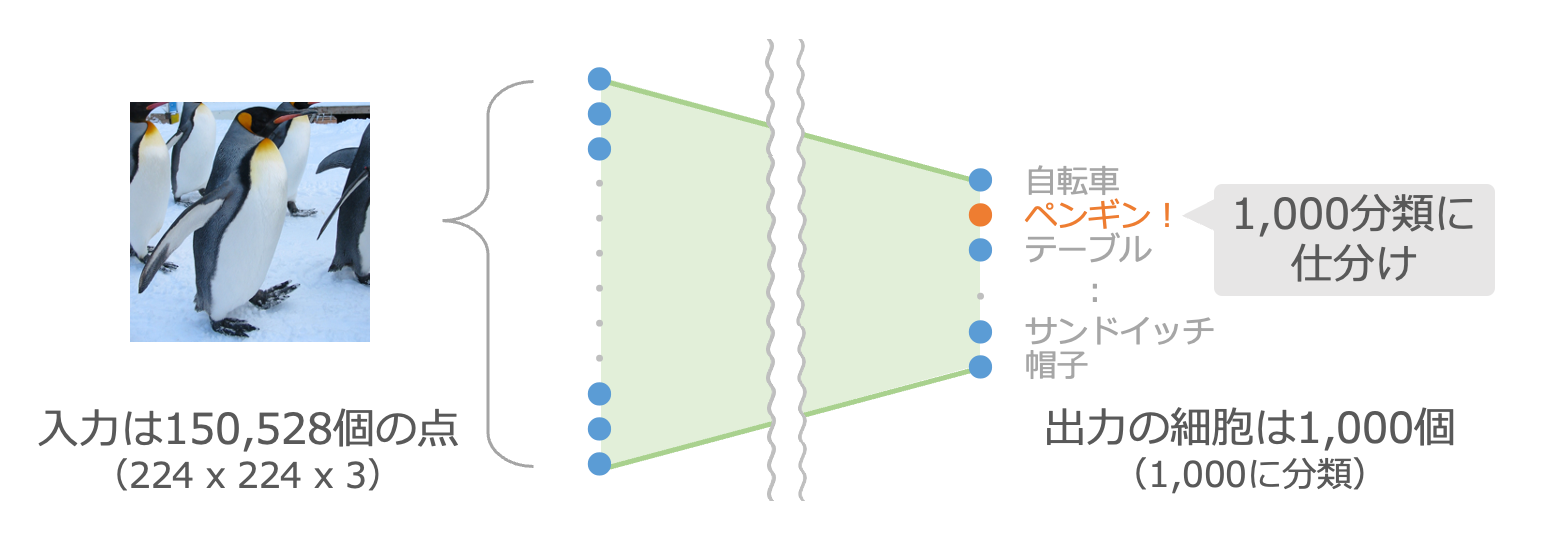
第2章でご紹介した手書き数字の認識では縦横28個の点からなる画像を10種類の数字に分類しましたが、それを細胞数を増やして高度にした仕組みです1。この仕組みでは縦横224個の点を扱います。カラー画像では1個の点を赤・緑・青の3個の数字で表すため、入力は約15万個の数字になっています。
図では細胞を1つずつ書いて線で結ぶのが大変なので薄い緑で塗りつぶしています。実際には第3章でご紹介したような様々な機能の細胞が様々な工夫でつながっている状態だと思ってください。以降も同様です。
この仕組みの最終出力は分類の判定結果になる1,000個の細胞ですが、その1つ手前には4,096個の細胞が並んでいます。この4,096個の細胞の出力を受けて、最後に1,000分類のどれに該当するのかが判定されています。つまり、この4,096個の細胞には、画像を1,000個の分類に仕分けるための重要な情報が凝縮されているといえます。
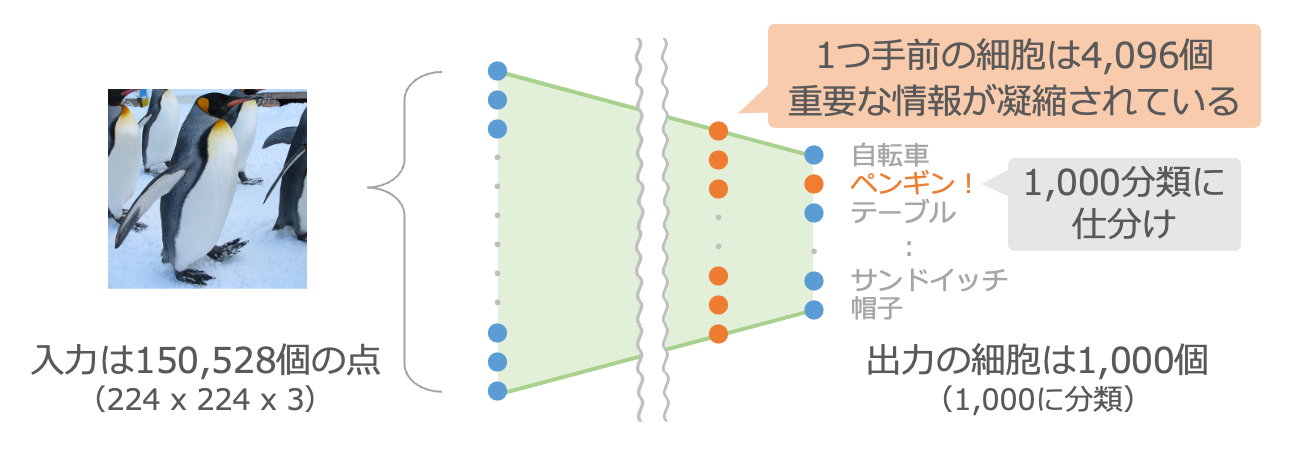
そこで、この部分だけを切り出して、画像の150,528個の入力を4,096個の数字に凝縮する調整済みの仕組みとして流用します。
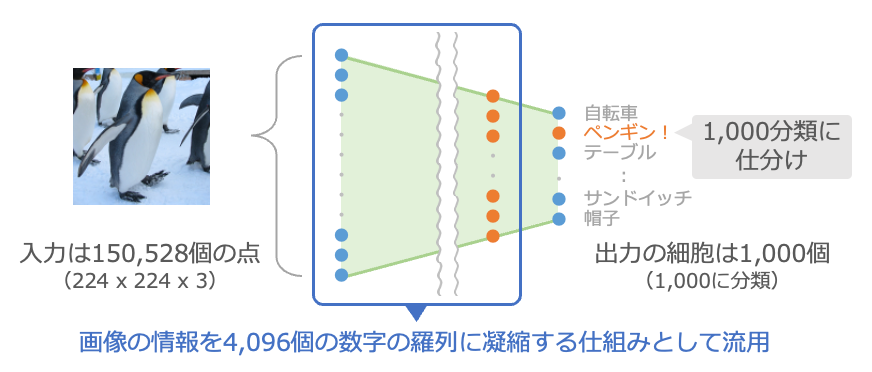
文章生成の仕組みを組み合わせると……
これと組み合わせるのは第4章でご紹介した文章生成の仕組みです。第4章では小説の頭の単語から順番に入れて調整していましたが、今回はまず画像から凝縮した情報を入力し2、続いてその画像の説明文を入力して調整します。
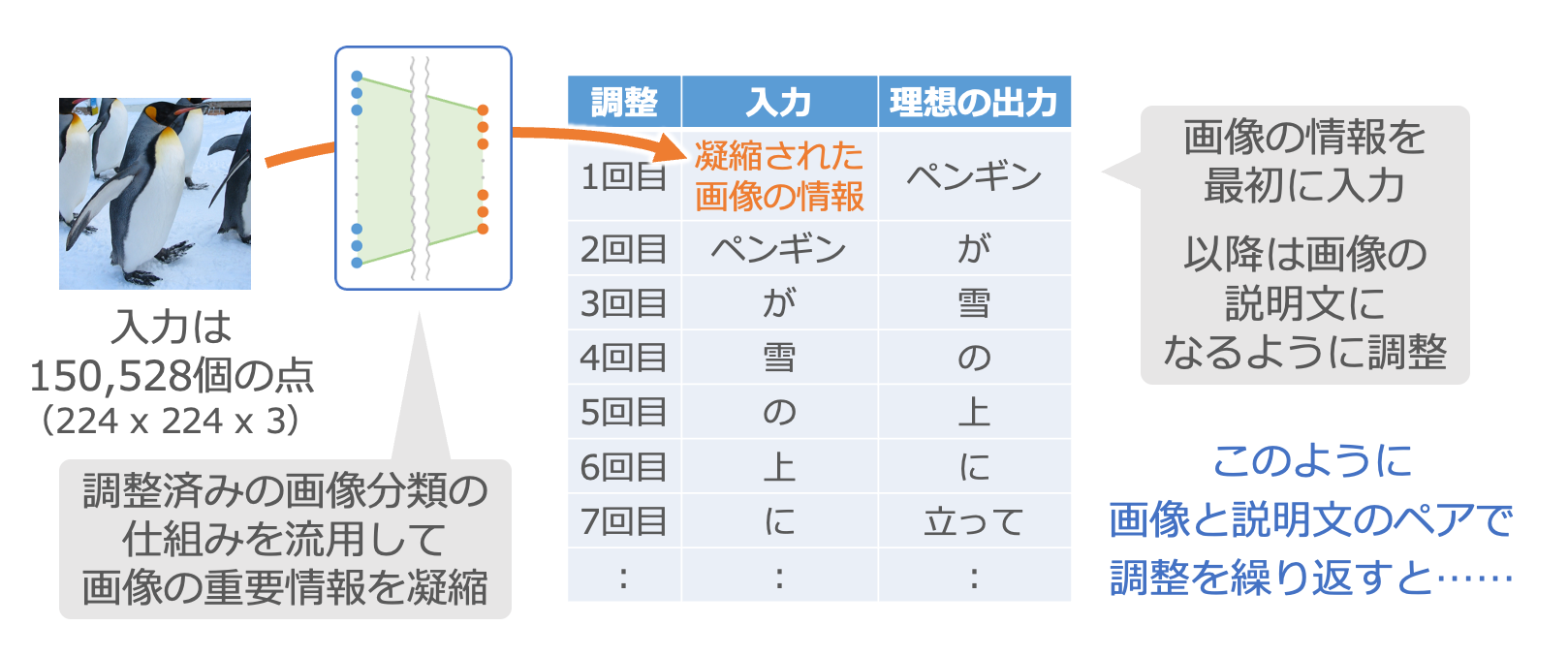
大量の画像とその説明文のペアを用意して、このような調整を繰り返します。
画像の説明文が作れる!
この調整が終わると、入力画像に対して説明文を生成してくれる仕組みができあがります。
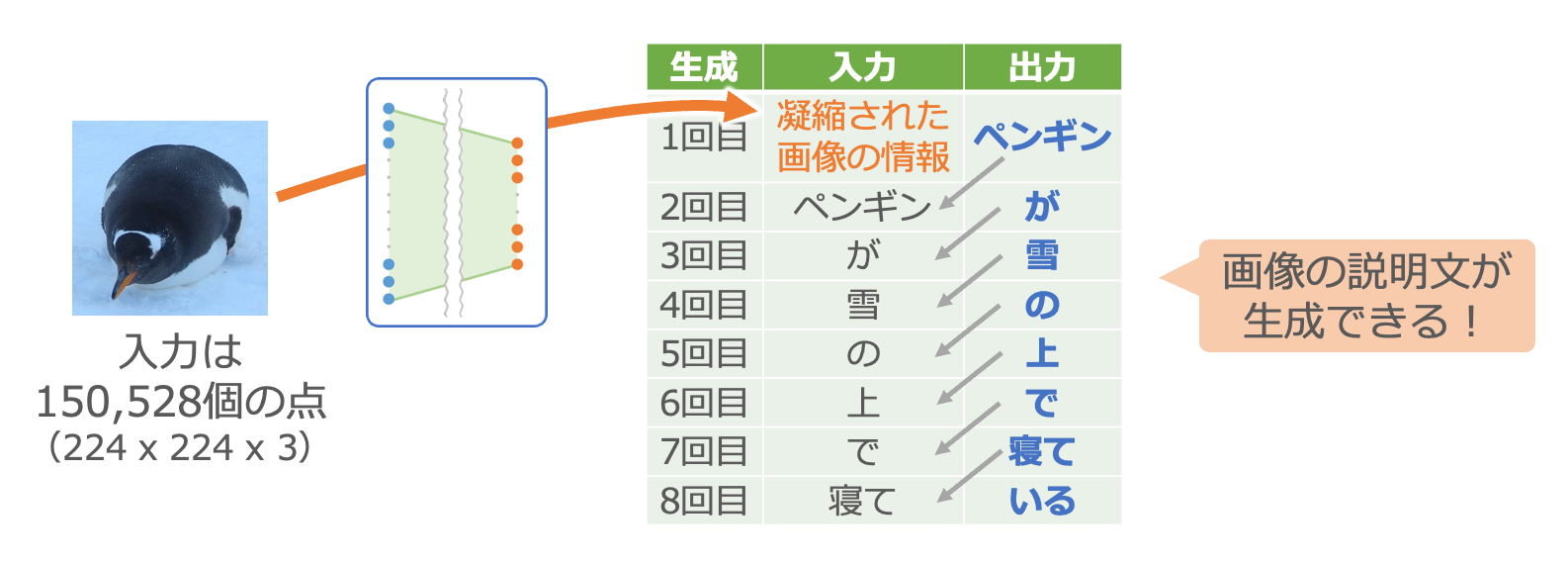
この例では、画像を4,096個の数字の羅列に凝縮する部分で既存の仕組みを流用しました3。本来であればこの凝縮する仕組みを使う前に、大量の画像とそれぞれが1,000分類のどれに該当するかの正解のペアを用意して時間をかけて調整する必要がありますが、それを省くことができたわけです。

【例2】 画像と説明文の正誤判定+画像の繊細化
画像と説明文の関係が正しいかどうかを判定する仕組みと……
次の例で流用するのは、画像と説明文の関係が正しいかどうかを判定する仕組みです4。この仕組みでは、左から文章を入力し、右からその文章通りの画像を入力すると、双方の凝縮した数字が近くなるように調整済みです。逆に、左の文章と右の画像が無関係なものの場合は、双方の凝縮した数字はまったく異なるものになります。
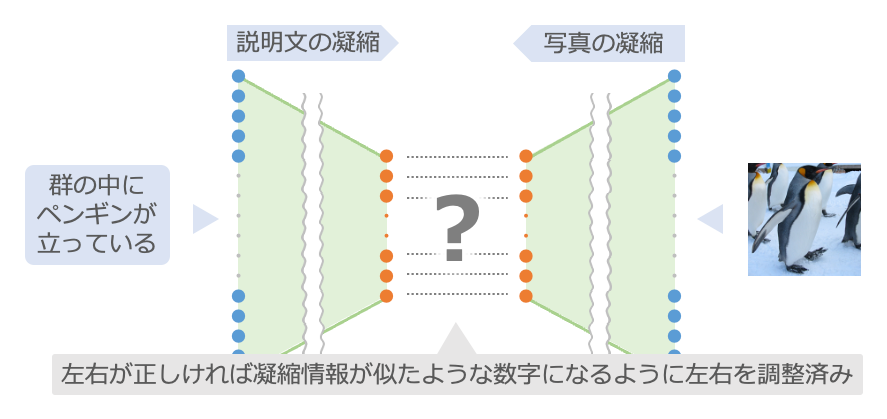
画像を繊細化する仕組みを……
これと組み合わせるのは、画像を繊細化する仕組み5です。
この仕組みでは、まず調整のためのデータとして大量の画像を用意し、その画像を少しずつ繰り返し汚します6。

そして、汚した画像と汚す1つ前の画像をペアにして、汚した画像を入力したら汚す1つ前の画像になるように調整を繰り返します。

この調整が終わると、汚れた画像から繊細な画像を作り出せるようになります7。

組み合わせて調整していくと……
この2つの仕組みを組み合わせます。
まず、説明文と画像のペアを大量に用意します。そして、最初にご紹介した「画像と説明文の関係が正しいかどうかを判定する仕組み」の左半分を流用して説明文を数字の羅列に凝縮し、次にご紹介した「画像を繊細化する仕組み」の最初の入力にします。それに対する理想の出力は、ペアになる正解の画像を何度も汚したものです。
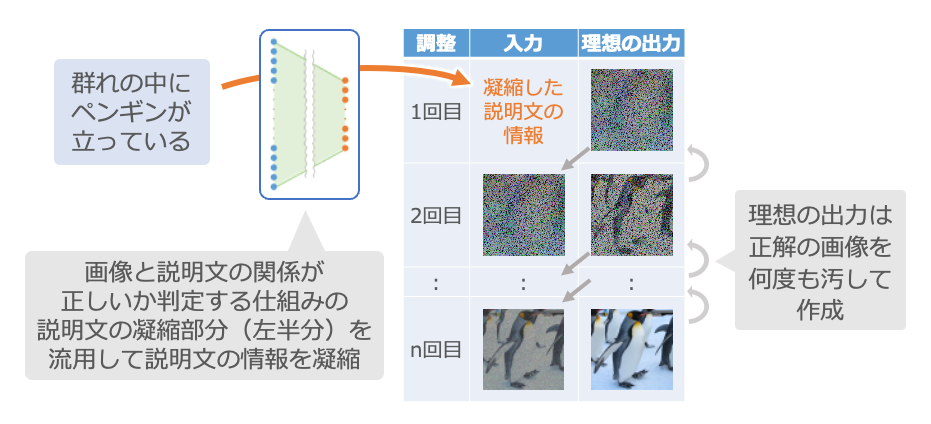
このように、説明文と、その画像を何度も汚すことで作った多くのペアを使って調整を繰り返します。
説明文から繊細な絵が描ける!
この調整が終わると、説明文から繊細な絵を描く仕組みができあがります。
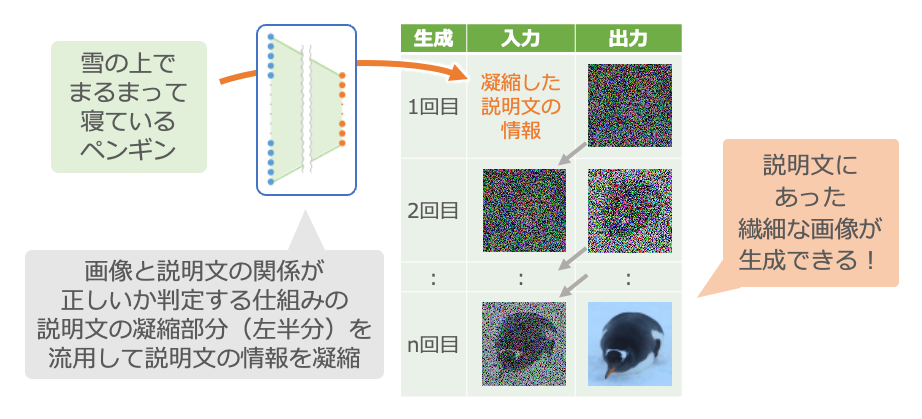
この例では、画像と説明文の関係が正しいかどうかを判定する仕組みの左半分を流用しました。本来であれば、この凝縮する仕組みを調整するためにも大変な労力が必要なのですが、それを省くことができています。

【例3】 文章を数字の羅列に凝縮+数字の羅列の検索
文章を数字の羅列に凝縮する仕組みと……
最後の例では、文章を数字の羅列に凝縮する仕組み8を流用します。今回使う仕組みは、事前に多くの文章のペアを用意して、その文章の意味が近いものは凝縮した数字が似るように、文章の意味が異なるものは似ないように調整が済んでいるものです9。
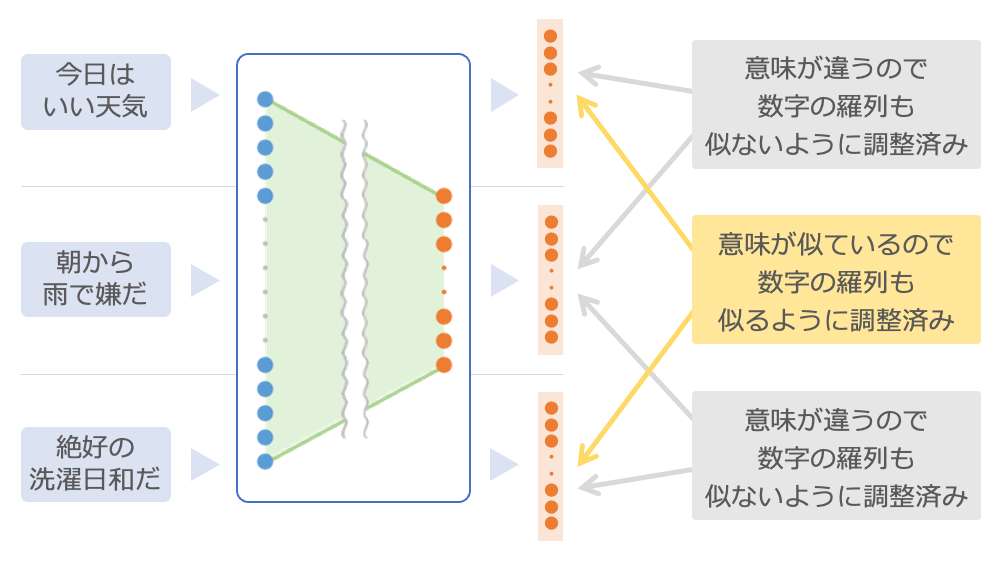
たとえば、「今日はいい天気」と「絶好の洗濯日和だ」は意味が似ているので、それぞれを凝縮した数字も似るように調整済みです。逆に、「今日はいい天気」と「朝から雨で嫌だ」は全然意味が違うので、それぞれを凝縮した数字は似ないようになっています。
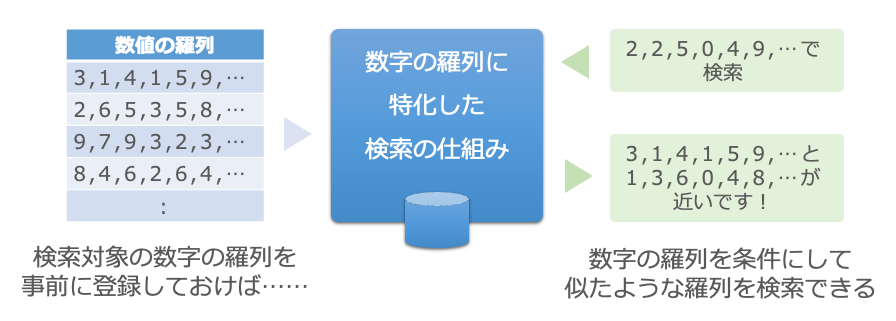
数字の羅列を検索する仕組みを……
これと組み合わせるのは、数字の羅列を検索する仕組みです。この仕組みは少し変わっていて、似たような数字の羅列を検索できるようになっています。個々の数字は多少違っていても、全体で似たものを探してくることができます10。事前に検索対象としたい数字の羅列を登録しておくことで、大量の数字の羅列でも高速な検索ができるようになっています。
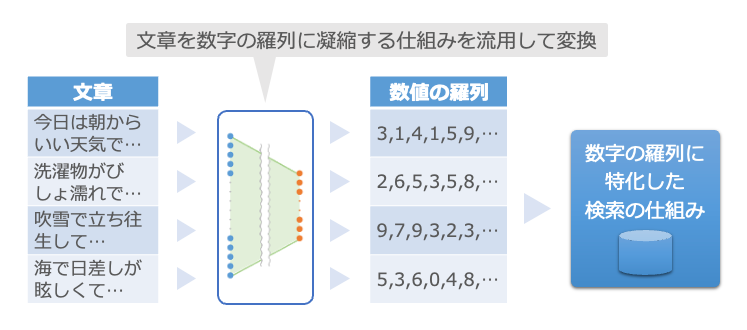
組み合わせて事前に登録しておくと……
この2つを組み合わせて、事前に文章を数字の羅列に変換し11、数字の羅列に特化した検索の仕組みへ登録しておきます。
意味の似ている文章が検索できる!
そうすると、意味の似ている文章を検索する仕組みができあがります。
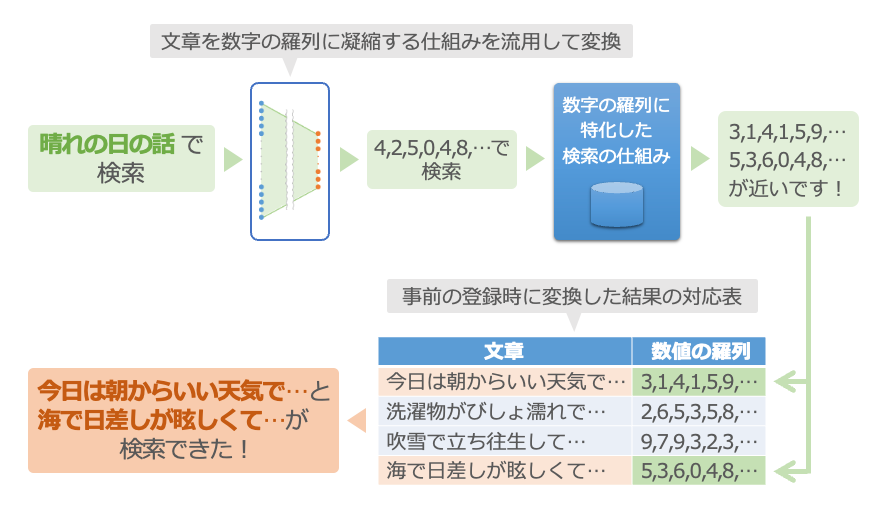
まず、検索条件の文章を、最初の仕組みで数字の羅列に変換します。そして、数字の羅列が検索できる仕組みで検索すると、事前に登録した中から数字の似たものがわかります。最後にその数字の羅列を、事前に変換して登録した時の元の文章に戻します。
これで、たとえば「晴れの日の話」で検索して、事前に登録しておいた「今日は朝からいい天気で…」や「海で日差しが眩しくて…」といった意味の近い文章を検索できます12。
この例では、文章を数字の羅列に凝縮する仕組みを流用しました。本来であれば、この凝縮する仕組みを調整するためだけでも大変な労力が必要なのですが、それを省くことができています。

第5章のまとめ
- 調整済みの仕組みを流用することで、データの準備や調整のコストが抑えられます。
- 調整済みの仕組みで情報を凝縮して他の用途に使えば、効率的にできることが増やせます。今回はその例として、
【例1】画像から説明文を生成
【例2】説明文から繊細な絵を描く
【例3】意味の似た文章の検索
の3つをご紹介いたしました。
なお、調整済みの仕組みを組み合わせる際は、用途にあったものを選ぶ必要があります。たとえば【例1】でも【例3】でも文章を数字の羅列に凝縮する仕組みを使いましたが、流用した2つの仕組みはまったく別のものですのでご注意ください。
ここまでが2021年ごろまでのお話でした。次からは最近の技術や動向についてお話していきます。
「第6章 文章生成の大規模化による進化」へ続きます。
-
この例は「VGG16」という仕組みです。ここでの説明には「AI人工知能テクノロジー」さんのブログ「VGG16モデルを使用してオリジナル写真の画像認識を行ってみる」を参考にいたしました。 ↩
-
ここではわかりやすくなるように、凝縮した画像の情報と続く単語が同じ形で入力される表にしています。実際の画像の情報は、細胞がつながり合う構造の中間部分に直接入力する形になっています。 ↩
-
この例ではVGG16を使うことで画像を4,096個の数字に凝縮して、それを説明文の生成に流用しました。このような調整済みの仕組みを別の目的に流用することを「転移学習」(transfer learning)と呼びます。
また、情報を凝縮させる仕組みを「エンコーダー」(encoder)と呼び、その凝縮された情報を利用して文章などの別の情報を生成する仕組みを「デコーダー」(decoder)と呼びます。エンコーダーとデコーダーの組み合わせ例は多くあり、今回の例1や次の例2もそうです。他にも日本語の文章をエンコーダーで凝縮して英文生成のデコーダーで文章生成することで日英翻訳を実現する例などがあります。 ↩ -
この例は「CLIP」(Contrastive Language–Image Pre-training)という仕組みです。ここでの説明は「TRAIL (Tokyo Robotics and AI Lab)」さんの記事「CLIP:言語と画像のマルチモーダル基盤モデル」を参考にいたしました。 ↩
-
この例は「Stable Diffusion」という仕組みの一部です。ここでの説明は「Gigazine」さんの記事「画像生成AI「Stable Diffusion」がどのような仕組みでテキストから画像を生成するのかを詳しく図解」を参考にいたしました。 ↩
-
Stable Diffusionでは画像を直接汚すのではなく、実際にはまず凝縮して情報量を減らし、それに対してノイズを加えて汚します。そのため、実際には目で汚れていく様子が確認できるようなデータとしては処理されていません。 ↩
-
ノイズを加えて汚したデータを用意し、それを元に戻せるように調整していく仕組みを「拡散モデル」(diffusion model)と呼びます。 ↩
-
数字の羅列は「ベクトル」と呼ばれ、ベクトル同士の距離や類似度を計算することができます。ベクトルの距離や類似度の計算方法にもいくつか種類があり、「ユークリッド距離」や「コサイン類似度」などが有名です。 ↩
-
この例は「教師ありSimCSE」(supervised SimCSE)という仕組みです。ここでの説明は書籍「大規模言語モデル入門」を参考にいたしました。実際には2つの文章とその関係(含意/中立/矛盾)のセットを大量に用意して調整して、含意の場合は凝縮したベクトルが近くなるように、矛盾の場合は遠くなるように調整しています。 ↩
-
数字の羅列である「ベクトル」を使って情報を検索する仕組みは「ベクトル空間モデル」や「ベクトル検索」と呼ばれ、「ベクトルストア」(vector store)や「ベクトル検索エンジン」(vector search engine)、「埋め込みデータベース」(Embedding Database)と呼ばれるシステムに実装されています。通常の検索の仕組みは条件に一致するものを探しますが、ベクトル検索の場合は、「ユークリッド距離」や「コサイン類似度」などにより似たようなベクトルを検索できることが特徴です。 ↩
-
文章を凝縮してベクトルに変換することを、「文章の埋め込み」(text embedding)と呼びます。多言語に対応する仕組みの場合は、同じ意味なら日本語のベクトルも英語のベクトルも中国語のベクトルも近い関係になります。 ↩
-
これまでの文章の検索は「全文検索」の利用が一般的でしたが、字面が違いすぎたり表現が違いすぎたりすると意味の似た文章を検索できませんでした。文章の埋め込みとベクトル検索の組み合わせはこの弱点を補えるものとして非常に期待されていますが、文章の埋め込みに使う仕組みが情報を適切に凝縮できない文章は検索できないので、決して万能ではありません。そのため、複数の検索の仕組みを組み合わせたり、検索結果の並びを調整する仕組みと組み合わせたりする工夫が重要になっています。 ↩