はじめまして
始めまして!株式会社 Panta Rheiの「かず」と申します。pandasista という名前でXをやっております。普段はデータをねりねりしたりCEOをしたりしています。

本記事は4年前に勉強会で用いた記事になります!
ぜひいいねを押してってください🙌
導入
本記事の構成は4部となっており
- Titanicデータセットと探索的データ分析(EDA)
- 探索的データ分析(EDA)の続きと特徴量エンジニアリング
- 特徴量エンジニアリングの続きとAIモデルへの適用
- djangoを用いた簡単なTitanic乗客生死予測アプリケーションの作成
という内容でお届けしています。
本記事は3章目!特徴量エンジニアリングと実際のモデルへの適用を紹介します!
以下の記事を読んだ後に本Titanicシリーズを読むと段階的に理解ができます。
続き
さて、今回からついにAIの実装となります。前回の振り返りを少しだけすると、
「EDAをして」「各カラムごとに前処理する方針を定める」といった感じでした。その方針は、
・PClass…ワンホットエンコーディング
・Name…削除
・Sex…数字化(0or1)
・Age…中央値で欠損値埋め
・SibSp…そのまま
・Parch…そのまま
・Ticket…削除
・Fare…そのまま
・Cabin…削除
・Embarked…ワンホットエンコーディング
といった形でした。これからこの処理をまとめて行う関数を実装していきましょう。
データを取得
import pandas as pd
train_data = pd.read_csv('titanic/train.csv')
test_data = pd.read_csv('titanic/test.csv')
前処理関数の実装
def pretreatment(_df):
_df = _df.drop(['Name', 'Ticket', 'Cabin'], axis=1) # 不要カラムの削除
_df['Age'] = _df['Age'].fillna(_df['Age'].median()) # Ageカラムの欠損値埋め
_df = pd.get_dummies(_df, columns=['Sex'], drop_first=True, prefix='', prefix_sep='') # 男性を1、女性を0と数字化
_df = pd.get_dummies(_df, columns=['Pclass', 'Embarked']) #ワンホットエンコーディング
return _df
treated_train_data = pretreatment(train_data)
treated_train_data
OUTPUT

treated_test_data = pretreatment(test_data)
treated_test_data
OUTPUT

しっかりtrain_dataにもtest_dataにも処理が適用されています。処理関数を実装したら、しっかりと出力を確認しましょう。ワンホットエンコーディングしたときは出力されるテーブルのカラムが異なることがあります。例えばtrain_dataのEmbarkedには「C」「Q」「S」の3種類がありました。ここでtest_dataに「C」「Q」しかなかったとします。この時、ワンホットエンコーディングの処理をすると、train_dataにはEmbarkedの3列のカラムができますが、test_dataには2列しかできません。学習器にかける時は投げるテーブルのカラムを統一しなければいけないので、出力の確認はやはり必須です。pandasにはワンホットエンコーディングする時にこの問題に対処する方法がありますが、欠損値埋めを必要としたりなど処理が複雑になるため、今回は割愛して単純にワンホットエンコーディングしました。今回の出力はtrain_dataもtest_dataもカラムはSurvivedを除けば種類も順番も同じなので、どちらのテーブルにも同等の処理ができたことになります。
アルゴリズムの選定
sklearnの公式サイトには、データセットによってどんなアルゴリズムを使うかの目安を示したチートシートがあります。以下がそのチートシートとなります。
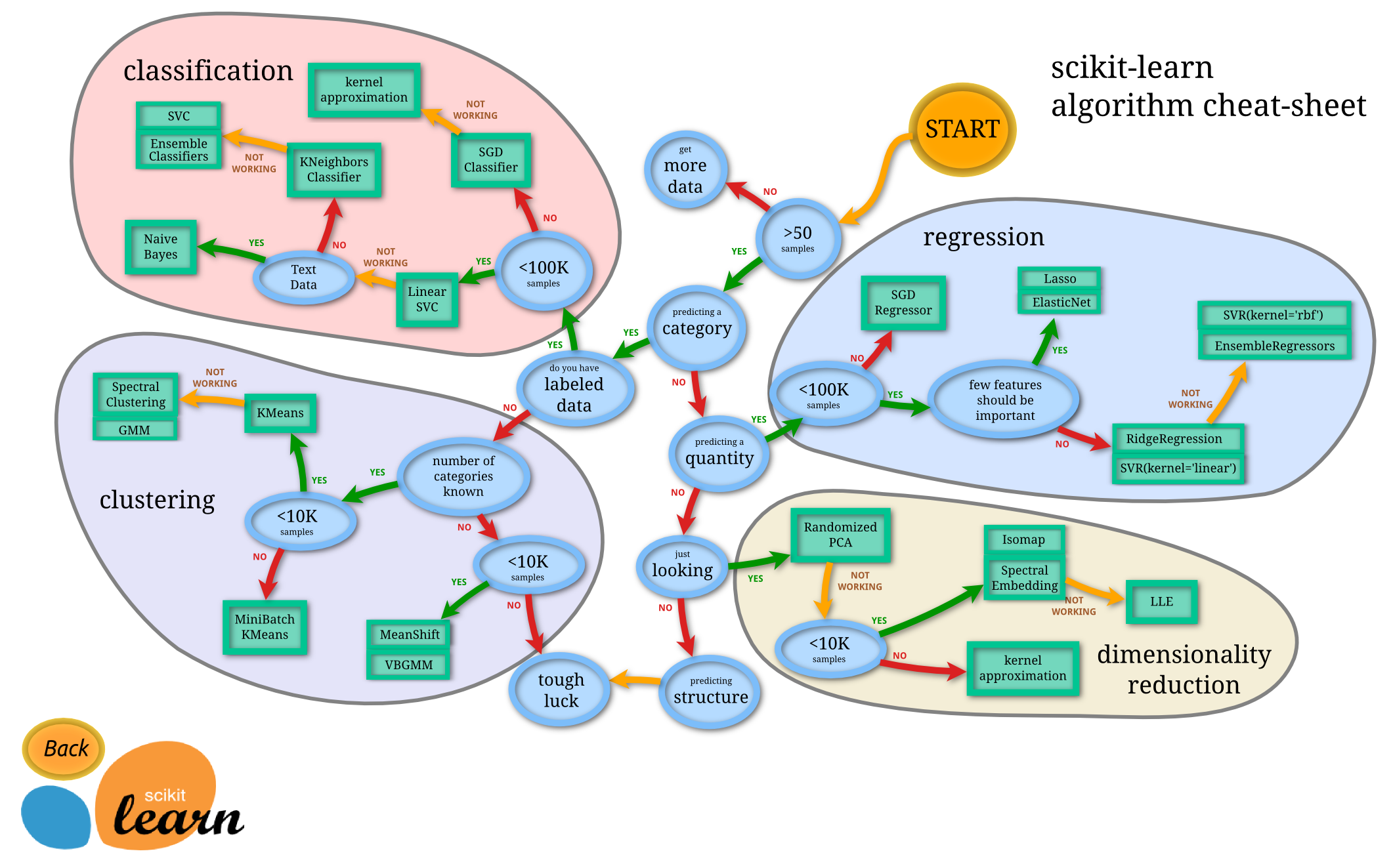
今回はこのチートシートに従ってアルゴリズムを選定していきましょう。
-
50以上データがあるか
→Yes…train_dataだけで891レコードあるので十分です -
予測するのはカテゴリか
→Yes…今回は予測する対象が連続値ではなく離散値(カテゴリ)です -
ラベル付きデータか
→Yes…train_dataの方に正解ラベル(Survived)があります。補足として、正解ラベルがないところから2つに分類する時は「クラスタリング」と言うタスクになり「教師なし学習」に分類されます。今回は「こんな正解があるよ(train_data)」から「正解データ(教師)を元に別のデータを予測してみよう(test_data)」と言う形なので「教師あり学習」に分類されます。 -
データ数は10万個以下か
→No…前述の通りです。タイタニックには10万人も乗船できません。 -
LinearSVCを試してみよう
-
上手くいかなくて、テキストデータでなければk最近傍法を試してみよう
-
上手くいかなかったらSVC(Support Vector Machine Classification)かアンサンブル分類器を試してみよう
こういった流れになります。初手としてはLinearSVC、その次にk最近傍法、それでもダメだったらSVCかアンサンブル分類器を使ってみよう。と言う形になります。早速SVCをLinearSVCを実装していきましょう。
LinearSVCのモデル
###モデルの舟形作成
モデルの作成を一気にやっていきましょう。
# モジュールのインポート
from sklearn.svm import LinearSVC
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
# 特徴量と目的変数の分割
X = treated_train_data.drop(['PassengerId','Survived'], axis=1)
y = treated_train_data['Survived']
# 標準化
sc = StandardScaler()
sc.fit(X)
X_std = sc.transform(X)
# SVCモデルのインスタンス化
clf = LinearSVC(C=1.0, class_weight='balanced', random_state=0, max_iter=10000)
# KFoldでデータを5分割し学習、resultに精度(正解率)を代入
kf = KFold(n_splits=5)
result = cross_val_score(clf, X_std, y, cv = kf, scoring = "accuracy")
# 5分割したデータのそれぞれの精度とその平均値を出力
print(result)
print(result.mean())
[0.76536313 0.78651685 0.76966292 0.75280899 0.81460674]
0.7777917268219194
モジュールのインポート
今回使用するパッケージをインポートしています。
特徴量と目的変数の分割
train_dataからSurvivedを落としたもの(特徴量テーブル)をX、train_dataのSurvivedだけ(正解ラベル)をyに代入しています。
標準化
「標準化」とはテーブルのスケールを揃える方法です。どういうことかというと「年齢カラムは最大値90で最小値0、価格カラムは最大値100,000,000で最小値1,000」といった様に、カラム間で値のスケールが異なると、学習に時間がかかったり精度の低下につながったりしてしまいます。これを避けるために特徴量テーブルの全てのカラムについて「平均0、分散1」にする操作を加えています。
1行目は「標準化するStandardScalerをscという名前でインスタンス化したよ」
2行目は「X(特徴量テーブル)の情報をscに知らせているよ」
3行目は「その情報を元にXを標準化して新しく取得したテーブルをX_stdに代入したよ」
X_stdを見てみましょう。
X_std
array([[-1.73010796, -0.56573646, 0.43279337, ..., -0.48204268,
-0.30756234, 0.61930636],
[-1.72622007, 0.66386103, 0.43279337, ..., 2.0745051 ,
-0.30756234, -1.61470971],
[-1.72233219, -0.25833709, -0.4745452 , ..., -0.48204268,
-0.30756234, 0.61930636],
...,
[ 1.72233219, -0.1046374 , 0.43279337, ..., -0.48204268,
-0.30756234, 0.61930636],
[ 1.72622007, -0.25833709, -0.4745452 , ..., 2.0745051 ,
-0.30756234, -1.61470971],
[ 1.73010796, 0.20276197, -0.4745452 , ..., -0.48204268,
3.25137334, -1.61470971]])
numpyを覚えていますか?行列を扱うパッケージでpandasよりも表計算が早いものの視認性が低いといった特徴があります。scikit-learnは内部的にnumpyを使っているので、pandasのテーブルを投げてもnumpy配列を出力してきます。上に表示されているテーブルはnumpyの配列なので非常に見にくいです。pandasに変換しましょう。
pd.DataFrame(X_std, columns=X.columns)
OUTPUT
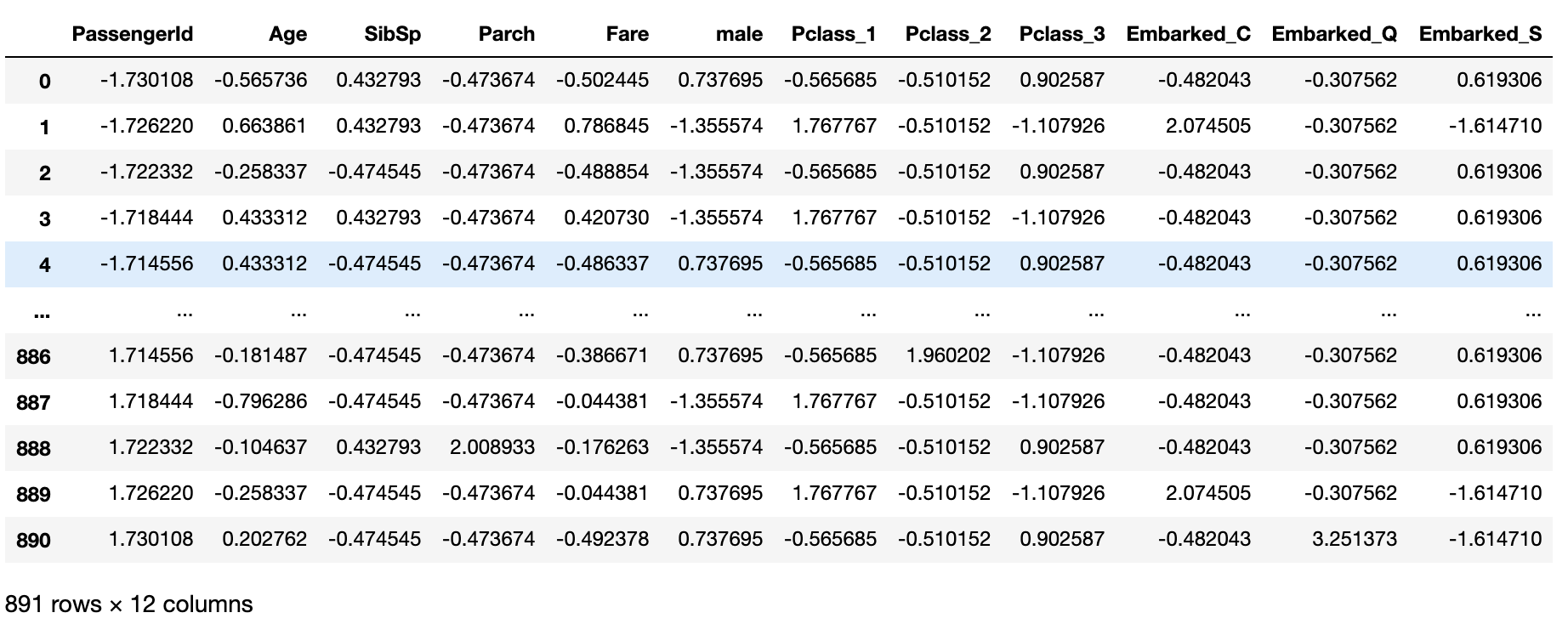
見やすくなりましたね。これを見ると全てのカラムの値が0に近い値になっていて、値のスケールが調整されたことが分かります。
SVCモデルのインスタンス化
今回使うLinearSVCを
C=1.0, class_weight='balanced', random_state=0, max_iter=10000
というパラメータ設定でインスタンス化しました。LinearSVCはCのパラメータが非常に重要になるのであとで調整します。
KFoldでデータを5分割し学習、resultに精度(正解率)を代入
「KFold」初登場のワードです。これはモデルの精度を正確に評価するための操作です。最初にXとyのペアをk分割(今回は5分割)します。そしてそのうちのk-1(4)つを用いてモデルを学習させ、残りの1つでそのモデルの精度を評価します。これを異なるk-1(4)つの組を使って合計k(5)回繰り返します。この時k(5)個の評価指標が得られるので、その平均値をそのモデル自体の精度とします。

参照:(https://axa.biopapyrus.jp/machine-learning/model-evaluation/k-fold-cross-validation.html)
train_test_splitはただ単に割合に応じてデータを2分割して訓練データと評価データとしていましたが、これは分割によっては「たまたま」良い精度が出てしまったりします。学習したモデルが評価用データに対して良い精度を示したが、それは偶然で他のデータに対しては精度が低くなってしまうかもしれません。
KFoldはデータを5個に分けて5回学習してその精度を出すので、train_test_splitよりも精度への信頼性が高いです。
1行目は「KFoldを実行するインスタンスの分割数5に設定したよ」
kf = KFold(n_splits=5)
2行目は「X_stdとyをkfで分割してそれぞれclfのモデルに学習させ、その精度をaccuracy(正答率)で評価したよ」
result = cross_val_score(clf, X_std, y, cv = kf, scoring = "accuracy")
5分割したデータのそれぞれの精度とその平均値を出力
これを見るとresultは5つの値が入っています。これはそれぞれのKFoldでの評価指標(正答率)です。ばらつきがあります。やはり学習するデータや評価するデータによって精度が変わることが示されています。その平均値は0.7777917268219194となっています。Kaggleでの最初の提出のスコアが0.76555だったことから、これは精度が上ったと考えられます(実際に提出してみないと分からないですが)。
ここまでで非常に大変だったと思いますが、ここまで一連の操作の結論は
「LinearSVCの設定がC=1.0の時、そのモデルの精度は約0.778」
となります。とりあえず精度が出ました。あとはパラメータチューニングをして、最終的なLinearSVCの精度を出しましょう。
パラメータチューニング
LinearSVCのモデルでのC=1での精度は出ました。ここからはこのCの値を調整して精度の最も高いLinearSVCモデルを作りましょう。
# パラメータ調整用のモジュールをインポート
from sklearn.model_selection import GridSearchCV
# 調整するパラメータの詳細設定
tuned_parameters = [
{'C': [0.01, 0.1, 1, 10, 100, 1000, 10000],
'class_weight': ['balanced'],
'random_state': [0],
'max_iter': [10000]}]
# グリッドサーチの設定
clf_GS = GridSearchCV(
LinearSVC(), # 使用するモデル
tuned_parameters, #調整するパラメータのリスト
cv=5, # KFoldの分割数
scoring='accuracy' # 評価指標
)
# グリッドサーチによる精度測定&出力
clf_GS.fit(X_std, y)
print(clf_GS.best_params_)
print(clf_GS.best_score_)
{'C': 10, 'class_weight': 'balanced', 'max_iter': 10000, 'random_state': 0}
0.7811436821291821
これは「Cが10の時に一番いい精度(約0.781)が出たよ」と言っています。先ほどのC=1の時よりも精度が向上していますね。細かく解説していきます。
パラメータ調整用のモジュールをインポート
パラメータ調整のパッケージにはsklearnに付属した「GridSearchCV」と2018年12月にPreferedNetworks社がリリースした「optuna」があります。後者の方が高速で細かいパラメータ調整ができるものの、リリースが最近という理由でanacondaに付属していません。pip3やcondaを使えば利用はできるものの、今回は環境面から採用を見送ります。対するGridSearchCVはoptunaが出るまでパラメータチューニングのファーストチョイスでした。オライリーなど多くの書籍ではこちらの方が多く取り上げられていて、アルゴリズムも理解しやすいです。パラメータ候補のリストを投げると総当たりで調べ上げてくれます。
調整するパラメータの詳細設定
調整するパラメータの候補を辞書型で指定します。今回はCしかチューニングしないので「'C': [0.01, 0.1, 1, 10, 100, 1000, 10000]」以外の部分は固定になっています。このリスト内の数字全てに対して学習を実行し、精度を測定します。
グリッドサーチの設定
以上がグリッドサーチの記法です。少し複雑です。暗記してしまいましょう。最初にモデルを指定、その次に調整するパラメータのリスト、その次KFoldの分割数、最後に評価指標を指定します。データをclf_GSに投げると勝手にKFoldして精度を評価してくれるので便利です。
グリッドサーチによる精度測定&出力
fit(特徴量デーブル, 正解ラベル)とすると学習が始まります。しばらくして学習が終わると、clf_GSにこの総当たりの学習で一番精度の高かったパラメータとその精度が記憶されているので出力します。
ここで初めて最終的な精度が得られました。結果は
「LinearCSVのアルゴリズムではC=10のときが最も精度が高くその精度は0.781だった」
となります。
LinearCSVのモデルでtest_dataで予測値を出力
ここからは一気にいきます。
treated_test_data = treated_test_data.fillna(test_data.median(numeric_only=True))
clf = LinearSVC(C=10, class_weight='balanced', random_state=0, max_iter=10000)
clf.fit(X_std, y)
X_test = treated_test_data.drop(['PassengerId'], axis=1)
X_test_std = sc.transform(X_test)
y_test = clf.predict(X_test_std)
1行目「実はtrain_dataにはなかったFareの欠損がtest_dataにはあったので平均値で穴埋めしたよ」
3行目「C=10に設定し直したLinearSVCモデルをインスタンス化したよ」
4行目「train_dataで学習したよ」
6行目「test_dataから乗客識別番号を落としたよ」
8行目「test_dataを標準化したよ」
10行目「学習器にtest_dataを投げてその予測値をy_testに代入したよ」
天下り的ですがtest_dataのFareには欠損があります。train_dataにはなかったのでここは応急処置的に平均値で穴埋めしています。
さて予測結果はどうだったんでしょうか。
y_test
array([0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0,
1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1,
1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1,
1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1,
1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1,
0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1,
1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1,
0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0,
1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1,
0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0,
0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0,
0, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0,
1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0,
0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0,
1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1,
0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0])
1と0の予測値がしっかりと出力されていますね。
#出力を整形してKaggleに提出
y_pred_series = pd.Series(y_test, name='Survived')
LinearSVC_submission = pd.concat([test_data['PassengerId'], y_pred_series], axis=1)
LinearSVC_submission.to_csv('titanic/LinearSVC.csv', index=False)
1行目は「y_testをpandasの一列にしたよ」
3行目は「y_testのPassengerIdとy_testをくっつけたよ」
5行目は「このテーブルをcsvファイルとしてtitanicフォルダにLinearSVC.csvという名前で保存したよ」
はい。やっと予測結果が出力できました。LinearSVC_submissionを見てみましょう。
LinearSVC_submission
OUTPUT
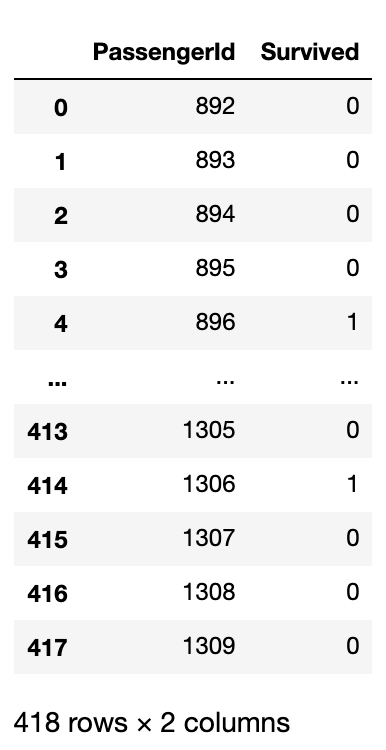
いい感じのテーブルが得られました。これをKaggleに提出してみましょう!
お疲れ様でした!
非常に大変だったと思います。ただここに書いてあることを実行できる様になれば、例えどんなテーブルデータがきても対処できるようなります。基本的にはここに書いてあることの応用です。皆さんも是非、新しいキャリアの選択肢やスキルとして「AI」に挑戦してみてください。本当にお疲れ様でした!
続き
以下の記事をご覧ください!
【入門】Titanic号乗客の生死を予想しよう!(4)
紹介
株式会社 Panta Rheiでは「Everything Analysable」を標榜とし、世の中にあるあらゆる定性的な対象をAIによって定量化する事業をおこなっております。
AIに召し上がっていただく綺麗なデータを作る、データフローを整形するなどの課題や、そもそものAIの内製化等、挑戦したい試みがあればぜひご一報ください!